1. Introduction
Passive location plays a significant role in modern communication scenarios for its satisfactory concealment based on the passive reception pattern. In addition, with the characteristics of long distance measurement and high robustness [
1], passive location techniques are of significance in both civil and military areas. The major passive location technique is angle-of-arrival (AOA) [
2], which obtains the target location by combining the measured angles of each station and whose performance is highly affected by scheduling plans [
3,
4]. Resource scheduling is implemented to establish an optimized task-to-resource dispatch with the purpose of maximizing the total performance (such as location accuracy and task completion rate) and avoiding the conflicts effectively. However, despite its importance, little attention is paid to the scheduling mechanism. In recent years, studies in passive location have mainly focused on location algorithms [
5,
6], accuracy analysis [
7], filters and tracking [
8,
9]. There is little information available in the literature about passive location resource scheduling. The scheduling method mostly used today, which we call traditional manual scheduling, is unable to handle the increasing number of tasks and overloaded resources, thus leading to the following serious problems.
Low efficiency. Because manually allocated broadcast resources cannot achieve parallel processing very well, when task conflicts occur, some signals may be lost, reducing efficiency.
Unstable location accuracy. Because location accuracy is highly relevant to the stations-to-tasks schedule plans, it is possible to encounter low location accuracy due to mistakes caused by human subjectivity.
To address these problems and achieve high efficiency and location accuracy, new intelligent automated scheduling methods urgently need to be studied. Xiu et al. [
10] analyzed constellations in bearing-only location systems and proposed an optimal geometric relationship to improve location precision and minimize circular probable error, providing an important reference for station scheduling. Prasan et al. [
11] proposed the pre-scheduling-based k-coverage group scheduling and self-organized k-coverage scheduling algorithms to address problems in existing sleep-scheduling algorithms.
Hu et al. [
12] established a centralized framework for sensor scheduling in wireless sensor networks and modeled the problem using integer linear programming. In [
13], the proposed algorithms, which deal directly with minimizing the mean squared error, are based on the convex relaxation approach to address the binary optimization scheduling problems that are formulated in sensor network scenarios. Xu et al. [
3] analyzed the Cramer-Rao lower bound of AOA and discussed the measurement of location accuracy based on the information matrix. Wei et al. [
9] proposed a modified binary particle swarm optimization (BPSO) algorithm motivated by the information matrix in the wireless sensor network nodes scheduling problem for tracking. Sun et al. [
14] were inspired by Xu et al. and Wei et al. and proposed a BPSO algorithm motivated by geometric dilution of precision deduced from the information matrix for station scheduling. However, Sun et al. did not solve the problem thoroughly because they neglected to consider complex constraints and efficiency. Furthermore, previous studies seldom discuss scheduling strategies for scenes with multiple concurrent tasks. Therefore, to solve passive location station scheduling more specifically, the scheduling method must satisfy these conditions. (1) The optimal objective must involve not only accuracy but also other important factors, especially efficiency. (2) Complex constraints are formulated. (3) The method can support multiple concurrent task scenarios.
Inspired by the factors mentioned above, we propose a new method called multi-object, multi-constraint and improved genetic algorithm-based Scheduling (MMIGAS), enhancing the efficiency and practicability for passive location resource scheduling. Our first contribution is to construct a mathematical primary centralized optimization model of passive location resource scheduling according to a practical system framework. Second, we introduce position dilution of precision (PDOP) to measure the location accuracy and define other objective values, such as completion rate, resource utilization and task priority. These values are combined into a multi-objective function to ensure that our schedule can balance performance with respect to multiple aspects, specially efficiency. Third, based on several important assumptions, we formulate complex constraints in three categories: frequency, station capability and task cooperation requirement, thus improving practicability. Moreover, since the model is an NP-hard problem, we conceive an improved genetic algorithm (IGA) by introducing constraint-proof initialization (CI), penalty function (PF) and modified genetic operator (MGO), which can achieve a better convergence rate and global optimization ability. Simulations show that MMIGAS has a satisfactory astringency and stability of time complexity. Additionally, the method is appropriate for multiple concurrent targets. Compared with manual scheduling, MMIGAS can clearly improve the efficiency while maintaining high location accuracy.
The remainder of this paper is organized as follows.
Section 2 introduces the primary framework of the location system, clarifies some critical assumptions and establishes a basic mathematical optimization model. In
Section 3, we demonstrate our design for multiple objectives and multiple constraints. In
Section 4, we illustrate the three steps of the IGA: CI, PF and MGO.
Section 5 presents the experimental results and analyses the performance of proposed method.
Section 6 concludes the paper.
2. Problem Formulation
The passive location channel is heavily crowded due to the narrowband and dense signals. The time-varying fading and silence zones also cause many problems, making the passive location problem a difficult task and topic of interest [
15,
16,
17,
18,
19,
20]. To increase the location accuracy and flexibility, a location system generally uses a cooperative location approach [
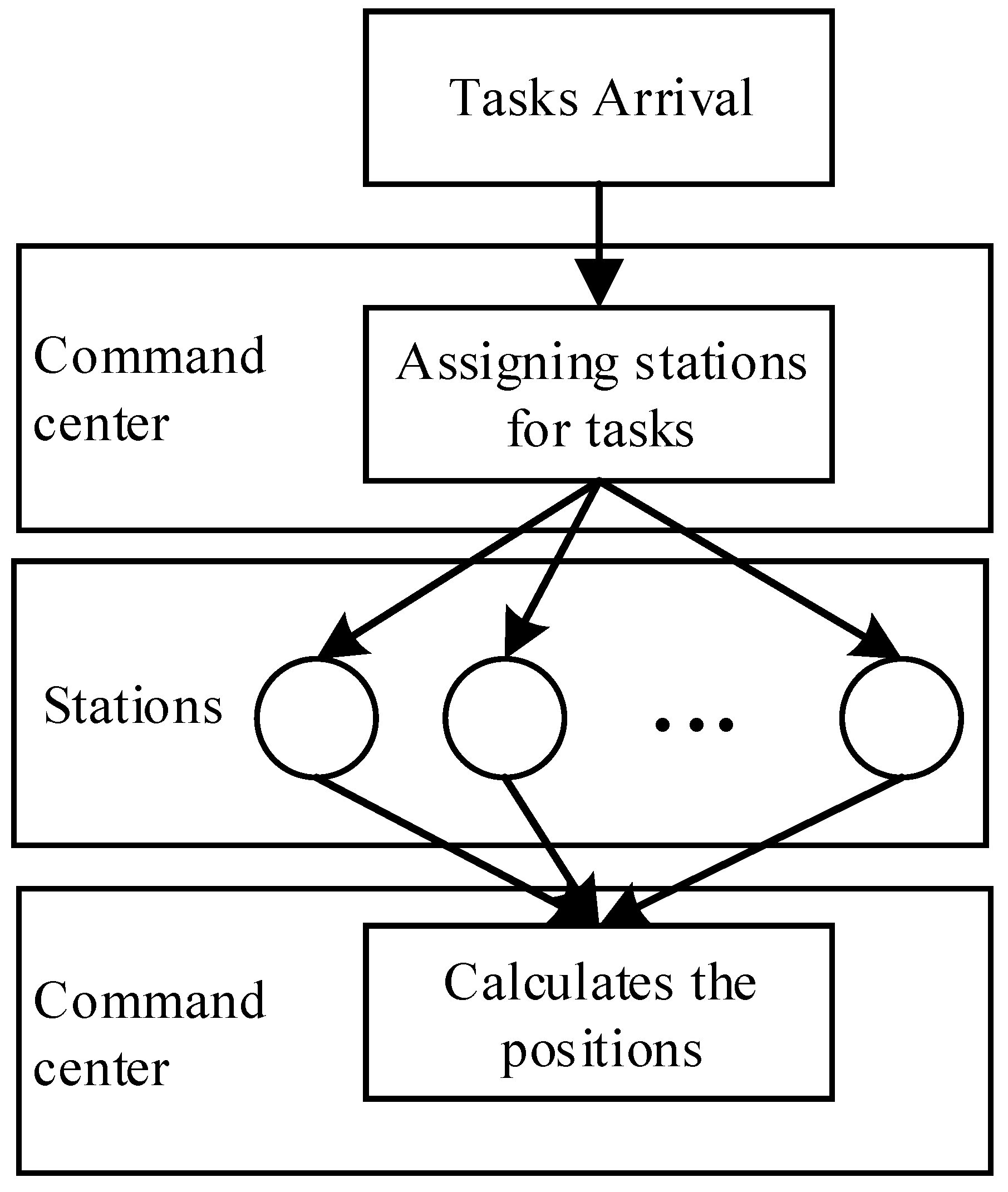
21], which consists of the steps of task arrival, command downloading, data uploading and position output, as shown in
Figure 1.
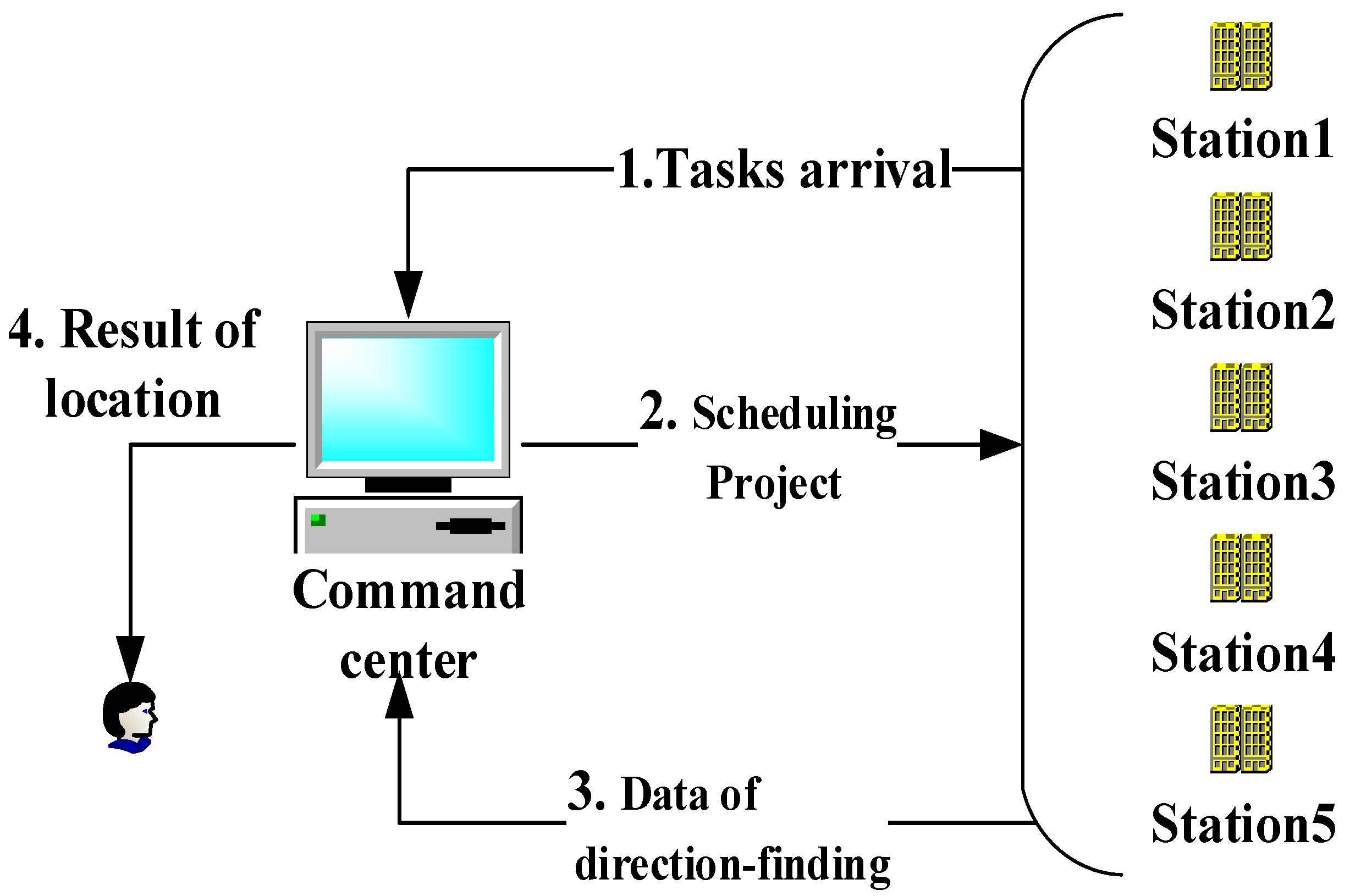
Moreover, the system has a centralized architecture consisting of the command center and direction-finding stations, as shown in
Figure 2. Therefore, the essence of station scheduling is a centralized tasks-to-resources allocation, which guides us to establish a combination optimization model.
