An Enhanced Hidden Markov Map Matching Model for Floating Car Data

Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Description
2.2. Model Schema
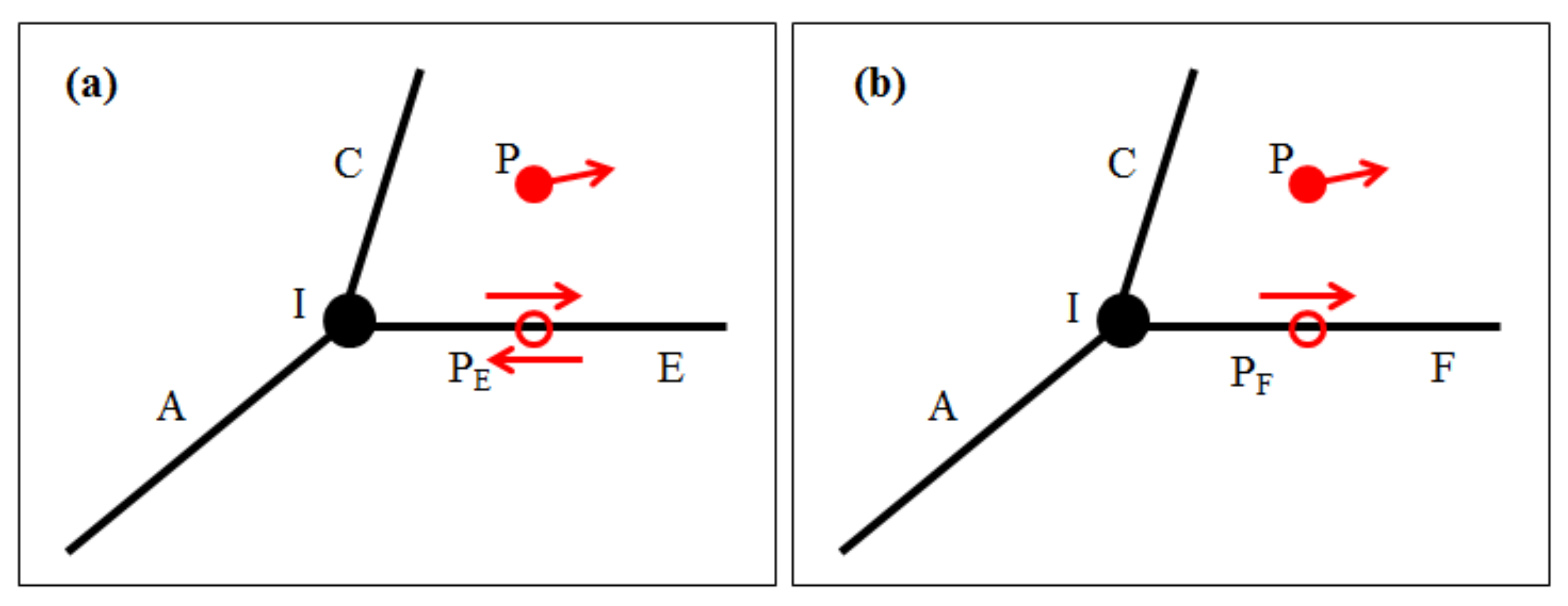
2.2.1. Definitions
2.2.2. Observation Probability
2.2.3. Transmission Probability
2.2.4. Matching Solution
2.3. Reference Models
2.4. Evaluation and Analysis Approaches
3. Results Analysis
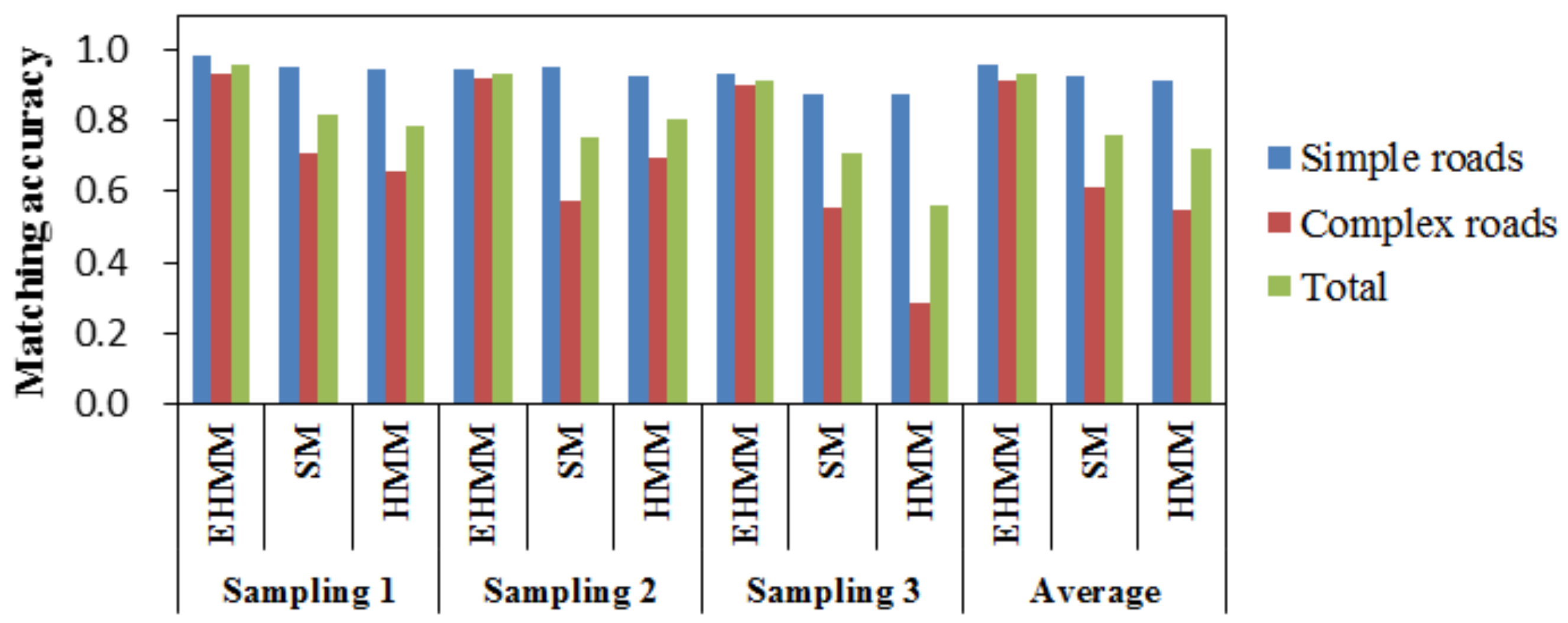
3.1. Evaluation of Matching Accuracy at a High Sampling Rate
3.2. Comparison of Matching Accuracy at Various Sampling Rates
3.3. Analysis of the Running Time
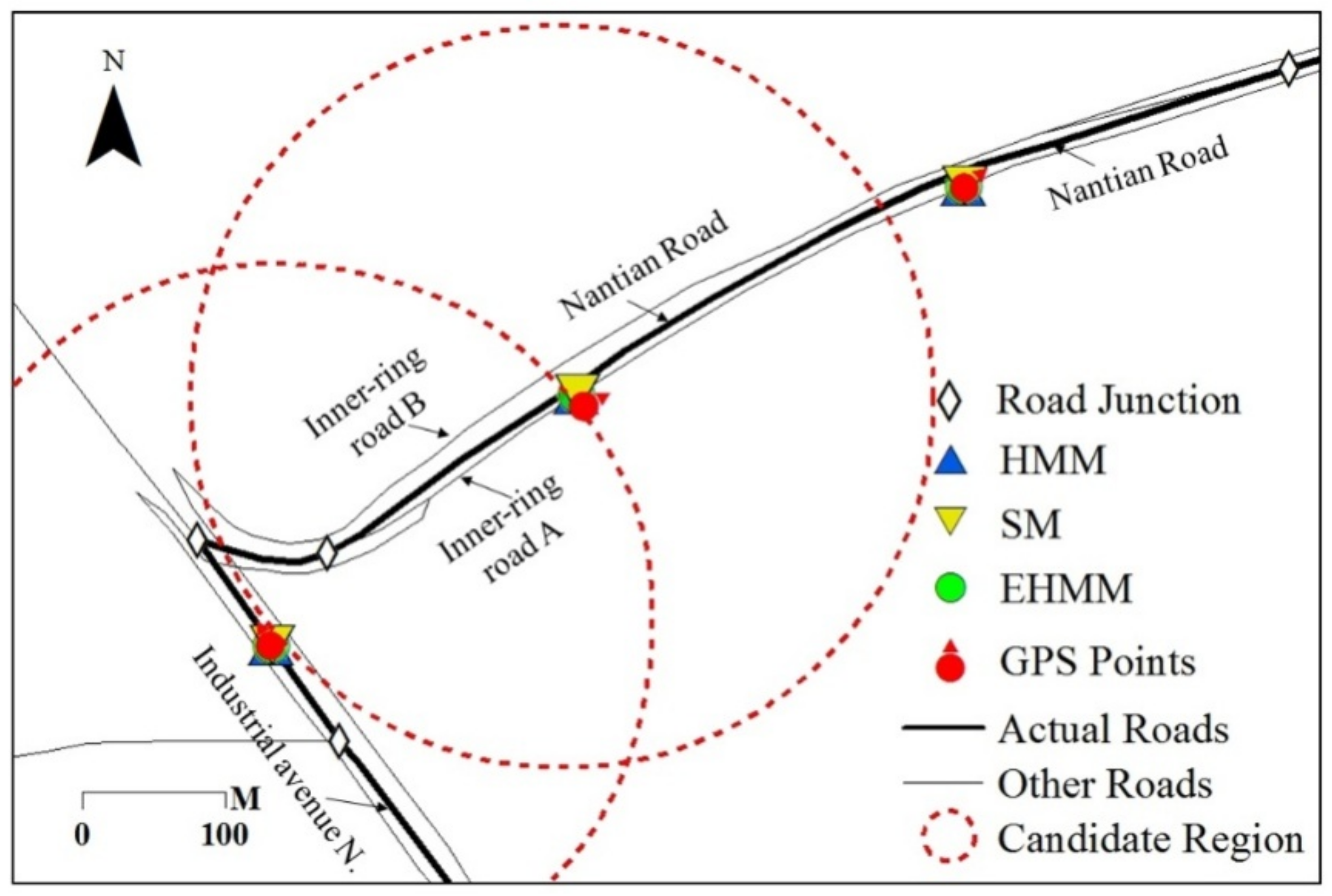
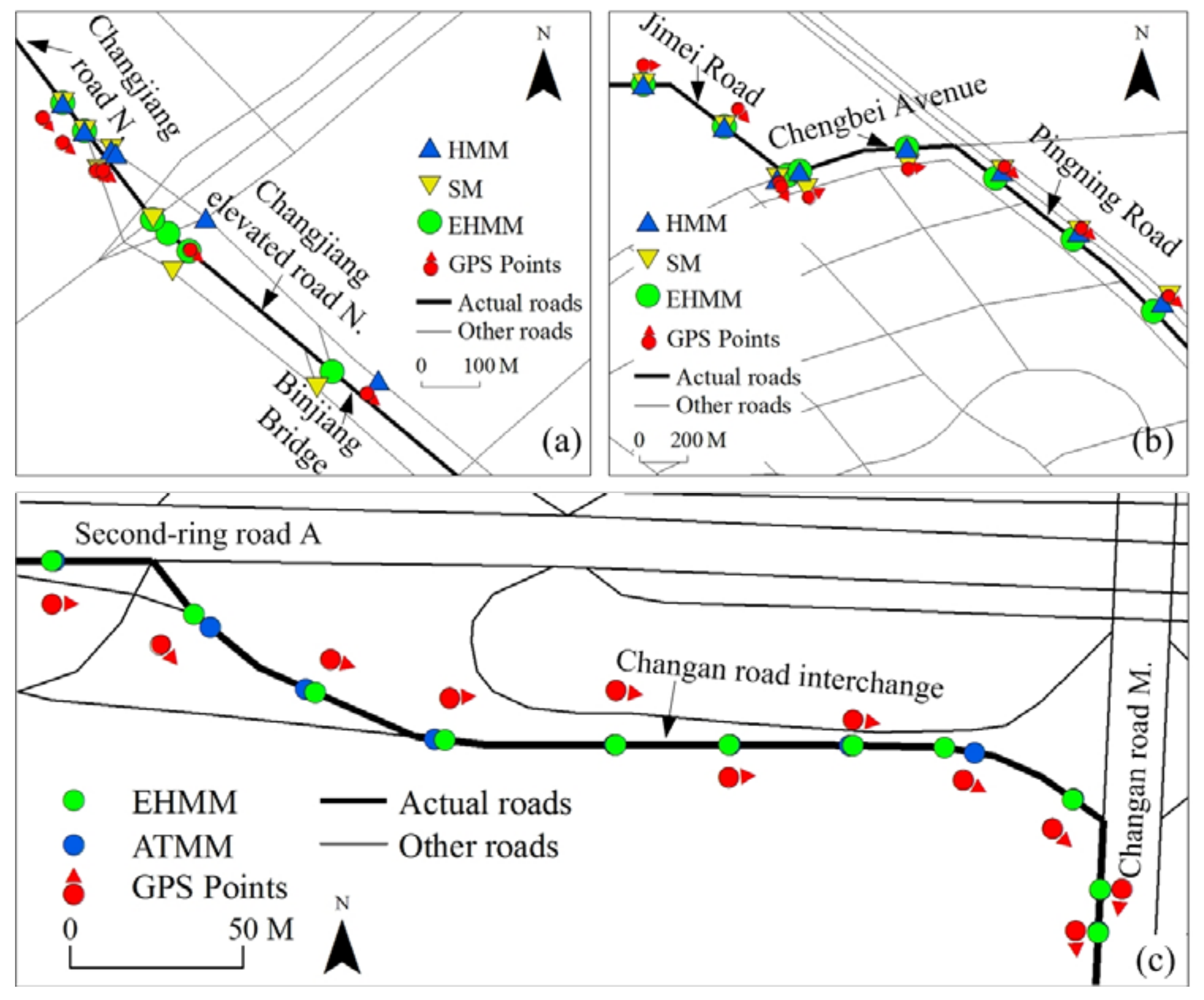
3.4. Results on Real Data
4. Discussion
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Jimenez, F.; Monzon, S.; Naranjo, J.E. Definition of an enhanced map-matching algorithm for urban environments with poor GNSS signal quality. Sensors 2016, 16, 193. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Xie, L.H.; Lai, X.J. Route reconstruction from floating car data with low sampling rate based on feature matching. Res. J. Appl. Sci. Eng. Technol. 2013, 6, 2153–2158. [Google Scholar] [CrossRef]
- Brakatsoulas, S.; Pfoser, D.; Salas, R.; Wenk, C. On Map-Matching Vehicle Tracking Data. In Proceedings of the 31st VLDB Conference, Trondheim, Norway, 30 August–2 September 2005; pp. 853–864. [Google Scholar]
- Pfoser, D.; Jensen, C.S. Capturing the uncertainty of moving-object representations. In Advances in Spatial Databases; Springer: Berlin/Heidelberg, Germany, 1999; pp. 111–131. [Google Scholar]
- Quddus, M.A.; Ochieng, W.Y.; Noland, R.B. Current map matching algorithms for transport applications: State-of-the art and future research directions. Transp. Res. C Emerg. Technol. 2007, 15, 312–328. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.; Yue, C. Application of improved map matching algorithm in vehicle navigation system. J. Inf. Eng. Univ. 2008, 9, 115–117, (In Chinese with English Abstract). [Google Scholar]
