4.3. Image Databases
Extensive experiments were conducted on five benchmark databases, including two remote sensing image databases (RSSCN7 and AID), two textural image datasets (Outex-00013 and Outex-00014), and one object image database (ETHZ-53). The details of these datasets are summarized as follows:
The RSSCN7 [
41] is a publicly available remote sensing dataset produced by different remote imaging sensors. It consists of seven land-use categories, such as industrial region, farm land, residential region, parking lot, river lake, forest and grass land. For each category, there are 400 images with size of 400 × 400 in JPG format. Some sample images are shown in
Figure 5a, in which each row represents one category. Note that there are images with rotation and resolution differences in the same category. Thus, the RSSCN7 dataset can not only verify the effective of the proposed descriptor but also inspect the robustness of different rotations and resolutions. The RSSCN7 dataset can be downloaded from
https://www.dropbox.com/s/j80iv1a0mvhonsa/RSSCN7.zip?dl=0.
- 2.
AID database
The aerial image dataset (AID) [
40] is also a publicly available large-scale remote sensing dataset produced by different remote imaging sensors. It contains 10,000 images in 30 categories, for example, airport, bare land, meadow, beach, park, bridge, forest, railway station, and baseball field. Each category includes different numbers of images varying from 220 to 420 with size of 600 × 600 in JPG format. Some sample images are shown in
Figure 5b, in which each row is one category. Similar to RSSCN7, there are images with rotation and resolution differences in the same category. The AID dataset can be downloaded from
http://www.lmars.whu.edu.cn/xia/AID-project.html.
- 3.
Outex-00013
The Outex-00013 [
46] is a publicly available color texture dataset produced by an Olympus Camedia C-2500 L digital camera. It contains 1360 images in 68 categories, for example, wool, fabric, cardboard, sandpaper, natural stone and paper. Each category includes 20 images, each with size of 128 × 128 in BMP format. Some sample images from Outex-00013 are shown in
Figure 5c, in which each row represents one category. There is no difference in the same category. The Outex-00013 dataset can be downloaded from
http://www.outex.oulu.fi/index.php?page=classification.
- 4.
Outex-00014
The Outex-00014 [
46] is also a publicly available color texture dataset produced by an Olympus Camedia C-2500 L digital camera. It contains 4080 images in 68 categories, for example, wool, fabric, cardboard, sandpaper, natural stone, and paper. Each category includes 20, each with size of 128 × 128 images in BMP format. Some sample images from Outex-00014 are shown in
Figure 5d, in which each row represents one category. All images are produced under three different illuminants: the 4000 K fluorescent TL84 lamp, the 2856 K incandescent CIE A and the 2300 K horizon sunlight. The Outex-00014 dataset can also be downloaded from
http://www.outex.oulu.fi/index.php?page=classification.
- 5.
ETHZ-53
The ETHZ-53 [
45] is a publicly available object dataset collected by a color camera. It contains 265 images in 53 objects, such as cup, shampoo, vegetable, fruit, and car model. Each object includes 5 images, each with size of 320 × 240 in BNG format. Some sample images are shown in
Figure 5e, in which each row represents one category. Note that each object is with 5 different angles. The ETHZ-53 dataset can be downloaded from
http://www.vision.ee.ethz.ch/en/datasets/.
4.7. Comparison with Other Fusion-Based Descriptors
To illustrate the effectiveness and robustness of hybrid histogram descriptor (HHD), it is compared with nine fusion-based feature descriptors and the fusion of the perceptually uniform histogram and motif co-occurrence matrix (flagged as “PUH + MCM”) on the RSSCN7, AID, Outex-00013, Outex-00014 and ETHZ-53 datasets. All comparative methods are detailed as follows:
- (1)
mdLBP [
30]: The 2048-dimensional multichannel adder local binary patterns by combining three LBP maps extracted from the R, G and B channels.
- (2)
maLBP [
30]: The 1024-dimensional multichannel decoded local binary patterns by combining three LBP maps extracted from the R, G and B channels.
- (3)
CDH [
15]: The 90-dimensional color histogram obtained by quantizing the L*a*b* color space and the 18-dimensional edge orientation histogram extracted from the L*a*b* color space.
- (4)
MSD [
14]: The 72-dimensional color histogram obtained by quantizing the HSV color space and the 6-dimensional edge orientation histogram extracted from the HSV color space.
