1. Introduction
Accommodating massive connectivity for machine-type communications is considered one of the crucial goals of future fifth generation (5G) cellular systems. Nonorthogonal multiple access (NOMA), which enables a group of smart terminals (STs) (e.g., the Internet of Things devices) to share the same frequency channel simultaneously and further utilizes successive interference cancellation (SIC) to reduce the co-channel interference, has provided a promising solution towards achieving this important goal [
1,
2,
3,
4]. Compared with conventional orthogonal multiple access (OMA), which allocates orthogonal resource blocks to smart terminals and thus suffers from the limited number of available resource blocks, NOMA has been envisioned to facilitate massive connectivity for a large number of STs’ data deliveries in a spectrum-efficient manner. Meanwhile, NOMA also plays a vital role in enabling ultra-high throughput and low-latency transmission in 5G systems.
However, due to allowing co-channel interference, reaping the benefits of NOMA necessitates careful resource management which has thus motivated significant research effort in recent years. Many studies have been devoted to investigating the power allocation for NOMA. In reference [
5], Zhu et al. investigated the optimal power allocation with a given channel assignment under different performance criteria (e.g., the max-min fairness and the weighted sum rate maximization). In reference [
6], a two-user power allocation scheme was proposed to maximize the sum rate within Quality of Service (QoS) constraints. Driven by the growing demand for green communication [
7,
8,
9,
10], in reference [
11], Zhang et al. proposed a power allocation scheme for maximizing the energy efficiency with QoS constraints for users. In addition to power allocation alone, many studies have investigated joint power allocation and channel allocation for NOMA [
12,
13,
14]. For instance, in reference [
12], Lei et al. proposed joint optimization of channel allocation and power allocation for downlink NOMA for maximizing the total throughput. In reference [
13], Fang et al. jointly optimized the subchannel assignment and power allocation to maximize the energy efficiency for the downlink NOMA network. In reference [
14], joint sub-channel allocation, power allocation and user scheduling for downlink NOMA throughput maximization was proposed.
Meanwhile, exploiting NOMA for different paradigms and applications has also attracted lots of interest [
15,
16,
17,
18,
19]. For instance, in [
15], Elbamby et al. studied resource allocation for the in-band full duplex-enabled NOMA networks. In reference [
16], Sun et al. studied the MIMO NOMA system to improve energy efficiency. In reference [
17], Wu et al. studied the optimal power allocation and traffic scheduling for relay-assisted networks via NOMA transmission. In reference [
18], NOMA-enabled mobile edge computing was proposed for 5G systems. In reference [
19], energy-efficient NOMA-enabled traffic offloading via dual-connectivity was proposed. Recently, there has been a growing interest in exploiting NOMA for IoT applications [
20,
21,
22]. For instance, in reference [
20], Shirvanimoghaddam et al. discussed the exploitation of a massive NOMA technique as a solution to support a massive number of IoT devices in cellular networks and identified its challenges. In reference [
21], by exploiting the NOMA transmission, Mostafa et al. proposed a joint subcarrier and transmission power allocation problem to maximize the number of served IoT devices while satisfying the quality of service and transmission power requirements.
