Improving Classification Algorithms by Considering Score Series in Wireless Acoustic Sensor Networks




Abstract
:1. Introduction
1.1. Sound Monitoring and Classification
1.2. Previous Work
1.3. Research Objectives
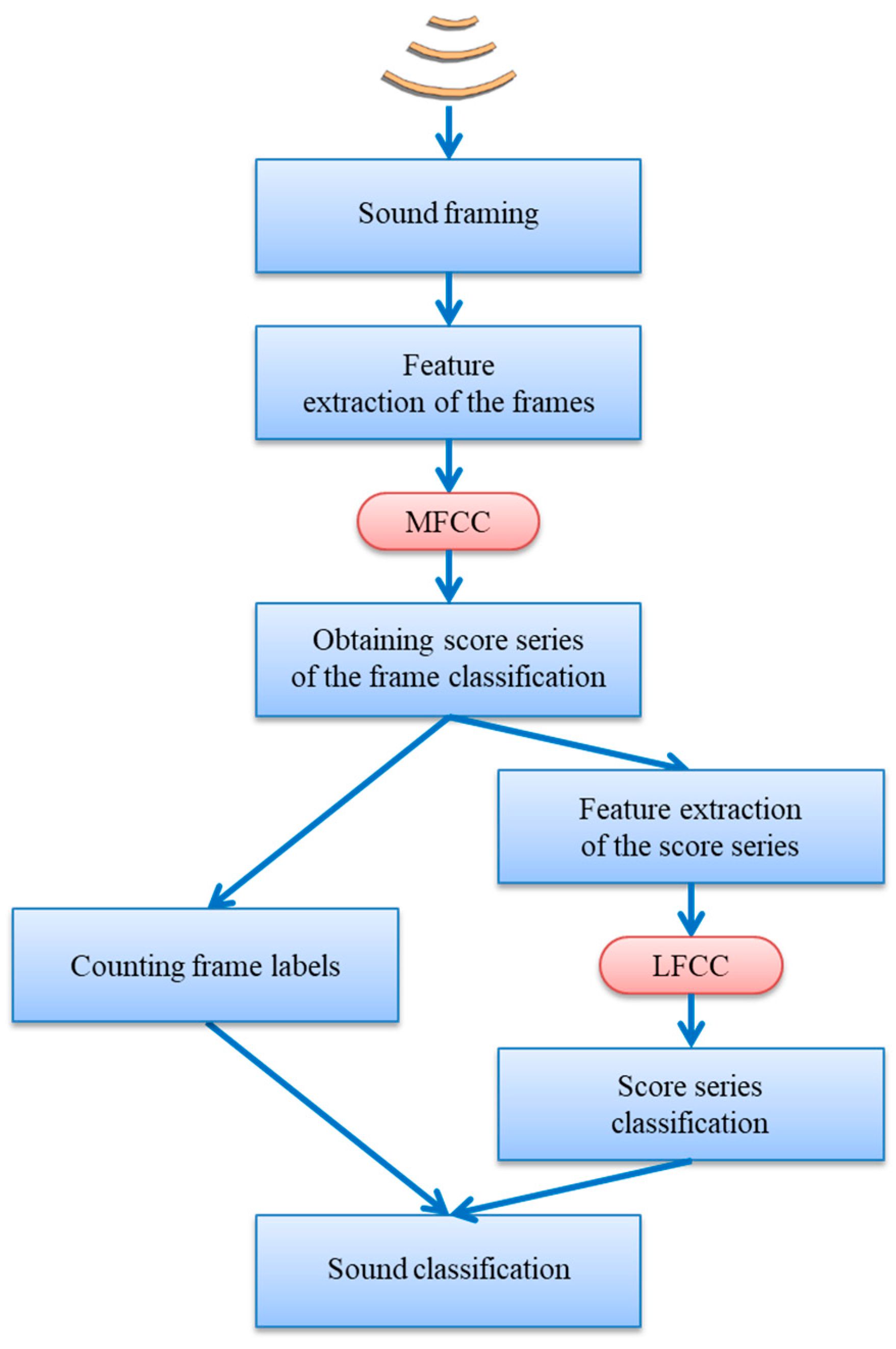
2. Materials and Methods
2.1. WSN Architecture
2.2. Dataset
- Epidalea calamita; mating call (369 records).
- Epidalea calamita; release call (63 records).
- Alytes obstetricans; mating call (419 records).
- Alytes obstetricans; distress call (17 records).
2.3. Feature Extraction
- Sound pre-emphasis, using a first-order digital filter with constant , which provides a more uniform signal-to-noise ratio (SNR).
- Sound framing using a Hamming window of 25 ms and a hop size of 10 ms.
- Obtaining the Energy Spectral Density (ESD) of each frame.
