Components of Artificial Neural Networks Realized in CMOS Technology to be Used in Intelligent Sensors in Wireless Sensor Networks


Abstract
:1. Introduction
1.1. State-of-the-Art Study
1.1.1. Wireless Sensors
- front-end sensor used to collect analog data from the environment;
- anti aliasing filter and filters used to remove the noise from the signal;
- ADC used to convert measured analog signal into its digital counterpart; and
- RF communication block.
1.1.2. ANNs Realized at the Transistor Level
1.2. Technical Background
- Initialize the neuron weights that aims at distribution of the neurons over the overall input data space.
- Provide a new learning pattern X to the inputs of all neurons in the ANN (a data normalization may be required before following stages).
- Calculate distances (, , , , …, ) between the pattern X and the weight vectors W of all neurons in the ANN (N is the total number of neurons in the NN). The distance may be computed according to one of typical distance measures, for example the Manhattan (L1 norm) or the Euclidean (L2 norm) ones [3].
- Determine the neuron that is located in the closest proximity to a given pattern X. This neuron becomes the winner. Mathematically, the min(, , , , …, ) operation is used at this stage.
- Determine the neighborhood of the winning neuron (explained in more detail below).
- Adapt the weights of the winning neuron and of its neighbors (in the WTM and the NG algorithms).
2. Materials and Methods
2.1. Materials
2.1.1. Chip Design—Cadence Environment
2.1.2. Measurement Setup