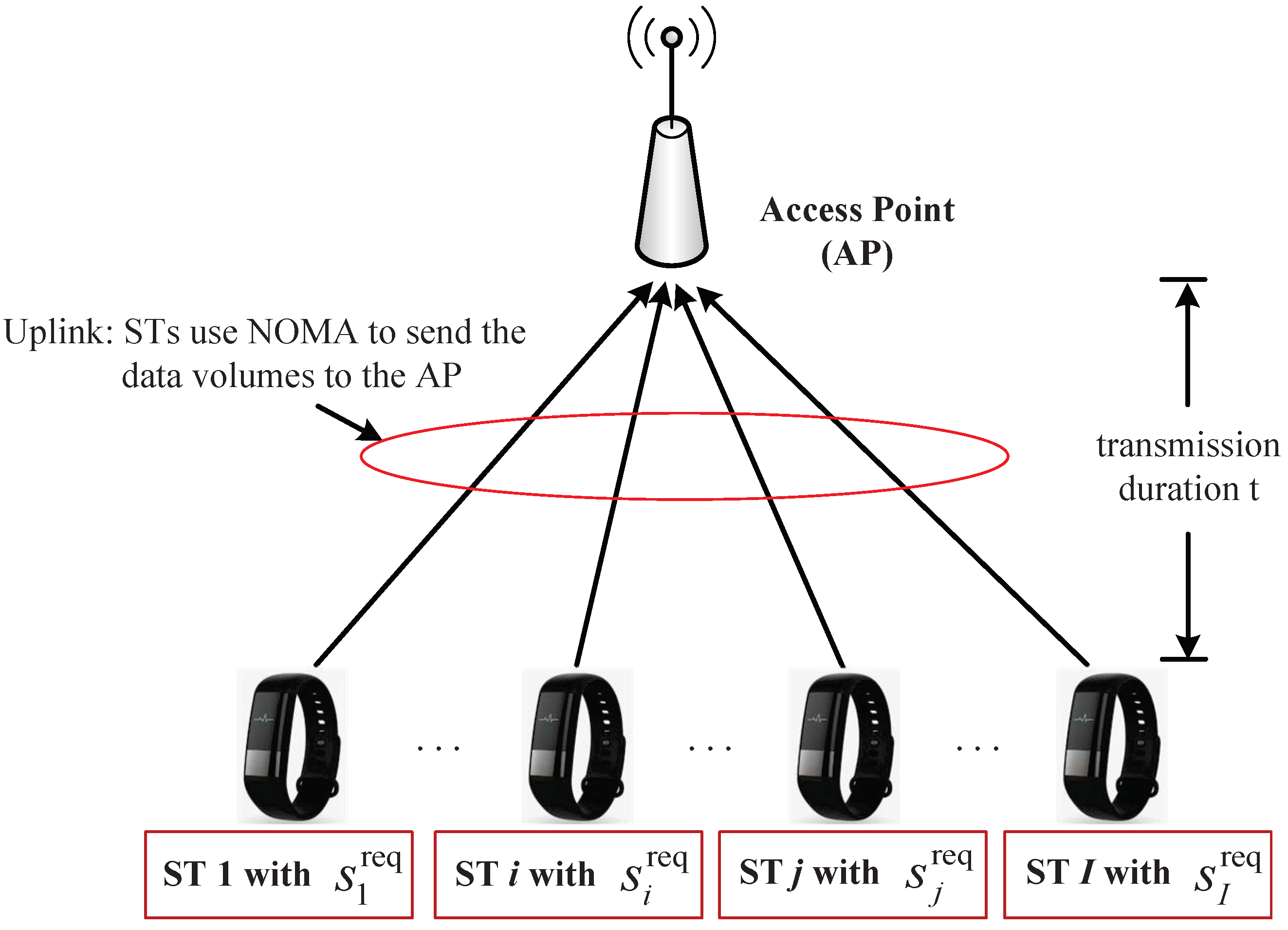
In this work, we consider that a group of smart terminals (e.g., sensors) are monitoring the environment and using NOMA to send their collected data to an access point (AP) simultaneously (e.g., the real-time data collection from smart meters in the emerging smart grids [
23]). Our detailed contributions can be summarized as follows:
Taking into account the different data delivery requirements of the smart terminals (STs) and their respective channel power gains to the AP, we formulate joint optimization of the SIC decoding-order for the channel-usage time and power allocations for the STs (according to [
2,
3] and Chapter 6 in [
24], an arbitrary SIC decoding-order is viable for the uplink NOMA transmission. However, different SIC decoding-orders will yield different throughputs and power consumption levels for different STs). Our objective is to minimize the total cost for resource consumption, which includes the channel usage and the total energy consumption of all STs, for finishing all STs’ data delivery requirements.
