HyTexiLa: High Resolution Visible and Near Infrared Hyperspectral Texture Images

 , , ,
, , , 
Abstract
:1. Introduction
2. Comparison of HyTexiLa with Existing Hyperspectral Datasets
3. Image Acquisition and Processing
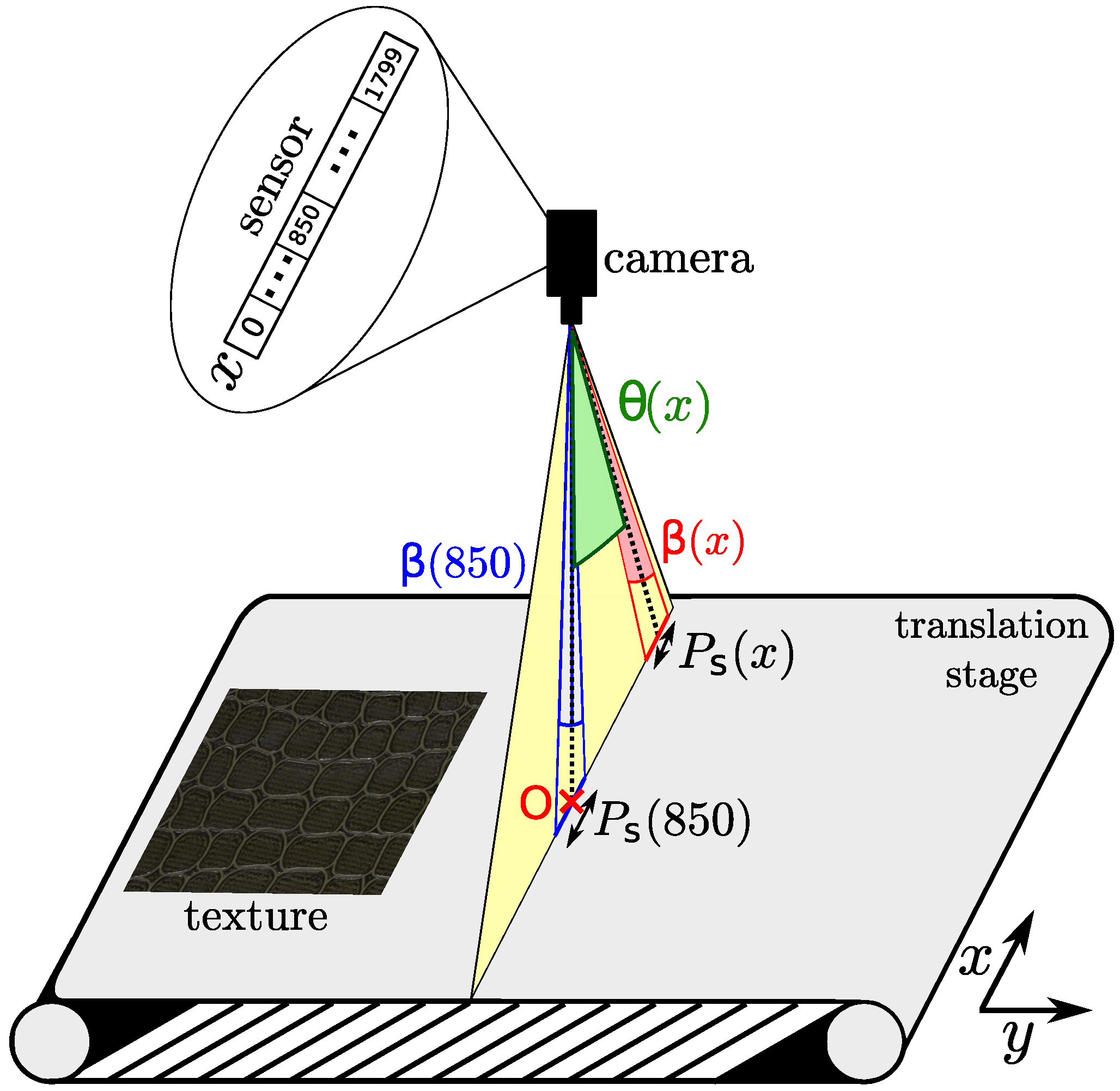
3.1. Notations
3.2. Objects in the Dataset
3.3. Acquisition Setup
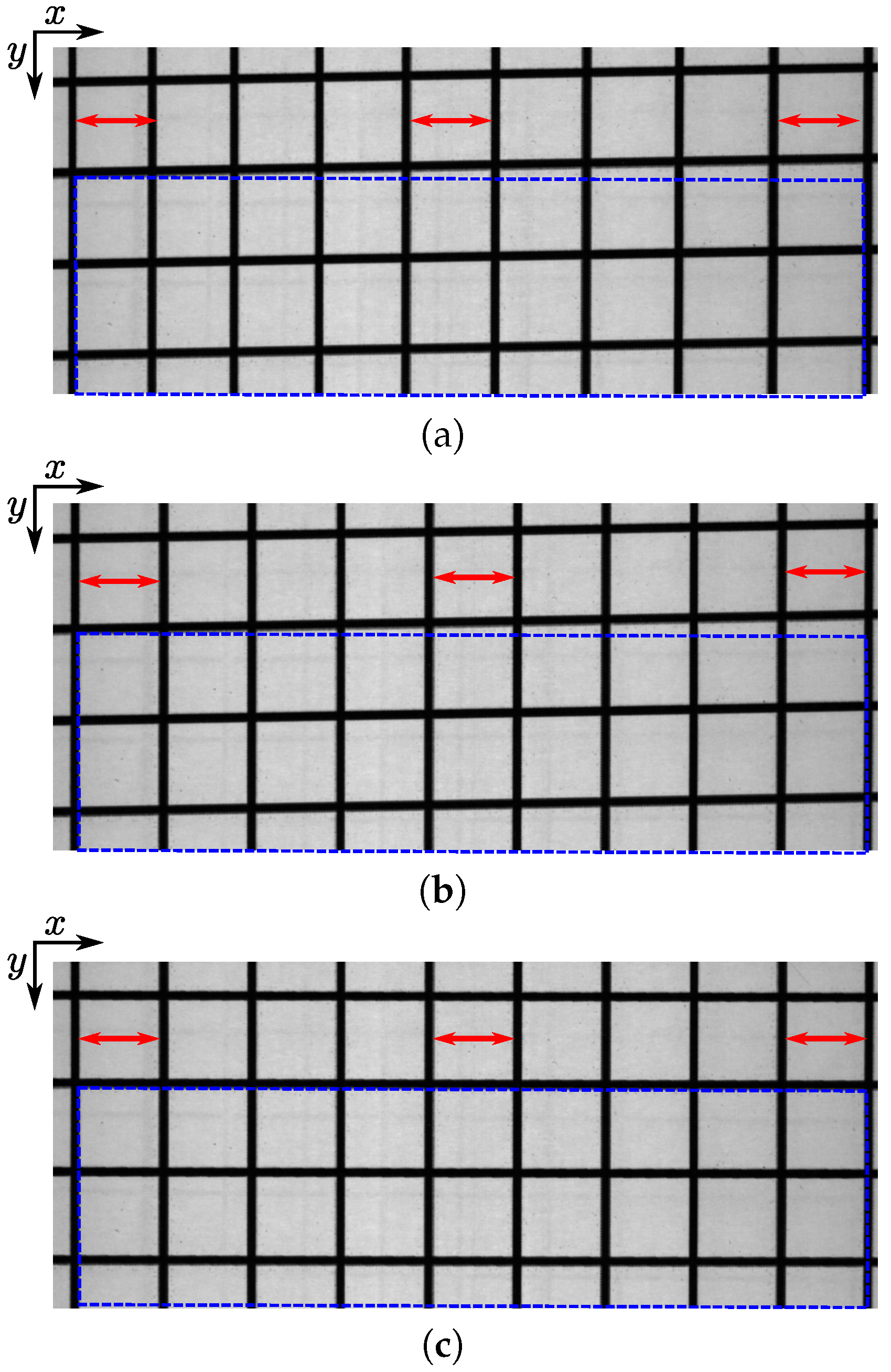
3.4. Corrections of Spatial Distortions
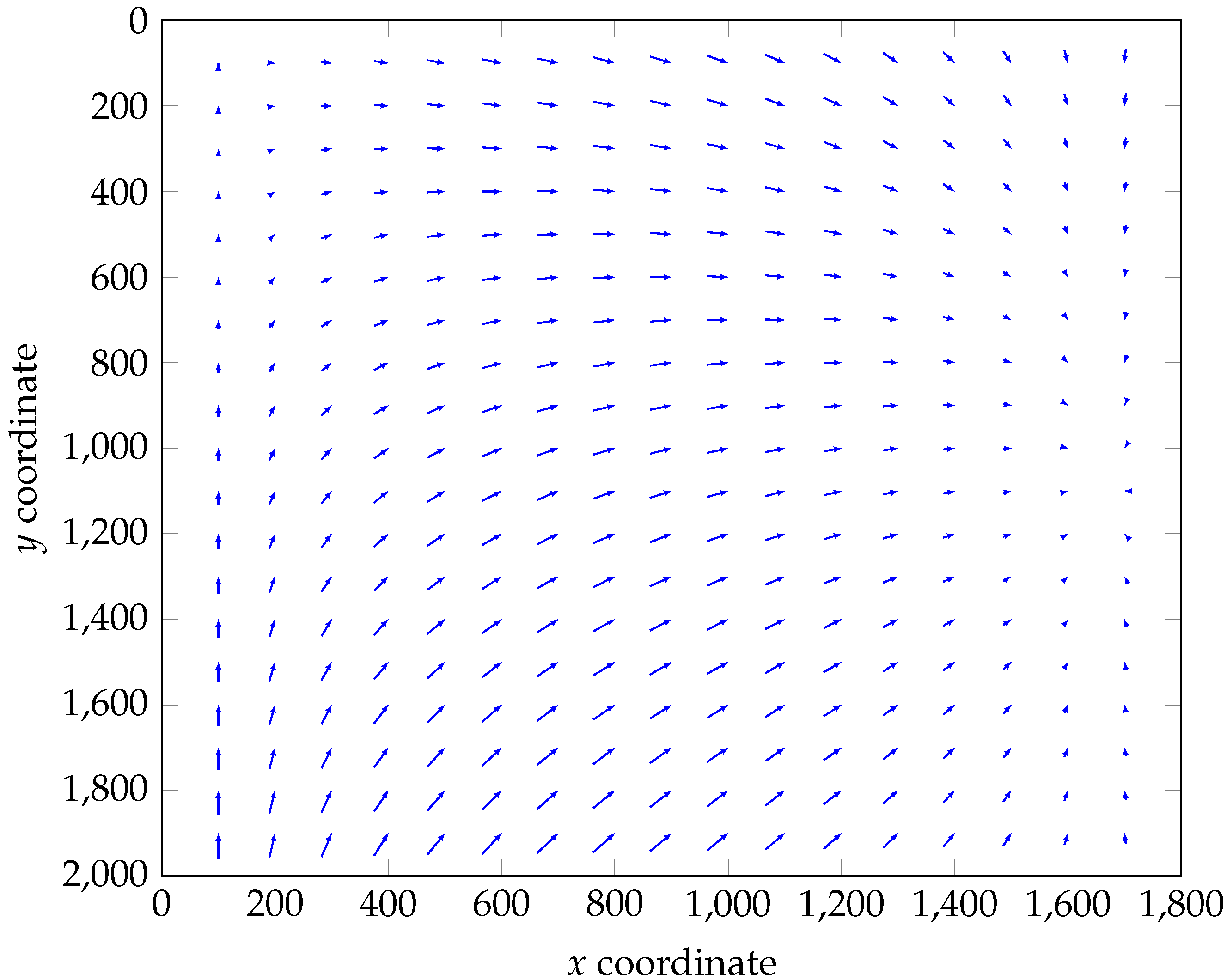
3.4.1. Cross-Track Distortion
3.4.2. Shear Distortion
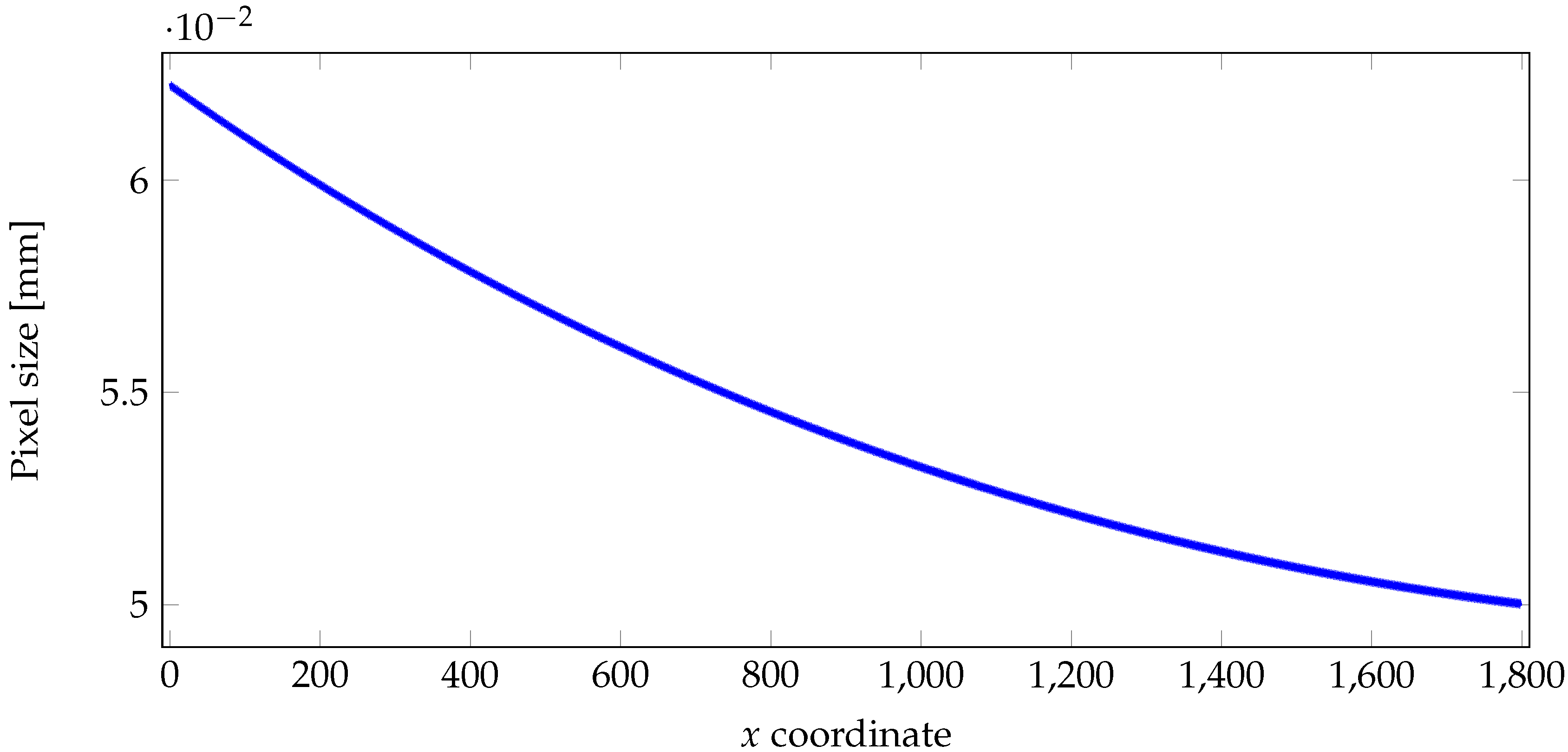
3.5. Impact of the Corrections on Pixel Resolution
3.6. Reflectance Computation
3.7. Dataset Description
- A description of camera parameters (i.e., camera ID, integration time, aperture size, etc.). These metadata were written by the HySpex acquisition software and we decided to keep them unchanged.
- Required information to open the associated binary raw file (i.e., image size, number of bands, data type, etc.),
- Default bands (65, 45, and 18) whose band centers match with the primary Red, Green and Blue of sRGB standards. Generally these are used to generate false color RGB images using three channels.