- Representing the values of ESD in logarithmic scale (LogESD).
- Spectrum filtering between 300 Hz and 3700 Hz, a band where the vocal sounds contain most of their energy.
- Obtaining the Mel Logarithmic Filter Bank Energy (MelLogFBE) spectrum as the LogESD at a triangular filter bank which uses 20 filters centred at the Mel frequencies [53]. After this step, the frame spectrum is represented by the 20 values of the energy at each filter.
- Cepstral representation of the MelLogFBE using the Discrete Cosine Transform, obtaining 20 cepstral coefficients (MelLogDCT), which are the first form of the MFCC.
- Reducing the number of cepstral coefficients (MFCC) by preserving the first coefficients and discarding the remaining 7.
- Cepstral liftering the MFCC using a sine lifter (a filter in the cepstral domain) with constant .
2.4. Frame Classification
2.5. Score-Series Classification
- Obtaining the Energy Spectral Density (ESD) of the score series.
- Representing the values of ESD in logarithmic scale (LogESD).
- Obtaining the Linear Logarithmic Filter Bank Energy (LinLogFBE) spectrum as the LogESD at a triangular filter bank which uses 20 filters centred at linear (not Mel scaled) frequencies. After this step, the frame spectrum is represented by the 20 values of the energy at each filter.
- Cepstral representation of the LinLogFBE using the Discrete Cosine Transform, obtaining 20 cepstral coefficients (LinLogDCT), which are the first form of the Linear Frequency Cepstral Coefficients (LFCC).
- Reducing the number of the cepstral coefficients (LFCC), by preserving the first coefficients and discarding the remaining 7.
2.6. Classification Metrics
2.7. Bootstrap Analysis
3. Results
3.1. Classification by Counting Frames
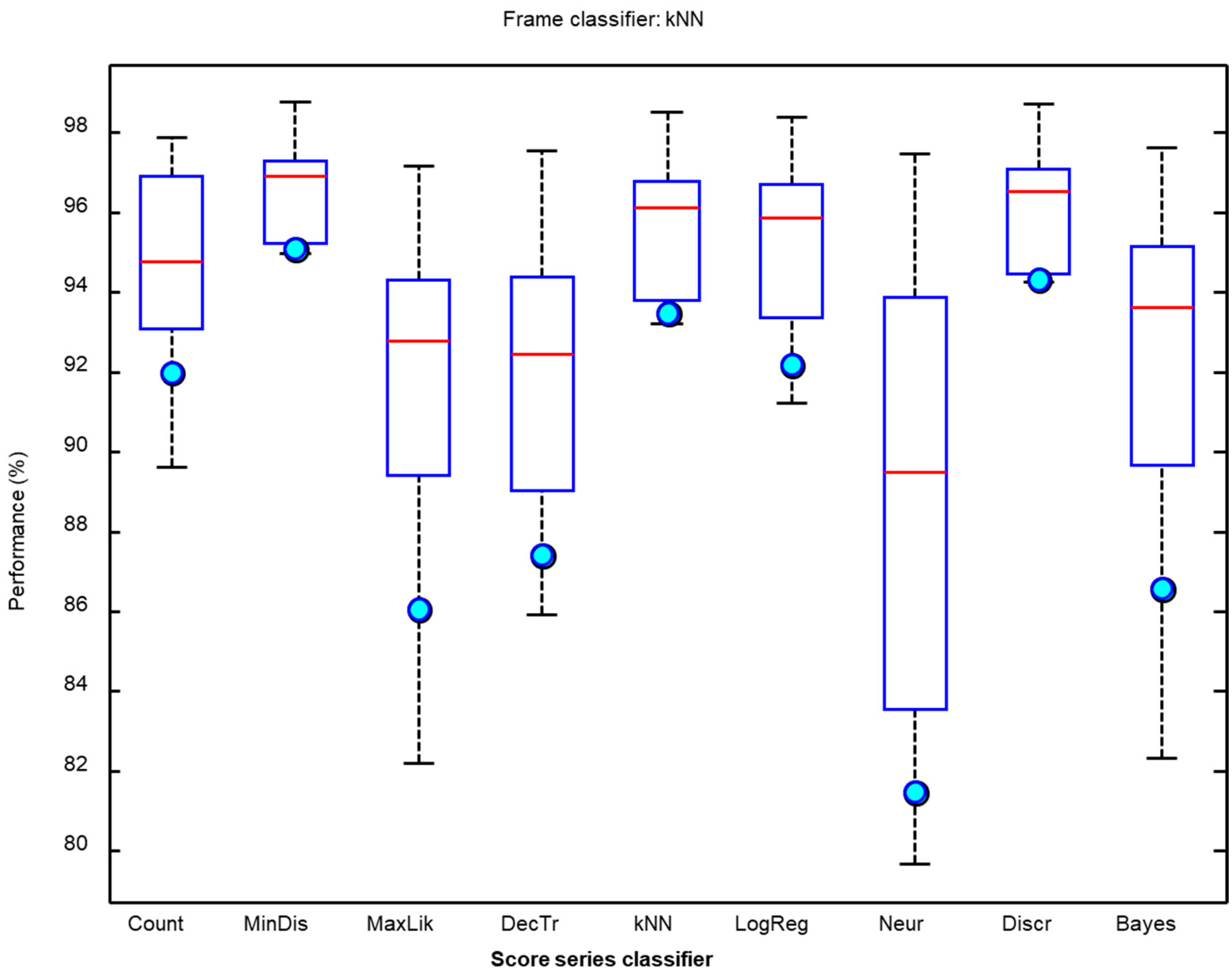
3.2. Classification of Score Series Obtained with the kNN Frame Classifier
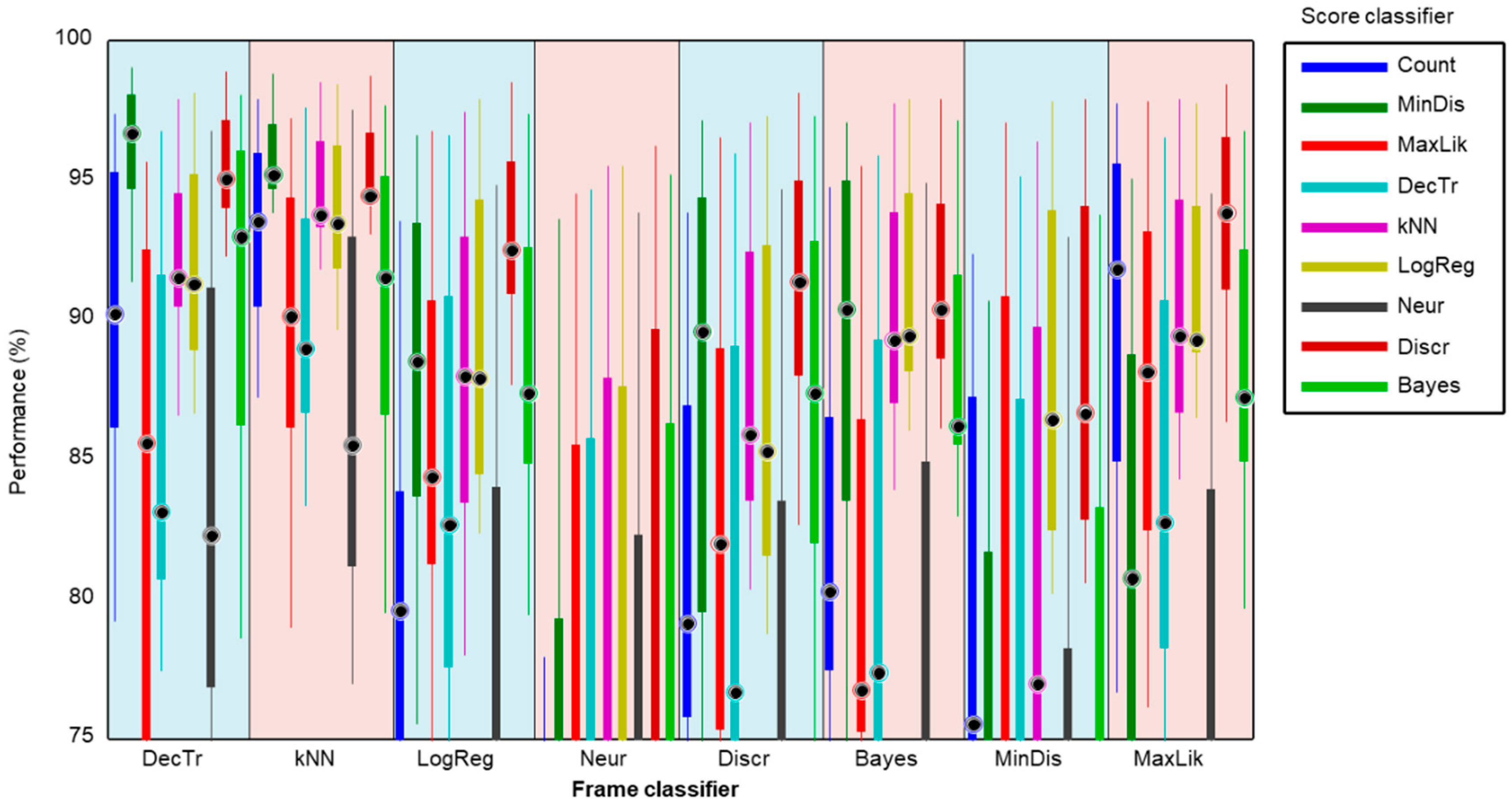
3.3. Optimum Classification of Score Series
3.4. Bootstrap Analysis
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mydlarz, C.; Salamon, J.; Bello, J.P. The implementation of low-cost urban acoustic monitoring devices. Appl. Acoust. 2017, 117, 207–218. [Google Scholar] [CrossRef] [Green Version]
- Hernandez-Jayo, U.; Alsina-Pages, R.M.; Angulo, I.; Alías, F. Remote Acoustic Monitoring System for Noise Sensing. In Online Engineering & Internet of Things; Springer: Cham, Switzerland, 2018; pp. 77–84. [Google Scholar]
- Segura-Garcia, J.; Navarro-Ruiz, J.M.; Perez-Solano, J.J.; Montoya-Belmonte, J.; Felici-Castell, S.; Cobos, M.; Torres-Aranda, A.M. Spatio-Temporal Analysis of Urban Acoustic Environments with Binaural Psycho-Acoustical Considerations for IoT-Based Applications. Sensors 2018, 18, 690. [Google Scholar] [CrossRef] [PubMed]
- Khamukhin, A.A.; Demin, A.Y.; Sonkin, D.M.; Bertoldo, S.; Perona, G.; Kretova, V. An algorithm of the wildfire classification by its acoustic emission spectrum using Wireless Sensor Networks. J. Phys. Conf. Ser. 2017, 803, 1–6. [Google Scholar] [CrossRef]