- (5)
LNDP + LBP [
31]: The 512-dimensional local neighborhood difference pattern extracted from the grey-scale space and the 256-dimensional LBP extracted from the grey-scale space.
- (6)
MPEG-CED [
25]: The 256-dimensional color histogram descriptor (CHD) extracted from the RGB color space, and the 5-dimensional edge histogram extracted from the HSV color space.
- (7)
Joint colorhist [
12]: The 512-dimensional color histogram obtained by combining the quantized R, G and B channels.
- (8)
OCLBP [
47]: The fusion of the 1536-dimensional opponent color local binary patterns extracted from the RGB color space.
- (9)
IOCLBP [
46]: The fusion of the 3072-dimensional improved opponent color local binary patterns extracted from the RGB color space.
- (10)
PUH + MCM: The fusion of the 148/364-dimensional perceptually uniform histogram (PUH) extracted from the L*a*b* color space and the 36-dimensional motif co-occurrence matrix (MCM) extracted from the grey-scale space.
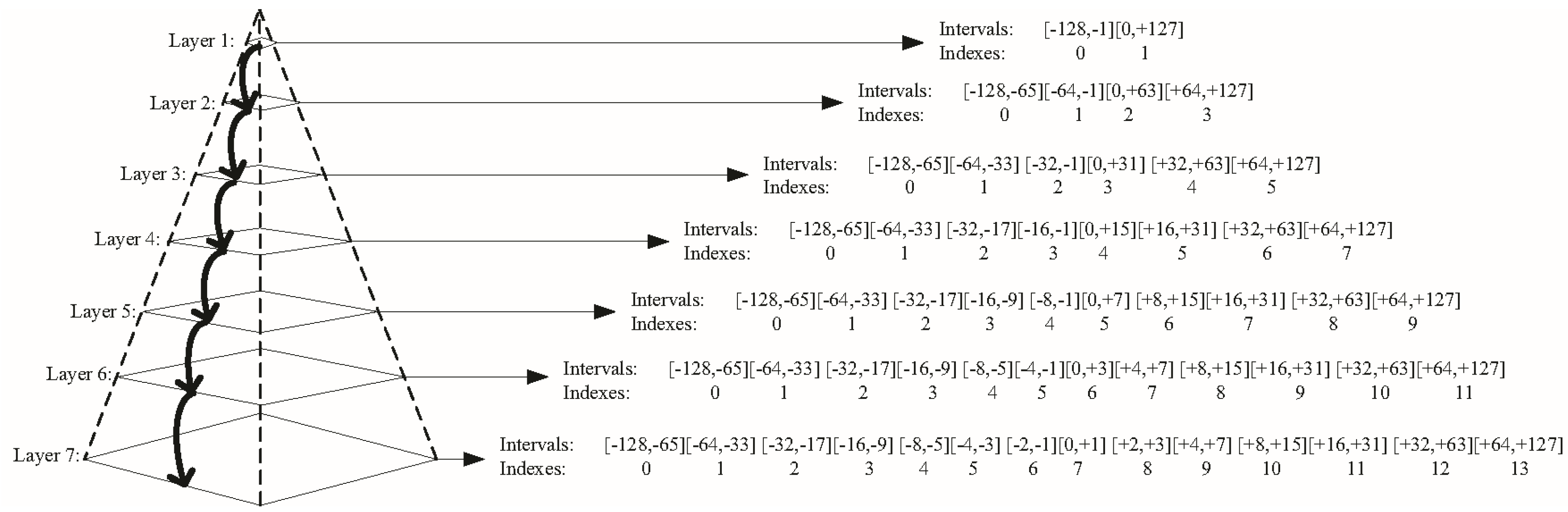
- (11)
HHD: The fusion of the 148/364-dimensional perceptually uniform histogram (PUH) and the 81-dimensional motif co-occurrence histogram (MCH) extracted from the L* channel.
Quantitative and Qualitative performance valuations are performed from the following seven perspectives: the average precision rate (APR) value, the average recall rate (ARR) value, the average precision rate versus number of top matches (APR vs. NTM), the average recall rate versus number of top matches (ARR vs. NTM), the top-10 retrieved images, the precision–recall curve and the computational complexity. Meanwhile, the robustness of rotation, illumination and resolution is also illustrated in our comparative experiments. To guarantee the accuracy of the experiments, all experiments are performed under the principle of leave-one-out cross-validation.