- Loomis, P.V.W. Vehicle Navigation by Dead Reckoning and GNSS-Aided Map-Matching. Patent Wo 2018/057425 A1, 29 March 2018. [Google Scholar]
- Koponen, L.; Sun, R. Methods and Systems for Map Matching. Patent Wo 2018/019984 A1, 1 February 2018. [Google Scholar]
- Goh, C.Y.; Dauwels, J.; Mitrovic, N.; Asif, M.T.; Oran, A.; Jaillet, P. Online Map-Matching Based on Hidden Markov Model for Real-Time Traffic Sensing Applications. In Proceedings of the 2012 15th International IEEE Conference on Intelligent Transportation Systems (ITSC), Anchorage, AK, USA, 16–19 September 2012. [Google Scholar]
- Alt, H.; Godau, M. Computing the Fréchet distance between two polygonal curves. Int. J. Comput. Geom. Appl. 1955, 5, 75–91. [Google Scholar] [CrossRef]
- Fréchet, M.M. Sur Quelques Points du Calcul Fonctionnel. Rendiconti del Circolo Matematico di Palermo (1884–1940) 1906, 22, 1–72. [Google Scholar] [CrossRef]
- Cao, K.; Tang, J.; Liu, R. Intelligent map-matching algorithm using Frechet distance measure based. Comput. Eng. Appl. 2007, 43, 223–226, (In Chinese with English Abstract). [Google Scholar]
- Lou, Y.; Zhang, C.; Zheng, Y.; Xie, X.; Wang, W.; Huang, Y. Map-matching for low-sampling-rate GPS trajectories. In Proceedings of the 17th ACM Sigspatial International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2009; pp. 352–361. [Google Scholar]
- Hart, P.; Nilsson, N.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Chandio, A.A.; Tziritas, N.; Zhang, F.; Xu, C.-Z. An approach for map-matching strategy of GPS-trajectories based on the locality of road networks. In Internet of Vehicles—Safe and Intelligent Mobility; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9502, pp. 234–246. [Google Scholar]
