Outlier Detection in Wireless Sensor Networks Using Model Selection-Based Support Vector Data Descriptions


Abstract
:1. Introduction
2. Support Vector Data Description and Random Fourier Feature
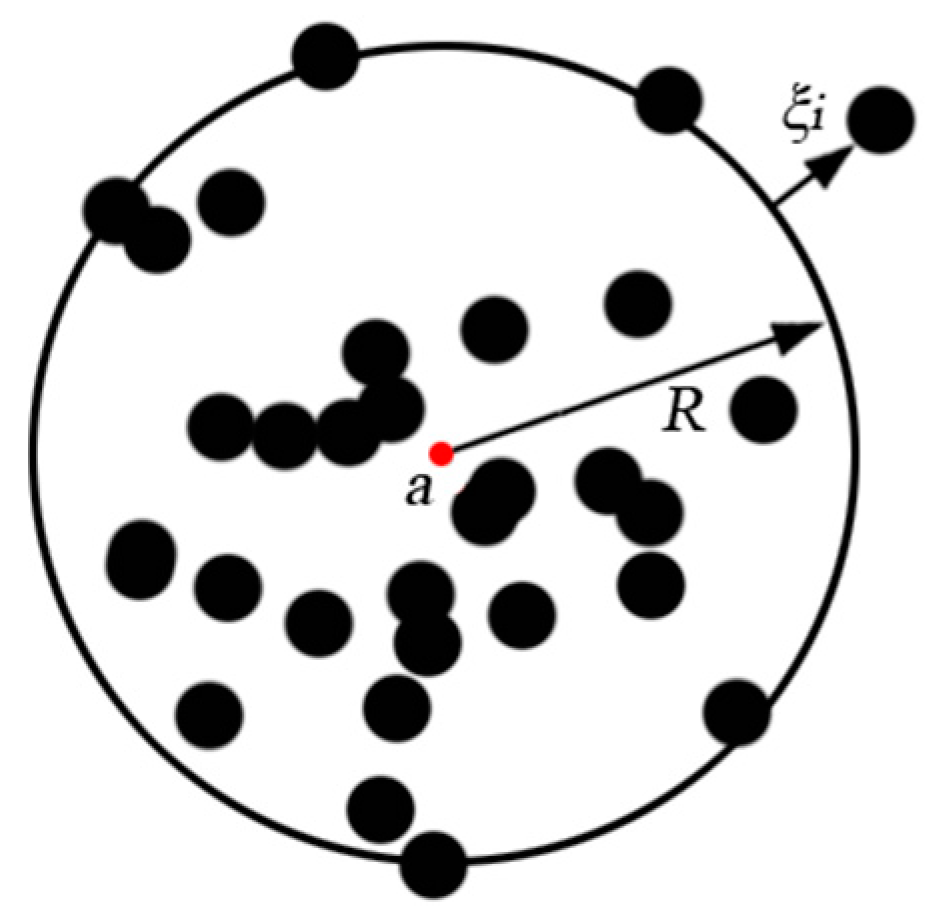
2.1. Support Vector Data Description
2.2 Random Fourier Feature
3. Outlier Detection Algorithm Using Model Selection Based Support Vector Data Description
3.1. Toeplitz Random Fourier Feature Mapping in Support Vector Data Description (TRFF)
- Step 1:
- Initialize the radial basis function parameter δ and the feature dimension D.
- Step 2:
- Draw samples T(1) from N (0, ID/δ2);
- Step 3:
- Use the Toeplitz transformation to obtain the D-dimensional matrix TD;
- Step 4:
- Compute the approximate radial basis function KM_RFF by Equation(11);
- Step 5:
- Solve the QP problem using the SMO algorithm for KM_RFF;
- Step 6:
- Construct the decision function of the TRFF algorithm.
