1. Introduction
Localization of a device in an unknown environment is critical in many fields. The Global Navigation Satellite System (GNSS) receivers and visual simultaneous localization and mapping (visual-SLAM) systems are popular navigation solutions.
In the simplest SLAM systems, a monocular camera is used to determine the ego-motion and build a map. This system does not rely on any external equipment and can work effectively in GNSS-denied environments. With recent SLAM approaches [
1,
2,
3], very high localization and mapping accuracy can be obtained for a medium-length trajectory. Therefore, SLAM systems are often used in autonomous navigation [
4], path planning [
5], environment reconstruction [
6], scene understanding [
7], and so on. However, SLAM systems accumulate error while running, which grows almost linearly with running distance or time [
8]. Another drawback of SLAM is that the absolute pose of the device cannot be observed. It only measures the relative pose with repect to the first frame. Moreover, if a monocular camera is used, the absolute scale of the system is ambiguous [
9].
In the case of outdoor navigation, a GNSS receiver is currently the most commonly used system. These provide localization measurements with an accuracy of <5 m in open-sky areas. However, in applications such as autonomous driving and unmanned aerial vehicle control, such positioning accuracy does not meet practical requirements [
10]. Although RTK(Real-time kinematic)-GNSS can achieve a positioning accuracy of centimeters or even millimeters, it requires cooperative ground station assistance and is very expensive. Therefore, RTK-GNSS is not commonly used. Moreover, GNSS receivers can only measure the position of the device; obtaining the attitude is not easy. To determine the attitude, an inertial measurement unit (IMU) is often used. However, Agrawal, et al. [
11] points out that the estimation error of low-cost GNSS and IMU integrated systems is still high. Navigation systems based on GNSS or GNSS–IMU require a tradeoff between price and accuracy. In addition, GNSS receivers will always be affected by environmental factors. For example, in tunnels or underground, the system cannot receive navigation signals, and in buildings or valleys, signals are shadowed or suffer from multipath effects. Even in GNSS–IMU coupled systems, the IMU prediction error grows quadratically when GNSS data become invalid, which means that the coupled system cannot run for a long time after losing the GNSS signal.
The complementary nature of visual-SLAM and GNSS results in numerous benefits. The integration of the two systems greatly improves performance. Dusha et al. [
12] proved that visual-GNSS integrated navigation systems can observe absolute pose. GNSS receiver observations can be used to provide the absolute pose and scale for SLAM systems and limit drift. Additionally, with visual measurements, a GNSS receiver is capable of attitude estimation, and the localization error is smoothed. Moreover, the camera and the GNSS receiver can be very cheap and portable. Therefore, the integration of GNSS and SLAM systems has received extensive attention from researchers [
13,
14,
15].
In this study, we chose ORB-SLAM [
1] as the visual module and propose a data fusion scheme to integrate the visual and GNSS information. ORB-SLAM [
1] is a state-of-the-art SLAM system that uses ORB [
16] features for tracking, mapping, loop closure, and relocalization. The system utilizes monocular, stereo, or RGB-D cameras, runs in real-time, and provides high localization accuracy. Regarding data fusion, at present, most visual-GNSS integrated navigation systems fuse data by filtering-based methods. However, in modern SLAM systems, we found that an optimization-based method has been proven to have higher accuracy and computational efficiency. When using a low-cost GNSS, the measurements are noisy. Hence, we introduce an optimization-based data fusion method to improve the navigating performance. We first studied the data alignment method of the two devices. After that, the information fusion framework was designed. Compared with the original ORB-SLAM system, we propose big bundle adjustment (big BA) and global BA threads to utilize GNSS information and maintain global consistency in localization and mapping. We name this system GVORB (GNSS-Visual-ORB-SLAM).
The paper is organized as follows: We review related work on SLAM and visual-GNSS coupled navigation in
Section 2. Then, the proposed system is introduced in
Section 3 and
Section 4. In
Section 5, we evaluate the performance of our algorithm through experiments on the KITTI [
17] dataset. In
Section 6, the application and extensibility of the system are discussed. Finally, we provide a summary in
Section 7.
2. Related Work
2.1. Visual SLAM
The concept of SLAM was firstly proposed in 1986 [
18]. Initially, the filtering-based backend was used to process visual measurements. For example, Montemerlo et al. [
19] proposed FastSLAM, in which a Rao–Blackwellized particle filter was used to estimate the pose of the camera. In 2003, Davison et al. proposed MonoSLAM [
20], in which an extended Kalman filter (EKF) was used to filter the camera pose and position of map points (MPs). MonoSLAM was the first real-time and open-source SLAM system and greatly promoted the development of SLAM research. After that, Klein et al. presented PTAM [
21]. It uses an optimization- and keyframe-based approach with two parallel processing threads. The optimization algorithm in PTAM is called BA, which was first used in structure from motion (SfM). BA optimizes camera poses and MP positions jointly to minimize the MP reprojection error. Benefitting from the sparsity of the SLAM problem, BA can provide results efficiently, and the estimation accuracy of BA is higher than that of a filtering-based estimator [
22]. Additionally, keyframes in PTAM are used to efficiently estimate camera poses and reduce redundancy of information. These characteristics led to the development of modern SLAM. Nowadays, mainstream SLAM methods, such as ORB-SLAM [
1], DSO [
2], and LSD [
23], are based on keyframe- and optimization-based algorithms.
The visual information processing in SLAM can be divided into direct and indirect methods. DSO [
2] is based on the direct method, which uses the pixel’s grayscale variation directly to determine the pose, with which more visual information can be obtained and runtime can be very fast. However, because of the large amount of uncertainty in data alignment, the method is more likely to fall into local extrema. Indirect methods, such as ORB-SLAM [
1], first extract features from the input images and match them with features in the map. By minimizing the reprojection error, the pose can be determined. The advantage of the indirect method is that it is more robust during strong motion. Moreover, it is easier to deal with relocalization and loop closure. Therefore, we selected the indirect method to extract visual information in our system.
2.2. GNSS-Visual Navigation
In 2005, Roberts et al. [
24] introduced visual-GNSS navigation and mapping on an aircraft. In their system, the position and velocity of the device are directly measured by the GNSS receiver, while the attitude is calculated by the GNSS and optical flow of the images. Finally, the velocity and optical flow are used to build a depth map of the environment. In [
25], the observability of GNSS-aided SfM was studied. The observability of monocular or depth camera-based visual-GNSS navigation systems was analyzed in [
12,
26]. These studies showed that as long as the system has acceleration that is not parallel to the direction of movement, the scale and the pose of the system are observable. At this point, the theory and practice of visual-GNSS integrated navigation proved to be feasible.
There are different ways to implement visual-GNSS navigation systems. For example, in autonomous driving, pre-built maps for visual localization are often used [
10,
27,
28,
29,
30,
31]. However, such a scheme requires the use of additional maps and can hardly be used in arbitrary scenarios. Additionally, some studies were based on 3 degrees of freedom (DoF) (two-dimensional (2D) position and one-dimensional (1D) direction) localization [
10,
32,
33], whereas in most applications, 6-DoF (three-dimensional (3D) position and attitude) pose estimation is necessary. For universality, our work studied 6-DoF localization without any pre-built maps.
