Comparison of Data Preprocessing Approaches for Applying Deep Learning to Human Activity Recognition in the Context of Industry 4.0




Abstract
:1. Introduction
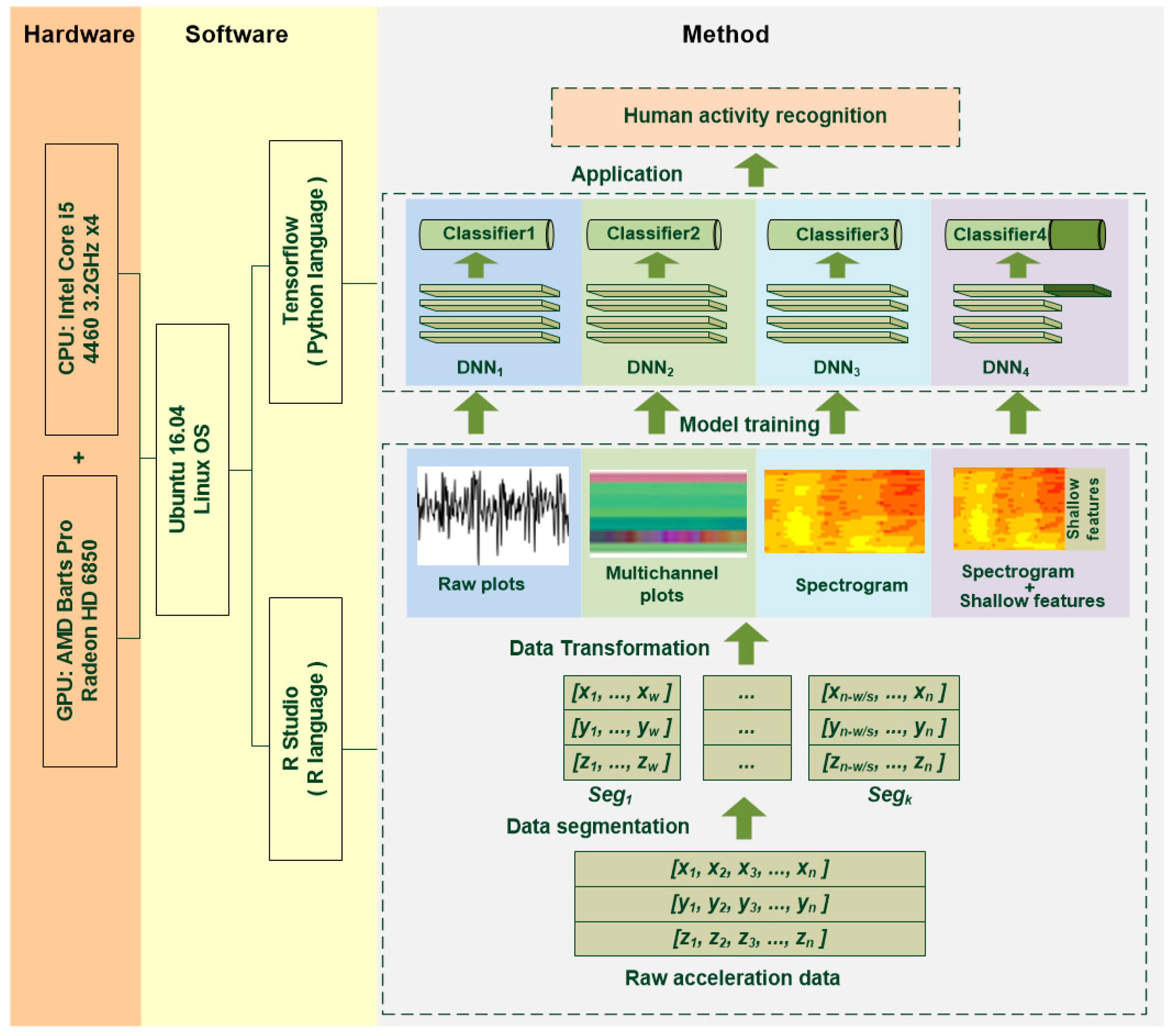
2. Materials and Methods
2.1. Data Segmentation
2.2. Data Transformation
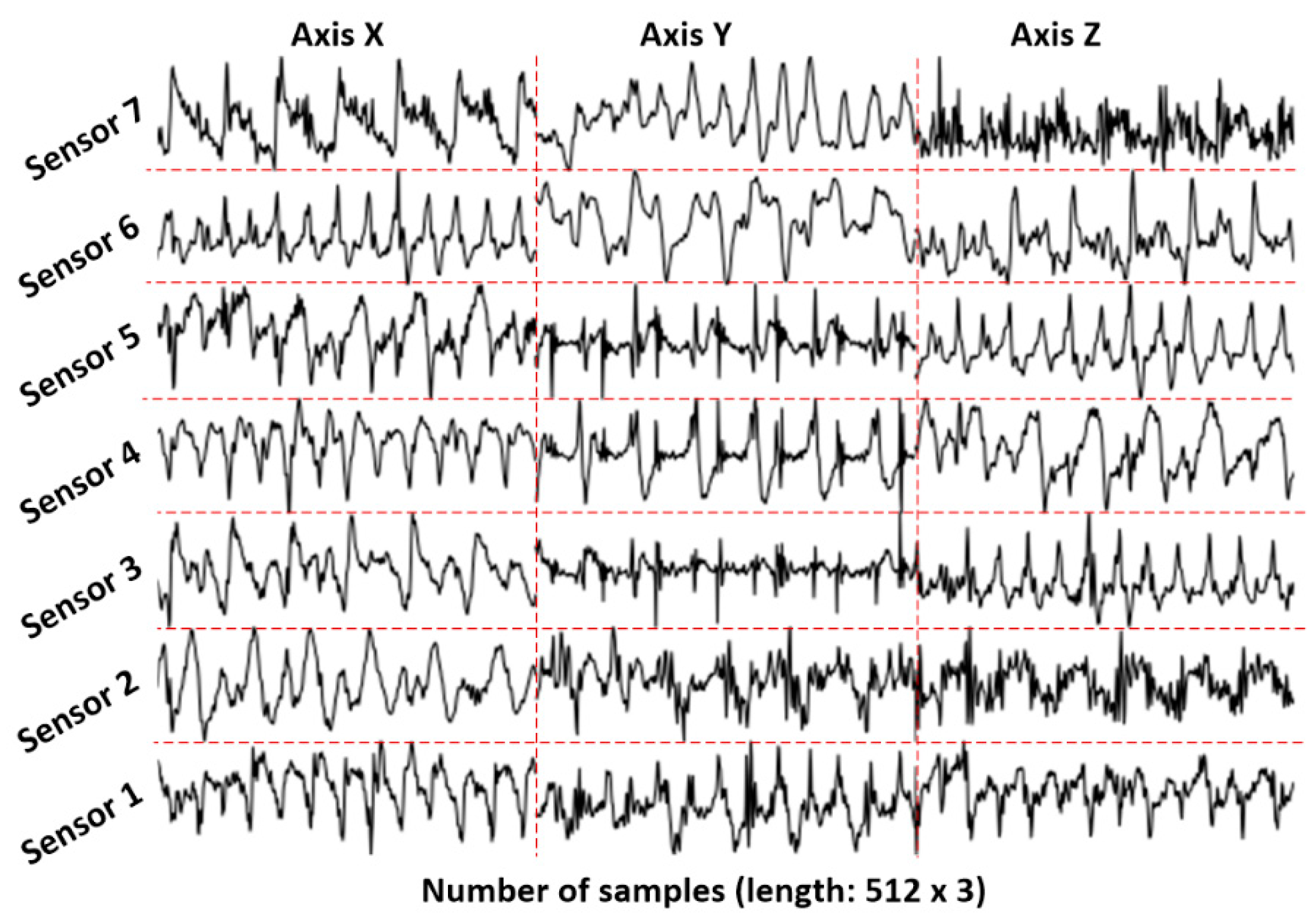
2.2.1. Raw Plot
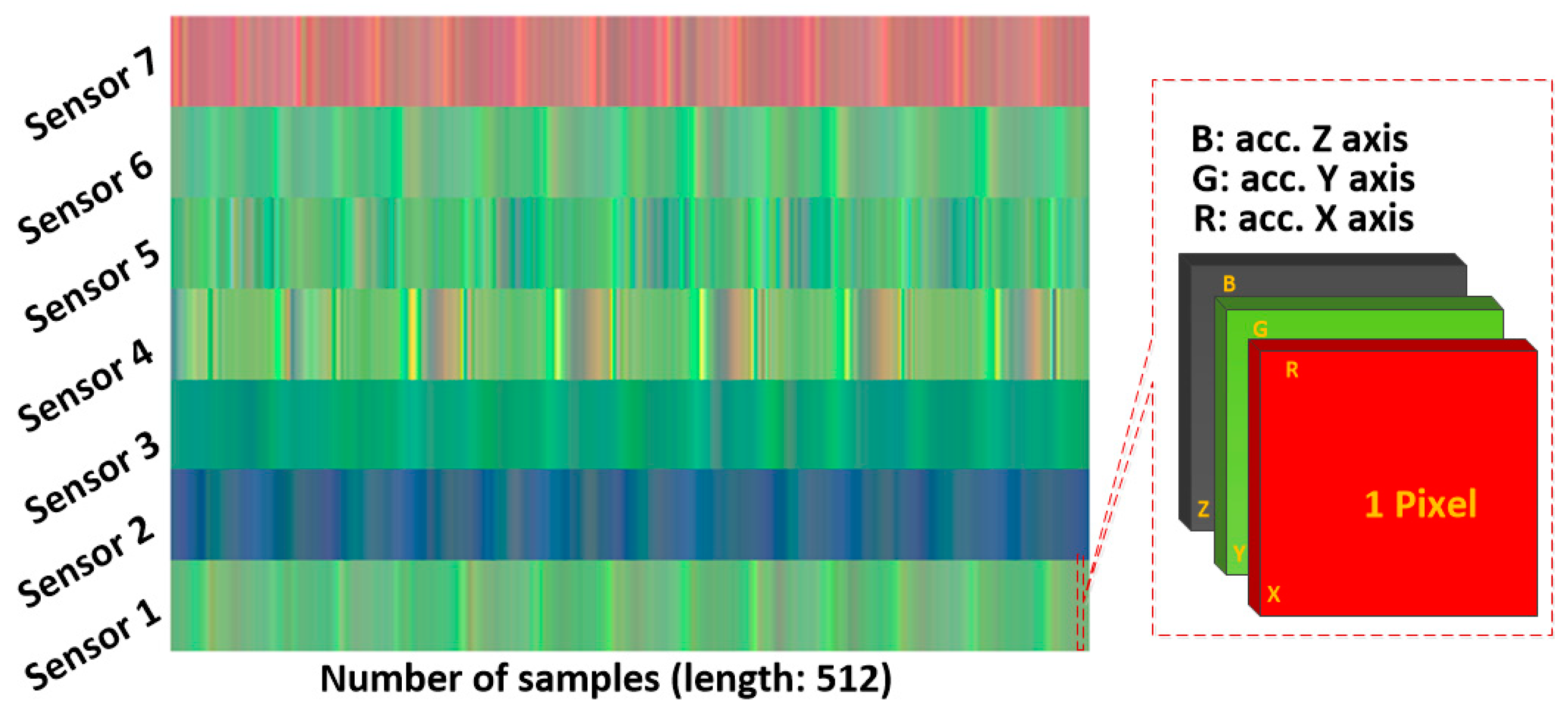
2.2.2. Multichannel Method
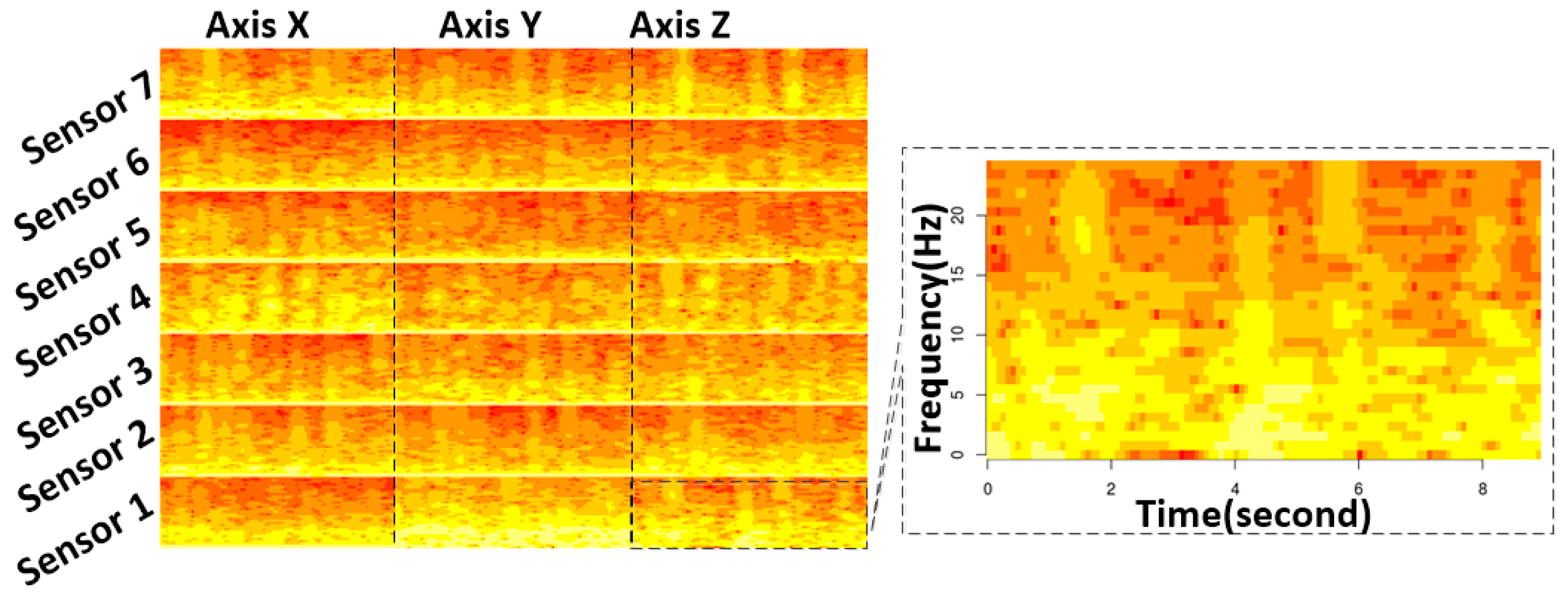
2.2.3. Spectrogram
2.2.4. Spectrogram Combined with Shallow Features
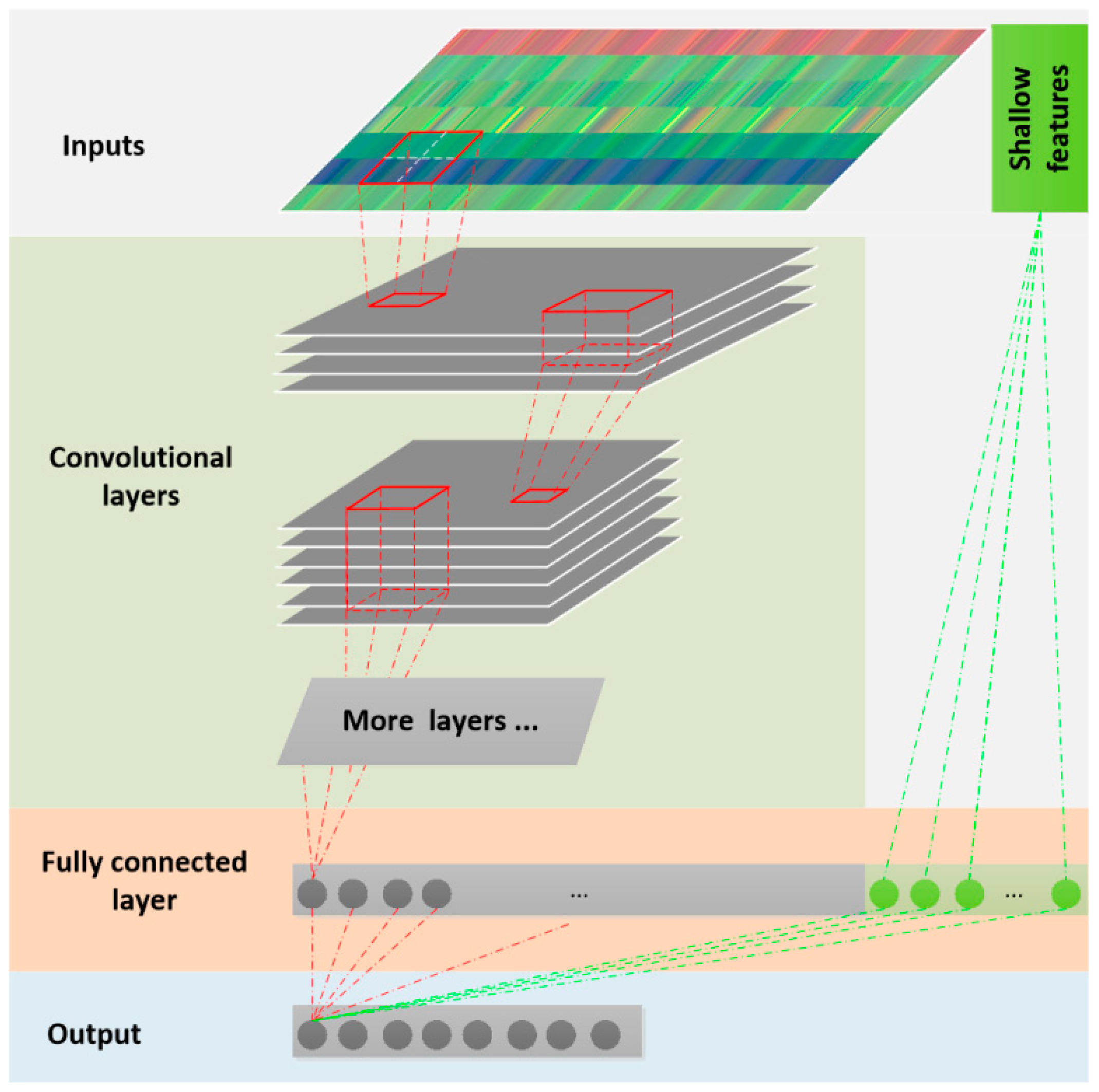
2.3. Deep Learning Method
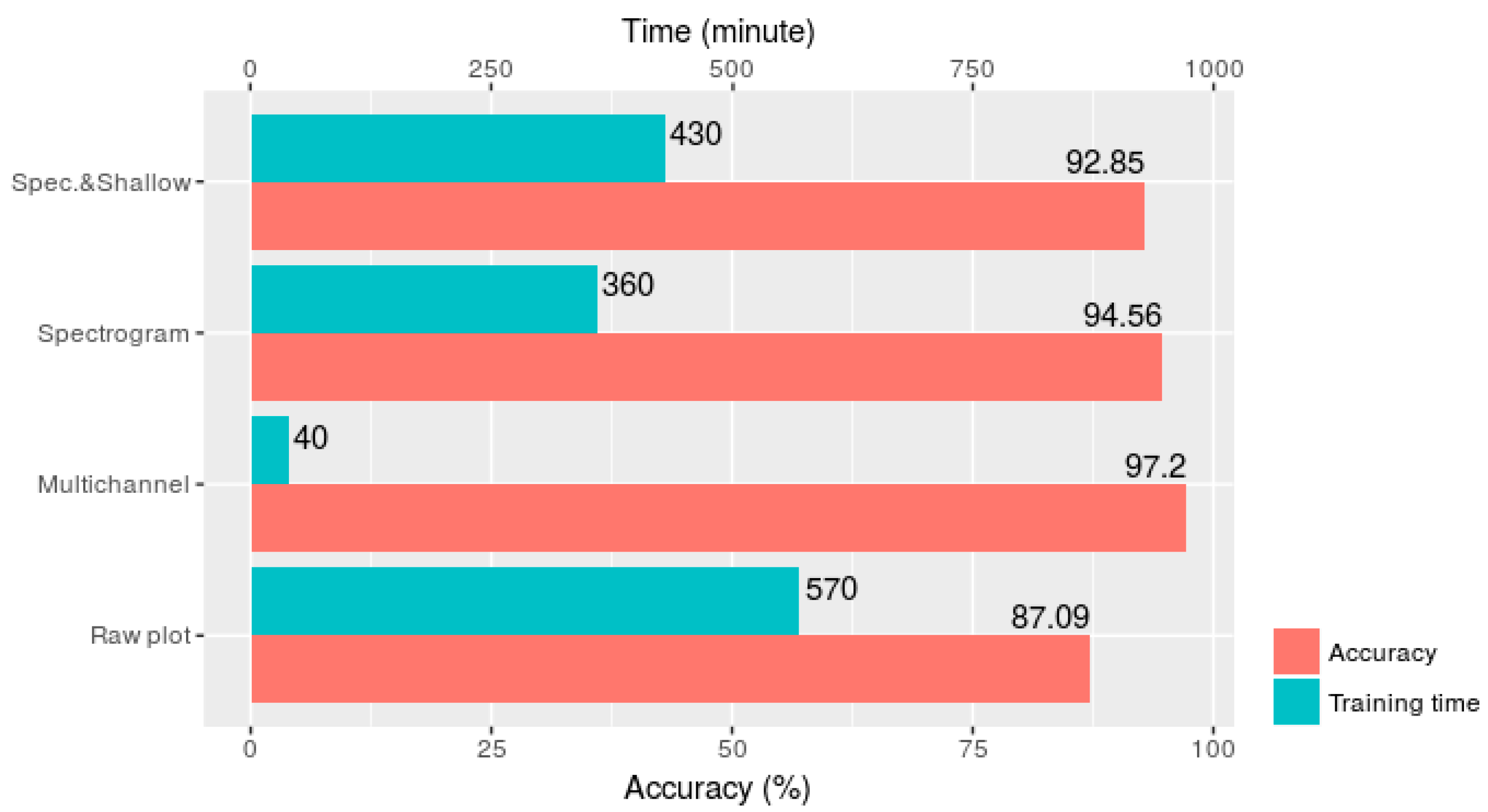
3. Results
3.1. Dataset and Experimental Setup
3.2. Results and Discussion
4. Discussions and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, S.; Chen, Y.; Hsu, C. A New approach to integrate internet-of-things and software-as-a-service model for logistic systems: A case study. Sensors 2014, 14, 6144–6164. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Bagheri, B.; Kao, H. A cyber-physical systems architecture for industry 4.0-based manufacturing systems. Manuf. Lett. 2015, 3, 18–23. [Google Scholar] [CrossRef]
- Xu, X. From cloud computing to cloud manufacturing. Robot. Comput. Integr. Manuf. 2012, 28, 75–86. [Google Scholar] [CrossRef]
- Ooi, K.; Lee, V.; Tan, G.W.; Hew, T.; Hew, J. Cloud computing in manufacturing: The next industrial revolution in malaysia? Expert Syst. Appl. 2018, 93, 376–394. [Google Scholar] [CrossRef]
- Hao, Y.; Helo, P. The role of wearable devices in meeting the needs of cloud manufacturing: A case study. Robot. Comput. Integr. Manuf. 2017, 45, 168–179. [Google Scholar] [CrossRef]
- Putnik, G. Advanced manufacturing systems and enterprises: Cloud and ubiquitous manufacturing and an architecture. J. Appl. Eng. Sci. 2012, 10, 127–134. [Google Scholar] [Green Version]
- Gorecky, D.; Schmitt, M.; Loskyll, M.; Zühlke, D. Human-machine-interaction in the industry 4.0 era. In Proceedings of the 12th IEEE International Conference on Industrial Informatics (INDIN), Porto Alegre, Brazil, 27–30 July 2014; pp. 289–294. [Google Scholar]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, Australia, 14–18 March 2016; pp. 1–9. [Google Scholar]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Ward, J.A.; Lukowicz, P.; Troster, G.; Starner, T.E. Activity recognition of assembly tasks using body-worn microphones and accelerometers. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1553–1567. [Google Scholar] [CrossRef] [PubMed]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Complex