Despite the non-convexity of the formulated joint optimization, we propose an efficient algorithm to compute the optimal solution. Specifically, we exploit the layered structure of the problem and firstly solve the optimal time and power allocation under a given SIC decoding-order. In particular, after executing a series of equivalent transformations, we identify the convexity of the subproblem regarding the joint time and power allocations and thus find the corresponding optimal solution efficiently. By exploiting the optimal time and power allocations under each given SIC decoding-order, we further propose an efficient iterative algorithm to find the optimal SIC decoding-order.
Extensive numerical evaluations are presented to verify the effectiveness of our proposed algorithms. Meanwhile, we also present the results of a validation of the advantages of our proposed optimal NOMA-enabled data collection scheme in comparison with using the conventional orthogonal multiple access scheme.
The reminder of this paper is organized as follows.
Section 2 illustrates the system model and problem formulation. In
Section 3, we propose an algorithm to find the optimal time and power allocations under a given decoding-order. In
Section 4, we further propose an algorithm to find the optimal decoding-order. Finally, we conclude this work in
Section 5.
3. Proposed Algorithm to Solve Problem (P1-m)
In this section, we propose an efficient algorithm to solve Problem (P1-
m), which thus yields the minimum total cost under the given decoding-order,
. To efficiently solve this problem, we introduce a variable-change as
Notice that we do not use the script
m in (
9) since
x is treated as an internal variable which can be used for an arbitrary decoding-order,
.
Using (
9), we thus express ST
i’s minimum required transmit-power as
and Problem (P1-
m) was equivalently transformed into (letter “E” means “equivalent”)
For the sake of easy presentation, we define an auxiliary function,
, as
Recall that
stems from (
10).
The key idea in solving Problem (P1-
m-E) was to introduce an additional new variable,
, which required
Thus, by using
, we transform Problem (P1-
m-E) into
Notice that Problem (P2) corresponds to finding the optimal value of
(which is denoted by
) that can meet constraints (
15)–(
17). The value of
is the minimum cost of Problem (P1-
m-E) under the
m-th decoding-order.
The rationale to solve Problem (P2) (as well as the original Problem (P1-
m-E)) and to determine
is as follows. First of all, let us denote a parameterized subproblem (P2) under a given temporal value of
:
We use
to denote the optimal objective function value of Problem (P2-Sub). In particular, if Problem (P2-Sub) output
, then Problem (P2) is feasible under the currently given
(which means that
can be reduced further). On the other hand, if Problem (P2-Sub) output
, then Problem (P2) is infeasible under the current
(which means that we need to increase
). To solve the original Problem (P2), we need to further find the minimum value of
(i.e.,
) that would be able to yield the corresponding
, i.e., we need to solve the following problem
It can be seen from Problem (P2-Sub) that the optimal output, , decreases in due to the following reasons: (i) the objective function decreases in , and (ii) the feasible interval increases in . As a result, we exploit a bisection search to solve Problem (P2-Top) and find the corresponding . We present the details of our proposed algorithm in the next subsections.
Recall that we can determine the minimum total cost for resource consumption of Problem (P1Sub-
m) as
under the given decoding-order,
.
In the next subsection, we focus on proposing an algorithm to solve Problem (P2-Sub) under a given .
3.1. Proposed Subroutine to Solve Problem (P2-Sub)
To solve Problem (P2-Sub) under a given
, we firstly compute the first-order derivative of
as follows:
Equation (
26) shows that
increases in
x. Based on the theory of convex optimization [
25],
is convex with respect to
x.
For the sake of easy presentation, we further introduce
to denote the objective function of Problem (P2-Sub) as follows:
and correspondingly, we obtain the first-order derivative of
as follows:
which, again, increases in
x (due to
is increasing in
x). As a result,
is convex with respect to
x.
Based on the convexity of function and function , we obtain the following important property.
Proposition 1. Given θ, Problem (P2-Sub) is a strict convex optimization with respect to x.