- Wimmer, J.; Towsey, M.; Roe, P.; Williamson, I. Sampling environmental acoustic recordings to determine bird species richness. Ecol. Appl. 2013, 23, 1419–1428. [Google Scholar] [CrossRef] [PubMed]
- Alonso, J.B.; Cabrera, J.; Shyamnani, R.; Travieso, C.M.; Bolaños, F.; García, A.; Villegas, A.; Wainwright, M. Automatic anuran identification using noise removal and audio activity detection. Expert Syst. Appl. 2017, 72, 83–92. [Google Scholar] [CrossRef]
- Cambron, M.E.; Bowker, R.G. An automated digital sound recording system: The Amphibulator. In Proceedings of the Eighth IEEE International Symposium on Multimedia, San Diego, CA, USA, 11–13 December 2006; pp. 592–600. [Google Scholar] [CrossRef]
- Aide, T.M.; Corrada-Bravo, C.; Campos-Cerqueira, M.; Milan, C.; Vega, G.; Alvarez, R. Real-time bioacoustics monitoring and automated species identification. PeerJ 2013, 1, e103. [Google Scholar] [CrossRef] [PubMed]
- Diaz, J.J.; Nakamura, E.F.; Yehia, H.C.; Salles, J.; Loureiro, A. On the Use of Compressive Sensing for the Reconstruction of Anuran Sounds in a Wireless Sensor Network. In Proceedings of the IEEE International Conference on Green Computing and Communications (GreenCom), Besancon, France, 20–23 November 2012; pp. 394–399. [Google Scholar] [CrossRef]
- Potamitis, I. Unsupervised dictionary extraction of bird vocalisations and new tools on assessing and visualising bird activity. Ecol. Inform. 2015, 26, 6–17. [Google Scholar] [CrossRef]
- Forti, L.R.; Foratto, R.M.; Márquez, R.; Pereira, V.R.; Toledo, L.F. Current knowledge on bioacoustics of the subfamily Lophyohylinae (Hylidae, Anura) and description of Ocellated treefrog Itapotihyla langsdorffii vocalizations. PeerJ 2018, 6, e4813. [Google Scholar] [CrossRef] [PubMed]
- Noda, J.J.; Travieso, C.M.; Sánchez-Rodríguez, D. Methodology for automatic bioacoustic classification of anurans based on feature fusion. Expert Syst. Appl. 2016, 50, 100–106. [Google Scholar] [CrossRef]
- Colonna, J.G.; Cristo, M.; Salvatierra, M.; Nakamura, E.F. An incremental technique for real-time bioacoustic signal segmentation. Expert Syst. Appl. 2015, 42, 7367–7374. [Google Scholar] [CrossRef]
- Rabiner, L.; Juang, B.H. Fundamentals of Speech Recognition; Prentice-Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Benesty, J. Springer Handbook of Speech Processing; Springer Science & Business Media: Berlin, Germany, 2008. [Google Scholar]
- Fulop, S. Speech Spectrum Analysis; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Zheng, F.; Zhang, G.; Song, Z. Comparison of different implementations of MFCC. J. Comput. Sci. Technol. 2001, 16, 582–589. [Google Scholar] [CrossRef]
- European Telecommunications Standards Institute (ETSI). ETSI Std 202 050-1.5 Speech Processing, Transmission and Quality Aspects (STQ); Distributed Speech Recognition; Advanced Front-End Feature Extraction Algorithm; Compression Algorithms; ETSI: Nice, France, 2007. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin, Germany, 2006. [Google Scholar]