human activity recognition using smartphone and wrist-worn motion sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef] [PubMed]
- Attal, F.; Mohammed, S.; Dedabrishvili, M.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. Physical human activity recognition using wearable sensors. Sensors 2015, 15, 31314–31338. [Google Scholar] [CrossRef] [PubMed]
- Nakai, D.; Maekawa, T.; Namioka, Y. Towards unsupervised measurement of assembly work cycle time by using wearable sensor. In Proceedings of the IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), Sydney, Australia, 14–18 March 2016; pp. 1–4. [Google Scholar]
- Koskimaki, H.; Huikari, V.; Siirtola, P.; Laurinen, P.; Roning, J. Activity recognition using a wrist-worn inertial measurement unit: A case study for industrial assembly lines. In Proceedings of the 17th Mediterranean Conference on Control and Automation, Thessaloniki, Greece, 24–26 June 2009; pp. 401–405. [Google Scholar]
- Kim, E.; Helal, S.; Cook, D. Human activity recognition and pattern discovery. IEEE Pervasive Comput. 2010, 9, 48–53. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Cho, S. Activity recognition with android phone using mixture-of-experts co-trained with labeled and unlabeled data. Neurocomputing 2014, 126, 106–115. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A Tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 33. [Google Scholar] [CrossRef]
- Álvarez de la Concepción, M.A.; Soria Morillo, L.M.; Gonzalez-Abril, L.; Ortega Ramírez, J.A. Discrete techniques applied to low-energy mobile human activity recognition. A New approach. Expert Syst. Appl. 2014, 41, 6138–6146. [Google Scholar] [CrossRef]
- Clark, C.C.; Barnes, C.M.; Stratton, G.; McNarry, M.A.; Mackintosh, K.A.; Summers, H.D. A review of emerging analytical techniques for objective physical activity measurement in humans. Sports Med. 2016, 47, 439–447. [Google Scholar] [CrossRef] [PubMed]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A Robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Ravì, D.; Wong, C.; Lo, B.; Yang, G. A Deep learning approach to on-node sensor data analytics for mobile or wearable devices. IEEE J. Biomed. Health Inf. 2017, 21, 56–64. [Google Scholar] [CrossRef] [PubMed]
- Ronao, C.A.; Cho, S. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Hammerla, N.Y.; Halloran, S.; Ploetz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables. 2016. Available online: https://arxiv.org/abs/1604.08880 (accessed on 23 May 2018).
