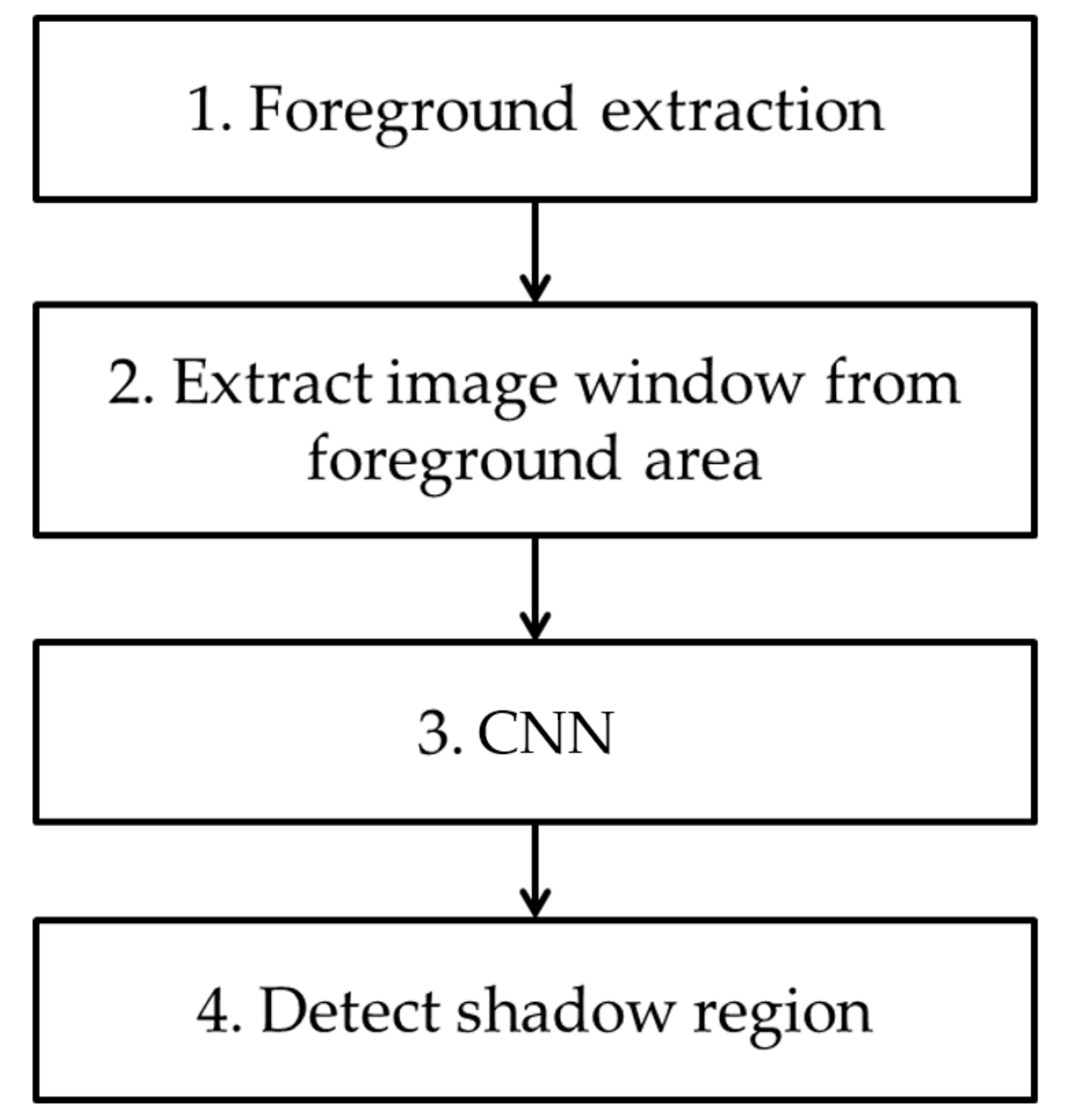
4.2. Training of CNN Model
Window images are extracted from DSDD-DB1, as explained in
Section 3.2. The total number of extracted window images is 1008,254 (696,692 non-shadow images and 311,562 shadow images). In this research, we divide our dataset in halves to perform the two-fold cross validation. If those halves are called group 1 and group 2, respectively, as shown in
Table 4, then group 1 uses 347,617 non-shadow images and 156,348 shadow images, whereas group 2 uses 349,075 non-shadow images and 155,214 shadow images. In other words, in the first-fold cross validation, the training applies the group 1 data and the testing applies the group 2 data. Alternatively, the second-fold cross validation uses group 2 data for training and group 1 data for testing.