- Wavelength array that contain values of in nanometers, for example, the center wavelength of channel is ,
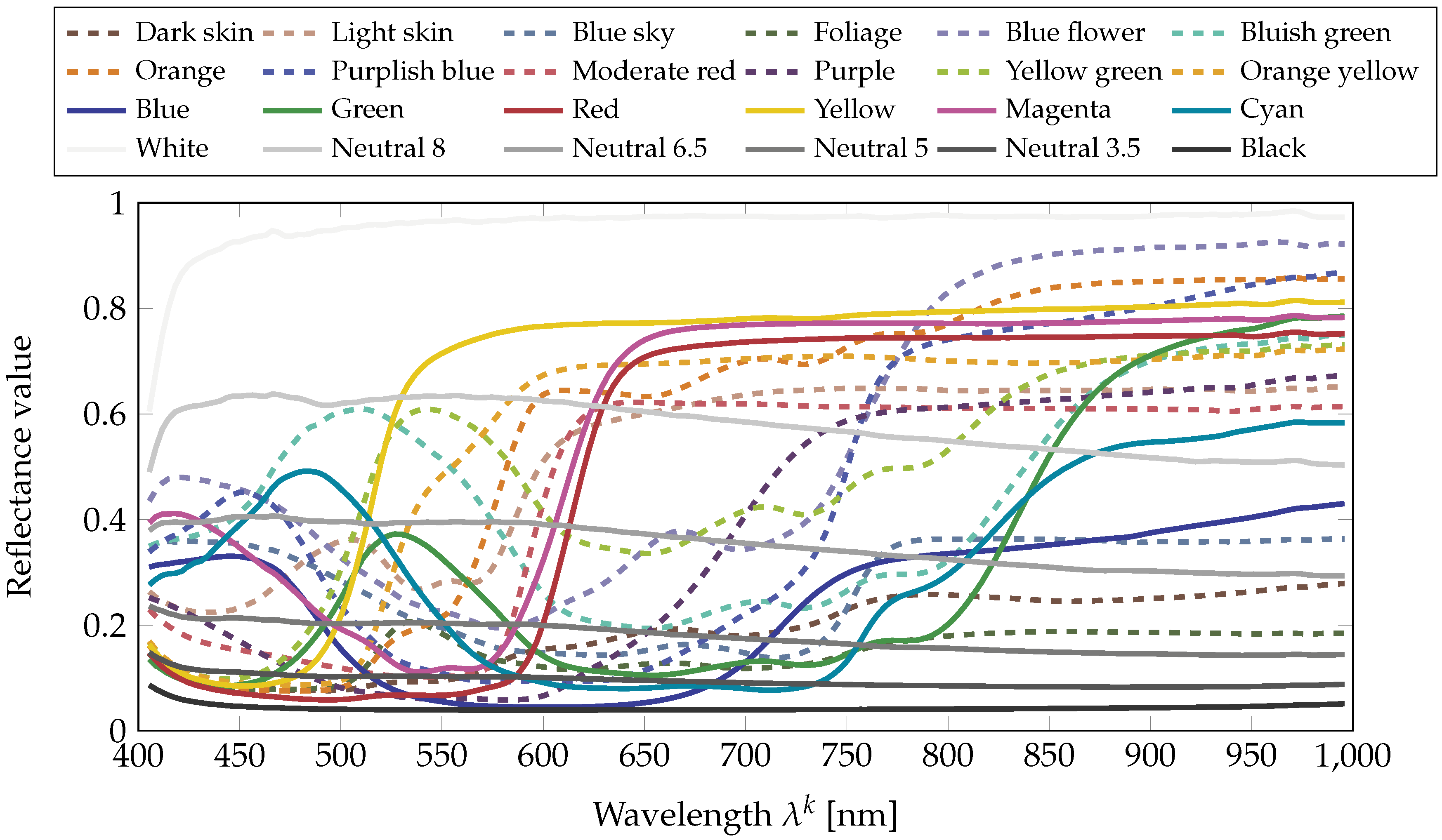
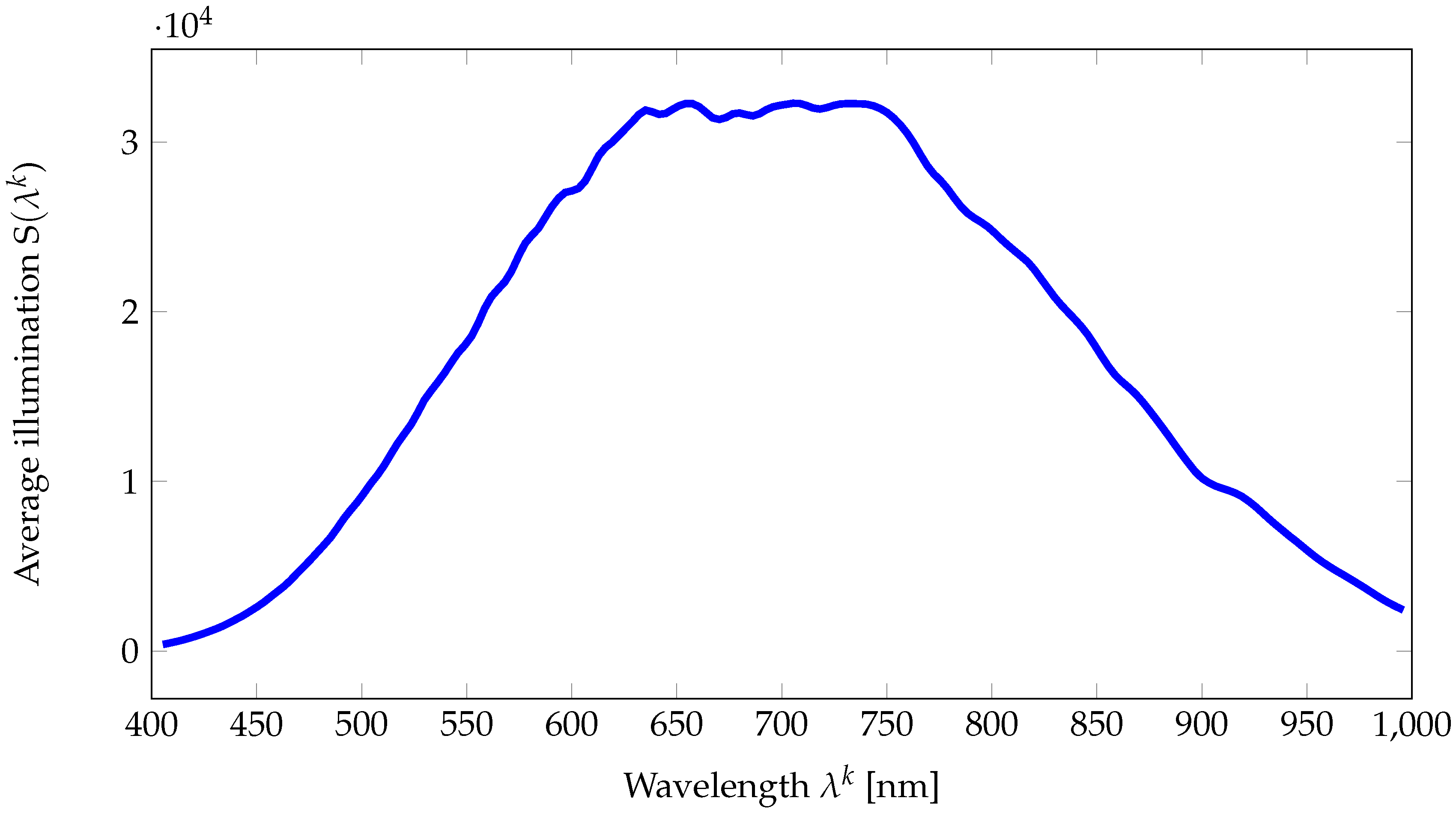
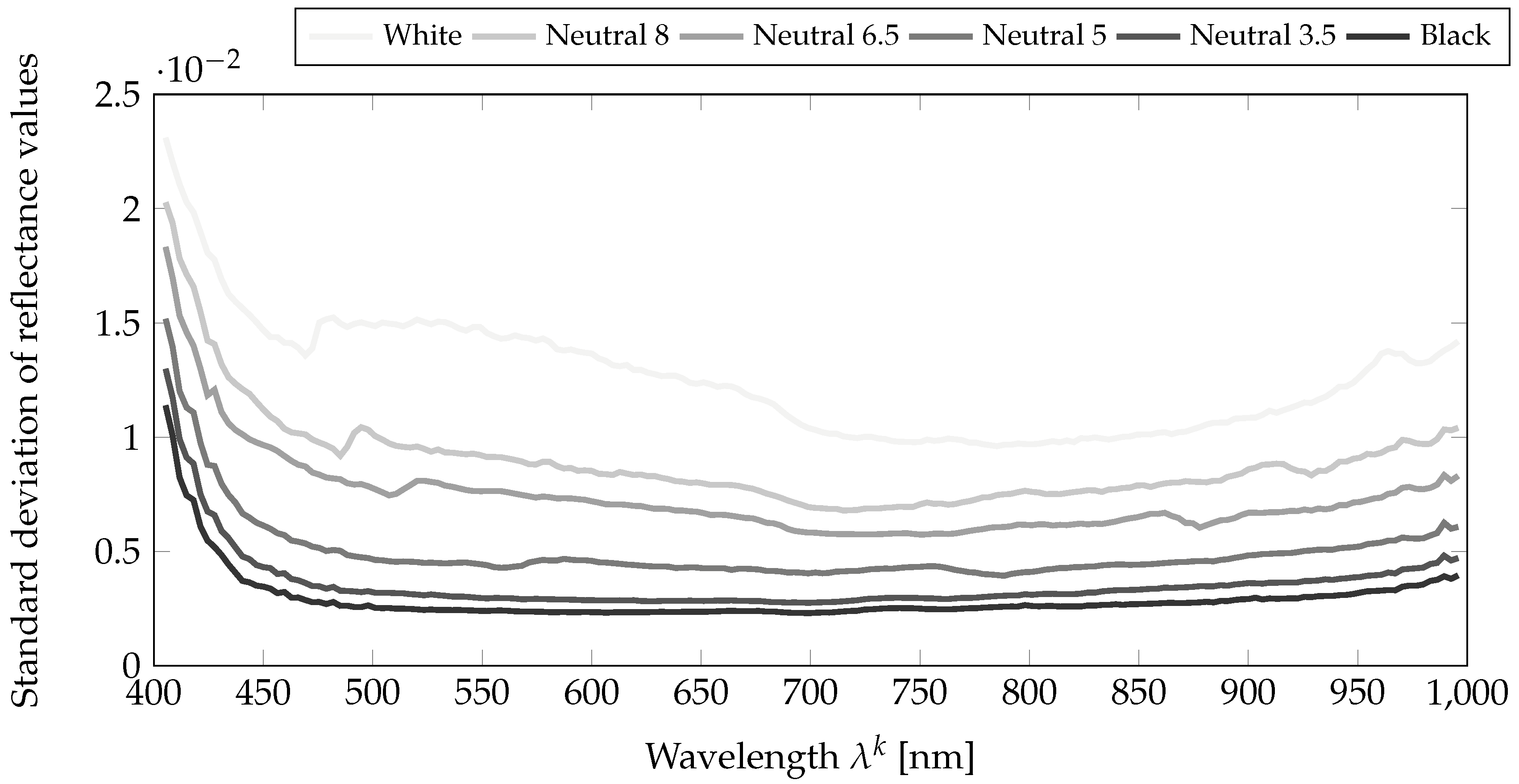
- Illumination array that contains the values of illumination provided by Equation (9). The illumination can be used to compute the corrected radiance channels, , using Equation (10). The average value of this illumination over the 112 images is provided in Figure 7. It can be seen that illumination around 400 is weak, and consequently, respective channels in the reflectance images are likely to undergo noise [57]. We then measure the noise power by analyzing the standard deviation on pixels on each gray patch of the reflectance image of the Macbeth ColorChecker on Figure 8. In addition to the illumination effect, the problem of having a good signal at low wavelengths is classically due to optics and low sensor sensitivity in this area, where we are at the limit of the optical model that is being used . Nevertheless we chose to provide these data and let the users decide if they want to use them in their simulations.Moreover, we provide ImageJ plugins and Python code for opening and processing the data. Matlab users can call the following instruction to open one hyperspectral reflectance image:R = multibandread(’<image_name>.raw’, [1024,1024,186],’float32’,0,’bsq’,’ieee-be’); These codes are available as Supplementary Materials.
