1. Introduction
Contour points acquired by active sensors using sonar, radar or LiDAR [
1], or extracted from image data [
2,
3], are a key source of information for mobile robots in order to detect obstacles or to localize themselves in known or unknown environments [
4,
5]. For this purpose, often, geometric features are extracted from raw data since in contrast to detailed contours, features are uniquely described just by a limited set of parameters, and their extraction works as additional filtering in order to improve reliability when dealing with sensor noise and masking [
6]. However, the performance of feature-based localization or SLAM strongly depends on exact the determination of a feature vector
y from measured raw data. Moreover, especially for data association, as well as for sensor fusing, not only the feature parameters are needed, but also a reliable estimation of their uncertainty is required. Generally, in the case of non-linear multi-sensor fusing, likelihood-based models can be applied (see [
7]), which employ Bayesian filtering [
8] or the calculation of entropies [
9] to quantify uncertain information. Alternatively, especially for localization and map building, sensor fusing often is achieved with a Kalman filter (EKF). For this purpose, the covariance matrix
R is required, which encapsulates the variances of the single elements in
y and their dependencies.
This will be obvious if one looks at the standard algorithm for updating an estimated system state
typically by means of EKF; compare [
10,
11,
12]: new measurements
y are plausible if their deviations from expected measurements
dependent on the in general non-linear measurement model
are within a limited range. For exact calculation of this limit, usually the Mahalanobis metric is applied (see [
11,
13]), which considers the covariance matrix
S of the innovation
with
dependent on
R, the covariance matrix
of the system state and using
. A new measurement
y will be considered to relate to an already known feature vector
if its distance is below a given threshold
with
. Only in this case, the system state vector
can be updated by means of
using the Kalman gain
, again depending on the covariance matrix
R of the measurements, while otherwise
and
are expanded by the new feature.
Thus, for reliable map building, errors in the step of data association should be strictly avoided by means of exact knowledge of the covariance matrix at each measurement, since otherwise, multiple versions of certain features would be included in the map, while other features erroneously are ignored.
Particularly in artificial environments, straight lines in a plane are frequently used as features, since these are defined by just two parameters and can be clearly and uniquely determined. In contrast to point features, lines in images are almost independent of illumination and perspective, and a number of measurements can be taken along their length to localize them accurately and to distinguish them from artifacts [
14]. Moreover, already, a single line enables a robot to determine its orientation and perpendicular distance, which clearly improves localization accuracy. Thus, many tracking systems have been proposed based on line features, either using range-bearing scans [
15,
16] or applying visual servoing (see [
17,
18]), and also, recently, this approach has been successfully implemented [
19,
20,
21]. However, due to missing knowledge of the covariance matrix, for data association, often, suboptimal solutions like the Euclidean distance in Hough space [
15] or other heuristics are used [
22].
Obviously, fitting data to a straight line is a well-known technique, addressed in a large number of papers [
23,
24,
25] and textbooks [
26,
27,
28]. In [
29], a recent overview of algorithms in this field is outlined. As shown in [
30,
31], if linear regression is applied to data with uncertainties in the
x- and
y-direction, always both coordinates must be considered as random variables. In [
32], Arras and Siegwart suggest an error model for range-bearing sensors including a covariance matrix, affected exclusively by noise in the radial direction. Pfister et al. introduce weights into the regression algorithm in order to determine the planar displacement of a robot from range-bearing scans [
33]. In [
34], a maximum likelihood approach is used to formulate a general strategy for estimating the best fitted line from a set of non-uniformly-weighted range measurements. Furthermore, merging of lines and approximating the covariance matrix from an iterative approach is considered. In [
30], Krystek and Anton point out that the weighting factors of the single measurements depend on the orientation of a line, which therefore can only be determined numerically. This concept has been later extended to the general case with covariances existing between the coordinates of each data point [
35].
Since linear regression is sensitive with respect to outliers, split-and-merge algorithms must be applied in advance, if a contour consists of several parts; see [
36,
37]. In cases of strong interference, straight lines can still be identified by Hough-transformation (compare [
38,
39,
40]), or alternatively, RANSAC algorithms can be applied; see [
