Modeling and Characterization of Traffic Flows in Urban Environments

 ,
,  ,
,  ,
,  and
and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Overview of the Simulation Tools Used
3.1. SUMO
3.2. O-D Matrix Generation with DFROUTER
4. Methodology
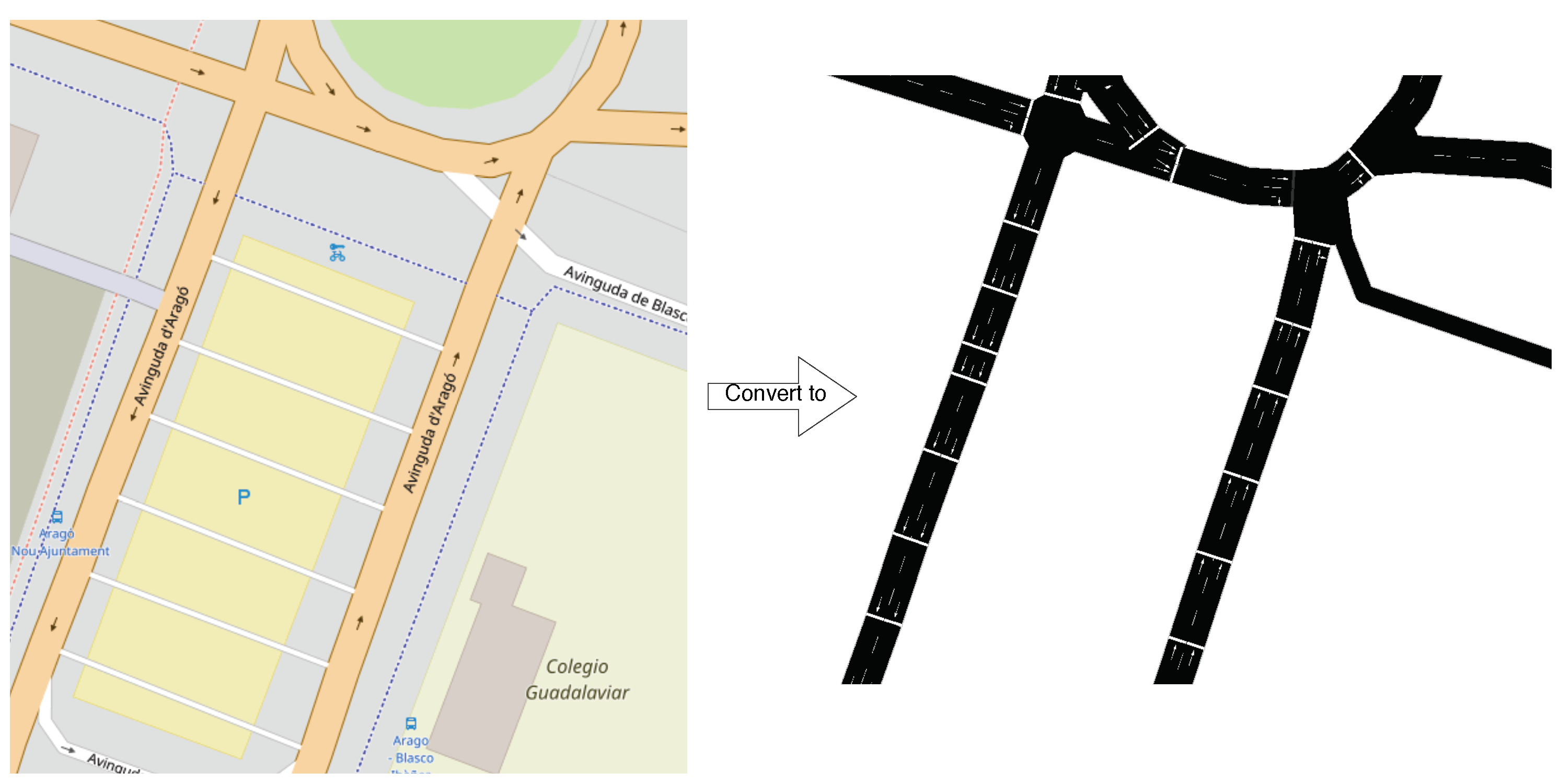
4.1. Unifying Segments
- Streets are partitioned into tiny segment sizes, often measuring less than 7.5 m (size of a vehicle plus inter-vehicular security gap).
- Such small sizes do not allow to characterize the segment profile correctly.
- Inconsistent graphs are obtained when applying the regression analysis to predict traffic behavior.
- The street to be reunified must be a set of partitioned segments.
- The adjacent segment should not have another segment that intersects it.
- The street ID codes must be the same for segments to be reunified.
- Segments to be reunified must have consecutive numbers in their sequential part of the ID.