3.2. Model Selection
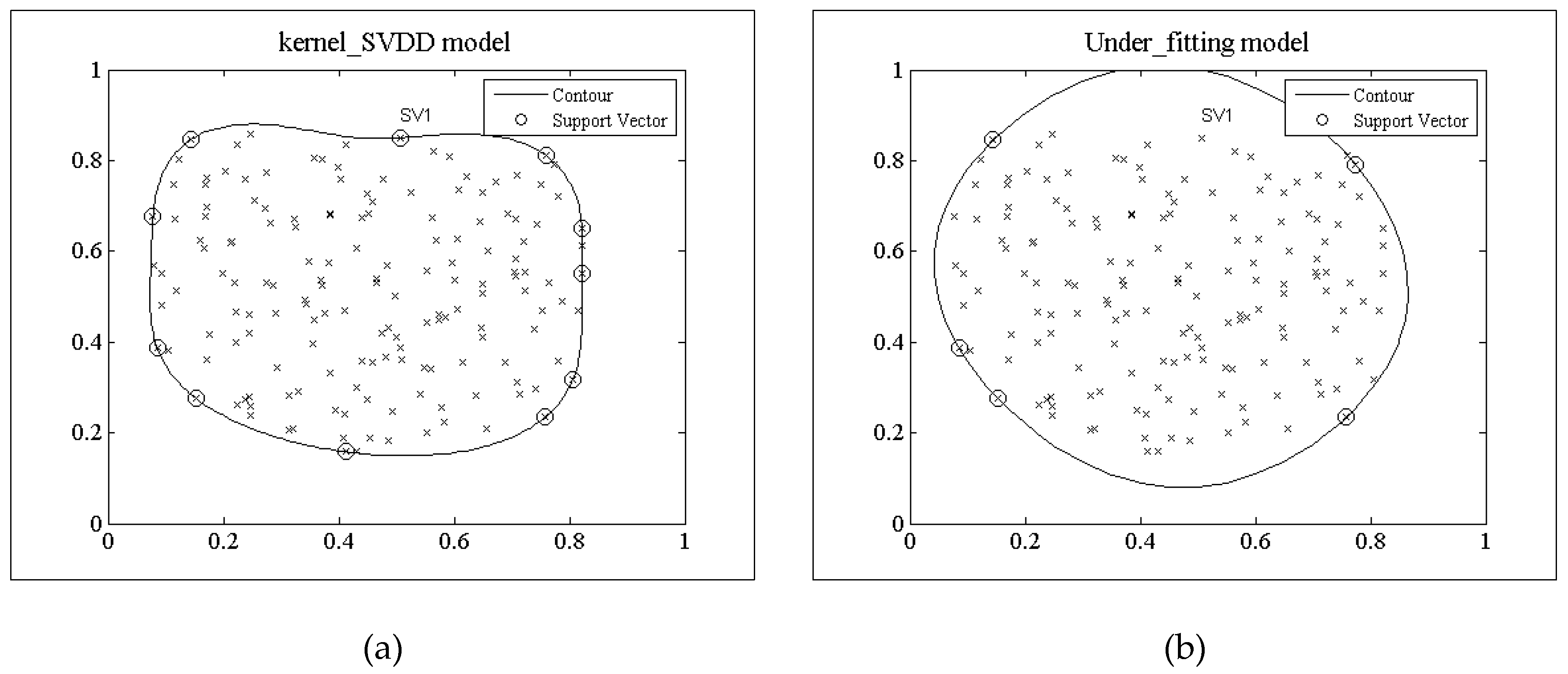
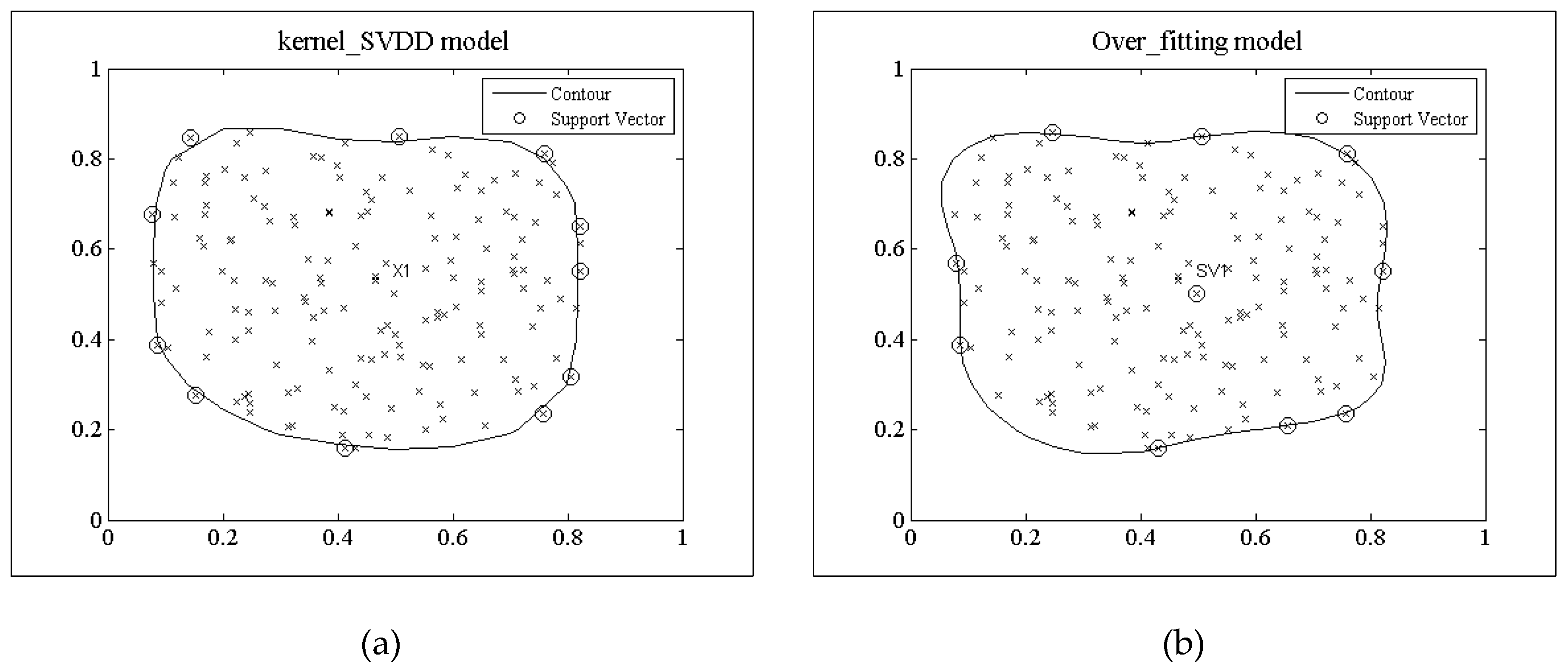
3.2.1 Under-Fitting Error
3.2.2 Over-Fitting Error
| Algorithm 1 Model selection for Kernel_SVDD |
| Input: Training dataset Train = {x1, x2, …, xn} |
| Support vector SVS of kernel_SVDD |
| Process: |
| 1: while (1) do |
| 2: Sample T(1)~N(0, ID/δ2); |
| 3: Apply the Toeplitz transformation of T(1) to form a D-dimensional feature matrix TD; |
| 4: Train the training set Train to obtain decision model TRFF_f using TRFF algorithm; |
| 5: Calculate the over-fitting error: error_over |
| 6: if error_over = 0 |
| 7: Calculate the under-fitting error error_under; |
| 8: if error_under < error_underτ |
| 9: break; |
| 10: else |
| 11: continue; |
| 12: end if; |
| 13: else |
| 14: continue; |
| 15: end if; |
| 16: end while; |
| Output: Random feature matrix of optimal model TD |
| Algorithm 2 TSVDD algorithm |
| Input: Training dataset Train |
| Testing dataset: Test = {x1, x2, …, xn} |
| Process: |
| 1: Derive the decision model f of SVDD use training dataset; |
| 2: While (Test ≠ φ) do |
| 3: if f(xi) > 0, (i = 1, 2, …, n) |
| 4: xi is marked as an outlier; |
| 5: else |
| 6: xi is marked as an adequate sample; |
| 7: end if; |
| 8: end while; |
| Output: the outlier set |