41,
42]. Although these algorithms work reliably, exact determination of line parameters and estimating their uncertainties still requires linear regression [
43].
In spite of a variety of contributions in this field, a straightforward, yet accurate algorithm for determining the covariance matrix of lines reliably, quickly and independently of the a priori mostly unknown measurement noise is missing. In
Section 4, such a model in closed-form is proposed depending on just a few clearly-interpretable and easily-obtainable parameters. Besides its low complexity and great clarity, the main advantage of the covariance matrix in closed form results from the fact that it can be calculated from the same data points as used for line fitting without the need to provide additional reliability information of the measurements, which in many cases is not available.
Beforehand, in the next two paragraphs, existing methods for the linear regression and calculation of the covariance matrix are reviewed with certain extensions focusing on the usage of range-bearing sensors, which cause strong covariances between the
x- and
y-coordinates. Based on these theoretical foundations,
Section 5 exhibits detailed simulation results in order to compare the precision and robustness of the presented algorithms.
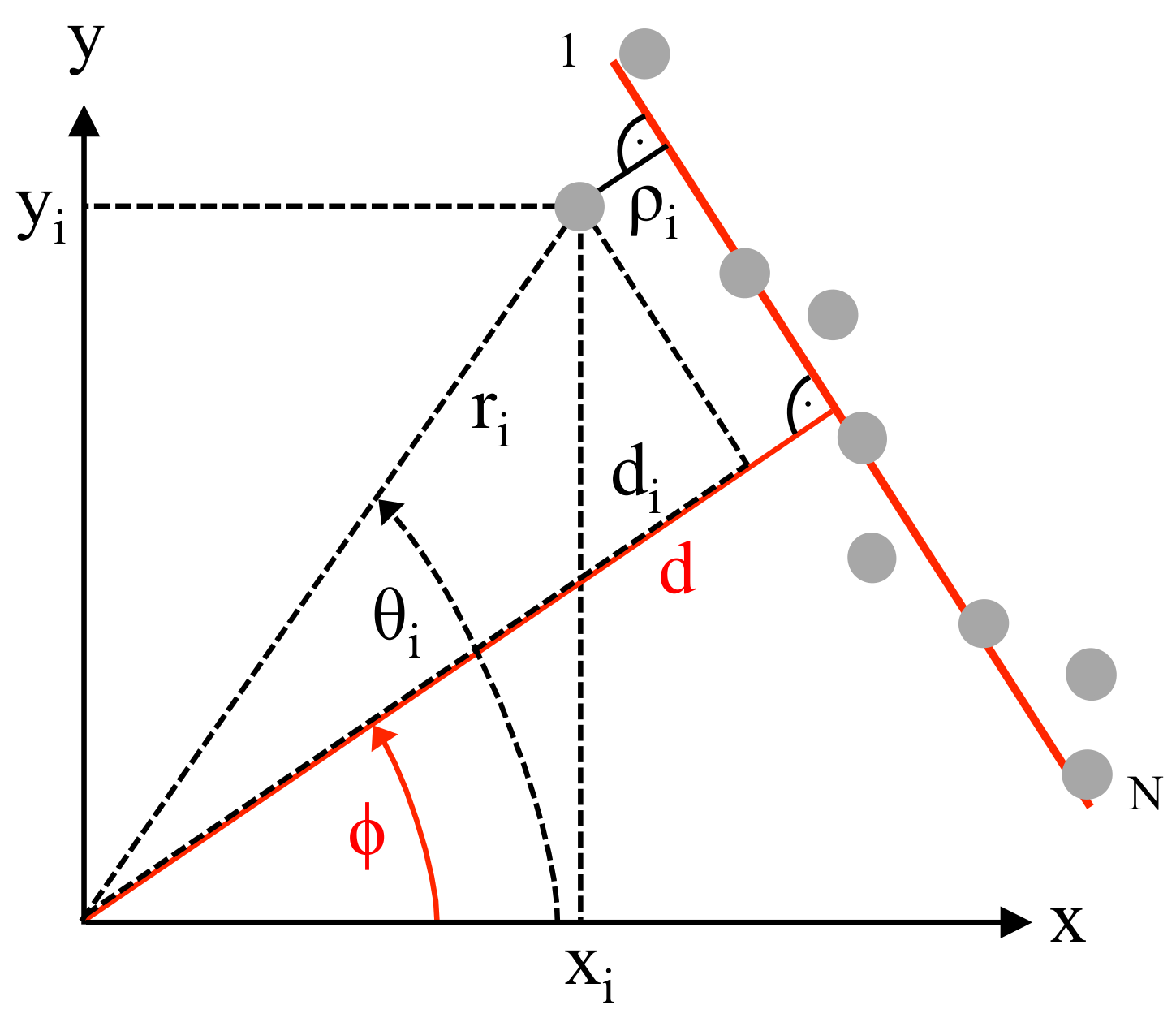
2. Determination of the Accurate Line Parameters
In 2D-space, each straight line is uniquely described by its perpendicular distance
d from the origin and by the angle
between the positive
x-axis and this normal line; see
Figure 1. In order to determine these two parameters, the mean squared error
considering the perpendicular distances of
N measurement points from the fitted line needs to be minimized. For this purpose, each perpendicular distance
of point
i is calculated either from polar or with
and
alternatively in Cartesian coordinates as:
Then,
is defined as follows dependent on
and
d:
In (
2), optional scaling values
are included in order to consider the individual reliability of each measurement point. By calculating the derivatives of (
2) with respect to
and
d and setting both to zero, the optimum values of these parameters can be analytically derived assuming all
to be constant, i.e., independent of
and
d. The solution has been published elsewhere (compare [
32]), and in the Appendix of this paper, a straightforward derivation is sketched, yielding for
and
d:
The function
means the four quadrant arc tangent, which calculates
always in the correct range. If
d becomes negative, its modulus must be taken, and the corresponding
has to be altered by plus or minus
. In these equations,
and
denote the mean values of all
N measurements
and
, while
,
and
denote the variances and the covariance:
In (
5)–(
9), normalized weighting factors
are used with
and
, calculated dependent on the chosen scaling values
:
As pointed out in [
35], for accurate line matching, the scaling values
must not be assumed to be constant since in general, they depend on
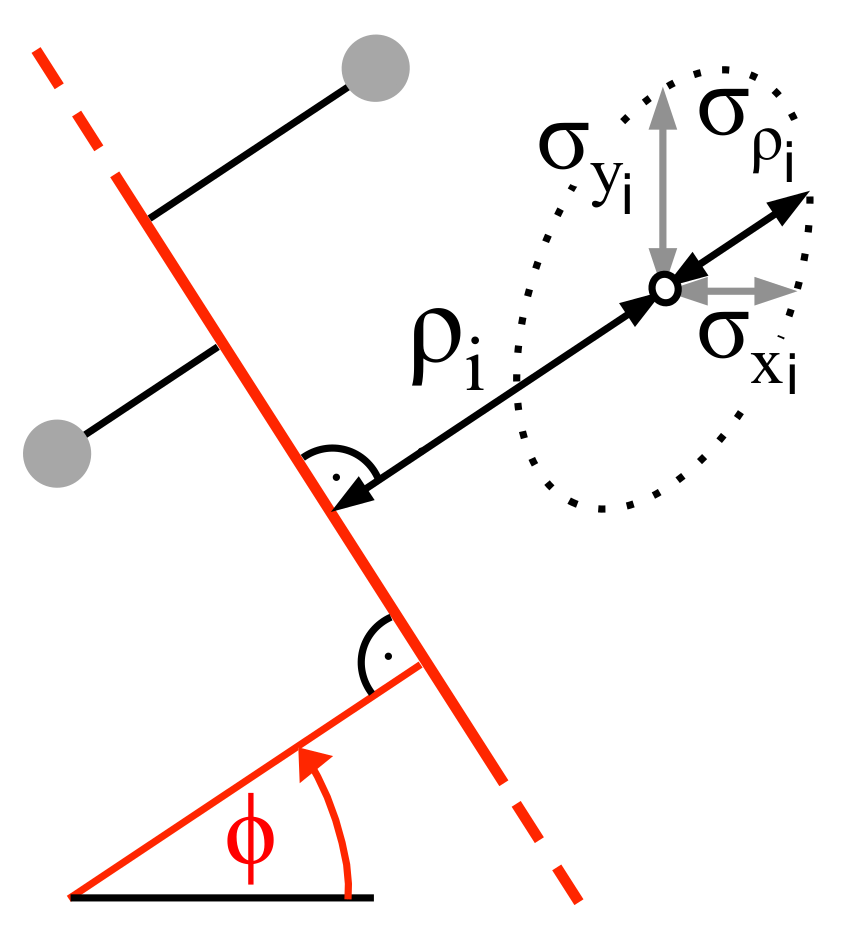
. This can be understood from
Figure 2, which shows for one measurement point
i the error ellipse spanned by the standard deviations
and
, while the rotation of the ellipse is caused by the covariance
.
Apparently, as a measure of confidence, only the deviation
perpendicular to the line is relevant, while the variance of any data point parallel to the fitted line does not influence its reliability. Thus, the angle
given in (
3) will only be exact, if the error ellipse equals a circle, which means that all measurements exhibit the same standard deviations in the
x- as in the
y-direction, and no covariance exists. Generally, in order to determine optimum line parameters with arbitrary variances and covariance of each measurement
i, in Equation (
2) the inverse of
dependent on
has to be used as scaling factor
, yielding:
In this formula, which can only be solved numerically, the variance
needs to be calculated dependent on the covariance matrix of each measurement point
i. In the case of line fitting from range-bearing scans, the covariance matrix
can be modeled as a diagonal matrix since both parameters
and
are measured independently, and thus, their covariance
equals zero:
Typically, this matrix may also be considered as constant, thus independent of index i, assuming that all measured radii and angles are affected by the same noise, i.e., .
With known variances
and
and for a certain
, now
is determined by evaluating the relation between
and the distances
of each data point with
. According to (
1) and with the distance
d written as the mean of all
, it follows:
Since noise-induced variations of all distances
are uncorrelated with each other, now the variance
is calculated by means of summing over all variances
:
In order to derive
, changes of
with respect to small deviations of
and
from their expected values
and
are considered with
,
and with
:
The terms on the right side of (
15) can be determined independently of each other, since
and
are assumed to be uncorrelated. With
, it follows:
and:
In the last line, the addition theorem was applied for cos, and for small variations, the approximations cos and sin are valid.