- Flach, P. Machine Learning: The Art and Science of Algorithms That Make Sense of Data; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Dietterich, T.G. Machine learning for sequential data: A review. In Structural, Syntactic, and Statistical Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2002; pp. 15–30. [Google Scholar]
- Esling, P.; Agon, C. Time-Series Data Mining. ACM Comput. Surv. 2012, 45, 12. [Google Scholar] [CrossRef]
- Theodoridis, S.; Chellappa, R. Academic Press Library in Signal Processing. In Signal Processing Theory and Machine Learning; Academic Press: Cambridge, MA, USA, 2013; Volume 1. [Google Scholar]
- Gopi, E.S. Digital Speech Processing Using Matlab; Springer: New Delhi, India, 2014. [Google Scholar]
- Dayou, J.; Han, N.C.; Mun, H.C.; Ahmad, A.H.; Muniandy, S.V.; Dalimin, M.N. Classification and identification of frog sound based on entropy approach. In Proceedings of the 2011 International Conference on Life Science and Technology, Singapore, 1–3 June 2011; Volume 3, pp. 184–187. [Google Scholar]
- Towsey, M.; Wimmer, J.; Williamson, I.; Roe, P. The use of acoustic indices to determine avian species richness in audio-recordings of the environment. Ecol. Inform. 2014, 21, 110–119. [Google Scholar] [CrossRef]
- Ganchev, T.D.; Jahn, O.; Marques, M.I.; de Figueiredo, J.M.; Schuchmann, K.L. Automated acoustic detection of Vanellus chilensis lampronotus. Expert Syst. Appl. 2015, 42, 6098–6111. [Google Scholar] [CrossRef]
- Patti, A.; Williamson, G.A. Methods for classification of nocturnal migratory bird vocalizations using Pseudo Wigner-Ville Transform. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 758–762. [Google Scholar] [CrossRef]
- Lee, C.H.; Lee, Y.K.; Huang, R.Z. Automatic recognition of bird songs using cepstral coefficients. J. Inf. Technol. Appl. 2006, 1, 17–23. [Google Scholar]
- Wielgat, R.; Potempa, T.; Świętojański, P.; Król, D. On using prefiltration in HMM-based bird species recognition. In Proceedings of the 2012 International conference on Signals and Electronic Systems (ICSES), Wroclaw, Poland, 18–21 September 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Huang, C.J.; Chen, Y.J.; Chen, H.M.; Jian, J.J.; Tseng, S.C.; Yang, Y.J.; Hsu, P.A. Intelligent feature extraction and classification of anuran vocalizations. Appl. Soft Comput. 2014, 19, 1–7. [Google Scholar] [CrossRef]
- Chou, C.H.; Liu, P.H. Bird species recognition by wavelet transformation of a section of birdsong. In Proceedings of the Symposia and Workshops on Ubiquitous, Autonomic and Trusted Computing (UIC-ATC’09), Brisbane, Australia, 7–9 July 2009; pp. 189–193. [Google Scholar] [CrossRef]
- Somervuo, P.; Harma, A.; Fagerlund, S. Parametric representations of bird sounds for automatic species recognition. IEEE Trans. Audio Speech Lang. Process 2006, 14, 2252–2263. [Google Scholar] [CrossRef]