In a tightly coupled visual-GNSS navigation system, the carrier phase or pseudo-range is measured directly and is fused with visual information. In the tightly coupled system, even if only one satellite is tracked, the system can still make use of the GNSS information [
34,
35]. In a loosely coupled system, the position calculated by the GNSS receiver is fused with visual measurements. At least four satellites must be observed in this scheme. However, in many applications, the user can only achieve the positioning information of the GNSS module, as a loosely coupled system has a wider range of applications. Therefore, we studied loosely coupled visual-GNSS SLAM systems in this paper.
With respect to data fusion, most of the above studies were based on filtering methods. Currently, to the best of our knowledge, only [
36] attempted to fuse visual and GNSS data using an iterative optimization-based method with good results. In the field of SLAM, optimization-based algorithms are proven to be more accurate and efficient than filtering-based algorithms. Therefore, our SLAM system is based on optimization.
3. System Overview
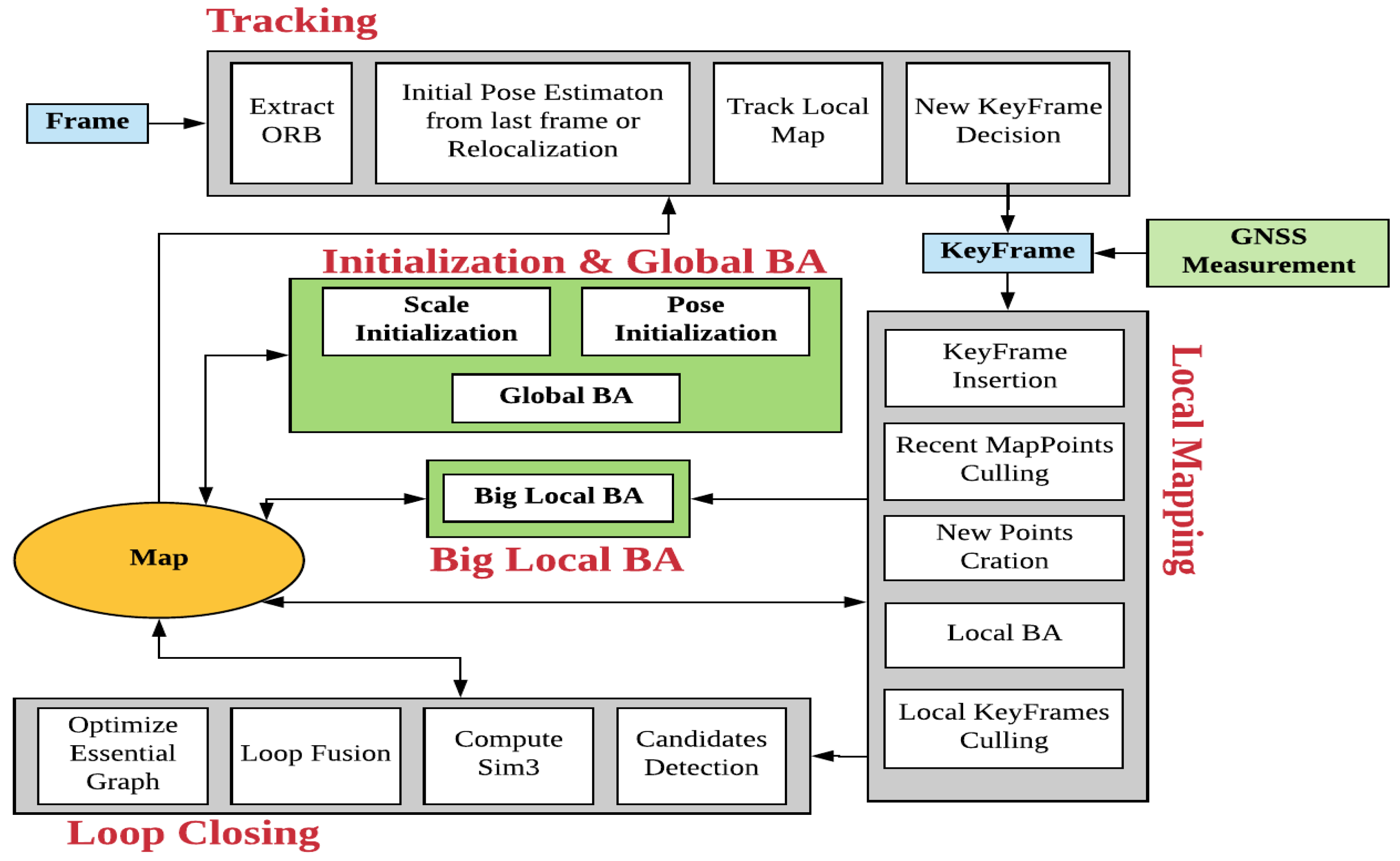
In GVORB, we need to integrate data from the GNSS receiver and a camera. The system can be divided into two parts: visual-SLAM and data fusion.
The visual part of GVORB is based on ORB-SLAM2 [
37] (
https://github.com/raulmur/ORB_SLAM2), an open-source visual-SLAM system. The original ORB-SLAM has three threads: tracking, local mapping, and loop closing (see
Figure 1, gray modules). The tracking thread tracks every input frame by matching feature points between the frame and the map and creates keyframes. Then, the local mapping thread builds and refines the local map. Local BA (LBA) is used here to optimize the keyframes and MPs. Finally, the keyframes are sent to the loop closing thread to correct the drift.
For the GNSS and visual information fusion, to improve the performance of a system running on low-cost devices, we present an optimization-based scheme. Two additional threads are added to the system: big LBA (BLBA) and global BA (GBA). The initialization module for aligning GNSS and visual measurements is implemented in the GBA thread (see
Figure 1, green modules). The initialization module is divided into two parts. First, if the displacement of the camera is far enough, scale initialization is performed. Then, if the distance moved by the camera is great enough in two orthogonal directions, pose initialization is performed. Afterward, the world and visual coordinates are merged.
After the initialization, BLBA and GBA run separately. GBA optimizes all keyframes poses and MPs with all GNSS and visual observations. The result of GBA is nearly optimal, although it takes a long time. If there are a total of N keyframes in the map, the computational complexity is . BLBA is used to integrate GNSS measurements quickly. It only optimizes keyframes and MPs in a local window. However, the local window in BLBA is much bigger than the LBA window in the local mapping thread. This is because in LBA, the local window is too small, and the visual constraints are too strict. GNSS measurements almost do not affect optimization. We did not replace LBA by BLBA because LBA runs faster, which is important for local map updates in fast-motion scenarios. BLBA can be seen as a balance between GBA and LBA. It runs faster than GBA while optimizing more states than LBA.