4. Experimental Results
4.1. Data Sets
4.1.1. IBRL Dataset
4.1.2. SensorScope Dataset
4.2. Performance Metrics
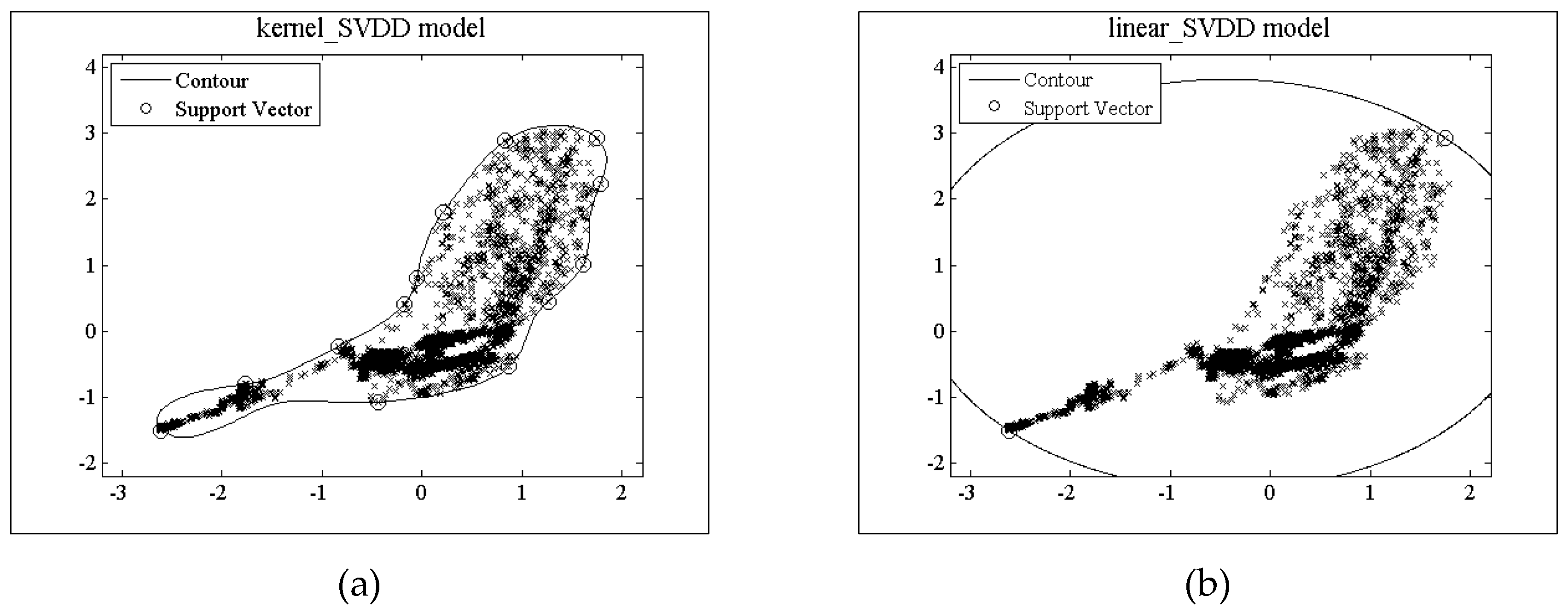
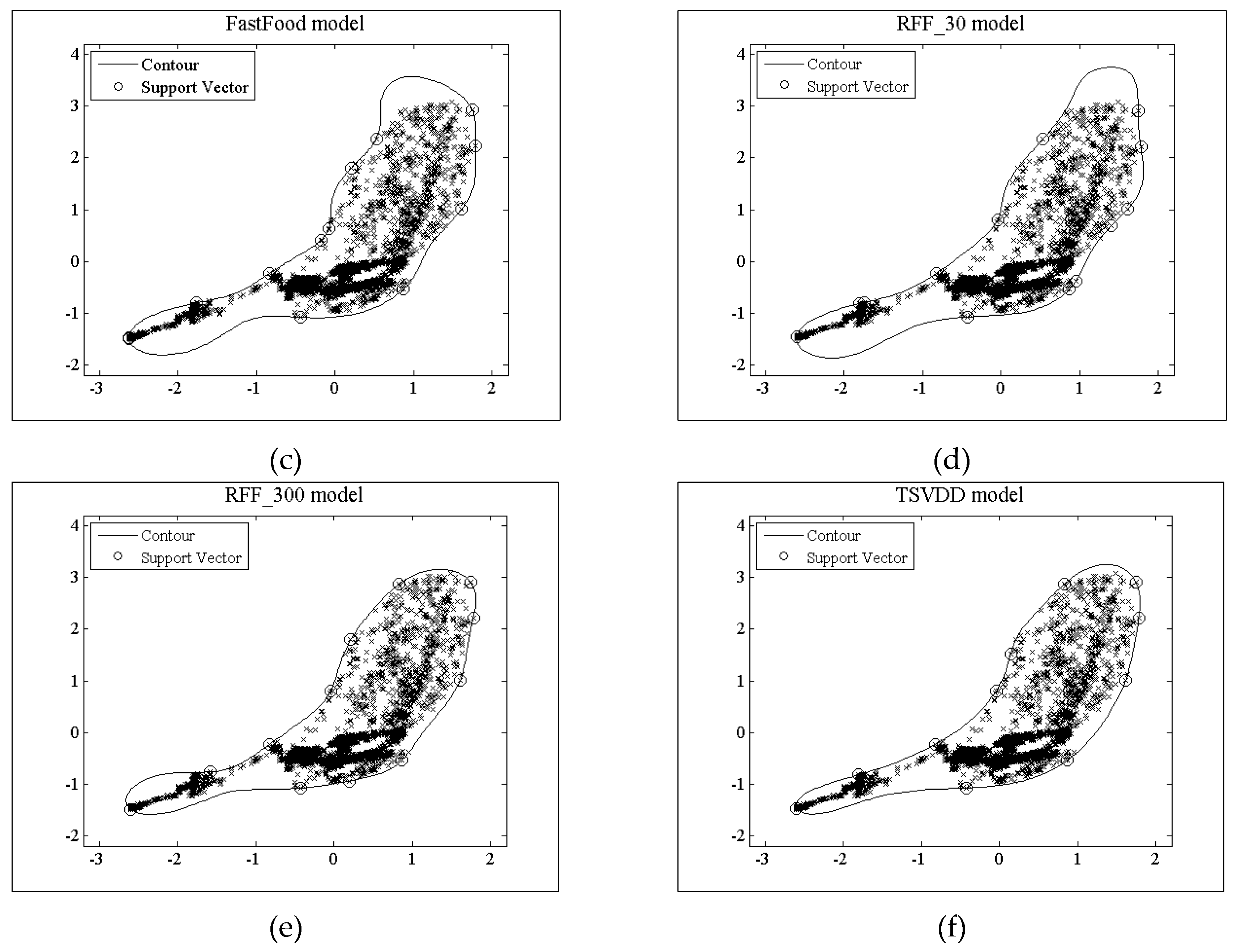
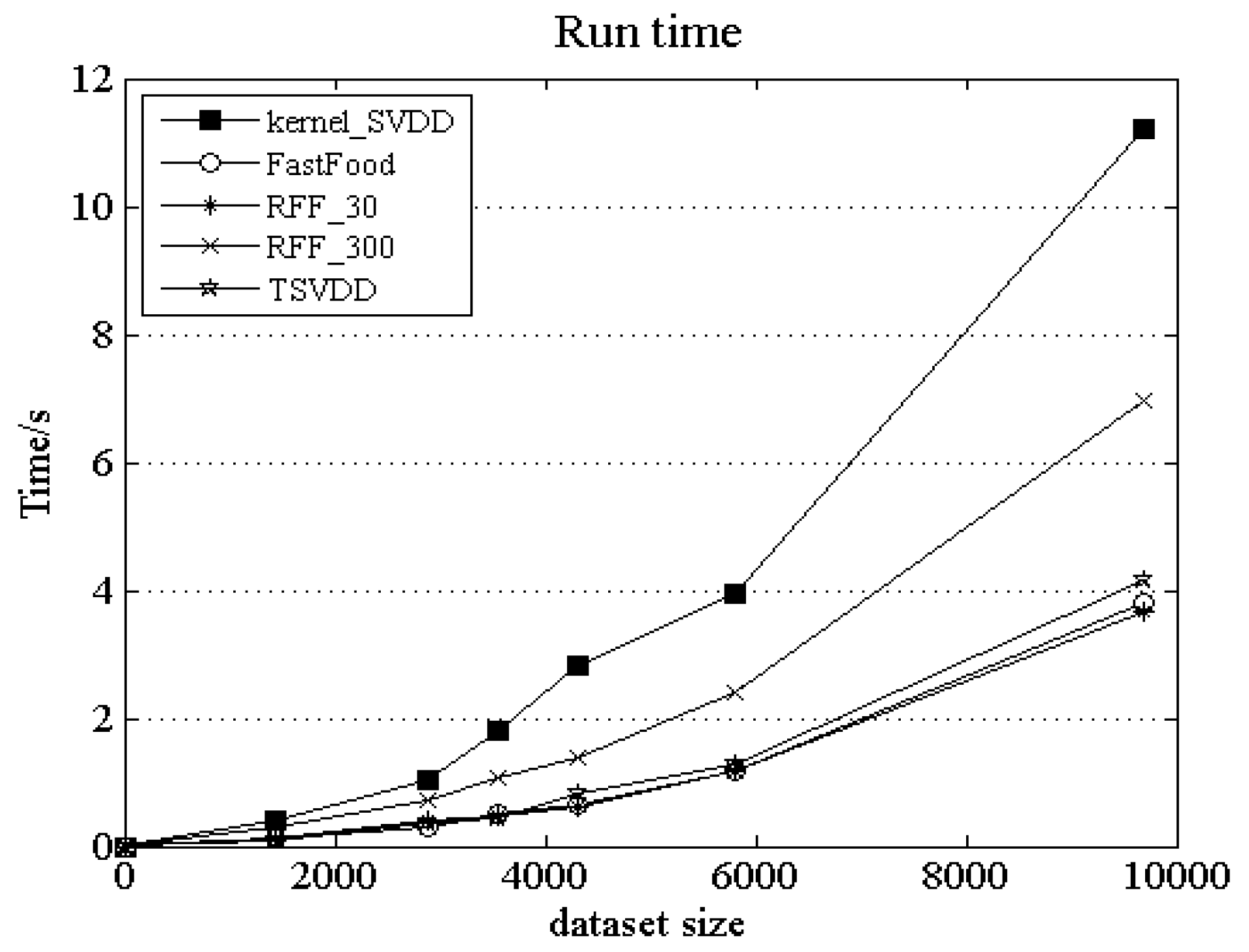
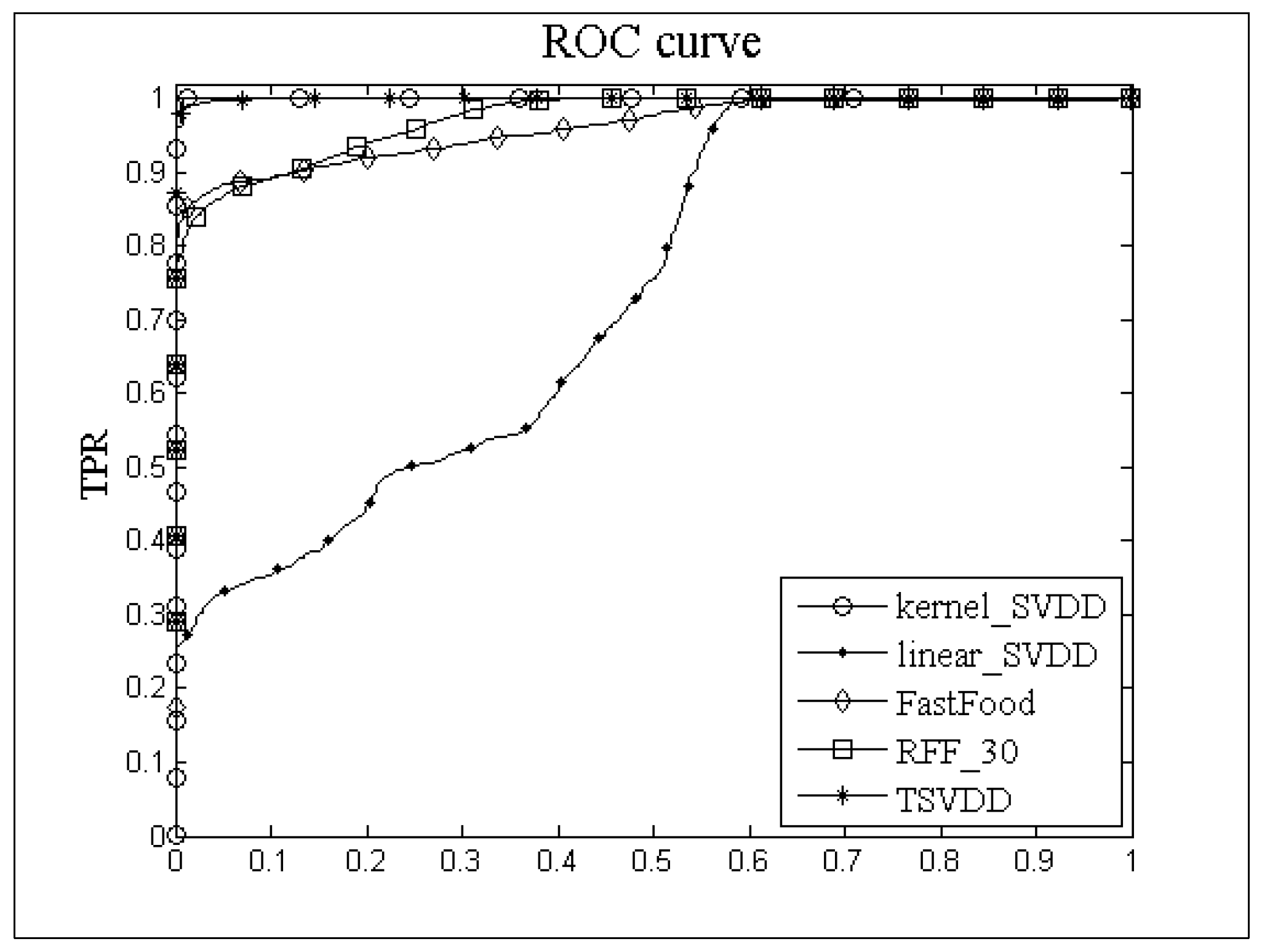
4.3 Performance Comparison Among Different Outlier Detection Algorithms
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tomić, I.; Mccann, J.A. A Survey of Potential Security Issues in Existing Wireless Sensor Network Protocols. IEEE Int. Things J. 2017, 4, 1910–1923. [Google Scholar] [CrossRef] [Green Version]
- Rawat, P.; Singh, K.D.; Chaouchi, H.; Bonnin, J.M. Wireless sensor networks: a survey on recent developments and potential synergies. J. Supercomput. 2014, 68, 1–48. [Google Scholar] [CrossRef]
- Zhang, Z.; Mehmood, A.; Shu, L.; Huo, Z.; Zhang, Y.; Mukherjee, M. A survey on Fault Diagnosis in Wireless Sensor Networks. IEEE Access 2016, 6, 11349–11364. [Google Scholar] [CrossRef]
- Qiu, T.; Qiao, R.; Wu, D.O. EABS: An Event-Aware Backpressure Scheduling Scheme for Emergency Internet of Things. IEEE Trans. Mob. Comput. 2018, 17, 72–84. [Google Scholar] [CrossRef]
- Qiu, T.; Chen, N.; Li, K.; Atiquzzaman, M.; Zhao, W. How can heterogeneous Internet of Things build our future: A survey. IEEE Commun. Surv. Tutorials 2018, 20, 2011–2027. [Google Scholar] [CrossRef]