The stochastic gradient descent (SGD) method [
39] is used for CNN training. The SGD method is a derivative-based method of finding an optimal weight to minimize the difference between desired output and calculated output. Unlike the gradient descent method, the SGD method defines the division of mini-batch by an iteration of size unit. One epoch is the duration where the iteration number of training is completed. Training is conducted as many as a predetermined number of epochs. In this research, we train CNN by ten epochs. CNN training parameters are as follows. The optimum fine-tuning model is experimentally found, based on the optimal parameters of initial learning rates of 0.001, the momentum value of 0.9, and a mini-batch size of 20. Additionally, the learn-rate-drop is 0.01, and the learning rate decreases by 1/10 of the previous value every 3.3 epochs.
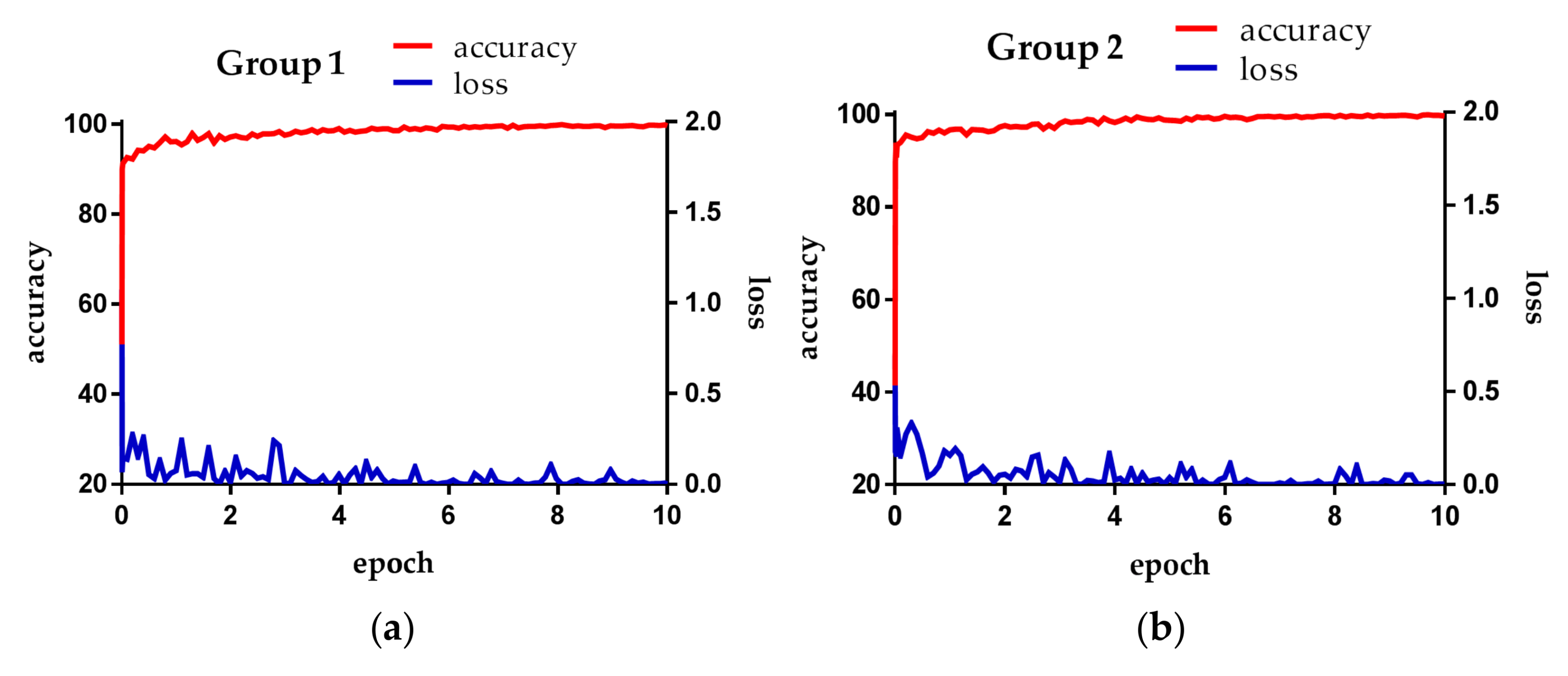
Figure 5 is the loss and accuracy of each epoch during the training in our experiment. The loss is the training loss, and the accuracy is the degree of training measure. That is, the accuracy obtained by retesting the training data. The loss value depends on learning rate and batch size. If the learning rate is set to a low value, the loss value gradually decreases in a linear form. If the learning rate is high, the loss value decreases drastically and does not reach the desired optimal training result, thereby retaining a loss value.
