Student’s-t Mixture Regression-Based Robust Soft Sensor Development for Multimode Industrial Processes


Abstract
:1. Introduction
2. Preliminaries
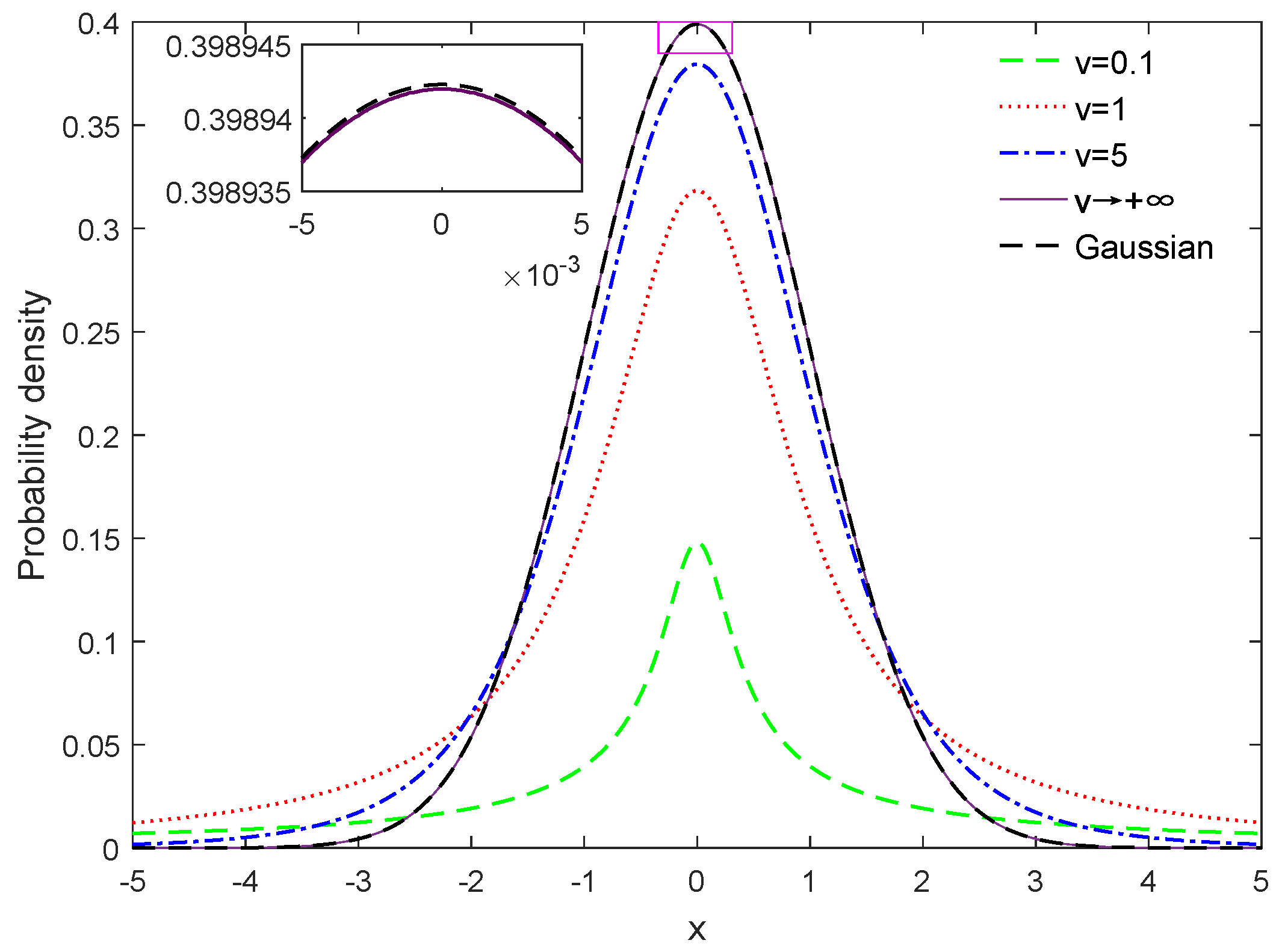
2.1. Student’s-t Distribution
2.2. Student’s-t Mixture Model
3. Methodology
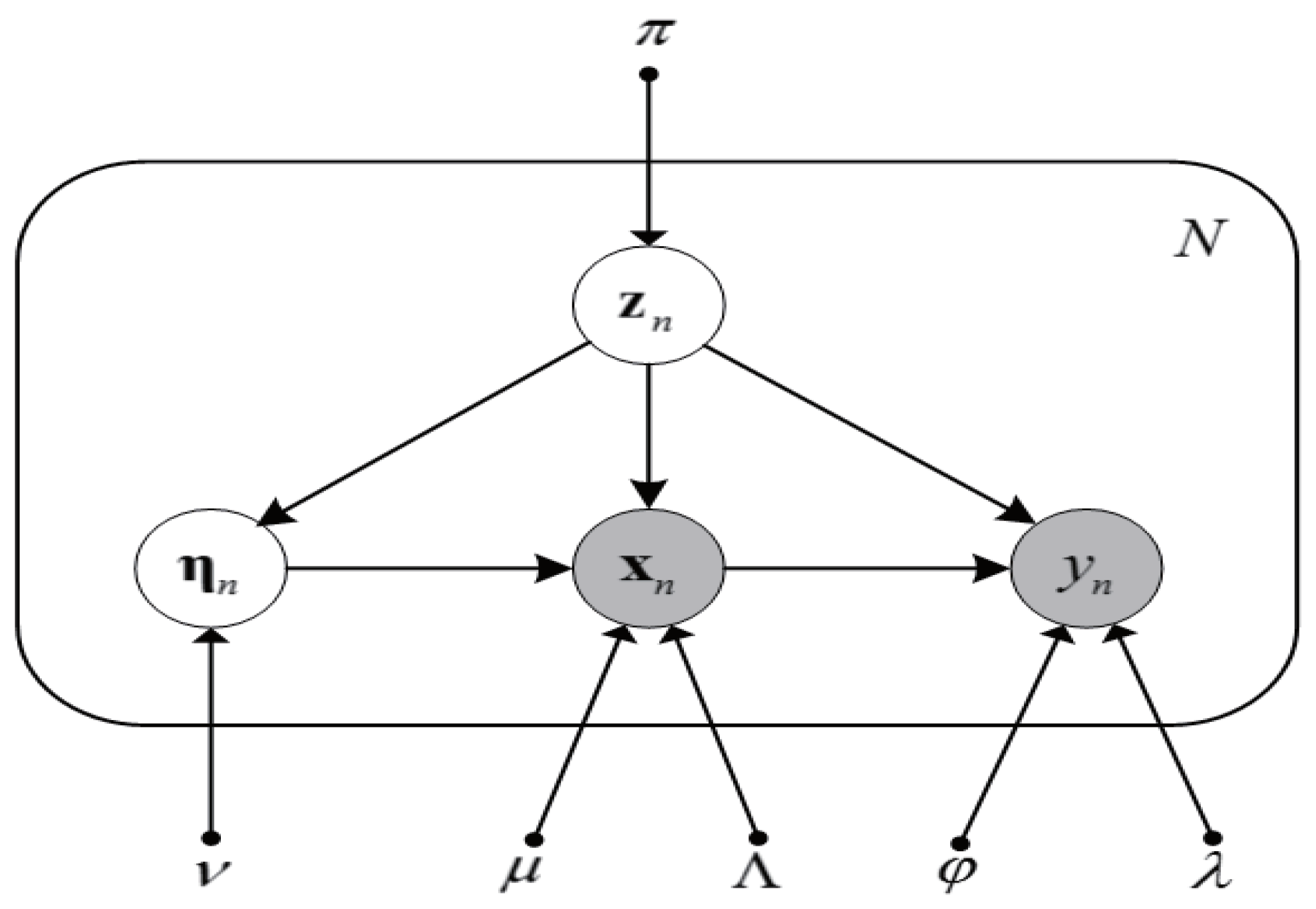
3.1. Student’s-t Mixture Regression
3.2. Parameters Learning for the SMR
| Algorithm 1 Pseudocode for training SMR. |
| Given K, initialize , and the ; Set ; while do Set ; for ; do Calculate using Equation (16); Calculate and using Equation (19) and Equation (20), respectively; end for for do Update , , and , with Equation (26), Equation (27), Equation (28), Equation (29) and Equation (32) respectively; Solve Equation (31) for ; end for Calculate using Equation (21). if the convergence criterion in Equation (33) is satisfied then Terminate while; end if end while |
3.3. Soft Sensor Development Based on SMR
4. Case Studies
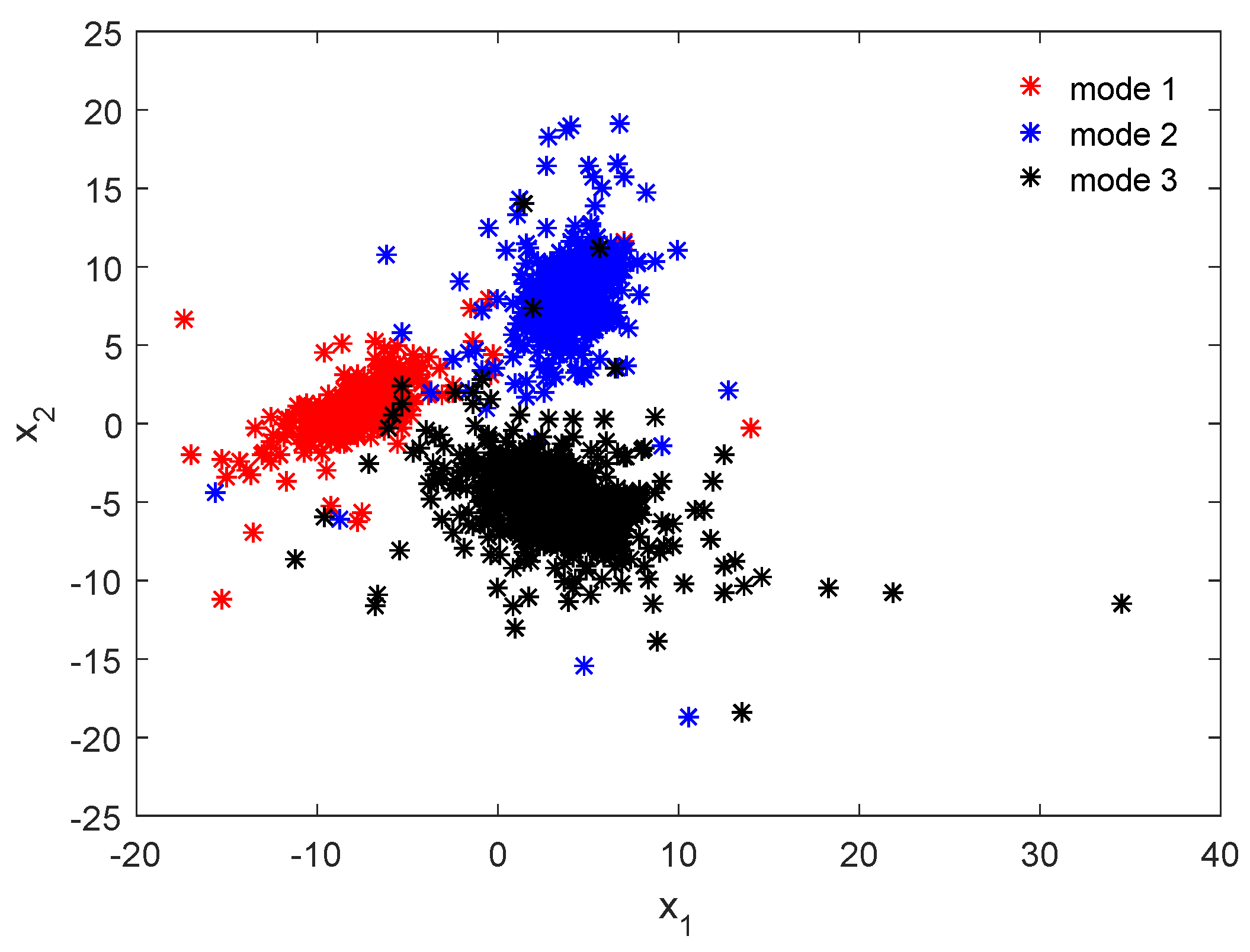
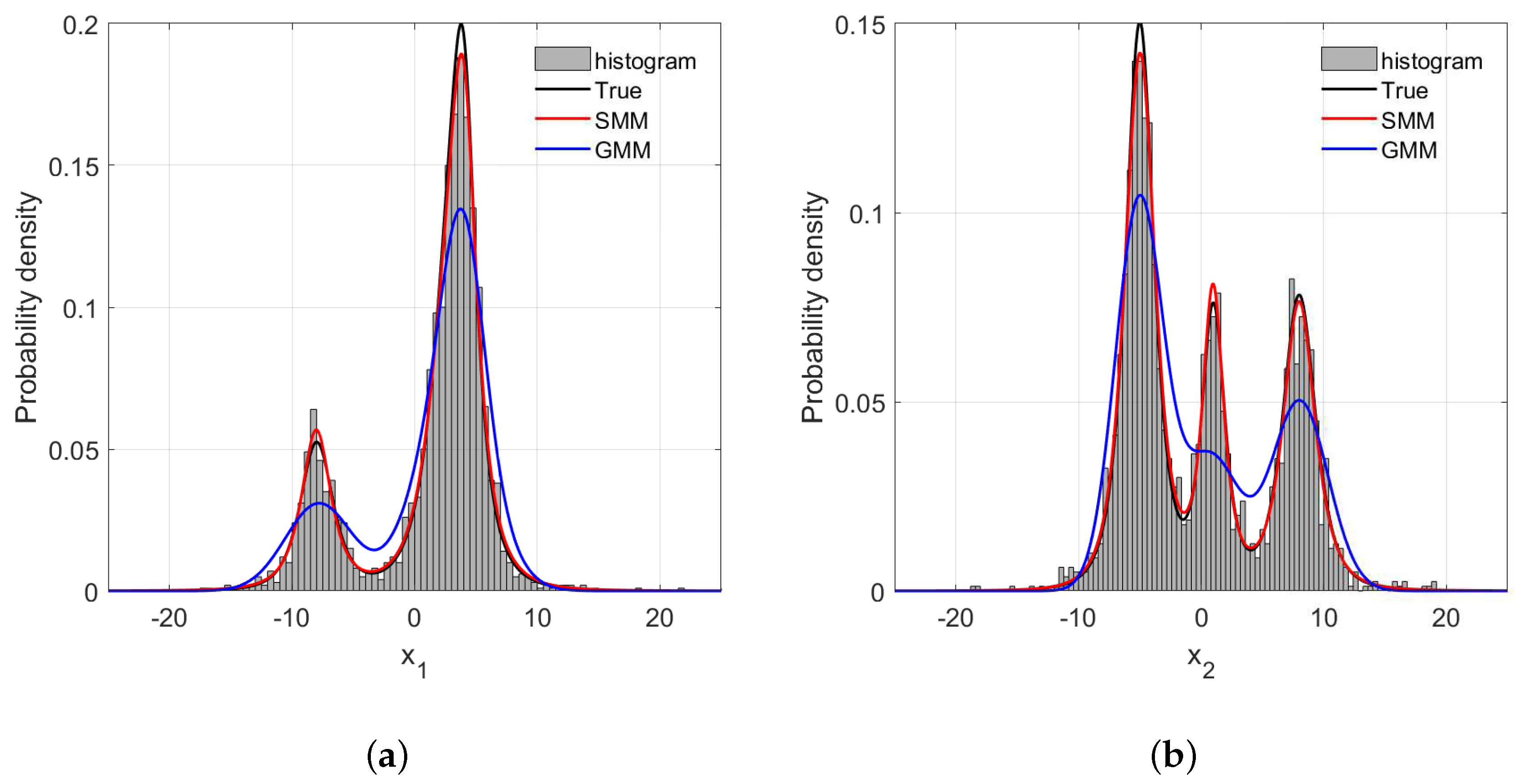
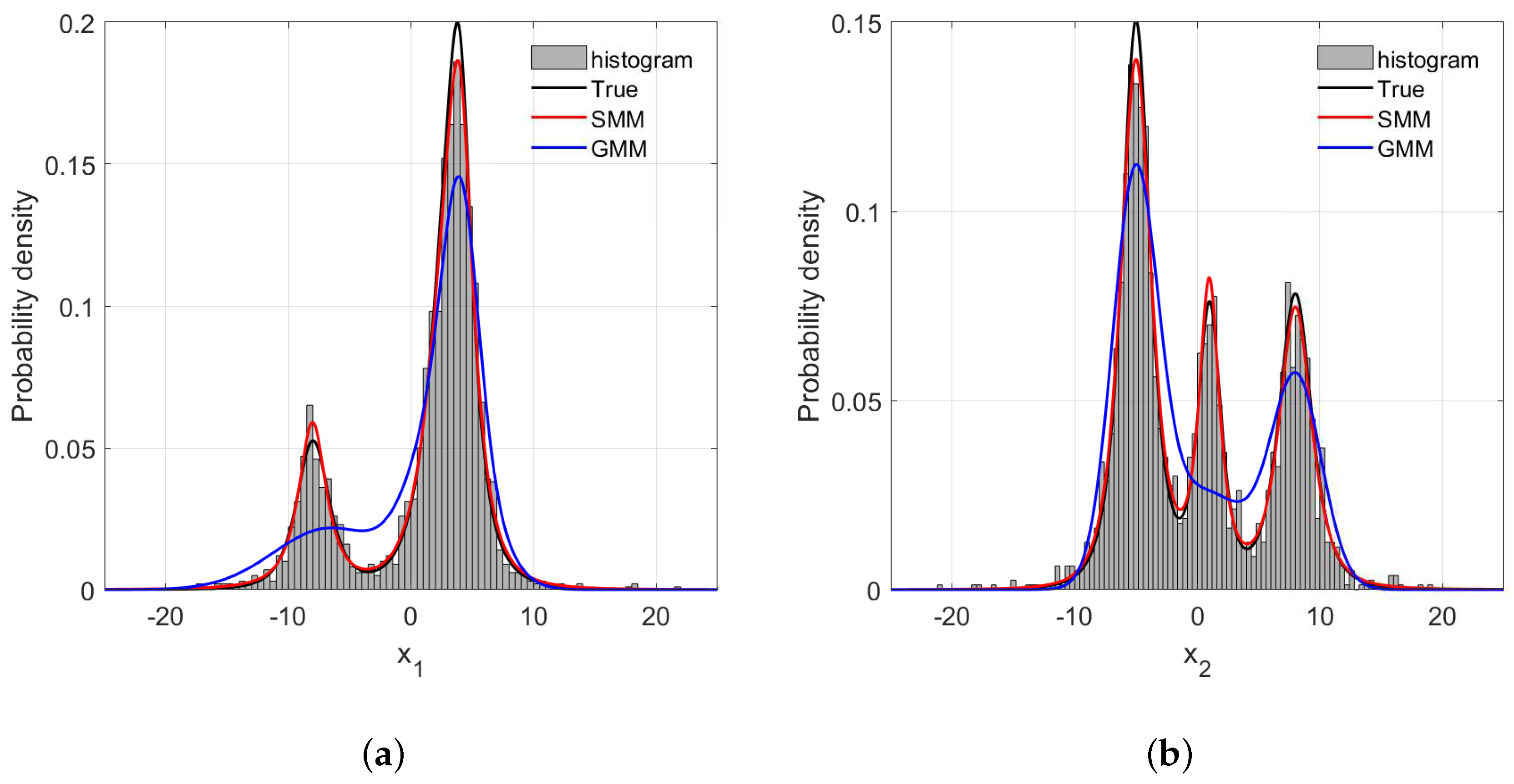
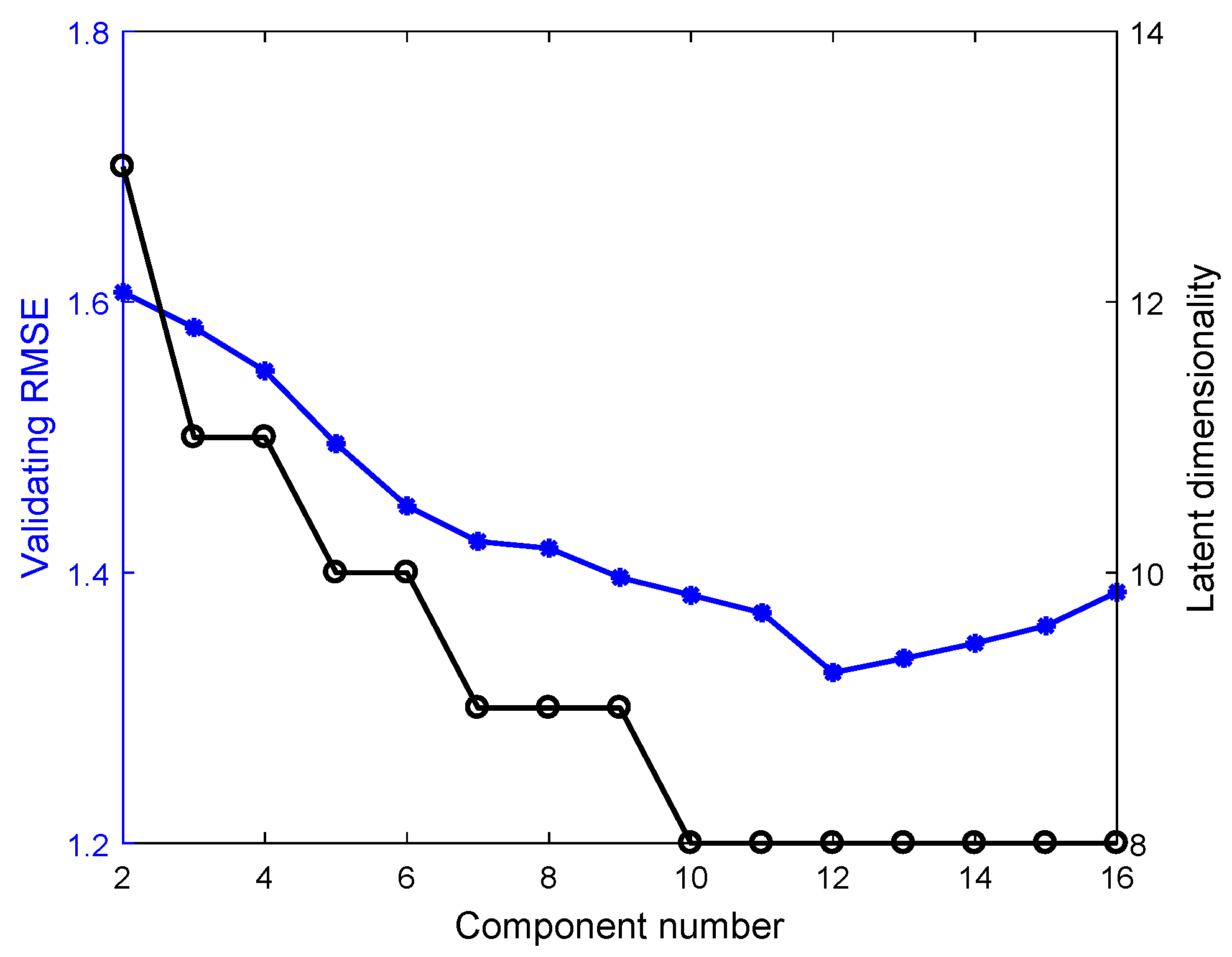
4.1. Numerical Example
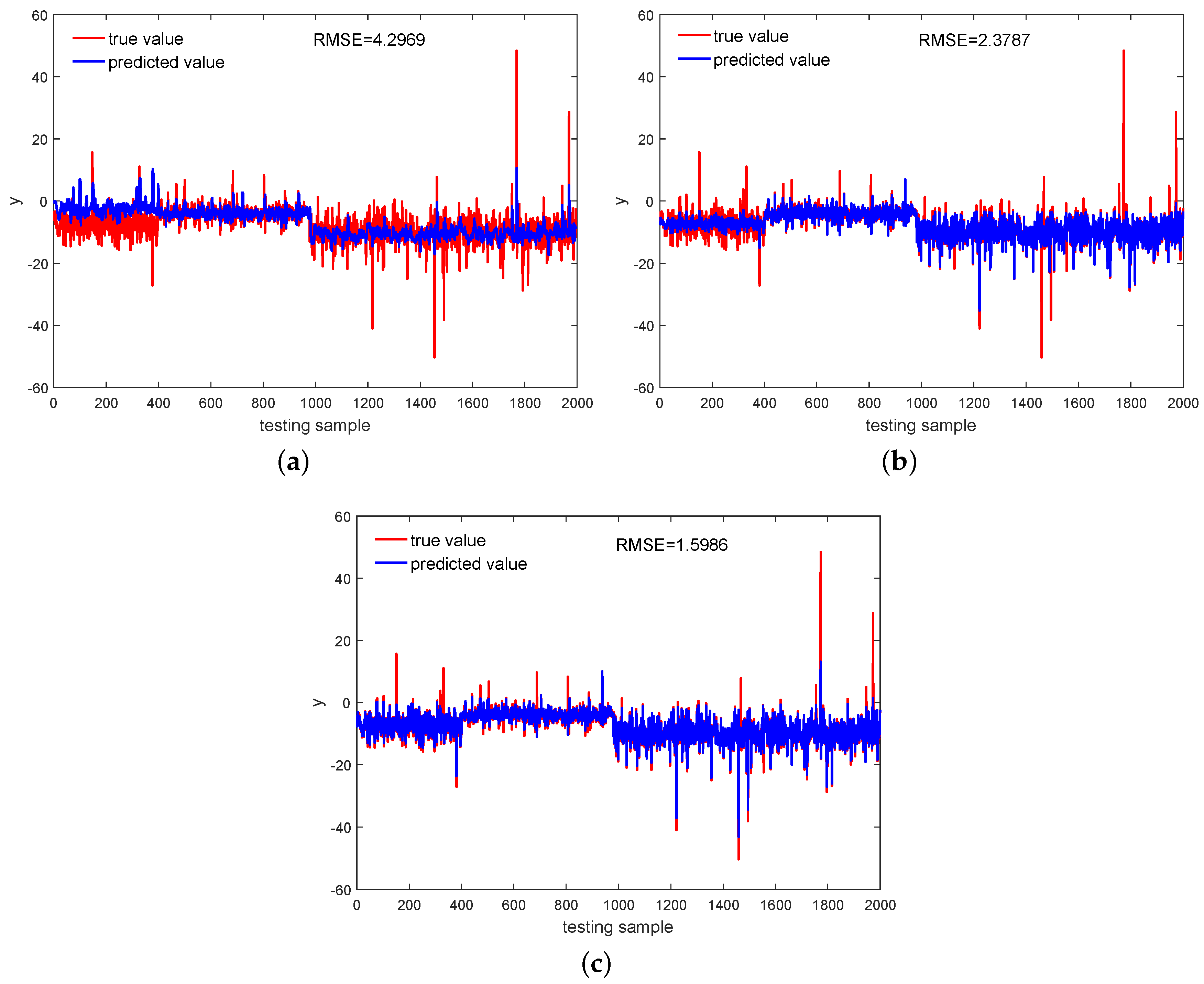
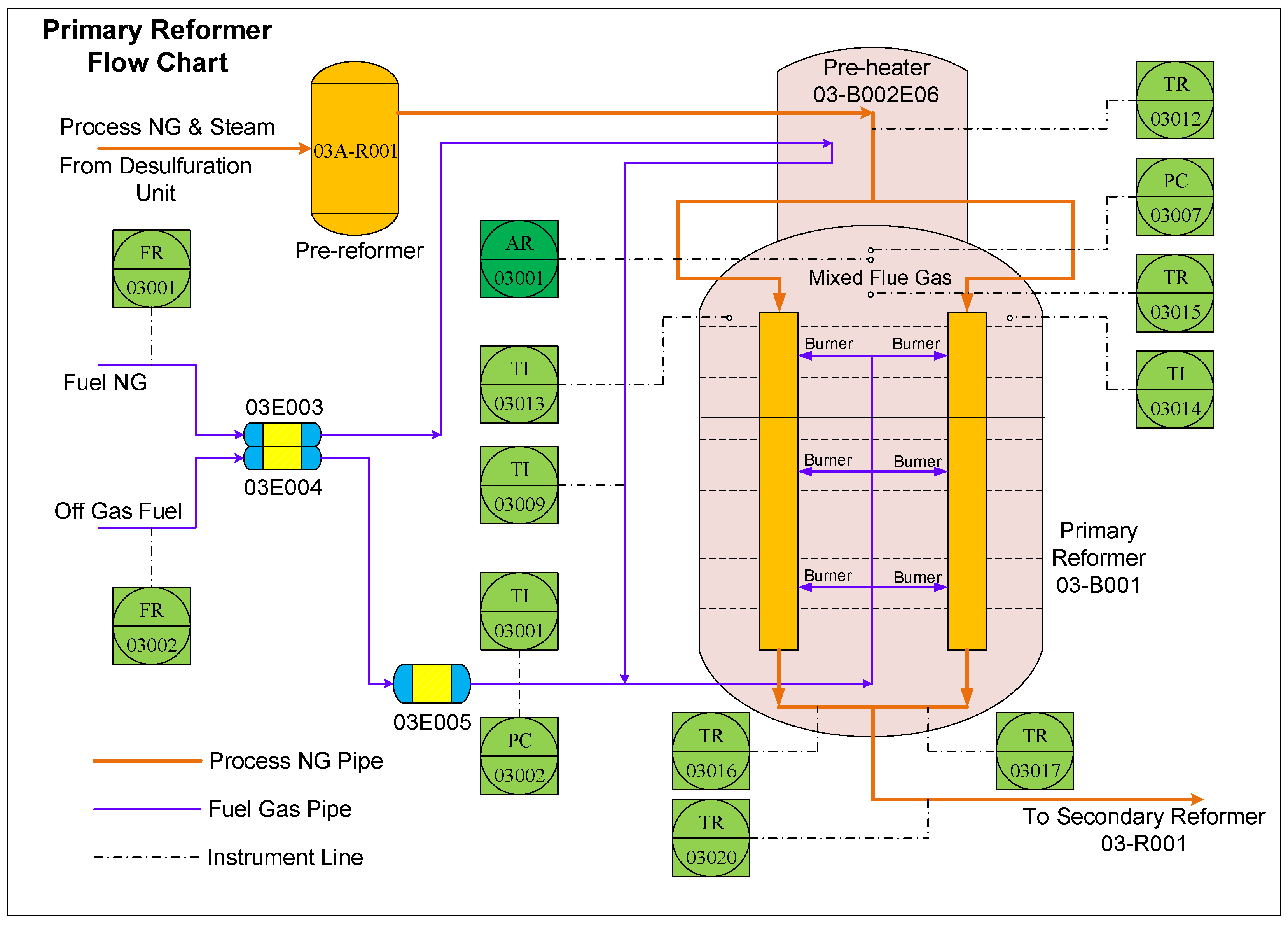
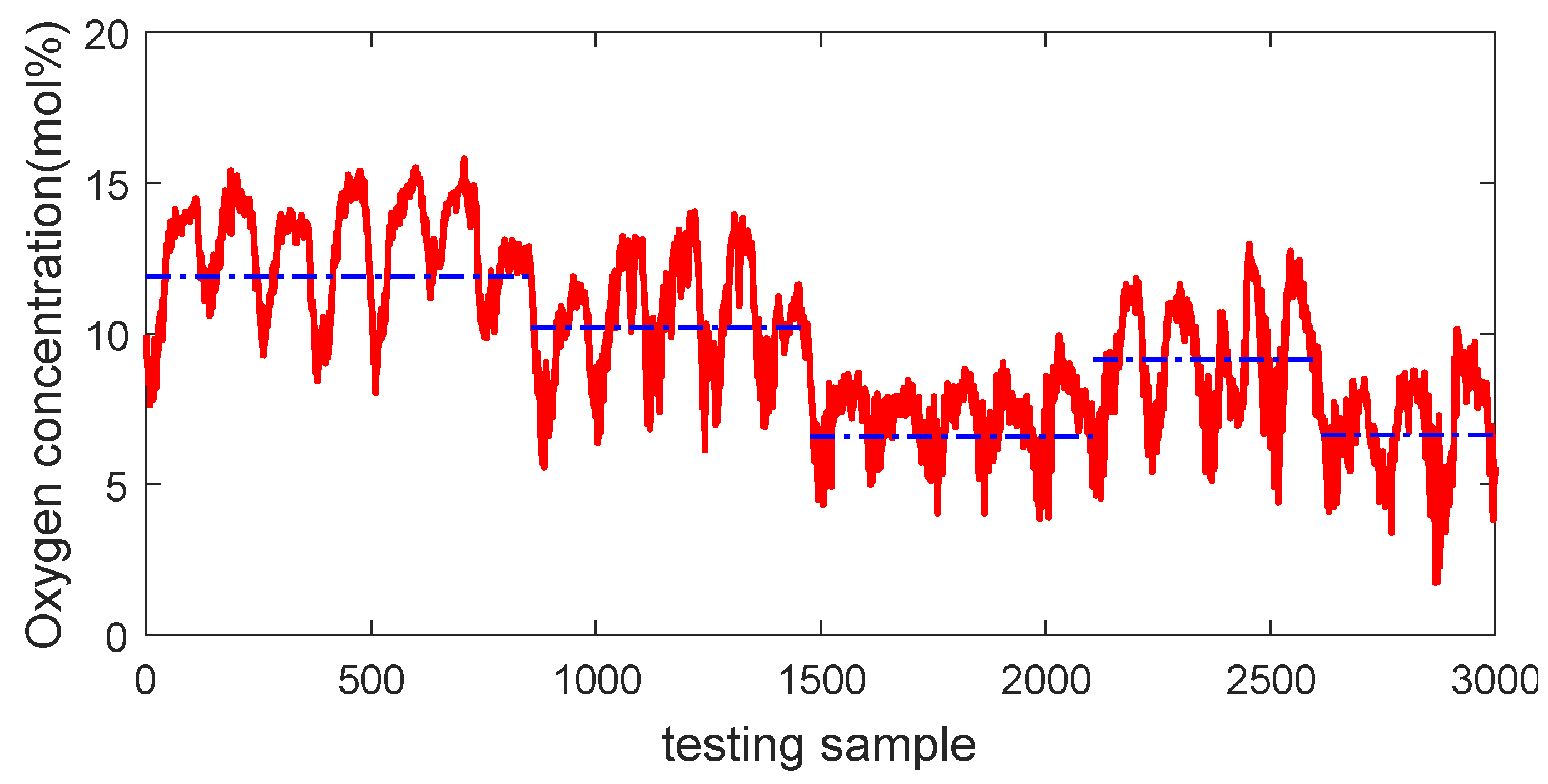
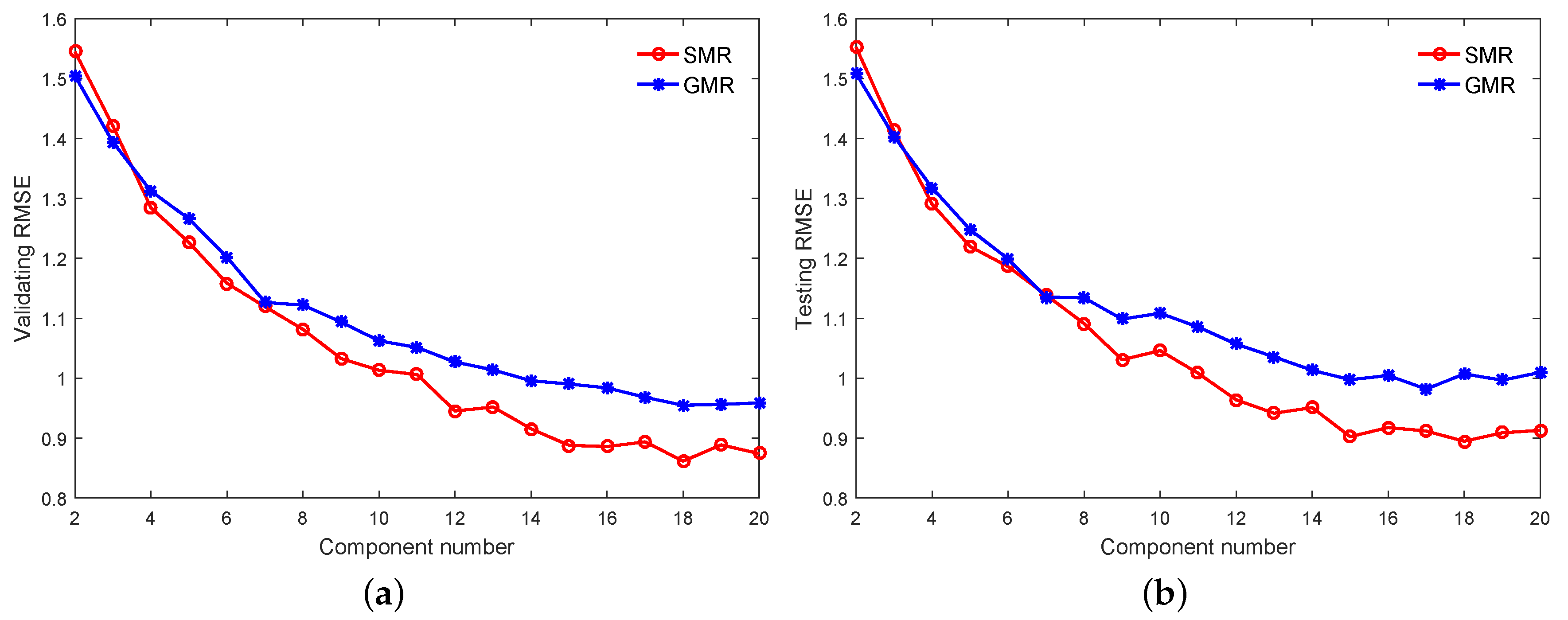
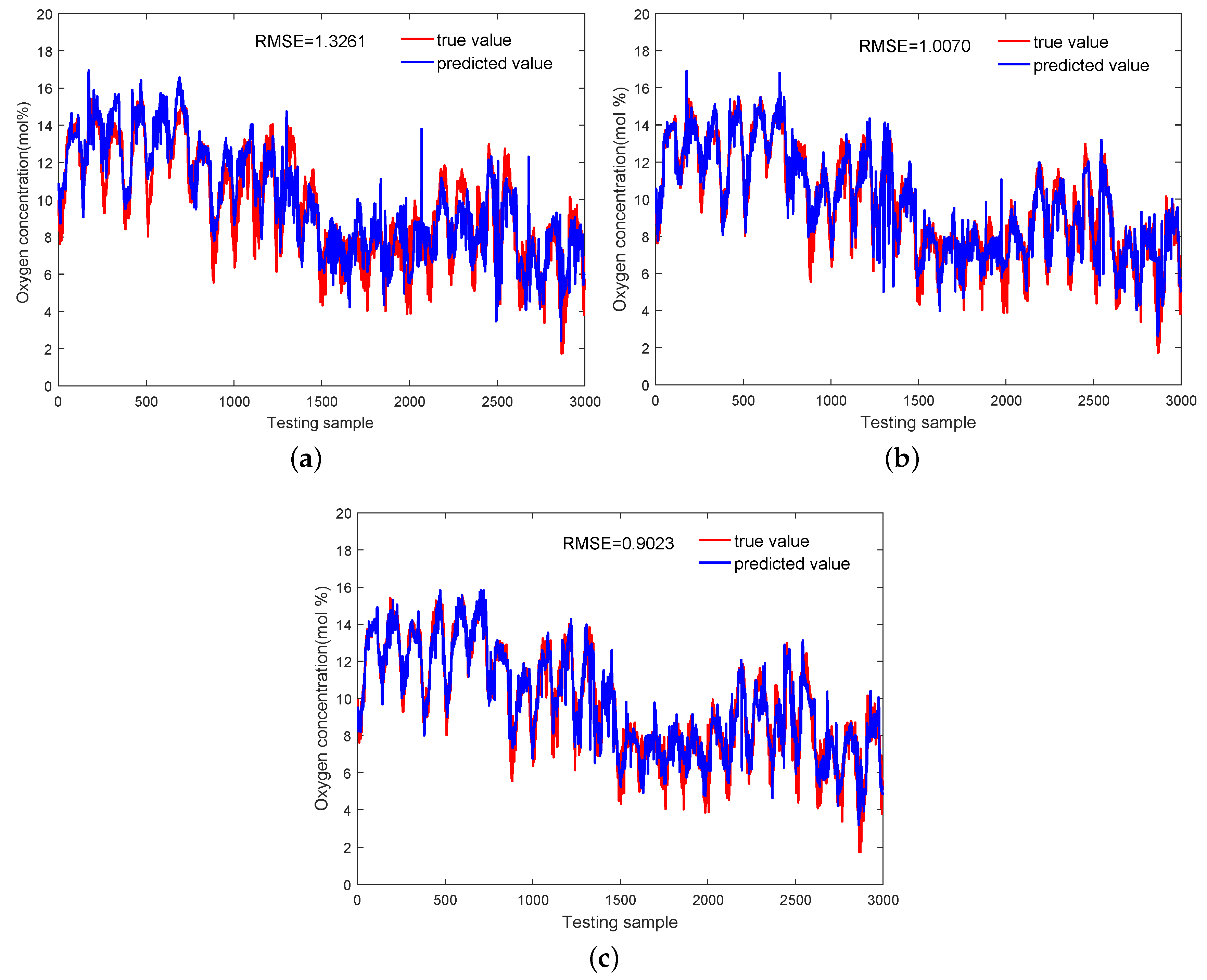
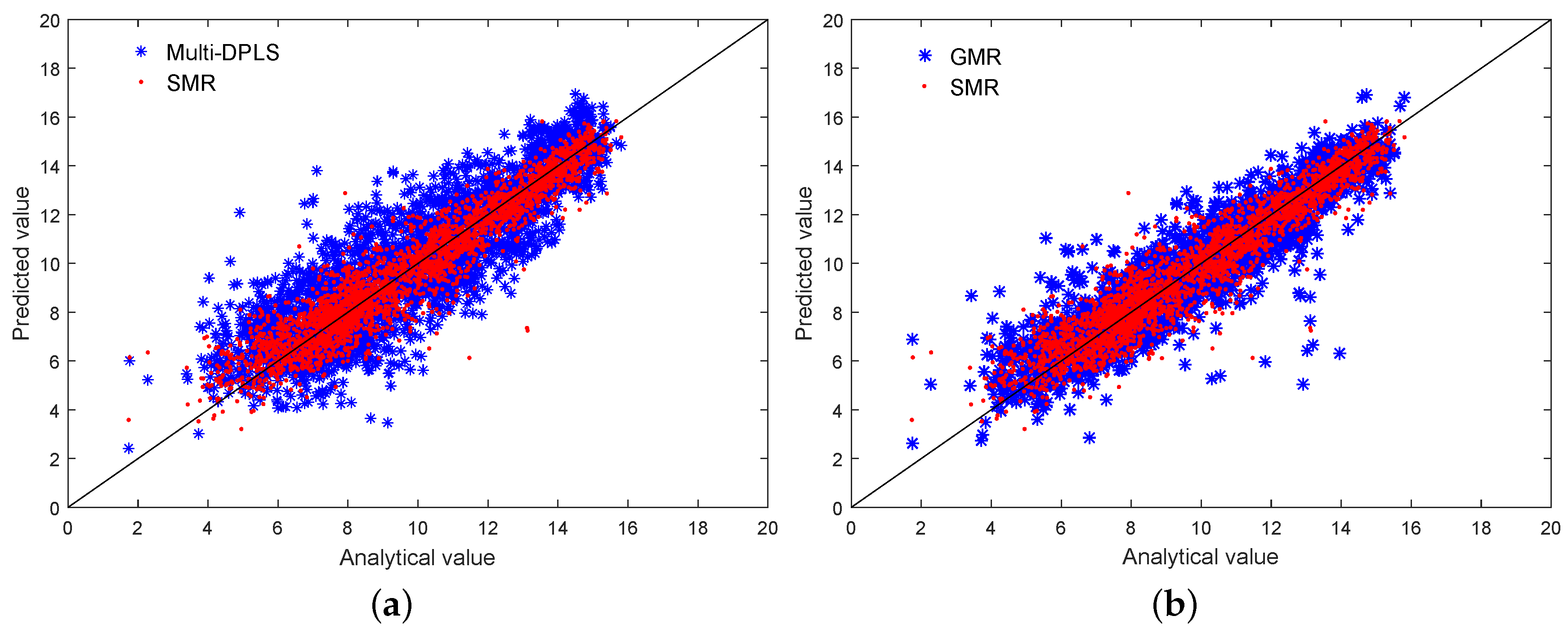
4.2. Primary Reformer
