1. Introduction
One of the most promising applications of the emerging Internet of Things (IoT) paradigm is Smart Cities [
1]: the myriad sensors and actuators deployed in a modern city can provide many novel services to citizens and institutions and make the existing ones more efficient and user-friendly.
Bike sharing is a perfect example of a Smart City-enabled service. Although bike-sharing schemes have existed since the 1960s [
2], issues with theft, vandalism and wrongful usage prevented their widespread adoption [
3] until the arrival of smart biking systems. With the possibility of electronically unlocking bicycles and identifying users, smart bike-sharing systems solved or mitigated these issues: by requesting users’ credit card information before lending the bikes, bike-sharing companies can charge users for damages or theft, with a strong deterrent effect. The use of technology also allowed cities to provide a better service, embedding sensors to obtain real-time data, which can be used to plan and manage the bike-sharing docking stations and adapt to the needs of the users. Many services provide live maps of the available bikes, and ways to detect broken bikes remotely to quickly repair or substitute them are being studied [
4]. Over the past few years, bike-sharing schemes were implemented in most major world cities, with almost universal success. Some of the biggest bike-sharing services in the world are in Barcelona, Paris, London, Hangzhou, Taiyuan and Shanghai in China, New York City, and Montreal. The usage data were easily recorded and used to improve the service and increase the number of users [
5,
6], reducing traffic and pollution. The abundance of data, sometimes including GPS tracking of the bikes’ trajectories, has led to new opportunities for Smart City management, such as, for example, the planning of new bike lanes to cover the most common routes [
7].
In May 2013, New York City launched CitiBike, the largest bike-sharing system in North America. The CitiBike bike-sharing network consists of more than 700 docking stations in Manhattan, Brooklyn and Jersey City, with tens of thousands of rides every day. Despite such large numbers, the service is not always satisfactory. For example, the massive use of the service by commuters results into the quick depletion of the stations in residential areas in the morning hours, and the rapid exhaustion of the available stalls in the docking stations in commercial areas, so that users cannot deposit more bikes. In addition, stations at the top of slopes are more likely to be empty, as users are less keen on cycling uphill. This disparity highlights the importance of finding smart ways to manage large bike-sharing systems, and is reflected by the high rate of negative reviews of the service on TripAdvisor (36% of users rate CitiBike as “average” or lower) and by competitors’ recent experiments with “dockless” bikes that can be parked anywhere and unlocked with a smartphone app.
An effective way to improve bike-sharing systems consists of relocating bikes from overcrowded stations to those with a shortage of bikes. This technique is commonly known as rebalancing. Operators can, e.g., deploy a fleet of trucks to pick up and drop off bikes at different stations to balance the network. The trucks can all depart from the same location, or be distributed in different depots, depending on the size of the network and the operational costs of the service.
The design of an efficient rebalancing scheme, then, requires addressing two major challenges: predicting the demand for bikes and stalls in the docking stations in the different locations covered by the service, and selecting the most efficient way to relocate the bikes in order to best satisfy such a demand. Rather than performing bike rebalancing based on a static scheme, as is common in practical bikesharing services, in this study, we propose a dynamic rebalancing scheme that aims at increasing the users’ satisfaction by minimizing the probability of service failures, i.e., the chance that a user experiences an unsatisfactory service because of the unavailability of bikes or stalls in the docking stations. We model the occupancy of each station as a Birth-Death Process (BDP), with time varying birth and death rates (i.e., arrivals and departures, respectively). In this way, we are able to estimate how long a station will be self-sufficient before running out of bikes or available stalls, knowing its initial state. Periodically, we use the knowledge about such expected survival times to decide whether rebalancing is necessary. Clearly, employing a fleet of vehicles to rebalance the system has a monetary cost that counterbalances the improvement in the network conditions by moving bikes among stations. This cost also depends on the covered distance, as this affects the fuel consumption and the time required for the rebalancing operations. These are important factors that need to be tuned carefully when designing a rebalancing strategy because they play a role in deciding when to perform the bike relocation.
To gauge the performance of our scheme, we use three different metrics: the fraction of time the system is out of service (empty or full stations), the number of daily rebalancing operations, and the daily distance covered by the rebalancing trucks. Our scheme is compared with the benchmark case in which no relocation is done, and a static rebalancing scheme from the literature that rebalances bikes twice a day at preset times [
8]. All the numerical evaluations are based on the dataset of the CitiBike system. In particular, we use the data collected over the past four years, during which the bike-sharing system grew in both number of stations and available bikes. The observed trips are a lower bound for true demand, as empty or full stations prevent users from taking or returning bikes, respectively. In addition, there may be unexpected events such as broken or stolen bikes that affect the bike availability, or special events in the city that make the bike demand differ from its usual pattern. Nonetheless, although the numerical results may be altered by the censoring problem, they are still representative of the positive impact the rebalancing has on the bike-sharing system. Furthermore, the framework we propose is general and can be readily adapted to new data. It is also an effective tool to identify the critical stations and locations so as to improve the bike-sharing systems by adding bikes at selected stations and increasing the station density in the critical areas. For a deeper analysis of the dataset, with considerations on other patterns such as weather and distance from mass transit stops, we refer the reader to our related work in [
9], in which we compare the results from New York City with another dataset from a smaller system.
The rest of this work is organized as follows.
Section 2 gives an outline of the state of the art on Smart Cities, bike sharing and rebalancing optimization.
Section 3 presents our model of the bike-sharing problem, while
Section 4 introduces the CitiBike dataset and the processing to derive the model parameters from it.
Section 5 describes the performance of our dynamic rebalancing scheme. Finally,
Section 6 contains our conclusions and some possible avenues of future research on the subject.
3. System Model
We define the network of bike-sharing stations as a fully connected directed graph , where is the set of stations, and with is the set of edges between stations. Note that each link is counted twice to allow for different costs between two stations according to the direction of the path. Each node is characterized by its capacity , i.e., the total number of bike stalls at the station, and its current occupancy , i.e., the number of bikes available at time t. The edges are weighed by a distance metric between stations, denoted as . As the graph is fully connected, each station can be reached from any other station.
Our goal is to determine a dynamic rebalancing scheme that minimizes the user dissatisfaction while maintaining the rebalancing cost as low as possible. The dissatisfaction is related to the probability that users experience service failures, i.e., find stations either empty () or full ().(In this work, we do not distinguish between failures due to empty and full stations, though this aspect will be studied in future work.) We assume that a fleet of vehicles with given capacities is available for the rebalancing procedure and that the operating day is divided into discrete time frames of length . The rebalancing fleet can be deployed at the beginning of each frame.
The rebalancing problem is made up of two main components.
At each time frame k, we need to determine the desired state for each station . Since we would like to maximize the time until a station becomes either empty or full, is the inventory level that maximizes the survival time of the station. This is computed by analyzing the historical user data.
The real rebalancing problem, which consists of identifying which stations are either overcrowded or in shortage of bikes, according to their survival times, and designing the truck routes to perform the bikes pickups and deliveries.
In the following, we first describe the procedure to determine the survival times based on the historical data, and then the network-wide rebalancing optimization.
3.1. Survival Time
Modeling the network as a whole is not computationally tractable for a large number of stations. However, we can model each station’s occupancy separately as a Markov-Modulated Poisson Process (MMPP) [
49]: the occupancy follows a finite Markov BDP
, where the birth and death processes are Poisson distributed with time-varying rates
and
, respectively. We can reasonably assume that the demand for bikes is not affected by the current occupancy of the station (unless it is either empty or completely full(The censoring problem will be described in
Section 4.1), and therefore the birth and death rates are assumed to be independent of the current state. The BDP is limited by the station’s capacity
.
In order to reduce the computational complexity [
50,
51] and accurately estimate
and
from the historical data, we simplify the station behavior as a discrete-time BDP, with birth and death rates that are piecewise constant during time frames of duration
, which is an integer multiple of the BDP slot
. Basically, we map the continuos time
t into its discrete counterpart
where
n is the index of the
frame (which has duration
) and
k is the index of the
slot (which has duration
). The two assumptions we have made (piecewise constant birth and death rates, and discrete time) make it possible to have a simpler yet accurate model of the stations’ dynamics, and also to derive the correct parameters of the arrival and departure processes for the available dataset. Once
was defined, we verified that the empirical distribution of the inter-arrival times in a single time frame
fits an exponential distribution, thus validating the short-term Poisson assumption.
As mentioned, a service failure occurs whenever a station is in state 0 or in state
: if the stalls are all empty, bikes cannot be rented, while if they are all full, users cannot deposit more bikes. In order to compute the first passage time to either of the two failure states, we can consider an equivalent process in which 0 and
are absorbing states. Accordingly, we formally define the survival time
of node
v as the smallest time
after which the probability
of reaching state
, starting from state
at time
t, exceeds a predefined threshold
, i.e.:
Note that
is time varying, reflecting the fluctuations of the arrival and departure rates. For ease of writing, however, the parameter
t will be omitted in the following, whenever possible. The threshold
makes it possible to tune the reactivity of the rebalancing system: lower values of
will yield shorter survival times and, in turn, more frequent rebalancing, which will reduce the service failure risk but increase the operational costs of the service.
Since the birth and death rates vary from frame to frame, the transition probability
needs to be calculated by considering the state distribution at the end of the previous frame. Applying the Markov property, we get:
where
n and
k are given by the time relation (
1). The transition matrix after
steps is the
-th power of the one-step transition matrix (note that the time slot index
k starts from 0 according to the time relation (
1)), and then we use the Markov property as in Equation (
3) to derive the transition probabilities when the system is in frame
n and slot
k.