Proof. Equations (
22) and (
24) together lead to the objective function of Problem (P2-Sub), i.e.,
, is a strictly convex function. Meanwhile, Equation (
22) means that constraint (
18) leads to a convex feasible set. As a result, according the convex optimization theory [
25], Problem (P2-Sub) is a strictly convex optimization with respect to
x, which finishes the proof. ☐
The convexity of Problem (P2-Sub) enables us to use the Karush–Kuhn–Tucker (KKT) conditions to find the optimal solution. Exploiting the KKT conditions, the following algorithm was proposed to solve Problem (P2-Sub). The details are illustrated as follows.
3.1.1. Procedures to Determine the Viable Interval of x for Problem (P2-Sub)
Our first step was to determine the feasible interval of
x for Problem (P2-Sub), i.e., the interval of
x that could meet constraints (
18) and (
19) simultaneously.
To derive the upper-bound of
x given by constraint (
18), we notice that constraint (
18) could be separated with respect to different STs. As a result, we express the upper-bound of
x as
with the value of
given by
Specifically, function
is given by
according to constraint (
18). For each ST
i,
corresponds to the largest value of
x that can ensure
(or constraint (
18) is satisfied).
To find
, we derive the first-order derivative of
as follows:
The above result shows that decreases in x. In other words, for each ST i, function is a typical unimodal function. By exploiting this property and an important feature of , we consider the following two cases to find :
Case-I. If (i.e., ), then .
Case-II. If (i.e., ), then can be uniquely determined by , where the value of is uniquely determined by .
We explain the above two cases as follows. If
, then
monotonically decreases for
. In this case, based on the features of
, we have
(i.e., Case-I). On the other hand, if
, then a unique point exists in the interval of
, such that
, since function
is decreasing and we have
according to (
28). Let us denote such a point as
, i.e.,
. Notice that, since we have
,
always exists. As a result, a unique point exists in the interval of
, such that
. Such a point corresponds to
, i.e.,
, which corresponds to the solution in Case-II.
The detailed procedures to find
are shown in Steps 3–8 in our following proposed algorithm (i.e., Algorithm 1) to solve Problem (P2-Sub). After finding
for each ST
i, thus determined the viable interval for
x as
according to constraint (
19) which corresponds to Step 12 in our Algorithm 1.
3.1.2. Procedures to Determine for Problem (P2-Sub)
After deriving the viable interval
, we then continue to solve Problem (P2-Sub) and obtain
. To this end, we exploit the convexity of function
(i.e., its first order derivative
in (
24) is decreasing), and used the KKT conditions to find the minimum value of the objective function, i.e.,
. To this end, we need to consider the following two cases:
If , then a unique point, , exists such that .
If , no such exists such that , meaning that is increasing for .
Step 16 to Step 30 in our Algorithm 1 correspond to the operations of the above two cases.
| Algorithm 1 To solve Problem (P2-Sub) and output . |
- 1:
Initialization: Set , and set a sufficiently large upper-bound for the value of x. - 2:
whiledo - 3:
if then - 4:
Firstly, use the bisection-search method to find , such that . - 5:
Secondly, use the bisection-search method to find such that . - 6:
else - 7:
Set . - 8:
end if - 9:
Update . - 10:
end while - 11:
ifthen - 12:
Set the viable interval for x as . - 13:
else - 14:
Output that Problem (P2-Sub) is infeasible. - 15:
end if - 16:
ifthen - 17:
Use the bisection-search to find such that . - 18:
if then - 19:
Set . - 20:
else - 21:
if then - 22:
Set . - 23:
else - 24:
Set . - 25:
end if - 26:
end if - 27:
else - 28:
Set . - 29:
end if - 30:
. - 31:
Output: and .
|
Until now, we have proposed Algorithm 1 that solves Problem (P2-Sub) and obtained the value of for the given value of .