| Algorithm 1 Segment reunification strategy. |
|
4.2. Per-Segment Travel Time Prediction
| Algorithm 2 Extraction of travel times vs. load samples. |
|
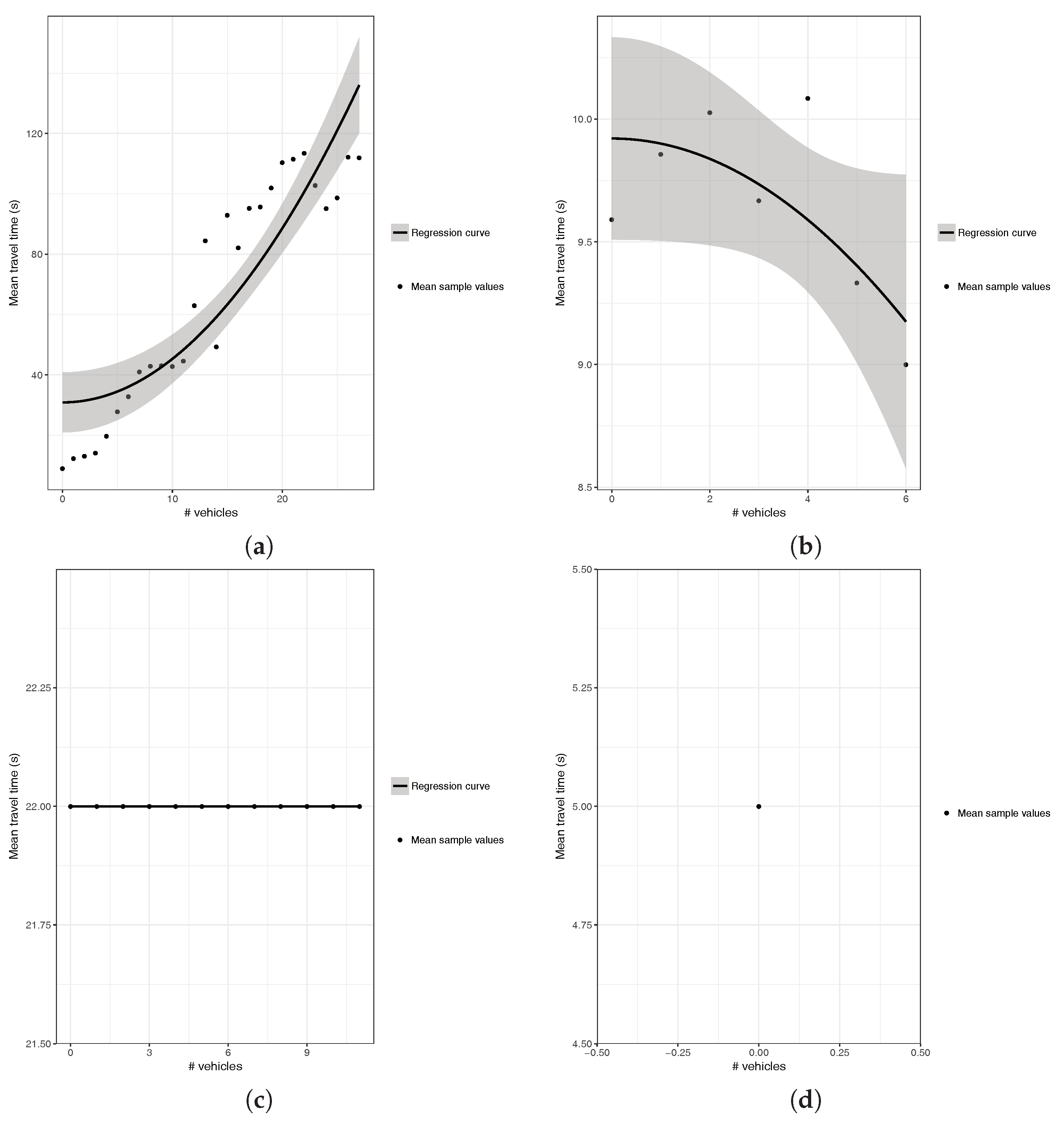
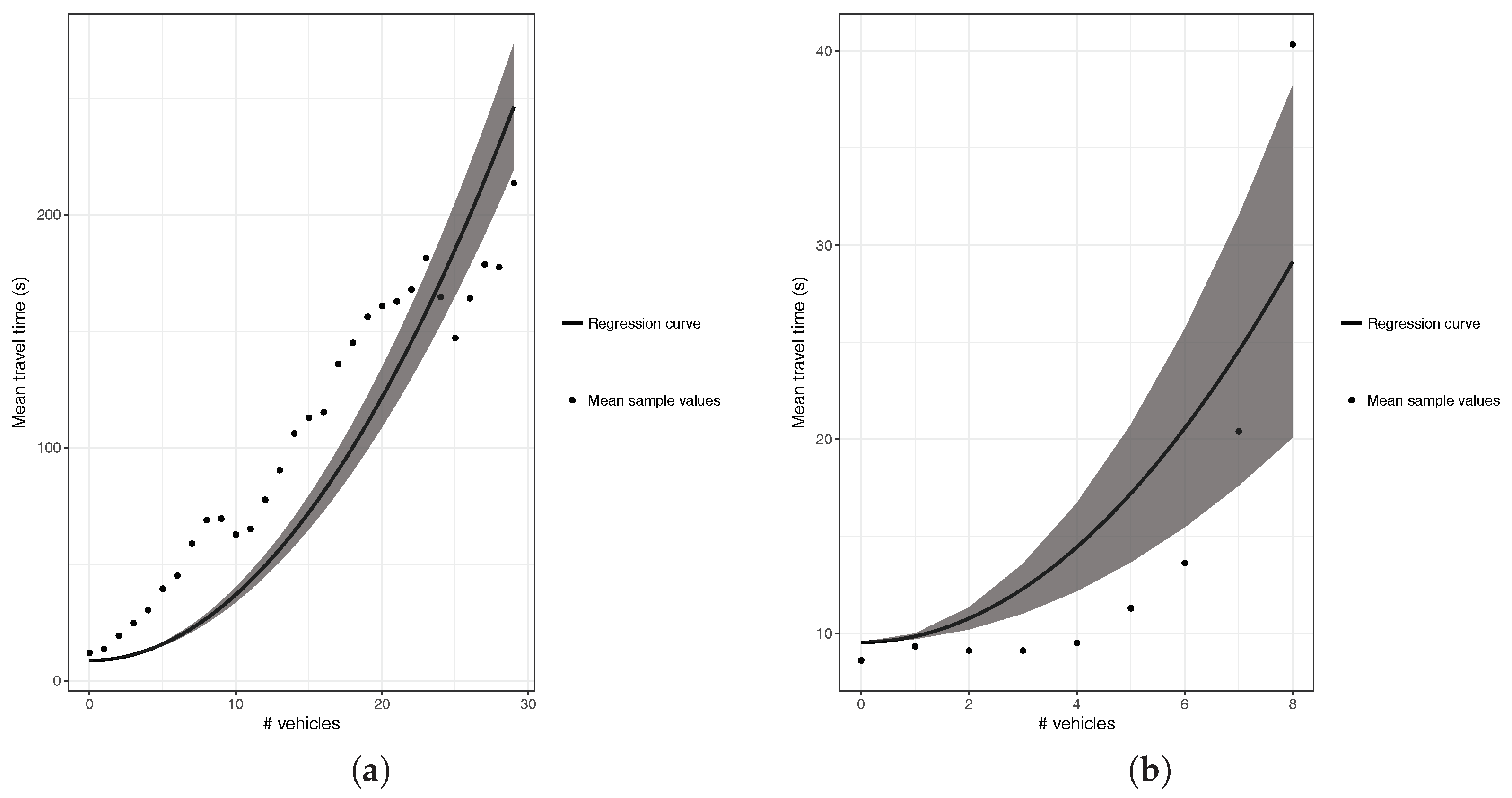
4.3. Segment Behavior Characterization with Polynomial Regression
5. Proposed Predictor of Vehicular Travel Times
6. Traffic Congestion Behavior Analysis
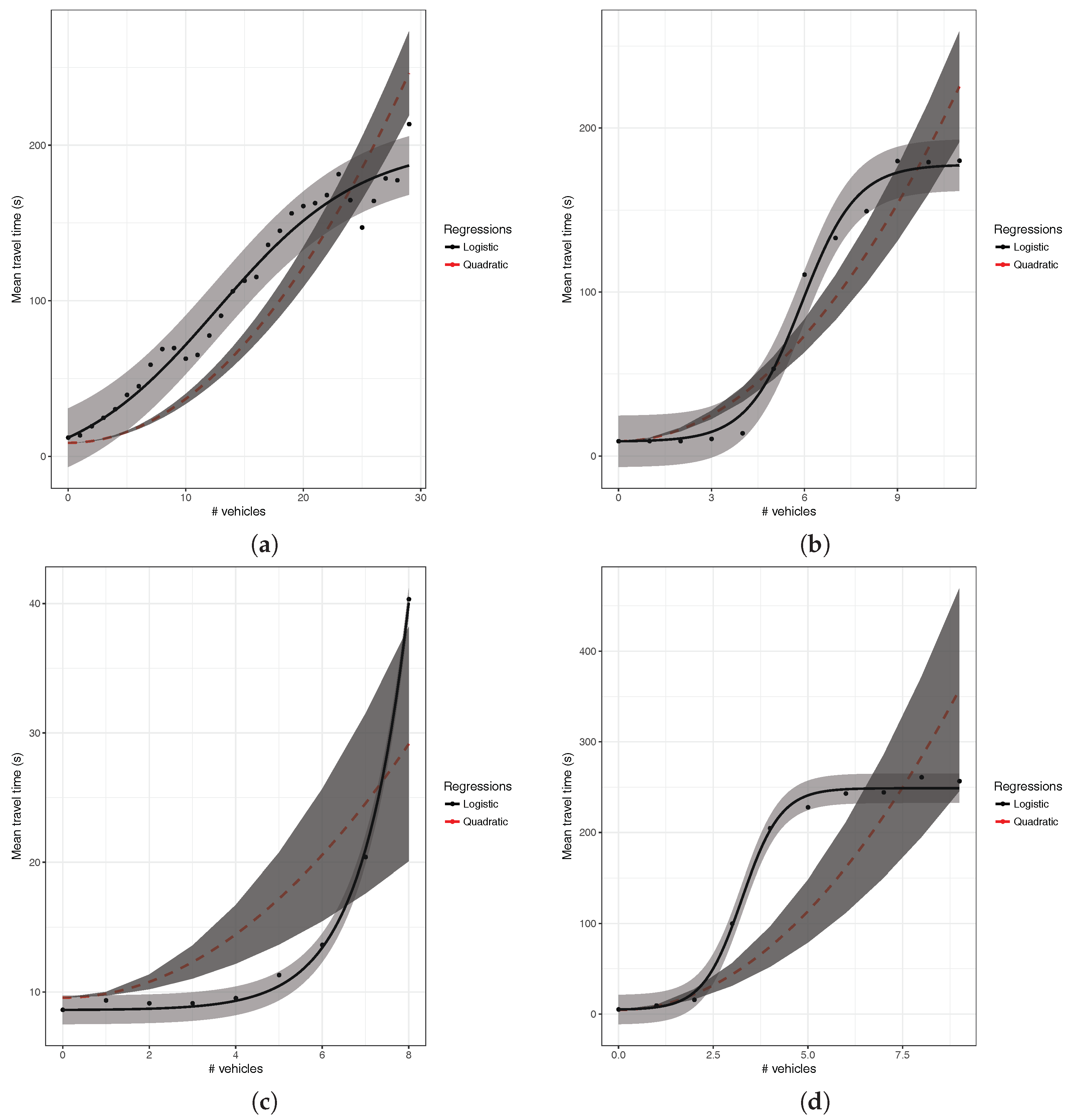
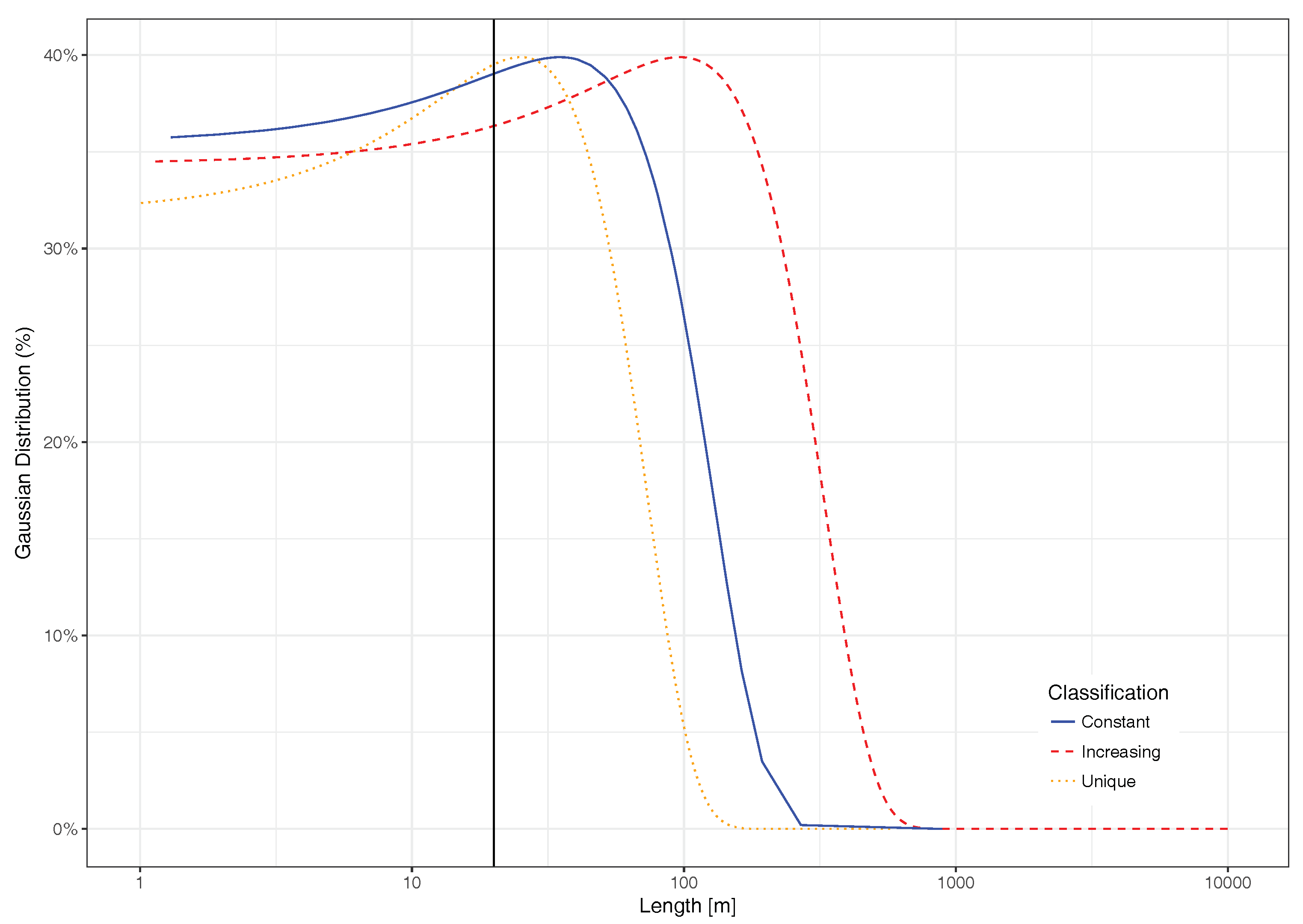
6.1. Validation of the Logistic Regression
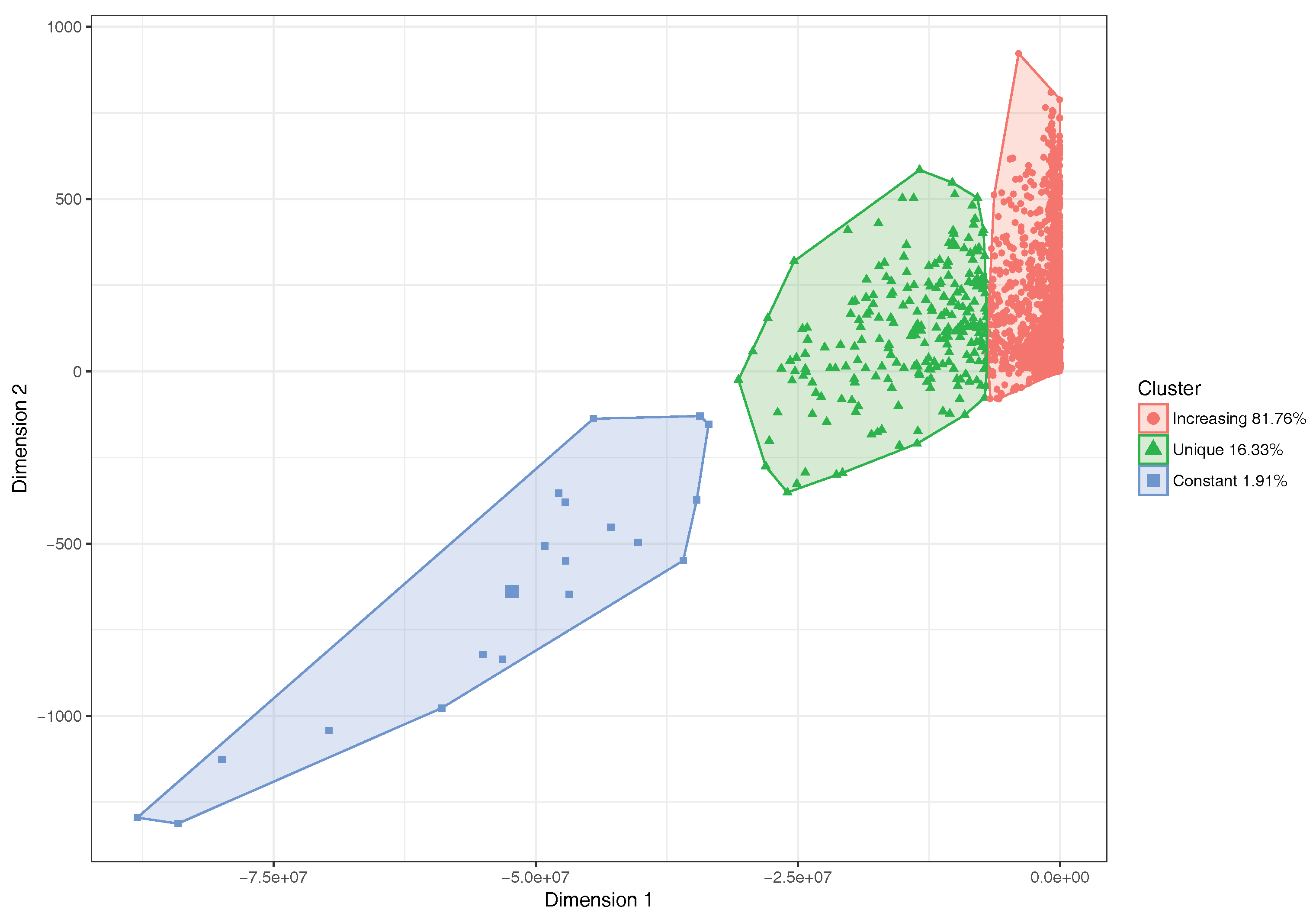
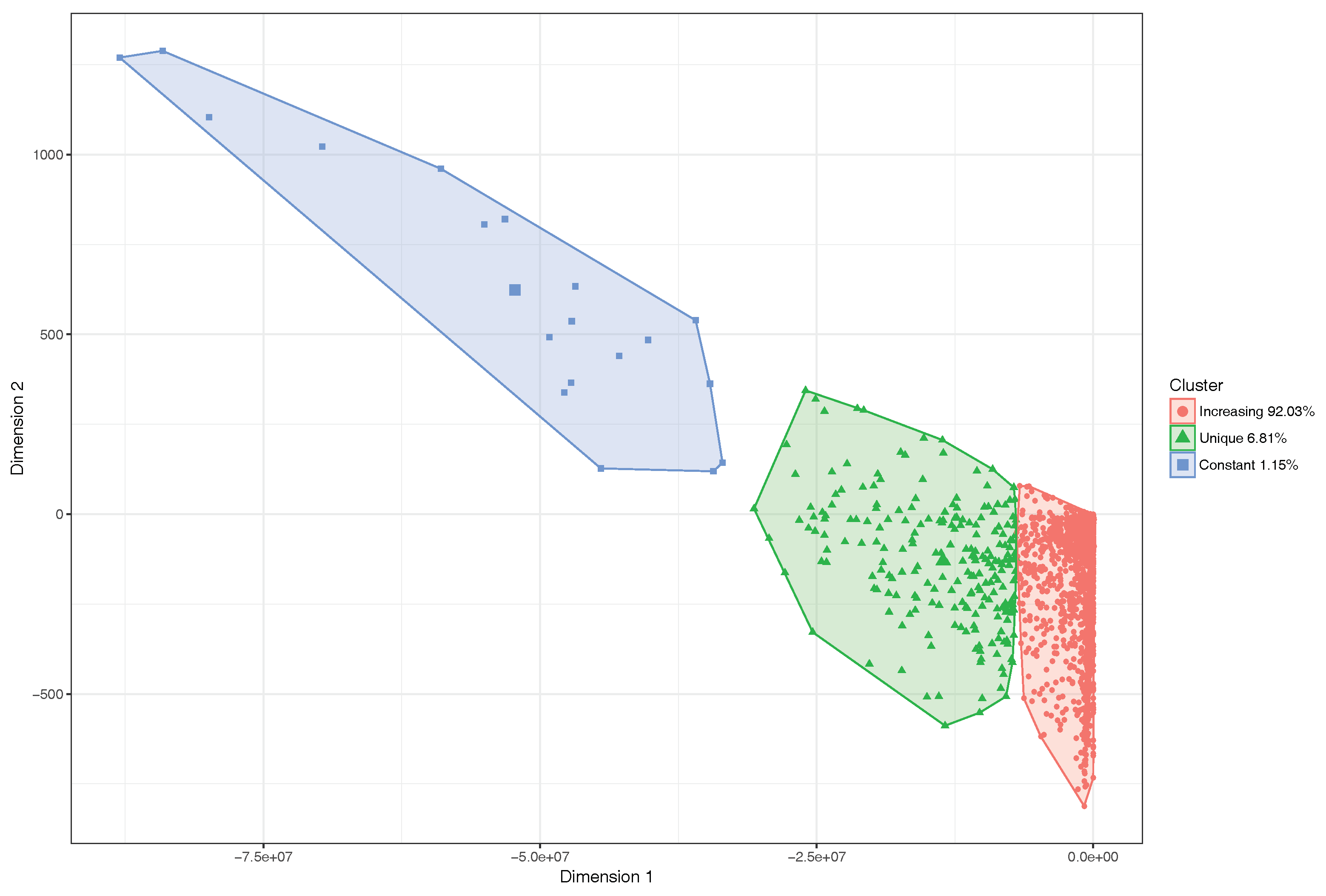
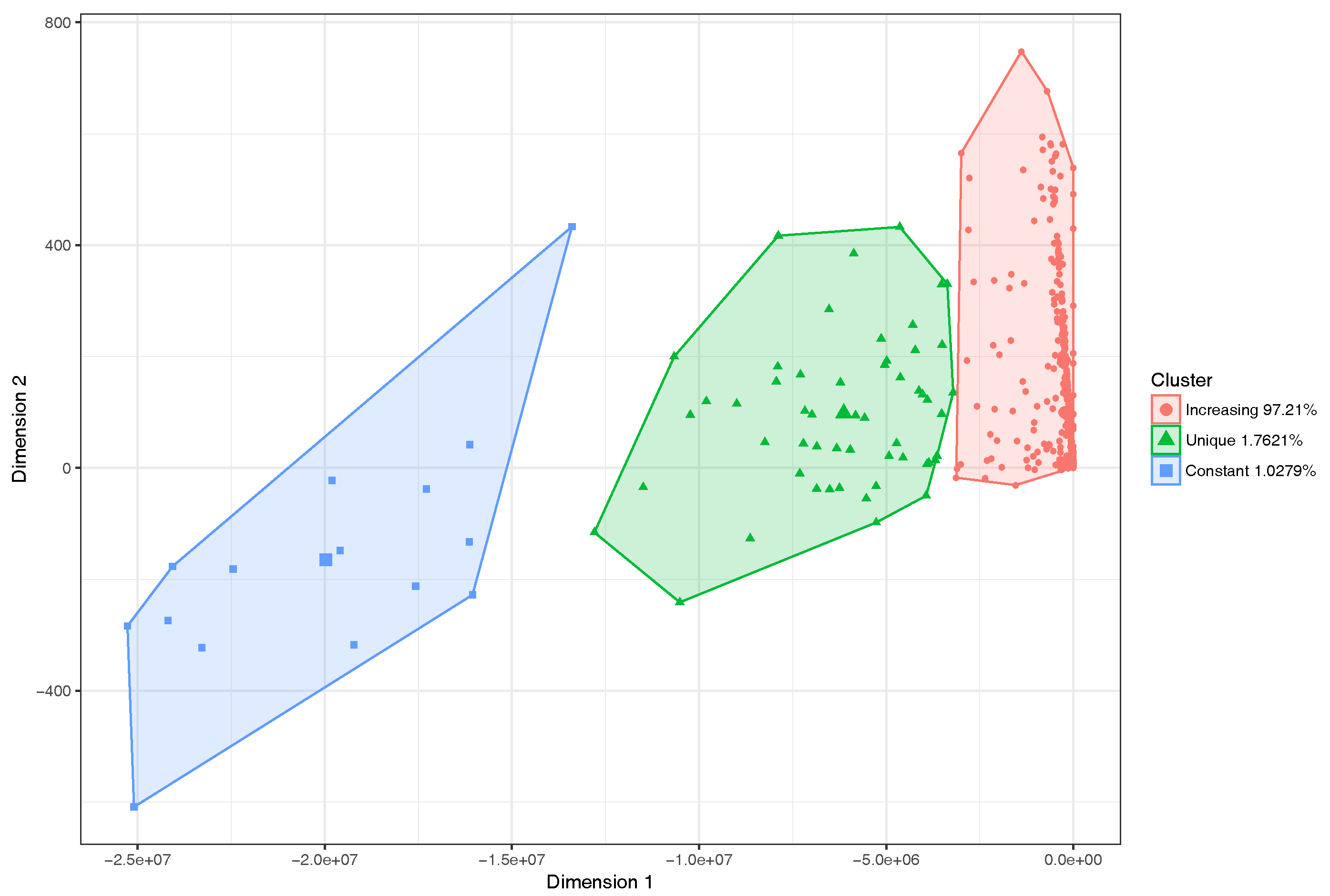
6.2. Clustering Results with Logistic Regression