- Qiu, T.; Zheng, K.; Song, H.; Han, M.; Kantarci, B. A local-optimization emergency scheduling scheme with self-recovery for smart grid. IEEE Trans. Ind. Inf. 2017, 13, 3195–3205. [Google Scholar] [CrossRef]
- Dhurgadevi, M.; Devi, P.M. An Analysis of Energy Efficiency Improvement through Wireless Energy Transfer in Wireless Sensor Network. Wirel. Pers. Commun. 2018, 98, 3377–3391. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Zhang, Y.; Meratnia, N.; Havinga, P. Outlier Detection Techniques for Wireless Sensor Networks: A Survey. IEEE Commun. Surv. Tutor. 2010, 12, 159–170. [Google Scholar] [CrossRef] [Green Version]
- Tax, D.M.J.; Duin, R.P.W. Support vector domain description. Pattern Recognit. Lett. 1999, 11, 1191–1199. [Google Scholar] [CrossRef]
- Tax, D.M.J.; Duin, R.P.W. Support Vector Data Description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef] [Green Version]
- Platt, J.C. Fast Training of Support Vector Machines Using Sequential Minimal Optimization; MIT Press: Cambridge, MA, USA, 1999; pp. 185–208. [Google Scholar]
- Fan, R.E.; Chen, P.H.; Lin, C.J. Working Set Selection Using Second Order Information for Training Support Vector Machines. J. Mach. Learn. Res. 2005, 6, 1889–1918. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Liu, Y.H.; Liu, Y.C.; Chen, Y.J. Fast support vector data descriptions for novelty detection. IEEE Trans. Neural Netw. 2010, 21, 1296–1313. [Google Scholar] [PubMed]
- Feng, Z.; Fu, J.; Du, D.; Li, F.; Sun, S. A new approach of anomaly detection in WSNs using support vector data description. Int. J. Distrib. Sens. Netw. 2017, 13, 1120–1123. [Google Scholar] [CrossRef]
- Rahimi, A.; Recht, B. Random features for large-scale kernel machines. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1177–1184. [Google Scholar]
- Rahimi, A.; Recht, B. Weighted sums of random kitchen sinks: replacing minimization with randomization in learning. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008; pp. 1313–1320. [Google Scholar]
- Sutherland, D.J.; Schneider, J. On the error of random Fourier features. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Amsterdam, The Netherlands, 12–16 July 2015; pp. 862–871. [Google Scholar]
- Aman, S.; John, C.D. Learning kernels with random features. In Proceedings of the Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Vedaldi, A.; Zisserman, A. Efficient Additive Kernels via Explicit Feature Maps. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 480–492. [Google Scholar] [CrossRef] [PubMed]