The random variables
and
are assumed to be normally distributed with variances
and
. Thus, the random variable
exhibits a
-distribution with variance
(see [
44]), and the variance of
is calculated from (
15)–(
17) as the weighted sum with
and
approximately replaced by
and
, respectively:
When applying this algorithm, a one-dimensional minimum search of
according to (
11) needs to be executed, yielding the optimum
of the straight line. For this purpose,
is inserted from (
14) considering (
18) and
is determined according to (
1) by calculating
d from (
4) and (
8)–(
10) with
.
Obviously, numerical line fitting can also be accomplished if measurements are available in Cartesian coordinates
and
. In this case, the covariance matrix
of each measurement point must be known, defined as:
Furthermore, the partial derivatives of
according to (
1) with respect to
and
need to be calculated:
Then,
follows dependent on
and
:
If raw data stem from a range-bearing scan,
can be calculated from
by exploiting the known dependencies between the polar and Cartesian plane. For this purpose, the Jacobian matrix
is determined:
Then, the covariance matrix
will depend on
, if small deviations from the mean value of the random variables
and
and a linear model are assumed:
According to (
23), generally a strong covariance
in
must be considered, if measurements are taken by range-bearing sensors.
By means of applying (
21)–(
23) instead of (
18) for searching the minimum of
dependent on
, the second order effect regarding
is neglected. This yields almost the same formula as given in [
35], though the derivation differs, and in [
35], additionally, the variance of
d is ignored assuming
, which according to (
14) is only asymptotically correct for large
N.
Finally, it should be noted that the numerical determination of
according to (
11) means clearly more complexity compared to the straightforward solution according to Equation (
3). Later, in
Section 5, it will be analyzed under which conditions this additional computational effort actually is required.
3. Analytic Error Models of Straight Lines
In the literature, several methods are described to estimate errors of
and
d and their mutual dependency. Thus, the covariance matrix
must be known, defined as:
For this purpose, a general method in nonlinear parameter estimation is the calculation of the inverse Hessian matrix at the minimum of
. Details can be found in [
30,
35], while in [
45], it is shown that this procedure may exhibit numerical instability. In
Section 5, results using this method are compared with other approaches.
Alternatively, in [
32,
46], an analytic error model is proposed based on fault analysis of the line parameters. In this approach, the effect of variations of each single measurement point defined by
with respect to the covariance matrix of the line parameters
is considered, based on (
3) and (
4). Thereto, the Jacobian matrix
with respect to
and
is determined, defined as:
With this matrix, the contribution of a single data point
i to the covariance matrix between
d and
can be written as:
For determining the partial derivatives of
d in (
25), Equation (
4) is differentiated after expanding it by (
8) and (
9), yielding:
Differentiating
according to (
3) with respect to
gives the following expression with
and
:
The partial derivation of
u in (
29) is calculated after expanding it with (
7) and (
8) as:
while partial derivation of
v with (
5), (
6) and (
8) yields:
Finally, after substituting all terms with
u and
v in (
29), it follows:
Correspondingly, for the partial derivative of
with respect to
, the following result is obtained:
Now, after inserting (
27), (
28), (
32) and (
33) into (
25), the covariance matrix of
d and
(
24) is calculated by summing over all
N data points since the noise contributions of the single measurements can be assumed to be stochastically independent of each other:
Equation (
34) enables an exact calculation of the variances
,
and of the covariance
as long as the deviations of the measurements stay within the range of a linear approach, and as long as Equations (
3) and (
4) are valid. In contrast to the method proposed in [
35], no second derivatives and no inversion of the Hessian matrix are needed, and thus, more stable results can be expected.
However, both algorithms need some computational effort especially for a large number of measurement points. Moreover, they do not allow one to understand the effect of changing parameters on , and these models can only be applied, if for each data point, the covariance matrix is available. Unfortunately, for lines extracted from images, this information is unknown, and also, in the case of using range-bearing sensors, only a worst case estimate of is given in the data sheet, while is ignored.
4. Closed-Form Error Model of a Straight Line
In this section, a simplified error model in closed form is deduced, which enables a fast, clear and yet, for most applications, sufficiently accurate calculation of the covariance matrix in any case when line parameters d and have been determined from a number of discrete data points.
Thereto, first, the expected values of the line parameters
d and
, denoted as
and
, are assumed to be known according to the methods proposed in
Section 2 with
and
. Besides, for modeling the small deviation of
d and
, the random variables
and
are introduced. Thus, with
and
, it follows for the variances and the covariance:
Next,
and
shall be determined dependent on a random variation of any of the
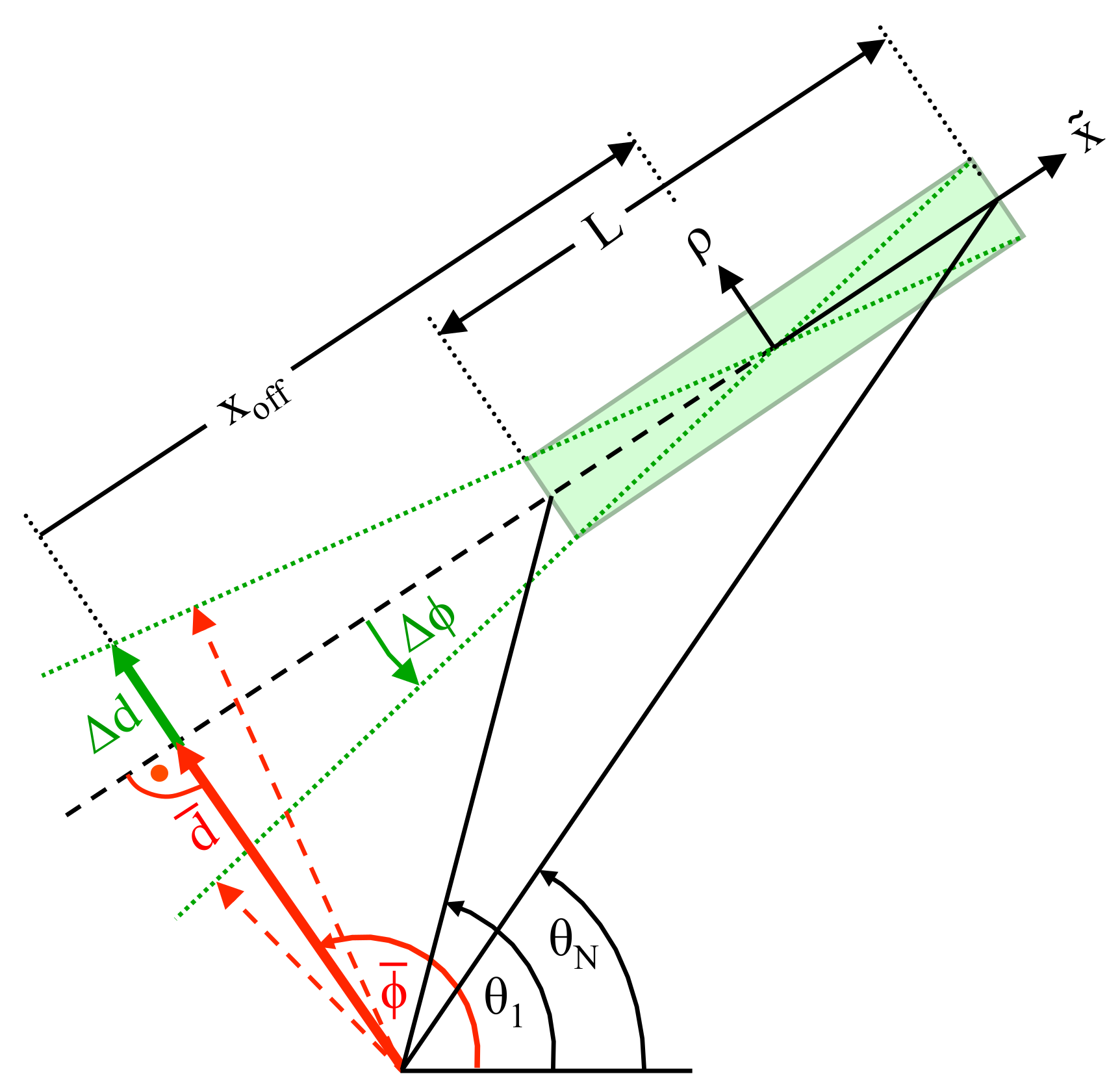
N measured data points. For this purpose,
Figure 3 is considered, which shows the expected line parameters and the random variables
and
.