Figure 5a,b shows loss and accuracy obtained from training in the first- and second-fold cross validations, respectively. Both cases reveal that the increase of training epoch is accompanied by the convergence of loss and accuracy to 0 and 100%, respectively.
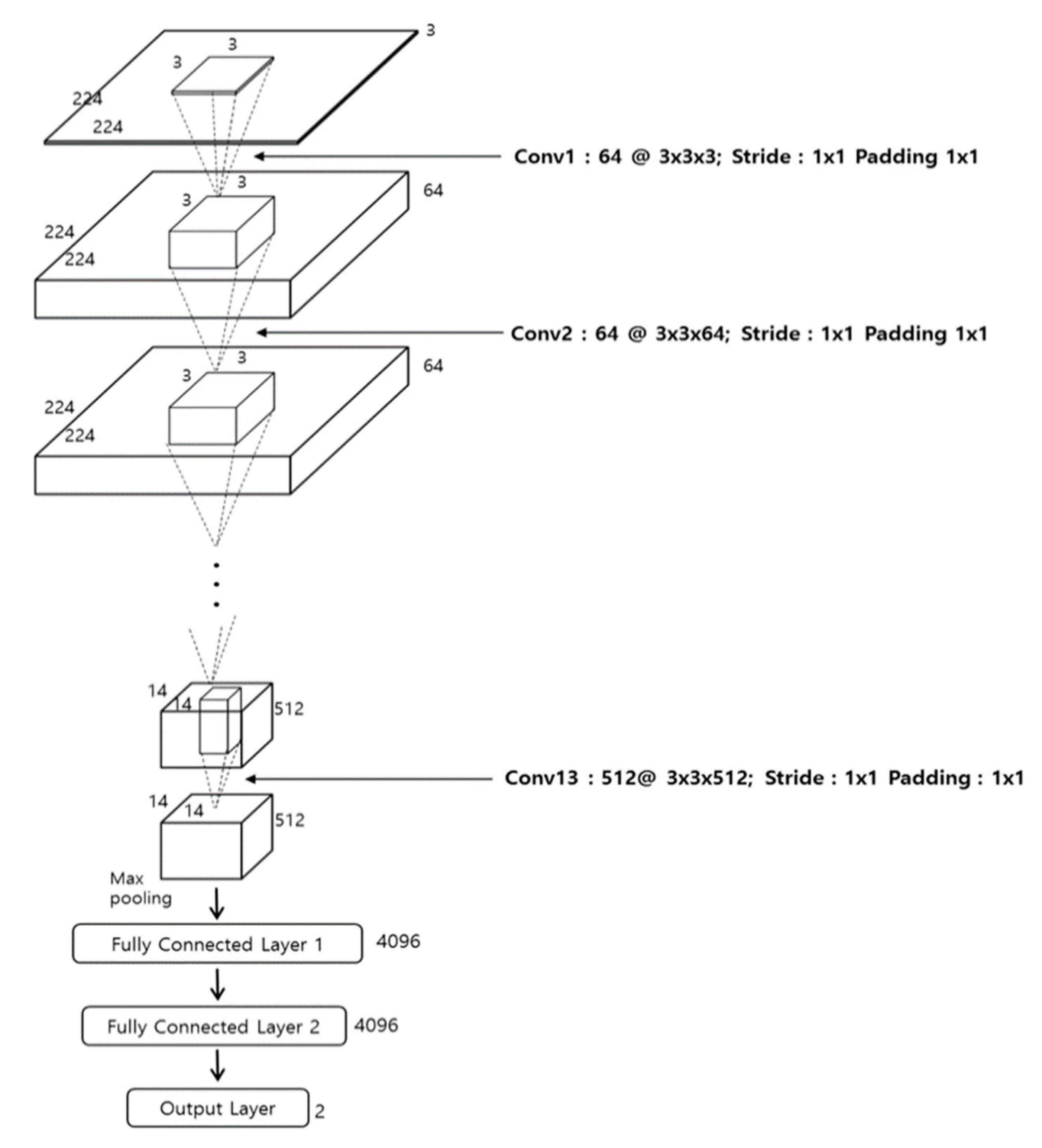
Figure 6 illustrates the filters in the first convolutional layer of the trained CNN model. As shown in
Table 2, the first convolution layer has 64 kernels and the size of
(i.e., width × height).
