GreenVMAS is an Ambient Intelligence Organization based MAS whose purpose is to make greenhouses more profitable by recycling waste energy from power plants. First, the deployed infrastructure and the system architecture will be defined, then the AI techniques employed by the system and user software application will be described.
3.1. Infrastructure
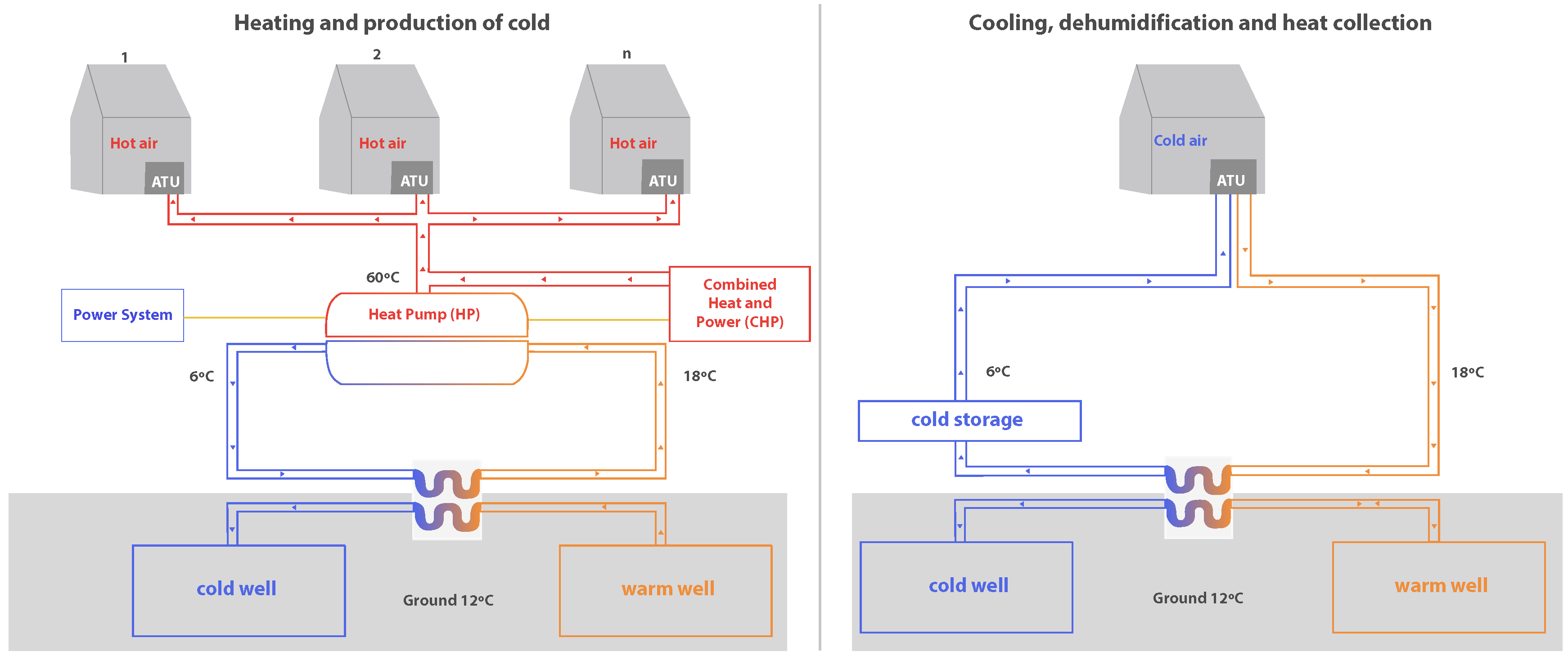
GreenVMAS reuses waste energy (hot water) from power plants to heat greenhouses, its subsystems and its connections are presented in this subsection.
Sensors required by the system are deployed in this infrastructure in order to distribute the energy in an efficient way, considering the greenhouse’s requirements which are defined by the farmer through the software described in
Section 3.4.
Figure 1 shows a diagram of the infrastructure for both the heating system and the cooling system. The main novelty of this work is shown in the heating and production of cold system. The waste energy generated by the power plant is transformed into hot water and electric power thanks to a Combined Heat and Power (CHP) module.