In order to derive expressions for
and
depending on the random variables
,
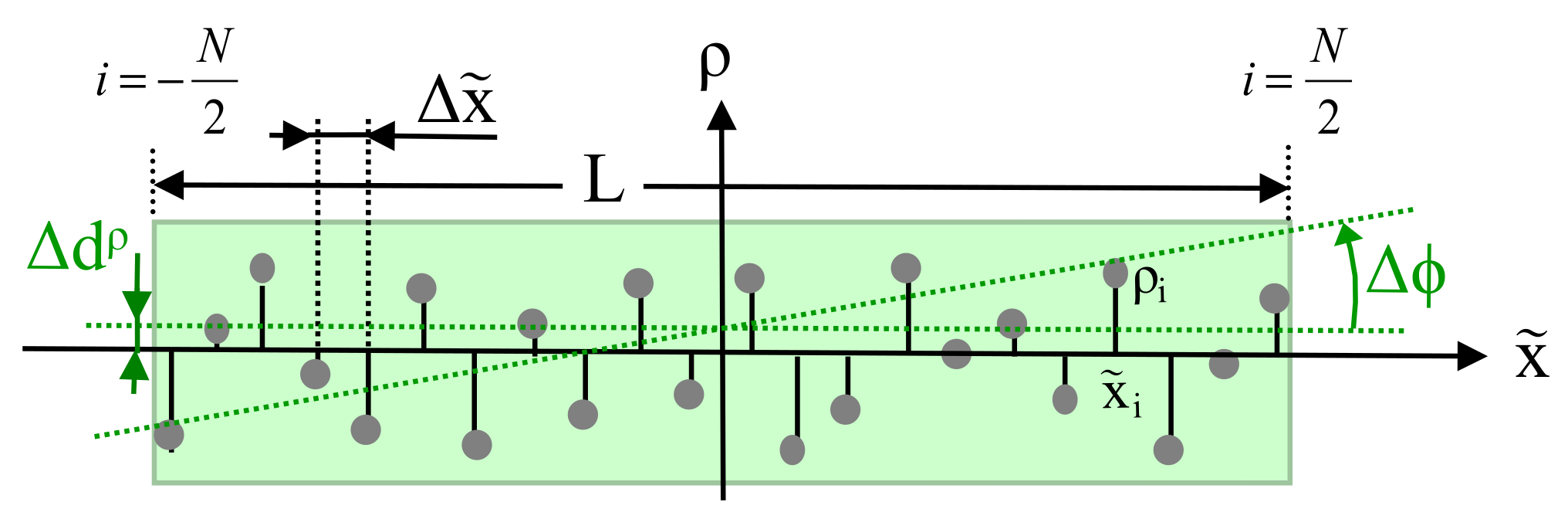
Figure 4 shows an enlargement of the rectangular box depicted in
Figure 3 along the direction of the line
.
First, the effect of variations of any
on
is considered. Since
is very small, this angle may be replaced by its tangent, which defines the slope
of the line with respect to the direction
. Here, only
is considered as random variable, but not
. Thus, the standard formula for the slope of a regression line can be applied (see, e.g., [
26] Chapter 2), which will minimize the mean squared distance in the direction of
, if all
are assumed to be exactly known:
Now, in order to calculate the variance of
, a linear relation between
and each
is required, which is provided by the first derivation of (
36) with respect to
:
Then, the variance of
dependent on the variance of
can be specified. From (
37), it follows:
If
is assumed to be approximately independent of
i, it may be replaced by
and can be estimated from (
2) with
taken from (
1) and setting all
to
:
It should be noted that for a bias-free estimation of
with (
39), the exact line parameters
and
d must be used in (
1), which obviously are not available. If instead, estimated line parameters according to
Section 2 are taken, e.g., by applying (
3) and (
4), calculated from the same data as used in (
39), an underestimation of
especially for small
N can be expected, since
and
d are determined by minimizing the variance of
of these
N data points. This is referred to later.
Next, from (
38), the variance of
results as the sum over all
N data points, since all
are independent of each other:
Equations (
40) with (
35) and (
39) enables an exact calculation of
dependent on the
N data points of the line.
However, from (
40), a straightforward expression can be derived, which is sufficiently accurate in most cases and enables a clear understanding of the influencing parameters on
; compare
Section 5. For this purpose, according to
Figure 3, the length
L of a line segment is determined from the perpendicular distance
d and from the angles
and
of the first and
N-th data point, respectively:
Furthermore, a constant spacing
between adjacent data points is assumed:
Applying this approximation, the sum over all squared
can be rewritten, yielding for even
N as depicted in
Figure 4:
The last sum can be transformed into closed form as:
With
N odd, the sum must be taken twice from 1–
, since in this case, the central measurement point has no effect on
, yielding:
Again, the last sum can be written in closed form, which gives the same result as in (
44):
Finally, by substituting (
43) with (
44) or (
45) with (
46) into (
40) and regarding (
35), as well as (
42), a simple analytic formula for calculating the variance of
is obtained, just depending on
L,
N and the variance of
:
The last simplification in (
47) overestimates
a little bit for small
N. Interestingly, this error compensates quite well for a certain underestimation of
according to (
39), assuming that the line parameters
and
d are determined from the same data as
; see
Section 5.
Next, in order to deduce the variance
, again,
Figure 3 is considered. Apparently, the first part of the random variable
is strongly correlated with
since any mismatch in
is transformed into a deviation
by means of the geometric offset
with:
Actually, with a positive value for
, as depicted in
Figure 3 the correlation between
and
becomes negative, since positive values of
correspond to negative values of
. According to
Figure 3,
is determined from
and
d, as well as from
and
:
Alternatively,
can be taken as the mean value from all
N data points of the line segment:
Nevertheless, it should be noted that is not completely correlated with , since also in the case , the error will not be zero.