In GVORB, although the integration of GNSS can avoid SLAM drift, we still run the loop closing thread. This is because loop closure can further improve the system’s consistency. In addition, by finding loop closures, the system understands the real topology of the environment [
38]. Further, when a loop is detected, tracking is based on the previously built map, and the map size will not increase when we revisit the same place.
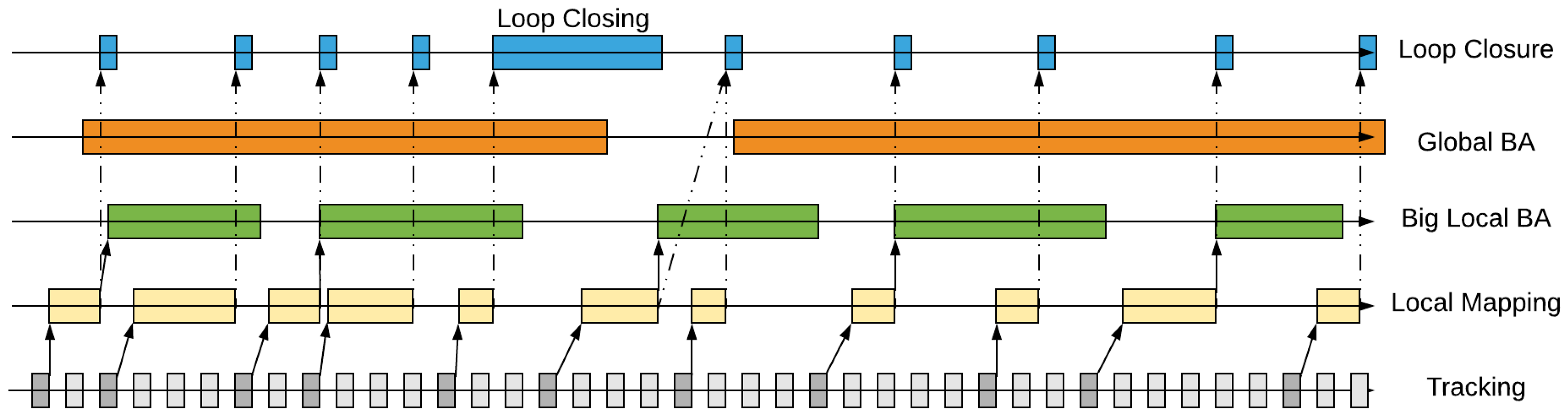
The relationship between GVORB threads and their timing diagram is shown in
Figure 2:
- (1)
In the tracking thread, every input frame is tracked. If the frame is selected as a keyframe, it will be sent to the local mapping thread.
- (2)
The local mapping thread receives the keyframes and then builds and refines the local map. After that, the keyframes are sent to the loop closing thread. At the same time, the BLBA thread is triggered if it is idle.
- (3)
The BLBA thread optimizes the keyframe poses and MPs in the big local window and then updates the map.
- (4)
GBA may run at any time but sleeps for a period of time between runs. It optimizes the whole map and updates it.
- (5)
The loop closing thread runs when it receives the keyframes from the local mapping thread. It detects loops and corrects them. However, in GVORB, this thread does not correct loops, but waits for the GBA thread to do so.
4. Modules of GVORB
In the GVORB implementation, we propose GNSS data records, initialization, and the GBA and BLBA modules. We introduce these in this section.
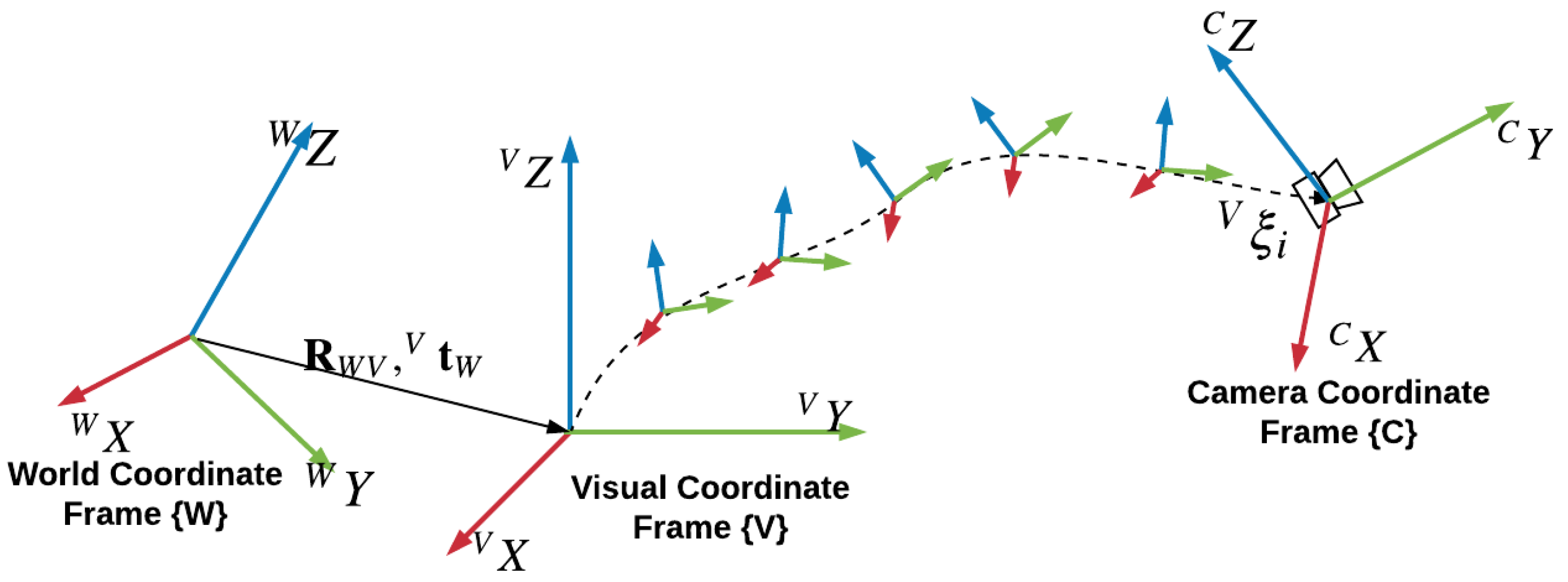
Three coordinate frames are used in GVORB (see
Figure 3). We use the local tangent plane (LTP) as the world coordinate frame, denoted as {W}. GNSS measurements are transformed into the LTP. In visual-SLAM, we place the origin of the visual coordinate frame {V} at the camera’s initial pose. Another frame is the camera coordinate frame, denoted as {C}, which is fixed with the camera. The GNSS receiver is located at
. If the low-cost GNSS receiver is used where the positioning accuracy is not high, we may assume that the GNSS receiver is located at the origin of {C}, that is,
.
