1. Introduction
Human Activity Recognition (HAR) is a research topic which has attracted an increasing amount of attention from the research community, in the wake of the development and spread of increasingly powerful and affordable mobile devices or wearable sensors. The main goal of HAR is automatic detection and recognition of activities from the analysis of data acquired by sensors. HAR finds potential applications in numerous areas, ranging from surveillance tasks for security, to assistive living and improvement of the quality of life or gaming [
1,
2].
The development of a HAR system typically follows a standardized sequence of actions involving the use of sensor engineering, data analysis and machine learning techniques.
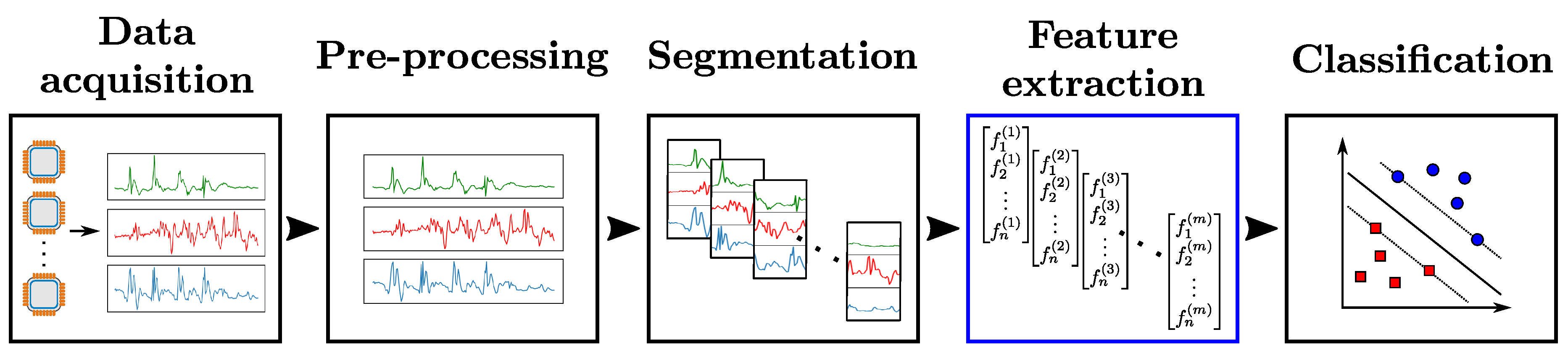
Figure 1 illustrates this process—referred to as
Activity Recognition Chain (ARC) [
3]—which comprises the following steps:
Data acquisition: Choice and setup of wearable sensors. Constraints on the choice of sensors due to the nature of activities to be recognized, or potential implementation-related issues (e.g., obstrusiveness, energy consumption, difficulty to setup on the subject, etc. [
2]) have to be taken into account at that stage.
Data pre-processing: Operations to make the data suitable for further analysis. They comprise various techniques including sensor calibration, unit conversion, normalization or cleaning of corrupted data which could be caused by possible hardware failures or problems on data transfer. In cases involving the use of several sensor modalities, the synchronization of different sensor channels also has to be considered.
Segmentation: Identification of segments which contain information about the activities to be recognized. This step serves two main purposes. It filters the data by excluding parts irrelevant to the recognition problem. Additionally, it reduces the quantity of data to be processed by the subsequent stages of the ARC by extracting segments of limited size. This last point especially matters in practice, as hardware-related constraints can limit the amount of data which are possible to process at each time step.
Feature extraction: Computation of values to abstract each segment of data into a representation relevant to the activity associated with this segment. Finding a high-level representation is important to ensure the generalization capacity of the HAR system on large-scale data.
Classification: Construction of a classifier using the extracted features. The classifier provides separations as clear as possible between different activities in the feature space, i.e., to establish rules to distinguish between the features computed on segments associated with one class and the other segments.
Experience has shown the final activity recognition performances to be very dependent on every step of the ARC. While many extensive theoretical studies have also been carried out in the past decades to establish powerful—and nowadays standardized—classification models such as Support Vector Machine (SVM) [
4] or softmax classification [
5], most of the focus has been put recently on the feature extraction stage, as the effectiveness of the classification is directly impacted by the quality of the obtained feature representation. Traditionally, features were engineered (i.e., hand-crafted) by experts with knowledge in the considered application domain. Several attempts to find effective features have in particular been done in image-processing-related fields, such as image classification [
6], image retrieval [
7] or object detection/recognition/tracking [
8]. However, this approach is not always possible in practice, for instance when the structure of the input data is unknown a priori because of a lack of expert knowledge in the domain. Additionally, there is no guarantee for features crafted manually to be optimal. For this reason, finding more systematic ways to get good features has drawn an increasing research interest [
9].
Notable progress has been done recently to find
feature learning techniques allowing models to learn automatically features from data with minimal or even no manual input. Solutions using Artificial Neural Networks (ANNs) have especially exploded in popularity in the past few years. ANNs are composed of connected non-linear computational units called artificial neurons, organized in a layer-wise structure, with each layer being composed of an ensemble of neurons. Each neuron of a layer encodes a specific feature computed on the outputs of the previous layer; a behavior particularly highlighted for image classification [
10]. Deep ANNs (i.e., composed of an input and output layers, and at least two
hidden (intermediate) layers) can craft highly abstract features by stacking hidden layers, which enables the computation of features on the low-level descriptors encoded by the first layers of the network. The ways to re-use learned features are also increased by allowing a higher number of possible connections between input and output neurons [
9]. The effectiveness of deep ANNs has been demonstrated in many fields other than image classification, such as audio and natural language processing or transfer learning, as surveyed in [
9]. Consequently, studies using deep-learning based solutions for HAR using wearable sensors have multiplied for the past few years [
11,
12,
13], all reporting state-of-the-art performances obtained on various HAR benchmark datasets.