2.2. Methods—Solutions for the Adaptation Mechanism and Clock Generator
2.3. Adaptation Mechanism
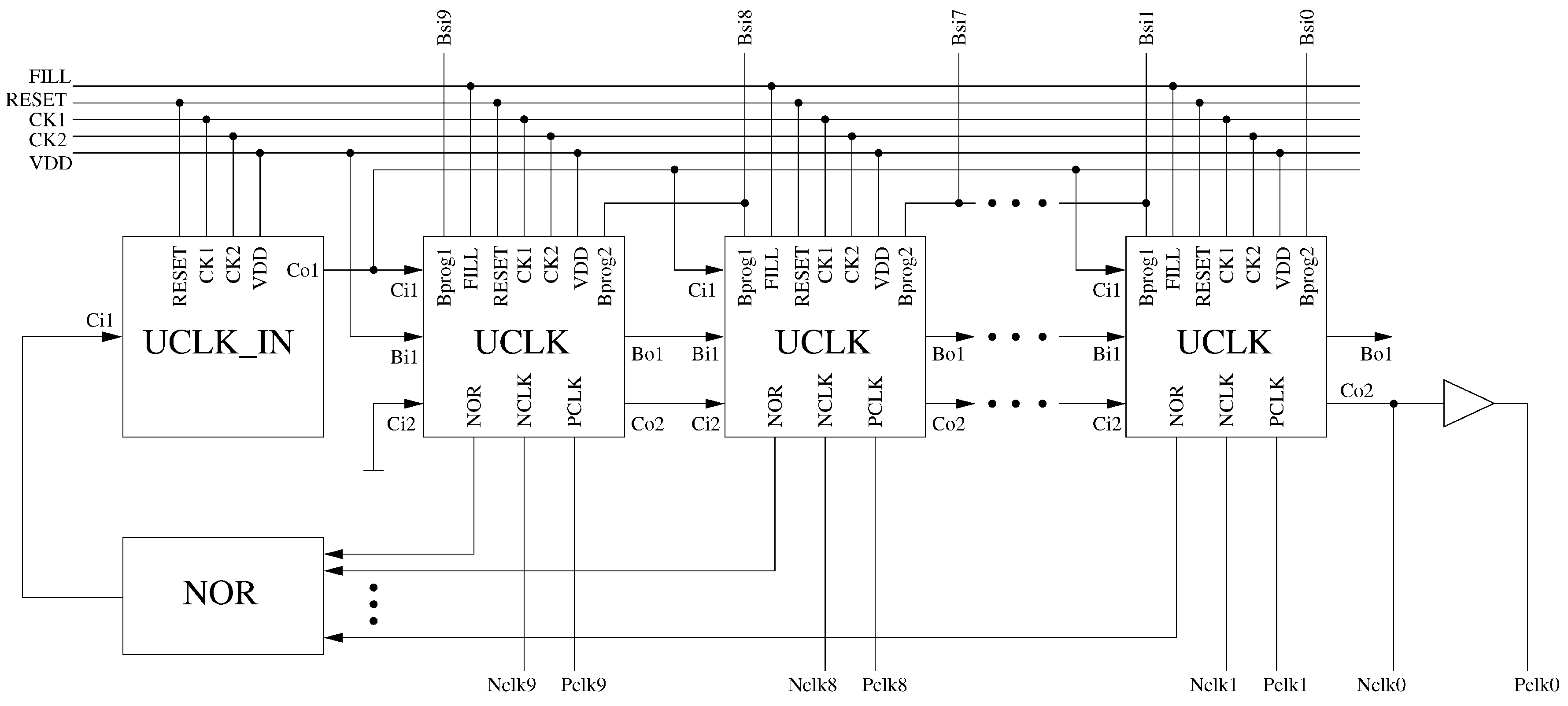
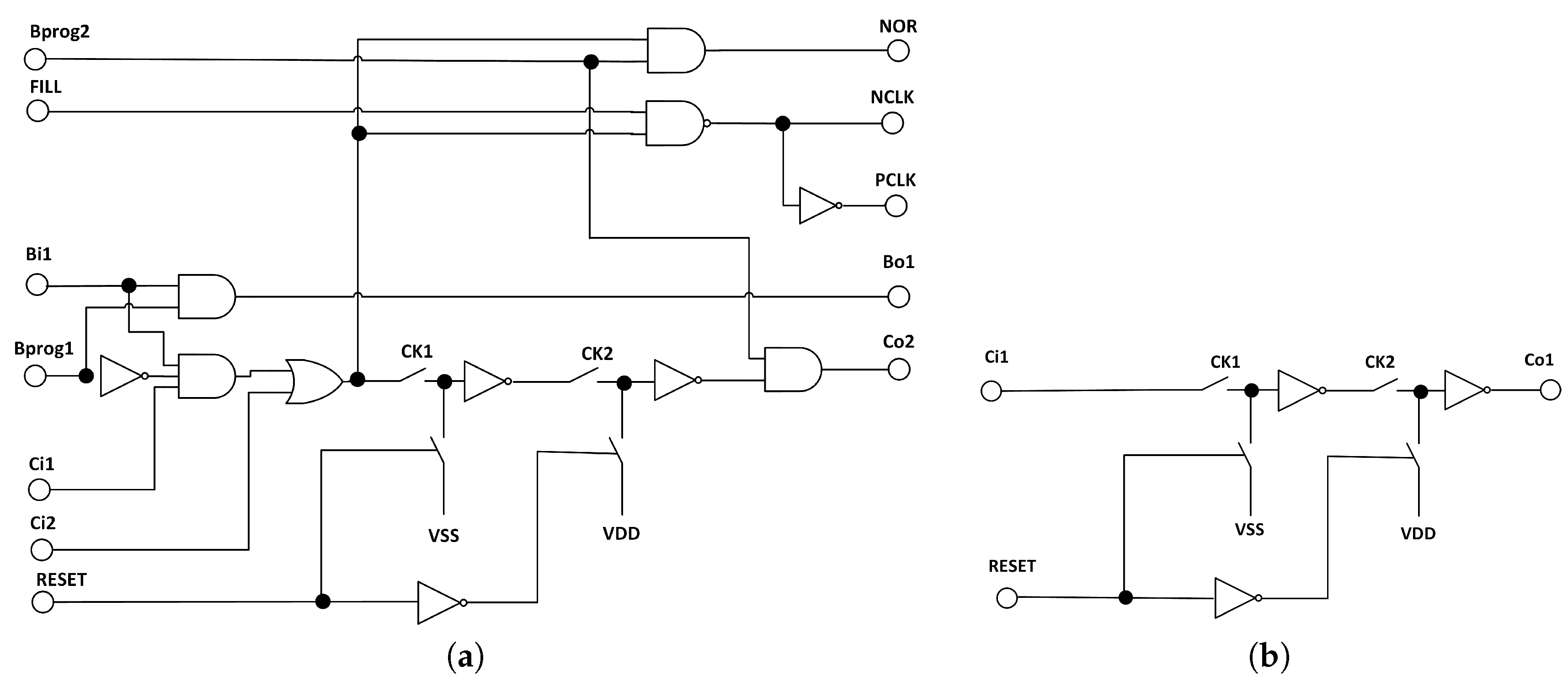
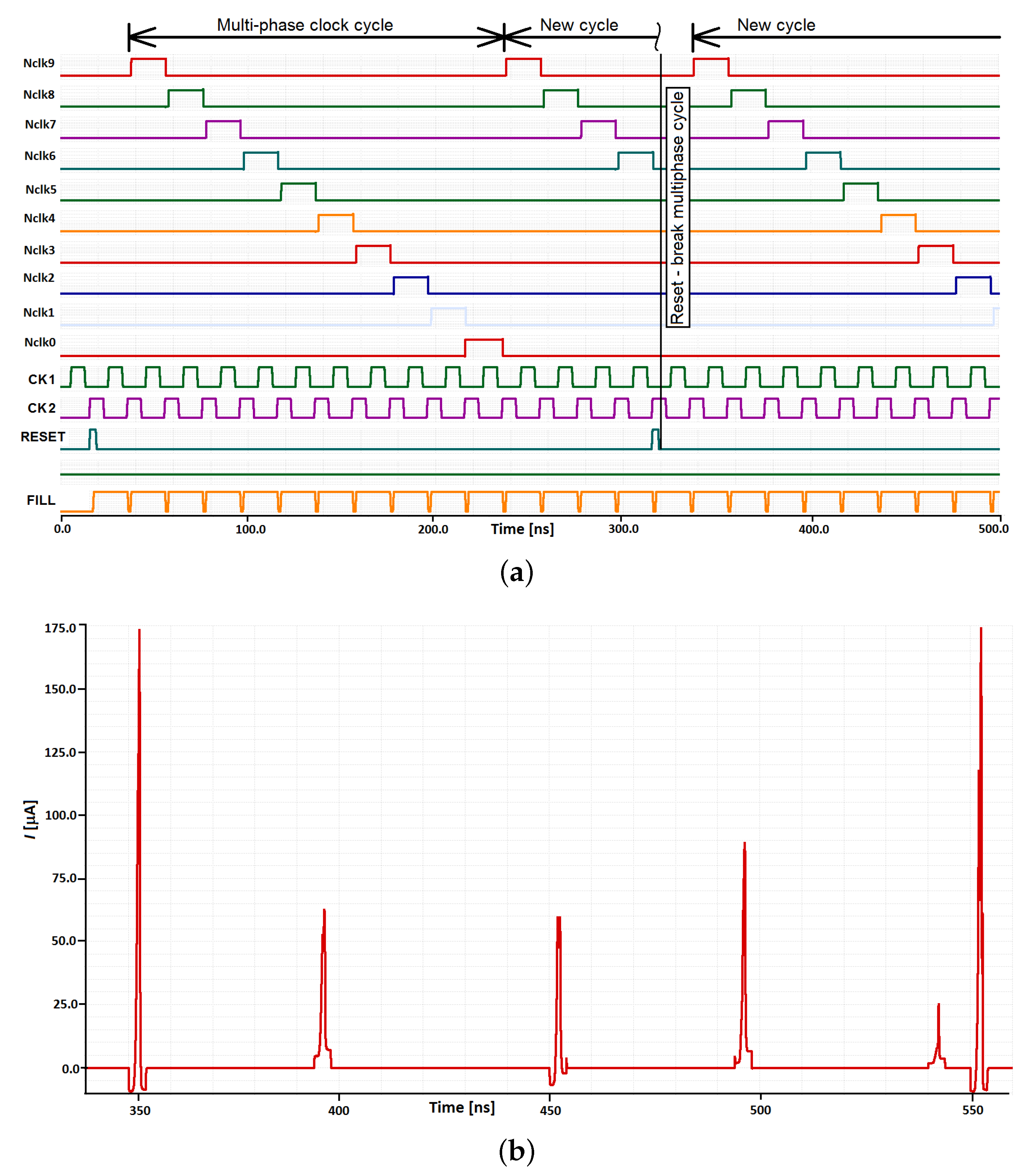
Programmable Multi-Phase Clock Generator
3. Results
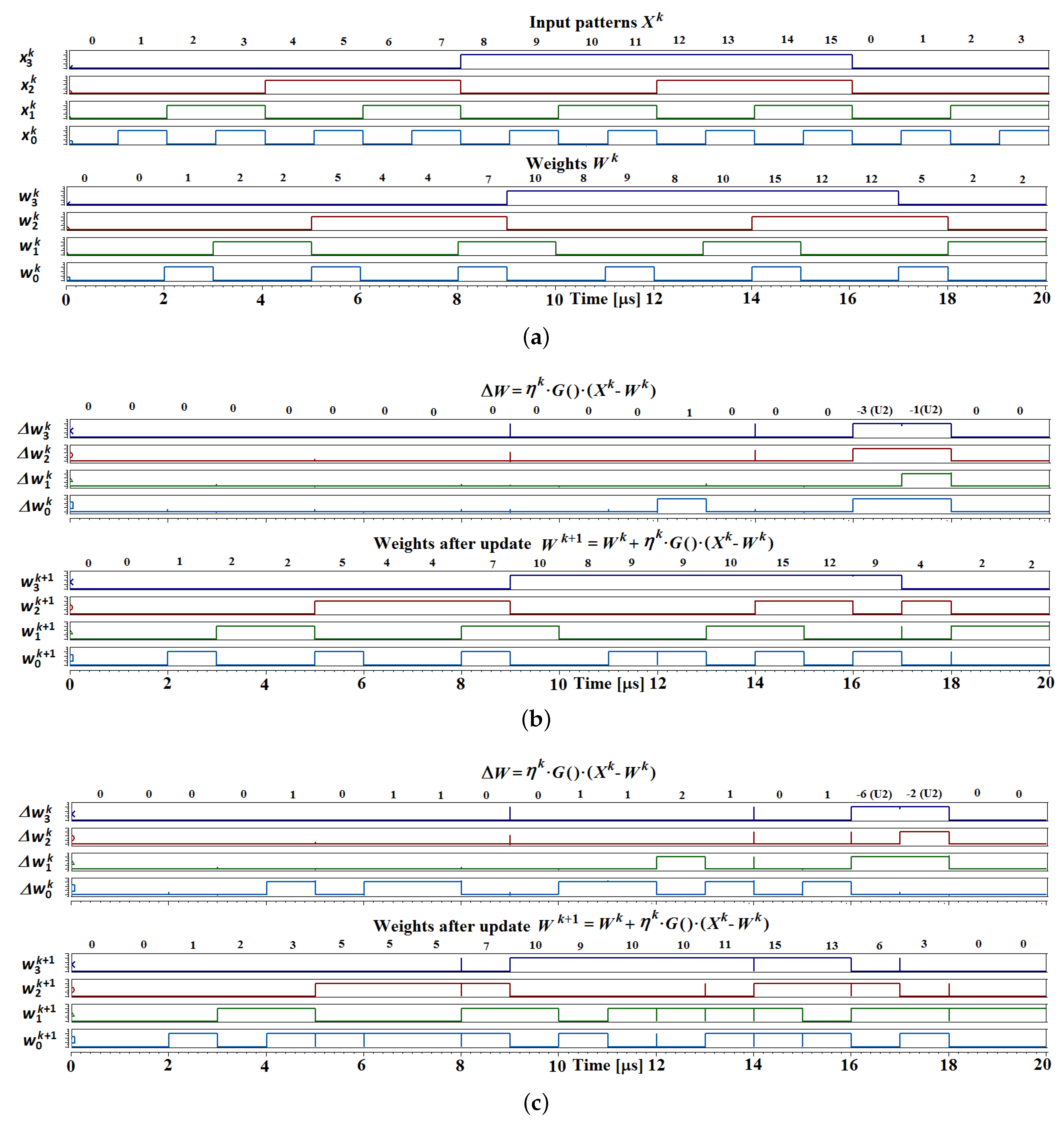
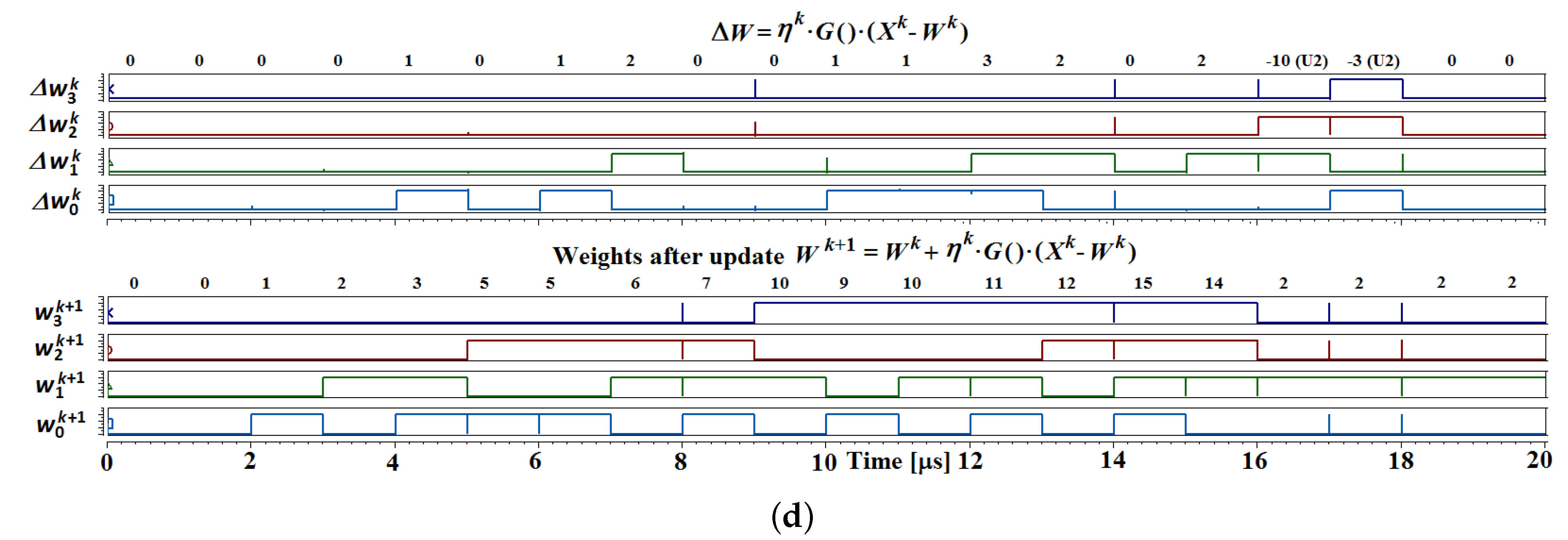
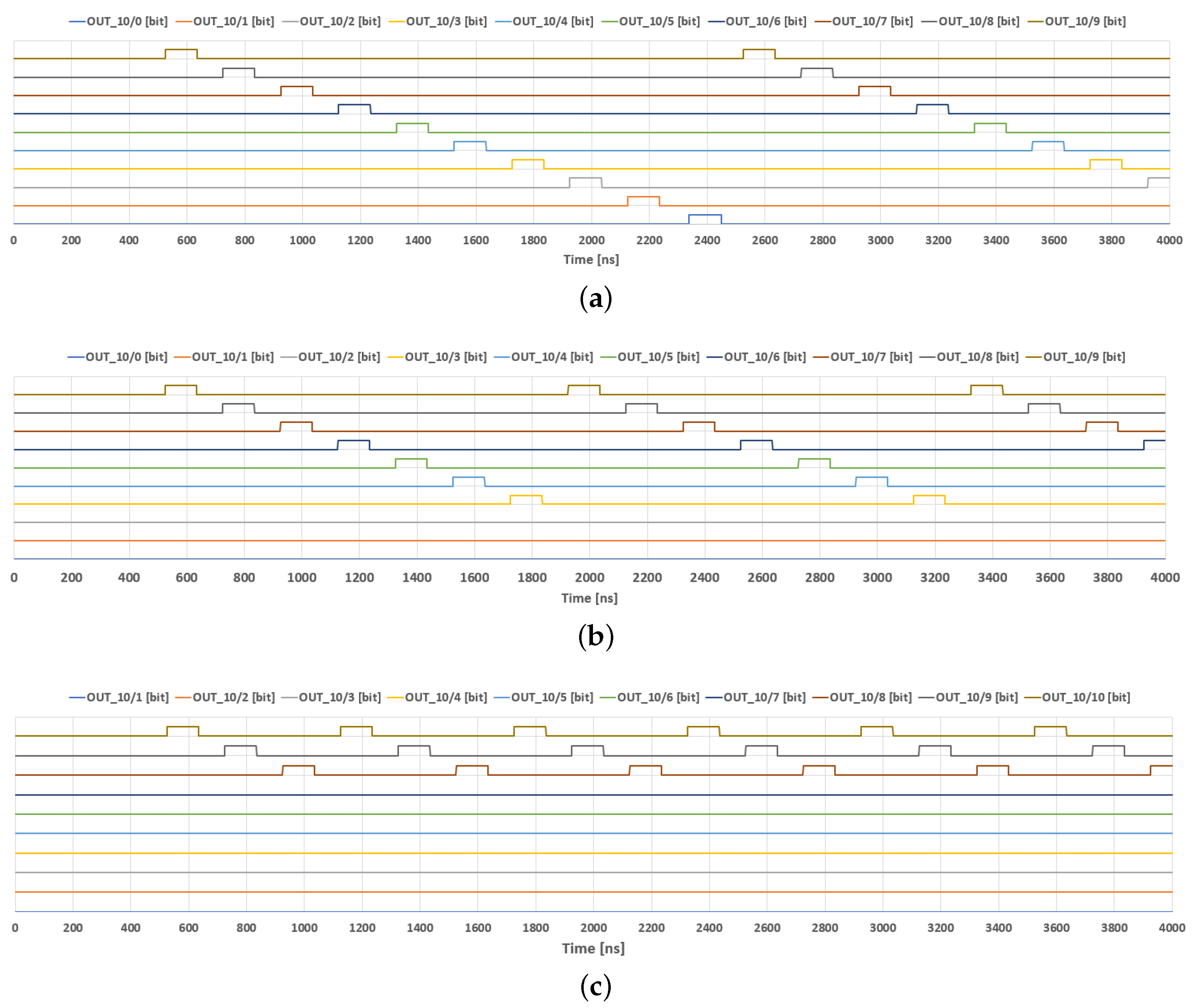
3.1. Adaptation Mechanism
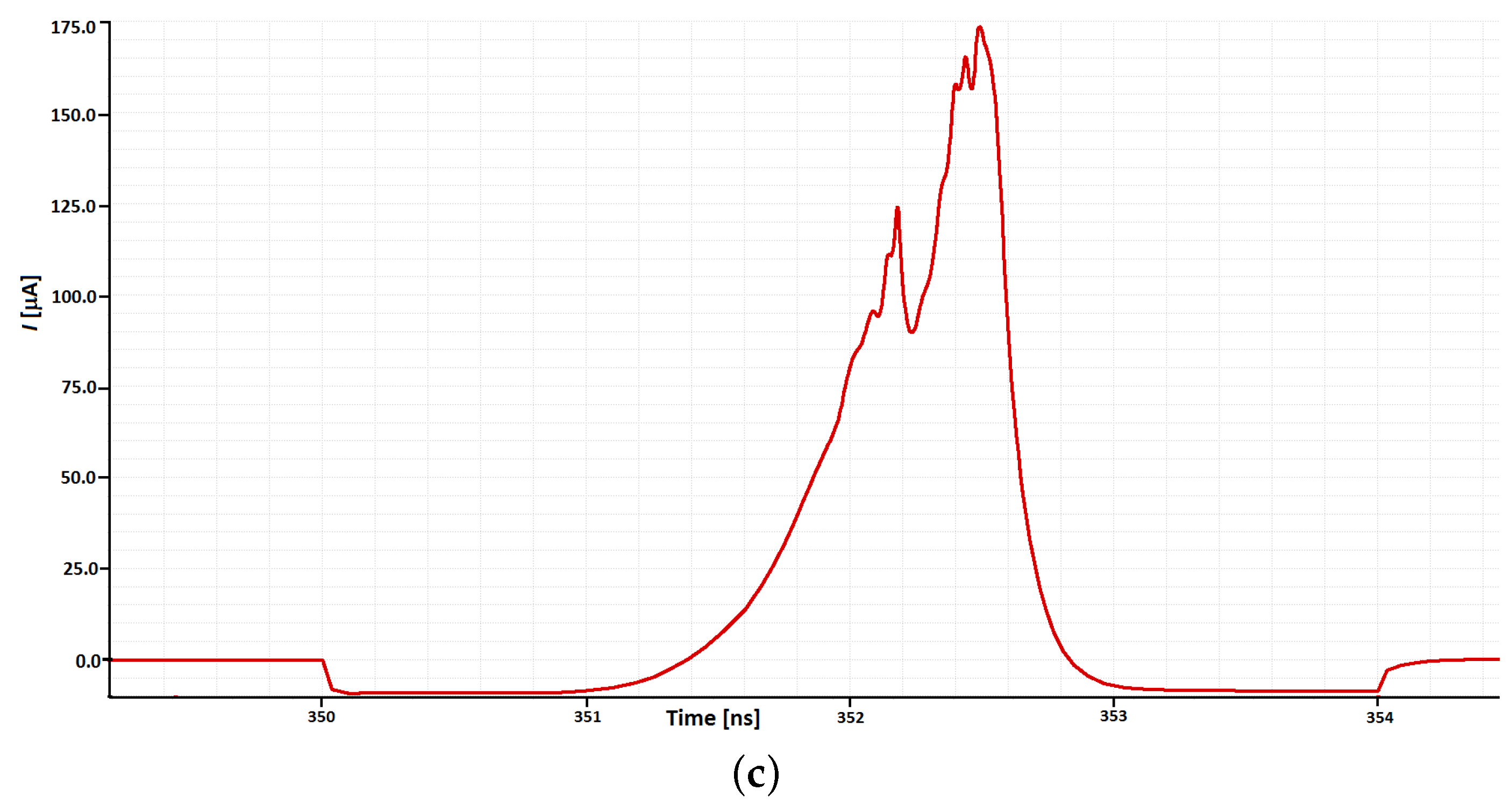
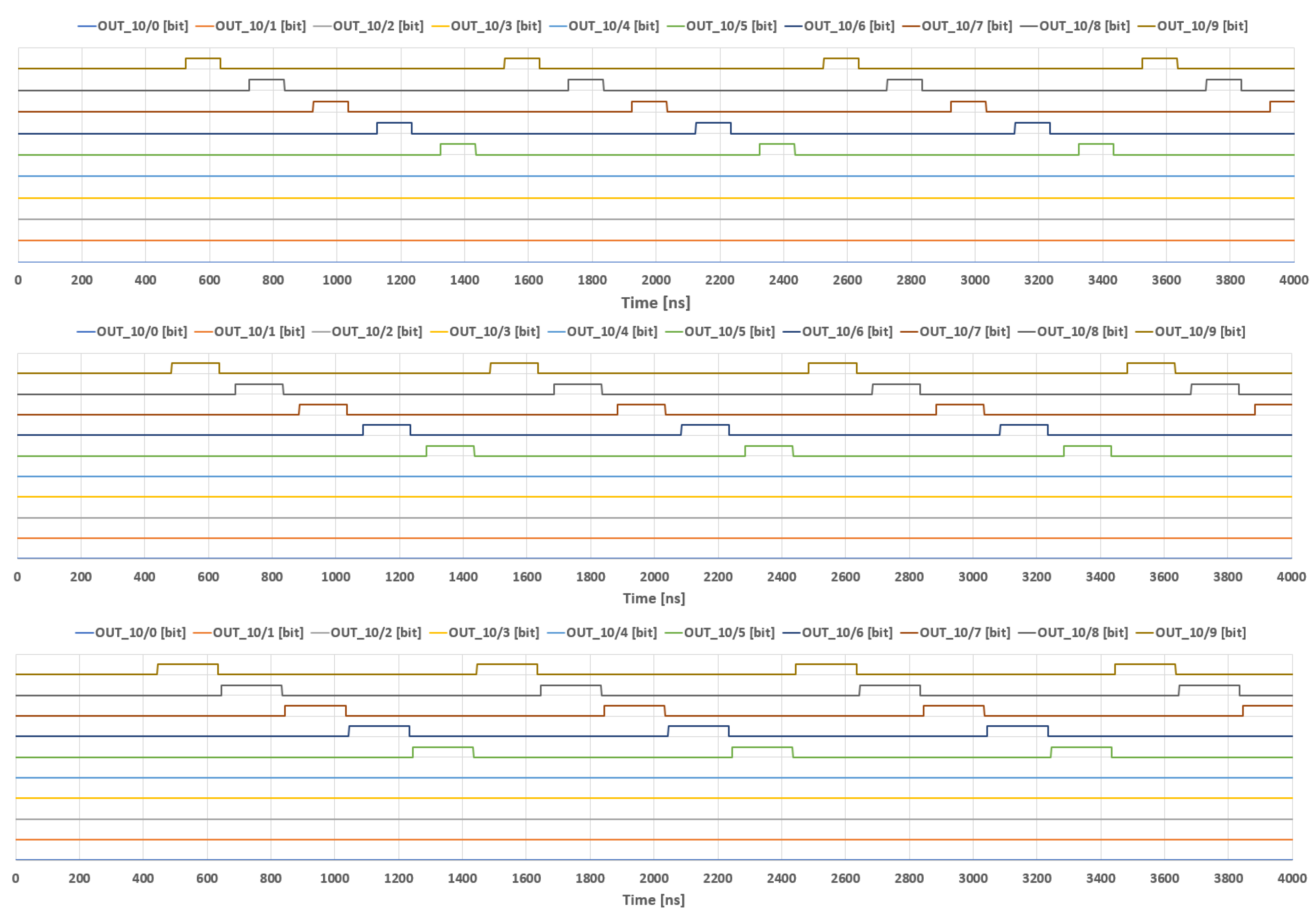
3.2. Clock Generator
4. Discussion
4.1. Clock Generator
4.2. Adaptation Mechanism
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CMOS | Complementary Metal Oxide Semiconductor |
| WSN | Wireless Sensor Network |
| ANN | Artificial Neural Network |
| WTA | Winner Takes All |
| WTM | Winner Takes Most |
| NG | Neural Gas |
| NF | Neighborhood Function |
| FPGA | Field Programmable Gate Array |
| ADC | Analog to Digital Converter |
| SAR ADC | Successive Approximation Analog to Digital Converter |
| RF | Radio Frequency |
| CPLD | Complex Programmable Logic Device |
| PCB | Printed Circuit Board |
| MBFA | Multi Bit Full Adder |
| MBFS | Multi Bit Full Subtractor |
References
- Yan, J.; Zhou, M.; Ding, Z. Recent Advances in Energy-Efficient Routing Protocols for Wireless Sensor Networks: A Review. IEEE Access 2016, 4, 5673–5686. [Google Scholar] [CrossRef]
- Srbinovska, M.; Dimcev, V.; Gavrovski, C. Energy consumption estimation of wireless sensor networks in greenhouse crop production. In Proceedings of the IEEE EUROCON 2017–17th International Conference on Smart Technologies, Ohrid, Macedonia, 6–8 July 2017. [Google Scholar]