4. Spectral Dimension Analysis
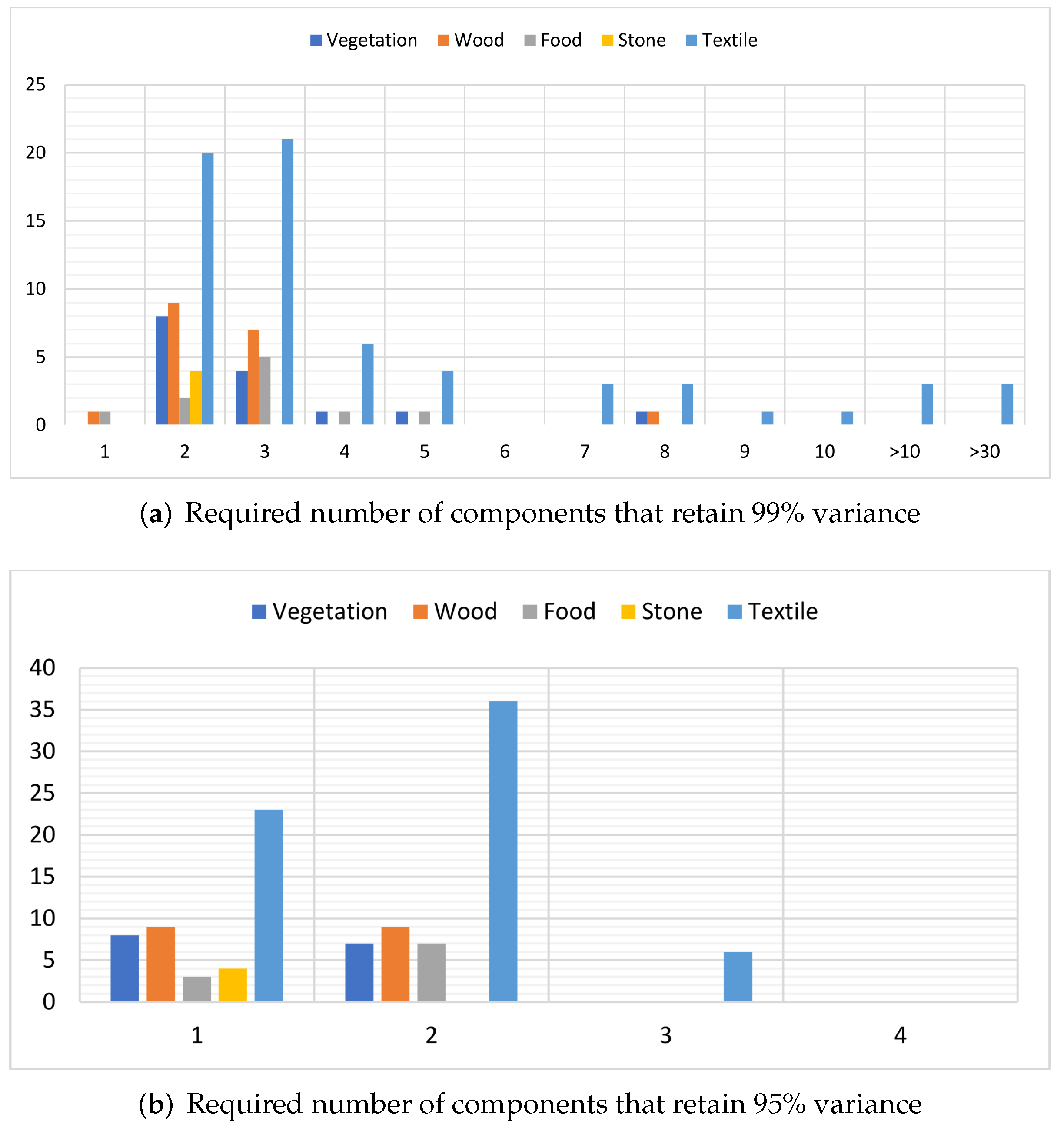
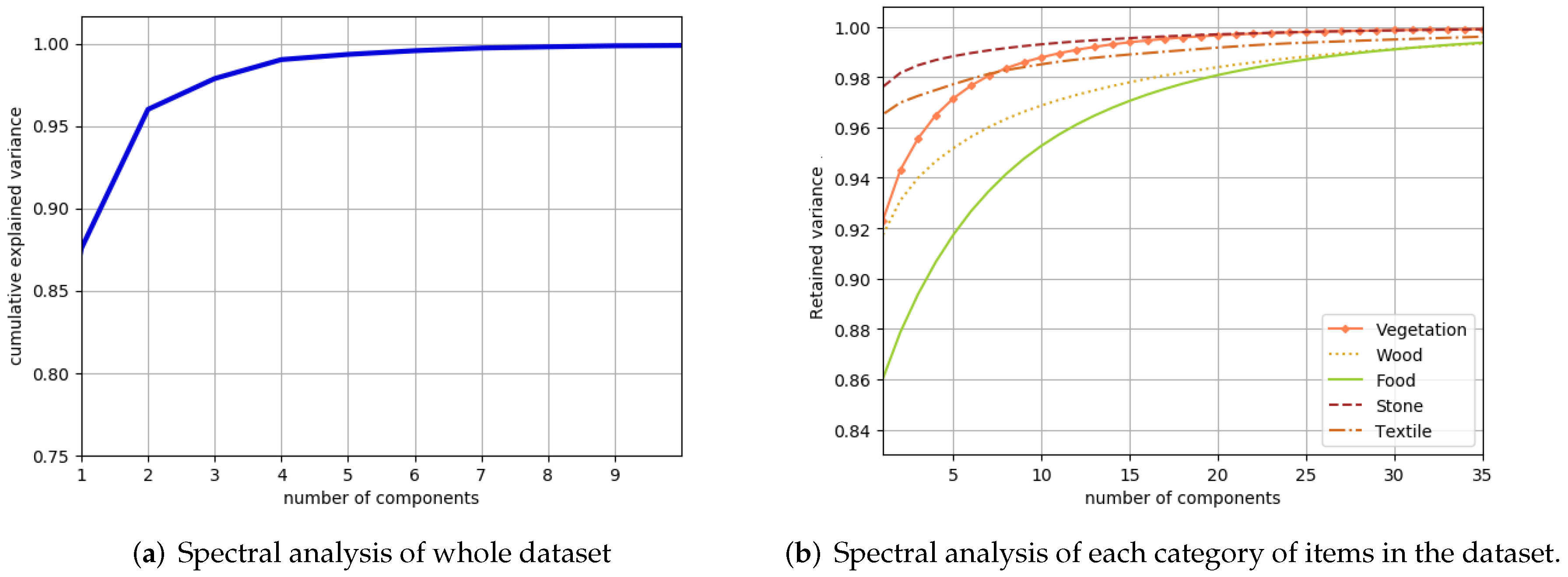
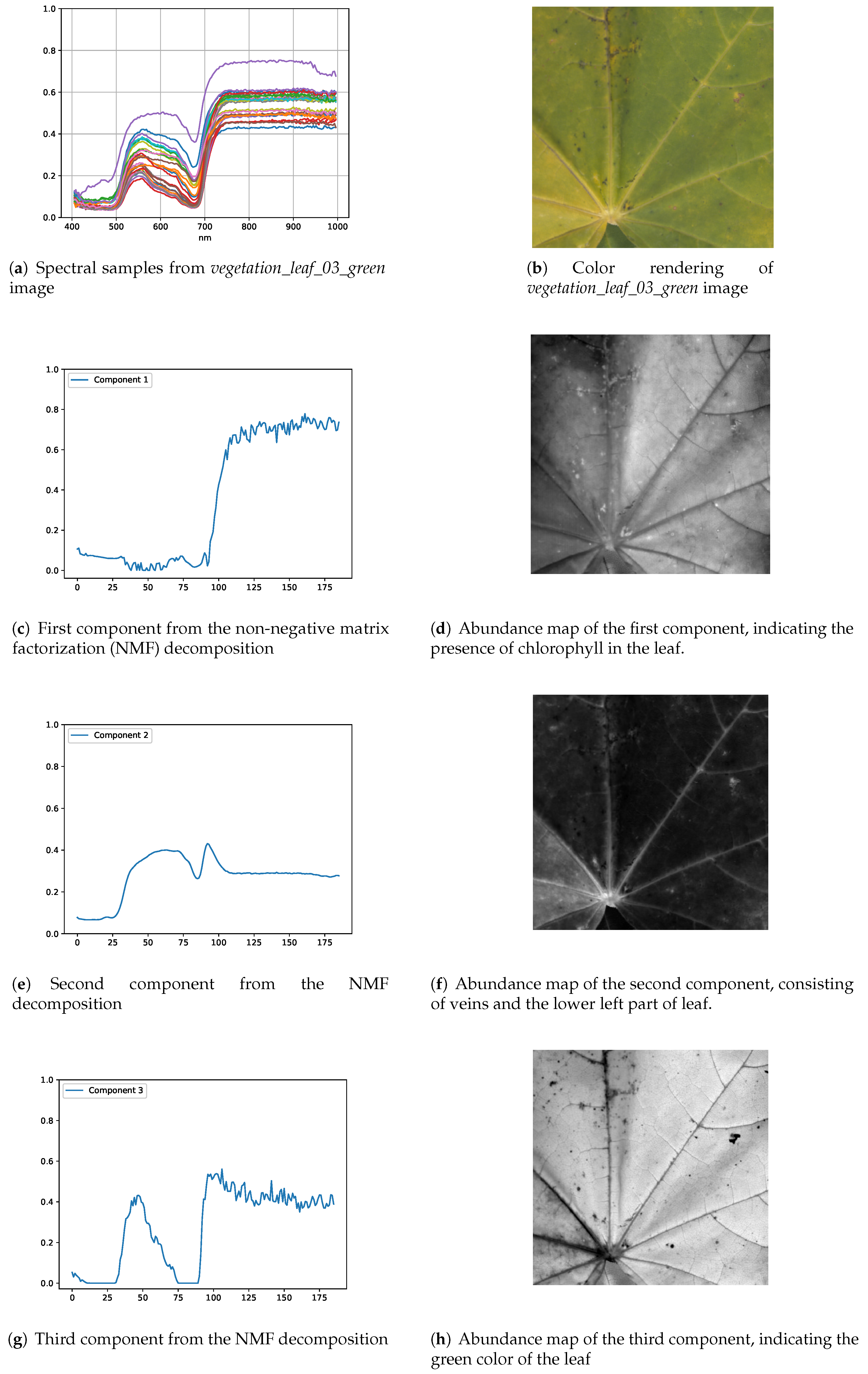
4.1. Spectral Analysis of the Proposed Dataset
4.2. Interpretation of the Effective Dimension
5. Texture Classification
5.1. Texture Features Based on Local Binary Patterns
- Marginal LBP (LBP): The basic LBP operator is applied marginally to each channel at each pixel p as [75]where is the index of each neighboring pixel, q, of p in , and the sign function, s, is defined as if , or 0 otherwise. The final texture feature results from the concatenation of the K -bin un-normalized histograms of , and its size is .
- The Opponent Band LBP (OBLBP): Mäenpää et al. [76] improved the LBP operator by taking the inter-channel correlation into account. For this purpose, they considered the opponent band (OBLBP) operator of each pair of channels, , :The final texture feature results from the concatenation of the histograms of and its size is .
- Luminance-Local Color Contrast LBP (L-LCCLBP): This approach considers an image to have both spatial information of luminance and inter-channel information of different bands. The spatial information of the luminance results from the LBP operator being applied to the pseudo panchromatic image (PPI) , which is computed as the average value over all channels at each pixel [77]:Regarding the inter-channel content, Cusano et al. [78] define the local color contrast (LCC) operator that depends on the angle, , between the value of a pixel, p, and the average value, , of its neighbors in the spectral domain:The LCC operator is then given byThe final texture feature is the concatenation of the histogram of and the histogram of , and its size is .
- Luminance-Opponent Band Angles LBP (L-OBALBP): As for L-LCCLBP, this approach first applies the LBP operator to the PPI , and then Lee et al. [79] considers the angle between each pair of bands, , aswhere is a constant of small value. The final texture feature is the concatenation of the histogram of and the histograms of . Its size is .
5.2. Assessment on Our Proposed Dataset
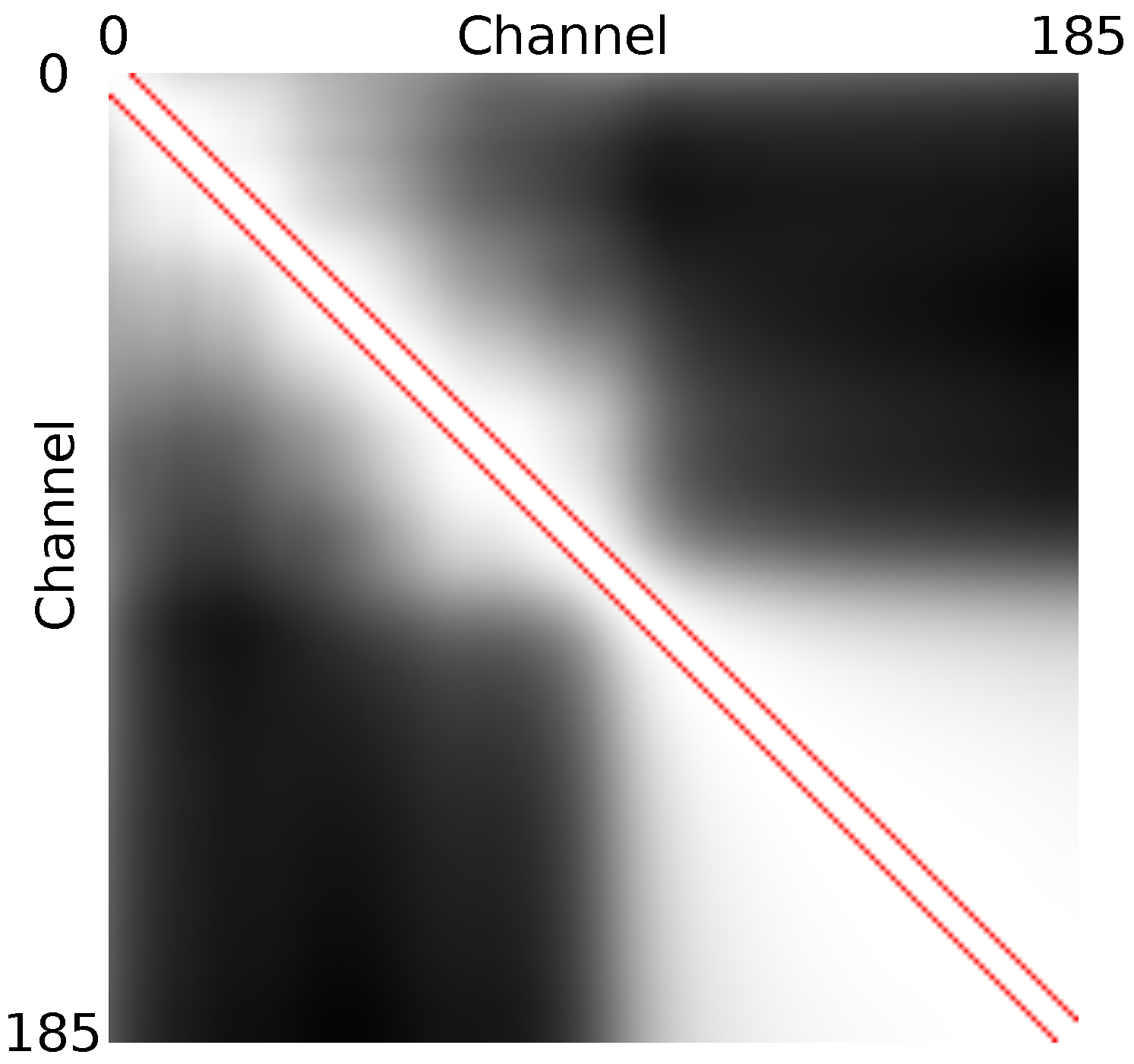
5.2.1. Covariance Analysis
5.2.2. Classification Scheme
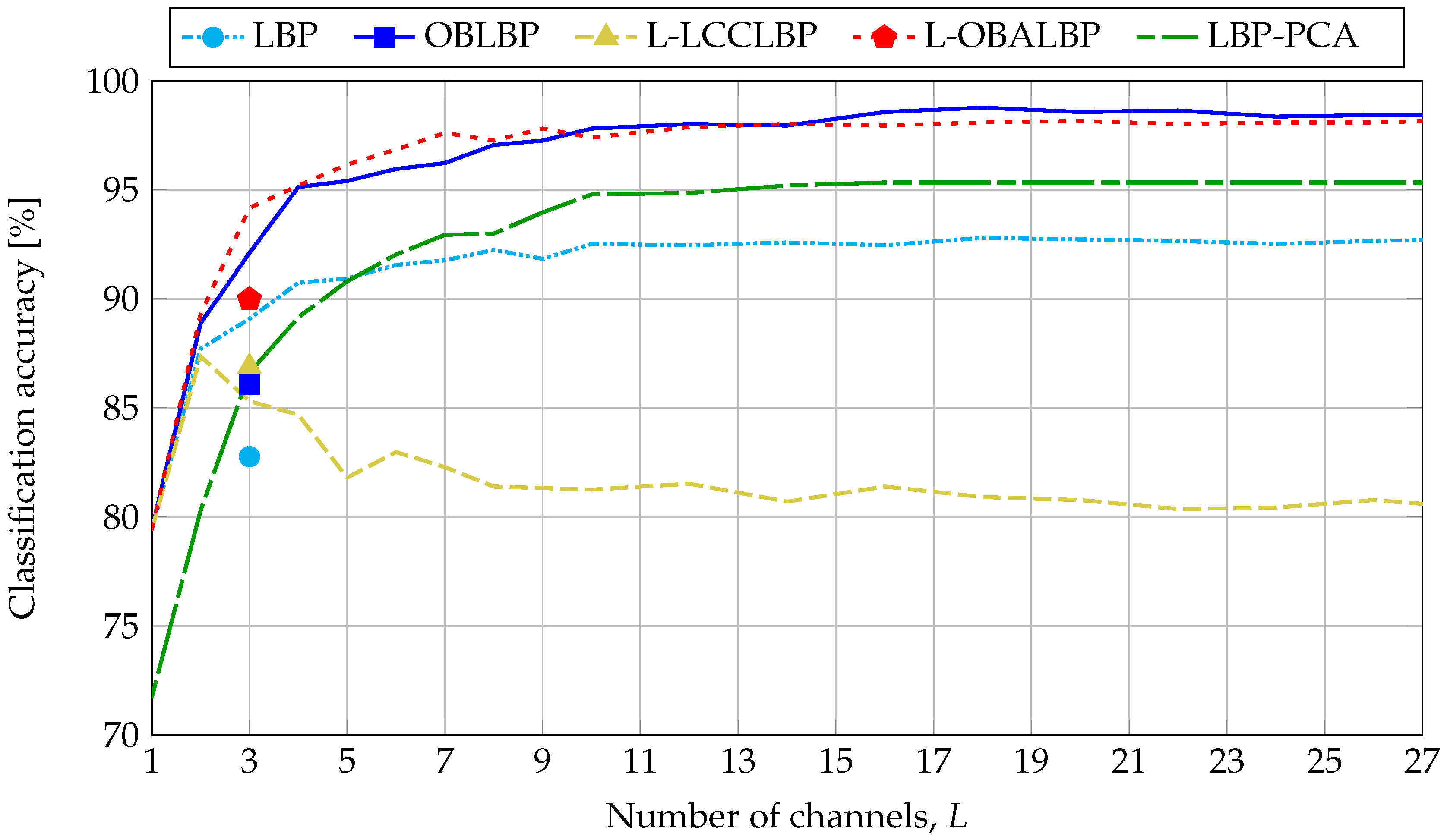
5.2.3. Classification Accuracy
6. Conclusions
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Wolfe, W.L. Introduction to Imaging Spectrometers; SPIE Press: Bellingham, WA, USA, 1997; Volume 25. [Google Scholar]
- Miller, P.J. Use of Tunable Liquid Crystal Filters to Link Radiometric and Photometric Standards. Metrologia 1991, 28, 145. [Google Scholar] [CrossRef]
- Neumann, N.; Ebermann, M.; Hiller, K.; Seifert, M.; Meinig, M.; Kurth, S. MEMS Tunable Fabry-Pérot Filters for Infrared Microspectrometer Applications. Opt. Soc. Am. 2016. [Google Scholar] [CrossRef]
- Sigernes, F.; Syrjäsuo, M.; Storvold, R.; Ao Fortuna, J.; Grøtte, M.E.; Johansen, T.A. Do it yourself hyperspectral imager for handheld to airborne operations. Opt. Express 2018, 26, 6021–6035. [Google Scholar] [CrossRef] [PubMed]
- Kang, X.; Xiang, X.; Li, S.; Benediktsson, J.A. PCA-Based Edge-Preserving Features for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7140–7151. [Google Scholar] [CrossRef]
- Bandos, T.V.; Bruzzone, L.; Camps-Valls, G. Classification of Hyperspectral Images with Regularized Linear Discriminant Analysis. IEEE Trans. Geosci. Remote Sens. 2009, 47, 862–873. [Google Scholar] [CrossRef]