However, despite the promising results obtained, it remains actually difficult to assess rigorously the efficiency of feature learning methods, especially deep-learning related ones. The lack of details about the pre-processing of data —sometimes even about the implementation of the feature learning process itself —can make the reproduction of the reported performances complicated. It is also difficult to compare the different approaches because of a lack of standardization regarding the ARC steps: differences in the benchmark HAR dataset(s), data pre-processing operations, segmentation techniques and parameters, or classification models are all obstacles hindering this goal.
The main contribution of this paper is to tackle both of the aforementioned issues regarding the evaluation of feature learning models for HAR. To address the first problem concerning the lack of standardized framework, we define our own evaluation framework where all stages of the ARC— except the feature extraction step—are fixed (as shown in
Figure 1), taking inspiration from the comparative study carried out for image classification in [
14]. This framework enables us to evaluate and compare the different feature learning models on a fair and objective basis. Specifically, our framework is used to perform comparative studies on two public benchmark datasets: OPPORTUNITY [
15] and UniMiB-SHAR [
16]. In addition, further experiments to assess the impact of hyper-parameters related to the data acquisition and segmentation steps of the ARC are carried out.
To address the second issue regarding the lack of implementation details, we provide all the datasets, codes and details on how to use them needed to make the reproduction of our results as easy as possible (all research materials used in our studies are provided at
http://www.pr.informatik.uni-siegen.de/en/human-activity-recognition). In addition, a generic evaluation script is made available. It can be re-used by other researchers to rigorously evaluate the performances of their own feature learning approaches on the datasets we used, in such a way that allows direct comparisons with our own results.
The comparative studies using our evaluation framework are novel, because such an analysis has in particular been missing in most survey papers of sensor-based HAR [
1,
2,
3]. More precisely, a comprehensive taxonomy of sensor-based approaches (i.e., using time series data, as opposed to vision-based ones using images and/or videos) is realized in [
1], describing past works involving the use of generative models (i.e., attempting to build a probabilistic description of the data space, such as Hidden Markov Fields (HMF), Dynamic Bayesian Networks (DBN), etc.) and discriminative models (i.e., attempting to map the input data to class labels, like SVM). Similarly, [
2] provides an overview of different discriminative techniques for HAR using wearable sensors, with a special focus on supervised and semi-supervised approaches (i.e., building models using data fully or partially labeled). Both of the aforementioned surveys however only make a list of different methods, without any comparative study being carried out in a reference evaluation framework. In [
3], the authors carried out extensive experiments to assess the effectiveness of several approaches, but only considered simple hand-crafted features and classifiers using a small self-produced dataset. To our best knowledge, no paper therefore presents a rigorous comparison of state-of-the-art feature learning approaches similar to the one done in our paper.
This paper is organized as follows. In
Section 2, we list, describe and justify our choice of the feature learning methods in our comparative study.
Section 3 presents the details of the datasets used in our comparative study, as well as the pre-processing and segmentation techniques employed on them.
Section 4 and
Section 5 detail the experimental setup and model implementation on the OPPORTUNITY and UniMiB-SHAR datasets, respectively. An analysis of the results is then performed in
Section 6. Finally,
Section 7 concludes this paper by summarizing our framework and findings.
2. Methods
This section presents succinctly the feature learning approaches selected in our comparative study. We test seven different feature crafting approaches covering most of the recent state-of-the-art ones in HAR:
Hand-crafted features (HC) comprising simple statistical metrics computed on data: this approach constitutes a baseline in our comparative study as the only manual feature crafting method.
Multi-Layer-Perceptron (MLP): the most basic type of ANN featuring fully-connected layers. The features learned by this model are obtained in a supervised way. The MLP results are used as a baseline for automatic supervised feature crafting.
Convolutional Neural Network (CNN): a class of ANN featuring convolutional layers which contain neurons performing convolution products on small patches of the input map of the layer, thus extracting features carrying information about local patterns. Apart from image processing [
17], audio recognition [
18] and natural language processing [
19], CNNs recently started to be used for time series-processing in sensor-based HAR [
11].
Long Short-Term Memory network (LSTM): one of the most successful and widespread variant of Recurrent Neural Networks which feature layers containing LSTM cells, able to store information over time in an internal memory. LSTM networks are used to capture temporal dependencies in diversified application fields such as automatic translation [
20], image captioning [
21] or video-based activity recognition [
22].
Hybrid model featuring CNN and LSTM layers: taking advantage of the high modularity of ANN-based architectures, previous studies in sensor-based HAR reported that hybrid architectures can extract features carrying information about short and long-term time dependencies, and yield better performances than pure CNNs or LSTM networks [
12].
Autoencoder (AE): a class of ANNs trained in a fully unsupervised way to learn a condensed representation which leads to the most accurate reproduction of its input data on its output layer. The results obtained by this approach are used as a baseline for unsupervised feature learning.
Codebook approach (CB): an unsupervised feature learning method based on the determination of “representative” subsequences— referred to as
codewords—of the signals used for the learning. The ensemble of codewords (
codebook) is then used to extract histogram-based features based on similarities between subsequences of the processed data and codewords. Codebook-based methods can be regarded as one-layer CNN, as codewords are learned in a similar unsupervised way to convolutional kernels. They were used in previous works for time series classification [
23] or HAR [
24].