- Długosz, R.; Kolasa, M.; Pedrycz, W.; Szulc, M. Parallel programmable asynchronous neighborhood mechanism for Kohonen SOM implemented in CMOS technology. IEEE Trans. Neural Netw. 2011, 22, 2091–2104. [Google Scholar] [CrossRef] [PubMed]
- Długosz, R.; Talaśka, T.; Pedrycz, W.; Wojtyna, R. Realization of the conscience mechanism in CMOS implementation of winner-takes-all self-organizing neural networks. IEEE Trans. Neural Netw. 2010, 21, 961–971. [Google Scholar] [CrossRef] [PubMed]
- Morrison, D.; Ablitt, T.; Redouté, J.M. Miniaturized Low-Power Wireless Sensor Interface. IEEE Sens. J. 2015, 15, 4731–4732. [Google Scholar] [CrossRef]
- Chen, S.-L.; Lee, H.-Y.; Chen, C.-A.; Huang, H.-Y.; Luo, C.-H.; Morrison, D.; Ablitt, T.; Redouté, J.M. Wireless Body Sensor Network With Adaptive Low-Power Design for Biometrics and Healthcare Applications. IEEE Syst. J. 2009, 3, 398–409. [Google Scholar] [CrossRef] [Green Version]
- Gao, D.; Fu, Y. A fully integrated SoC for large scale wireless sensor networks in 0.18 μm CMOS. In Proceedings of the IET International Conference on Wireless Sensor Network (IET-WSN 2010), Beijing, China, 15–17 November 2010; pp. 90–94. [Google Scholar]
- Somov, A.; Karpov, E.F.; Karpova, E.; Suchkov, A.; Mironov, S.; Karelin, A.; Baranov, A.; Spirjakin, D. Compact Low Power Wireless Gas Sensor Node With Thermo Compensation for Ubiquitous Deployment. IEEE Trans. Ind. Inform. 2015, 11, 90–94. [Google Scholar] [CrossRef]