To compute
and
for a given station
v, we need to evaluate the transition probabilities starting from state
m at every time step. In the following, we thus focus only on a single slot of length
, with birth and death rates denoted as
and
, respectively. Let
and
be the random variables that describe the numbers of departures and arrivals at station
v in the considered slot, respectively. We model the demand for bikes (i.e., potential departures) and empty stalls (i.e., potential arrivals) as Poisson variables, with mean
and
, respectively. We assume that a sequence of events results in the same state regardless of the order of occurrence, so that the next state of the station is given only by the total number of departures and arrivals in a time slot. This is not strictly correct, as different orderings of the same events might bring the system in an absorbing state. In general, however, the probability of this event is sufficiently low and does not significantly affect the accuracy of the simplified model. The probability
of going from state
i to state
j in one time step
is
where the last equality follows from the Poisson distribution of
and
. The result of the sum in Equation (
4) follows a truncated Skellam distribution [
52]:
with
,
(the average of
), and
(the average of
).
is the modified Bessel function of the first kind and order
k [
53]:
The mass probability function given in Equation (
5) is for the standard Skellam distribution, while we need to truncate it over the finite range
. Thus, the transitions to the two absorbing states 0 and
have the following probabilities:
Since 0 and
are absorbing states,
, while
and
.
In practice, the transition probabilities at time instant
t are computed in three steps with a time hierarchical interrelation, which exploits the time equivalence of Equation (
1):
We use the Markov property to separate the problem at a frame level; to calculate the transition probabilities in frame , it is necessary to compute those at the end of each frame .
Within a single frame n, the transition probabilities at slot are derived by elevating the single-step transition matrix of frame n to the power of (since slot indices start from 0).
The transition probabilities at the beginning of a frame (i.e., for slot index
) are then computed using Equations (
4), (
8) and (9).
Hence, for each time instant
t and starting state
m, we are able to compute the probability of being in one of the failure states, 0 or
, and, consequently, the survival time
of station
v. Intuitively,
is first increasing and then decreasing in
m (it is 0 for both
and
), and there exists a state
that leads to the maximum survival time
:
Ideally, at time t, we would like to be in state as it corresponds to the longest time for which station v is self-sufficient (i.e., it does not need rebalancing). Next, we describe how to plan the rebalancing operation by exploiting the knowledge of the survival times.
3.2. Network-Wide Optimization
We model the dynamic rebalancing problem as an optimization problem on the bike-sharing network graph
. The number of deployed trucks is predefined and denoted as
X, and we assume that the subsets of stations visited by each vehicle are disjoint. Each truck has a given capacity, which defines the maximum number of bikes it can transport concurrently. Then, we define a circular graph
, where
is the union of the set of stations that the fleet of trucks rebalances (
) and the truck depot (
), while
is the set of edges that solves the Vehicle Routing Problem (VRP) [
54] on
.
We denote the station occupancy vector before rebalancing as
, while the occupancy vector after rebalancing is
. The obtained reward is measured as the time gained before a system failure occurs, i.e., the difference between the minimum survival times among all the stations after and before the rebalancing operation. Each rebalancing operation also implies a fixed cost for each vehicle in the fleet, plus an additional cost that depends on the total length
of the route of each vehicle
. The rebalancing optimization function
can thus be modeled as
where and
and
are two weights (measured in time units and time units per kilometer, respectively), and the survival times
are computed as described in
Section 3.1.
We introduce a further parameter
in the optimization function, which indicates the clipping threshold for the survival time: this has the dual purpose of disregarding longer survival times, which might have a larger estimation error, and avoiding useless rebalancing operations when the minimum survival time of the system is already very long. The optimization function then becomes
As discussed in the introduction of
Section 3, the operating day is divided into discrete frames of length
. The rebalancing problem is solved periodically, every
, and consists of defining
and
, which means i) identifying which stations require rebalancing, and ii) determining the path for the rebalancing truck. Note that, if at time
t the optimization function
is negative for any
, the cost of moving the vehicle fleet is larger than the reward obtained for reallocating the bikes, and thus no rebalancing is performed. In this case,
.
Since the optimization function also depends on the distance covered by the rebalancing truck, the set of stations to visit, , and the vehicle route, , should be jointly determined. For simplicity, we first assume to know the minimum path length of the rebalancing route for a given set of nodes, so that we can derive and then describe how to compute such distance. The computation is simplified by the following theorem, which states that contains the nodes with the smallest survival times, so that all subsets that do not satisfy the theorem can be safely discarded as suboptimal.
Theorem 1. If , then
Proof. Assuming the truck follows the optimal route
, adding a node to
cannot decrease the distance
because of the triangle inequality. It follows that, in order for
v to be part of the rebalancing set
, its presence needs to increase the first term of the function in (
12), i.e.,
. ☐
The procedure to determine
is hence described in Algorithm 1. Intially,
only contains the deposit node 0 (Line 1); then, at each iteration
i, we identify the node
with the minimum survival time (Line 9). We compute the reward obtained by adding
to
, as if its survival time were optimal,
(Line 10), and the cost to add it to the truck route (Line 14). In particular, the reward is computed as the difference between the smallest survival time in set
and the smallest survival time before rebalancing (Lines 4 and 11), while the cost depends on the new route length (see Equation (
12)). If the optimization function increases (Line 15), node
is indeed added to
. The algorithm stops if either all nodes of
have been included in
, or the optimization function can no longer be increased because the minimum of the optimal survival times among all visited nodes
after rebalancing is smaller than the current survival time of any of the unvisited nodes (those in
) (Line 18).
The solution of the dynamic rebalancing problem has two distinct parts: (i) determining the route for the set of stations that need to be rebalanced (Line 12 in Algorithm 1) including possible additional constraints given by vehicle capacity and travel times, and (ii) deciding whether to start the rebalancing operation and, possibly, which stations to visit. The literature on the first part of the problem is already extremely vast and well-developed. In particular, any of the solutions discussed in
Section 2.2 can be used to determine the rebalancing path. Instead, there are very few studies on the second problem, i.e., deciding which station to rebalance and when, which is the focus of our model. We remark that the path-planning algorithm has an impact on the rebalancing strategy provided by our approach, since the cost computed in Line 14 includes the covered distance that, in turn, depends on the chosen path. However, our framework is general and can accomodate any path-planning strategy.
| Algorithm 1 Rebalancing strategy |
| 1: | Initialize , , , done |
| 2: | Set parameters | |
| 3: | Set | ▹ Vector with survival times before rebalancing |
| 4: | Set | ▹ Smallest survival time before rebalancing |
| 5: | | ▹ Set the survival time threshold |
| 6: | Set | ▹ Vector with optimal survival times for each station |
| 7: | while () and (done ) do | ▹ Until there are nodes to visit that can improve the net reward |
| 8: | | |
| 9: | | ▹ Choose unvisited node with smallest survival time |
| 10: | | ▹ Update survival time of node |
| 11: | | ▹ Update reward |
| 12: | Determine rebalancing path over | |
| 13: | compute path length of | ▹ Compute distance to cover for rebalancing |
| 14: | | ▹ Update cost |
| 15: | if (reward − cost) then | ▹ It is worth to include node in the rebalancing |
| 16: | |
| 17: | reward − cost |
| 18: | if then |
| 19: | done | ▹ The optimization function can no longer be increased |
The path-planning problem can be optimally solved by the well-known VRP, which yields the lowest possible cost. However, the VRP is an NP-hard problem, so that several efficient optimization algorithms have been defined in the literature for different scenarios and sets of assumptions, in order to reduce the computational complexity. In our simulation, we made the following assumptions to simplify the problem:
We use the Euclidean distance between stations as distance metric for the set of edges . This implies that for any two stations i and j.
We consider a single rebalancing vehicle, i.e., , with infinite capacity. Notice that this scenario reduces the VRP to the Traveling Salesman problem.
The Traveling Salesman problem is still NP-hard. Since the focus of this work is on the dynamic algorithm and not on the solution to the routing problem, we opted for a simple heuristic that greedily chooses the closest unvisited node at each step. Let
be the set of nodes visited up to iteration
i. Since the truck deposit is the first node to be visited, we set
, while for
(Note that the last iteration is
because
includes also the deposit node
.), we have
, where
is the node visited at iteration
i, such that
where, as mentioned,
is the Euclidean distance between nodes
x and
y. This rule implements the well-known
nearest-neighbor heuristic, which has often been used as a benchmark for Traveling Salesman heuristic solutions [
55]. The total path distance covered by the rebalancing truck is
where the last term is the distance the vehicle covers to go back to the deposit after the rebalancing operations. This heuristic can be computed in
time. The total running time of the heuristic algorithm is
, since
. Although using a greedy heuristic may not give the optimal routing solution, solving an NP-hard problem might not be practical for large instances.
5. Results
In order to validate our optimization scheme, we compare its performance with two other scenarios: a system with no rebalancing and one with static rebalancing. In the first case, we just let the bike-sharing system evolve without intervening. In the second one, we bring the whole network to the optimal state twice a day, at 3 a.m. and 3 p.m., as in [
8]. In our simulations, we make the following assumptions.
The CitiBike data accurately represent the demand for bikes. As discussed in
Section 4.1, this may not be strictly true because of the censoring effect, so that the demand patterns in the data represent a lower bound for the real demand.
Bikes coming from or going to stations that are not considered in the optimization framework because of lack of data are assumed to be new bikes entering the system, or broken bikes exiting it, respectively.
If a user does not find a bike at their desired station, they simply exit the system and the trip does not happen. If they find a bike at their departure station but do not find a free spot at the arrival station, the bike exits the system.
At the beginning of every month, the state of each station is reset to the optimal value. Since the dataset does not provide the state of each station, this assumption was necessary to define the initial state of the system.
Naturally, the optimization schemes themselves are not affected by these assumptions, but the numerical results of the simulation may change when choosing different assumptions. The simulations were run for a whole year of data, from July 2016 to June 2017, and the results are presented on a month-by-month basis. We set the cost of taking a rebalancing trip, , to 2700 s (45 min); since the duration of a slot is 15 min, this means that the minimum survival time must improve by at least an hour for the system to consider a rebalancing operation. The parameter , which represents the cost of moving the rebalancing truck, was set to four different values, namely 0.02, 0.04, 0.08, and 0.12 s/m.
We used the data without any optimization scheme to test the assumptions of our model. First, we verified the accuracy of the Poisson model for the interarrival times by considering the data of several randomly chosen stations, which exhibited an extremely good fit with the exponential distribution, despite the relatively small sample.