The generated electrical energy powers the electric Heat Pump (HP), which heats the water and distributes it to each Air Transfer Unit (ATU). The HP is also backed-up with a traditional power grid system and a photovoltaic system, which supply energy to the HP at times when the CHP is not able to fully satisfy the energy needs.
In addition to the feed, the HP receives warm water from the corresponding water tank that uses geothermal techniques to maintain its temperature at approximately 18 °C. The HP causes the temperature of the water to rise to 60 °C and this output current is mixed with the hot water current coming from the CHP, which is also at a temperature of 60 °C. As a result of the operation of the electric HP, a cold water current is also produced as an output, it is approximately 6 °C and will rise to 18 °C in the geothermal circuit which it follows to once again be the input of the HP. When the water reaches 60 °C, it is distributed to the greenhouses. The hot water first goes to the ATU where it is converted into hot air, used to maintain the target temperature in each greenhouse.
When the climatic circumstances require the addition of cold and not hot air, the circuit that is used is the one shown on the right-hand side of
Figure 1. In this case, waste energy is not recovered (neither CHP nor HP are used), instead a basic geothermal system is used which is not described in this article, nor evaluated in the case studies presented below.
3.2. GreenVMAS Architecture
The deployed infrastructure contains valuable information inside it, this information has to be extracted in order to recycle waste energy efficiently. A heterogeneous sensor network is deployed to have a detailed view of the processes (CHP, Cold Water Tank, Hot Water Tank, Solar harmonic, ATU) that occur within the system and take the appropriate actions.
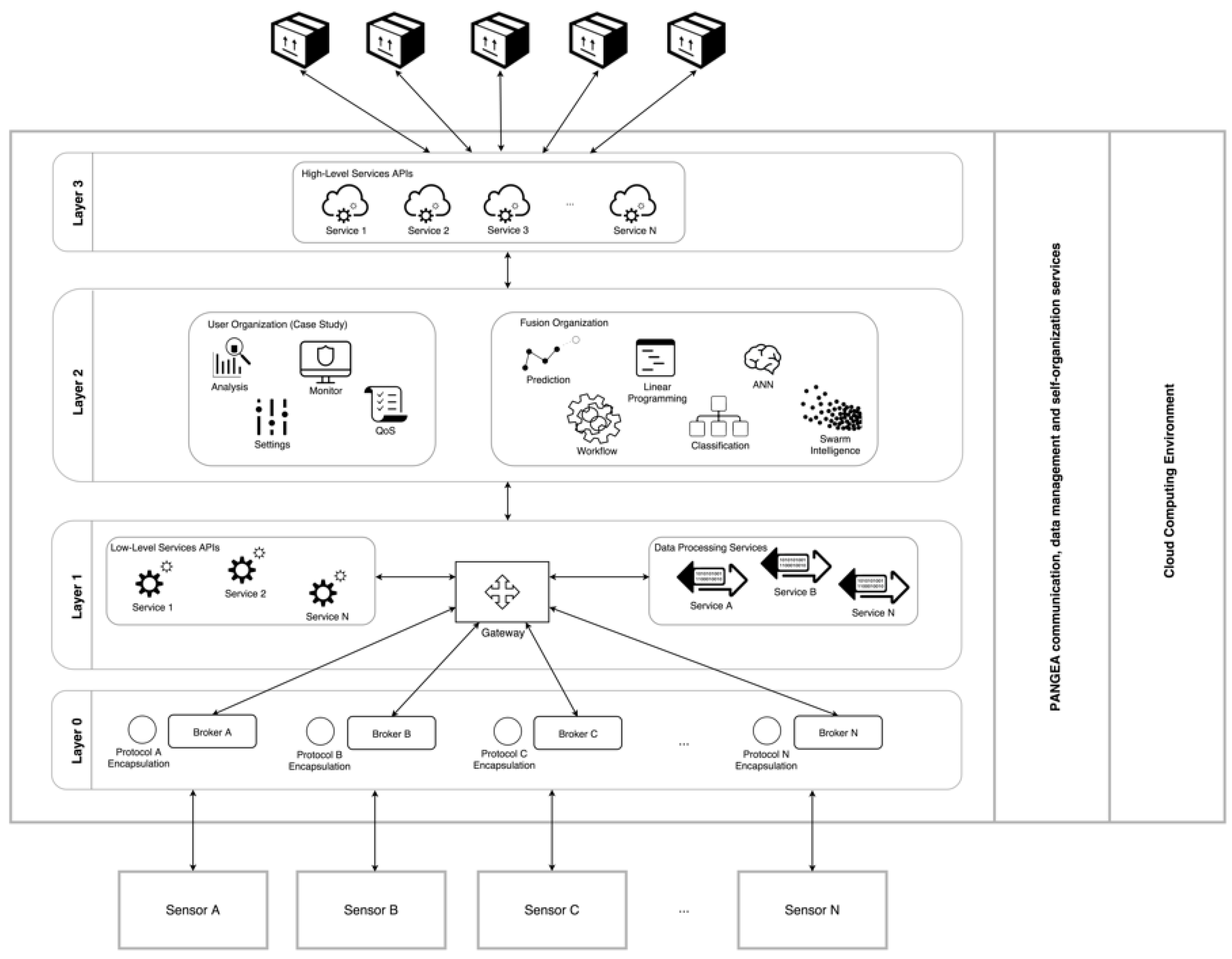
Data generated by the sensor layer are sent to the platform where they are processed as explained in
Figure 2. The figure shows the different layers that make up the system. Information flows vertically in both directions. Two big modules that support the platform are shown on the right hand-side: PANGEA and the Cloud Computing (CC) environment.