- Banach, M.; Wasilewska, A.; Długosz, R.; Pauk, J. Novel techniques for a wireless motion capture system for the monitoring and rehabilitation of disabled persons for application in smart buildings. J. Technol. Health Care 2018, 26, 671–677. [Google Scholar] [CrossRef] [PubMed]
- Banach, M.; Długosz, R. Real-time Locating Systems for Smart City and Intelligent Transportation Applications. In Proceedings of the IEEE 30th International Conference on Microelectronics (Miel 2017), Nis, Serbia, 9–11 October 2017; pp. 231–234. [Google Scholar]
- Macq, D.; Verleysen, M.; Jespers, P.; Legat, J.-D. Analog implementation of a Kohonen map with onchip learning. IEEE Trans. Neural Netw. 1993, 4, 456–461. [Google Scholar] [CrossRef] [PubMed]
- Peiris, V. Mixed Analog Digital VLSI Implementation of a Kohonen Neural Network. Ph.D. Thesis, Dépt. Électr., Ecole Polytechnique Fédérale Lausanne, Lausanne, Switzerland, 2004. [Google Scholar]
- Długosz, R.; Talaśka, T.; Pedrycz, W. Current-Mode Analog Adaptive Mechanism for Ultra-Low-Power Neural Networks. IEEE Trans. Circuits Syst. II Express Briefs 2011, 58, 31–35. [Google Scholar] [CrossRef]
- Długosz, R.; Talaśka, T. Low power current-mode binary-tree asynchronous min/max circuit. Microelectron. J. 2010, 41, 64–73. [Google Scholar] [CrossRef]
- Talaśka, T.; Kolasa, M.; Długosz, R.; Pedrycz, W. Analog Programmable Distance Calculation Circuit for Winner Takes All Neural Network Realized in the CMOS Technology. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 661–673. [Google Scholar] [CrossRef] [PubMed]