3.2. Proposed Algorithm to Solve Problem (P2-Top)
After obtaining
for the given
, we continue to solve the original Problem (P2-Top), i.e., finding the minimum value of
(which is denoted by
) such that
. As we have explained before,
decreases in
, which thus enabled us to use the bisection search method to find
[
26]. The details are shown in our proposed Algorithm 2.
In our Algorithm 2, for the currently given , we invoke Algorithm 1 (as a subroutine) to obtain the value of (i.e., Step 4). If , and then we use the bisection method to further reduce (i.e., Step 6). Otherwise (), we use the bisection method to increase (i.e., Step 8). The operations of the bisection search continued until we reach convergence.
| Algorithm 2 To solve Problem (P2-Top) and find . |
- 1:
Initialization: Set as a sufficiently large number and . Set the tolerable computation error, . - 2:
whiledo - 3:
Set . - 4:
Given , use Algorithm 1 to obtain . - 5:
if then - 6:
Set . - 7:
else - 8:
Set . - 9:
end if - 10:
end while - 11:
Set - 12:
Given , use Algorithm 1 to obtain . - 13:
Output: .
|
Until now, we have proposed the Algorithm 2 that solves Problem (P2-Top) and obtained the optimal value of
. Notice that based on (
21), the minimum total cost for resource consumption
is obtained for the
m-th decoding-order,
, which thus solves the original Problem (P1-
m).
3.3. Numerical Results for Algorithms 1 and 2 to Solve Problem (P1-m)
In this subsection, we firstly evaluate the performance of our proposed Algorithms 1 and 2 to solve Problem (P1-
m). To this end, we set up a scenario in which the AP is located at (0 m , 0 m), and the group of STs are uniformly distributed within a plane whose central is the AP and the radius is 100 m. We use the same method used by reference [