- Chandio, A.A.; Tziritas, N.; Zhang, F.; Yin, L.; Xu, C.-Z. Towards adaptable and tunable cloud-based map-matching strategy for GPS trajectories. Front. Inf. Technol. Electron. Eng. 2016, 17, 1305–1319. [Google Scholar] [CrossRef]
- Hsueh, Y.-L.; Chen, H.-C. Map matching for low-sampling-rate GPS trajectories by exploring real-time moving directions. Inf. Sci. 2018, 433–434, 55–69. [Google Scholar] [CrossRef]
- Haibin, S.; Jiansheng, T.; Chaozhen, H. A Integrated Map Matching Algorithm based on Fuzzy Theory for Vehicle Navigation System. In Proceedings of the 2006 International Conference on Computational Intelligence and Security, Guangzhou, China, 3–6 November 2006; pp. 916–919. [Google Scholar]
- Kim, S.; Kim, J.H. Adaptive fuzzy-network-based -measure map-matching algorithm for car navigation system. IEEE Trans. Ind. Electron. 2001, 48, 432–441. [Google Scholar]
- He, Z.-C.; Xi-wei, S.; Nie, P.-L.; Zhuang, L.-J. On-line map-matching framework for floating car data with low sampling rate in urban road networks. IET Intell. Transp. Syst. 2013, 7, 404–414. [Google Scholar] [CrossRef]
- Quddus, M.A.; Noland, R.B.; Ochieng, W.Y. A high accuracy fuzzy logic based map matching algorithm for road transport. J. Intell. Transp. Syst. 2006, 10, 103–115. [Google Scholar] [CrossRef] [Green Version]
- Syed, S.; Cannon, M.E. Fuzzy logic based-map matching algorithm for vehicle navigation system in urban canyons. Presented at the ION National Technical Meeting, San Diego, CA, USA, 26–28 January 2004; Volume 26–28. [Google Scholar]
- Newson, P.; Krumm, J. Hidden Markov Map Matching through Noise and Sparseness; Microsoft Research: New York, NY, USA, 2009. [Google Scholar]