- Amigo, J.M.; Ravn, C.; Gallagher, N.B.; Bro, R. A comparison of a common approach to partial least squares-discriminant analysis and classical least squares in hyperspectral imaging. Int. J. Pharm. 2009, 373, 179–182. [Google Scholar] [CrossRef] [PubMed]
- Song, W.; Li, S.; Kang, X.; Huang, K. Hyperspectral image classification based on KNN sparse representation. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016. [Google Scholar]
- Mercier, G.; Lennon, M. Support Vector Machines for Hyperspectral Image Classification with Spectral-Based Kernels. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Toulouse, France, 21–25 July 2003. [Google Scholar]
- Liu, F.; Ye, X.; He, Y.; Wang, L. Application of visible/near infrared spectroscopy and chemometric calibrations for variety discrimination of instant milk teas. J. Food Eng. 2009, 93, 127–133. [Google Scholar] [CrossRef]
- Merényi, E.; Farrand, W.H.; Taranik, J.V.; Minor, T.B. Classification of hyperspectral imagery with neural networks: comparison to conventional tools. EURASIP J. Adv. Signal Process. 2014, 2014, 71. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. A new deep convolutional neural network for fast hyperspectral image classification. ISPRS J. Photogramm. Remote Sens. 2017. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral Remote Sensing Data Analysis and Future Challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef] [Green Version]
- Lu, G.; Fei, B. Medical hyperspectral imaging: A review. J. Biomed. Opt. 2014, 19, 010901. [Google Scholar] [CrossRef] [PubMed]
- Fischer, C.; Kakoulli, I. Multispectral and hyperspectral imaging technologies in conservation: Current research and potential applications. Stud. Conserv. 2006, 51, 3–16. [Google Scholar] [CrossRef]
- Hardeberg, J.Y.; George, S.; Deger, F.; Baarstad, I.; Palacios, J.E.H. Spectral Scream: Hyperspectral Image Acquisition and Analysis of a Masterpiece. In Public Paintings by Edvard Munch and His Contemporaries: Change and Conservation Challenges; Frøysaker, T., Streeton, N., Kutzke, H., Hanssen-Bauer, F., Topalova-Casadiego, B., Eds.; Archetype Publications: London, UK, 2015. [Google Scholar]
- Pan, Z.; Healey, G.; Prasad, M.; Tromberg, B. Face recognition in hyperspectral images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1552–1560. [Google Scholar] [CrossRef] [Green Version]
- Gowen, A.; O’Donnell, C.; Cullen, P.; Downey, G.; Frias, J. Hyperspectral imaging–An emerging process analytical tool for food quality and safety control. Trends Food Sci. Technol. 2007, 18, 590–598. [Google Scholar] [CrossRef]
- Eckhard, T.; Klammer, M.; Valero, E.M.; Hernández-Andrés, J. Improved Spectral Density Measurement from Estimated Reflectance Data with Kernel Ridge Regression. In Image and Signal Processing; Springer International Publishing: Cham, Switzerland, 2014; pp. 79–86. [Google Scholar]
- Coppel, L.G.; Le Moan, S.; Elıas, P.Z.; Slavuj, R.; Harderberg, J.Y. Next generation printing—Towards spectral proofing. Adv. Print. Media Technol. 2014, 41, 19–24. [Google Scholar]
- Majda, A.; Wietecha-Posłuszny, R.; Mendys, A.; Wójtowicz, A.; Łydżba-Kopczyńska, B. Hyperspectral imaging and multivariate analysis in the dried blood spots investigations. Appl. Phys. A 2018, 124, 312. [Google Scholar] [CrossRef] [Green Version]