Indeed, as a second effect, each single
has a direct linear impact on the variable
. For this purpose, in
Figure 4, the random variable
is depicted, which describes a parallel shift of the regression line due to variation in
, calculated as the mean value over all
:
Combining both effects, variations in
d can be described as the sum of two uncorrelated terms,
and
:
This missing correlation between
and the sum over all
is also intuitively accessible: if the latter takes a positive number, it will not be possible to deduce the sign or the modulus of
. From (
52) and with
,
and
, the variance
can be calculated as:
In the last step from (
53) to (
54), again, the independence of the single measurements from each other is used; thus, the variance of the sum of the
N data points approximates
N-times the variance
.
Finally, the covariance between
and
d needs to be determined. Based on the definition, it follows with
:
By means of (
47), (
54) and (
55), now, the complete error model in closed form is known, represented by the covariance matrix
given as:
Applying this error model is easy since no knowledge of the variances and covariance for each single measurement is needed, which in practice is difficult to acquire. Instead, just the number
N of preferably equally-spaced points used for line fitting, the variance
according to (
39), the length
L of the line segment calculated with (
41) and its offset
according to (
49) or (
50) must be inserted.
5. Simulation Results
The scope of this section is to compare the presented algorithms for linear regression and error modeling based on statistical evaluation of the results. Segmentation of raw data is not considered; if necessary, this must be performed beforehand by means of well-known methods like Hough transformation or RANSAC; compare
Section 1. Thus, for studying the performance reliably and repeatably, a large number of computer simulations was performed, applying a systematic variation of parameters within a wide range, which would not be feasible if real measurements are used.
For this purpose, straight lines with a certain perpendicular distance
d from the origin and within a varying range of normal angles
have been specified. Each of these lines is numerically described by a number of
N points either given in Cartesian (
) or in polar (
) coordinates. In order to simulate the outcome of a real range-bearing sensor as much as possible, the angular coordinate was varied between
and
. To each measurement, a certain amount of normally-distributed noise with
,
and
or alternatively with
and
was added. Further, for each
, a number of
sets of samples was generated, in order to allow statistical evaluation of the results. The first simulation was performed with
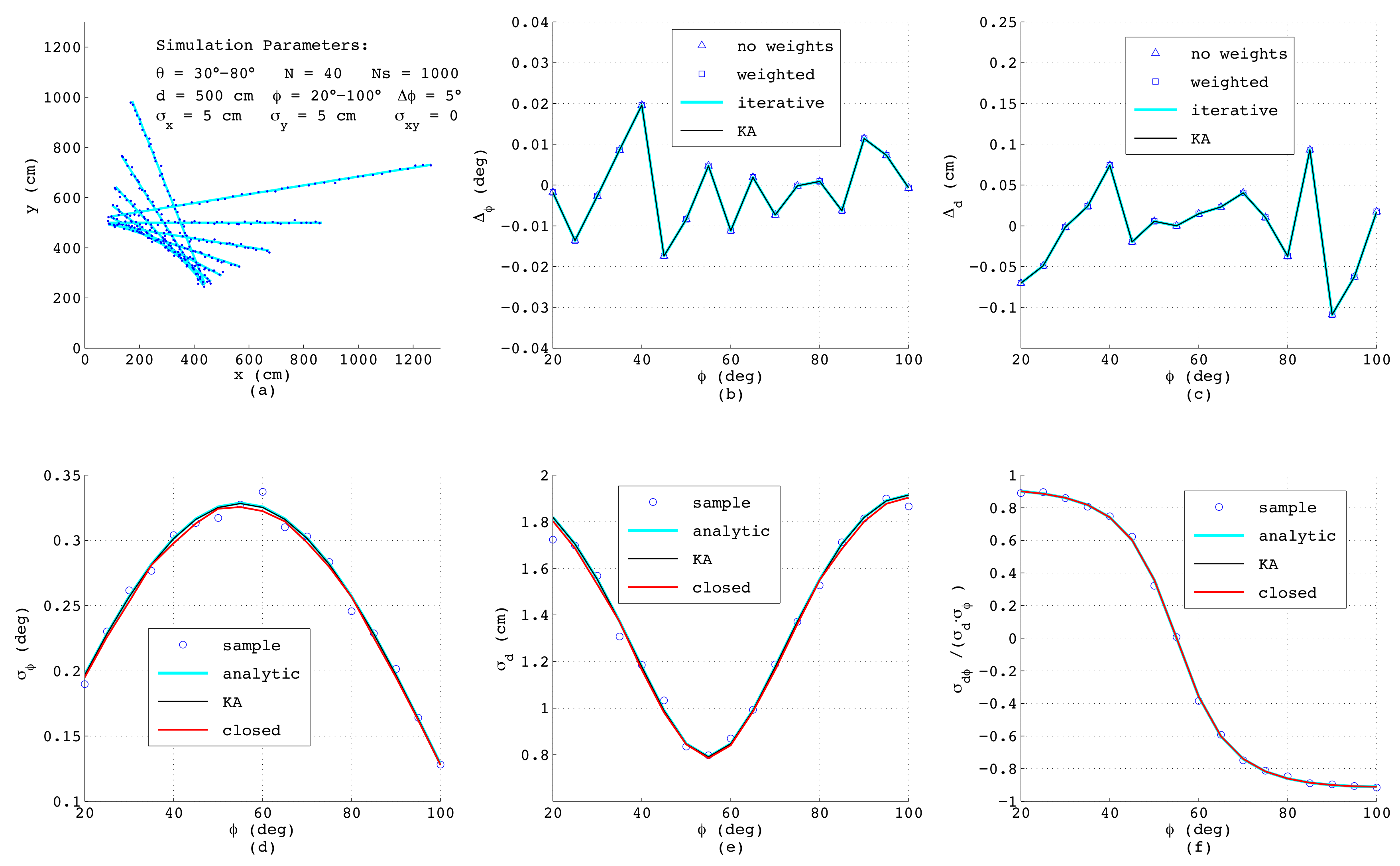
equally-spaced points affected each by uncorrelated noise in the
x- and
y-direction with standard deviations
cm. This is a typical situation when a line is calculated from binary pixels, and in
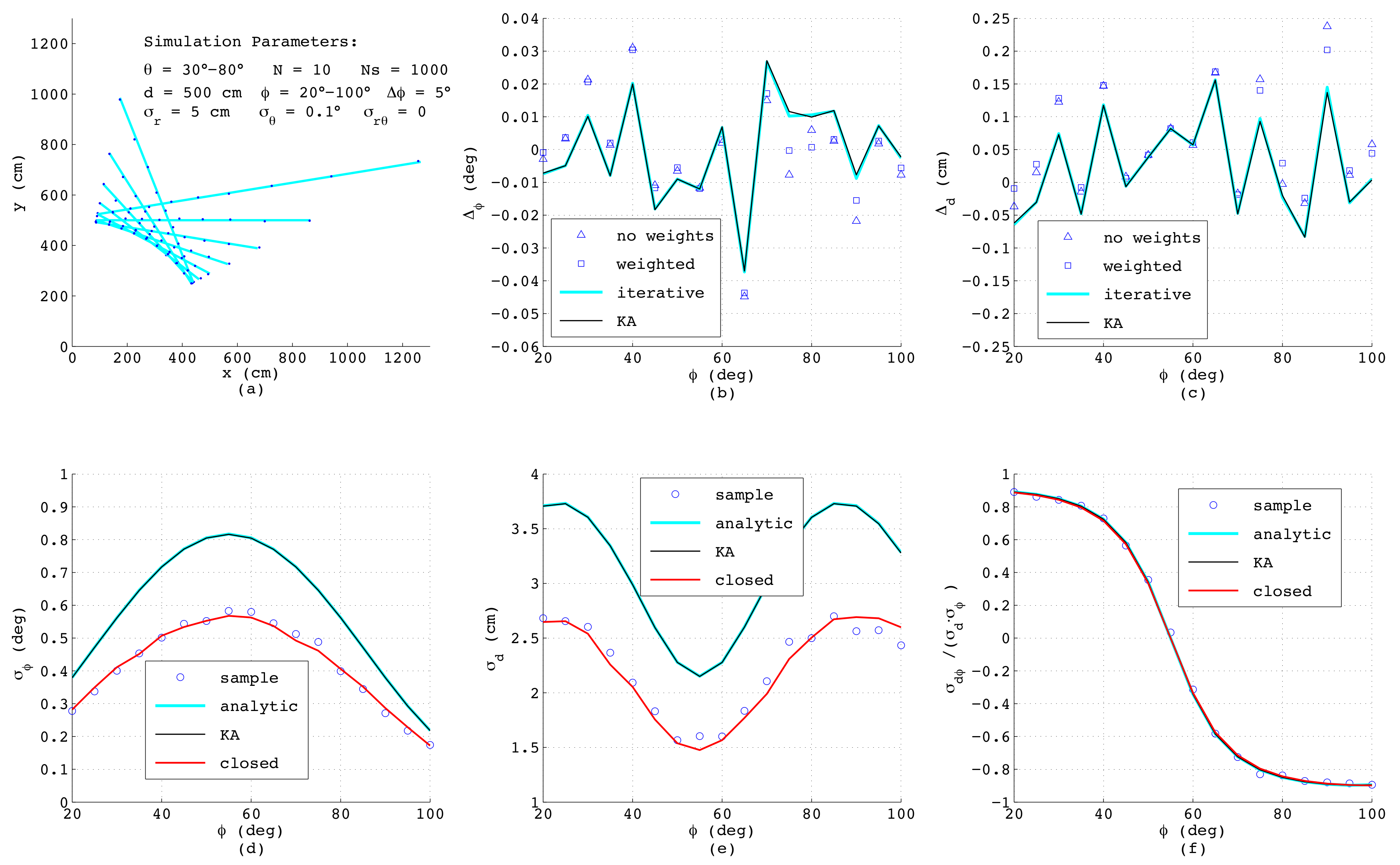
Figure 5a, a bundle of the simulated line segments is shown. The deviations
and
taken as the mean value over all
samples of the estimated
and
d from their true values, respectively, are depicted in
Figure 5b,c, comparing four algorithms as presented in
Section 2: The triangles mark the outcome of Equations (
3) and (