Each of the models aforementioned is used to learn features on a training and testing datasets. To evaluate the relevance of the obtained features, we use them to train and evaluate a standard classifier common to all approaches. We decide to use a soft-margin SVM [
4] with a linear kernel. A SVM draws a classification boundary based on the margin maximization principle, so that the separation is placed in the middle between examples of two different classes. This makes the generalization error of the SVM independent of the number of dimensions. This characteristic is especially important because the approaches described above usually produce high-dimensional features. It thus makes SVM more suitable for our comparative study than other popular classifiers such as k-Nearest-Neighbours, naive Bayes or decision trees, which might face overfitting problems when confronted to high-dimensional feature vectors [
25]. A linear kernel for the SVM classifier was picked as it reduces the computational cost compared to other popular kernels such as the Radial Basis Function (RBF), which especially matters for the implementation of a real-time HAR system. In our study, the soft-margin parameter
C is adjusted to yield the highest performances for each method separately.
It should be noted that many of the feature extractors in our comparative study require a certain number of hyper-parameters (e.g., learning rate, number of hidden layers, number of units per layer, etc.) to be set. The choice of those parameters has been shown to have a high impact on the final classification performances ([
13,
26] for HAR using wearable sensors). The choice of the optimal hyper-parameters is a difficult topic, for which several strategies are possible: grid search, random search [
27] or more elaborated approaches based on Bayesian optimization [
28]. All those optimization strategies however are very time-consuming and demanding in terms of computational resources. Since the focus of our study is the comparison of feature extraction models (rather than their optimization), we use a manual search approach to determine the best hyper-parameters for each model. A more detailed description of each model and its parameters is provided in the following subsections.
2.1. Hand-Crafted Features
Hand-crafted features for time series analysis can usually be built using simple statistical values (e.g., average, standard-deviation, etc.) or more elaborated descriptors such as features related to the frequency-domain based on the Fourier transform of signals [
29]. Despite the prevalence of feature learning nowadays, manually crafting features remains a viable alternative in classification problems due to its simplicity to setup, and to its lower computational complexity.
2.2. Codebook Approach
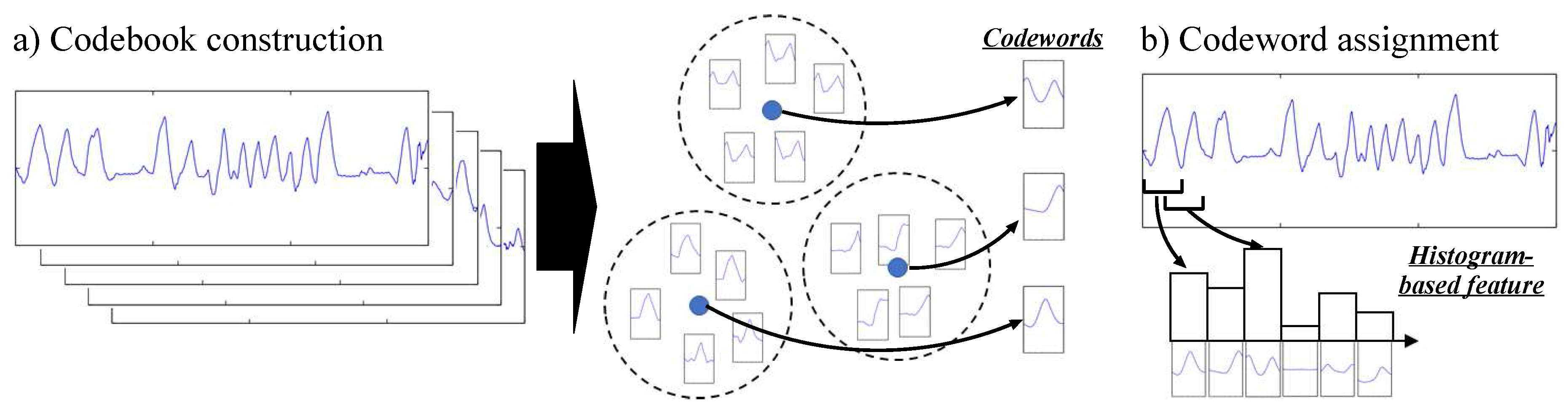
The idea behind the codebook approach is based on two consecutive steps, illustrated in
Figure 2. The first step—codebook construction—aims at building a codebook by applying a clustering algorithm on a set of subsequences extracted from the original data sequences. Each center of the clusters obtained this way is then considered as a codeword which represents a statistically distinctive subsequence. The second step—codeword assignment— consists in building a feature vector associated to a data sequence: subsequences are firstly extracted from the sequence, and each of them is assigned to the most similar codeword. Using this information, a histogram-based feature representing the distribution of codewords is then built. A detailed description of each step is provided below.
For the codebook construction step, a sliding time window approach with window size
w and sliding stride
l is firstly applied on each sequence to obtain subsequences (
w-dimensional vector). A
k-means clustering [
30] algorithm is then employed to obtain
N clusters of similar subsequences, with the Euclidean distance used as similarity metric between two subsequences. It can be noted that the outcome of
k-means clustering can be dependent on the initialization of the cluster centers, which is performed at random. We therefore run the clustering algorithm 10 times, and select the result for which the sum of the Euclidean distances between subsequences and their assigned cluster centers is minimal. At the end of this step, a codebook consisting of
N codewords is obtained.