The intelligent part of the system is responsible for achieving the desired results. This intelligent part is based on a VO MAS which is implemented in the software platform using the PANGEA framework, as presented in
Figure 2. PANGEA consists of a multi-agent platform, it provides self-organization capacities through the management of an agent based VO. A complete description of PANGEA can be found in [
9]. It runs on a CC environment based on OpenStack, so the storage and resources it provides are sufficient for executing the functionalities of the software platform.
This platform consist of four layers, which have a two-way relationship and are developed according to the classification of the Join Directors of Laboratories (JDL) fusion model [
40]. The modular architecture of the system has two main advantages: (i) it allows to decouple the different functional parts, in this way the changes in one module do not affect the rest of the modules; (ii) modules that perform the same functionalities but use different approaches can be exchanged (e.g., two modules can apply a different methodology or different information transmission technologies to solve the same issue). Thanks to this, it is possible to execute modules according to the requirements of different stages. In addition, these modules can be executed in parallel and only the best results offered by either of the modules are considered.
Layer 0 is on the bottom of the system, its features make the system an open platform that facilitates the dynamic integration of new sensors and communication technologies. This layer acts as a broker that defines communication with multiple networks of different natures (BLE, ZigBee, Wi-Fi, 6LoWPAN, etc.) and obtains raw data from sensor networks. The process followed in Layer 0 corresponds to Level 0, “Data Assessment” of the JDL model.
Layer 1 corresponds to Level 1 of the JDL model. It is responsible for offering low-level services. The main actor in this layer is the Gateway, it processes the contextual information that Layer 0 provides to Layer 1. The Gateway allows upper and lower layers to communicate with each other by sending and receiving requests (messages) in both directions. Inside this layer, there are two VOs: one in charge of providing low-level services and the other of data processing services. When raw data are obtained, the Gateway uses adapters from the VOs to standardize the received information. The services it provides are normalization, signal filtering or other processing services. To enable this, service adapters include algorithms. An API allows upper and lower layers to interact.
Layer 2 is connected to information fusion Levels 2–4 in the JDL model. Here, the platform is structured as a MAS and it is based on a VO. Every organization performs different tasks which allow to manage the information gathered at lower levels in an intelligent way. The MAS incorporates a series of agents that have been specifically designed to interact with the low-level services provided by Layer 1. Additionally, the design of several intelligent agents specialized in information fusion are included. The cognitive part of the system is found in this layer. Two VOs represent this layer in the MAS: The user organization (directly related to the case study) and the fusion organization. The first organization contains different agents that ensure the system operates correctly, that must follow specified settings or quality parameters. The information fusion organization is the intelligent part of the system, it implements two artificial intelligence techniques: a Case-Based Reasoning (CBR) system and ANN. They allow the system to achieve its aims and will be described in more detail later in the article. These artificial intelligence techniques calculate parameters like the heat transfer coefficient of the walls of the greenhouse and the soil or the density of air and water, therefore the system does not have to perform these calculations. Parameters that affected the use case and which have been considered in the study are: solar radiation (W/m−2), relative humidity (%), humidity ratio ([kg/kgDA] ∗ 10−5), indoor air temperature (°C), outdoor air temperature (°C), cultivation area (m2), average height of the greenhouse, specific heat of water at the ATU input, and volume of water in heating pipes and tanks.