The second test was intended to check the validity of the survival time formula, for which we run the prediction without implementing any rebalancing strategy, in order not to perturb the system evolution. This test was performed for two randomly chosen weeks in September 2016 and January 2017, and the results were extremely good, since the empirical distribution of the survival time obtained from the dataset was almost overlapping with our model, with a relative error on the survival time lower than 1.5%. The slight discrepancy can be explained by time-dependent factors such as the yearly increase in the demand for bikes, which causes the model to slightly underestimate the demand in late 2016 and early 2017 since we computed the survival time using the data from July 2013 to June 2016.
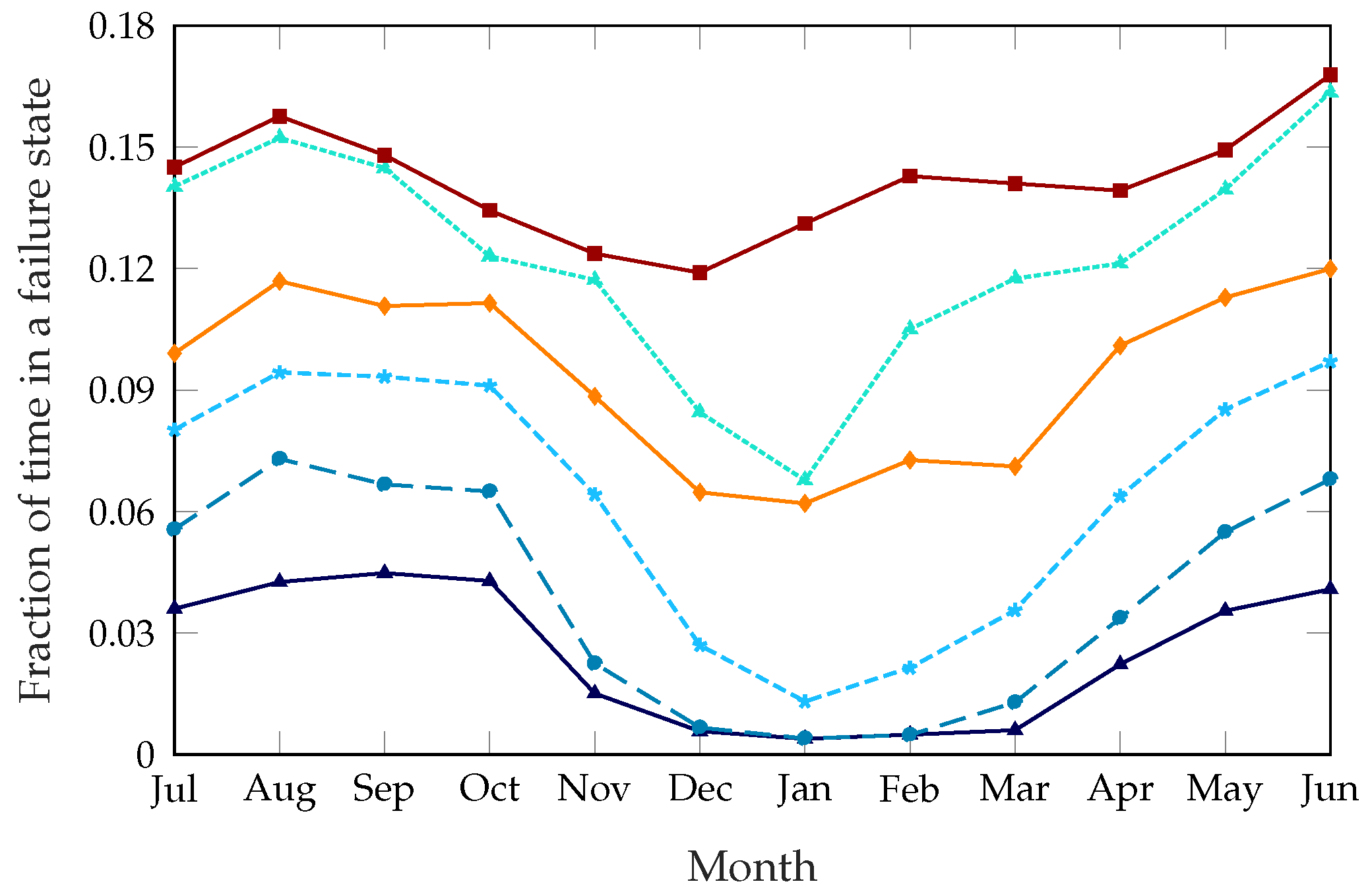
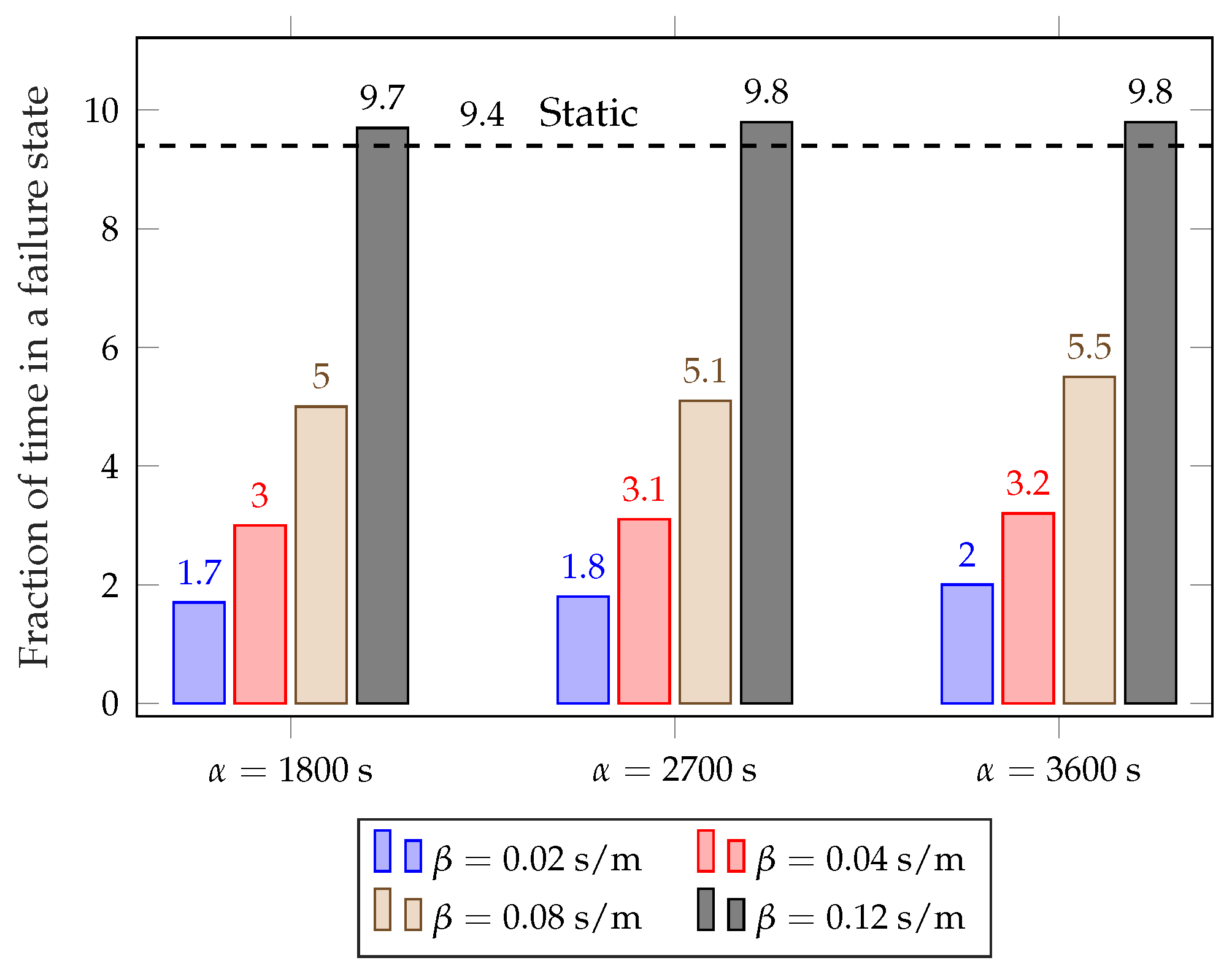
Service improvement. Figure 3 shows the fraction of time that the bike-sharing system spends in a failure state, i.e., either completely full or empty, averaged for each station and for each month of the year. We used this metric instead of the number of service failures because it is less affected by the censoring problem we described in
Section 4.1, as requests that could not be fulfilled are not shown and would not be counted in the results.
The unoptimized system has a failure probability of about 14%, which means that, without any rebalancing intervention, stations cannot satisfy the users’ needs for about 14% of the time. The static rebalancing strategy from [
8], which optimizes the whole system twice a day at preset times, can improve this to about 11% during the summer and 6% during the winter. This discrepancy is due to the far lower demand during colder months, which makes rebalancing actions more effective. The dynamic system can improve the service even further: with low values of
, the failure time can be as low as 3% during the summer and 0.4% during the winter. This obviously comes at a cost, as an aggressive rebalancing strategy will result in more daily trips and a higher cost to move the trucks. However, the framework we propose makes it possible to tune the dynamic scheme to the specific requirements of the system, in order to balance the operational costs and quality of the service as desired. For example, setting
, we can approximately replicate the performance of the static scheme, as shown in
Figure 3.