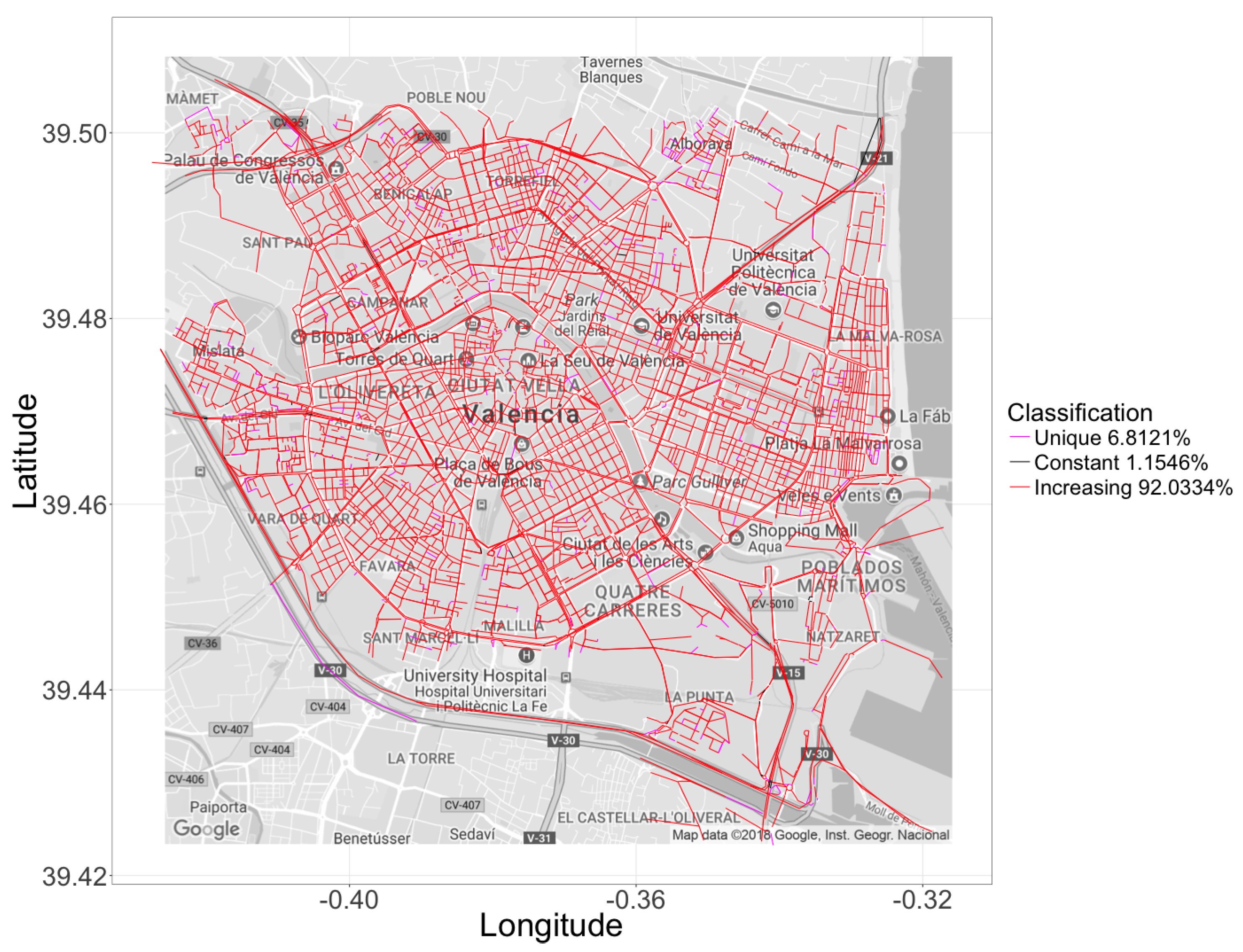
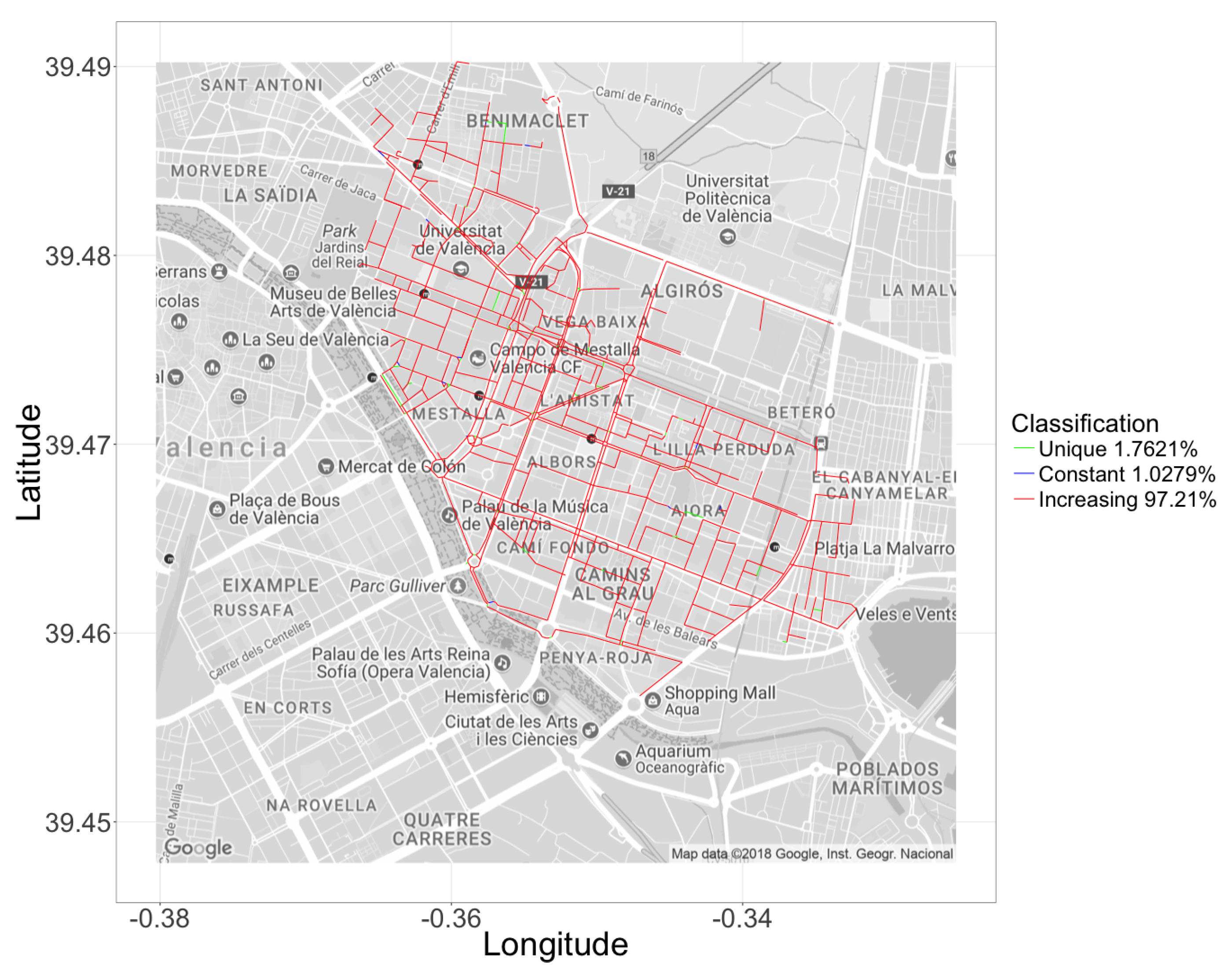
6.3. Hotspot-Based Traffic Congestion Behavior
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Jabali, O.; Woensel, T.; de Kok, A.G. Analysis of travel times and CO2 emissions in time-dependent vehicle routing. Prod. Oper. Manag. 2012, 21, 1060–1074. [Google Scholar] [CrossRef]
- Vallati, M.; Magazzeni, D.; De Schutter, B.; Chrpa, L.; McCluskey, T.L. Efficient Macroscopic Urban Traffic Models for Reducing Congestion: A PDDL + Planning Approach. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016; pp. 3188–3194. [Google Scholar]