- Raymond, R.; Morimura, T.; Osogami, T. Map Matching with Hidden Markov Model on Sampled Road Network. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR 2012), Tsukuba, Japan, 11–15 November 2012; pp. 2242–2245. [Google Scholar]
- Szwed, P.; Pekala, K. An Incremental Map-Matching Algorithm based on Hidden Markov Model. In Proceedings of the 14th International Conference Artificial Intelligence and Soft Computing, Zakopane, Poland, 14–18 June 2015; Volume 8468. [Google Scholar]
- Ren, M.; Karimi, H.A. A hidden Markov model-based map-matching algorithm for wheelchair navigation. J. Navig. 2009, 62, 383–395. [Google Scholar] [CrossRef]
- Velaga, N.R.; Quddus, M.A.; Bristow, A.L. Developing an enhanced weight-based topological map-matching algorithm for intelligent transport systems. Transp. Res. C Emerg. Technol. 2009, 17, 672–683. [Google Scholar] [CrossRef] [Green Version]
- Quddus, M.; Washington, S. Shortest path and vehicle trajectory aided map-matching for low frequency GPS data. Transp. Res. C Emerg. Technol. 2015, 55, 328–339. [Google Scholar] [CrossRef] [Green Version]
- Velaga, N.R. Development of a Weight-Based Topological Map-Matching Algorithm and an Integrity Method for Location-Based ITS Services. Ph.D. Thesis, Loughborough University, Loughborough, UK, 2010. [Google Scholar]
- Zhao, X.; Cheng, X.; Zhou, J.; Xu, Z.; Dey, N.; Ashour, A.S.; Satapathy, S.C. Advanced topological map matching algorithm based on D-S theory. Arabian J. Sci. Eng. 2017, 1–12. [Google Scholar] [CrossRef]
- Obradovic, D.; Lenz, H.; Schupfner, M. Fusion of map and sensor data in a modern car navigation system. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2006, 45, 111–122. [Google Scholar] [CrossRef]