For the codebook assignment step, subsequences are firstly extracted from a sequence using the same sliding window approach employed in the codebook construction step. For each subsequence, the most similar codeword is determined. A histogram of the frequencies of all codewords is then built, with the bin corresponding to one codeword being incremented by one each time the codeword was considered as the most similar to one of the subsequences. The histogram is finally normalized so that the sum of the N codeword frequencies yields one to obtain a probabilistic feature representation.
We refer to the approach described above as “codebook with
hard assignment” (from now on abbreviated as CBH) since each subsequence is deterministically assigned to one codeword. This approach however might lack flexibility to handle “uncertain” situations where a subsequence is similar to two or more codewords. To address this issue, we therefore use a
soft assignment variant (referred to as CBS) which performs a smooth assignment of a subsequence to multiple codewords based on kernel density estimation [
31]. Assuming that
and
are the
sth subsequence (
) in a sequence and the
codeword (
), respectively, we compute the smoothed frequency
of
as follows:
where
is the Euclidian distance between
and
, and
is its Gaussian kernel value with the smoothing parameter
. The closer
is to
(i.e., the smaller
is), the larger
becomes, or, in other words, the bigger the contribution of
to
becomes. Soft assignment allows us to obtain this way a feature which represents a smoothed distribution of codewords taking into account the similarity between all of them and subsequences. More details about the codebook approach can be found in [
24].
2.3. Artificial Neural Networks
An ANN consists of an ensemble of connected neurons, each of them taking input values , and applying a non-linear transformation —referred to as activation function—on the sum of elements of weighted by weight parameters . A bias b is added to the weighted sum to introduce flexibility by allowing the activation function to be shifted to the left or right. As a result, the output of a neuron is given by . Neurons of an ANN are grouped in layers, with outputs of neurons in one layer feeding inputs of the ones in the next layer.
ANNs are usually end-to-end models which directly use raw data and their labels to optimize output probability estimations for each class using an output layer with a softmax activation [
5]. To include our ANNs in our evaluation framework, we perform a fine-tuning operation similar to those realized in [
14,
32]. We firstly train the networks including a softmax output layer in a regular way, using a gradient descent based algorithm. We then remove the softmax layer and use the pre-trained model to compute features on both training and testing datasets. Those deep learning features are finally used to train and evaluate a SVM classifier. To check the relevance of this fine-tuning operation, we performed a preliminary experiment in the setting described in
Section 3.1. Its results showed no significant performance difference between using the fine-tuning approach and the usual one using directly the outputs of the softmax layer for the classification (The fine-tuning approach yields even slightly better results than the usual one. Specifically, the former gets an accuracy
, weighted-F1 score
and average-F1 score
, while those of the latter are
,
and
(cf.
Section 3.1 for more details on these evaluation metrics)).
Thus, a fair and appropriate performance comparison of deep-learning models can be performed by our framework based on the fine-tuning operation.
We propose to study the performances of some of the most common ANN architectures. A short description of each selected method is provided below.
2.3.1. Multi-Layer Perceptron
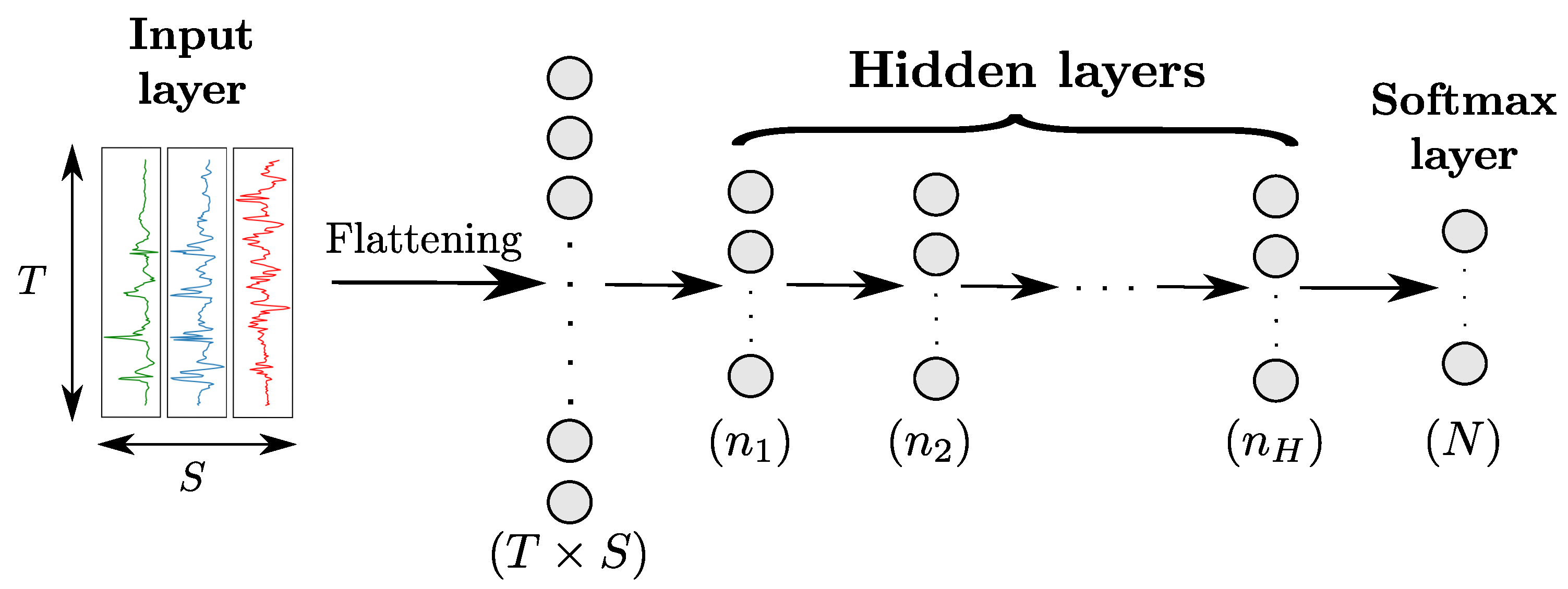
Multi-Layer-Perceptron (MLP) is the simplest class of ANN, and involves a hierarchical organisation of neurons in layers. MLPs comprise at least three fully-connected layers (also called
dense layers) including an input, one or more intermediate (hidden) and an output layer, as shown in
Figure 3. Each neuron of a fully-connected layer takes the outputs of all neurons of the previous layer as its inputs. Considering that the output values of hidden neurons represent a set of features extracted from the input of the layer they belong to, stacking layers can be seen as extracting features of an increasingly higher level of abstraction, with the neurons of the
layer outputting features computed using the ones from the
layer.