4.3. Testing of Proposed Method
Table 5 is a confusion matrix showing the testing results. Testing 1 and 2 present the accuracy of testing data for the first- and second-fold cross validations, respectively. If the shadow region corresponds to positive data and the non-shadow region to negative data, the first row, from left to right, indicates the true positive rate (TPR) of identifying shadow correctly and the false negative rate of mistaking shadow as non-shadow. The second row, from left to right, indicates the false positive rate of mistaking non-shadow as shadow and the true negative rate (TNR) of identifying non-shadow correctly.
We measure the testing accuracy by applying Equations (6)–(9), as shown in
Table 6. The minimum value and the maximum value are set to 0 and 100, respectively. The higher the value the more accurate. As in
Table 5, testing 1 and 2 show the accuracy for testing data in the first- and second-fold cross validations, respectively. In Equations (6)–(9), #TP, #TN, #FP, and #FN indicate the number of true positives (TPs), true negatives (TNs), false positives (FPs), and false negatives (FNs), respectively [
40]. As shown in
Table 5 and
Table 6, the proposed method produces the average shadow detection performance of at least 96%.
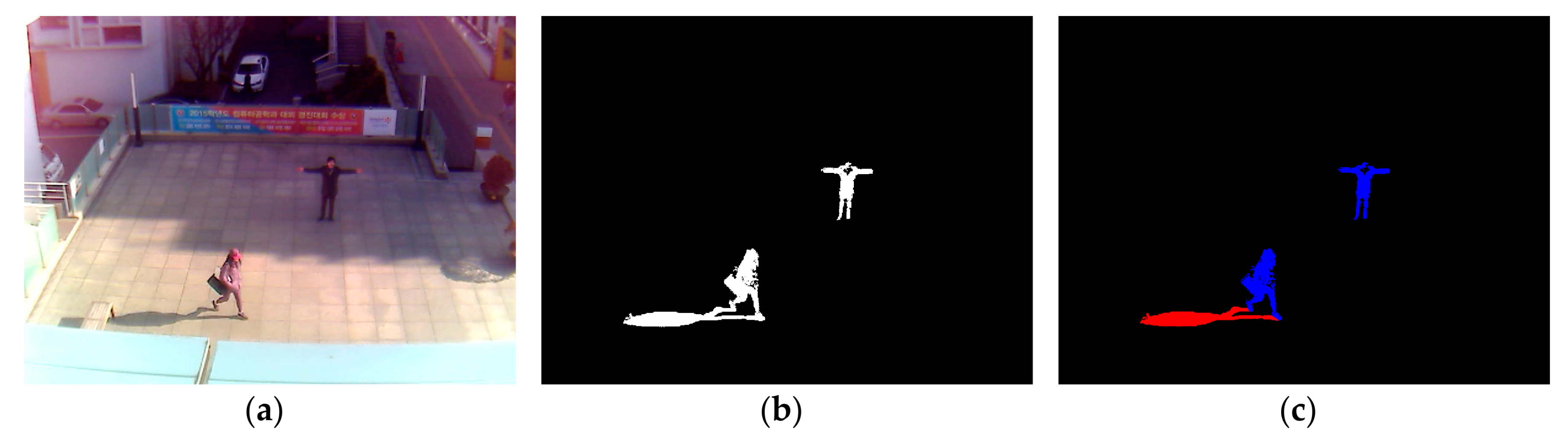
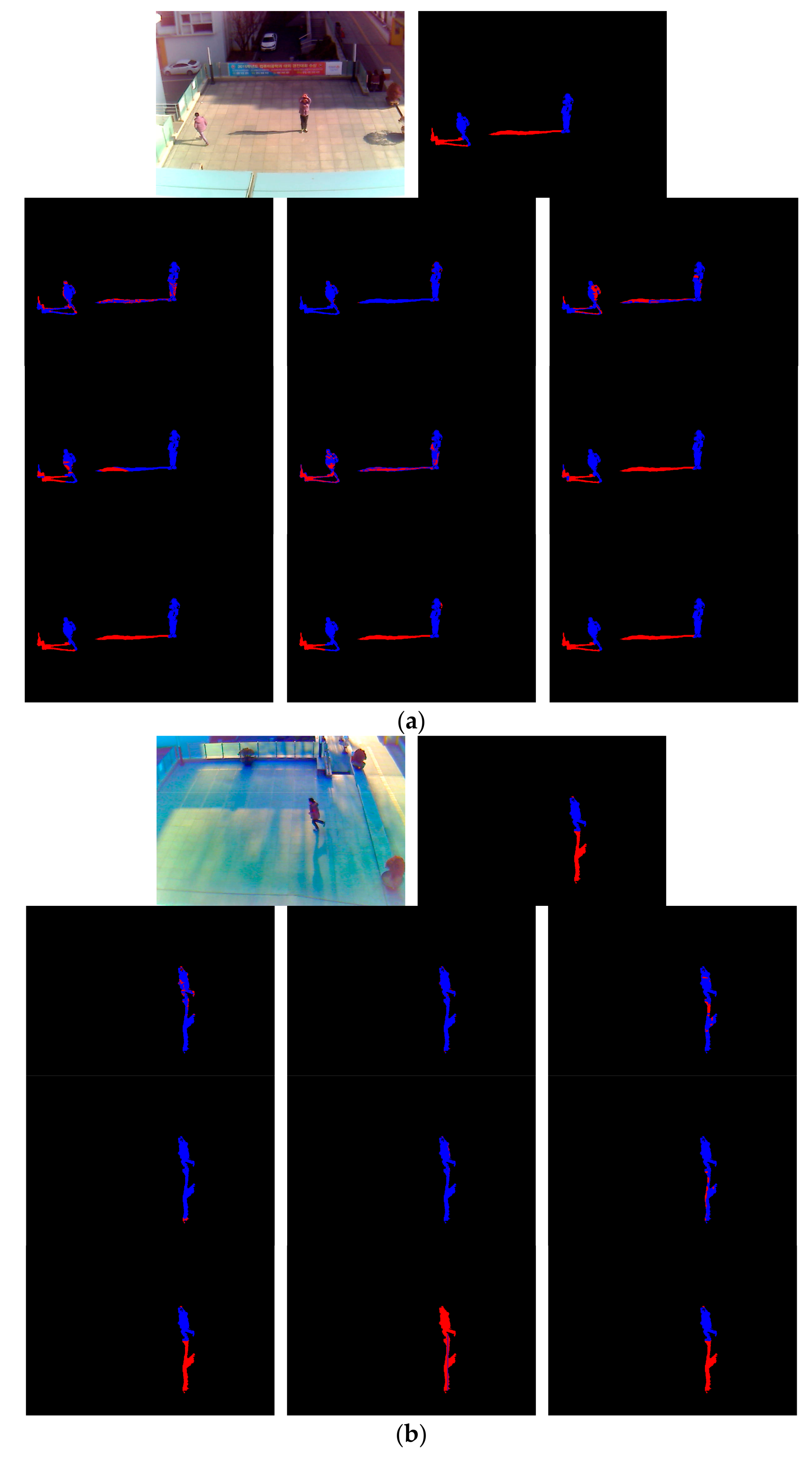
Figure 7 presents examples of result images for each phase, which are obtained by the proposed method. As shown in
Figure 7, we find that our method detects the correct human area by excluding the shadow region, even with the images of various environments and humans at far distances.
In the next experiment, we compare the performance between the proposed method and the methods [
8,
15,
17,
19,
20].