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shao, W.; Tian, X. Semi-supervised Selective Ensemble Learning Based On Distance to Model for Nonlinear Soft Sensor Development. Neurocomputing 2017, 222, 91–104. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z.; Gao, F. Review of Recent Research on Data-Based Process Monitoring. Ind. Eng. Chem. Res. 2013, 10, 3543–3562. [Google Scholar] [CrossRef]
- Kruger, U.; Xie, L. Statistical Monitoring of Complex Multivariate Processes: With Applications in Industrial Process Control. J. Qual. Technol. 2012, 45, 118–120. [Google Scholar]
- Ge, Z.; Song, Z.; Ding, S.; Huang, B. Data mining and analytics in the process industry: The role of machine learning. IEEE Access 2017, 5, 20590–20616. [Google Scholar] [CrossRef]
- Ge, Z. Review on data-driven modeling and monitoring for plant-wide industrial processes. Chemom. Intell. Lab. Syst. 2017, 171, 16–25. [Google Scholar] [CrossRef]
- Fortuna, L.; Graziani, S.; Xibilia, M. Soft sensors for product quality monitoring in debutanizer distillation columns. Control Eng. Pract. 2005, 13, 499–508. [Google Scholar] [CrossRef]
- Sharmin, R.; Sundararaj, U.; Shah, S.; Vande Griend, L.; Sun, Y.-J. Inferential sensors for estimation of polymer quality parameters: Industrial application of a PLS-based soft sensor for a LDPE plant. Chem. Eng. Sci. 2006, 61, 6372–6384. [Google Scholar] [CrossRef]