- Rudin, W. Fourier Analysis on Groups; Wiley-Interscience: New York, NY, USA, 1994. [Google Scholar]
- Le, Q.V.; Sarlos, T.; Smola, A.J. Fastfood: Approximate Kernel Expansions in Loglinear Time. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 244–525. [Google Scholar]
- Ingelrest, F.; Barrenetxea, G.; Schaefer, G.; Vetterli, M.; Couach, O.; Parlange, M. SensorScope: Application-Specific Sensor Network for Environmental Monitoring. ACM Trans. Sens. Netw. 2010, 6, 1–32. [Google Scholar] [CrossRef]









{kind=link}
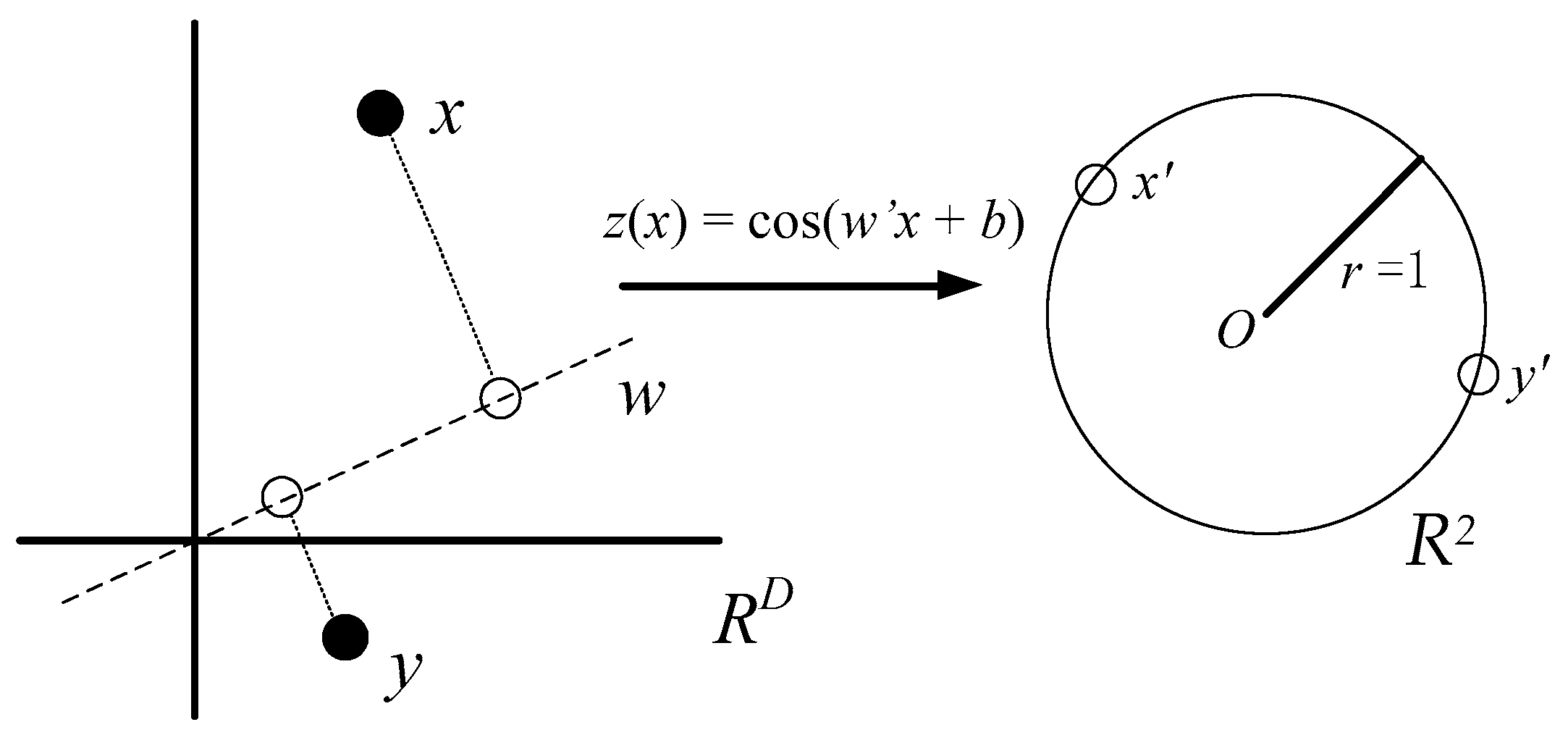{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Source | Data Type | Dataset Number | Size of Training Dataset | Size of Testing Dataset |
|---|---|---|---|---|
| SensorScope | Temperature & humidity | SS_12-1 | 717 | 1473 |
| SS_12-2 | 1440 | 2877 | ||
| SS-12-3 | 2157 | 4303 | ||
| IBRL | ambient temperature & surface temperature | IBRL_51-1 | 1822 | 3562 |
| IBRL_51-2 | 3562 | 5816 | ||
| IBRL_51-3 | 5068 | 9694 |
| True category | Decision category | |
|---|---|---|
| Outlier | Normal | |
| Outlier | TP | FN |
| Normal | FP | TN |
| (a) TPR comparison of SS_12 dataset. | |||||||||
| Data Set | Kernel_SVDD (%) | FastFood | RFF_30 | RFF_300 | TSVDD | ||||