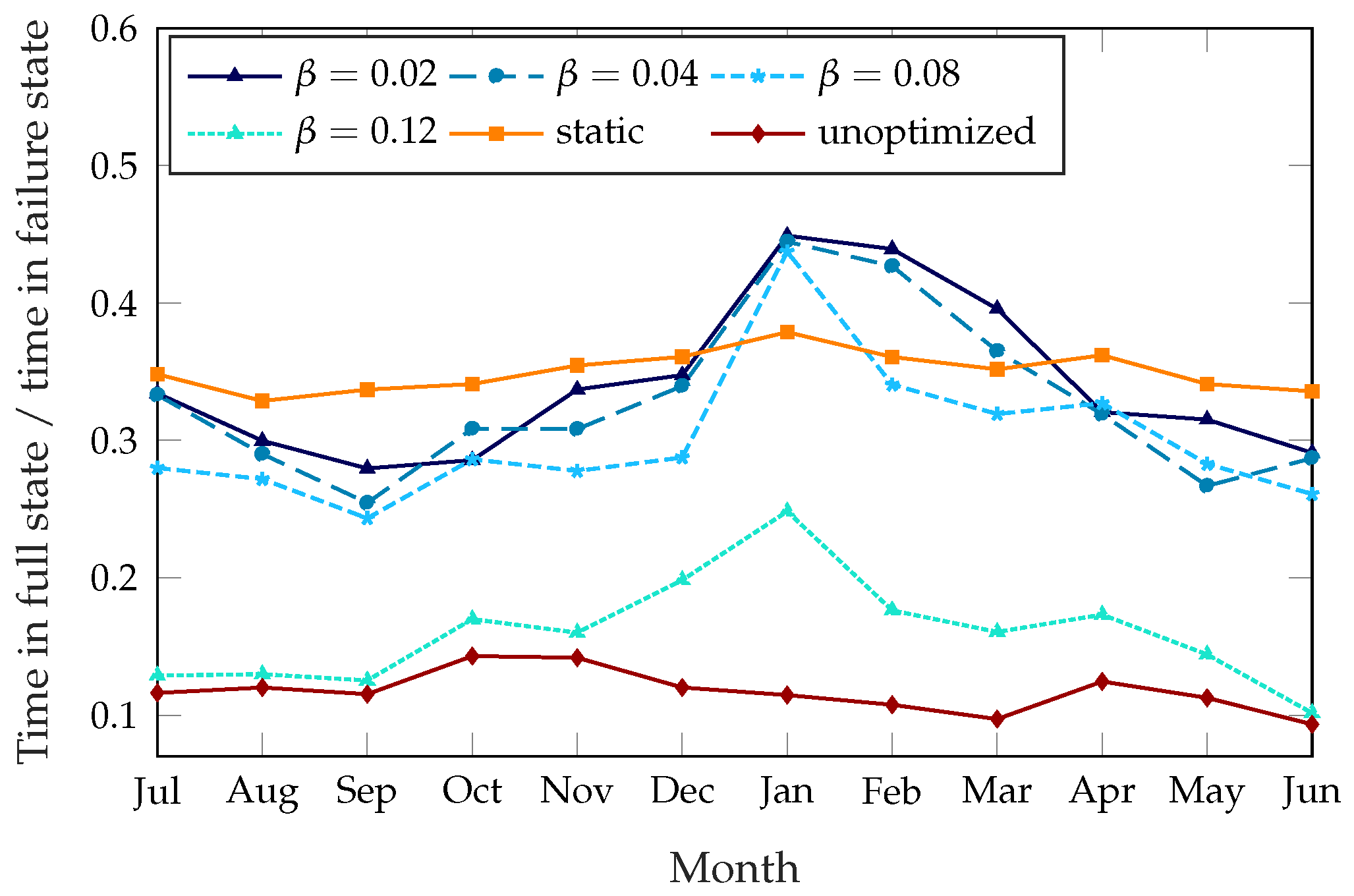
In order to have a full picture of the effectiveness of the scheme, we need to consider not only the total failure time but also the kinds of failures, as the two failure modes have a different impact on the behavior of the users and on the future planning of the system.
Figure 4 shows the ratio of the time the stations spend completely full over the total failure time. The unoptimized system has a very skewed failure mode, with almost 90% of failures due to empty stations. The static rebalancing scheme has a full station ratio of about 35%, which is almost constant throughout the year. The dynamic rebalancing schemes show a higher ratio of full stations during the winter months, mirroring the overall pattern from
Figure 3: since most of the failures during the summer months are due to empty stations, the improvement during the winter comes from the stations being empty less often, while the time they spend full does not decrease as much. This effect is particularly significant for
, which shows a variation from 15% in summer to over 30% in winter, while the other settings of the dynamic scheme are more similar to the static case.
Rebalancing costs. The improvement in the service obviously comes at a cost: the fleet of rebalancing trucks must be deployed several times a day, and a more aggressive rebalancing strategy increases both the number of trips and the total distance that needs to be covered, with higher fuel and personnel costs.
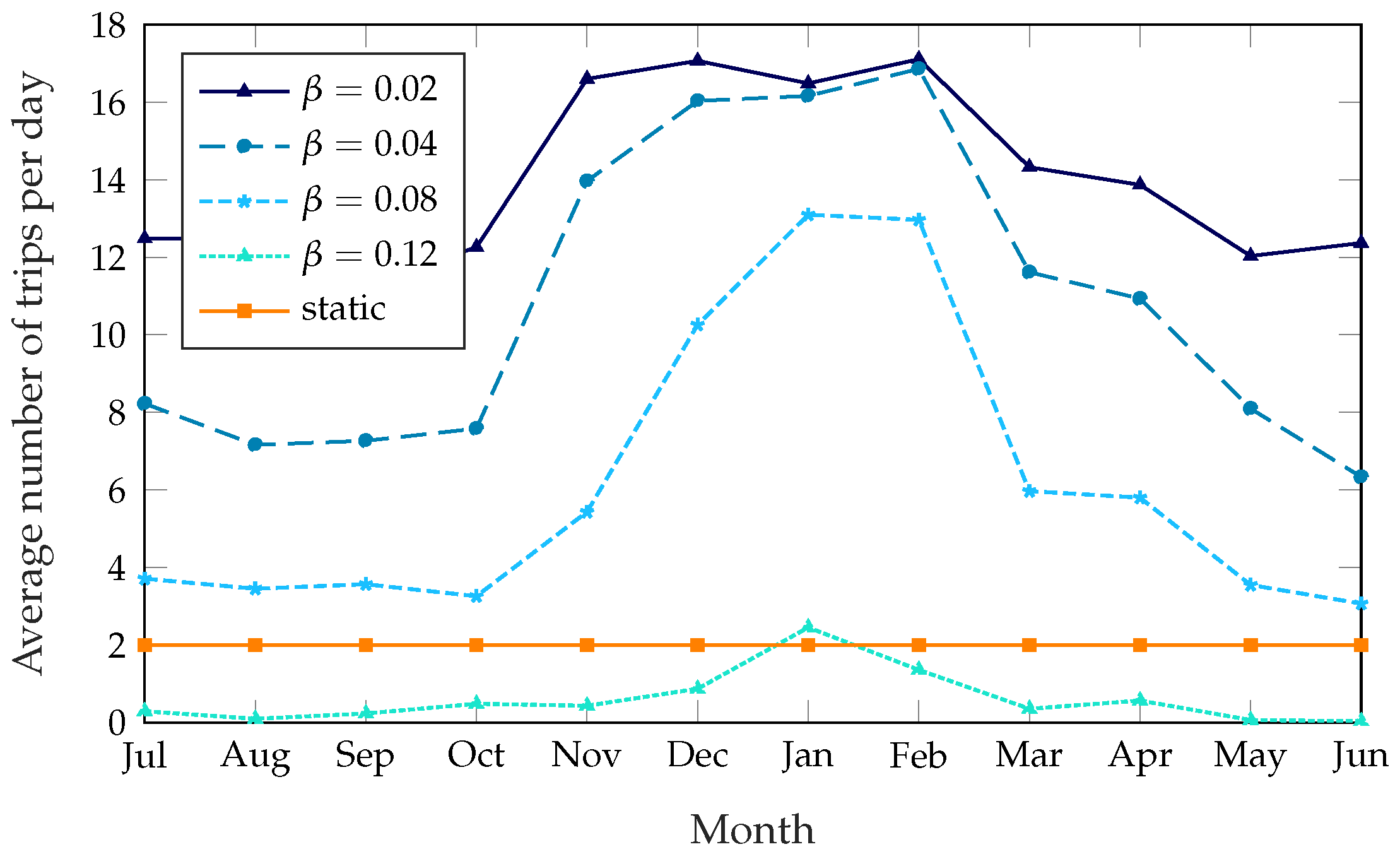
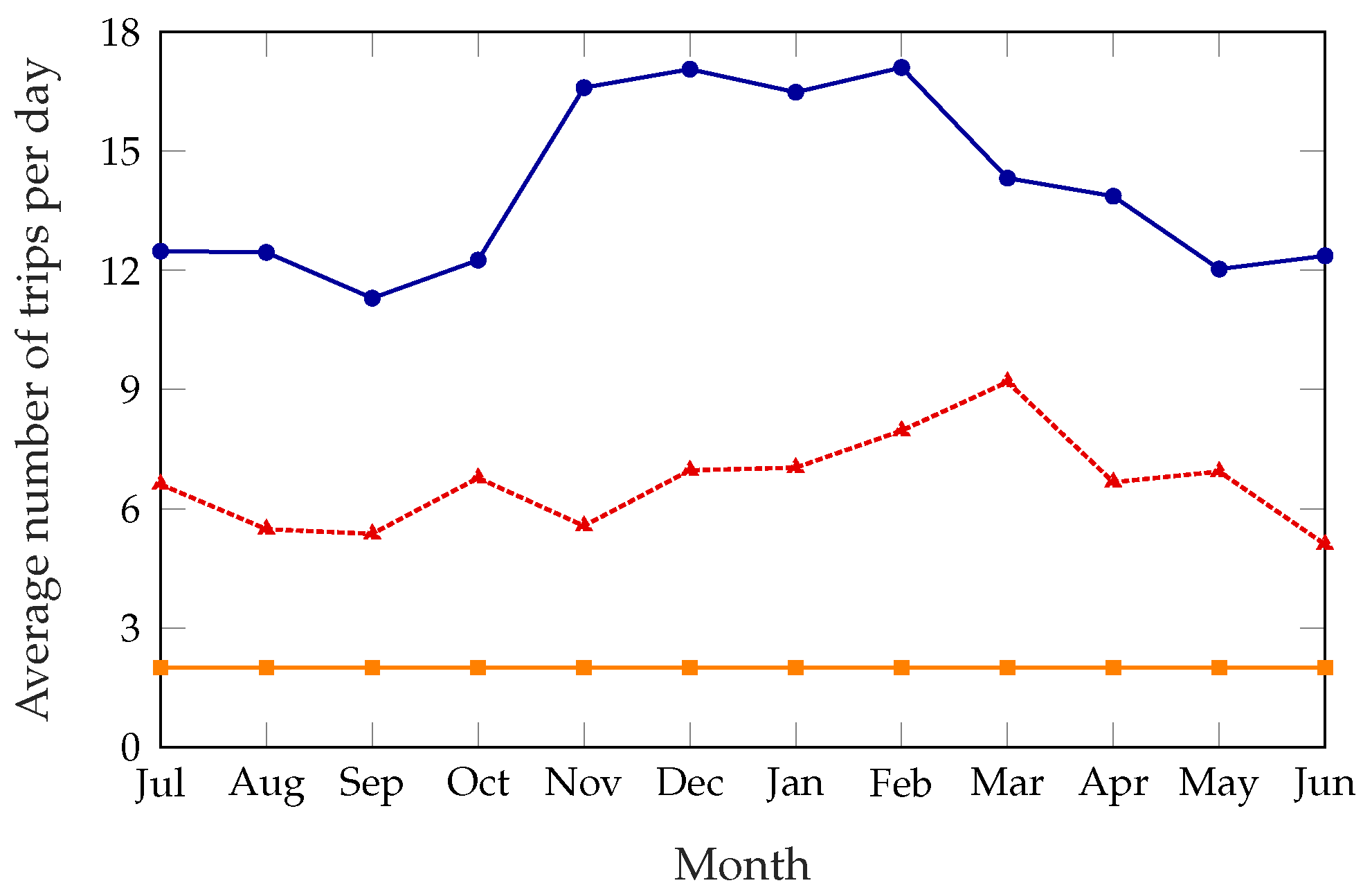
Figure 5 shows the number of trips the rebalancing truck has to take every day, averaged over each month; the unoptimized system is not shown in this figure, since no trips are taken at all. The static scheme has a constant number of trips per day, since it explicitly requires the truck to take two trips at predetermined times. As for the dynamic schemes, the large difference between the summer and winter months might be counterintuitive, as one would expect a lower demand to correspond to a lower number of trips. However, when demand is lower survival times are larger in general; stations that are not in their optimal state might therefore benefit more from a rebalancing, increasing the potential reward. Since the cost of rebalancing the system is constant, rebalancing the system is often more rewarding during the winter, resulting in a higher number of trips and a better service, as
Figure 3 and
Figure 5 show. This issue is exacerbated by time-dependent factors: as described in
Section 5, most of the anomaly disappears if we use the real demand data instead of the estimate based on historical patterns, and this can be explained by weather patterns, as 2017 was a particularly warm and dry winter.