As mentioned in
Section 2, the method of [
8] detects shadow in HSV color space by utilizing the fact that shadows reduce the brightness of the background, whereas its chromaticity does not change much. The method of [
15] uses gradient information, along with the existing HSV color information for shadow detection. The method of [
17] finds a candidate shadow region under the assumption that the shadow region of a gray image is half-transparent, having a similar value to that of the corresponding background region. The Gabor filter, which is applied to a small region, is used to extract features and to finally detect shadow. The method of [
19] uses the geometric properties of shadow and human regions. A rough shadow region is initially detected, and then the orientation and the center of gravity of the detected region are used for the Gaussian shadow modeling of shadow. The method of [
20] utilizes physics-based color features to model shadow and background. A shadow model is trained by GMM, based on gradient intensity distortion and spectral ratio, and then shadow is detected.
Additionally, as shown in
Table 2, the final two outputs of the classification layer are not used to distinguish shadow and non-shadow, but 4096 features extracted from the first FCL are used to calculate the mean Euclidean distance for each of shadow and non-shadow classes, which are obtained from training data, thereby detecting shadow and non-shadow regions. This scheme is also widely adopted by existing CNN-based recognition research [
41]. Besides, apart from VGG Net-16, which is used in this research, AlexNet [
27], which has lower depth and CNN architecture, was used to compare performance.
The previous researches [
8,
15,
17,
19,
20,
27,
41] have been widely compared for measuring the accuracy of shadow detection in previous works. Except for these researches, there is no more recent method focused on the topic of shadow detection. The methods [
5,
6] used the method of shadow detection of [
8]. In [
4], their method of shadow detection was used for detecting only the shadow of building (not pedestrian), and their experimental images were obtained from bird-eye view (like the images captured by airplane) with light detection and ranging (LiDAR) information. The consequent shadows in these images are much darker and larger than those of pedestrian in our research. Therefore, they used the simple method of shadow detection which selected the area whose brightness was lower than pre-determined threshold. This method causes lots of error for shadow detection in our experimental images because the brightness of pedestrian is lower than that of shadow in many cases of our experimental images. Therefore, this method was not compared in our experiment.
As additional comparison, the method of [
3] was also evaluated. The research [
3] proposes the method of shadow detection based on foreground detection, vertical histogram analysis, foreground partitioning, calculation of the orientation of major axis, and decision. However, this method has the assumption that the position of light source should be known in advance. In addition, the authors assume that the case that the light source exists at the upper position of pedestrian (which can make the shadow at the lower position of the pedestrian) does not happen. However, in the outdoor at noon, this can occur frequently. Because the self-collected database in [