| Avg (%) | std | Avg (%) | std | Avg (%) | std | Avg (%) | std | ||
| SS_12-1 | 99.79 | 99.77 | 0.0022 | 99.78 | 0.0033 | 99.71 | 0.0022 | 99.82 | 0.0013 |
| SS_12-2 | 99.21 | 97.84 | 0.0144 | 98.29 | 0.0129 | 98.68 | 0.0082 | 98.55 | 0.0112 |
| SS_12-3 | 96.82 | 96.87 | 0.0191 | 96.92 | 0.0153 | 97.32 | 0.0064 | 96.58 | 0.0086 |
| (b) FPR comparison of SS_12 dataset | |||||||||
| Data Set | Kernel_SVDD (%) | FastFood | RFF_30 | RFF_300 | TSVDD | ||||
| Avg (%) | std | Avg (%) | std | Avg (%) | std | Avg (%) | std | ||
| SS_12--1 | 10.81 | 28.22 | 0.1427 | 27.30 | 0.1428 | 14.32 | 0.0361 | 16.76 | 0.0444 |
| SS_12-2 | 0.00 | 1.62 | 0.0139 | 1.21 | 0.0122 | 0.12 | 0.0016 | 0.72 | 0.0031 |
| SS_12-3 | 0.75 | 8.80 | 0.0868 | 7.26 | 0.0879 | 1.28 | 0.0104 | 1.46 | 0.0108 |
| (c) TPR comparison of IBRL_51 dataset | |||||||||
| Data Set | Kernel_SVDD (%) | FastFood | RFF_30 | RFF_300 | TSVDD | ||||
| Avg (%) | Std | Avg (%) | Std | Avg (%) | Std | Avg (%) | Std | ||
| IBRL_51-1 | 99.76 | 97.58 | 0.0364 | 97.42 | 0.0323 | 99.14 | 0.0116 | 99.28 | 0.0066 |
| IBRL_51-2 | 99.43 | 98.15 | 0.0152 | 97.92 | 0.0152 | 98.19 | 0.0115 | 97.96 | 0.0019 |
| IBRL_51-3 | 99.73 | 99.26 | 0.0092 | 99.49 | 0.0062 | 99.49 | 0.0044 | 99.37 | 0.0090 |
| (d) FPR comparison of IBRL_51 dataset | |||||||||