2.3.2. Convolutional Neural Networks
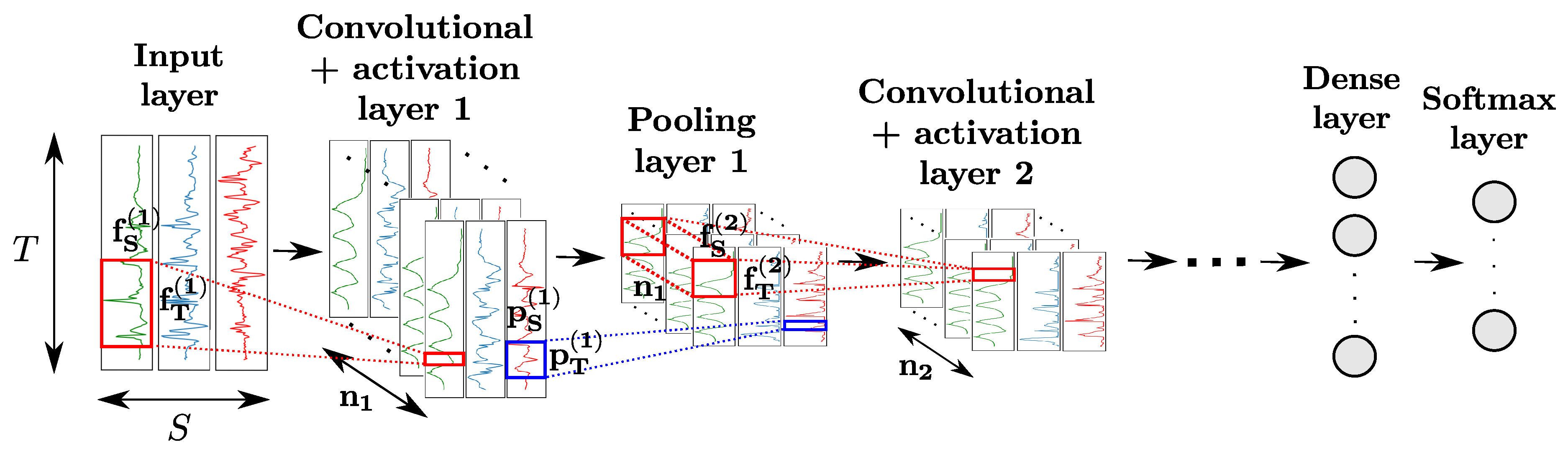
CNNs comprise convolutional layers featuring convolutional neurons. The
kth layer is composed of
neurons, each of which computes a convolutional map by sliding a convolutional kernel
over the input of the layer (indicated in red in
Figure 4). Convolutional layers are usually used in combination with activation layers, as well as pooling layers. The neurons of the latter apply a pooling function (e.g., maximum, average, etc.) operating on a patch of size
of the input map to downsample it (indicated in blue in
Figure 4), to make the features outputted by neurons more robust to variations in temporal positions of the input data. Convolution and pooling operations can either be performed on each sensor channel independently (
and/or
) or across all sensor channels (
and/or
).
Similarly to regular dense layers, convolutional-activation-pooling blocks can be stacked to craft high-level convolutional features. Neurons of stacked convolutional layers operate a convolutional product across all the convolutional maps of the previous layer. For classification purposes, a fully-connected layer after the last block can be added to perform a fusion of the information extracted from all sensor channels. The class probabilities are outputted by a softmax layer appended to the end of the network.
2.3.3. Recurrent Neural Networks and Long-Short-Term-Memory
Recurrent Neural Networks (RNNs) are a class of ANNs featuring directed cycles among the connections between neurons. This architecture makes the output of the neurons dependant on the state of the network at the previous timestamps, allowing them to memorize the information extracted from the past data. This specific behavior enables RNNs to find patterns with long-term dependencies.