Finally, layer 3 is the top part of the software architecture. It is represented in the MAS by a VO that includes different high level services. These services can be accessed by the proposed control applications or even by third party applications. The VO includes different agents providing secure real time services. For example, energy efficiency services are used by interactive data analytics applications. Some of the services included in this layer offer input points that allow to setup the sensor architecture, configure the settings of every greenhouse or define energy distribution patterns. Layer 3 is connected to Level 5 and Level 6 of the JDL model and it provides one module that allows to manage and customize end user services.
3.3. CBR and ANN for Estimating Greenhouse Energy Requirements
To distribute the recovered energy efficiently and equitably, it is necessary to estimate the amount of energy that each greenhouse requires for proper crop growth. In the case study, the energy requirements of the greenhouses were estimated in order to maintain their indoor temperature as close as possible to the target temperature. These estimates were made in 15-min time intervals. To determine the most influential parameters, the correlation analysis and Kruskal–Wallis [
41] methods were used. The Kruskal–Wallis method is used to test if a dataset originates from the same distribution, determining the dependency between the variable that is being studied and the rest of the variables.
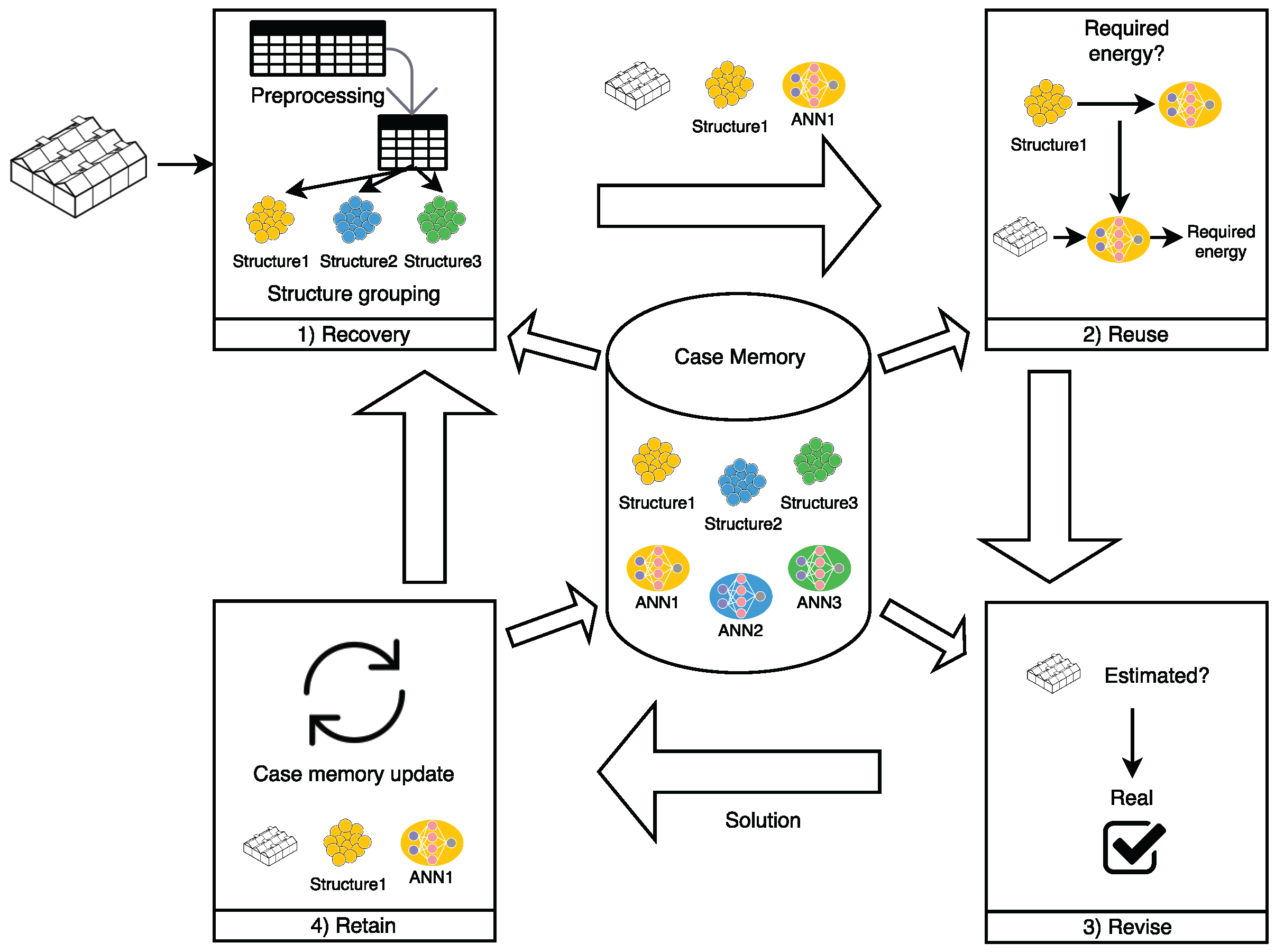
Once the most influential parameters are determined, the CBR agent estimates the energy requirements, as shown in
Figure 3. The case memory is grouped by the type of the greenhouses’ architectural structure. In the present case study, there were three types of structures, so there were three separate clusters in the case report. In these three clusters, the case base was organized to include the following in every case: target temperature (
), outdoor temperature (
), (initial) indoor temperature (
), solar radiation (
), relative humidity (
h), humidity ratio (
), ventilation (
v), current weather station (
s) and the amount of energy needed to change the (initial) indoor temperature to target temperature (
e).
The developed system is to be applied in multiple scenarios. Since CBR systems are based directly on historical data [
42], it is necessary to include a mechanism that will allow the CBR system used in this work to adapt to any context. To this end, an ANN is incorporated. Every cluster has a trained MLP where the inputs are target temperature (
), outdoor temperature (
), (initial) indoor temperature (
), solar radiation (
), relative humidity (
h), humidity ratio (
), ventilation (
v), current weather station (
s) and the architectural structure of the greenhouse (
g), and the output is the prediction of the amount of energy (kWh) required to change the (initial) indoor temperature to target temperature (