27] to model the channel power gains from the STs to the AP. We set each ST’s energy budget as
J, and we set
= 1 sec. For simplicity, we set the cost coefficients as
and
. Other parameter settings will be provided when needed.
To test the performance of our proposed Algorithm 2 (and Algorithm 1), we use a fixed decoding-order for the STs , i.e., the STs executed the SIC according to descent order of the channel power gains . Here, we emphasize that Algorithms 1 and 2 are applicable to an arbitrary decoding-order of the STs. In the next section, we further show the performance of our proposed Algorithm 2 (and Algorithm 1) for different decoding-orders.
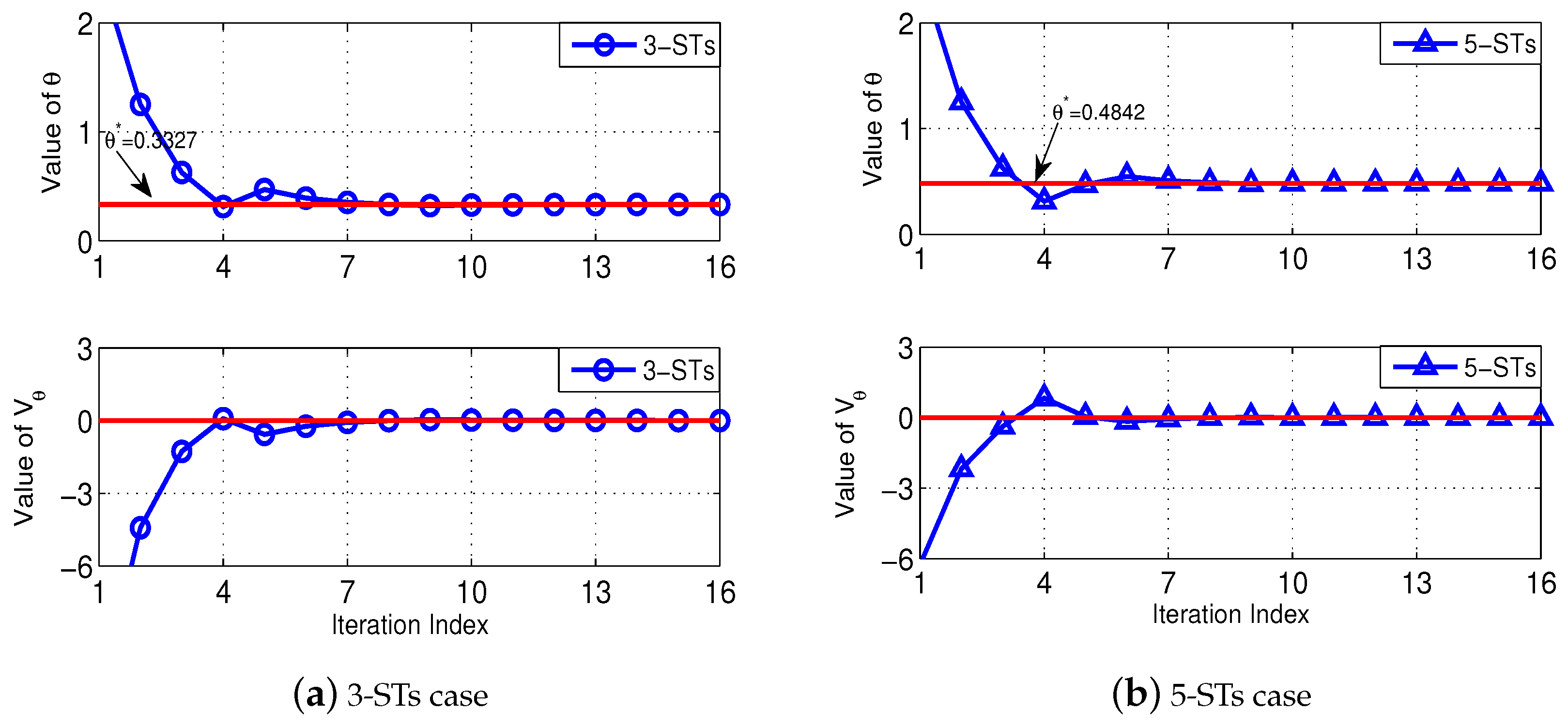
Figure 3 illustrates the rationale of our Algorithm 2 to solve Problem (P2-Top). Specifically, we test two cases, i.e., a 3-ST case and a 5-ST case. In both cases, the locations and channel power gains of the STs are generated as described before, and we set each ST’s
to be uniformly distributed within
Mbits, and we use a channel bandwidth of
MHz. In both
Figure 3a,b, the top-subplots show the convergence of
when executing the Algorithm 2, and the bottom-subplots show the corresponding convergence of
. As illustrated before, Algorithm 2 essentially executes a bisection search on
, with the objective of finding the minimum value of
such that
. Therefore, we observe from the bottom-subplots that the value of
gradually converges to zero (as indicated by the red-solid line), and correspondingly, in the top-subplots we observe that the value of
converges to
(i.e., the minimum total cost) when
is approaching zero.