4) with all weights set to one, whereas the squares are calculated according to the same analytic formulas, but using individual weighting factors applying (
10) with
. The perpendicular deviations
are determined according to (
14) and (
21) with
taken from (
3) without weights. Obviously, in this example, all triangles coincide with the squares since each measurement
i is affected by the same noise and thus for any
, all weighting factors are always identical. The blue lines in
Figure 5b,c show the results when applying the iterative method according to (
11) with the minimum of
found numerically. For this purpose,
is inserted from (
14) considering (
21) and
is taken from (
1) and
d is calculated from (
4), (
8)–(
10) with
. The black lines (KA) depict the deviations of
d and
obtained according to Krystek and Anton in [
35]. Both numerical algorithm yield the same results, which is not surprising, since the variances
used as weighting factors are all identical. Further, here, the analytical algorithms provide exactly the same performance as the numerical ones, since for
. the weighting factors show no dependency on
, and for that case, the analytical formulas are optimal.
The lower subfigures depict the parameters of the covariance matrix
, again as a function of
comparing different methods. Here, the circles represent numerical results obtained from the definitions of variance and covariance by summing over all
passes with
, yielding
and
, respectively:
Since these numerical results serve just as a reference for judging the accuracy of the error models, in the formulas above, the true values for
d and
have been used. The required line parameters
and
in (
57)–(
59) can be estimated with any of the four described methods, since minor differences in
and
have almost no effect on the resulting variances and the covariance. The blue lines in
Figure 5d–f show the results of the analytic error model as described in
Section 3, and the black lines represent the outcomes of the algorithm from Krystek and Anton [
35], while the red lines corresponds to the model in closed-form according to (
56) in
Section 4 with
L and
taken from (
41) and (
49), respectively. Interestingly, although the theoretical derivations differ substantially, the results match very well, which especially proves the correctness of the simplified model in closed-form. Since this model explicitly considers the effect of the line length
L and of the geometric offset
, the behavior of the curves can be clearly understood: The minimum of
L will occur if
equals the mean value of
and
, i.e., at
, and exactly at this angle, the maximum standard deviation
occurs. Further, since
L linearly depends on
, a quadratic dependence of
on
according to (
47) can be observed. With respect to
Figure 5e, the minimum of
also appears at
corresponding to
. At this angle, according to (
54), the standard deviation of
d is given as
, while the covariance
calculated according to (
55) and with it the correlation coefficient shown in
Figure 5f vanish.
When comparing the results, one should be aware that in the simulations of the analytic error models, the exact variances
,
and
are used; thus, in practice, the achievable accuracies will be worse. On the other hand, when applying the new error model in closed-form, the variance
is calculated as the mean value of all
from the actual set of
N data points according to (
39), and hence, is always available.