Table 8 reports the comparisons between the proposed descriptors and the former schemes in terms of average precision rate (APR) and average recall rate (ARR). Bold values highlight the best values. In
Table 8, it can be seen that HHD yields the highest APR and ARR compared to all former existing schemes on five datasets. For example, the {APR, ARR} of HHD on RSSCN7 outperforms mdLBP, maLBP, CDH, MSD, LNDP + LBP, MPEG-CED, OCLBP, IOCLBP and PUH + MCM by {6.47%, 0.16%}, {8.69%, 0.22%}, {5.97%, 0.15%} and {11.13%, 0.28%}, {10.11%, 0.25%}, {4.18%, 0.11%}, {6.75%, 0.17%}, {8.87%, 0.24%}, {9.61%, 0.24%} and {5.63%, 0.14%}, respectively. Similarly, more significant values are reported over AID, Outex-13, Outex-14 and ETHZ-53. From these results, the effectiveness of the proposed descriptor is demonstrated by comparing with other fusion-based feature descriptors in terms of APR and ARR. In addition, since there are various rotation and resolution differences on RSSCN7 and AID datasets (see
Figure 5a,b), and various illumination differences on Outex-00014 dataset (see
Figure 5d), the robustness of the rotation, resolution and illumination is also well illustrated to some extent.
Figure 6a–j shows the performance comparison between HHD and existing approaches in terms of average precision rate versus number of top matches (APR vs. NTM) and average recall rate versus number of top matches (ARR vs. NTM). To guarantee the accuracy and reproducibility, the number of top matches is set to 100, 200, 20, 20 and 5 on RSSCN7, AID, Outex-00013, Outex-00014 and ETHZ-53, respectively. In
Figure 6a,b, HHD achieves an obviously higher performance than all other fusion-based feature descriptors on RSSCN7. Meanwhile, we also note that the APR vs. NTM and ARR vs. NTM curves of mdLBP, maLBP, CDH, MSD, LNDP + LBP, MPEG-CED, Joint Colorhist, OCLBP, IOCLBP and PUH + MCM are close to one another extremely. The reason is that only seven land-use categories are very challenging to retrieve the targeted images from RSSCN7. As shown in
Figure 6c,d, the APR vs. NTM and ARR vs. NTM curves of HHD achieve an obviously higher curvature than all other descriptors on AID. This phenomenon illustrates that the proposed descriptor can acquire better performance on the large-scale dataset. As expected, as shown in
Figure 6e–j, HHD still outperforms all other existing descriptors over Outex-00013, Outex-00014 and ETHZ-53, respectively. Specifically, PUM + MCM and HHD are superior to other descriptors on ETHZ-53 obviously. The main reason is that they not only combine the color and edge information, but also integrate the texture information. Based on the above results, the effectiveness of the proposed descriptor is demonstrated by comparing with other fusion-based methods in terms of APR vs. NTM and ARR vs. NTM.
Figure 7a–e shows the performance comparison of the top-10 retrieved images using different methods. The leftmost image in each row of
Figure 7a–e is the query image, and the remaining images are a set of retrieved images ordered in ascending order from left to right. For clarity, if a retrieved image owns the same group label as the query, it is flagged as a green frame; otherwise, it is flagged as a red frame. In
Figure 7a, there are 7 related images to the query image “River Lake” from RSSCN7 using mdLBP, 8 using maLBP, 8 using CDH, 4 using MSD, 9 using LNDP + LBP, 3 using MPEG-CED, 3 using Joint Colorhist, 8 using OCLBP, 7 using IOCLBP, 4 using PUH + MCM and 10 using HHD. Note that, although the images from “Forest” have a similar color to “River Lake”, leading to the error results by most of the existing schemes, HHD can retrieve the targeted images accurately. In
Figure 7b, for the query image “Baseball Field” from AID, the number of targeted images using mdLBP, maLBP, CDH, MSD, LNDP + LBP, MPEG-CED, Joint Colorhist, OCLBP, IOCLBP, PUH + MCM, and HHD descriptors are 7, 7, 9, 6, 5, 9, 5, 8, 9, 9 and 10, respectively. It can be seen that HHD not only displays a better retrieval result than all other descriptors, but also shows the robustness of rotation and resolution differences. In
Figure 7c, for the query image “Rice” from Outex-00013, the precision achieved by using mdLBP, maLBP, CDH, MSD, LNDP + LBP, MPEG-CED, Joint Colorhist, PUH + MCM, and HHD descriptors are 40%, 40%, 80%, 70%, 30%, 80%, 80%, 90% and 100%, respectively. In comparison, we can see that although all retrieved images show a similar content appearance, yet HHD still outperforms all other descriptors. In
Figure 7d, for the query image “Carpet” from Outex-00014, the precision obtained by using mdLBP, maLBP, CDH, MSD, LNDP + LBP, MPEG-CED, Joint Colorhist, OCLBP, IOCLBP, PUH + MCM, and HHD descriptors are 40%, 30%, 70%, 10%, 30%, 40%, 30%, 70%, 50%, 50% and 100%, respectively. As shown in
Figure 7e, for the query image “Paper Bag” from ETHZ-53, HHD still outperforms all other existing descriptors. From the above results, we can conclude that HHD not only depicts the image semantic information with similar textural structure appearance but also discriminates the color and texture differences, effectively. In summary, the effectiveness of the proposed descriptor is demonstrated by comparing with existing approaches in terms of the top-10 retrieved images.