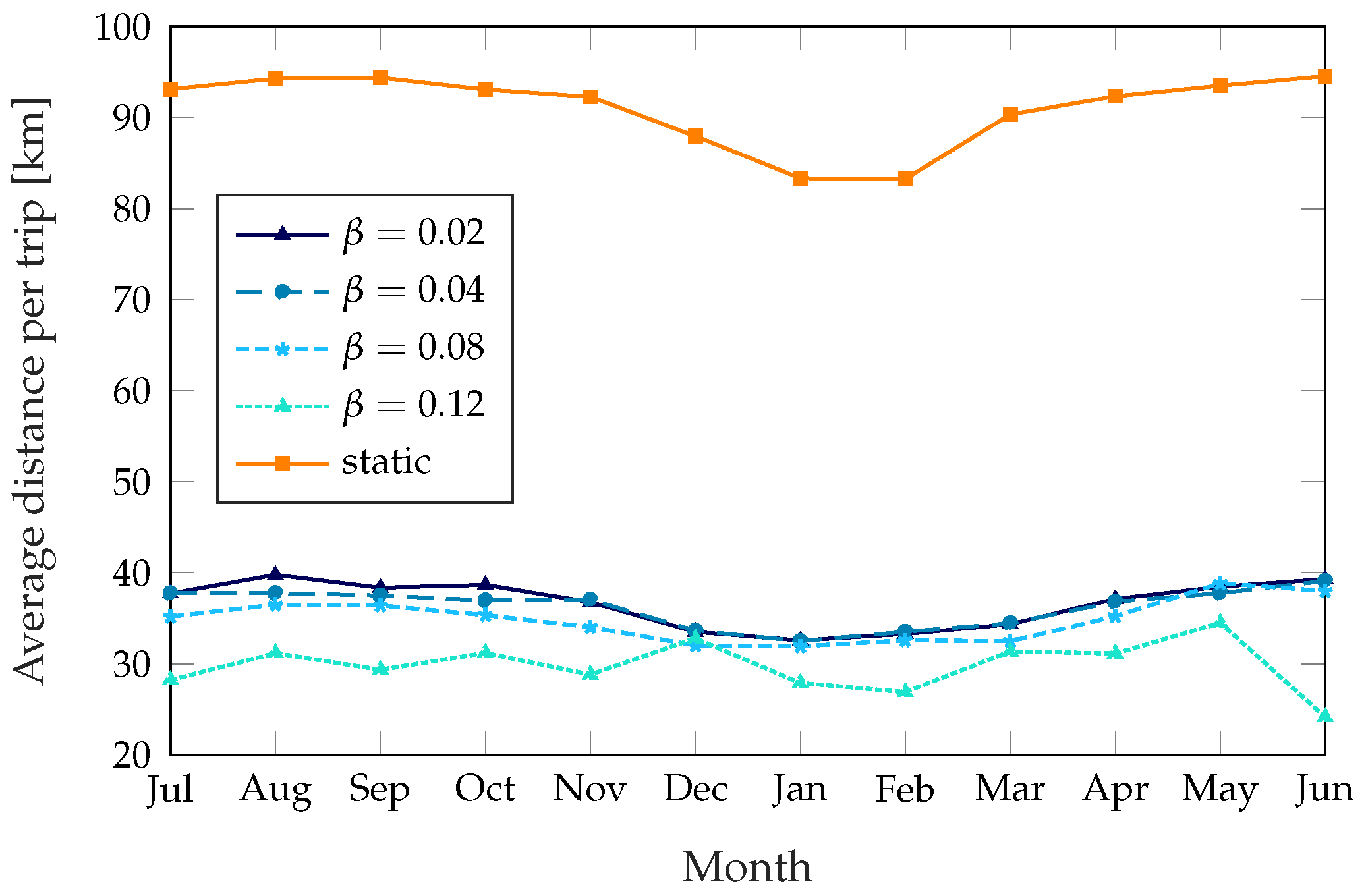
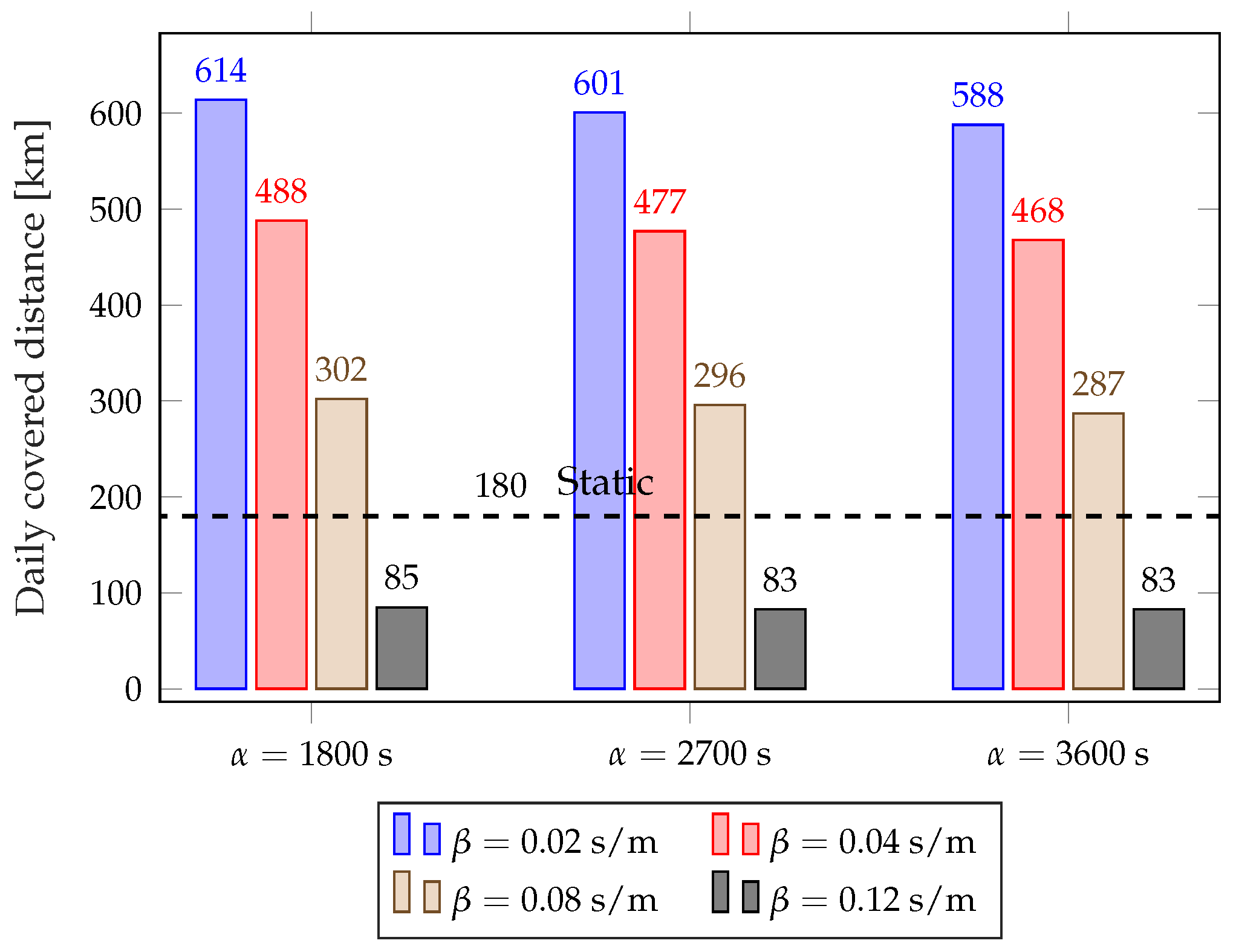
The dynamic schemes need a higher number of trips to get the performance improvement, but the distance the trucks cover on each trip is far lower: while the static scheme rebalances the whole system and covers every station that needs rebalancing, the dynamic schemes only target the stations that need it most. As
Figure 6 shows, the dynamic schemes need between 30 and 40 km per trip, while the static scheme can need more than 90 km during the summer.