- Kolasa, M.; Długosz, R. An Advanced Software Model for Optimization of Self-Organizing Neural Networks Oriented on Implementation in Hardware. In Proceedings of the International Conference Mixed Design of Integrated Circuits and Systems (MIXDES), Torun, Poland, 25–27 June 2015; pp. 266–271. [Google Scholar]
- De Sousa, M.A.; Pires, R.; Perseghini, S.; Del-Moral-Hernandez, E. An FPGA-based SOM circuit architecture for online learning of 64-QAM data streams. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Rio, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Angelo de Abreu de Sousa, M.; Del-Moral-Hernandez, E. Comparison of three FPGA architectures for embedded multidimensional categorization through Kohonen’s self-organizing maps. In Proceedings of the International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Hikawa, H.; Kaida, K. Novel FPGA Implementation of Hand Sign Recognition System With SOM–Hebb Classifier. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 153–166. [Google Scholar] [CrossRef]
- Długosz, R.; Kolasa, M.; Szulc, M. A FPGA implementation of the asynchronous, programmable neighbourhood mechanism for WTM Self-Organizing Map. In Proceedings of the International Conference Mixed Design of Integrated Circuits and Systems (MIXDES), Gliwice, Poland, 16–18 June 2011; pp. 258–263. [Google Scholar]
- Oike, Y.; Ikeda, M.; Asada, K. A High-Speed and Low-Voltage Associative Co-Processor with Exact Hamming/Manhattan-Distance Estimation Using Word-Parallel and Hierarchical Search Architecture. IEEE J. Solid-State Circuits 2004, 39, 1383–1387. [Google Scholar] [CrossRef]