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A Survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Preece, S.J.; Goulermas, J.Y.; Kenney, L.P.; Howard, D. A comparison of feature extraction methods for the classification of dynamic activities from accelerometer data. IEEE Trans. Biomed. Eng. 2009, 56, 871–879. [Google Scholar] [CrossRef] [PubMed]
- Sejdić, E.; Djurović, I.; Jiang, J. Time–frequency feature representation using energy concentration: An overview of recent advances. Digit. Signal Process. 2009, 19, 153–183. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1998; pp. 255–258. [Google Scholar]
- Zheng, X.; Ordieres, J. Step-by-Step Introduction to Acceleration Data Classification Using Deep Learning Methods. 2017. Available online: https://www.researchgate.net/publication/317180890 (accessed on 23 May 2018).
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SigKDD Explor. Newslett. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Lockhart, J.W.; Weiss, G.M.; Xue, J.C.; Gallagher, S.T.; Grosner, A.B.; Pulickal, T.T. Design considerations for the WISDM smart phone-based sensor mining architecture. In Proceedings of the Fifth International Workshop on Knowledge Discovery from Sensor Data, San Diego, CA, USA, 21–24 August 2011; pp. 25–33. [Google Scholar]
- Weiss, G.M.; Lockhart, J.W. The Impact of Personalization on Smartphone-Based Activity Recognition; AAAI Technical Report WS-12-05; Fordham University: New York, NY, USA, 2012; pp. 98–104. [Google Scholar]
- Zappi, P.; Lombriser, C.; Stiefmeier, T.; Farella, E.; Roggen, D.; Benini, L.; Troster, G. Activity recognition from on-body sensors: Accuracy-power trade-off by dynamic sensor selection. Lect. Notes Comput. Sci. 2008, 4913, 17–33. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Features |
|---|---|
| Raw signal | max, min, mean, median, variance, kurtosis, skewness, zero-cross, root mean square, standard deviation, interquartile range |
| First derivative | mean, variance, root mean square, standard deviation |
| Segment Length | Raw Plot | Multichannel | Spectrogram | Spectrogram and Shallow Features |
|---|---|---|---|---|
| 64 | 92.44 | 94.60 | 92.86 | 90.39 |
| 128 | 93.05 | 96.14 | 93.37 | 90.42 |
| 256 | 93.45 | 96.58 | 93.94 | 92.02 |
| 512 | 94.97 | 97.19 | 95.56 | 93.58 |
| 1024 | 82.13 | 92.81 | 91.54 | 85.55 |
| Subject | Raw Plot | Multichannel | Spectrogram | Spectrogram & Shallow Features |
|---|---|---|---|---|
| Mean | 95.25 | 97.58 | 95.81 | 93.92 |
| Min. | 92.42 | 93.91 | 91.61 | 88.46 |
| Max. | 97.22 | 99.56 | 98.57 | 97.18 |
| Sd. | 1.72 | 2.11 | 2.35 | 2.74 |
| A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | ||
|---|---|---|---|---|---|---|---|---|---|
| Raw plot | Precision (%) | 97.16 | 97.99 | 99.61 | 99.59 | 95.18 | 99.15 | 92.06 | 99.49 |
| Recall (%) | 95.41 | 96.89 | 98.78 | 99.18 | 91.40 | 98.53 | 85.24 | 99.08 | |
| Overall Acc. (%) | 94.97 | 95% CI: (0.9434, 0.9556) | |||||||
| Multichannel | Precision (%) | 97.65 | 97.96 | 99.74 | 99.89 | 96.29 | 99.63 | 96.99 | 99.72 |
| Recall (%) | 95.56 | 96.53 | 99.49 | 100.00 | 93.33 | 99.34 | 95.04 | 99.53 | |
| Overall Acc. (%) | 97.19 | 95% CI: (0.9670, 0.9763) | |||||||
| Spectrogram | Precision (%) | 97.65 | 97.23 | 99.92 | 98.60 | 98.84 | 97.47 | 91.18 | 97.76 |