2.1. Assumptions and Scenario Declaration
Because the passive location scenario is extremely complicated due to complex channels [
22], we make some critical assumptions to simplify this problem.
We ignore the silence zone. This assumption is made to reduce the space constraint and make the model more concise. According to related studies, potential silence zones can be fully avoided if appropriate locations for building stations are chosen [
10].
Signals from all directions have the same gain in the receiving antennas. This assumption is made to ensure the strength of the signal directly reflects the distance between the station and the target, which simplifies the discussion about geographical relationships. This can be achieved by using an omnidirectional antenna.
Targets are static or moving slowly enough that their locations do not noticeably change over a short time. This assumption avoids a heavy time delay or even invalidation of the scheduling due to drastic changes in geographical relationships.
Prior knowledge about targets is available. This assumption ensures that the approximate potential area of the target is known, which is an essential condition of using the proposed scheduling method.
In addition, the scenario discussed in this paper is specified by the following declarations.
We only discuss the scheduling activity in one slot. We define one slot as the duration of a scheduling and location process. It is the minimum interval needed to implement one complete activity in the passive location system. Therefore, any length of time can be considered to be a sum of several slots.
We only discuss narrow-band stations because wide-band stations can be considered the sum of several different narrow-band stations.
2.2. Notation
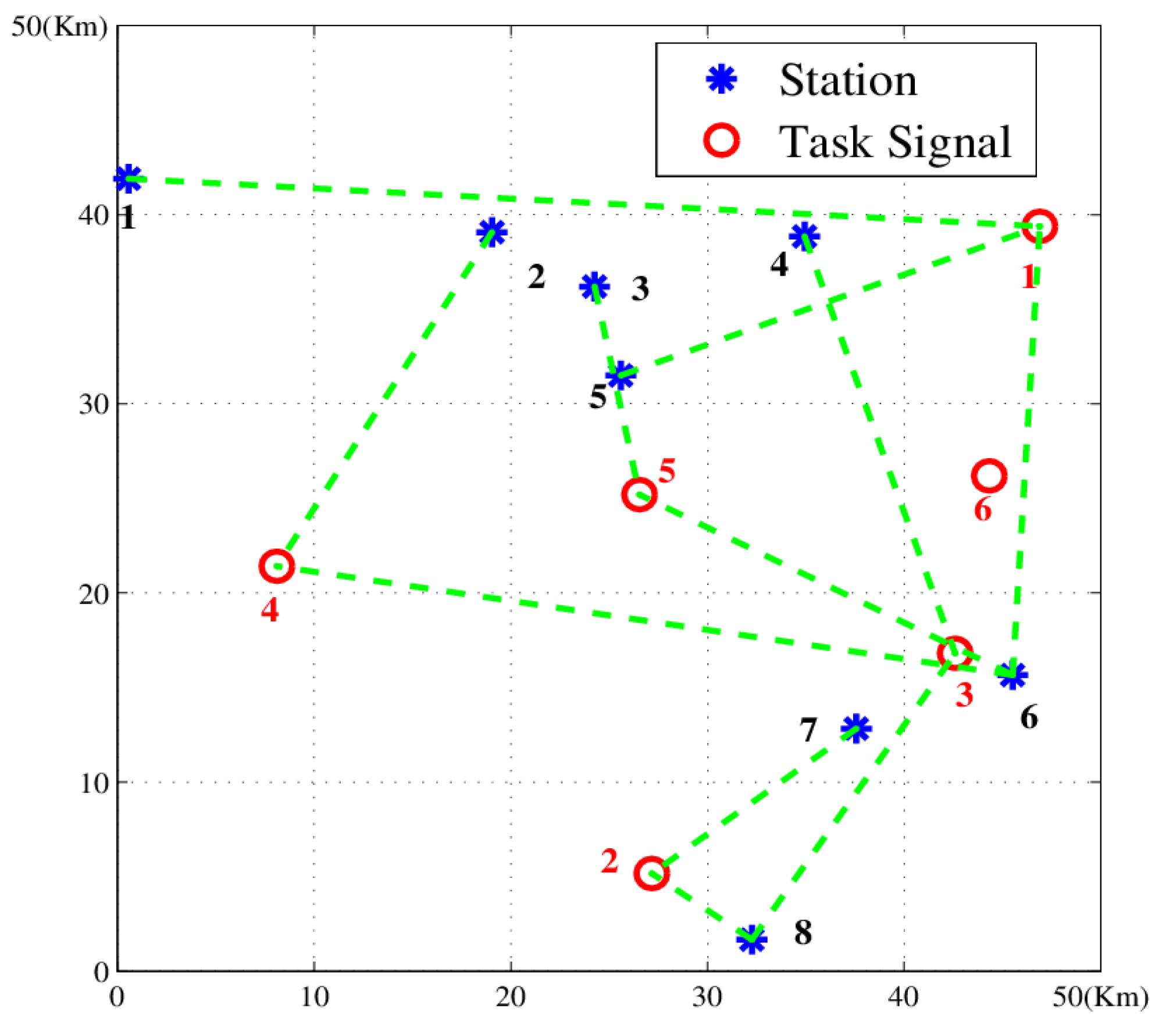
Stations and signals are considered to be resources and tasks, respectively. And to demonstrate their allocation relationship, we structure a scheduling matrix as follows.
- 1.
Task: We denote tasks as , where is the total number of tasks. We use four attributions to describe a task: frequency, location, collaboration and priority, , where denotes the task sequence number.
gives the frequency range of the task signal, where and .
denotes the two-dimensional coordinates of task , where .
gives the cooperative station number requirement for task location, where .
. We define the priority of tasks as an integer ranging from 1 to 6. The task is more important if its is higher.
- 2.
Resources: We denote direction-finding stations as . We use three attributions to describe one station (resource): frequency, location and capability, . Here, denotes the station sequence number.
is the frequency range at which the station implements direction-finding, where and .
denotes the two-dimensional coordinates of station , .
is the maximum number of tasks the station can process synchronously, implying its working capacity, where .
- 3.
Scheduling matrix: We design a binary solution matrix with columns and rows as , where indicates the relation between station and task . Here means that station is assigned to process task , while means is not assigned to process .
2.3. Optimization Model
Based on the analysis mentioned above, we formulate the passive location resource scheduling problem as a combination optimization problem. Denote
as the objective function,
as the equality constraints and
as the inequality constraints. Then, the mathematical model is:
4. IGA
Due to the strong relevant effects among tasks and resources, the proposed model becomes an NP-hard problem [
26], for which a genetic algorithm (GA) is suitable for searching for a solution because of its adaptive global optimization ability. Originally, a GA was conceived based on the simulation of heredity and evolution in the natural environment [
27].
In the algorithm initialization, various initial feasible solutions are randomly generated as the original genetic group. During the iterations, genetic operators construct the offspring based on the parental genetic group, where the genes with highest environmental fitness can survive and multiply, thus conveying the dominated characteristics into the final generation. Eventually, the algorithm obtains an optimal solution. Compared with other algorithms, GA has low complexity and high practicability [
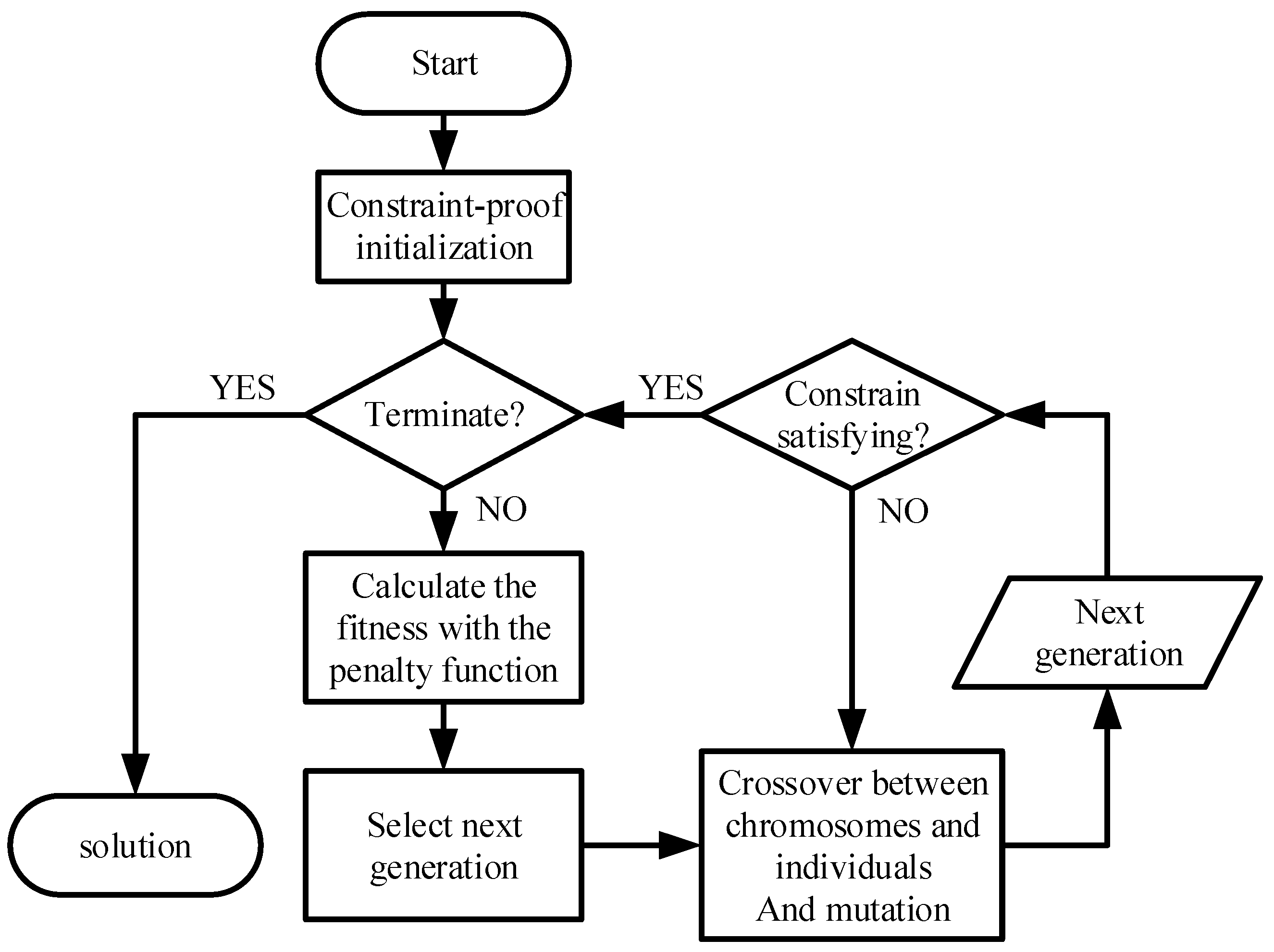
28], thus being appropriate for the passive location resource scheduling problem. However, the normal GA has the disadvantages of a low convergence rate and local optimization dilemma. To make it more suitable for our application scenario, we make several improvements by implementing CI, PF and MGO, helping the algorithm to obtain a satisfying solution quickly. The objective function is utilized as the fitness function, while the decision matrix is used for gene construction. The process of the algorithm is shown in
Figure 3 and details in Algorithm 1.