Nevertheless, if in this equation, the estimated line parameters
and
d are used, which are calculated, e.g., according to (
3) and (
4) using the same measurements as in (
39), no unbiased
can be expected. This is reasoned from the fact that for each set of
N data points, the mean quadratic distance over all
is minimized in order to estimate
and
d. Thus, the numeric value of
will always be smaller than its correct value calculated with the exact line parameters. This effect can be clearly observed from
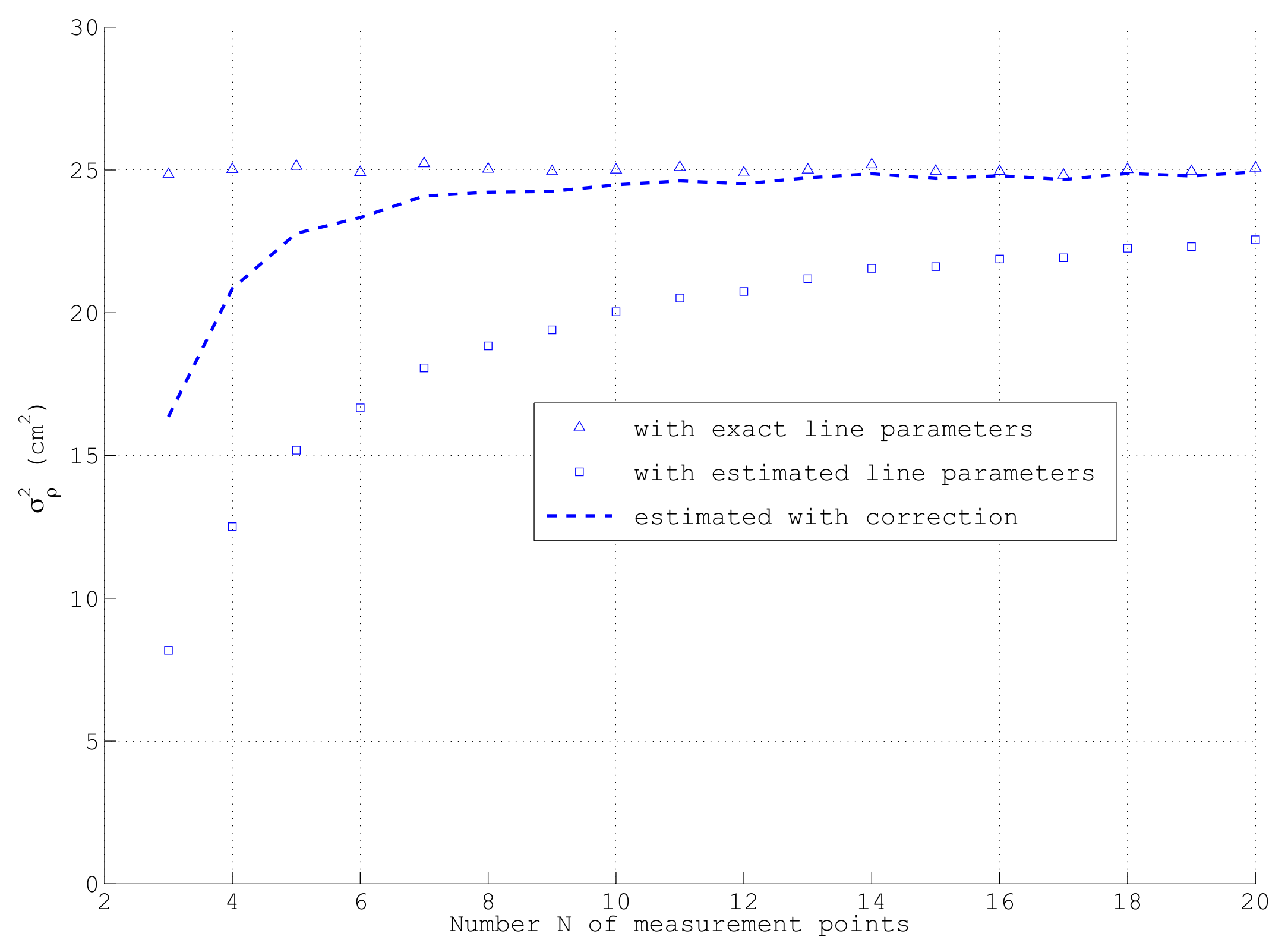
Figure 6, which shows for the same simulation parameters as depicted in
Figure 5a the dependency of
on the number of points on the line
N, averaged over
sets of samples: only in the case of using the exact line parameters in (
39), which obviously are only available in a simulation, actually the correct
cm
is obtained as shown by the triangles. If however, in each run,
is calculated with the estimated
and
d as indicated by the squares, a clear deviation especially at low
N occurs. Only asymptotically for large
N when
converges to its exact value, the correct
is reached. Fortunately, this error can be compensated quite well by means of multiplying
with a correction factor
as shown by the dashed line in
Figure 6. Due to the strongly non-linear relation between
and any
, this correction works much better than simply exchanging in (
39) the divisor
N by
as often used in statistics. Since
c is the inverse of the term neglected in the approximation of
in (
47), the closed-form of the covariance matrix
according to (
56) yields almost unbiased results also for small
N if
is calculated according to (
39) with estimated line parameters
and
d. Although not shown here, the proposed bias compensation works well for a large range of measurement parameters. For a reliable determination of
from
N data points of a line segment,
N should be at least in the order of 10.
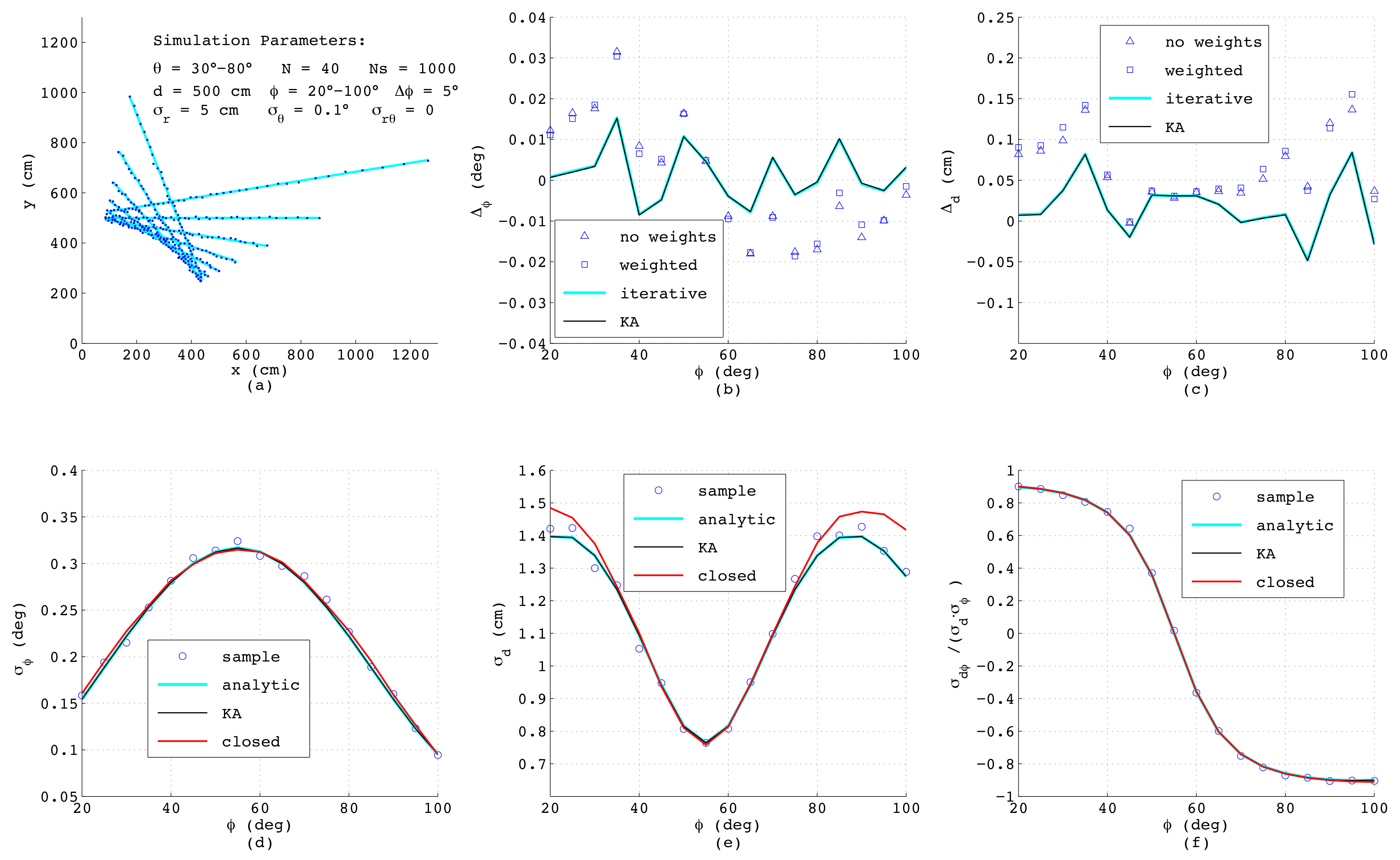
Figure 7 shows the results when simulating a range-bearing scan with a constant angular offset
between adjacent measurements. Each measurement is distorted by adding normally-distributed noise with standard deviations
cm and
. This is a more challenging situation, since now that the measurements are not equispaced, each data point exhibits individual variances
,
dependent on
, and moreover, a covariance
exists. As can be seen, the errors of the estimated
and
d as depicted in
Figure 7b,c exhibit the same order of magnitude as before; yet, both analytic results differ slightly from each other and are less accurate compared to the numerical solutions. Both numerical methods yield quasi-identical results, since for the chosen small noise amplitudes, the differences between both algorithms have no impact on the resulting accuracy.