- Cheng, J.H.; Jin, H.; Xu, Z.; Zheng, F. NIR hyperspectral imaging with multivariate analysis for measurement of oil and protein contents in peanut varieties. Anal. Methods 2017, 9, 6148–6154. [Google Scholar] [CrossRef]
- Cheng, J.H.; Nicolai, B.; Sun, D.W. Hyperspectral imaging with multivariate analysis for technological parameters prediction and classification of muscle foods: A review. Meat Sci. 2017, 123, 182–191. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Li, J.; Fan, S.; Huang, W.; Zhao, C.; Liu, C.; Huang, D. Hyperspectral imaging combined with multivariate analysis and band math for detection of common defects on peaches (Prunus persica). Comput. Electron. Agric. 2015, 114, 14–24. [Google Scholar] [CrossRef]
- Brelstaff, G.J.; Parraga, A.; Troscianko, T.; Carr, D. Hyperspectral camera system: Acquisition and analysis. In Proceedings of the Proceedings Geographic Information Systems, Photogrammetry, and Geological/Geophysical Remote Sensing, Paris, France, 17 November 1995. [Google Scholar]
- Foster, D.H.; Amano, K.; Nascimento, S.M.C. Time-lapse ratios of cone excitations in natural scenes. Vis. Res. 2016, 120, 45–60. [Google Scholar] [CrossRef] [PubMed]
- Arad, B.; Ben-Shahar, O. Sparse Recovery of Hyperspectral Signal from Natural RGB Images. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Nascimento, S.M.C.; Ferreira, F.P.; Foster, D.H. Statistics of spatial cone-excitation ratios in natural scenes. J. Opt. Soc. Am. A 2002, 19, 1484–1490. [Google Scholar] [CrossRef]
- Foster, D.H.; Amano, K.; Nascimento, S.M.C.; Foster, M.J. Frequency of metamerism in natural scenes. J. Opt. Soc. Am. A 2006, 23, 2359–2372. [Google Scholar] [CrossRef]
- Nascimento, S.M.C.; Amano, K.; Foster, D.H. Spatial distributions of local illumination color in natural scenes. Vis. Res. 2016, 120, 39–44. [Google Scholar] [CrossRef] [PubMed]
- Eckhard, J.; Eckhard, T.; Valero, E.M.; Nieves, J.L.; Contreras, E.G. Outdoor scene reflectance measurements using a Bragg-grating-based hyperspectral imager. Appl. Opt. 2015, 54, D15–D24. [Google Scholar] [CrossRef]
- Chakrabarti, A.; Zickler, T. Statistics of Real-World Hyperspectral Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’11), Cambridge, MA, USA, 6–13 November 2011. [Google Scholar]
- Nguyen, R.M.H.; Prasad, D.K.; Brown, M.S. Training-Based Spectral Reconstruction from a Single RGB Image. In Computer Vision–ECCV 2014(ECCV’14); Springer-Verlag: Zürich, Switzerland, 2014; pp. 186–201. [Google Scholar]
- Yasuma, F.; Mitsunaga, T.; Iso, D.; Nayar, S.K. Generalized Assorted Pixel Camera: Postcapture Control of Resolution, Dynamic Range, and Spectrum. IEEE Trans. Image Process. 2010, 19, 2241–2253. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hordley, S.; Finalyson, G.; Morovic, P. A Multi-Spectral Image Database and its Application to Image Rendering Across Illumination. In Proceedings of the 3rd International Conference on Image and Graphics (ICIG’04), Hong Kong, China, 18–20 December 2004. [Google Scholar]
- Brainard, D.H. Hyperspectral Image Data. Available online: http://color.psych.upenn.edu/hyperspectral (accessed on 25 June 2018).
- Hyperspectral Images of Illustrated Manuscripts. Available online: http://personalpages.manchester.ac.uk/staff/d.h.foster/Hyperspectral_Images_of_Illustrated_Manuscripts.html (accessed on 26 April 2018).