| Algorithm 1. IGA. |
| 1. Parameters setting and constraint-proof initialization. |
| 2. Terminate? Yes→Step 6, No→Step3. |
| 3. Calculate the fitness with the PF and select next generation. |
| 4. Use MGO to get next generation. |
| 5. Constrain satisfaction? Yes→step 2, No→Step 4. |
| 6. Get the solution. |
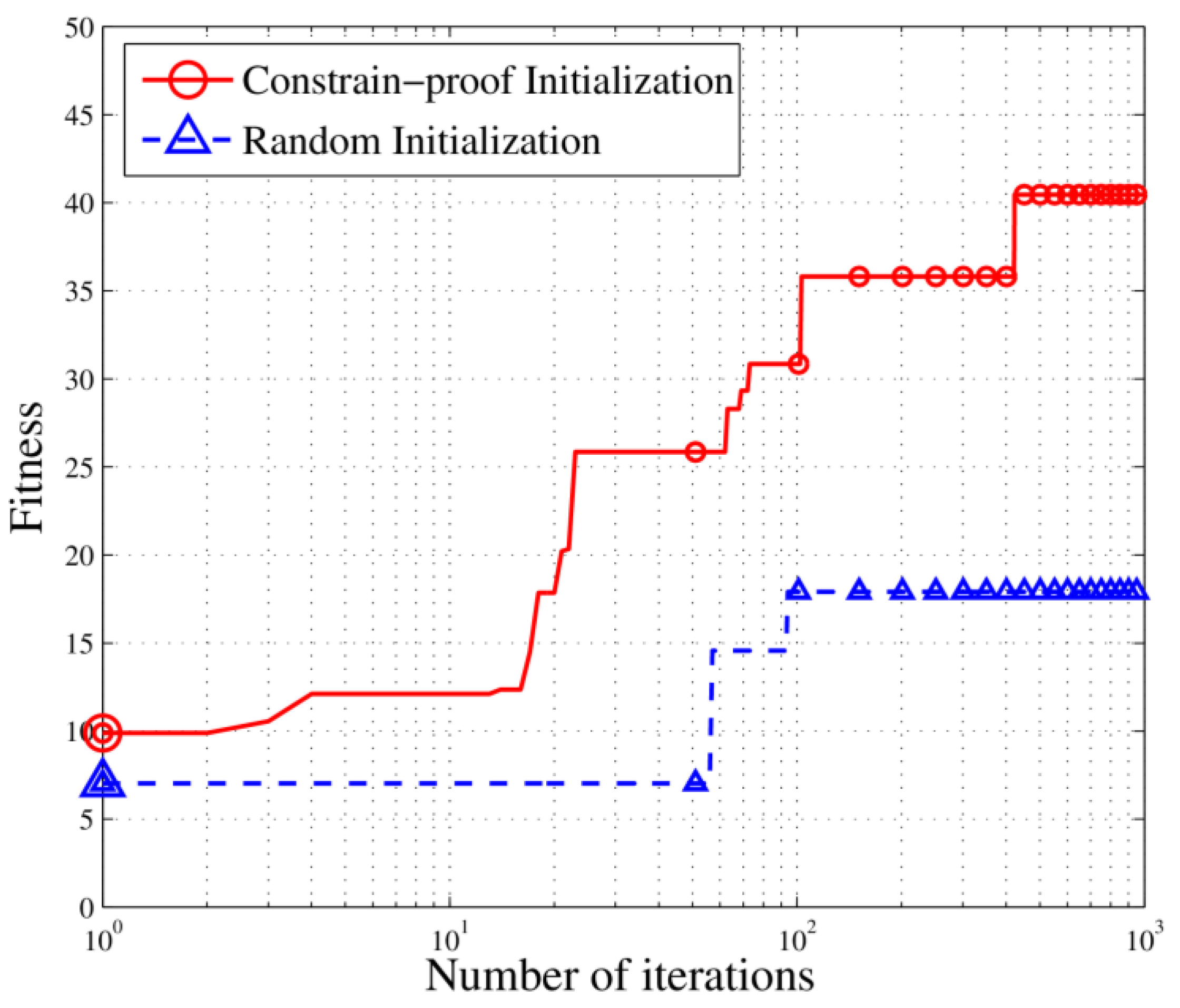
4.1. CI
Traditional GA is very sensitive to the initial values [
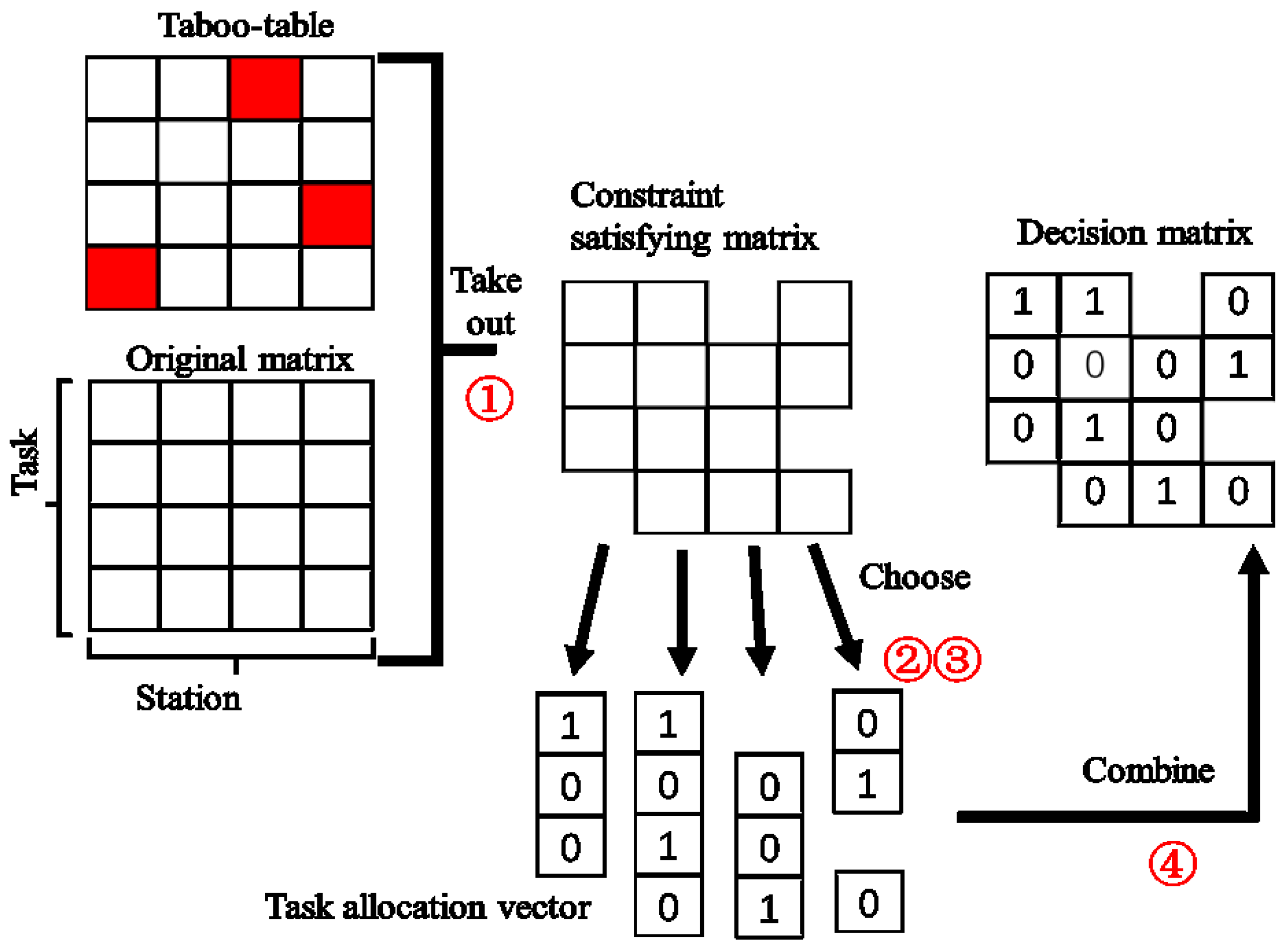
29]. When the initial values do not meet the constraints, the algorithm is unable to calculate the fitness and thus the evolution direction is unclear, which substantially reduces the convergence rate and even leads to the non-convergence. Therefore, in order to provide a specific evolution direction at the beginning and improve the astringency, we implement the CI by building a taboo-table which marks out the element unable to satisfy the frequency constrain and coding the scheduling matrix stepwise. The process is shown in
Figure 4.
Step ①: Generate the original matrix according to the number of tasks and stations. Build up a taboo-table by using Equations (14)–(16). And take away the taboo-table from the original matrix to obtain the frequency-satisfying matrix.
Step ②: Select one column of the matrix as a vector, which indicates the task scheduling table of one station. Value it randomly within the capability of the resource and then use it as a task allocation vector.
Step ③: Repeat Step ② for every column in the frequency-satisfying matrix to obtain the task allocation vectors of all stations.
Step ④: Combine the task allocation vectors as a decision matrix.
4.2. PF
To enhance the algorithm performance, the original genetic group must satisfy all constraints in our model. CI guarantees the original genetic group will meet the constraints on frequency and resource capability. For the task cooperation constraint, we introduce the PF method based on
Section 2.2 and Equation (1).
Denote
as the penalty factor. Set
. Define
as the number of stations scheduled for task
. The PF is denoted as
:
Therefore, the fitness function becomes:
According to (17) and (18), if one solution does not meet the task cooperation requirement, its will increase exponentially, rapidly reducing its fitness and causing it to be eliminated during the iteration. Therefore, solutions eventually that survive must satisfy the task cooperation constraint.
4.3. MGO
The preceding section introduces the generation of the initial solution and the penalty function. Then, we will introduce the modified genetic operation of the solution which contains roulette wheel, elitism selection, crossover and mutation.
4.3.1. Roulette Wheel and Elitism Selection
We introduce a combined roulette-wheel and elitism selection strategy, which can keep the randomness of offspring and prevent the loss of the best individual in the group. First, the individuals with the highest fitness are directly saved to the next generation. Second, parents are selected according to probability
, of individual
, which is calculated as follows:
where
is the population of genetic group in this algorithm and
is the fitness of individual
.
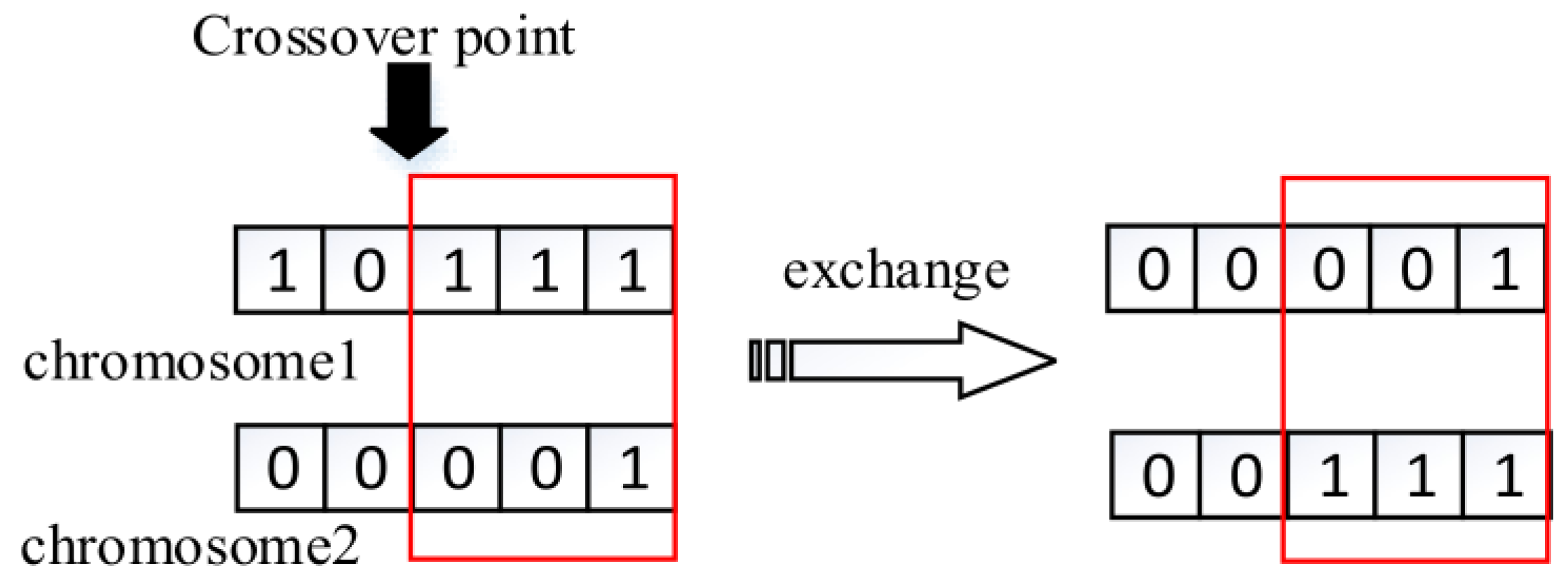
4.3.2. Crossover
1. Crossover between chromosomes
There is a probability
that chromosome crossover will happen for each individual. In the case, two chromosomes will be randomly selected and exchange their gene in the same location. Parameters
is set according to human experience, normally ranging from 0.3 to 0.7.