- Fortuna, L.; Graziani, S.; Rizzo, A.; Xibilia, M.G. Soft Sensors for Monitoring and Control of Industrial Processes; Spring Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Kano, M.; Fujiwara, K. Virtual sensing technology in process industries: Trends and challenges revealed by recent industrial applications. J. Chem. Eng. Jpn. 2013, 46, 1–17. [Google Scholar] [CrossRef]
- Kadlec, P.; Gabrys, B.; Strandt, S. Data-driven soft sensors in the process industry. Comput. Chem. Eng. 2009, 33, 795–814. [Google Scholar] [CrossRef]
- Kadlec, P.; Grbić, R.; Gabrys, B. Review of adaptation mechanisms for data-driven soft sensors. Comput. Chem. Eng. 2011, 35, 1–24. [Google Scholar] [CrossRef]
- Prasad, V.; Schley, M.; Russo, L.P.; Bequette, B.W. Product property and production rate control of styrene polymerization. J. Process Control 2002, 12, 353–372. [Google Scholar] [CrossRef]
- Yuan, X.; Ge, Z.; Song, Z. Soft sensor model development in multiphase/multimode processes based on Gaussian mixture regression. Chemom. Intell. Lab. Syst. 2014, 138, 97–109. [Google Scholar] [CrossRef]
- Kano, M.; Nakagawa, Y. Data-based process monitoring, process control, and quality improvement: Recent developments and applications in steel industry. Comput. Chem. Eng. 2008, 32, 12–24. [Google Scholar] [CrossRef] [Green Version]