| Recall (%) | 95.65 | 96.05 | 100.00 | 97.56 | 98.96 | 96.55 | 82.73 | 96.08 | |
| Overall Acc. (%) | 94.56 | 95% CI: (0.9251, 0.9618) | |||||||
| Spectrogram & Shallow features | Precision (%) | 94.92 | 98.25 | 91.51 | 98.60 | 95.92 | 96.60 | 93.39 | 95.38 |
| Recall (%) | 91.05 | 98.59 | 83.33 | 97.56 | 93.14 | 93.75 | 88.42 | 91.51 | |
| Overall Acc. (%) | 93.58 | 95% CI: (0.9157, 0.9512) | |||||||
| Original | Prediction | |||||||
|---|---|---|---|---|---|---|---|---|
| A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | |
| A1 | 68 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| A2 | 0 | 78 | 2 | 0 | 1 | 0 | 0 | 1 |
| A3 | 0 | 3 | 22 | 0 | 0 | 0 | 0 | 0 |
| A4 | 0 | 0 | 0 | 81 | 1 | 0 | 0 | 0 |
| A5 | 0 | 6 | 0 | 0 | 98 | 1 | 3 | 0 |
| A6 | 0 | 0 | 0 | 0 | 0 | 92 | 1 | 0 |
| A7 | 0 | 0 | 0 | 1 | 5 | 1 | 86 | 0 |
| A8 | 0 | 1 | 0 | 0 | 0 | 0 | 2 | 100 |
| Dataset 1: WISDM v1.1 | |||||||
| Walking | Jogging | Sitting | Standing | Upstairs | Downstairs | ||
| Ravì et al. [23] | Prec. | 99.37 | 99.64 | 97.85 | 98.15 | 95.52 | 94.44 |
| Rec. | 99.37 | 99.40 | 98.56 | 97.25 | 95.13 | 95.90 | |
| MCT | Prec. | 98.34 | 98.11 | 100.00 | 100.00 | 96.14 | 98.44 |
| Rec. | 97.31 | 97.53 | 100.00 | 100.00 | 93.10 | 97.67 | |
| Dataset 2: WISDM v2.0 | |||||||
| Jogging | Lying Down | Sitting | Stairs | Standing | Walking | ||
| Ravì et al. [23] | Prec. | 98.01 | 88.65 | 87.32 | 85.00 | 82.05 | 97.17 |
| Rec. | 97.73 | 85.85 | 89.28 | 76.98 | 82.11 | 97.19 | |
| MCT | Prec. | 98.76 | 96.85 | 90.25 | 87.03 | 91.02 | 95.85 |
| Rec. | 97.95 | 94.96 | 82.05 | 75.00 | 85.94 | 94.81 | |
| Dataset 3: Skoda | |||||||
| Write on Notepad | Open Hood | Close Hood | Check Gaps Front | Open Left Front Door | |||
| Ravì et al. [23] | Prec. | 96.67 | 97.78 | 89.47 | 91.15 | 100.00 | |
| Rec. | 91.34 | 97.78 | 94.44 | 92.79 | 100.00 | ||
| MCT | Prec. | 100.00 | 99.54 | 100.00 | 100.00 | 80.00 | |
| Rec. | 100.00 | 100.00 | 100.00 | 100.00 | 60.00 | ||
| Close Left Front Door | Close Both Left Door | Check Trunk Gaps | Open and Close Trunk | Check Steer Wheel | |||
| Ravì et al. [23] | Prec. | 88.89 | 92.86 | 98.78 | 100.00 | 93.55 | |
| Rec. | 80.00 | 94.20 | 97.59 | 98.04 | 100.00 | ||
| MCT | Prec. | 99.18 | 100.00 | 100.00 | 100.00 | 94.44 | |
| Rec. | 100.00 | 100.00 | 100.00 | 100.00 | 88.89 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Wang, M.; Ordieres-Meré, J. Comparison of Data Preprocessing Approaches for Applying Deep Learning to Human Activity Recognition in the Context of Industry 4.0. Sensors 2018, 18, 2146. https://doi.org/10.3390/s18072146
Zheng X, Wang M, Ordieres-Meré J. Comparison of Data Preprocessing Approaches for Applying Deep Learning to Human Activity Recognition in the Context of Industry 4.0. Sensors. 2018; 18(7):2146. https://doi.org/10.3390/s18072146
Chicago/Turabian StyleZheng, Xiaochen, Meiqing Wang, and Joaquín Ordieres-Meré. 2018. "Comparison of Data Preprocessing Approaches for Applying Deep Learning to Human Activity Recognition in the Context of Industry 4.0" Sensors 18, no. 7: 2146. https://doi.org/10.3390/s18072146
APA StyleZheng, X., Wang, M., & Ordieres-Meré, J. (2018). Comparison of Data Preprocessing Approaches for Applying Deep Learning to Human Activity Recognition in the Context of Industry 4.0. Sensors, 18(7), 2146. https://doi.org/10.3390/s18072146