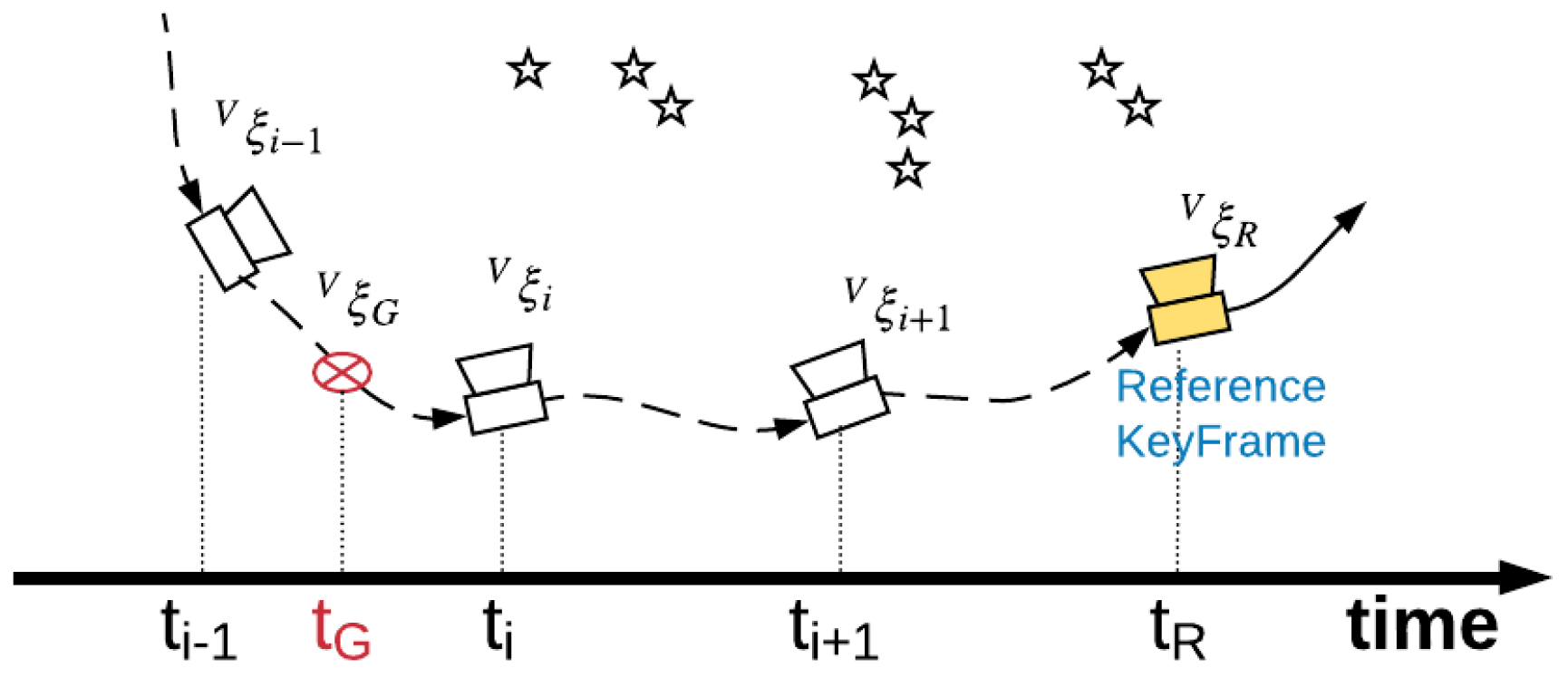
4.1. GNSS Data Record
Usually, data from two devices is not recorded synchronously. We assume that the timestamp of GNSS data is
, which is between the timestamps of frames
and
i:
and
. We try to create a keyframe on the basis of the
ith frame (if the local mapping thread is running, we create the keyframe until it is idle). The new created keyframe works as the reference keyframe, and it is set as non-deletable (to prevent the loop mapping thread from deleting it). The GNSS information is bound to this reference keyframe, as shown in
Figure 4.
Because
is between
and
, the position of the device at
is between
and
(where
represents the pose vector of the camera at
in {V}). Through first-order interpolation, the device’s pose at
in {V} can be obtained by:
where ∘ represents the multiplication of two pose vectors:
. Then, we convert the pose at
to the reference keyframe’s coordinate frame {R},
. In {R}, the position of the GNSS receiver at
is
. Afterward, the estimated position of the GNSS receiver in {V} is recorded in the reference keyframe as
.
4.2. Scale Initialization
The scale of the visual-SLAM system can be initialized when the camera has moved a certain distance and sufficient GNSS measurements have been received. We suppose that in {V}, the estimated position of the GNSS receiver is
and that the camera trajectory in {W} measured directly by the GNSS receiver is
, where the standard deviation (STD) of GNSS measurement errors is
. Then, the scale factor
between {W} and {V} can be estimated by
where
and
are the mean of the measured and estimated values of the GNSS receivers’ positions, respectively.
After the scale initialization, the entire map is updated with , where the positions of keyframes and MPs are adjusted by . Moreover, the GNSS receivers’ positions in the reference keyframes are also updated.
4.3. Pose Initialization
After scale initialization, the pose between {W} and {V} is aligned. According to [
39], the rotation matrix
between {W} and {V} can be solved by singular-value decomposition. First, we build a matrix:
We then perform singular-value decomposition on : . The diagonal elements of are sorted in descending order: . If is larger than a certain threshold, we start pose initialization. This is because a higher leads to higher rotation estimation accuracy. Further, if is small, the determinant of or may equal (mirror ambiguous). In this case, the last column of or should be reversed.
After that, the rotation between the two coordinates can be estimated by . The relative translation then becomes .
After pose initialization, keyframes and MPs in the entire map are transformed by and . Thus, {W} and {V} become coincident. We use {W} to represent them. GBA runs immediately after this to further adjust the visual and GNSS localization results.
4.4. Global Bundle Adjustment
In the GBA thread, we use all visual and GNSS measurements to constrain the pose of the entire map. The graph model of GBA is shown in
Figure 5 (GBA window).
The cost function of
Figure 5 can be written as
where
is the state vector to be optimized:
;
is the
ith keyframe’s pose;
is the
kth MP’s position; and
is the weight of the GNSS measurements. Because the number of visual measurements is much higher than the number of GNSS measurements, the GNSS measurements need a greater weight to affect the optimization. (Moreover, the GNSS measurement model can be introduced to Equation (
4) as a cost term.)
is the cost of the visual measurement of the
ith frame and
kth MPs (if not observed, the cost is 0). Here, we use the weighted norm of the reprojection error as a cost function:
where
represents the weighted norm:
;
is the information matrix for the measurement;
is the residual;
is the measurement of the
kth MP in the
ith keyframe; and
is the predicted value of
, which is based on the keyframe’s pose estimation
and MP position’s estimation
:
where
and
are the rotation matrix and translation vector for
:
; and
is the camera projection function that projects points from 3D space onto the image.
The partial derivative of
is
Among the terms,
is the Jacobian matrix of the camera projection function. For the pinhole camera model, this is
Then, the Jacobian matrix of
is
where the columns of the two non-zero matrix blocks respectively correspond to the rows in which the states
and
are located in
.