Figure 5 shows the crossover process.
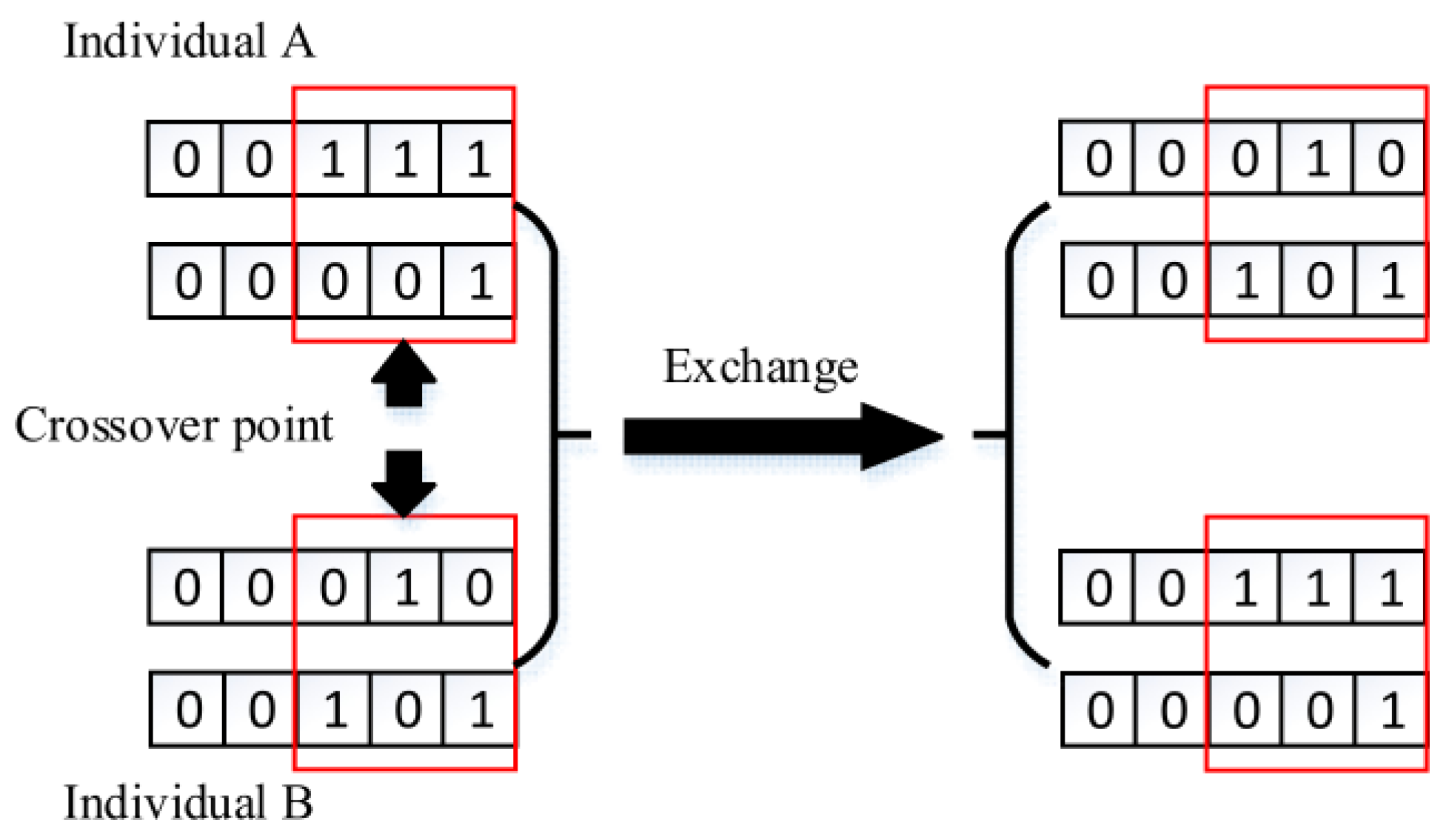
2. Crossover between individuals
In the same way, we need to consider the concurrent processing of multiple tasks. So, there is a probability
for individual crossover among the entire group, which is the operation that one individual exchanges part of its genes with another. The location at which the gene exchange happens is selected randomly. Probability
is set by experience as well, normally ranging from 0.3 to 0.7.
Figure 6 shows the process of two concurrent tasks.
3. Mutation
In every individual, there is a probability