- Wang, H.; Li, J.; Hou, Z.; Fang, R.; Mei, W.; Huang, J. Research on parallelized real-time mapmatching algorithm for massive GPS data. Clust. Comput. 2017, 20, 1123–1134. [Google Scholar] [CrossRef]
- Gustafsson, F.; Gunnarsson, F.; Bergman, N.; Forssell, U.; Jansson, J.; Karlsson, R.; Nordlund, P.J. Particle filters for positioning, navigation and tracking. IEEE Trans. Signal Process. 2002, 50, 1–11. [Google Scholar] [CrossRef]
- Yu, C.; Lan, H.; Liu, Z.; El-Sheimy, N.; Yu, F. Indoor Map Aiding/Map Matching Smartphone Navigation Using Auxiliary Particle Filter. In China Satellite Navigation Conference (CSNC) 2016 Proceedings: Volume I; Springer: Singapore, 2016; pp. 321–331. [Google Scholar]
- Nikolić, M.; Jović, J. Implementation of generic algorithm in map-matching model. Expert Syst. Appl. 2017, 72, 283–292. [Google Scholar] [CrossRef]
- Xiao, Z.; Wen, H.; Markham, A.; Trigoni, N. Lightweight Map Matching for Indoor Localisation Using Conditional Random Fields. In Proceedings of the 13th International Symposium on Information Processing in Sensor Networks, Berlin, Germany, 15–17 April 2014; pp. 131–142. [Google Scholar]
- Bierlaire, M.; Chen, J.; Newman, J. A probabilistic map matching method for smartphone GPS data. Transp. Res. C Emerg. Technol. 2013, 26, 78–98. [Google Scholar] [CrossRef]
- Hashemi, M.; Karimi, H.A. A critical review of real-time map-matching algorithms: Current issues and future directions. Comput. Environ. Urban Syst. 2014, 48, 153–165. [Google Scholar] [CrossRef]
- Jagadeesh, G.R.; Srikanthan, T. Online map-matching of noisy and sparse location data with hidden Markov and route choice models. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2423–2434. [Google Scholar] [CrossRef]