The cost of the GNSS measurements is as follows (if there are no GNSS measurements in this keyframe, the cost is 0):
where
is the estimated GNSS position recorded by the
ith keyframe. It can be calculated from the keyframe’s pose estimation
and the GNSS position in {R}
(where the position is expressed as a homogeneous vector):
The partial derivative of
is
The Jacobian matrix of
then becomes
where the column of the non-zero matrix block corresponds to the row of the state
in
.
Finally, we combine the residual vectors, Jacobian matrix blocks, and information matrix blocks of all measurements. They are as follows:
where
only has non-zero matrix blocks on the diagonal, which represents the inverse uncertainty of each measurement, and there is no correlation between the measurements.
is the information matrix for the visual observation;
is the location error of the point in the image, which is related to the level
l of the feature point; and
is the weight of the GNSS measurement recorded by the
ith keyframe, which is related to the GNSS positioning error.
The state increment of each iteration of the optimization can be solved by the following equation:
After several iterations, all keyframe poses and MP positions in the entire map can be optimized.
4.5. Big Local Bundle Adjustment
After the scale initialization, the BLBA thread starts. This thread is similar to the GBA thread, except that BLBA does not optimize the whole map, but instead selects a local window for optimization. However, the local window in BLBA is much larger than that in LBA in the local mapping thread.
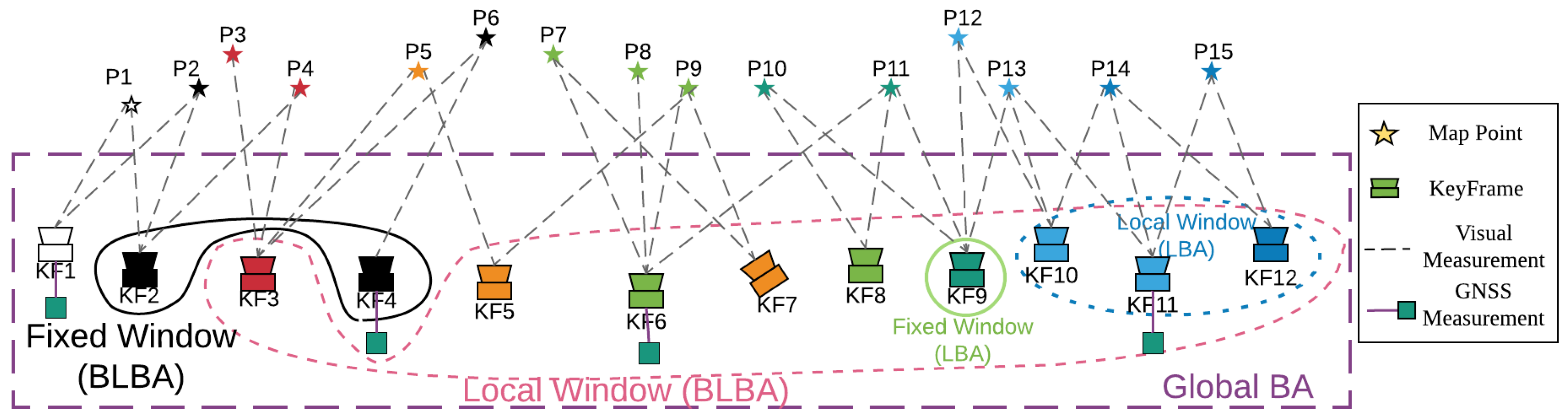
In LBA, the local window contains all the covisible keyframes of the current keyframe (keyframes sharing the same MPs are called covisible keyframes) and their visible MPs. Moreover, the keyframes that lie outside the local window but that have covisibility with some keyframes in the window are included in the optimization but remain fixed. For example, in
Figure 1, KF12 is the current keyframe, and it observes P14 and P15. Meanwhile, KF10 and KF11 observe the same MP. Thus, KFs 10–12 are in the local window, but the GNSS measurement of KF11 is not used in LBA. Keyframes in the local window observe three MPs: P13–15. KF9 also observes P13. Hence, KF9 is in the fixed window.
However, in BLBA, we set the size of the local window, for example, 8–10 keyframes. We select the keyframes by covisibility iteratively until the number of keyframes in the local window meets the requirements. For example, in
Figure 5, KF3 and MPs 5–12 are selected using covisibility several times, and we obtain nine keyframes in the local window. KFs 2 and 4 have covisibility with keyframes in the window and are thus selected by the fixed window. Therefore, the BLBA states are the poses of KF3 and KFs 5–12 and the position of MPs 2–15. Moreover, KF6 and KF11 are constrained not only by visual measurements but also by GNSS measurements.
The cost function of BLBA is similar to that of Equation (
4). The only difference is that in BLBA, only states in the local window are optimized. After the optimization, the BLBA thread updates the keyframes and MPs in the local window and waits for the next run.
5. Experiments
In this section, we describe how sequences 00–10 of the KITTI odometry dataset [
17] were used to evaluate the proposed method. In this dataset, they provide stereo camera and laser scanner data and ground-truth trajectories obtained by the RTK-GPS (Global Positioning System)/IMU (inertial navigation system). The frame rate of the video is about 10 Hz, and the resolution is
with a
field of view. The resolution of the ground-truth data is 0.02 m/0.1
. In our experiment, only one camera in the stereo camera system was used. The GNSS measurements were simulated by resampling the ground truth to a 1 Hz trajectory and adding Gaussian white noise with a STD of 3 m by default, which is achievable with a low-cost GNSS. In real practice, the noise model may be more complicated. One may use the pre-processing methods to filter the GNSS measurements [
31] or add a cost term in Equation (
4) to model the GNSS receiver’s noise.
The tests were performed on an Ubuntu 16.04 system running on an Intel Core i7-4710MQ processor with 16 GB of RAM. The median running time per frame of GVORB was 34 ms, which was slightly slower than that of ORB-SLAM at 32 ms. This was because the tracking threads of the two systems are the same but the GVORB updates the map more frequently; hence it takes slightly more time. In the KITTI dataset, the frame rate was about 10 Hz; hence all the tested systems ran in real-time.