In practice, RNNs are very affected by the problem of
vanishing or exploding gradient, which refers to the phenomenon happening when derivatives of the error function with respect to the network weights become either very large or close to zero during the training phase [
33]. In both cases, the weight update by the back-propagation algorithm is adversely affected. To address this issue, a variant of the standard neuron called Long-Short-Term-Memory (LSTM) cell was proposed [
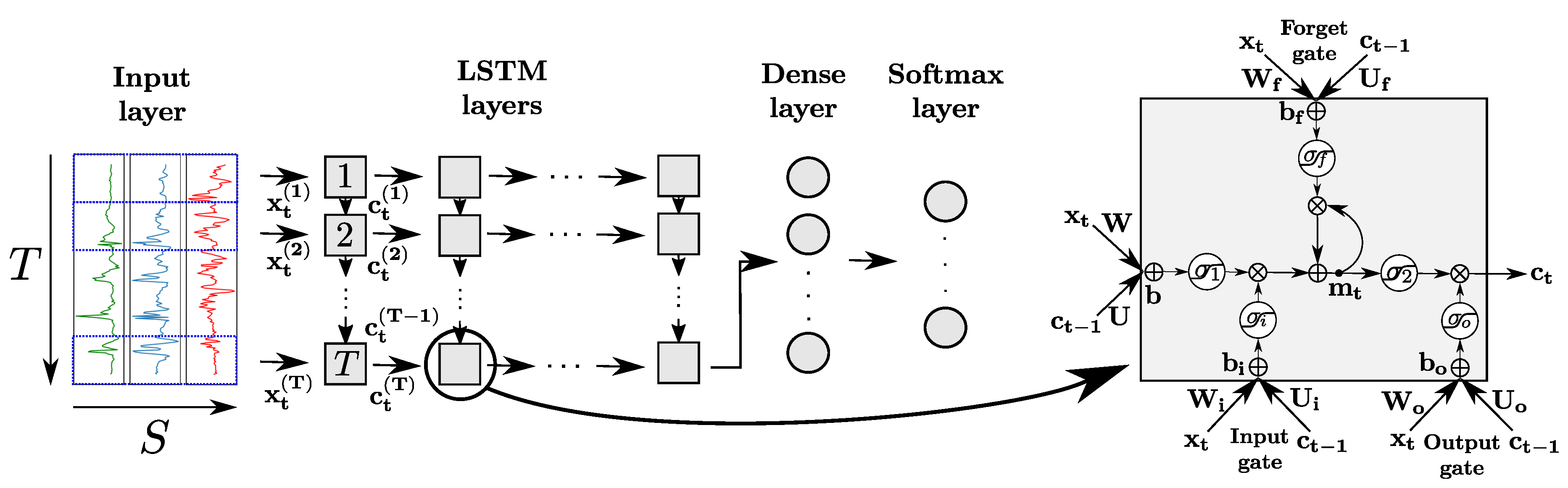
34]. The latter is designed to remember information over time by storing it in an internal memory, and update, output or erase this internal state depending on their input and the state at the previous time step. This mechanism, depicted in
Figure 5, is achieved by introducing several internal computational units called
gates, each featuring their own weights, bias, and activation functions. An input, output and forget gates are used to respectively block the input of the cell (preserving its memory
), block its output (preventing it from intervening in the computation of
), and erase its internal memory at time
t. All gates operate on the input vectors
of the cell at time
t, and the outputs of the cell at the previous time step
, following the equations
with
representing the output of gate ∗ at time
t for
(referring to input, output and forget respectively), and
indicating the memory state of the cell at time
t.
designates the activation function,
,
the matrices of weights, and
the vector of biases of the gate
.
,
and
are matrices of weights and a bias vector for the input of the cell, respectively.
and
are activation functions designed to squash the input and output of the cell, respectively. ⊗ represents the element-wise multiplication of two vectors.
Similarly to regular neurons, LSTM cells are organized in layers, with the output of each cell being fed to its successive cell in the layer and to the next layer of the network. LSTM layers can be organized following several patterns, including in particular many-to-many (the outputs of all cells of the layer are used as inputs of the next one) and many-to-one (only the output of the last cell is used as input of the next layer). The output of the last layer can be passed to a dense and softmax layers for the classification problem.