- Huang, C.J.; Yang, Y.J.; Yang, D.X.; Chen, Y.J. Frog classification using machine learning techniques. Expert Syst. Appl. 2009, 36, 373–3743. [Google Scholar] [CrossRef]
- Mitrovic, D.; Zeppelzauer, M.; Breiteneder, C. Discrimination and retrieval of animal sounds. In Proceedings of the 2006 12th International Multi-Media Modelling Conference, Beijing, China, 4–6 January 2006; p. 5. [Google Scholar] [CrossRef]
- Juang, C.F.; Chen, T.M. Birdsong recognition using prediction-based recurrent neural fuzzy networks. Neurocomputing 2007, 71, 121–130. [Google Scholar] [CrossRef]
- Tyagi, H.; Hegde, R.M.; Murthy, H.A.; Prabhakar, A. Automatic identification of bird calls using spectral ensemble average voice prints. In Proceedings of the 2006 14th European Signal Processing Conference, Florence, Italy, 4–8 September 2006; pp. 1–5. [Google Scholar]
- Bedoya, C.; Isaza, C.; Daza, J.M.; López, J.D. Automatic recognition of anuran species based on syllable identification. Ecol. Inform. 2014, 24, 200–209. [Google Scholar] [CrossRef]
- Luque, J.; Larios, D.F.; Personal, E.; Barbancho, J.; León, C. Evaluation of MPEG-7-Based Audio Descriptors for Animal Voice Recognition over Wireless Acoustic Sensor Networks. Sensors 2016, 16, 717. [Google Scholar] [CrossRef] [PubMed]
- International Organization for Standardization. ISO/IEC 15938-4:2001 (MPEG-7: Multimedia Content Description Interface), Part 4: Audio; ISO/IEC JTC, 1; ISO: Geneva, Switzerland, 2001. [Google Scholar]
- Luque, A.; Romero-Lemos, J.; Carrasco, A.; Barbancho, J. Non-sequential automatic classification of anuran sounds for the estimation of climate-change indicators. Expert Syst. Appl. 2018, 95, 248–260. [Google Scholar] [CrossRef]
- Luque, A.; Romero-Lemos, J.; Carrasco, A.; Gonzalez-Abril, L. Temporally-aware algorithms for the classification of anuran sounds. PeerJ 2018, 6, e4732. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luque, A.; Gómez-Bellido, J.; Carrasco, A.; Barbancho, J. Optimal Representation of Anuran Call Spectrum in Environmental Monitoring Systems Using Wireless Sensor Networks. Sensors 2018, 18, 1803. [Google Scholar] [CrossRef] [PubMed]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; et al. The HTK Book (for HTK Version 3.5); Department of Engineering, University of Cambridge: Cambridge, UK, 2015. [Google Scholar]
- Luque, A.; Gómez-Bellido, J.; Carrasco, A.; Personal, E.; Leon, C. Evaluation of the Processing Times in Anuran Sound Classification. Wirel. Commun. Mob. Comput. 2017, 2017, 8079846. [Google Scholar] [CrossRef]
- Fonozoo. Available online: www.fonozoo.com (accessed on 23 January 2018).
- Li, J.; Deng, L.; Gong, Y.; Haeb-Umbach, R. An overview of noise-robust automatic speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 745–777. [Google Scholar] [CrossRef]