- Shao, W.; Tian, X. Adaptive soft sensor for quality prediction of chemical processes based on selective ensemble of local partial least squares models. Chem. Eng. Res. Des. 2015, 95, 113–132. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z. Semisupervised Bayesian method for soft sensor modeling with unlabeled data samples. AIChE J. 2011, 57, 2109–2119. [Google Scholar] [CrossRef]
- Gonzaga, J.C.B.; Meleiro, L.A.C.; Kiang, C.; Maciel Filho, R. ANN-based soft-sensor for real-time process monitoring and control of an industrial polymerization process. Comput. Chem. Eng. 2009, 33, 43–49. [Google Scholar] [CrossRef]
- Kaneko, H.; Funatsu, K. Database monitoring index for adaptive soft sensors and the application to industrial process. AIChE J. 2014, 60, 160–169. [Google Scholar] [CrossRef]
- Kano, M.; Ogawa, M. The state of the art in chemical process control in Japan: Good practice and questionnaire survey. J. Process Control 2010, 20, 969–982. [Google Scholar] [CrossRef]
- Souza, F.A.A.; Araújo, R. Mixture of partial least squares experts and application in prediction settings with multiple operating modes. Chemom. Intell. Lab. Syst. 2014, 130, 192–202. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Ge, Z.; Song, Z. Variational Bayesian Gaussian mixture regression for soft sensing key variables in non-Gaussian industrial processes. IEEE Trans. Control Syst. Technol. 2017, 25, 1092–1099. [Google Scholar] [CrossRef]