Figure 8a–e shows the performance comparison of the proposed HHD with existing approaches over RSSCN7, AID, Outex-00013 and Outex-00014 in terms of the precision–recall curve. According to
Figure 8a,b, it can be observed that the precision–recall curve of HHD is obviously superior to all other fusion-based approaches. According to
Figure 8c,d, it can be seen that the precision–recall curve of other fusion-based approaches is inferior to HHD over Outex-00013 and Outex-00014 obviously. Moreover, as shown in
Figure 8e, both HHD and PUH + MCM are higher than mdLBP, maLBP, CDH, MSD, LNDP + LBP, OCLBP, IOCLBP, and Joint Colorhist on ETHZ-53. The reasons can be summarized as follows:
- (1)
Joint Colorhist, mdLBP, maLBP and LNDP + LBP only extract an independent color or texture information.
- (2)
CDH, MSD and MPEG-CED consider the color and edge orientation information from different channels, while the texture information is ignored.
- (3)
OCLBP and IOCLBP combine the color and texture information, but the edge orientation information is lost.
- (4)
Although PUH + MCM integrates the color, edge orientation and texture information as a whole, the perceptually uniform motif patterns are lost.
- (5)
HHD not only integrates the merits of the color, edge orientation and texture information, but also considers the perceptually uniform motif patterns.
Depending upon the above results and analyses, the effectiveness of the proposed descriptor is demonstrated by comparing with other fusion-based methods in terms of the precision–recall curve.
Table 9 shows the feature vector length, average retrieval time, and memory cost per image of different descriptors to provide an in-depth evaluation of the computational complexity. All experiments are carried out on a computer with Intel Core
[email protected] GHz CPU processor, 4 cores active and 16 GB RAM. The feature vector length is compared by dimension (D). The average retrieval time is analyzed by seconds (S). The memory cost per image is measured in kilobytes (KB). Similar to PUM + MCM, the items of 445/229 (D) and 3.48/1.79 (KB) represent HHD with 445 dimensions and 3.48 kilobytes performing retrieval over RSSCN7, AID and ETHZ-53 databases, as well as HHD with 229 dimensions and 1.79 kilobytes performing retrieval over Outex-00013 and Outex-00014 databases. For RSSCN7, AID and ETHZ-53, the feature vector length and the memory cost per image of HHD are inferior to those of MSD, CDH, MPEG-CED and PUM + MCM, while HHD are superior to Joint Colorhist, maLBP, mdLBP, OCLBP, IOCLBP and LNDP + LBP For Outex-00013 and Outex-00014, the feature vector length and the memory cost per image of HHD are worse than MSD, CDH and PUM + MCM, but it is better than MPEG-CED, Joint Colorhist, maLBP, mdLBP, OCLBP, IOCLBP and LNDP + LBP. For the average retrieval time, HHD is more than MSD, CDH, MPEG-CED and PUM + MCM, yet HHD is less than Joint Colorhist, maLBP, mdLBP, OCLBP, IOCLBP and LNDP + LBP. The main reason is that the RSSCN7, AID and ETHZ-53 databases have more complex contents as compared with the Outex-00013 and Outex-00014 image databases. Although HHD does not outperform all other fusion-based descriptors, the usability and practicability of HHD is indicated under the content-based image retrieval framework configuration: adaptive feature vector length, competitive average retrieval time, and acceptable memory cost per image.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}