5.1. Precision of Initialization
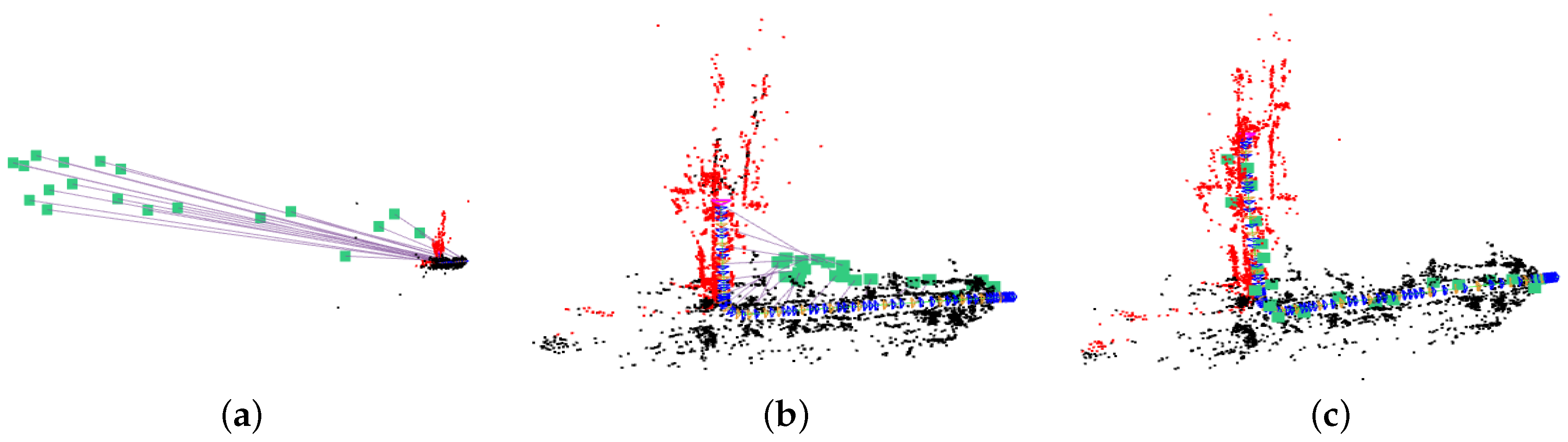
The GVORB initialization process is shown in
Figure 6. At first, the transformation and scale between {W} and {V} were arbitrary. After scale initialization, two coordinates had the same scale but different poses. Finally, after pose initialization, the two coordinates became coherent.
Five initializations were performed on each sequence of the KITTI dataset. When 20 GNSS data points were recorded and the distance moved by the camera was greater than 20 times the GNSS positioning error, initialization was triggered.
Table 1 records the scale initialization results.
As shown in the table, when GVORB ran for 20 s, 20 GNSS data points were recorded (in sequence 03, a GNSS measurement was aborted because of the slow motion), and the distance moved exceeded the threshold. Then, the scale initialization started. It can be seen that the scale estimation error was essentially around and that the maximum error was below .
After this, if the camera moved a sufficient distance in any two orthogonal directions, pose initialization was triggered.
Table 2 shows the results of pose initialization over five runs.
In the table, the data for sequences 01 and 04 are missing because the former lost tracking before the pose was initialized (see
Section 5.2) and the latter moved straight, which did not meet the initialization criteria. For the other sequences, the initialization times were different depending on the motion conditions. In the successfully initialized sequences, the average rotation error was lower than
and the average position error was lower than 3.6 m. Among the errors, the largest appeared for sequence 06. This was due to the shape of the trajectory being very “narrow” (see
Figure 7a). Therefore, the rotation estimation error was relatively large.
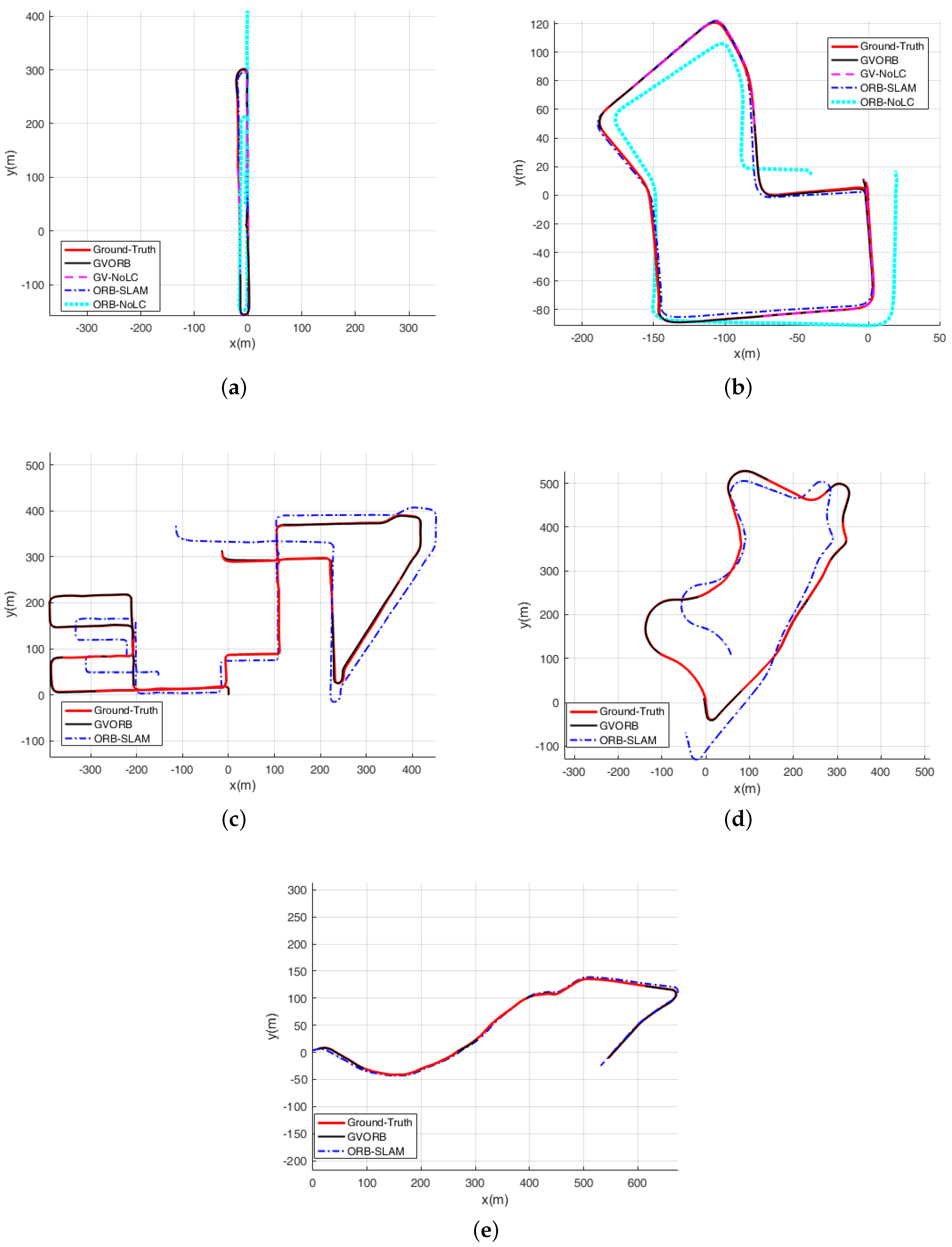
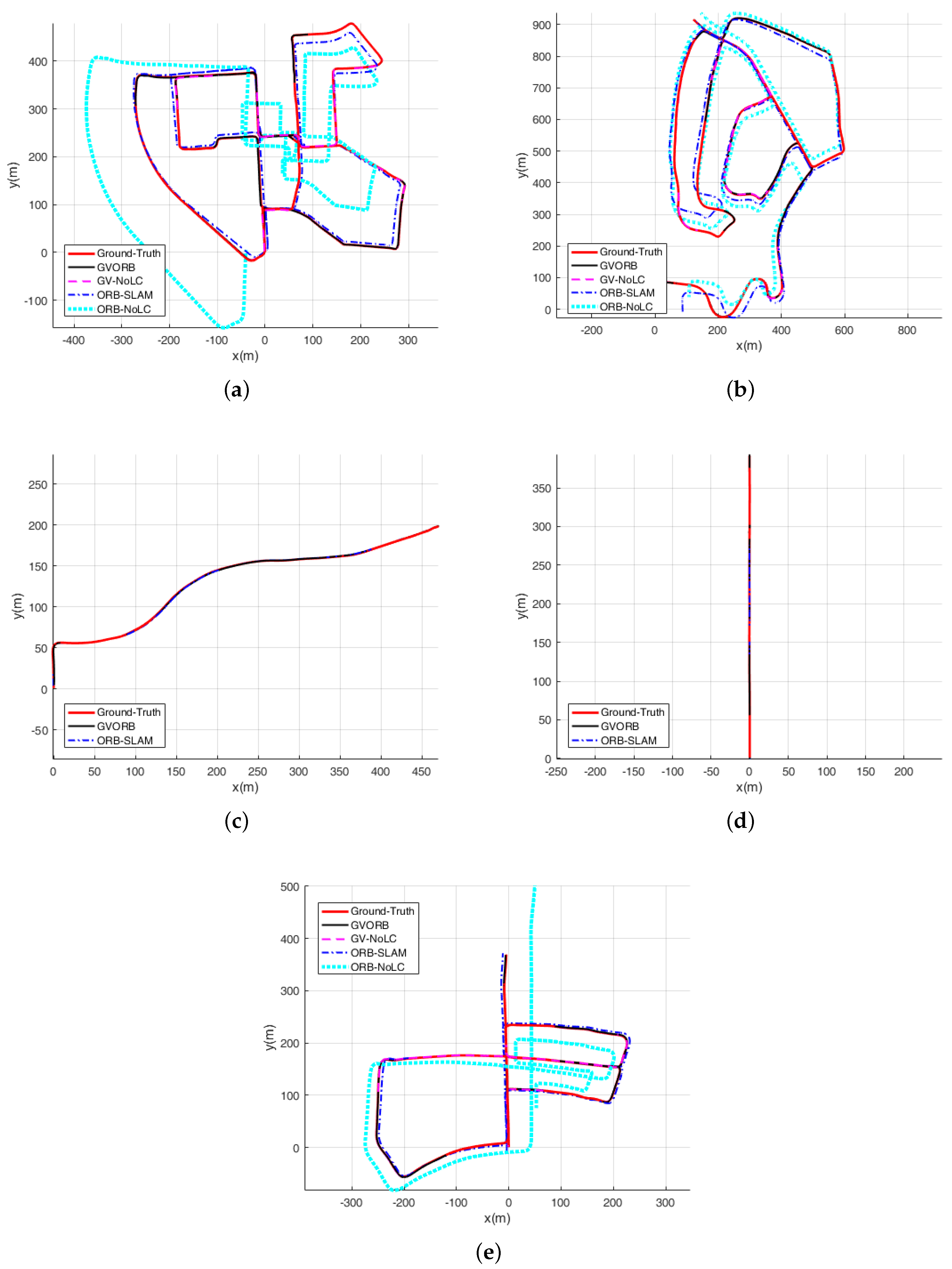
5.2. Localization Performance
In this section, we describe testing GVORB and ORB-SLAM on the dataset. Considering that in many applications the camera will not visit the same place twice, loop closure is not available, and localization before closing the loop is a good indicator for the accuracy [
40]. Therefore, we also tested the no-loop-closure versions of GVORB and ORB-SLAM (abbreviated as GV-NoLC and ORB-NoLC). The localization results are shown in
Figure 7 and
Figure 8 (blue lines: estimated trajectory; red lines: ground truth). The median root-mean-square error (RMSE) values of position and rotation estimations for all runs are shown in
Table 3 and