- Peel, D.; McLachlan, G.J. Robust mixture modeling using the t distribution. Stat. Comput. 2000, 10, 339–348. [Google Scholar] [CrossRef]
- Chatzis, S.; Varvarigou, T. Robust fuzzy clustering using mixtures of Student’s-t distributions. Pattern Recognit. Lett. 2008, 29, 1901–1905. [Google Scholar] [CrossRef]
- Svensén, M.; Bishop, C.M. Robust Bayesian mixture modelling. Neurocomputing 2005, 64, 235–252. [Google Scholar] [CrossRef] [Green Version]
- Gerogiannis, D.; Nikou, C.; Likas, A. The mixtures of Student’s t-distributions as a robust framework for rigid registration. Image Vis. Comput. 2009, 27, 1285–1294. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, Q.M.J.; Nguyen, T.M. Image segmentation by a new weighted Student’s t-mixture model. IET Image Process. 2013, 7, 240–251. [Google Scholar] [CrossRef]
- Moghaddam, Z.; Piccardi, M. Robust density modelling using the student’s t-distribution for human action recognition. In Proceedings of the 2011 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 3261–3264. [Google Scholar]
- Nguyen, T.M.; Wu, Q.M.J. Robust student’s-t mixture model with spatial constraints and its application in medical image segmentation. IEEE Trans. Med. Imaging 2012, 31, 103–116. [Google Scholar] [CrossRef] [PubMed]