Regarding the error models,
Figure 7d–f reveal that in spite of unequal distances between the measurement points and varying
, the results of the closed-form model match well with the analytic and numeric results. Only
shows a certain deviation at steep and flat lines with
below
or above
. This is related to errors in
, since in this range of
, the points on the lines measured with constant
have clearly varying distances, and thus, (
49) yields just an approximation of the effective offset of the straight line.
The next
Figure 8 shows the results with the models applied to short lines measured in the angular range of
with
, while all other parameters are identical to those depicted in
Figure 7a. As can be seen from
Figure 8b,c, now, the analytical algorithms based on (
3) and (
4) are no longer adequate since these, independent of applying weights or not, yield much higher errors than the numerical approaches. All error models however still provide accurate results. Actually, the closed-form model even yields better accuracy than before, since the distances of the data points on the line between adjacent measurement and also
are more uniform compared to the simulations with long lines.
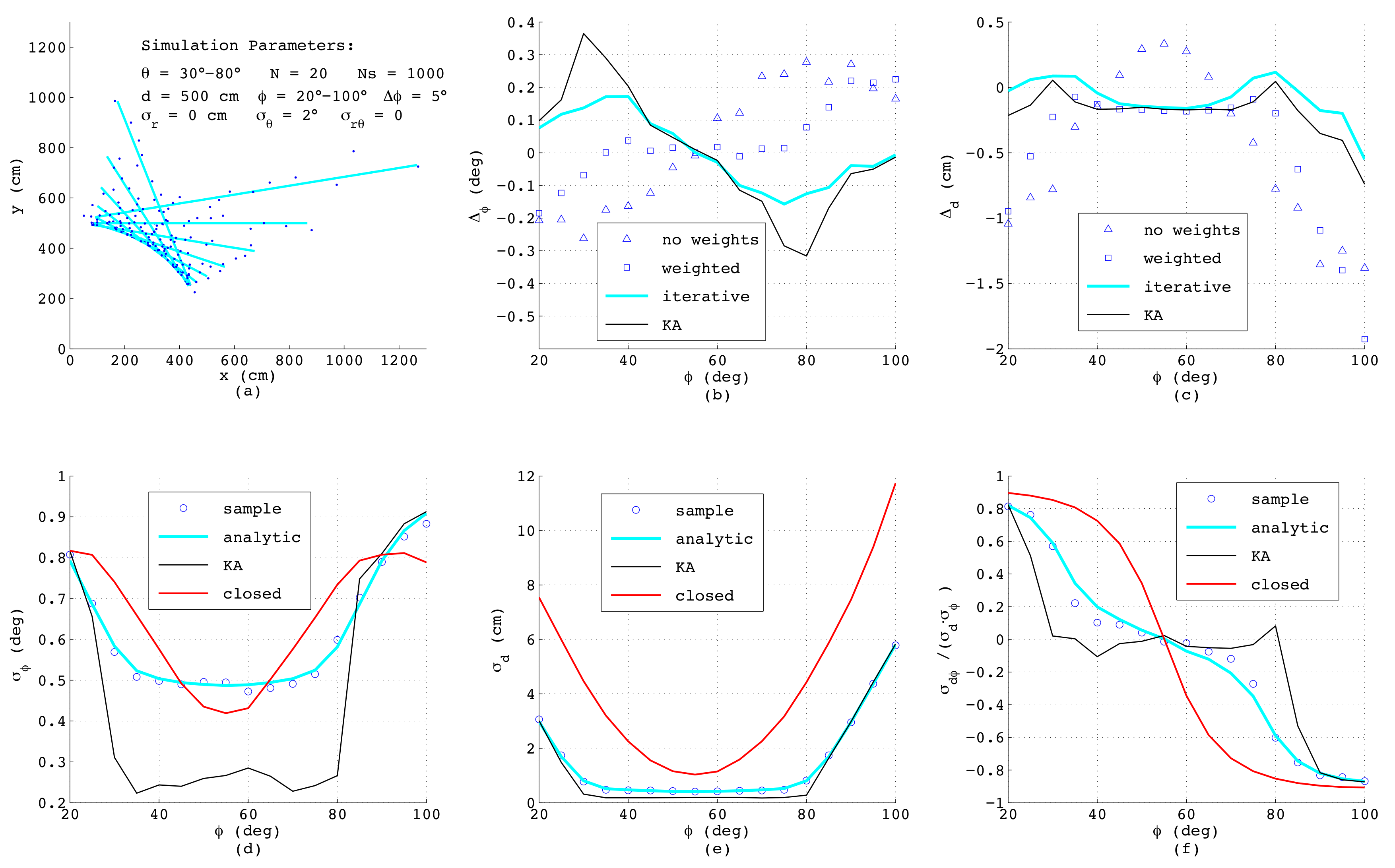
In order to check the limits of the models,
Figure 9 depicts the results when applying large angular noise with
. In this extreme case, also the numerical algorithms show systematic errors dependent on
since the noise of
can no longer be assumed to be normally distributed. However, according to
Figure 8b,c the iterative method as presented in
Section 2 shows clear benefits in comparison to the KA algorithm proposed in [
35], caused by the more accurate modeling of
.
With respect to the outcome of the noise models in
Figure 9d–f, now, only the analytic algorithm as presented in
Section 3 still yields reliable results, while the KA-method based on matrix inversion reveals numerical instability. Due to the clear uneven distribution of measurements along the line, also the simplified error model in this case shows clear deviations, although at least the order of magnitude is yet correct.
Finally,
Figure 10 shows typical results, if the sensor noise is not exactly known. In this example, the radial standard deviation was assumed to be 10 cm, whereas the exact value, applied when generating the measurements, was only 5 cm. The simulation parameters correspond to those in
Figure 7, only the number of data points has been reduced to
. According to
Figure 10b,c, now, for calculating
and
d, the numerical methods yield no benefit over the analytical formulas with or without weights. Due to the only approximately known variance, the analytic error model, as well as the KA-method in
Figure 10d–f reveal clear deviations from the reference results. Only the model in closed-form is still accurate, since it does not require any a priori information regarding sensor noise. In addition, these results prove the bias-free estimation of
with (
39) also if
N is low, as depicted in
Figure 6.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