- Zhang, Z.; Geiger, J.; Pohjalainen, J.; Mousa, A.E.D.; Jin, W.; Schuller, B. Deep learning for environmentally robust speech recognition: An overview of recent developments. ACM Trans. Intell. Syst. Technol. 2018, 9, 49. [Google Scholar] [CrossRef]
- Bardeli, R.; Wolff, D.; Kurth, F.; Koch, M.; Tauchert, K.H.; Frommolt, K.H. Detecting bird sounds in a complex acoustic environment and application to bioacoustic monitoring. Pattern Recognit. Lett. 2010, 31, 1524–1534. [Google Scholar] [CrossRef]
- Vélez, A.; Schwartz, J.J.; Bee, M.A. Anuran acoustic signal perception in noisy environments. In Animal Communication and Noise; Springer: Berlin/Heidelberg, Germany, 2013; pp. 133–185. ISBN 978-3-642-41493-0. [Google Scholar]
- Patel, R.R.; Dubrovskiy, D.; Döllinger, M. Measurement of glottal cycle characteristics between children and adults: Physiological variations. J. Voice 2014, 28, 476–486. [Google Scholar] [CrossRef] [PubMed]
- Fay, R.R.; Popper, A.N. (Eds.) Comparative Hearing: Fish and Amphibians; Springer Science & Business Media: New York, NY, USA, 2012; Volume 11, ISBN 978-0387984704. [Google Scholar]
- O’shaughnessy, D. Speech Communication: Human and Machin, 2nd ed.; Wiley-IEEE Press: Hoboken, NJ, USA, 1999; ISBN 978-0-7803-3449-6. [Google Scholar]
- Wacker, A.G.; Landgrebe, D.A. The Minimum Distance Approach to Classification; Information Note 100771; Purdue University: West Lafayette, IN, USA, 1971. [Google Scholar]
- Le Cam, L. Maximum likelihood: An introduction. Int. Stat. Rev./Rev. Int. Stat. 1990, 153–171, 153–171. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O. Data Mining with Decision Trees: Theory and Applications; World Scientific Pub Co. Inc.: Singapore, 2008; ISBN 978-981-277-171-1. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest neighbour pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Dobson, A.J.; Barnett, A. An Introduction to Generalized Linear Models; CRC Press: Boca Raton, FL, USA, 2008; ISBN 9781584889502. [Google Scholar]
- Du, K.L.; Swamy, M.N.S. Neural Networks and Statistical Learning; Springer Science and Business Media: Berlin, Germany, 2013; ISBN 978-1-4471-5571-3. [Google Scholar]
- Härdle, W.K.; Simar, L. Applied Multivariate Statistical Analysis; Springer Science and Business Media: Berlin, Germany, 2012; ISBN 978-3-540-72244-1. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference and Prediction; Springer: Berlin, Germany, 2005; ISBN 978-0-387-84858-7. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Gorodkin, J. Comparing two K-category assignments by a K-category correlation coefficient. Comput. Boil. Chem. 2004, 28, 367–374. [Google Scholar] [CrossRef] [PubMed]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Pavlopoulos, S.A.; Stasis, A.C.; Loukis, E.N. A decision tree—Based method for the differential diagnosis of Aortic Stenosis from Mitral Regurgitation using heart sounds. Biomed. Eng. Online 2004, 3, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bravo, C.J.C.; Berríos, R.Á.; Aide, T.M. Species-specific audio detection: A comparison of three template-based detection algorithms using random forests. PeerJ Comput. Sci. 2017, 3, e113. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sound Class | Sound Recordings | ||