- Sasaki, S.; Yasuda, M.; Mattausch, H.J. Digital Associative Memory for Word-Parrallel Manhattan-Distance-Based Vector Quantization. In Proceedings of the European Solid-State Circuit conference (ESSCIRC 2012), Bordeaux, France, 17–21 September 2012; pp. 185–188. [Google Scholar]
- Mattausch, H.J.; Imafuku, W.; Kawabata, A.; Ansari, T.; Yasuda, M.; Koide, T. Associative Memory for Nearest-Hamming-Distance Search Based on Frequency Mapping. IEEE J. Solid-State Circuits 2012, 47, 1448–1459. [Google Scholar] [CrossRef]
- Talaśka, T.; Długosz, R. Analog, parallel, sorting circuit for the application in Neural Gas learning algorithm implemented in the CMOS technology. Appl. Math. Comput. 2018, 319, 218–235. [Google Scholar] [CrossRef]
- Kolasa, M.; Długosz, R.; Pedrycz, W.; Szulc, M. A programmable triangular neighborhood function for a Kohonen self-organizing map implemented on chip. Neural Netw. 2012, 25, 146–160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Długosz, R.; Kolasa, M.; Szulc, M.; Pedrycz, W.; Farine, P.A. Implementation Issues of Kohonen Self-Organizing Map Realized on FPGA. In Proceedings of the European Symposium on Artificial Neural Networks Advances in Computational Intelligence and Learning, Bruges, Belgium, 25–27 April 2012; pp. 633–638. [Google Scholar]