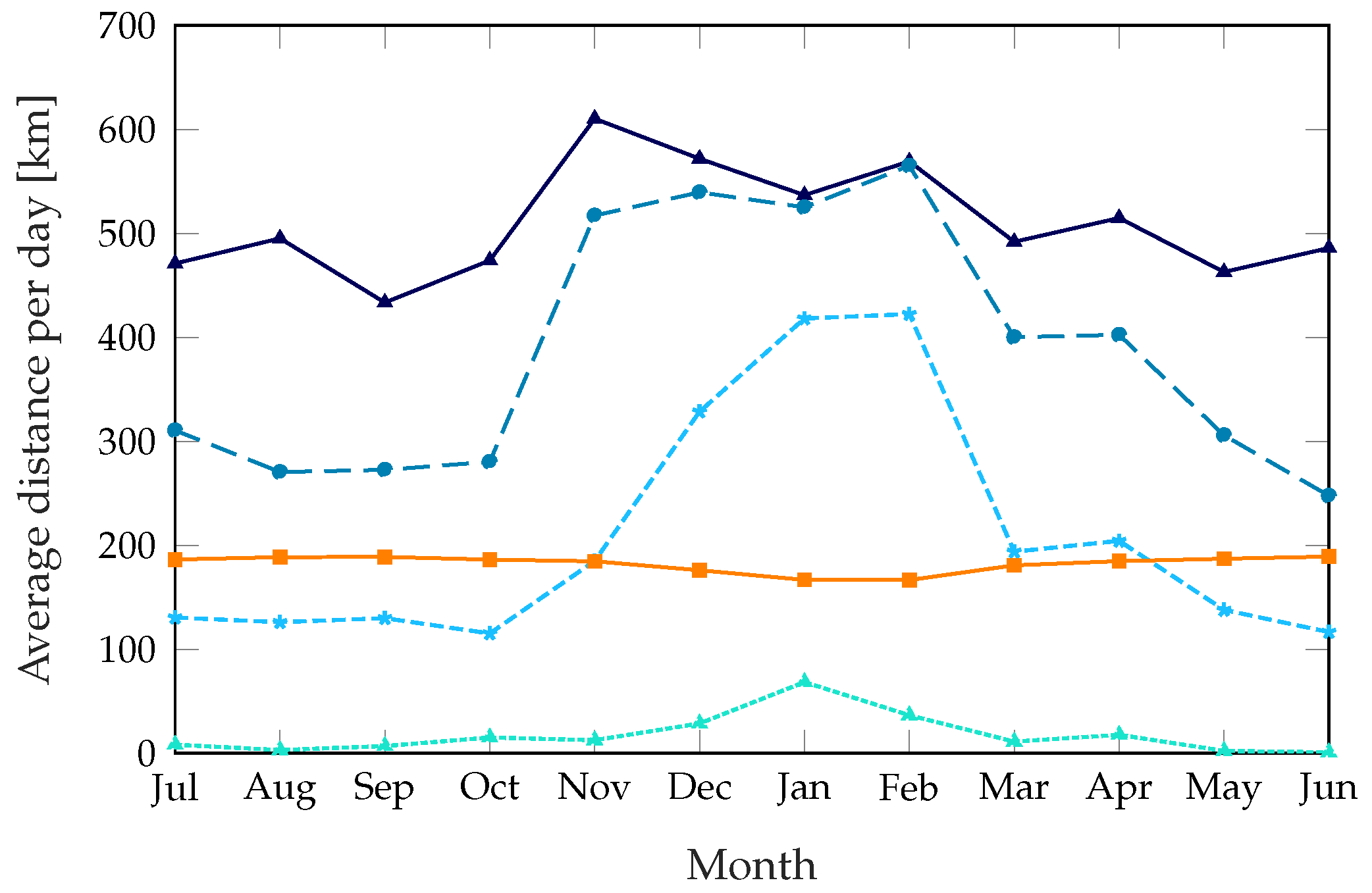
Figure 7 shows the average distance the truck covers during a day: even if the dynamic scheme with
takes more than twice as many trips as the static scheme, with a corresponding performance benefit, the total distance it covers is similar during the summer. The scheme with
reaches a service quality similar to the static scheme’s while taking fewer trips in the summer and covering a smaller distance during most of the year. The parameter
, which we kept at a constant value of 2500 s throughout these simulations, can be used to change the preference of the system from frequent short trips to fewer and longer ones.
In general, the dynamic schemes can take shorter trips, potentially deploying a smaller fleet. (We remark that we only consider one rebalancing truck in this work; future developments are going to address this issue, as the model and optimization function we propose are fully general.) The dynamic nature of our solution allows us to tune the rebalancing to the needs of the system, giving system controllers the freedom to choose the optimal point in the trade-off between service quality and rebalancing costs by changing and .
Figure 8 and
Figure 9 show the average failure rate and average daily distance covered by the rebalancing trucks for different values of
and
, considering the full year. The plots clearly show the trade-off between rebalancing costs and service performance: using lower values of
results in a lower failure rate, but the rebalancing trucks need to be deployed more often and, consequently, cover far more distance every day. The dynamic scheme with
results in a slightly higher failure rate than the static scheme, but requires less than half the rebalancing distance. The parameter
is the key to choose the operating point in the trade-off, as it has a significant impact on the performance of the scheme. The value of
has a limited effect over the considered range, so it can be used for fine-tuning the system after
has been selected.
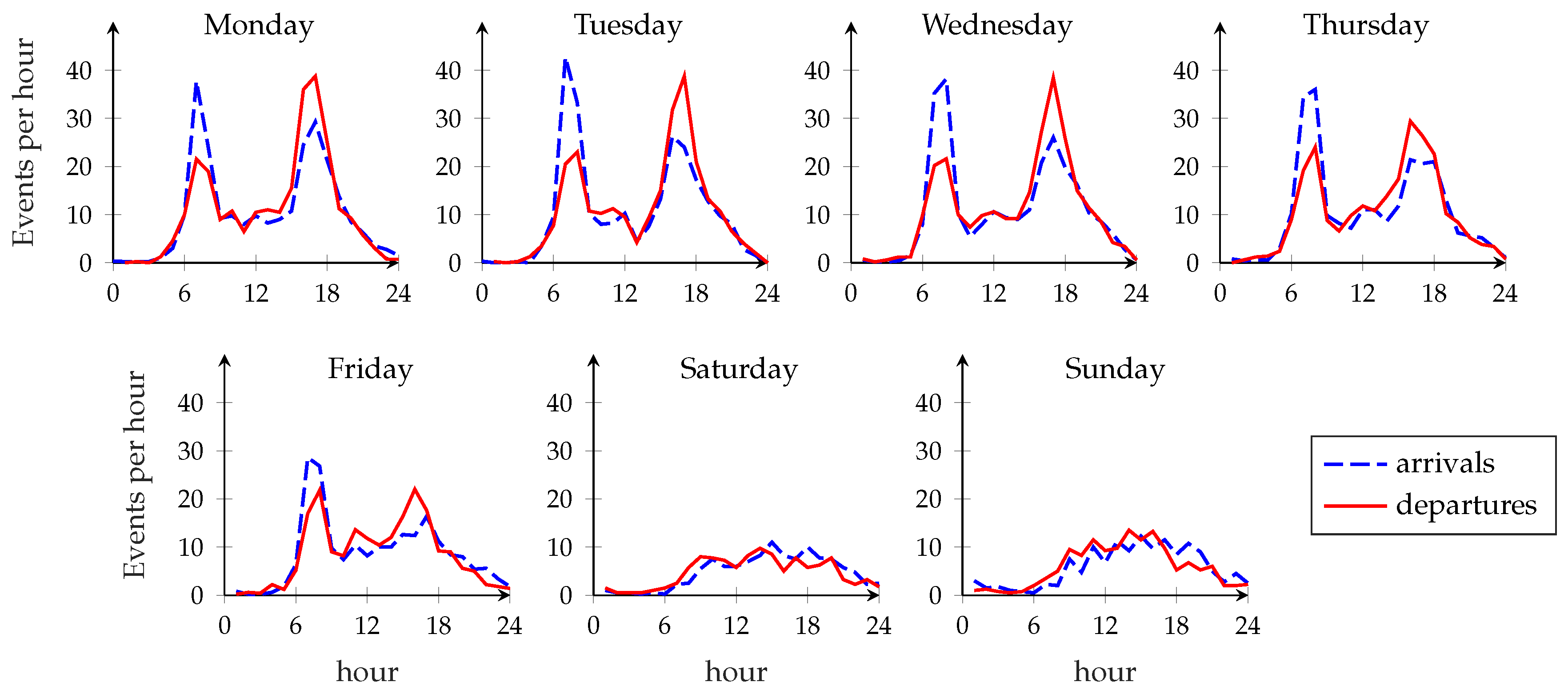
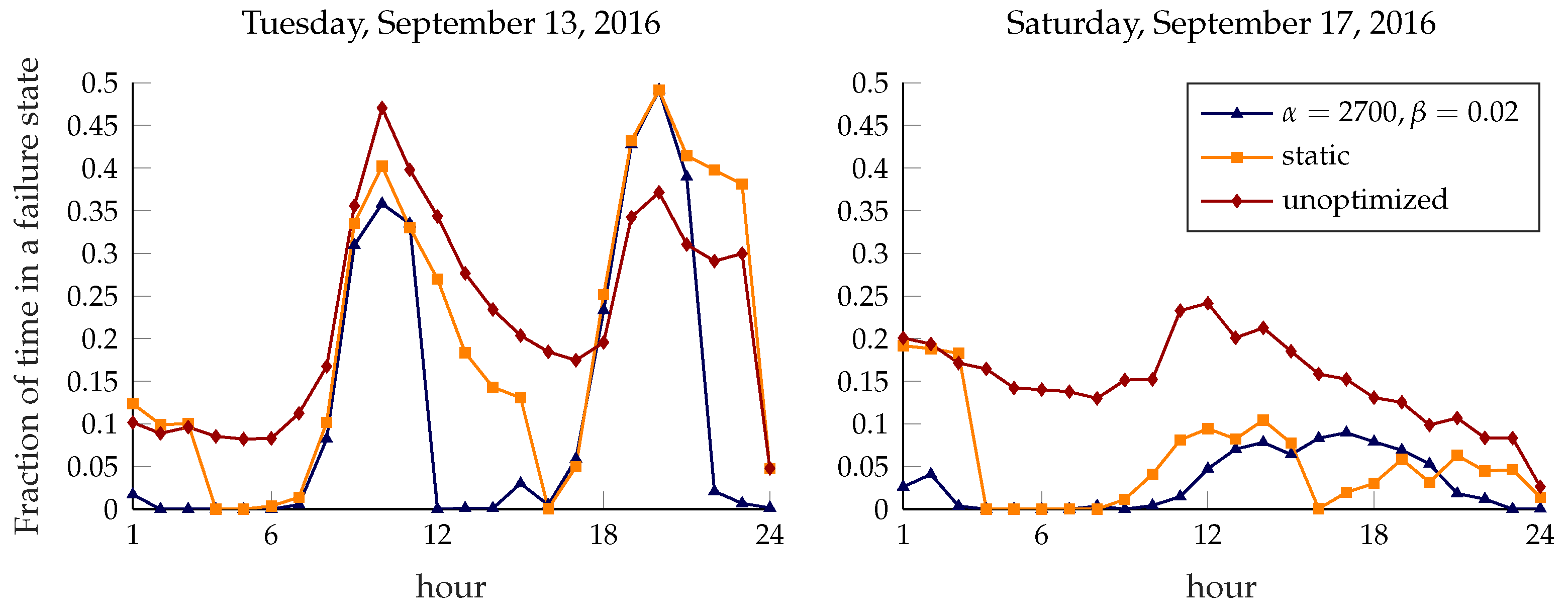
Evolution of the system over time. Figure 10 shows the average fraction of time that a station spends in a failure state for 13 September (Tuesday) and 17 September (Saturday) 2016. As shown in
Figure 2, the difference between a weekday and a holiday is striking: in the first plot, the two intense demand periods starting around 7 a.m. and 5 p.m. are evident from the steep increase of the failure rate, which is almost entirely absent in the other one. The limitations of the static approach to rebalancing can be clearly seen in the first plot: while the rebalancing operation at 3 p.m. brings the failure rate very close to 0 in the following hour, the system is left to itself during rush hour, and the failure rate quickly rises to match that