- Mirhashemi, A. Introducing spectral moment features in analyzing the SpecTex hyperspectral texture database. Mach. Vis. Appl. 2018, 29, 415–432. [Google Scholar] [CrossRef]
- Le Moan, S.; George, S.T.; Pedersen, M.; Blahová, J.; Hardeberg, J.Y. A database for spectral image quality. In Proceedings of the Proceedings Image Quality and System Performance XII, San Francisco, CA, USA, 8 February 2015. [Google Scholar]
- Noviyanto, A.; Abdullah, W.H. Honey Dataset Standard Using Hyperspectral Imaging for Machine Learning Problems. In Proceedings of the 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017. [Google Scholar]
- Zacharopoulos, A.; Hatzigiannakis, K.; Karamaoynas, P.; Papadakis, V.M.; Andrianakis, M.; Melessanaki, K.; Zabulis, X. A method for the registration of spectral images of paintings and its evaluation. J. Cult. Heritage 2018, 29, 10–18. [Google Scholar] [CrossRef]
- Nouri, M.; Gorretta, N.; Vaysse, P.; Giraud, M.; Germain, C.; Keresztes, B.; Roger, J.M. Near infrared hyperspectral dataset of healthy and infected apple tree leaves images for the early detection of apple scab disease. Data Brief 2018, 16, 967–971. [Google Scholar] [CrossRef] [PubMed]
- Hirvonen, T.; Orava, J.; Penttinen, N.; Luostarinen, K.; Hauta-Kasari, M.; Sorjonen, M.; Peiponen, K.E. Spectral image database for observing the quality of Nordic sawn timbers. Wood Sci. Technol. 2014, 48, 995–1003. [Google Scholar] [CrossRef]
- Skauli, T.; Farrell, J. A Collection of Hyperspectral Images for Imaging Systems Research. In Proceedings of the Digital Photography IX, Burlingame, CA, USA, 4 February 2013. [Google Scholar]
- Shin, H.; Reyes, N.H.; Barczak, A.L.; Chan, C.S. Colour Object Classification Using the Fusion of Visible and Near-Infrared Spectra. In PRICAI: Trends in Artificial Intelligence; Zhang, B.T., Orgun, M.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 498–509. [Google Scholar]
- Steiner, H.; Schwaneberg, O.; Jung, N. Advances in Active Near-Infrared Sensor Systems for Material Classification. In Imaging and Applied Optics Technical Papers; Optical Society of America: Washington, DC, USA, 2012; p. ITu2C.2. [Google Scholar]
- Guifang, W.; Hai, M.; Xin, P. Identification of Varieties of Natural Textile Fiber Based on Vis/NIR Spectroscopy Technology. In Proceedings of the IEEE Advanced Information Technology, Electronic and Automation Control Conference, Chongqing, China, 19–20 December 2015. [Google Scholar]
- Horgan, B.H.; Cloutis, E.A.; Mann, P.; Bell, J.F. Near-infrared spectra of ferrous mineral mixtures and methods for their identification in planetary surface spectra. Icarus 2014, 234, 132–154. [Google Scholar] [CrossRef]
- Lehtonen, J.; Parkkinen, J.; Jaaskelainen, T. Optimal sampling of color spectra. J. Opt. Soc. Am. A 2006, 23, 2983–2988. [Google Scholar] [CrossRef]
- HySpex VNIR-1800. Available online: https://www.hyspex.no/products/vnir_1800.php (accessed on 26 April 2018).
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef] [Green Version]
- Illumination Technologies Inc. 3900e DC Regulated ER Lightsouce. Available online: http://bit.ly/IT3900e (accessed on 21 May 2018).
- SG-3051 SphereOptics Diffuse Reflectance Tile. Available online: http://sphereoptics.de/wp-content/uploads/2014/03/Zenith_Product-Brochure.pdf (accessed on 21 May 2018).