- Gao, X.; Klumperink, E.A.M.; Nauta, B. Low-Jitter Multi-phase Clock Generation: A Comparison between DLLs and Shift Registers. In Proceedings of the 2007 IEEE International Symposium on Circuits and Systems, New Orleans, LA, USA, 27–30 May 2007; pp. 2854–2857. [Google Scholar]
- Liu, C.C.; Chang, S.J.; Huang, G.Y.; Lin, Y.Z. A 10-bit 50-MS/s SAR ADC With a Monotonic Capacitor Switching Procedure. IEEE J. Solid-State Circuits 2010, 45, 731–740. [Google Scholar] [CrossRef]
- Długosz, R.; Pawłowski, P.; Dąbrowski, A. Multiphase clock generators with controlled clock impulse width for programmable high order rotator SC FIR filters realized in 0.35 μm CMOS technology. In Proceedings of the Microtechnologies for the New Millennium 2005, Sevilla, Spain, 9–11 May 2005; Volume 1056. [Google Scholar]
- Shin, D.; Koo, J.; Yun, W.J.; Choi, Y.; Kim, C. A fast-lock synchronous multiphase clock generator based on a time-to-digital converter. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Taipei, Taiwan, 24–27 May 2009; pp. 1–4. [Google Scholar]
- Dong, L.; Qiao, M.; Fei, L. A 10 bit 50 MS/s SAR ADC with partial split capacitor switching scheme in 0.18 μm CMOS. J. Semiconduct. 2016, 37, 015004. [Google Scholar]
- Chuang, C.N.; Liu, S.I. A 40GHz DLL-Based Clock Generator in 90nm CMOS Technology. In Proceedings of the 2007 IEEE International Solid-State Circuits Conference. Digest of Technical Papers, Taipei, Taiwan, 11–15 February 2007; pp. 178–180. [Google Scholar]
- Liu, T.-T.; Wang, C.-K. A 1–4 GHz DLL Based Low-Jitter Multi-Phase Clock Generator for Low-Band Ultra-Wideband Application. In Proceedings of the IEEE Asia-Pacific Conference on Advanced System Integrated Circuits(AP-ASIC2004), Fukuoka, Japan, 5 August 2004; pp. 330–333. [Google Scholar]