|---|---|---|---|
| Number | Seconds | Ratio | |
| Ep. cal. mating call | 369 | 1853 | 43% |
| Ep. cal. release call | 63 | 311 | 7% |
| Al. ob. mating call | 419 | 2096 | 48% |
| Al. ob. distress call | 17 | 83 | 2% |
| Total | 868 | 4343 | 100% |
| Classifier | Training Functions | Test Functions |
|---|---|---|
| MinDis | - | - |
| MaxLik | fitgmdist | mvnpdf |
| DecTr | fitctree | predict |
| kNN | fitcknn | predict |
| LogReg | mnrfit | mnrval |
| Neur | feedforwardnet; train | net |
| Discr | fitcdiscr | predict |
| Bayes | fitNaiveBayes | posterior |
| Metric | Global | |
|---|---|---|
| Sensitivity | ||
| Specificity | ||
| Precision | ||
| Negative Predictive ) | ||
| Accuracy | Not defined | |
| Geometric Mean | ||
| Matthews Correlation Coefficient | Not defined | |
| Bookmaker Informedness | ||
| Markedness |
| SNS | SPC | PRC | NPV | ACC | F1 | GM | MCCn | BMn | MKn | |
|---|---|---|---|---|---|---|---|---|---|---|
| MinDis | 82.66% | 92.37% | 60.03% | 90.51% | 75.92% | 62.89% | 87.22% | 82.08% | 87.52% | 75.27% |
| MaxLik | 93.49% | 97.72% | 79.89% | 96.79% | 92.40% | 84.88% | 95.57% | 93.84% | 95.61% | 88.34% |
| DecTr | 82.51% | 96.69% | 95.30% | 97.36% | 92.40% | 86.15% | 88.04% | 93.60% | 89.60% | 96.33% |
| kNN | 89.64% | 97.57% | 95.97% | 97.90% | 94.35% | 92.01% | 93.11% | 95.23% | 93.60% | 96.93% |
| LogReg | 78.17% | 92.67% | 81.05% | 93.49% | 82.83% | 76.74% | 83.81% | 86.01% | 85.42% | 87.27% |
| Neur | 41.80% | 77.90% | 40.44% | 77.24% | 24.65% | 22.46% | 50.59% | 55.86% | 59.85% | 58.84% |
| Discr | 82.05% | 93.70% | 75.74% | 93.80% | 84.56% | 76.14% | 86.90% | 87.17% | 87.87% | 84.77% |
| Bayes | 79.32% | 94.43% | 81.15% | 94.73% | 86.52% | 79.11% | 85.32% | 88.71% | 86.87% | 87.94% |
| Classification Class | |||||
|---|---|---|---|---|---|
| Ep. cal. Mating Call | Ep. cal. Release Call | Al. ob. Mating Call | Al. ob. Distress Call | ||
| Data class | Ep. cal. mating call | 99.46% | 0.54% | 0% | 0% |
| Ep. cal. release call | 30.16% | 65.08% | 4.77% | 0% | |
| Al. ob. mating call | 5.97% | 0% | 94.03% | 0% | |
| Al. ob. distress call | 0% | 0% | 0% | 100% | |
| SNS | SPC | PRC | NPV | ACC | F1 | GM | MCCn | BMn | MKn | |
|---|---|---|---|---|---|---|---|---|---|---|
| Count | 89.64% | 97.57% | 95.97% | 97.90% | 94.35% | 92.01% | 93.11% | 95.23% | 93.60% | 96.93% |
| MinDis | 95.27% | 98.79% | 95.01% | 98.78% | 96.89% | 95.14% | 96.97% | 97.32% | 97.03% | 96.90% |
| MaxLik | 91.54% | 97.21% | 82.23% | 96.73% | 92.17% | 86.10% | 94.32% | 93.44% | 94.37% | 89.48% |
| DecTr | 85.95% | 97.40% | 89.09% | 97.58% | 93.55% | 87.42% | 91.16% | 94.41% | 91.68% | 93.33% |
| kNN | 93.86% | 98.48% | 93.24% | 98.53% | 96.31% | 93.53% | 96.11% | 96.82% | 96.17% | 95.89% |