- Makantasis, K.; Doulamis, A.; Matsatsinis, N.F. Student-t background modeling for persons’fall detection through visual cues. In Proceedings of the 2012 13th International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), Dublin, Ireland, 23–25 May 2012. [Google Scholar]
- Nguyen, T.; Wu, Q.M.J.; Zhang, H. Asymmetric mixture model with simultaneous feature selection and model detection. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 400–408. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C. Pattern Recognition and Machine Learning, 1st ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Liu, C.; Rubin, D.B. ML estimation of the t distribution using EM and its extensions, ECM and ECME. Stat. Sin. 1995, 5, 19–39. [Google Scholar]
- Yao, L.; Ge, Z. Moving window adaptive soft sensor for state shifting process based on weighted supervised latent factor analysis. Control Eng. Pract. 2017, 61, 72–80. [Google Scholar] [CrossRef]
- Peng, K.; Zhang, K.; You, B.; Dong, J. Quality-related prediction and monitoring of multi-mode processes using multiple PLS with application to an industrial hot strip mill. Neurocomputing 2015, 168, 1094–1103. [Google Scholar] [CrossRef]
- Shao, W.; Tian, X.; Wang, P. Supervised local and non-local structure preserving projections with application to just-in-time learning for adaptive soft sensor. Chin. J. Chem. Eng. 2015, 23, 1925–1934. [Google Scholar] [CrossRef]