). Thus, prediction is also part of the cases. Every case
i includes the trained ANN for greenhouse type (
) in addition to the required information, following the structure defined in Equation (
1).
In the recovery phase, the system recovers the trained ANN associated with the structure of the corresponding greenhouse which contains previous cases. In the reuse phase, the network is used to generate the prediction. Finally, the data and training are updated in the revise phase, once the target temperature has been reached and the required amount of energy is known.
The ANN is trained periodically, both manually and automatically. Manual training involves the use of a graphic user interface which facilitates the process. Automatic training, on the other hand, involves including a defined number of new cases in the system. In manual training, the evolution of error is analyzed with a set of training data (70% of data are used for training and 30% are used for testing). When the error starts to reduce at a slower rate, the ANN is validated with the test data. As the training continues, the error produced in the test data reduces.
The ANN configuration is as follows: nine neurons in the input layer, one neuron in the output layer. In the middle layer
neurons are placed where
n is the number of neurons in the input layer. This criterion is based on Kolmogorov’s theorem [
43], so 19 neurons are used in the hidden layer. The activation function is the sigmoid, which is defined according to the expression shown in Equation (
2).
Concretely, , it is necessary to define the functions which allow to update the bias and the weights of the neural network layers.
Weight updating for the weights that join the middle layer with the output layer, is defined in Equation (
3) [
29].
where:
is the weight between the hidden layer’s neuron
j and the output layer’s neuron
k,
is the pattern output value
p for the output layer’s neuron
k,
is the learning rate, generally
,
is the near-zero moment, for example
,
is the output value of the output layer’s neuron
k,
is the output value of the hidden layer’s neuron
j.
Weight updating for the
bias (
) associated with the neurons in the output layer, is defined in Equation (
4).
where:
is the
bias associated with the output layer’s neuron
k.
Weight updating for the weights that join the input layer with the middle layer is defined in Equation (
5).
where:
is the weight between neuron
i in the output layer and neuron
j in the hidden layer,
is the input value for neuron
i.
The update in series for the
bias associated with the middle layer neurons is defined in Equation (
6)
where:
is the
bias of neuron
j in the hidden layer.
Once the energy requirements of each greenhouse within the system are estimated, equitable distribution is ensured by assessing overall energy needs.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}