| LogReg | 93.39% | 98.45% | 91.24% | 98.44% | 96.20% | 92.24% | 95.85% | 96.73% | 95.92% | 94.84% |
| Neur | 79.72% | 97.24% | 83.59% | 97.52% | 92.97% | 81.50% | 87.43% | 93.91% | 88.48% | 90.56% |
| Discr | 94.48% | 98.66% | 94.29% | 98.71% | 96.66% | 94.34% | 96.47% | 97.12% | 96.57% | 96.50% |
| Bayes | 92.72% | 97.62% | 82.37% | 97.10% | 93.09% | 86.59% | 95.14% | 94.24% | 95.17% | 89.73% |
| Classification Class | |||||
|---|---|---|---|---|---|
| Ep. cal. Mating Call | Ep. cal. Release Call | Al. ob. Mating Call | Al. ob. Distress Call | ||
| Data class | Ep. cal. mating call | 96.48% | 2.98% | 0.27% | 0.27% |
| Ep. cal. release call | 3.17% | 95.24% | 1.59% | 0% | |
| Al. ob. mating call | 1.19% | 0.24% | 98.33% | 0.24% | |
| Al. ob. distress call | 0% | 0% | 0% | 100% | |
| SNS | SPC | PRC | NPV | ACC | F1 | GM | MCCn | BMn | MKn | |
|---|---|---|---|---|---|---|---|---|---|---|
| Count-kNN | 89.64% | 97.57% | 95.97% | 97.90% | 94.35% | 92.01% | 93.11% | 95.23% | 93.60% | 96.93% |
| Count-DecTr | 82.51% | 96.69% | 95.30% | 97.36% | 92.40% | 86.15% | 88.04% | 93.60% | 89.60% | 96.33% |
| MinDis-DecTr | 97.51% | 99.12% | 92.60% | 98.88% | 97.35% | 94.88% | 98.30% | 97.75% | 98.31% | 95.74% |
| Classifier | Statistic | SNS | SPC | PRC | NPV | ACC | F1 | GM | MCCn | BMn | MKn |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MinDis-DecTr vs. Count-kNN | Mean | 5.98 | 1.26 | −0.92 | 0.89 | 2.59 | 3.34 | 1.08 | 2.15 | 3.62 | −0.02 |
| Conf. Int. | ±3.56 | ±0.79 | ±3.06 | ±0.79 | ±1.96 | ±3.15 | ±2.4 | ±1.65 | ±2.06 | ±1.8 | |
| Pr. Outperf. | 99.9 | 99.9 | 28.2 | 99.1 | 99.9 | 98.6 | 99.9 | 99.9 | 99.9 | 48.2 | |
| MinDis-DecTr vs. Count-DecTr | Mean | 12.98 | 2.15 | −0.24 | 1.44 | 4.59 | 9.15 | 9.11 | 3.81 | 7.57 | 0.6 |
| Conf. Int. | ±4.54 | ±0.84 | ±2.96 | ±0.79 | ±2.16 | ±4.04 | ±3.13 | ±1.7 | ±2.53 | ±1.83 | |
| Pr. Outperf. | 100 | 100 | 42.4 | 100 | 100 | 100 | 100 | 100 | 100 | 74.9 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luque, A.; Romero-Lemos, J.; Carrasco, A.; Barbancho, J. Improving Classification Algorithms by Considering Score Series in Wireless Acoustic Sensor Networks. Sensors 2018, 18, 2465. https://doi.org/10.3390/s18082465
Luque A, Romero-Lemos J, Carrasco A, Barbancho J. Improving Classification Algorithms by Considering Score Series in Wireless Acoustic Sensor Networks. Sensors. 2018; 18(8):2465. https://doi.org/10.3390/s18082465
Chicago/Turabian StyleLuque, Amalia, Javier Romero-Lemos, Alejandro Carrasco, and Julio Barbancho. 2018. "Improving Classification Algorithms by Considering Score Series in Wireless Acoustic Sensor Networks" Sensors 18, no. 8: 2465. https://doi.org/10.3390/s18082465
APA StyleLuque, A., Romero-Lemos, J., Carrasco, A., & Barbancho, J. (2018). Improving Classification Algorithms by Considering Score Series in Wireless Acoustic Sensor Networks. Sensors, 18(8), 2465. https://doi.org/10.3390/s18082465