- Huang, J.; Qie, J.; Liu, C.; Li, S.; Weng, J.; Lv, W. Cloud computing-based map-matching for transportation data center. Electron. Commer. Res. Appl. 2015, 14, 431–443. [Google Scholar] [CrossRef]
- Chen, C.; Ding, Y.; Xie, X.; Zhang, S. A three-stage online map-matching algorithm by fully using vehicle heading direction. J. Ambient Intell. Humaniz. Comput. 2018, 1–11. [Google Scholar] [CrossRef]
- Miwa, T.; Kiuchi, D.; Yamamoto, T.; Morikawa, T. Development of map matching algorithm for low frequency probe data. Transp. Res. C Emerg. Technol. 2012, 22, 132–145. [Google Scholar] [CrossRef]
- Liu, X.; Liu, K.; Li, M.; Lu, F. A st-crf map-matching method for low-frequency floating car data. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1241–1254. [Google Scholar] [CrossRef]
- Forney, G.D. The viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Routes | Matching Accuracy | Running Time Per Point (ms) | ||||
|---|---|---|---|---|---|---|
| EHMM | SM | HMM | EHMM | SM | HMM | |
| Route 2 | 0.89 | 0.81 | 0.84 | 196 | 202 | 200 |
| Route 3 | 0.90 | 0.76 | 0.80 | 98 | 138 | 134 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Che, M.; Wang, Y.; Zhang, C.; Cao, X. An Enhanced Hidden Markov Map Matching Model for Floating Car Data. Sensors 2018, 18, 1758. https://doi.org/10.3390/s18061758
Che M, Wang Y, Zhang C, Cao X. An Enhanced Hidden Markov Map Matching Model for Floating Car Data. Sensors. 2018; 18(6):1758. https://doi.org/10.3390/s18061758
Chicago/Turabian StyleChe, Mingliang, Yingli Wang, Chi Zhang, and Xinliang Cao. 2018. "An Enhanced Hidden Markov Map Matching Model for Floating Car Data" Sensors 18, no. 6: 1758. https://doi.org/10.3390/s18061758
APA StyleChe, M., Wang, Y., Zhang, C., & Cao, X. (2018). An Enhanced Hidden Markov Map Matching Model for Floating Car Data. Sensors, 18(6), 1758. https://doi.org/10.3390/s18061758