- Pozanco, A.; Fernández, S.; Borrajo, D. Urban Traffic Control Assisted by AI Planning and Relational Learning. In ATT@ IJCAI; 2016; Available online: https://pdfs.semanticscholar.org/1371/1a39646c4663fbb45be84f3ce41bf6909a47.pdf (accessed on 23 June 2018).
- Xie, X.F.; Smith, S.F.; Barlow, G.J. Schedule-Driven Coordination for Real-Time Traffic Network Control. In Proceedings of the Twenty-Second International Conference on International Conference on Automated Planning and Scheduling (ICAPS 2012), Palaiseau, France, 23–27 July 2012; ACM: New York, NY, USA, 2013; pp. 323–331. [Google Scholar]
- Djahel, S.; Doolan, R.; Muntean, G.M.; Murphy, J. A communications-oriented perspective on traffic management systems for smart cities: Challenges and innovative approaches. IEEE Commun. Surv. Tutor. 2015, 17, 125–151. [Google Scholar] [CrossRef]
- Chrpa, L.; Magazzeni, D.; McCabe, K.; McCluskey, T.L.; Vallati, M. Automated planning for urban traffic control: Strategic vehicle routing to respect air quality limitations. Intell. Artif. 2016, 10, 113–128. [Google Scholar] [CrossRef]
- Zambrano, J.L.; Calafate, C.T.; Soler, D.; Cano, J.C.; Manzoni, P. Using real traffic data for its simulation: Procedure and validation. In Proceedings of the 2016 International IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), Toulouse, France, 18–21 July 2016; pp. 161–170. [Google Scholar] [CrossRef]