- Lapray, P.J.; Thomas, J.B.; Gouton, P. A Database of Spectral Filter Array Images that Combine Visible and NIR. In Computational Color Imaging Workshop; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10213, pp. 187–196. [Google Scholar]
- Deger, F.; Mansouri, A.; Pedersen, M.; Hardeberg, J.Y.; Voisin, Y. A sensor-data-based denoising framework for hyperspectral images. Opt. Express 2015, 23, 1938–1950. [Google Scholar] [CrossRef] [PubMed]
- Gillis, D.; Bowles, J.H.; Winter, M.E. Dimensionality Reduction in Hyperspectral Imagery. In Proceedings of the Proceedings Algorithms and Technologies forMultispectral, Hyperspectral, and Ultraspectral Imagery IX, Orlando, FL, USA, 23 September 2003; Volume 5093. [Google Scholar]
- Deborah, H.; Richard, N.; Hardeberg, J.Y. A Comprehensive Evaluation of Spectral Distance Functions and Metrics for Hyperspectral Image Processing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3224–3234. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis. In Wiley StatsRef: Statistics Reference Online; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2014. [Google Scholar]
- Wang, J.; Chang, C.I. Independent component analysis-based dimensionality reduction with applications in hyperspectral image analysis. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1586–1600. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhong, Y.; Huang, B.; Gong, J.; Li, P. Dimensionality Reduction Based on Clonal Selection for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4172–4186. [Google Scholar] [CrossRef]
- Zhang, T.; Tao, D.; Yang, J. Discriminative Locality Alignment. In Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008. [Google Scholar]
- Khodr, J.; Younes, R. Dimensionality Reduction on Hyperspectral Images: A Comparative Review Based on Artificial Datas. In Proceedings of the 4th International Congress on Image and Signal Processing, Shanghai, China, 15–17 October 2011. [Google Scholar]
- Hardeberg, J.Y. On the Spectral Dimensionality of Object Colours. In Conference on Colour in Graphics, Imaging, and Vision; Society for Imaging Science and Technology: Springfield, VA, USA, 2002; pp. 480–485. [Google Scholar]
- Dusselaar, R.; Paul, M. Hyperspectral image compression approaches: Opportunities, challenges, and future directions: discussion. J. Opt. Soc. Am. A 2017, 34, 2170–2180. [Google Scholar] [CrossRef] [PubMed]
- Berry, M.W.; Browne, M.; Langville, A.N.; Pauca, V.P.; Plemmons, R.J. Algorithms and applications for approximate nonnegative matrix factorization. Comput. Stat. Data Anal. 2007, 52, 155–173. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A.; Liu, L. Robust Collaborative Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6076–6090. [Google Scholar] [CrossRef] [Green Version]
- Bao, W.; Li, Q.; Xin, L.; Qu, K. Hyperspectral Unmixing Algorithm Based on Nonnegative Matrix Factorization. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016. [Google Scholar]
- Alsam, A.; Connah, D.; Hardeberg, J. Multispectral Imaging: How Many Sensors Do We Need? J. Imaging Sci. Technol. 2006, 50, 45–52. [Google Scholar]
- Verma, A.; Tyagi, D.; Sharma, S. Recent advancement of LBP techniques: A survey. In Proceedings of the 2016 International Conference on Computing, Communication and Automation (ICCCA), Noida, India, 29–30 April 2016. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef] [Green Version]
- Palm, C. Color texture classification by integrative Co-occurrence matrices. Pattern Recogn. 2004, 37, 965–976. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Harwood, D. Performance evaluation of texture measures with classification based on Kullback discrimination of distributions. In Proceedings of the 12th International Conference on Pattern Recognition, Jerusalem, Israel, 9–13 October 1994. [Google Scholar]
- Mäenpää, T.; Pietikainen, M.; Viertola, J. Separating Color and Pattern Information for Color Texture Discrimination. In Proceedings of the Object Recognition Supported by User Interaction for Service Robots, Quebec City, QC, Canada, 11–15 Auguest 2002. [Google Scholar]
- Mihoubi, S.; Losson, O.; Mathon, B.; Macaire, L. Multispectral Demosaicing Using Pseudo-Panchromatic Image. IEEE Trans. Comput. Imaging 2017, 3, 982–995. [Google Scholar] [CrossRef] [Green Version]
- Cusano, C.; Napoletano, P.; Schettini, R. Combining local binary patterns and local color contrast for texture classification under varying illumination. J. Opt. Soc. Am. A 2014, 31, 1453–1461. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.H.; Choi, J.Y.; Ro, Y.M.; Plataniotis, K.N. Local Color Vector Binary Patterns From Multichannel Face Images for Face Recognition. IEEE Trans. Image Process. 2012, 21, 2347–2353. [Google Scholar] [CrossRef] [PubMed]
- Trusseli, H.J.; Kulkarni, M.S. Sampling and processing of color signals. IEEE Trans. Image Process. 1996, 5, 677–681. [Google Scholar] [CrossRef] [PubMed]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- L301kc-Basler L300. Available online: https://www.baslerweb.com/en/products/cameras/line-scan-cameras/l300/l301kc/ (accessed on 14 May 2018).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Nature of Images | Camera | No. of Images | Spatial Resolution | Spectral Range (nm) | No. of Channels |
|---|---|---|---|---|---|---|
| Bristol (1994) [26] | Outdoor scenes of vegetation | Pasecon integrating camera tube | 29 | 256 × 256 | 400–700 | 31 |
| Natural scenes (2002) [29] | Urban and rural scenes | Pulnix TM-1010 with VariSpec tunable birefringent filter | 8 | 1024 × 1024 | 410–710 | 31 |
| Natural scenes (2004) [30] | Reflectance image of natural scenes | Hamamatsu C4742-95-12ER with VariSpec liquid crystal tunable filter | 8 | 1344 × 1024 | 400–720 | 33 |
| Natural scenes (2015) [31] | Radiance image of natural scenes | Hamamatsu C4742-95-12ER with VariSpec liquid crystal tunable filter | 30 | 1344 × 1024 | 400–720 | 33 |
| Time-Lapse (2015) [27] | Images of 5 natural scenes taken at different times | Hamamatsu C4742-95-12ER with VariSpec liquid crystal tunable filter | 33 | 1344 × 1024 | 400–720 | 33 |
| ICVL (2016) [28] | Urban and rural scenes | Specim PS Kappa D×4 | 201 | 1392 × 1300 | 400–1000 | 519 |
| Harvard (2011) [33] | Indoor and outdoor images | Nuance FX, CRI Inc. | 50 | 1392 × 1040 | 420–720 | 31 |
| UGR (2015) [32] | Outdoor scenes | Photon V-EOS | 14 | 1392 × 1040 | 400–1000 | 61 |
| CAVE (2008) [35] | Materials and objects | Apogee Alta U260 with VariSpec liquid crystal tunable filter | 32 | 512 × 512 | 400–700 | 31 |
| East Anglia (2004) [36] | Everyday objects placed in viewing booth | Applied Spectral Imaging Spectracube camera | 22 | Various resolutions | 400–700 | 31 |
| SIDQ (2015) [40] | Pseudo-flat objects | HySpex-VNIR-1600 | 9 | 500 × 500 | 400–1000 | 160 |
| Brainard (1998) [37] | Indoor scenes | Kodak KA4200 CCD with Optical Thin Films filter | 9 | 2000 × 2000 | 400–700 | 31 |
| Nordic sawn timbers (2014) [44] | Wood samples | N/A | 107 | 320 × 800 | 300–2500 | 440 |
| Scien (2012) [45] | Various objects, scenes and faces | N/A | 106 | Various resolutions | Various range | Various channels |
| Paintings (2017) [42] | Paintings | IRIS II filter wheel camera | 23 | 2560 × 2048 | 360–1150 | 23 |
| Ancient manuscripts (2012) [38] | Printed documents | Hamamatsu C4742-95-12ER with VariSpec liquid crystal tunable filter | 3 | 1344 × 1024 | 400–700 | 33 |
| Apple tree leaves (2018) [43] | Near infrared images of healthy & infected leaves | HySpex SWIR-320m-e | N/A | Various resolutions | 960–2490 | 256 |
| SpecTex (2017) [39] | Textiles | ImSpector V8 | 60 | 640 × 640 | 400–780 | 39 |
| Honey (2017) [41] | Honey samples | Surface Optic Corporation SOC710-VP | 32 | 520 × 696 | 400–1000 | 126 |
| Singapore (2014) [34] | Outdoor images of natural objects, man made objects, buildings | Specim PFD-CL-65-V10E | 66 | Various resolutions | 400–700 | 31 |
| HyTexiLa Our proposed dataset | Textured materials from 5 different categories | HySpex VNIR-1800 | 112 | 1024 × 1024 | 400–1000 | 186 |
| Value of | |
|---|---|
| After sensor correction | 0.0167 (0.0098) |
| After sensor and affine correction | 0.0006 (0.0003) |
| Ruler along x-axis | |
|---|---|
| Without corrections | 18.30 (1.21) |
| After sensor correction | 18.28 (0.60) |
| After sensor and affine correction | 18.31 (0.61) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, H.A.; Mihoubi, S.; Mathon, B.; Thomas, J.-B.; Hardeberg, J.Y. HyTexiLa: High Resolution Visible and Near Infrared Hyperspectral Texture Images. Sensors 2018, 18, 2045. https://doi.org/10.3390/s18072045
Khan HA, Mihoubi S, Mathon B, Thomas J-B, Hardeberg JY. HyTexiLa: High Resolution Visible and Near Infrared Hyperspectral Texture Images. Sensors. 2018; 18(7):2045. https://doi.org/10.3390/s18072045
Chicago/Turabian StyleKhan, Haris Ahmad, Sofiane Mihoubi, Benjamin Mathon, Jean-Baptiste Thomas, and Jon Yngve Hardeberg. 2018. "HyTexiLa: High Resolution Visible and Near Infrared Hyperspectral Texture Images" Sensors 18, no. 7: 2045. https://doi.org/10.3390/s18072045
APA StyleKhan, H. A., Mihoubi, S., Mathon, B., Thomas, J. -B., & Hardeberg, J. Y. (2018). HyTexiLa: High Resolution Visible and Near Infrared Hyperspectral Texture Images. Sensors, 18(7), 2045. https://doi.org/10.3390/s18072045