3] is not available as open dataset, we applied their method to our database and CAVIAR open database which were used in our experiments. Following the 1st assumption of this method, we used the position of light source for experiment, which was manually labelled in each image frame.
As shown in
Table 7, the accuracies by previous methods including the method [
3] are lower than those by our method.
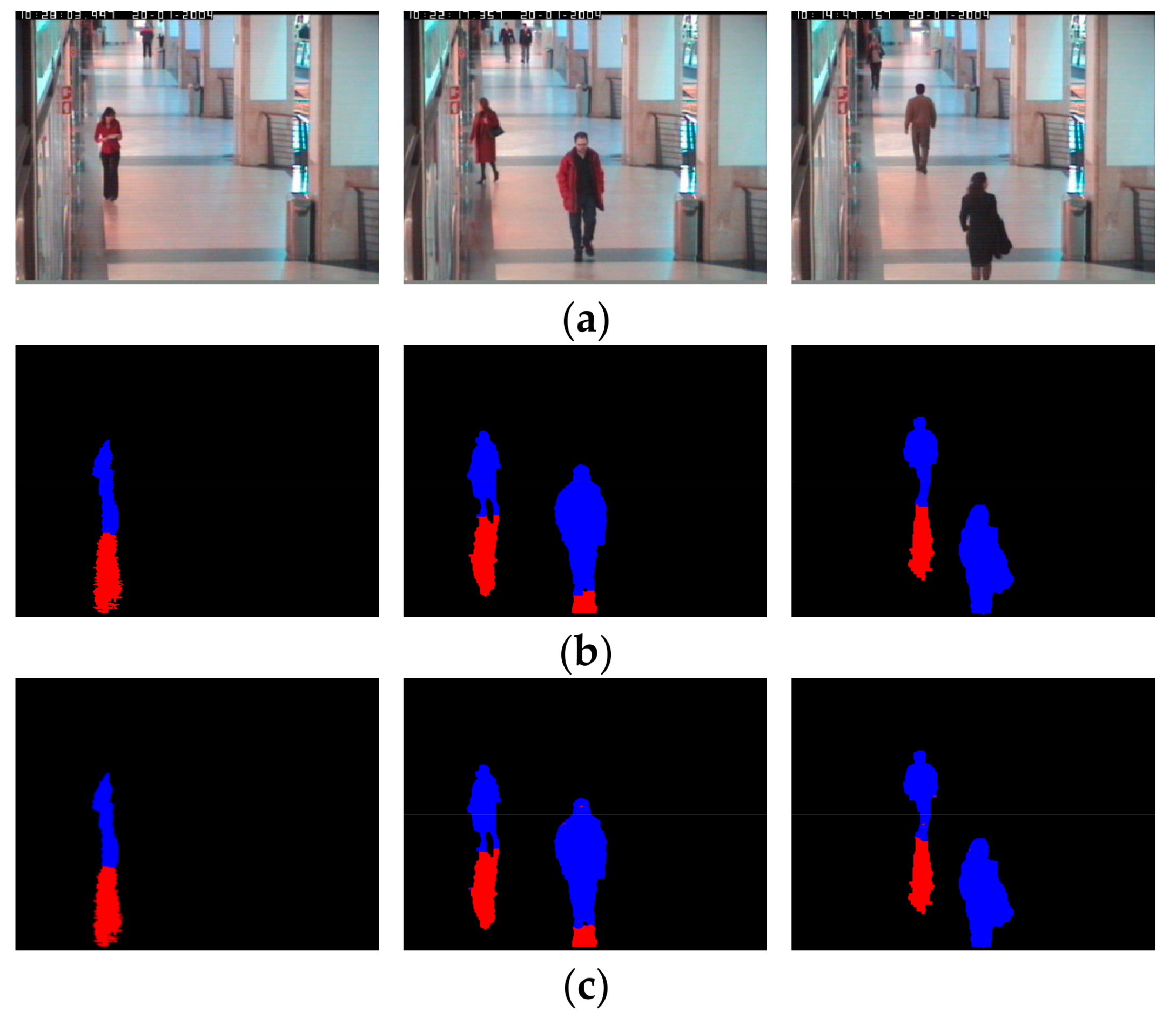
Figure 8 shows detected images of the proposed method and other compared methods along with the ground truth. In
Figure 8a,b, 10 images of each group are, from left to right: input image and ground truth image in the first row; the result images of Cucchiara et al. [
8], Sanin et al. [
15] and Leone et al. [
17] in the second row; the result images of Hsieh et al. [
19], Huang et al. [
20], Euclidean distance by 4096 features of first FCL [
41] in the third row; and the resultant images of AlexNet [
27], Lee et al. [
3], and the proposed method in the fourth row.
As shown in
Figure 8, the method of Cucchiara et al. [
8] cannot discriminate shadow and non-shadow pixels, in most cases. The method of Sanin et al. [
15] shows good results, showing light shadows. However, it does not show good results when a shadow is dark and similar to an object. Leone et al. [
17] proposed a method showing better detection performance than the method by Cucchiara et al. [
8], but still produces frequent errors. The method of Hsieh et al. [
19], as shown in
Figure 8a, produces good detection performance when a shadow cast beside a man, but degrades when the shadow is cast under a man, as shown in
Figure 8b. The method of Huang et al. [
20] shows better detection performance than using only color information, but still does not produce a good result. The Euclidean distance by 4096 features of the first FCL [
41] also contains detection errors. This is because, although optimal features are obtained by CNN, the Euclidean distance-based linear classifier is used without the FCL nonlinear classifier of the third column of
Table 2, which increases the detection errors. In the case where AlexNet [
27] is used, the result image is close to the ground truth image and the result image of the proposed method. However, as shown in
Table 7, the proposed method has higher detection accuracy. The accuracy by [
3] is lower than our method as shown in
Figure 8. That is because in their method [
3], the separation of shadow region from pedestrian is done only by vertical line, and accurate position of shadow pixel in various direction cannot be detected as shown in the second image of the 4th row ones of
Figure 8a. In addition, the shadow at the lower position of the pedestrian cannot be detected as shown in the second image of the 4th row ones of
Figure 8b.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}