Table 4 (in sequences 03–04 and 08–10, no loops were detected; thus the results of the original and NoLC versions were merged). In sequence 08, although the trajectory overlapped in some regions, the vehicle moved in opposite or orthogonal directions; this is very challenging for place recognition algorithms. Therefore, the systems did not detect any loop in the whole sequence. In sequence 01, all algorithms failed, because this sequence was on a highway with few close trackable objects [
1]. Therefore, we do not show the results of this sequence.
From the figures, for all sequences, it can be seen that both GVORB and GV-NoLC worked very well. The estimated and ground-truth trajectories almost overlapped. In
Table 3, the median RMSE of the estimated position was 0.82 m, which was much more accurate than measurements taken directly from GNSS receivers (3 m). The accuracy of GV-NoLC was similar to that of GVORB. This is because both visual loop closure and GNSS can correct drift for visual odometry, but in such situations, GNSS performs excellently and loop closure cannot further improve the performance. However, we did not cancel the loop closure thread. The reason is explained in
Section 3.
The algorithms developed in [
27,
30] integrate electronic maps and low-cost GNSS and IMUs. When the GNSS receiver’s accuracy is also 3 m, the positioning error is higher than 0.7 m. Our GVORB system achieves similar accuracy without any pre-built map or IMU.
For sequences 03, 04, and 07, the accuracies of ORB-SLAM and GVORB were similar. These three sequences are relatively short, and visual error accumulation was not significant. For sequences 00 and 05, although they are long, loop closure was performed several times, and thus the error was not high. Although there was a loop correction for sequence 02, it was not enough to effectively constrain all the trajectories. Sequences 08 and 09 are very long, but the system did not detect any loops. Thus, the positioning errors of sequences 02, 08, and 09 were much higher than for GVORB. Further, ORB-NoLC does not perform loop closure; thus, as a result of error accumulation, the positioning error was very high for all long sequences.
From
Table 4, the attitude accuracies estimated by every method were close for all sequences. With the exception of sequence 10, the median RMSE values were around
. GVORB was only slightly better than ORB-SLAM, and the loop closure slightly raised the attitude error. The results show that for the KITTI dataset, the attitude drift of visual-SLAM was very small.
The above results show that pure monocular visual-SLAM only guarantees positioning accuracy within a certain time and distance range. In the experiment, the positioning error was less than 5 m for 2 min and 1 km. When integrated with GNSS measurements, GVORB achieved very high positioning accuracy over any long trajectory.