of the unoptimized system. Even though the dynamic approach also has a peak failure rate at rush hour, it quickly recovers and keeps the system in a better state throughout the day; the bike-sharing system is probably underdimensioned for the peak demand, so it is hard for any rebalancing scheme to avoid failure during rush hour, but the dynamic system still yields a significant improvement. The weekend plot shows a similar pattern for the static approach, with perfect functioning right after rebalancing and a steadily increasing failure rate afterwards. However, the lower and more homogeneous demand makes rebalancing less urgent and decreases the gain of using a dynamic approach.
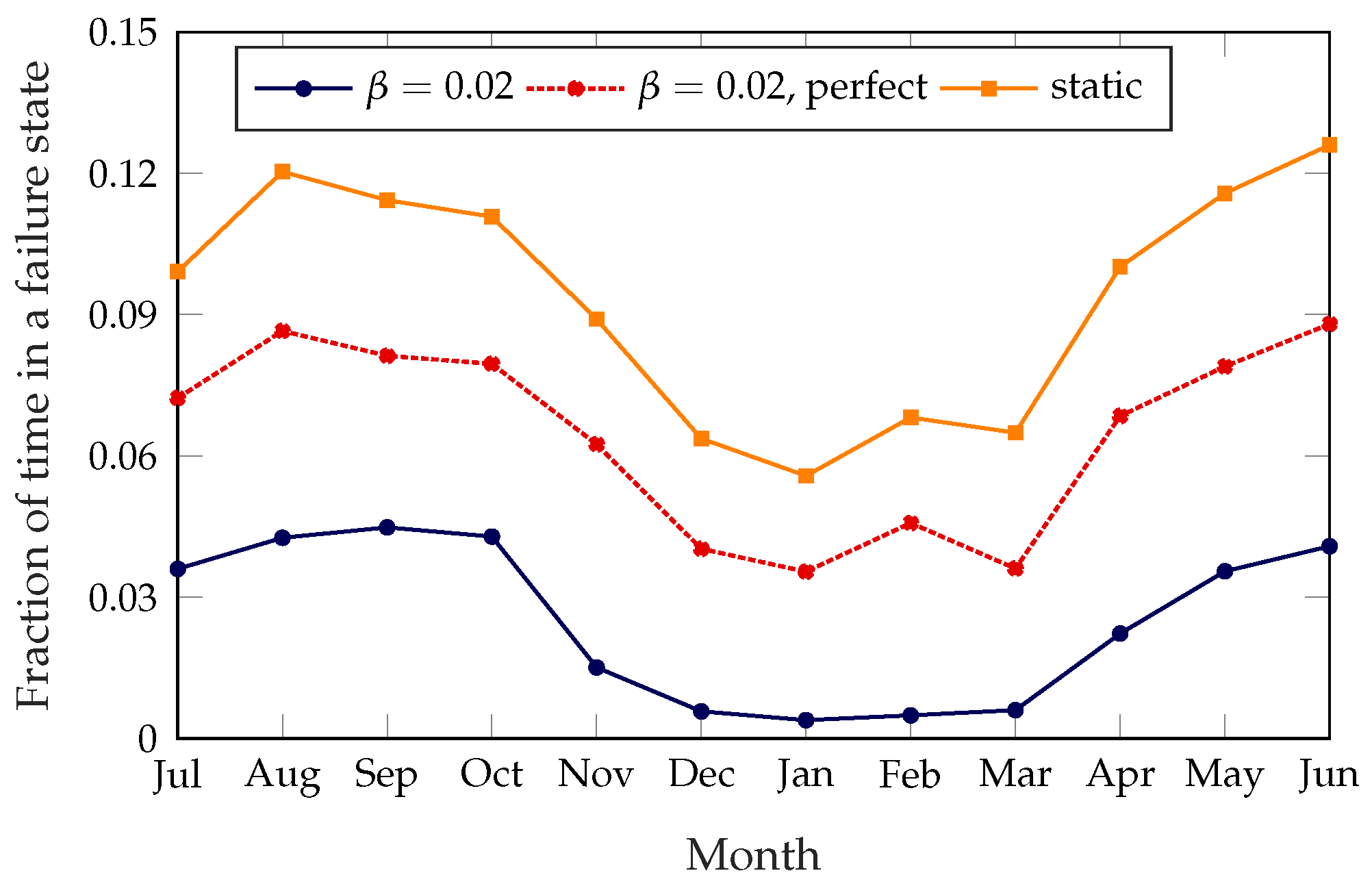
Effects of the demand estimation error. Figure 11 shows the effects of the estimation error in the demand data: we ran the simulations again, giving the system a perfect estimate of the demand for each hour, and used the performance as a benchmark. During the winter months (from November to February), the estimation error leads the system to take far more rebalancing trips (the distance covered on each trip was similar); a quick analysis of historical weather data suggests that the 2016–2017 winter was both considerably warmer and less snowy than previous years; this is the most plausible cause for the difference between the actual demand patterns and the estimates, which relied on data from previous years.
Figure 12 shows the effect that estimation errors have on the service quality. The system with perfect knowledge tends to rebalance far less because of its better knowledge of the demand; consequently, its failure rate is slightly higher (although still significantly lower than that of the static approach), but it needs half as many trips. We remind the reader that the trips taken by the dynamic systems, which do not rebalance the whole bike-sharing system at once, are far shorter than those in the static system; as such, the system with perfect knowledge gets a performance improvement over the static system while keeping the same rebalancing costs. A more aggressive setting of the
and
parameters would bring the failure rate closer to that of the imperfect information system, while presumably still limiting the rebalancing costs. An adaptive system that actively corrects the estimates based on a combination of current usage patterns, weather predictions and extraordinary events instead of relying on data from previous years would definitely improve the performance of the system. This is perfectly in line with the Smart City paradigm, which advocates a tighter integration of city services to exploit correlations in the data they generate. The remaining seasonal variations can either be accepted or smoothed out by adapting the parameters
and
to the seasonal behavior patterns of the system.