of mutation, which is when one or more genes inside this individual change themselves randomly. Parameter
usually ranges from 0.01 to 0.1. An example of mutation is shown in
Figure 7.
6. Conclusions
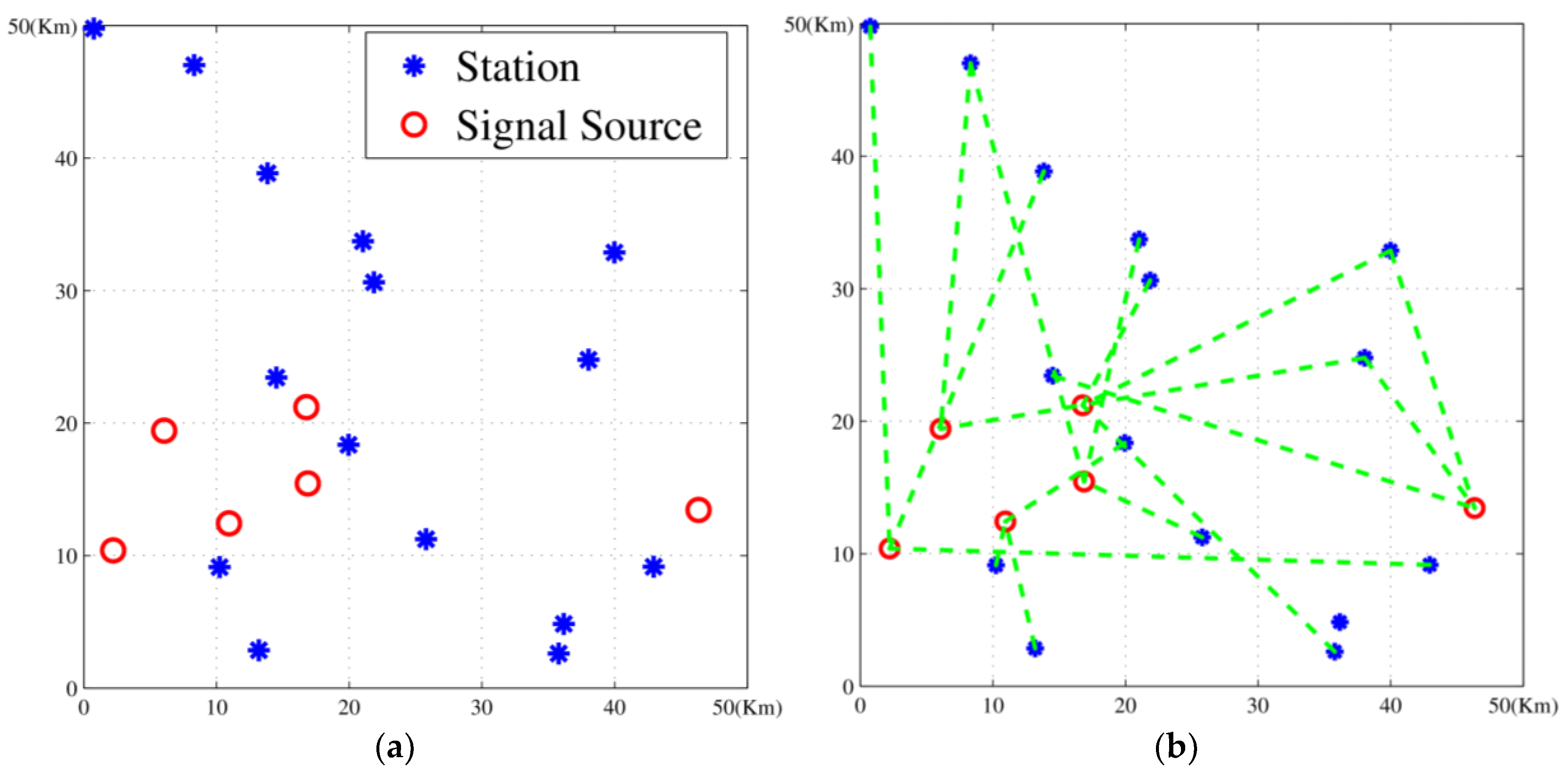
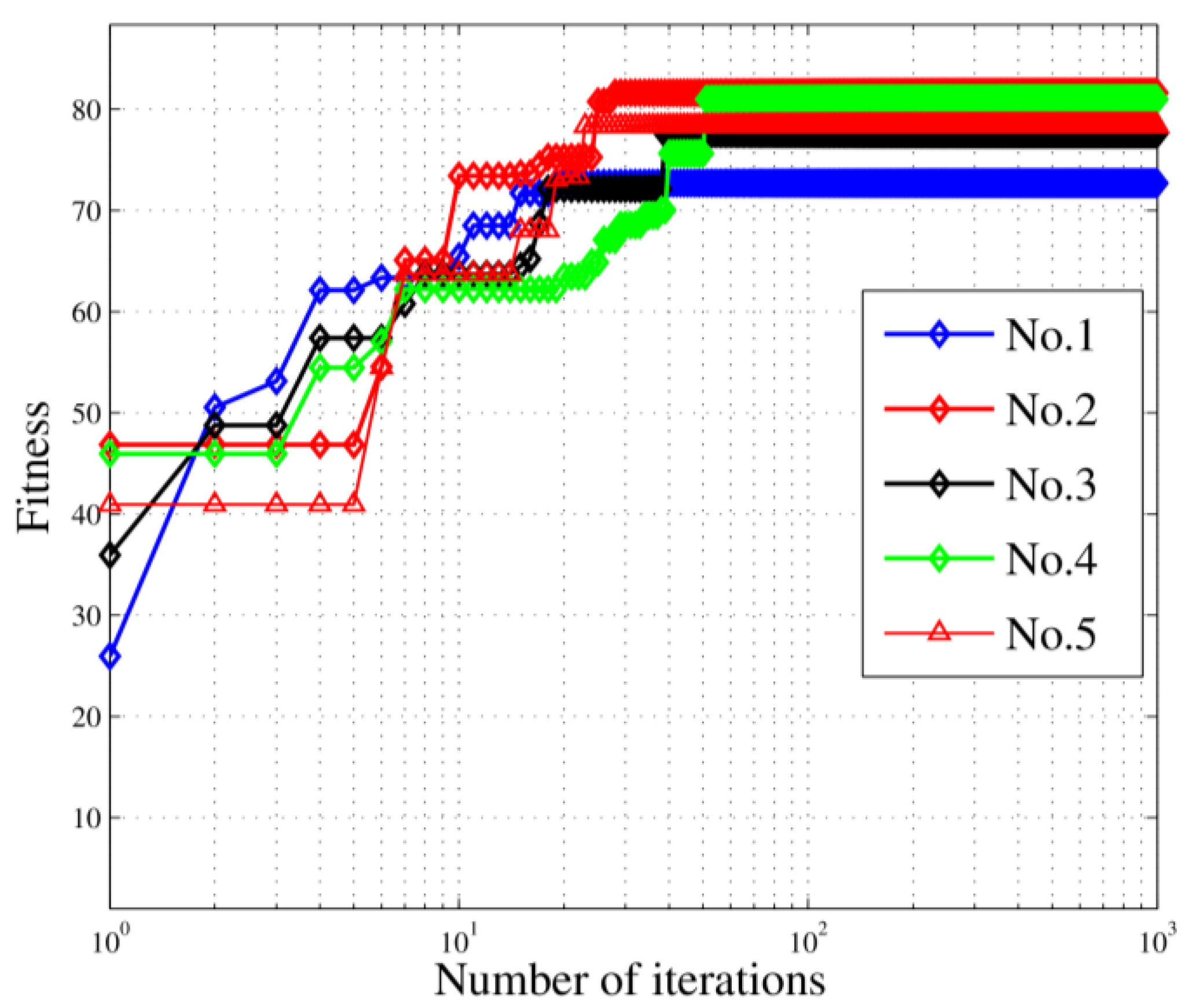
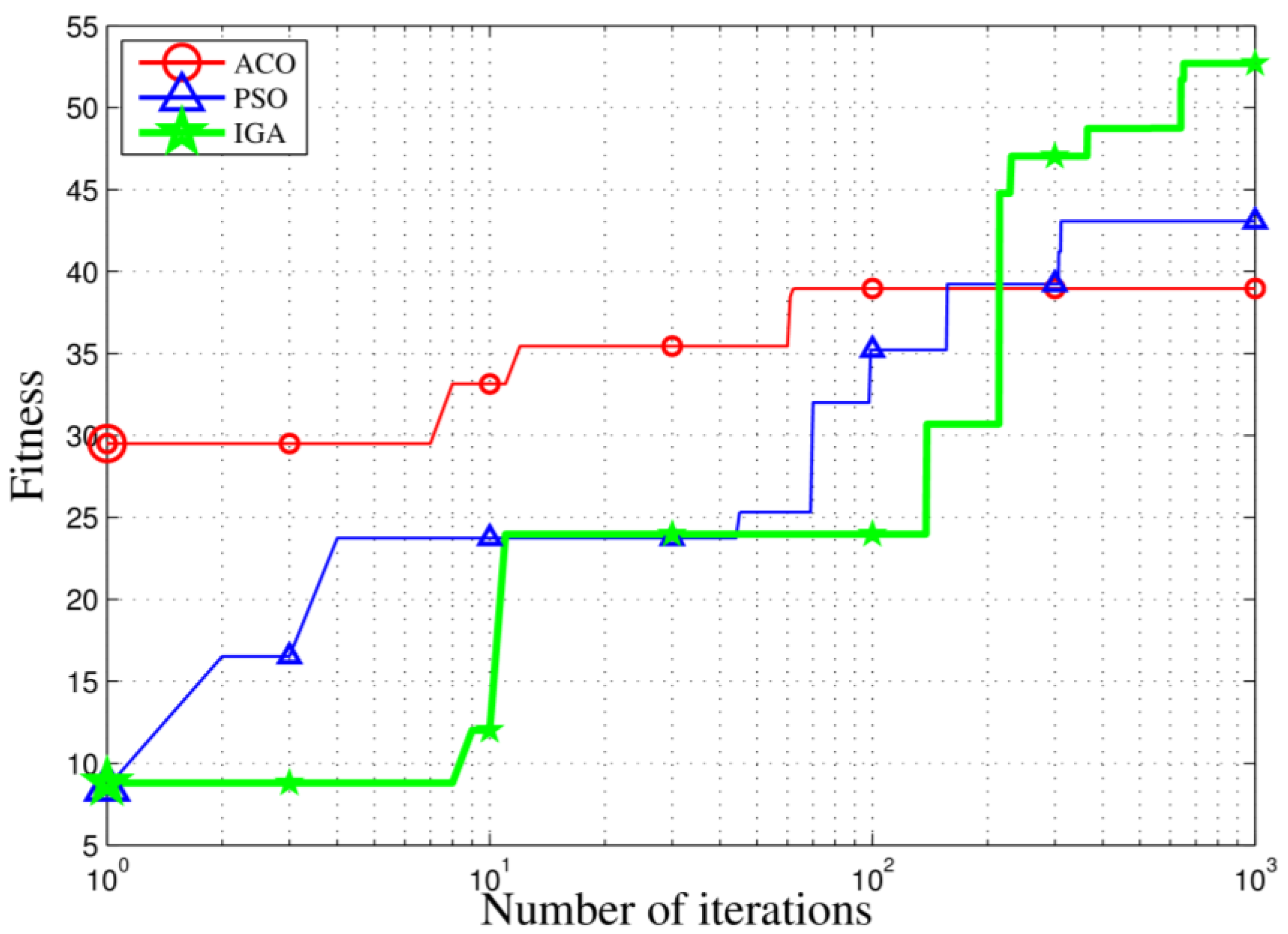
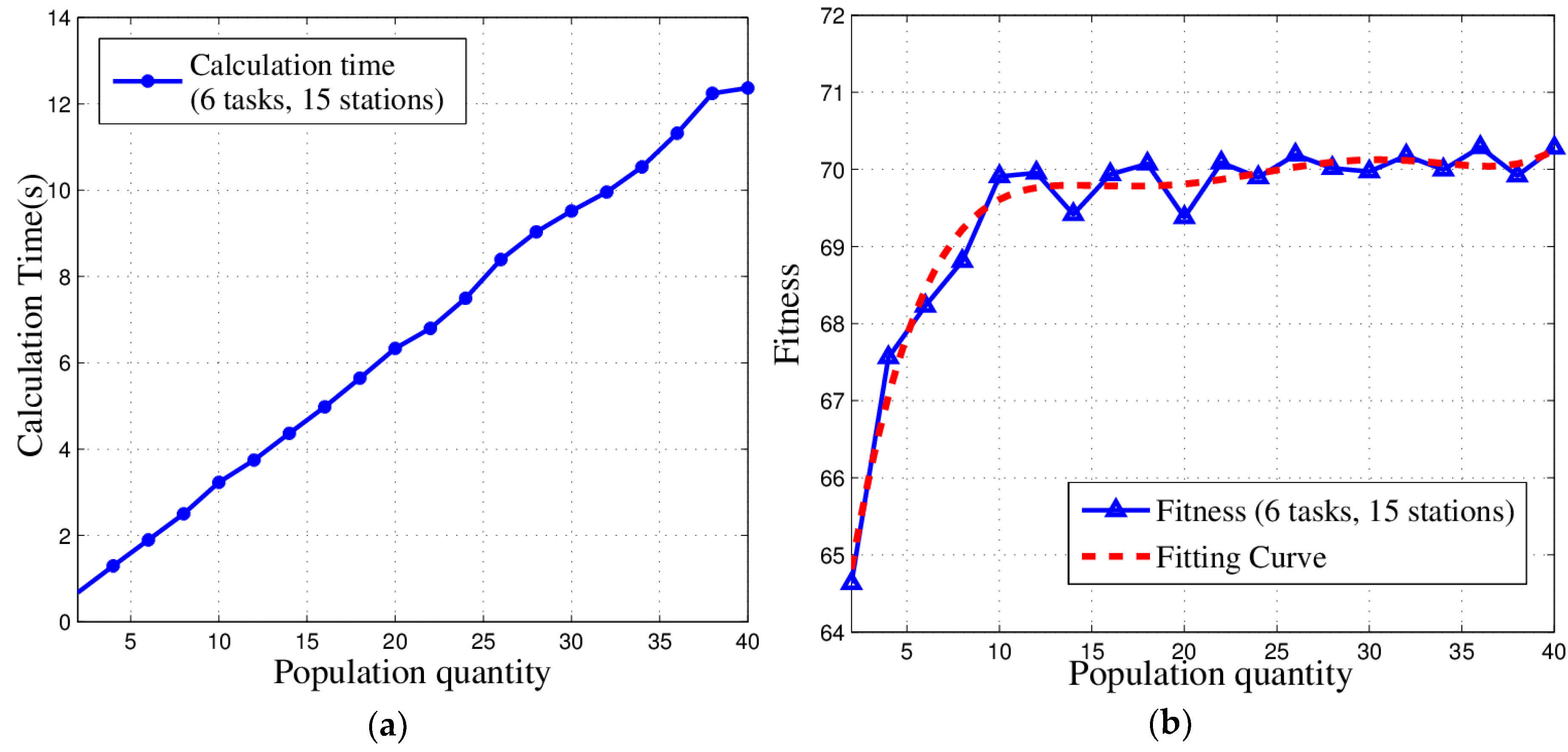
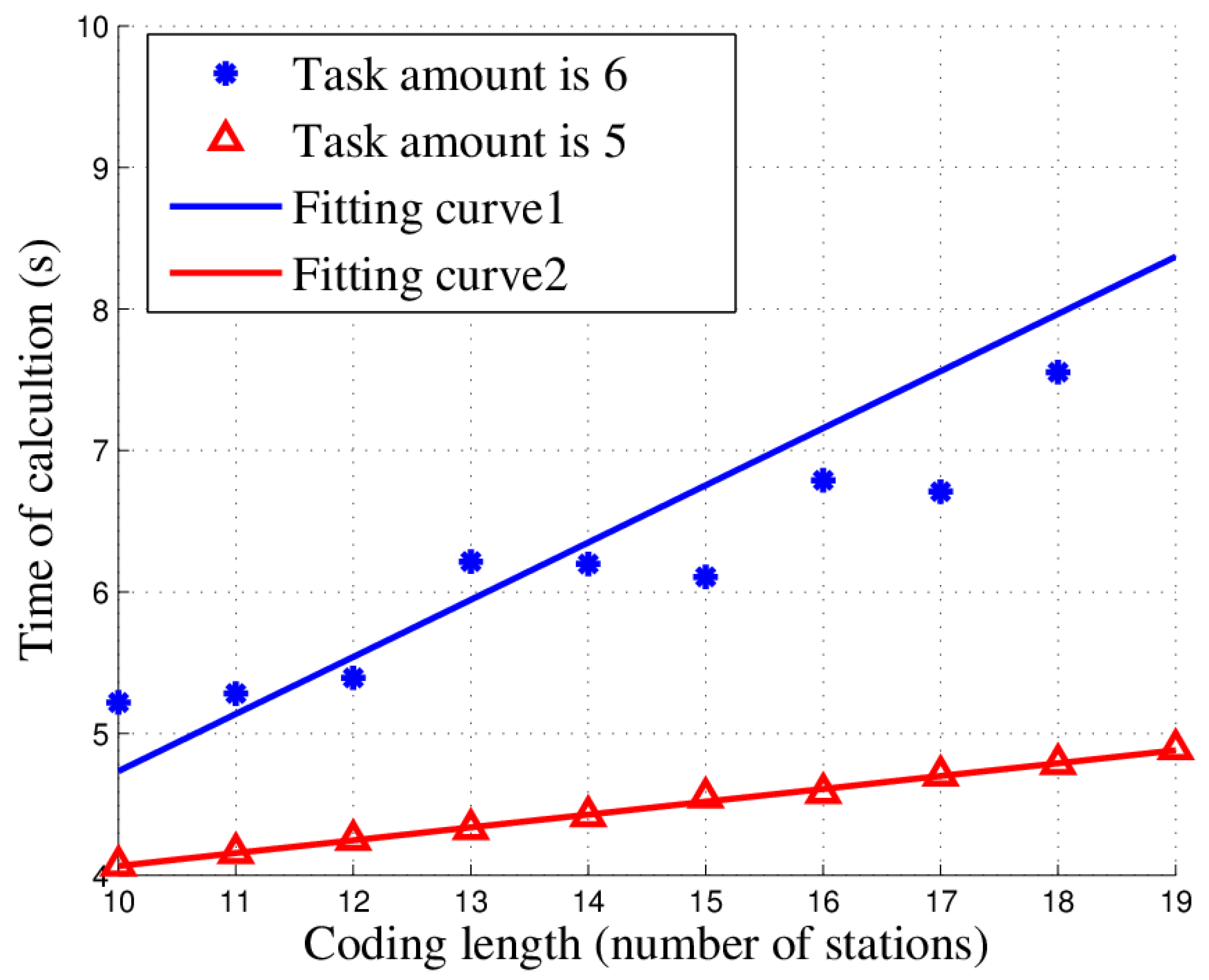
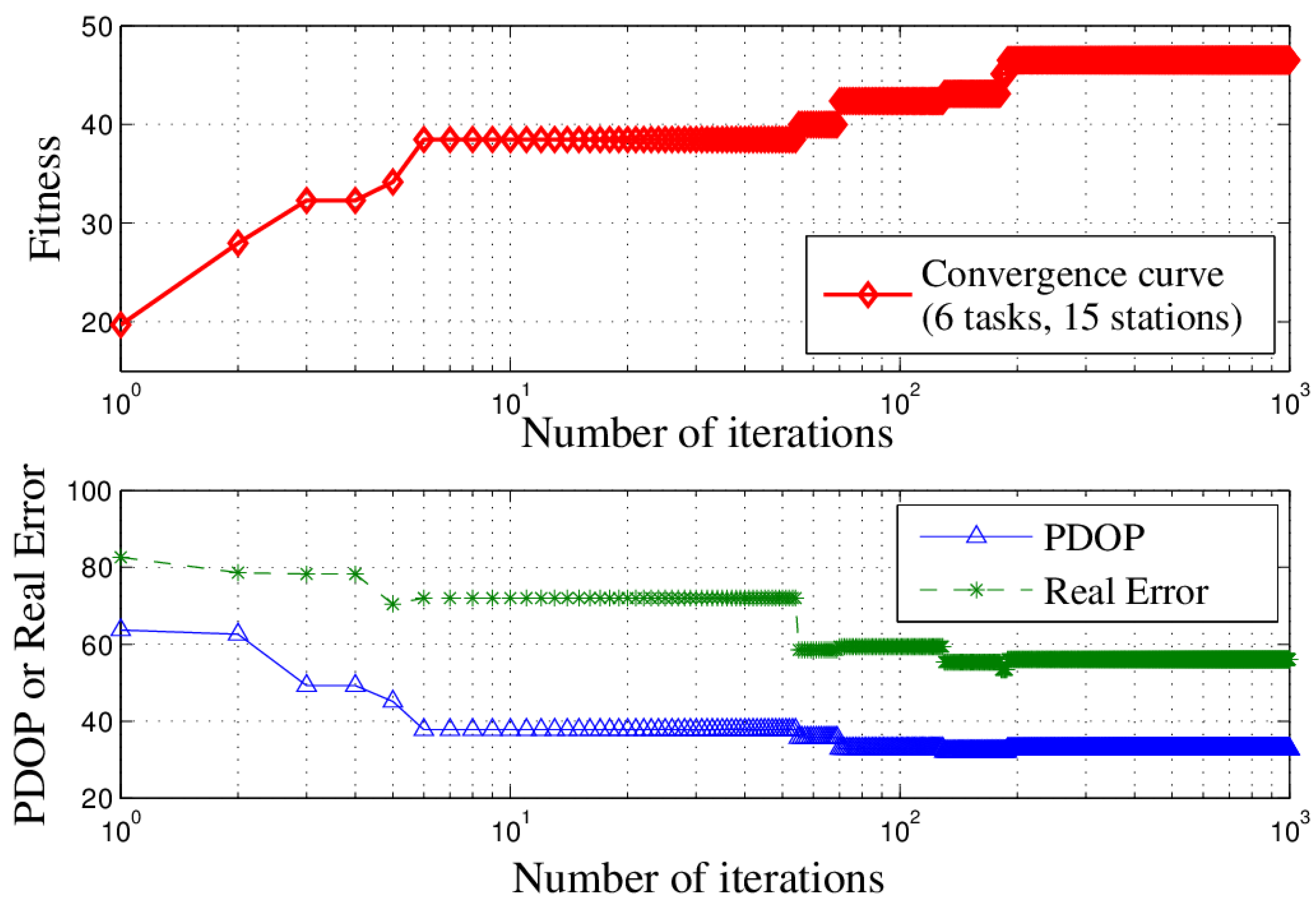
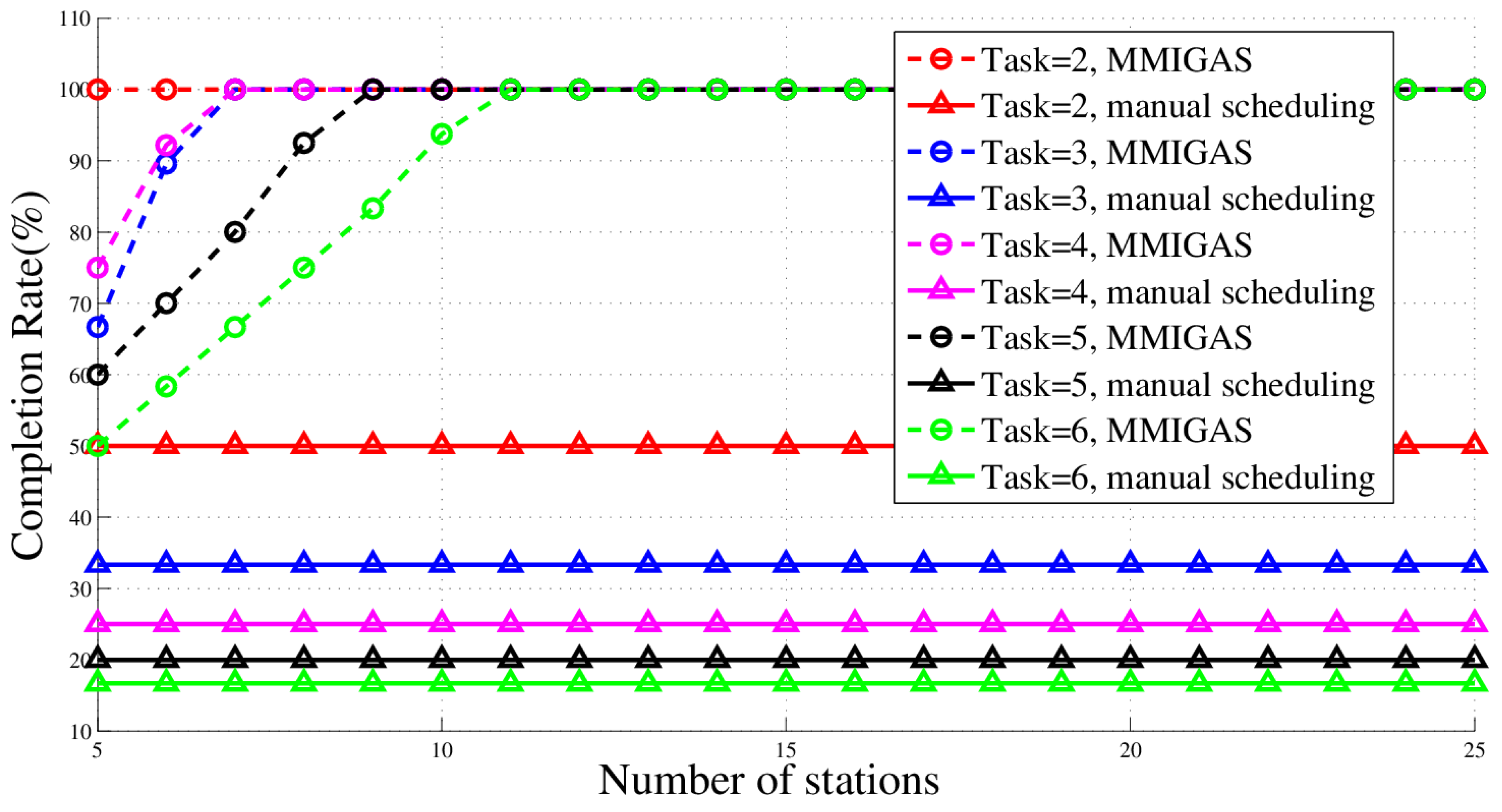
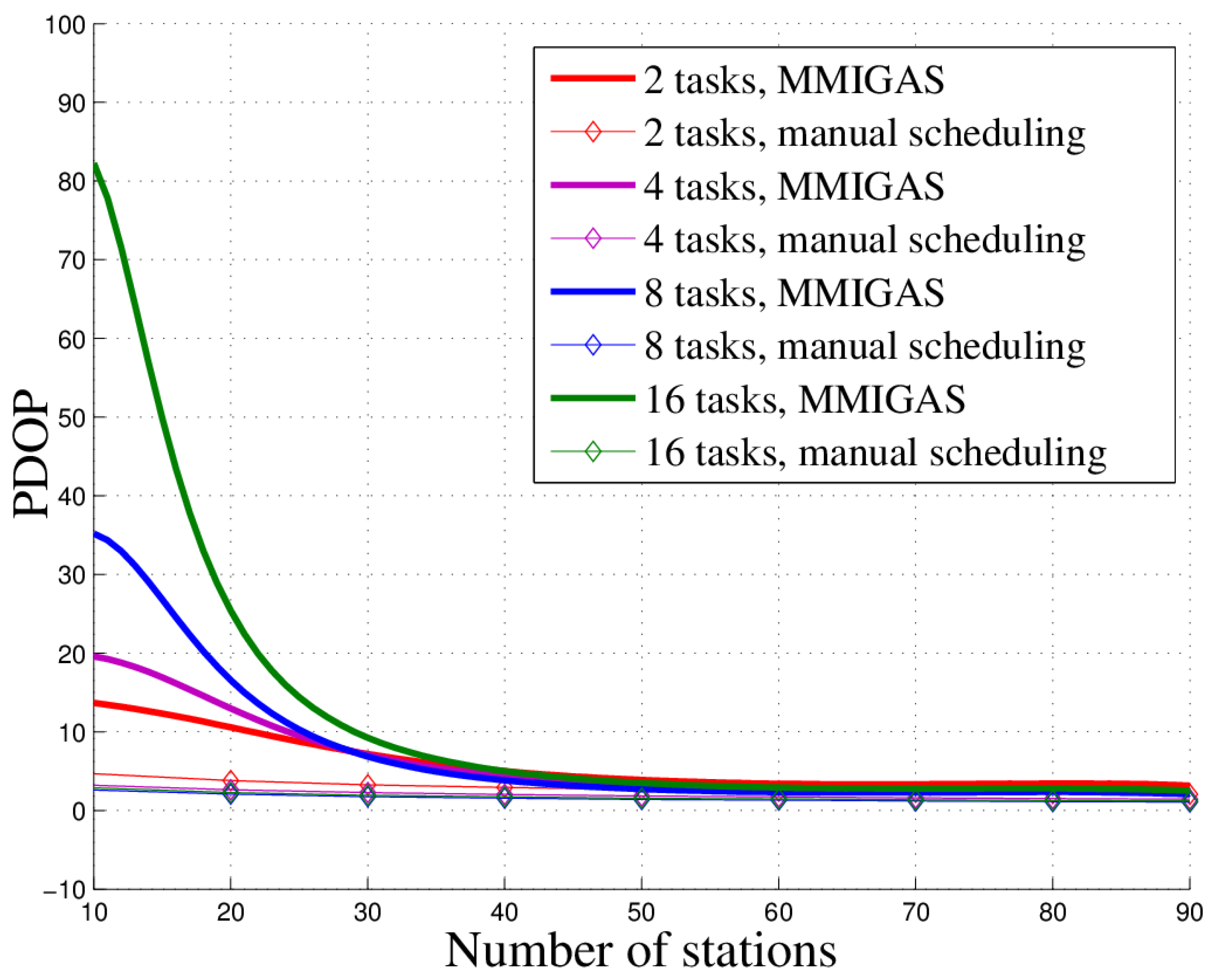
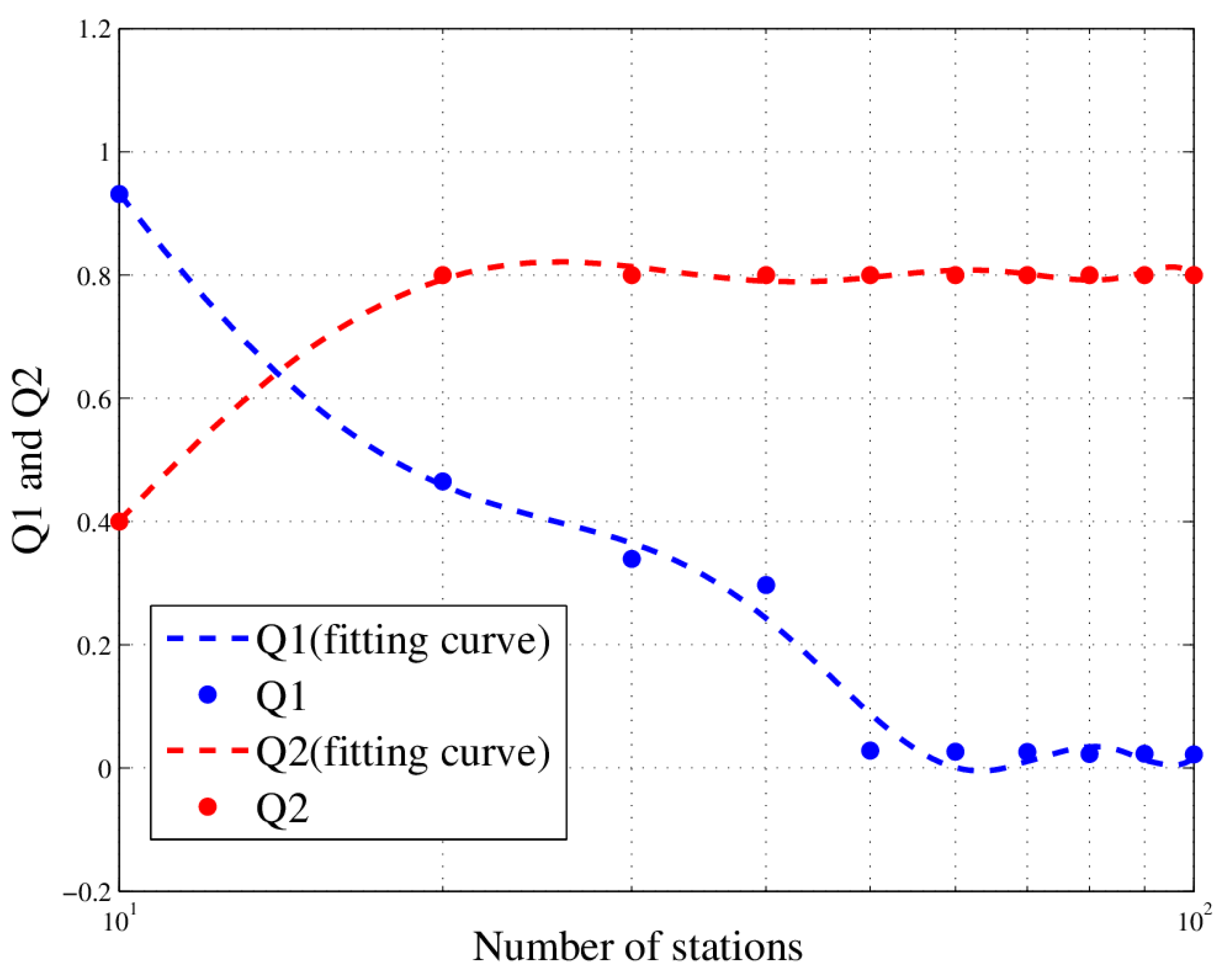