| Data Set | Kernel_SVDD (%) | FastFood | RFF_30 | RFF_300 | TSVDD | ||||
| Avg (%) | Std | Avg (%) | Std | Avg (%) | Std | Avg (%) | Std | ||
| IBRL_51-1 | 0.55 | 3.61 | 0.0448 | 2.61 | 0.0319 | 1.89 | 0.0147 | 1.88 | 0.0236 |
| IBRL_51-2 | 0.06 | 2.72 | 0.0224 | 2.27 | 0.0213 | 0.68 | 0.0085 | 0.41 | 0.0022 |
| IBRL_51-3 | 0.25 | 4.78 | 0.0352 | 5.87 | 0.0411 | 1.28 | 0.0156 | 1.14 | 0.0046 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huan, Z.; Wei, C.; Li, G.-H. Outlier Detection in Wireless Sensor Networks Using Model Selection-Based Support Vector Data Descriptions. Sensors 2018, 18, 4328. https://doi.org/10.3390/s18124328
Huan Z, Wei C, Li G-H. Outlier Detection in Wireless Sensor Networks Using Model Selection-Based Support Vector Data Descriptions. Sensors. 2018; 18(12):4328. https://doi.org/10.3390/s18124328
Chicago/Turabian StyleHuan, Zhan, Chang Wei, and Guang-Hui Li. 2018. "Outlier Detection in Wireless Sensor Networks Using Model Selection-Based Support Vector Data Descriptions" Sensors 18, no. 12: 4328. https://doi.org/10.3390/s18124328
APA StyleHuan, Z., Wei, C., & Li, G. -H. (2018). Outlier Detection in Wireless Sensor Networks Using Model Selection-Based Support Vector Data Descriptions. Sensors, 18(12), 4328. https://doi.org/10.3390/s18124328