- Zhu, J.; Ge, Z.; Song, Z. Multimode process data modeling: A Dirichlet process mixture model based Bayesian robust factor analyzer approach. Chemom. Intell. Lab. Syst. 2015, 142, 231–244. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.2 | 0.3 | 0.5 | |
| 3 | 3 | 3 | |
| 0.25 | 0.25 | 0.25 |
| Outliers | Dataset | Multi-DPLS | GMR | SMR |
|---|---|---|---|---|
| 1% | validating | 3.9414 | 1.9097 | 1.5939 |
| testing | 4.1216 | 1.6776 | 1.5208 | |
| 3% | validating | 4.0450 | 2.0692 | 1.6398 |
| testing | 4.2969 | 2.3787 | 1.5986 | |
| 5% | validating | 4.1307 | 2.2223 | 1.7352 |
| testing | 4.3127 | 2.7476 | 1.6388 |
| Outliers | CPT | CPT | |||||
|---|---|---|---|---|---|---|---|
| Multi-DPLS | GMR | SMR | Multi-DPLS | GMR | SMR | ||
| 1% | 0.0283 | 0.0095 | 0.0951 | 0.0013 | 0.001 | 0.00072 | |
| 3% | 0.0148 | 0.0135 | 0.1087 | 0.0012 | 0.0012 | 0.000846 | |
| 5% | 0.0193 | 0.0164 | 0.1099 | 0.0011 | 0.001 | 0.000777 | |
| Tags | Descriptions |
|---|---|
| FR03001.PV | Flow rate of fuel NG into 03B001 |
| FR03002.PV | Flow rate of fuel off gas into 03B001 |
| PC03002.PV | Pressure of fuel off gas at 03E005’s exit |
| PC03007.PV | Pressure of furnace flue gas at 03B001’s exit |
| TI03001.PV | Temperature of fuel off gas at 03E005’s exit |
| TI03009.PV | Temperature of fuel NG at 03B002E06’s exit |
| TR03012.PV | Temperature of process gas at 03B001’s entrance |