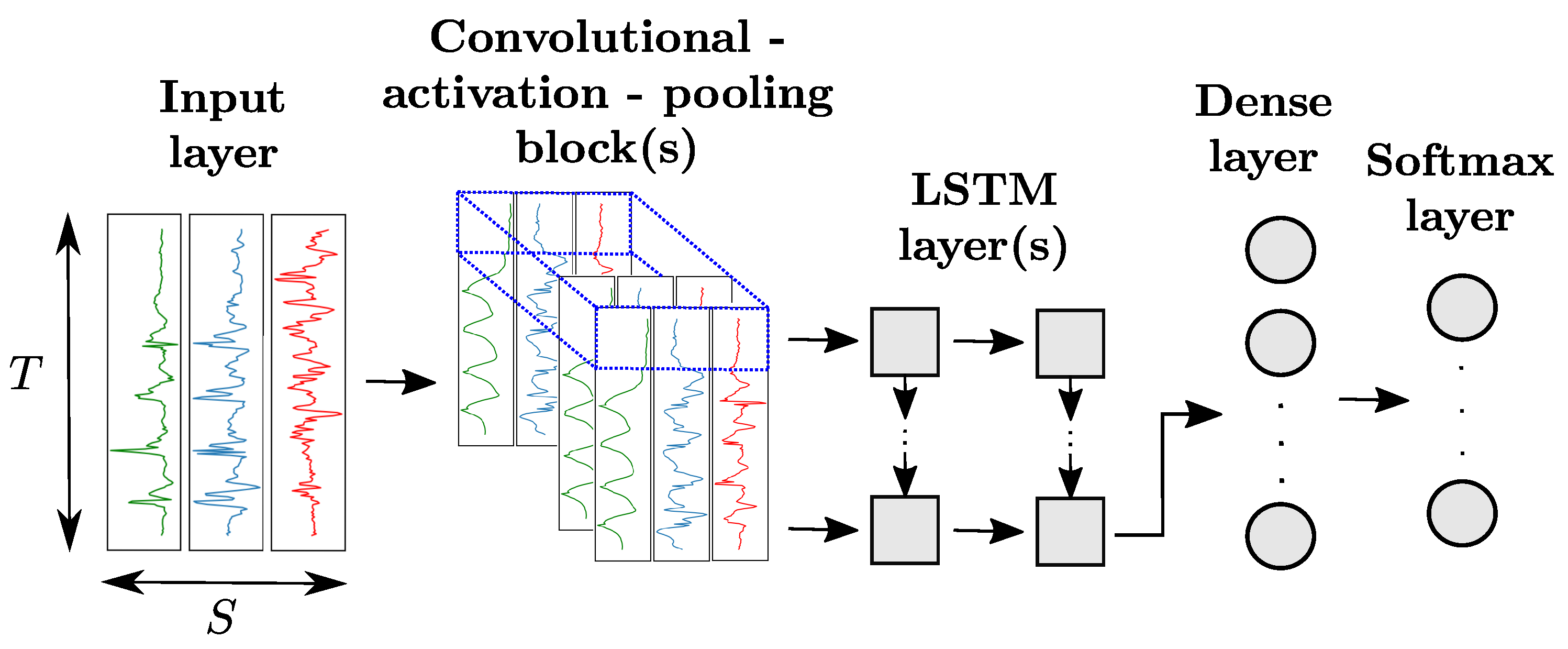
2.3.4. Hybrid Convolutional and Recurrent Networks
Thanks to the high modularity of ANN architectures, it is also possible to append LSTM layers to convolutional blocks as depicted in
Figure 6. The last convolutional block of the network produces
n-dimensional time series with
n being the number of neurons of the convolutional layer. This output is then sliced along the time dimension. Each slice, indicated in blue in
Figure 6, is flattened and fed as input of a LSTM cell. The number of LSTM cells, equal to the number of slices, is dependent on the sizes of the input data, convolutional and pooling kernels of the convolutional blocks.
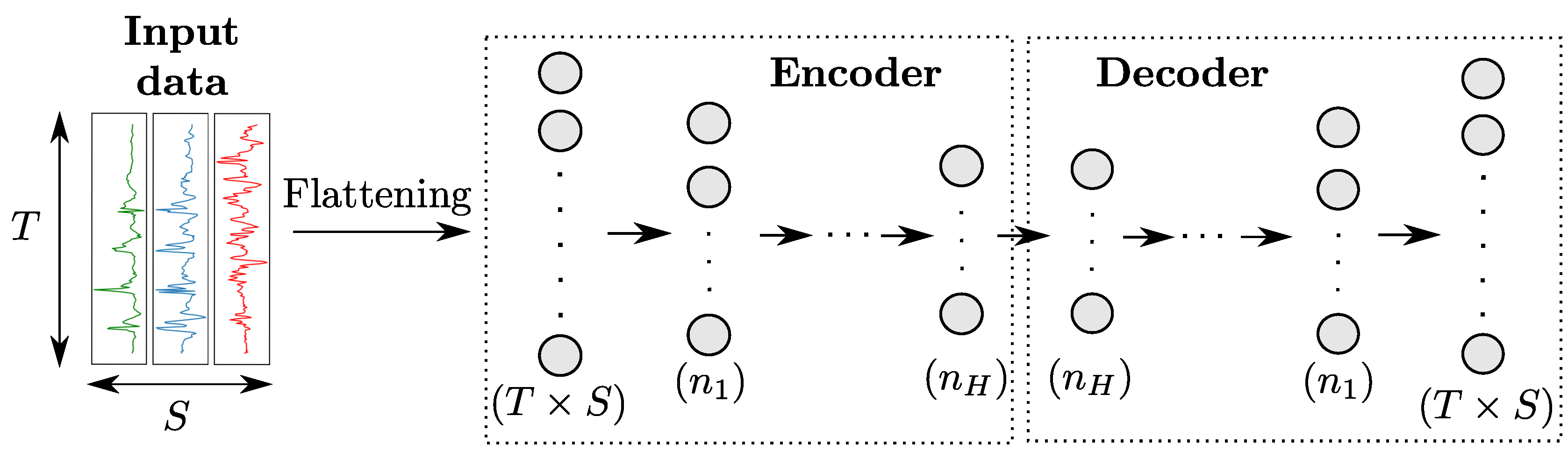
2.3.5. Autoencoders
An autoencoder (AE) [
35] uses a specific architecture consisting in the concatenation of an
encoder and a
decoder, as shown in
Figure 7. The encoder is a regular network that projects input data in a feature space of lower dimension, while the decoder—whose structure is usually the symmetric of the encoder one—maps the encoded features back to the input space. The AE is then trained to reproduce input data on its output based on a loss function like Mean Squared Errors.
5. Comparative Study on UniMiB-SHAR
This section presents the implementation details of the different feature learning approaches, and the results of their comparative study on the UniMiB-SHAR dataset.
5.1. Implementation Details of the Feature Extraction Models
Most of the feature learning approaches (models and training algorithm) employed on the UniMiB-SHAR data remained unchanged compared to those used on the OPPORTUNITY dataset (cf.