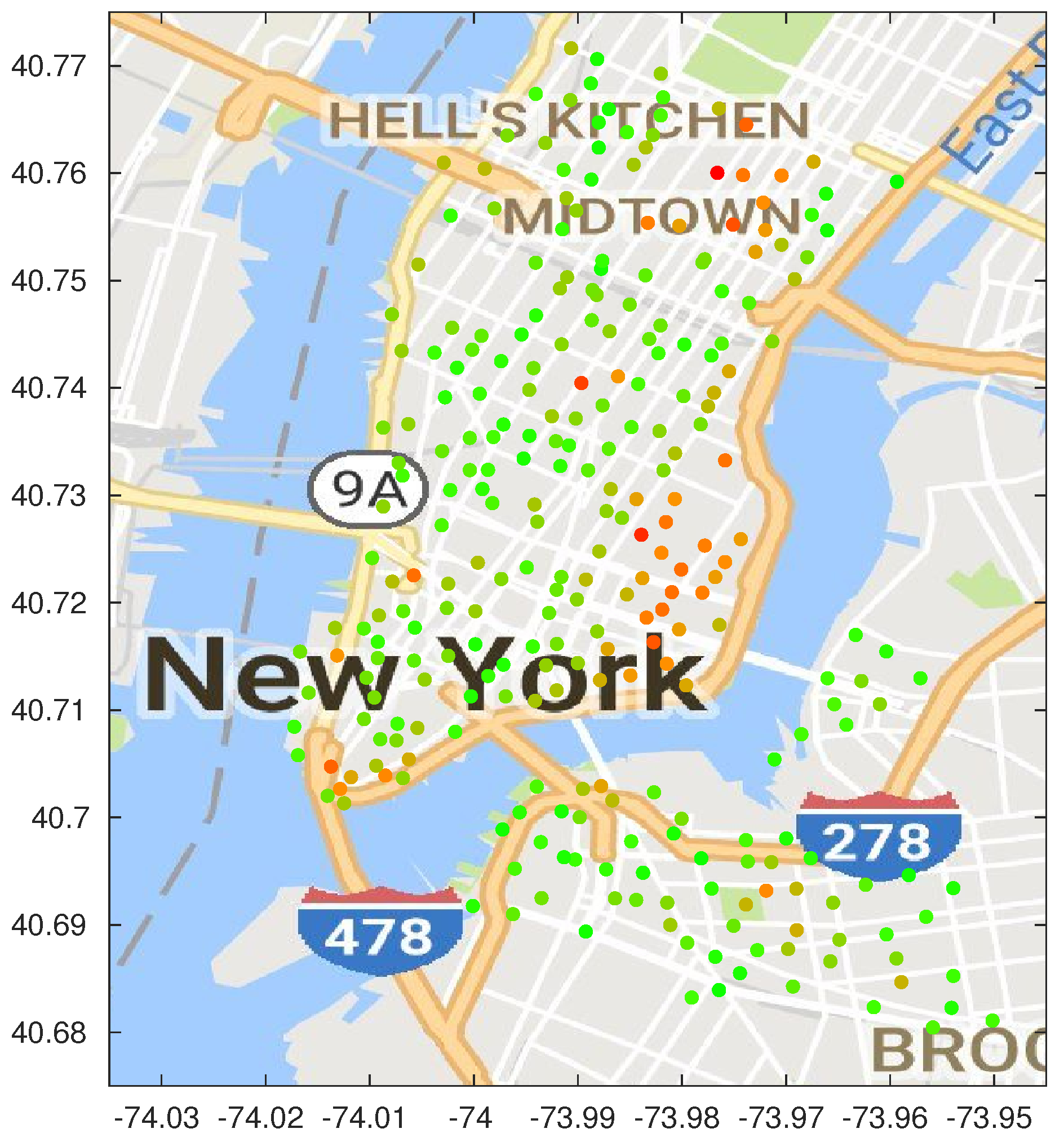
Critical stations and consequences for system planning.
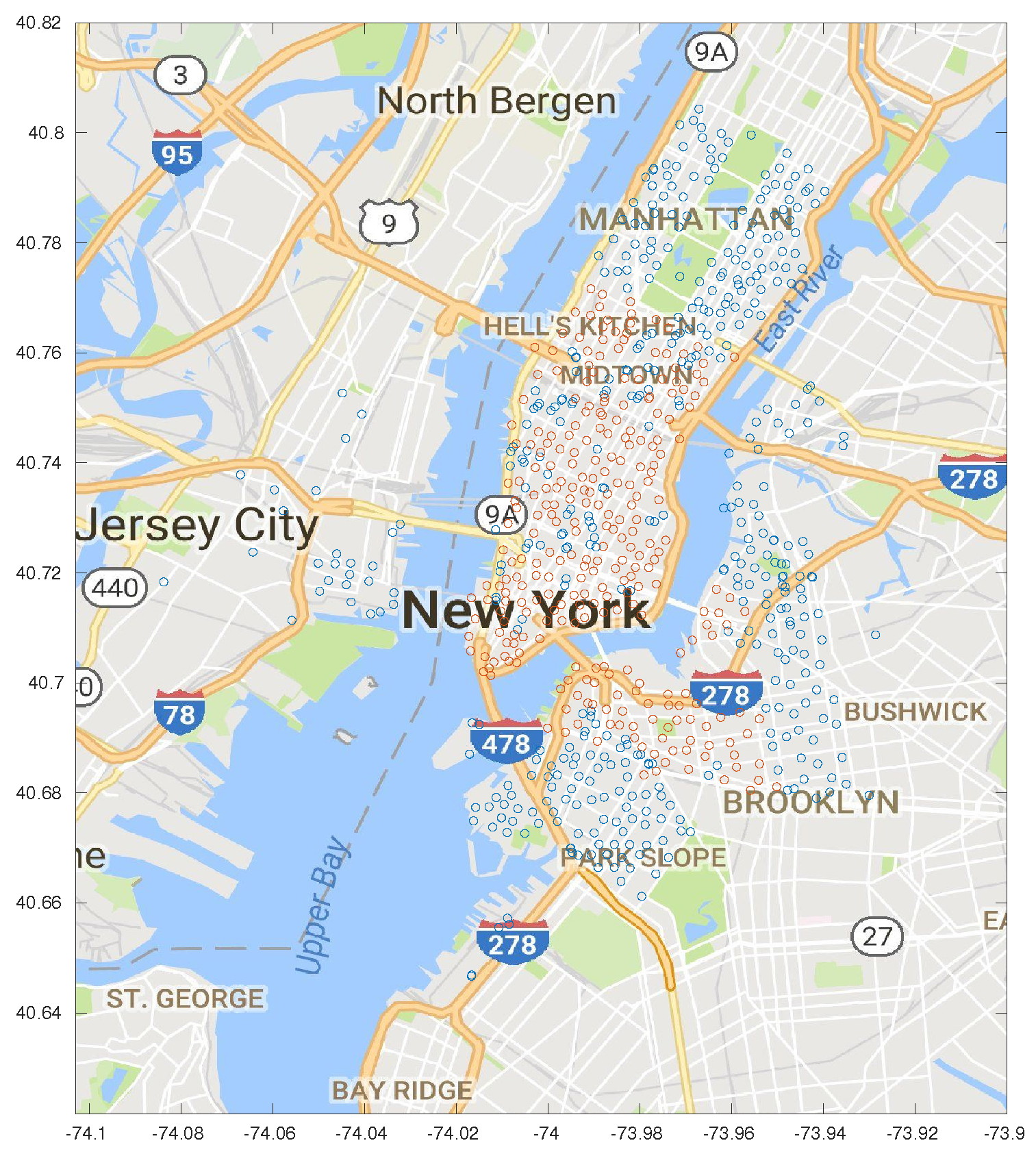
Figure 13 shows a map of the optimized stations, color-coded based on their failure rate. Green stations have a lower than average failure rate, while the orange ones have an extremely high failure rate. The only red station is the one with the highest failure rate, almost four times the average. The map clearly shows two clusters of congested stations in the Midtown and East Village neighborhoods; although the map was based on the results of the dynamic algorithm with
, the same pattern can be seen across all the considered schemes.
Although CitiBike is mostly focusing on expanding throughout Upper Manhattan and to the other boroughs, increasing either the number of stations or the capacity of the existing ones in these two congested areas would greatly increase the quality of the offered service. The presence of stations that are often empty or completely full also contributes to further skew the data from the real demand, exacerbating the censoring problem we discussed in
Section 4.1. A more thorough analysis of stations’ criticality, including time-dependent patterns and correlations with public transport schedules, would be extremely useful to improve both the bike-sharing and mass transit systems.
6. Conclusions
In this paper, we proposed a general framework for the dynamic rebalancing of a bike-sharing system, in order to improve the availability of the service, i.e., to prevent stations from becoming either completely full or completely empty. A periodical scan of the network can identify overcrowded or almost empty stations, which will not be able to support the expected bike demand without human intervention to balance the system. Bike-sharing usage is estimated by analyzing the historical data, which makes it possible to identify traffic patterns over time. In particular, we extrapolated bike arrival and departure rates for each station that depend on the hour, the day of the week, and the month. This information is used to model each bike station through a BDP. In this way, we are able to estimate the time until the station becomes either empty or full with a high probability. Rebalancing is performed if the gain obtained by reallocating bikes exceeds the cost of moving the rebalancing truck. We identify the stations to visit and a greedy rebalancing path.
The results we obtained show that the model we defined is realistic and flexible, and that a dynamic approach to rebalancing can outperform static ones and allow system controllers to decide whether to prioritize maintenance costs or service quality. The dynamic approach can also reduce the rush hour problem during the weekdays, keeping the quality of the service more stable and avoiding high failure rates during times of peak demand. The data from the system can also be used for future planning, as critical stations and areas are easy to identify. Finally, the results show that some of the issues of rebalancing systems are due to an inaccurate estimation of the demand patterns; in order to be more effective, the system should not just take into account historical data, but also current trends and weather data.
We would like to stress that, although we made some simplifications for the sake of mathematical tractability, the model we proposed is of general validity. In particular, the rebalancing optimization function of
Section 3.2 can readily accommodate different costs and rewards by appropriately tuning its parameters. Furthermore, although we specifically provided a simple heuristic to compute the rebalancing path for a single vehicle, the rebalancing algorithm (1) considers a fleet with an arbitrary number of trucks. Similarly, we focused on a scenario where the cost between two stations is independent of the link direction and is only defined by the Euclidean distance between the nodes, but our model envisages a directed graph with different costs, so as to model the presence of one-way streets or other differences in the two directed links between two stations. The simplified framework we proposed already improves the bike-sharing system, and this encourages us to relax some assumptions and adopt a more accurate model to obtain further performance enhancements. We plan to consider multiple vehicles in charge of rebalancing bikes, since in big cities it is unrealistic and probably inefficient to use a single vehicle; the trip time and the limited capacity of rebalancing trucks should also be taken into account in the optimization model. The extension to a fleet of vehicles requires that stations be grouped into almost independent clusters; then, each vehicle will perform rebalancing only within its associated cluster. This would also allow us to consider the time it takes to perform rebalancing, resulting in a more accurate modeling of the rebalancing costs. Finally, it would be interesting to model the user satisfaction and use more complex behavior patterns, e.g., users taking a bike from a nearby station if the one they choose is empty.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