- Calafate, C.T.; Soler, D.; Cano, J.C.; Manzoni, P. Traffic management as a service: The traffic flow pattern classification problem. Math. Probl. Eng. 2015, 2015. [Google Scholar] [CrossRef]
- Nguyen, T.V.; Krajzewicz, D.; Fullerton, M.; Nicolay, E. DFROUTER-Estimation of Vehicle Routes from Cross-Section Measurements. In Modeling Mobility with Open Data; Springer: Berlin/Heidelberg, Germany, 2015; pp. 3–23. ISBN 978-3-319-15024-6. [Google Scholar]
- Zambrano-Martinez, J.L.; Calafate, C.T.; Soler, D.; Cano, J.C. Towards realistic urban traffic experiments using DFROUTER: Heuristic, validation and extensions. Sensors 2017, 17, 2921. [Google Scholar] [CrossRef] [PubMed]
- Zambrano-Martinez, J.L.; Calafate, C.T.; Soler, D.; Cano, J.C.; Manzoni, P. Analysis and Classification of the Vehicular Traffic Distribution in an Urban Area. In Ad-hoc, Mobile, and Wireless Networks; Puliafito, A., Bruneo, D., Distefano, S., Longo, F., Eds.; Springer: Cham, Switzerland, 2017; pp. 121–134. [Google Scholar] [CrossRef]
- Behrisch, M.; Bieker, L.; Erdmann, J.; Krajzewicz, D. SUMO—Simulation of urban mobility: An overview. In Proceedings of the Third International Conference on Advances in System Simulation. ThinkMind (SIMUL 2011), Barcelona, Spain, 23–28 October 2011; IARIA XPS Press: København, Denmark, 2011. [Google Scholar]
- Lieu, H. Revised Monograph on Traffic Flow Theory; US Department of Transportation Federal Highway Administration: Washington, DC, USA, 2003.