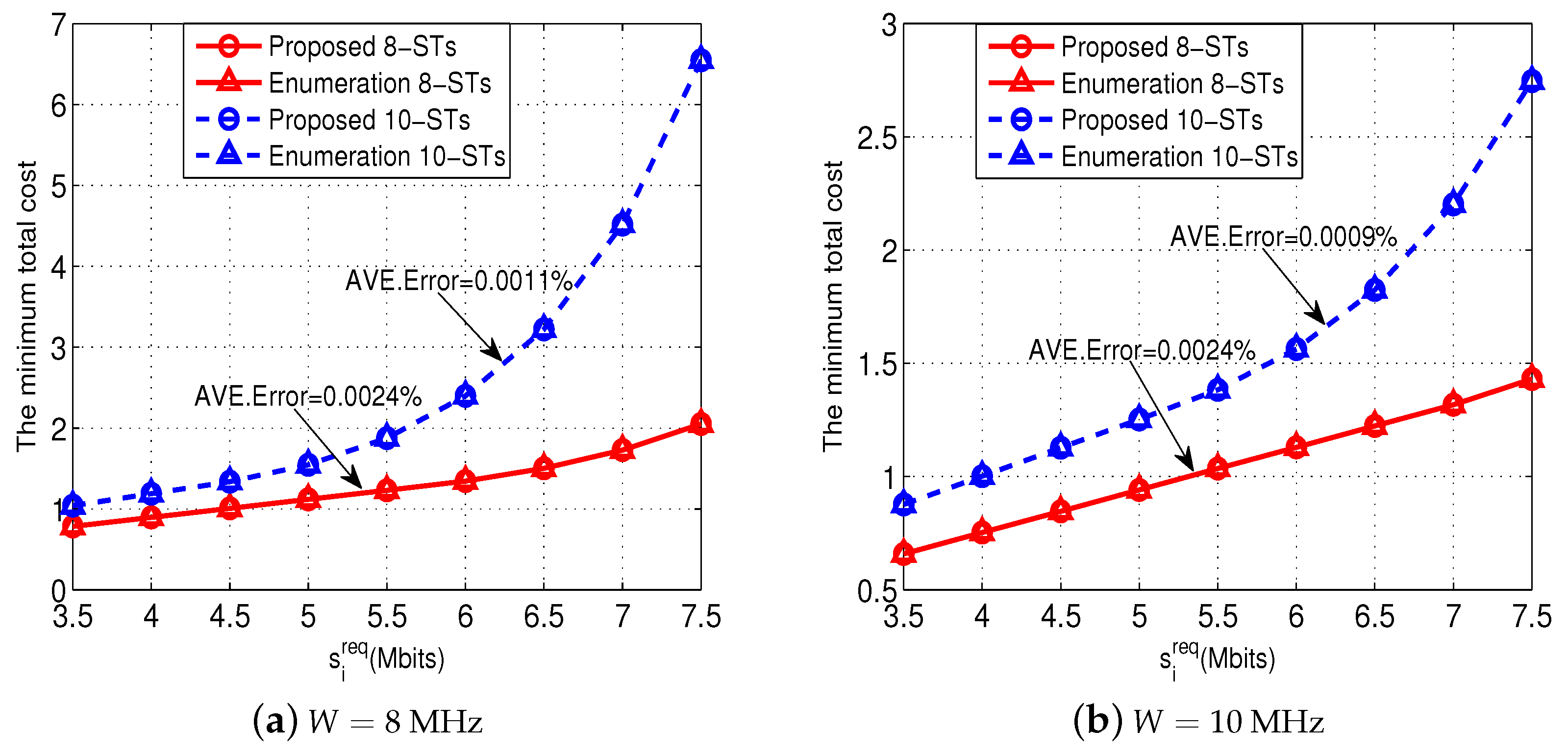
Figure 4 shows the effectiveness of our proposed Algorithms 1 and 2 to solve Problem (P1-
m). For the purpose of comparison, we use an enumeration method to solve Problem (P1-
m) directly and obtain the minimum total cost as a benchmark.
Figure 4a shows the comparison when
MHz, and
Figure 4b shows the comparison when
MHz. Notice that in both the 8-ST and 10-ST cases, the locations and the channel power gains of the STs are randomly generated. All the results show that our Algorithm 2 achieves the minimum total costs which are very close to those obtained by the enumeration method (with almost negligible error). These results validate the effectiveness of our proposed Algorithms 1 and 2.
4. Proposed Algorithm to Find Optimal Decoding-Order
In
Section 3 before, we solve Problem (P1-
m) and obtained the minimum total cost,
, for the
m-th decoding-order
. We next continue to solve Problem (P1-Order) in Equation (
9) to find the optimal decoding-order which yields the globally minimum cost, i.e.,
.
As we have described before, a benchmark approach to find the optimal decoding-order was done to enumerate all the possible decoding-orders
for
(e.g., enumerating the six decoding-orders for the 3-ST as shown in
Figure 2). However, enumerating all the decoding-orders is computational-prohibited, especially when the number of STs is large. For instance, for the case of 11 STs, the total number of the decoding-orders is larger than 39 million.