| TI03013.PV | Temperature of furnace flue gas at 03B001’s top left |
| TI03014.PV | Temperature of furnace flue gas at 03B001’s top right |
| TR03015.PV | Temperature of mixed furnace flue gas at 03B001’s top |
| TR03016.PV | Temperature of transformed gas at 03B001’s left exit |
| TR03017.PV | Temperature of transformed gas at 03B001’s right exit |
| TR03020.PV | Temperature of transformed gas at 03B001’s exit |
| Time/Method | Multi-DPLS | GMR | SMR |
|---|---|---|---|
| CPT | 4.4908 | 0.847 | 3.002 |
| CPT | 0.0731 | 0.009 | 0.005 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Shao, W.; Song, Z. Student’s-t Mixture Regression-Based Robust Soft Sensor Development for Multimode Industrial Processes. Sensors 2018, 18, 3968. https://doi.org/10.3390/s18113968
Wang J, Shao W, Song Z. Student’s-t Mixture Regression-Based Robust Soft Sensor Development for Multimode Industrial Processes. Sensors. 2018; 18(11):3968. https://doi.org/10.3390/s18113968
Chicago/Turabian StyleWang, Jingbo, Weiming Shao, and Zhihuan Song. 2018. "Student’s-t Mixture Regression-Based Robust Soft Sensor Development for Multimode Industrial Processes" Sensors 18, no. 11: 3968. https://doi.org/10.3390/s18113968
APA StyleWang, J., Shao, W., & Song, Z. (2018). Student’s-t Mixture Regression-Based Robust Soft Sensor Development for Multimode Industrial Processes. Sensors, 18(11), 3968. https://doi.org/10.3390/s18113968