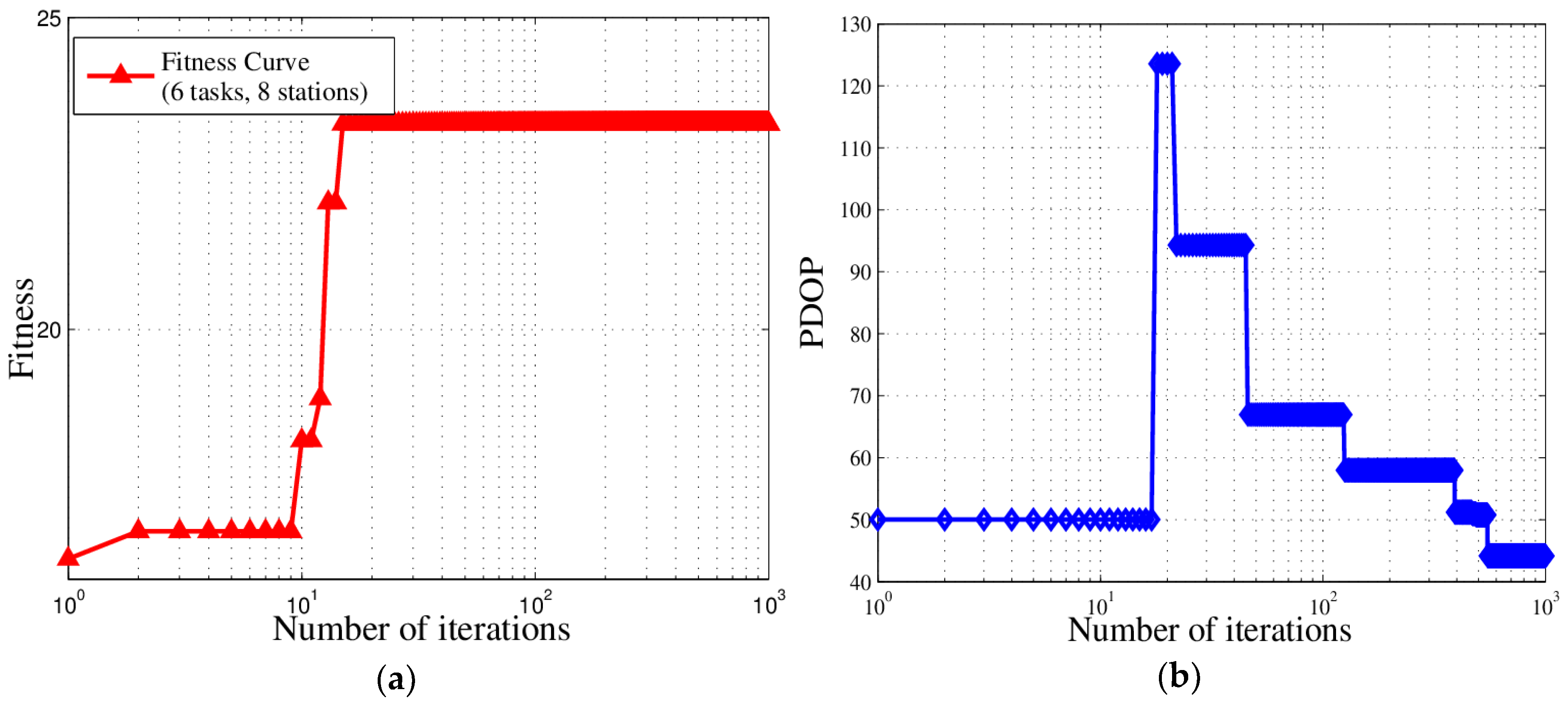
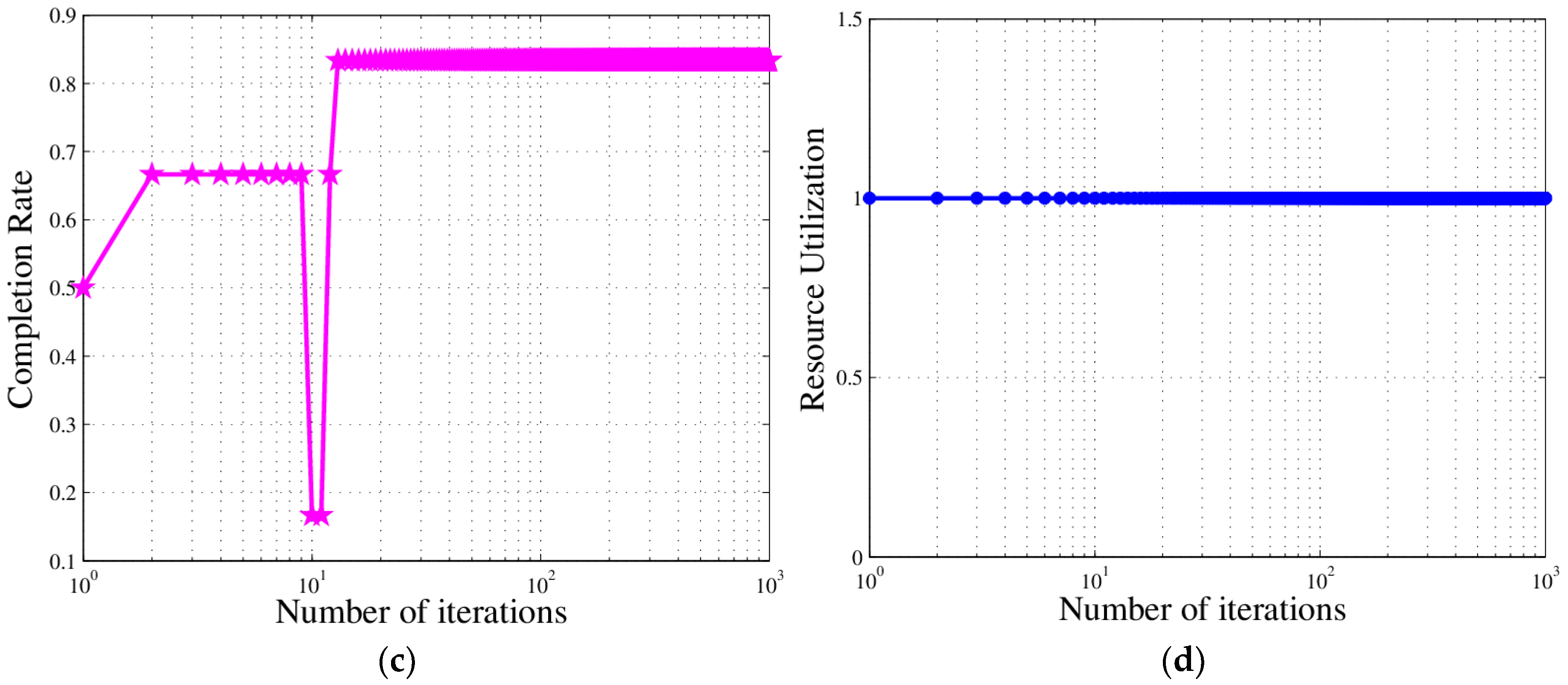
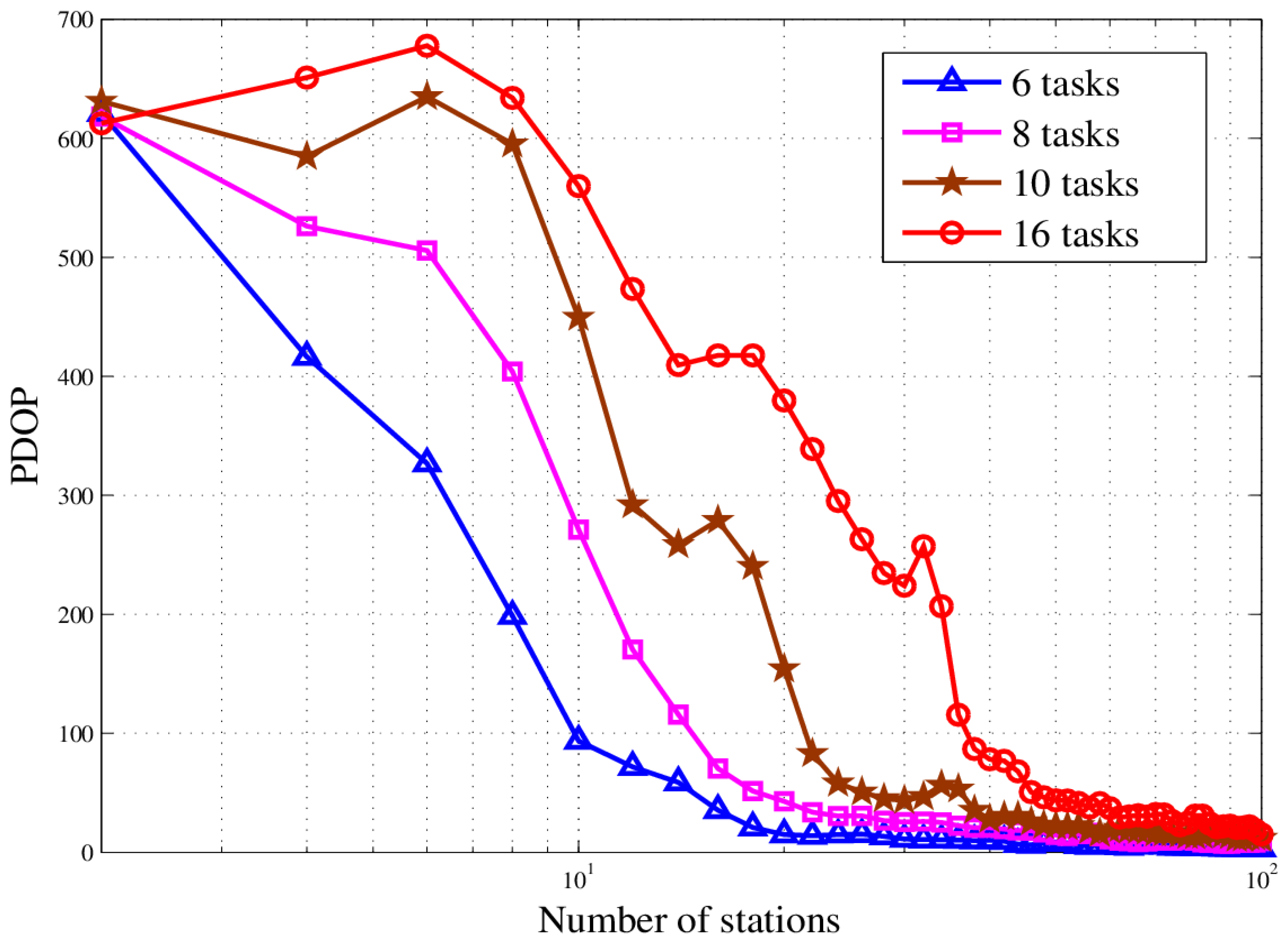
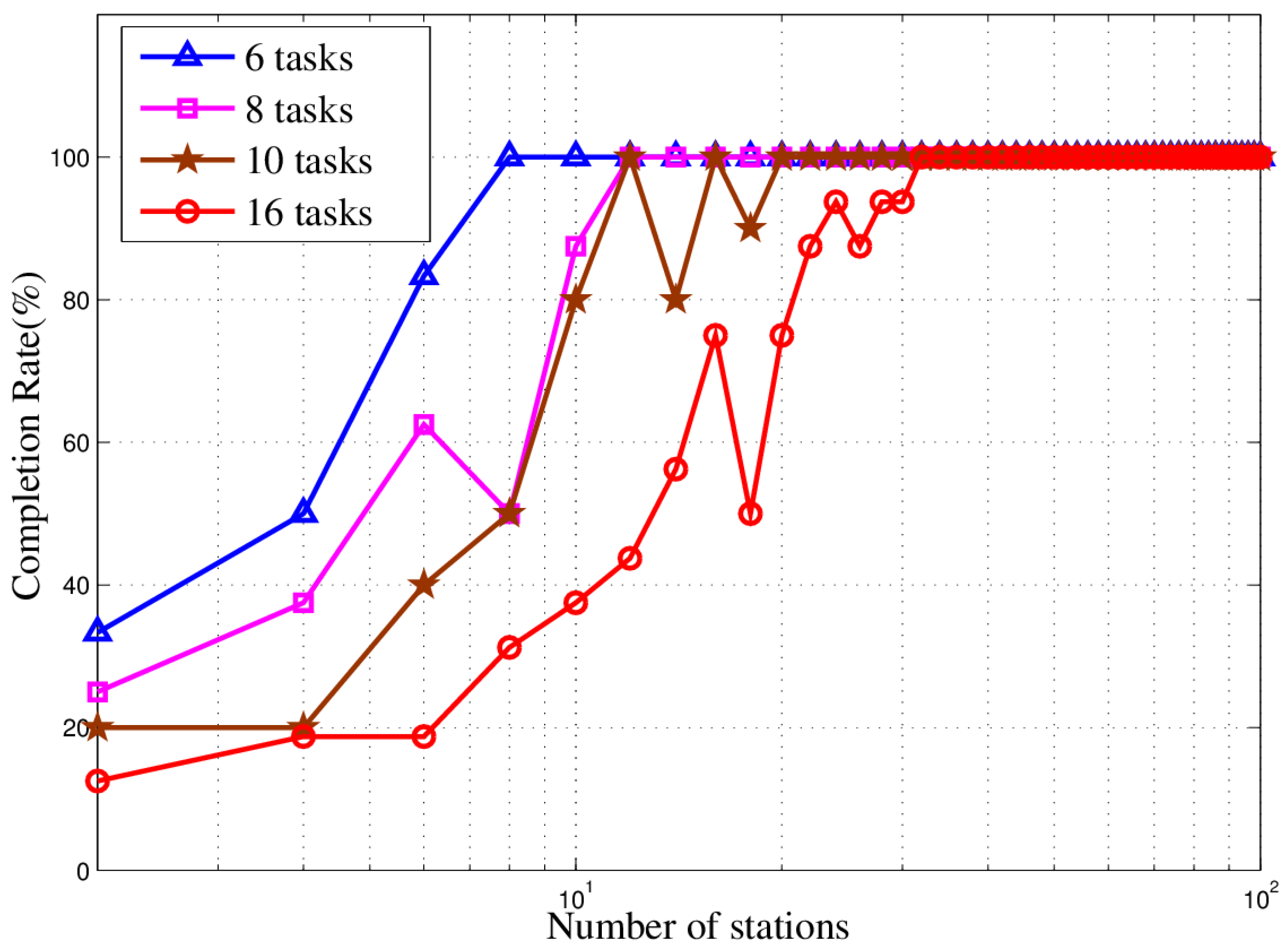
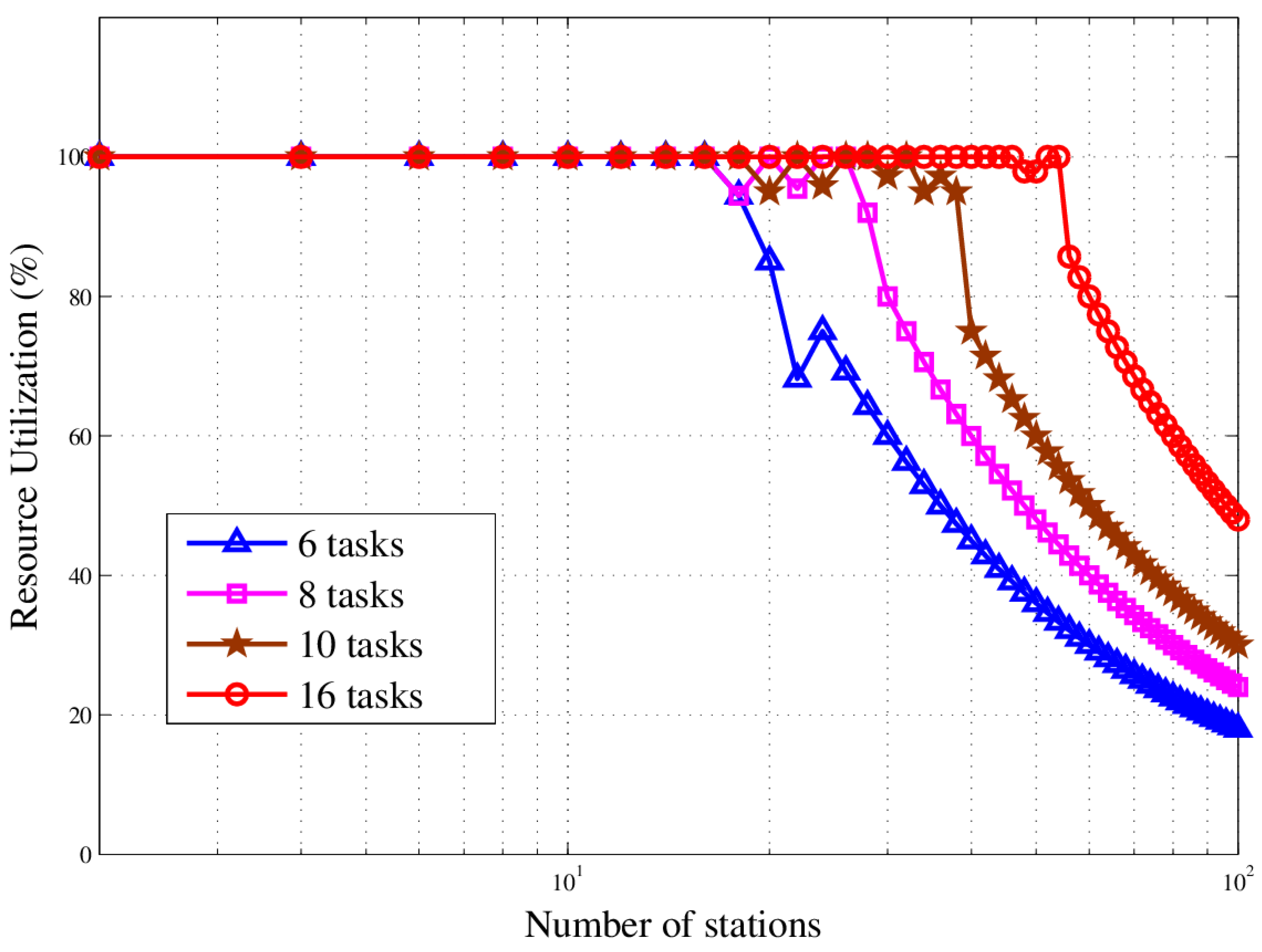
In this paper, we studied the scheduling problem for passive location resources and proposed a new solution method named MMIGAS. A multi-objective function was conceived to balance various aspects of the performance such as location accuracy, efficiency and resource utilization. And multi-constraint (i.e., frequency, cooperation requirement and capability) was formulated for the practicability of the approach. CI, PF and MGO were implemented to improve the GA, by enhancing the convergence rate and global optimal ability. We evaluated the performance of MMIGAS by computer simulations. In various scenarios, this method can reach its convergence bound within 100 iterations, showing a remarkable astringency. Moreover, its steady time complexity was illustrated because the calculation time was shown to have an approximately linear relationship with population and coding length. Furthermore, we compared traditional manual scheduling and MMIGAS. The results showed that the efficiency is clearly improved by MMIGAS and the location accuracy is still maintained at a high level in a scenario of more than 50 resources at the same time. At last, we also conducted a multi-objective parameter adjustment experiment to verify that the algorithm is suitable for different target requirements and reliable in different scenarios. In conclusion, the proposed algorithm can solve the problem of scheduling of station resources in passive location while maintaining high efficiency and stable location accuracy.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}