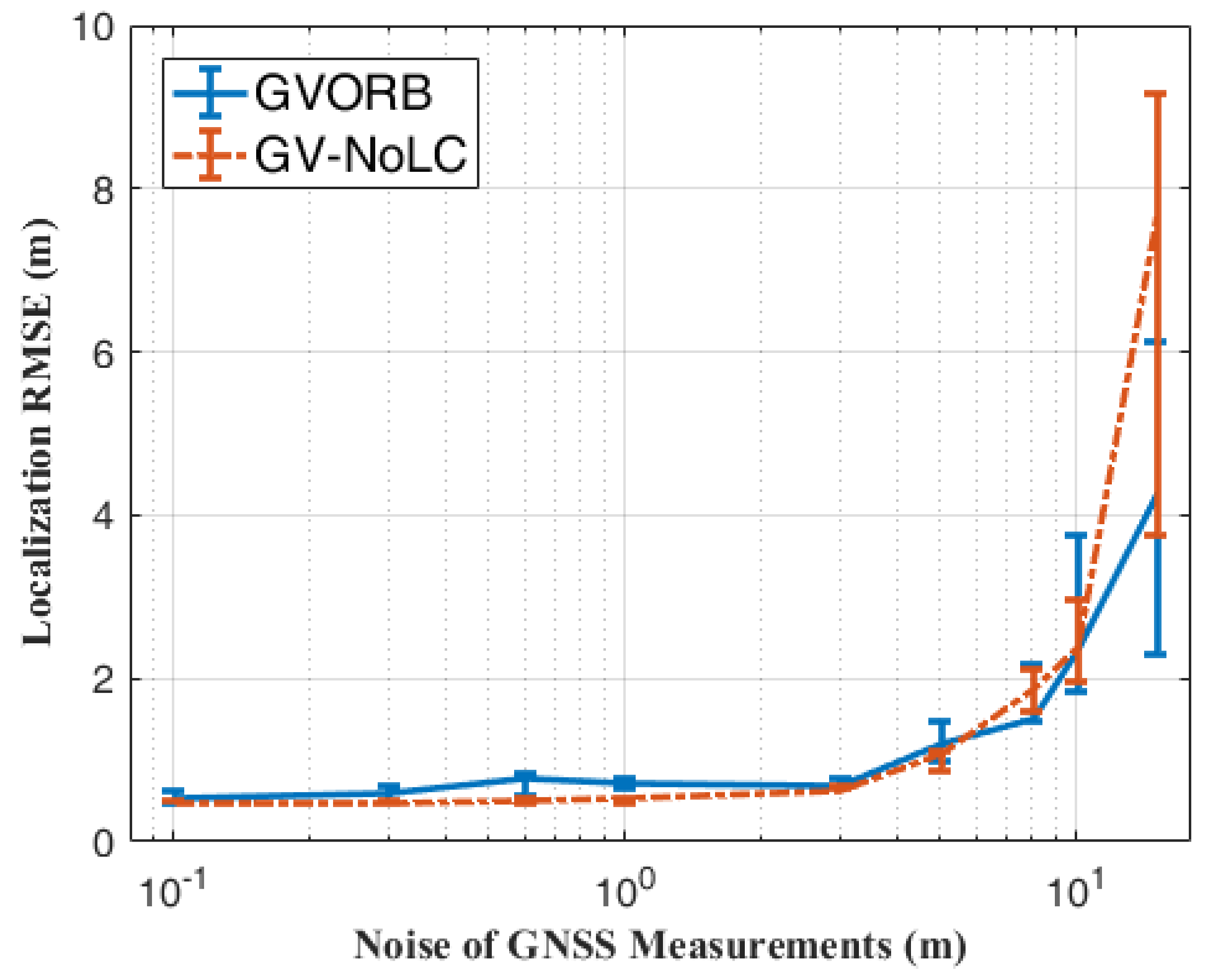
5.3. GNSS Noise versus Localization Error
We tested the effect of the GNSS error on the localization error of GVORB and GV-NoLC for sequence 05. Noise was added to the ground-truth trajectory to simulate noisy GNSS data. The STDs of the GNSS noise were set to
m. The localization errors are shown in
Figure 9.
From the figure, when the GNSS noise was less than 1 m, the localization error of GVORB was always around 0.6 m. In this situation, the GVORB error was higher than that of GNSS. This was mainly due to the fact that the GNSS frame rate was 1 Hz and the frame rate of the camera was about 10 Hz. Thus, only 1/10 of the frames could be constrained by the GNSS receivers. The visual error of the other frames played a major role in the localization error. Therefore, the overall error was slightly higher than the GNSS noise. When the GNSS noise increased from 1 to 15 m, although the GVORB error also increased, the growth rate was relatively low; it only increased from 0.7 to 4 m. The error was about 1/4 of the GNSS noise. In this situation, the weights of the GNSS measurements were decreased automatically; hence the error grew sublinearly with GNSS noise.
GVORB and GV-NoLC demonstrated similar performances when the GNSS noise was less than 5 m. We can conclude that in this case, GNSS and loop closure had similar abilities to reduce drift. When the GNSS noise grew larger, loop closure played a more important role in reducing the localization error. Comparing GV-NoLC with ORB-NoLC, for sequence 05, the former achieved 8 m accuracy in the worst case, while the error of the latter reached 26 m. We can conclude that when there is no loop in the trajectory, GVORB greatly outperforms pure GNSS and visual-SLAM.
6. Discussion
In the previous section, we evaluate GVORB in terms of the KITTI dataset. Experiments showed that GVORB incorporates the benefits of GNSS and visual-SLAM. The system estimates absolute pose with high accuracy and scale with no drift.
In addition, the original ORB-SLAM method has the ability to relocalize from a pre-built map. Although we did not test it, GVORB inherits this ability. Further, the map built by GVORB can be also utilized by pure visual-SLAM systems. GVORB can also be integrated with the other latest SLAM technologies. For example, the method in this article can be extended to stereo, panorama, and RGB-D cameras [
37] or can be combined with IMU [
41] to further improve the accuracy and robustness of the system. In addition, the map in GVORB is very sparse, which is only useful for localization. It is also possible and easy to add semi-dense [
42] and dense [
6,
43] mapping modules. By combining the scene understanding module, GVORB can also work for obstacle avoidance [
5] and scene segmentation and understanding [
6,
7,
44].
7. Conclusions
In this paper, we propose GVORB: an integrated visual-GNSS–SLAM system. In the system, a monocular camera and low-cost GNSS with a positioning accuracy of several meters were applied and studied. Compared with pure GNSS, GVORB can measure attitude, and it has higher localization accuracy. Compared to the visual-SLAM system, absolute pose and scale are observable in GVORB and drift is eliminated, which greatly improves the long-term localization accuracy. Experiments on the KITTI dataset verified the above conclusion. Through the experiments, we found that GNSS measurements could provide higher consistency compared to visual loop closure. Loop closure does not significantly improve the localization accuracy of GVORB when the GNSS positioning error is relatively small (less than 10 m). Benefitting from the smooth effect of visual-SLAM, GVORB obtains a higher frame rate and accuracy than pure GNSS positioning. In the case of poor GNSS accuracy, the performance of GVORB is much better than that of pure GNSS positioning.
In addition, unlike other visual-GNSS navigation systems, we use an optimization-based method for data fusion. Therefore, our method has high accuracy. Our method demonstrated a performance similar to that of navigation algorithms that integrate cameras, IMUs, GNSS receivers, and pre-built maps. Moreover, our method also creates a global map that has global consistency during long-term navigation.
Furthermore, our system can be extended to work on other types of cameras and to build other types of maps. This is a direction we will study in the future.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}