Section 4.1 for details). The only changes concerned model hyper-parameters. Concerning deep-learning-based models, we found that cross-sensor convolutions improve the classification results (unlike on the OPPORTUNITY dataset). For both CNN and Hybrid, we thus used only one convolutional block, with the convolutional layer performing a cross-sensor convolution. The full list of hyper-parameters is provided in
Table 8.
For CB, one codebook is constructed by clustering three-dimensional subsequences to consider correlations among different dimensions. In other words, the codebook construction and codeword assignment steps are carried out by regarding each subsequence as a -dimensional vector (no other modification is needed). Regarding the hyper-parameter setting, l is set to 1 for dense sampling of subsequences, and the other hyper-parameters are determined as follows: w is fixed to 16 based on preliminary tests using , and is chosen by examining . Because of the high computational cost, a codebook is constructed by applying the k-means clustering to one million subsequences randomly selected. For the soft assignment approach, is set to 4 by testing .
5.2. Results
We perform a 30-fold Leave-One-Subject-Out cross validation on the UniMiB-SHAR dataset by using the data from one subject for testing, from the others for training, and then repeating the process for all of the 30 subjects (Because of the high computational cost of CBH and CBS, only one codebook is constructed using subsequences collected from all 30 subjects, and then used to build features on all folds. Subsequences of test subjects are thus also used for the training on each fold, which might slightly skew CB performances. However, experiments on a simple training/testing partition (20 first subjects/10 last subjects, respectively) presented in
Section 6 showed that using completely distinct datasets for the codebook construction and evaluation does not change the relative performances of CBS and Hybrid.) The final performance metrics are the average of those obtained for each subject. The results are provided in
Table 9. For a baseline comparison, we also add the results obtained by the authors of [
16] who directly used the data contained in the time windows as inputs of the classifier (i.e., no feature extraction).
The codebook approach with soft-assignments yields the highest accuracy and weighted F1-score at and respectively, while the the best average F1-score is obtained by CNN at . Overall, CBS, CNN and Hybrid yield sensibly better performances than the other feature extraction methods. We think that this might in part be caused by the specific segmentation technique employed on this dataset: since data frames are exclusively centered around peaks of inputs signals, local features characterizing the shape of the peaks—typically obtained by codebook approaches and ANNs containing convolutional layers—carry a high relevance to the classification problem. The lack of temporal consistency between the different data frames or the absence of frames characterizing transitions between different actions might explain the relatively poor performances displayed by the LSTM architecture.
6. Analysis
The results obtained on both datasets highlight three points: the superiority of automatically learned features over hand-crafted ones, the stability of hybrid CNN-LSTM architectures which are able to obtain top performing features on both datasets, and the relevance of the codebook approach with soft-assignment to some specific setups.
If the bad results obtained by hand-crafted features compared to the other feature learning approaches are not unexpected, the gap in their relative performances displayed on both datasets is more surprising: the difference between their average F1-score and the one of the best performing method is
on OPPORTUNITY, and
on UniMiB-SHAR. To investigate this, we applied a feature selection method [
41] to determine which features are the most relevant to the classification problem. On OPPORTUNITY, we found out that the best features are acquired by sensors placed on the feet of the subjects. We believe this is mainly due to the fact that the dominant NULL class on OPPORTUNITY mainly comprises transitions of the subjects between two different locations of the experimental environment, whereas the others ADLs featured in the dataset do not involve any significant movement of the lower part of the body. Sensors placed on the feet of the subjects and their associated features would then be effective to distinguish the NULL class from the others. On the other hand, the lack of dominant class coupled to the specific peak shape of the signals explains the low performance on the UniMiB-SHAR dataset, as well as its inferiority to the baseline raw data approach.
One interesting observation is the dependence of the performances of deep-learning models on the segmentation phase. Depending on whether the latter is sliding-window-based (e.g., OPPORTUNITY) or energy-based (e.g., UniMiB-SHAR), the type of data frames varies, thus impacting the type of predominant features for the classification. Features characterizing the shape of the time signals— which are typically obtained by convolution-based networks—perform well in the case of an energy-based segmentation, whereas a sliding window segmentation approach makes the memorization of previous data frames more relevant and the LSTM-based architectures more relevant. It can be noted that the hybrid CNN and LSTM model still ranks among the most efficient methods on UniMiB-SHAR, which highlights the stability of this model, and suggests its good generalization capacity on different datasets.
The good performances of CBS on the UniMiB-SHAR dataset is another indicator of the effectiveness of low-level shape-based features in the case of an energy-based segmentation. As we found out that the codebook and deep-learning-based approaches produce different features which yield significantly different results, we expect their fusion to take advantage of this “diversity” and lead to performance improvements [
42]. We thus carry out tests on both OPPORTUNITY and UniMiB-SHAR datasets. For this experiment, the UniMiB-SHAR dataset was partitioned using the 20 first and 10 last subjects for the training and testing of our models, respectively and both partitions were used to obtain features using the codebook and hybrid CNN and LSTM. We then perform the fusion by simply averaging the output scores of two SVMs, each trained with one type of features, and using the resulting scores for the class prediction. This kind of simple “late fusion” already proved its effectiveness to improve the performances of deep-learning-based approaches in previous works for video annotation [
43].
Table 10 shows a sensible performance improvement by the fusion approach compared to the ones using either codebook or ANN features exclusively on both datasets.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}