- Kim, J.-H.; Kwak, Y.-H.; Kim, M.; Kim, S.-W.; Kim, C. A 120-MHz–1.8-GHz CMOS DLL-Based Clock Generator for Dynamic Frequency Scaling. IEEE J. Solid-State Circuits 2006, 41, 2077–2082. [Google Scholar] [CrossRef]
- Kim, Y.; Pham, P.-H.; Heo, W.; Koo, J. A low-power programmable DLL-based clock generator with wide-range anti-harmonic lock. In Proceedings of the International SoC Design Conference (ISOCC), Busan, Korea, 22–24 November 2009; pp. 520–523. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
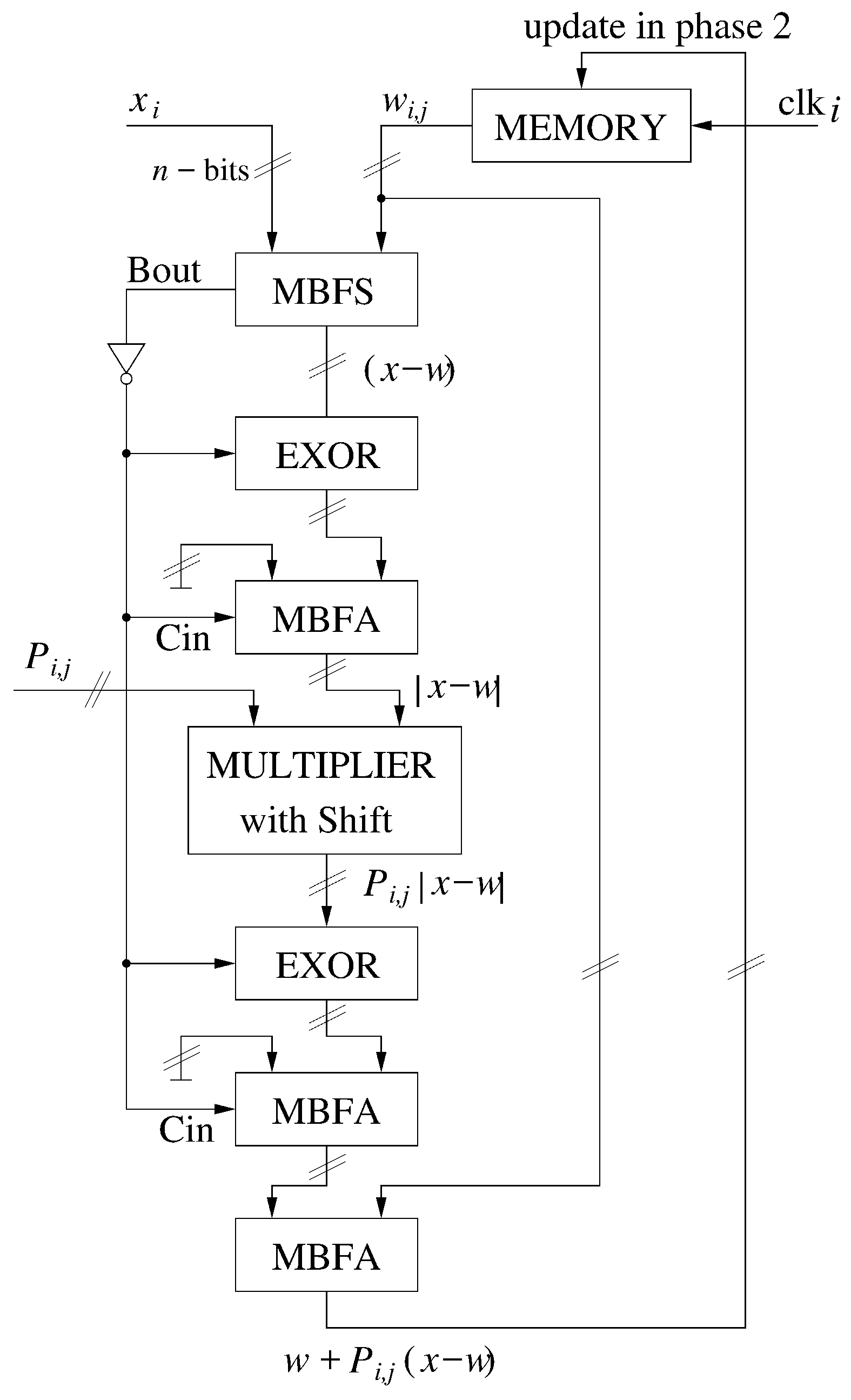{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Talaśka, T. Components of Artificial Neural Networks Realized in CMOS Technology to be Used in Intelligent Sensors in Wireless Sensor Networks. Sensors 2018, 18, 4499. https://doi.org/10.3390/s18124499
Talaśka T. Components of Artificial Neural Networks Realized in CMOS Technology to be Used in Intelligent Sensors in Wireless Sensor Networks. Sensors. 2018; 18(12):4499. https://doi.org/10.3390/s18124499
Chicago/Turabian StyleTalaśka, Tomasz. 2018. "Components of Artificial Neural Networks Realized in CMOS Technology to be Used in Intelligent Sensors in Wireless Sensor Networks" Sensors 18, no. 12: 4499. https://doi.org/10.3390/s18124499
APA StyleTalaśka, T. (2018). Components of Artificial Neural Networks Realized in CMOS Technology to be Used in Intelligent Sensors in Wireless Sensor Networks. Sensors, 18(12), 4499. https://doi.org/10.3390/s18124499