- Zhang, X.; Rice, J.A. Short-term travel time prediction. Transp. Res. C Emerg. Technol. 2003, 11, 187–210. [Google Scholar] [CrossRef]
- Guo, J.; Huang, W.; Williams, B.M. Adaptive Kalman filter approach for stochastic short-term traffic flow rate prediction and uncertainty quantification. Transp. Res. C Emerg. Technol. 2014, 43, 50–64. [Google Scholar] [CrossRef]
- Van Hinsbergen, C.P.; Schreiter, T.; Zuurbier, F.S.; Van Lint, J.W.C.; Van Zuylen, H.J. Localized extended kalman filter for scalable real-time traffic state estimation. IEEE Trans. Intell. Transp. Syst. 2012, 13, 385–394. [Google Scholar] [CrossRef]
- Min, W.; Wynter, L. Real-time road traffic prediction with spatio-temporal correlations. Transp. Res. C Emerg. Technol. 2011, 19, 606–616. [Google Scholar] [CrossRef]
- Costa, C.; Chatzimilioudis, G.; Zeinalipour-Yazti, D.; Mokbel, M.F. Towards Real-Time Road Traffic Analytics using Telco Big Data. In Proceedings of the International Workshop on Real-Time Business Intelligence and Analytics, Munich, Germany, 28 August 2017; ACM: New York, NY, USA, 2017; p. 5. [Google Scholar]
- Zhang, X.; Onieva, E.; Perallos, A.; Osaba, E.; Lee, V. Hierarchical fuzzy rule-based system optimized with genetic algorithms for short term traffic congestion prediction. Transp. Res. C Emerg. Technol. 2014, 43, 127–142. [Google Scholar] [CrossRef]
- Onieva, E.; Milanés, V.; Villagra, J.; Pérez, J.; Godoy, J. Genetic optimization of a vehicle fuzzy decision system for intersections. Expert Syst. Appl. 2012, 39, 13148–13157. [Google Scholar] [CrossRef] [Green Version]
- Hodge, V.J.; Krishnan, R.; Jackson, T.; Austin, J.; Polak, J. Short-Term Traffic Prediction Using a Binary Neural Network. In Proceedings of the 43rd Annual UTSG Conference, York, UK, 5–7 January 2011. [Google Scholar]
- Habtie, A.B.; Abraham, A.; Midekso, D. Artificial Neural Network Based Real-Time Urban Road Traffic State Estimation Framework. In Computational Intelligence in Wireless Sensor Networks; Springer: Cham, Switzerland, 2017; pp. 73–97. [Google Scholar] [CrossRef]
- Porikli, F.; Li, X. Traffic congestion estimation using HMM models without vehicle tracking. In Proceedings of the 2004 IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 188–193. [Google Scholar] [CrossRef] [Green Version]
- Kunt, M.M.; Aghayan, I.; Noii, N. Prediction for traffic accident severity: Comparing the artificial neural network, genetic algorithm, combined genetic algorithm and pattern search methods. Transport 2011, 26, 353–366. [Google Scholar] [CrossRef]
- Sananmongkhonchai, S.; Tangamchit, P.; Pongpaibool, P. Cell-based traffic estimation from multiple GPS-equipped cars. In Proceedings of the 2009 IEEE Region 10 Conference (TENCON 2009), Singapore, 23–26 January 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Kerner, B.S.; Rehborn, H.; Aleksic, M.; Haug, A. Traffic prediction systems in vehicles. In Proceedings of the 2005 IEEE Intelligent Transportation Systems, Vienna, Austria, 16 September 2005; pp. 72–77. [Google Scholar] [CrossRef]
- Basnayake, C. Automated traffic incident detection with GPS equipped probe vehicles. In Proceedings of the the 17th International Technical Meeting of the Satellite Division of the Institute of Navigation, Long Beach, CA, USA, 21–24 September 2004; pp. 1–10. [Google Scholar]
- Varga, A.; Hornig, R. An overview of the OMNeT++ simulation environment. In Proceedings of the 1st International Conference on Simulation Tools and Techniques for Communications, Networks and Systems & Workshops, Marseille, France, 3–7 March 2008. [Google Scholar]
- Menard, S. Applied Logistic Regression Analysis; SAGE Publications: Thousand Oaks, CA, USA, 2018; Volume 106, ISBN 9780761922087. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Linear, R.R. Principal Component Analysis. In Multivariate Statistics; Springer: Berlin, Germany, 2014; Volume 487, pp. 163–183. [Google Scholar] [CrossRef]
- Cal y Mayor Reyes Spíndola, R.; Cárdenas Grisales, J. Ingeniería de Tránsito: Fundamentos y Aplicaciones; Alfaomega Grupo Editor: Mexico D.F., Mexico, 2010. (In Spanish) [Google Scholar]













© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zambrano-Martinez, J.L.; Calafate, C.T.; Soler, D.; Cano, J.-C.; Manzoni, P. Modeling and Characterization of Traffic Flows in Urban Environments. Sensors 2018, 18, 2020. https://doi.org/10.3390/s18072020
Zambrano-Martinez JL, Calafate CT, Soler D, Cano J-C, Manzoni P. Modeling and Characterization of Traffic Flows in Urban Environments. Sensors. 2018; 18(7):2020. https://doi.org/10.3390/s18072020
Chicago/Turabian StyleZambrano-Martinez, Jorge Luis, Carlos T. Calafate, David Soler, Juan-Carlos Cano, and Pietro Manzoni. 2018. "Modeling and Characterization of Traffic Flows in Urban Environments" Sensors 18, no. 7: 2020. https://doi.org/10.3390/s18072020
APA StyleZambrano-Martinez, J. L., Calafate, C. T., Soler, D., Cano, J. -C., & Manzoni, P. (2018). Modeling and Characterization of Traffic Flows in Urban Environments. Sensors, 18(7), 2020. https://doi.org/10.3390/s18072020