To tackle this difficulty, we propose a computation-efficient algorithm (i.e., Algorithm 3) to find the optimal decoding-order. Our Algorithm 3 works as follows.
We first initialize the currently available STs as and the current best decoding-order (i.e., CBS) as .
In each round of iteration, we select one ST in and determine its index in the current best decoding-order CBS, with the objective of minimizing the total cost for resource utilization after including this selected ST into CBS. To this end, we enumerate the currently available STs in . For each selected ST (let us say ST m, i.e., the m-th ST in ), we further enumerate all the possible indexes for decoding based on CBS. Specifically, if , it means that we place ST m in front of the first ST in CBS. If , it means that we place ST m after the h-th ST in CBS. Otherwise, it means that we place ST m between the h-th ST in CBS and the -th ST in CBS.
Given the currently constructed decoding-order , we use our proposed Algorithm 2 to compute the minimum total cost for resource utilization denoted by . If (where CBV denotes the currently minimum total cost when enumerating the STs in and the possible indices based on CBS), then we update and record the current best decoding-order . Finally, we update , and then continue the next round of iteration.
Notice that for the sake of easy presentation, in Algorithm 3, we use to denote the cardinality of set , and use to denote the m-th element in set , and use to denote the subset of , i.e., from the m-th element to the n-th element in .
Figure 5 provides an illustrative example when executing our proposed Algorithm 3. Specifically, we consider a 5-ST case, i.e.,
. In the current iteration, shown in
Figure 5, the current best decoding-order is
and the currently available STs are
. Thus, when we enumerate the STs in
in the current round of iteration, there are three possible STs, i.e.,
,
, and
. Furthermore, when we select the first ST in
(i.e., ST 1), there are three possible indices in CBS to place the ST, which correspond to
,
, and
.
In summary, in our proposed Algorithm 3, we try to strike a balance between achieving optimality and reducing the complexity. Specifically, our proposed Algorithm 3 uses an iterative manner to determine the optimal decoding-order for the STs one-by-one. In each round of iteration, given the currently ordered subgroup of the STs (in which the decoding-orders of the STs have been determined), we optimally select a new ST from the remaining unordered STs and place this new ST into the currently ordered subgroup. To reduce the complexity, we do not change the decoding-orders of the STs in the currently ordered subgroup and aim to place the new ST at the most appropriate index such that we can achieve the minimum overall cost after including this newly selected ST into the currently ordered subgroup. Such an approach continues until we finish determining the decoding indices for all STs in
. Notice that our Algorithm 3 requires the total number of iterations to be equal to
, which is in order of
. Thus, compared with enumerating all possible
decoding-orders, our Algorithm 3 gains a significant advantage in saving the computational complexity, especially when the number of STs is large.
Table 1 in the following text verifies this advantage. Notice that since the computation complexity of our Algorithm 3 increases quadratically with the number of the STs, its computation time will become non-negligible when the number of STs is large. To address this issue, a viable approach is to jointly exploit the NOMA and TDMA; namely, we first use TDMA to divide a large number of the STs into several nonoverlapping (small) subgroups, with different subgroups using different nonoverlapping time-slots. Meanwhile, for the STs within the same subgroup, we can use our proposed Algorithm 3 to determine the optimal decoding-order efficiently.
| Algorithm 3 To find the optimal decoding-order. |
- 1:
Initialization: Set and set - 2:
whiledo - 3:
Set is a sufficiently large number. - 4:
for do - 5:
for do - 6:
Set . - 7:
if then - 8:
. - 9:
else - 10:
. - 11:
end if - 12:
Given , use Algorithm 2 to compute . - 13:
if then - 14:
Set - 15:
Set - 16:
end if - 17:
end for - 18:
end for - 19:
Update . - 20:
end while - 21:
Output: .
|
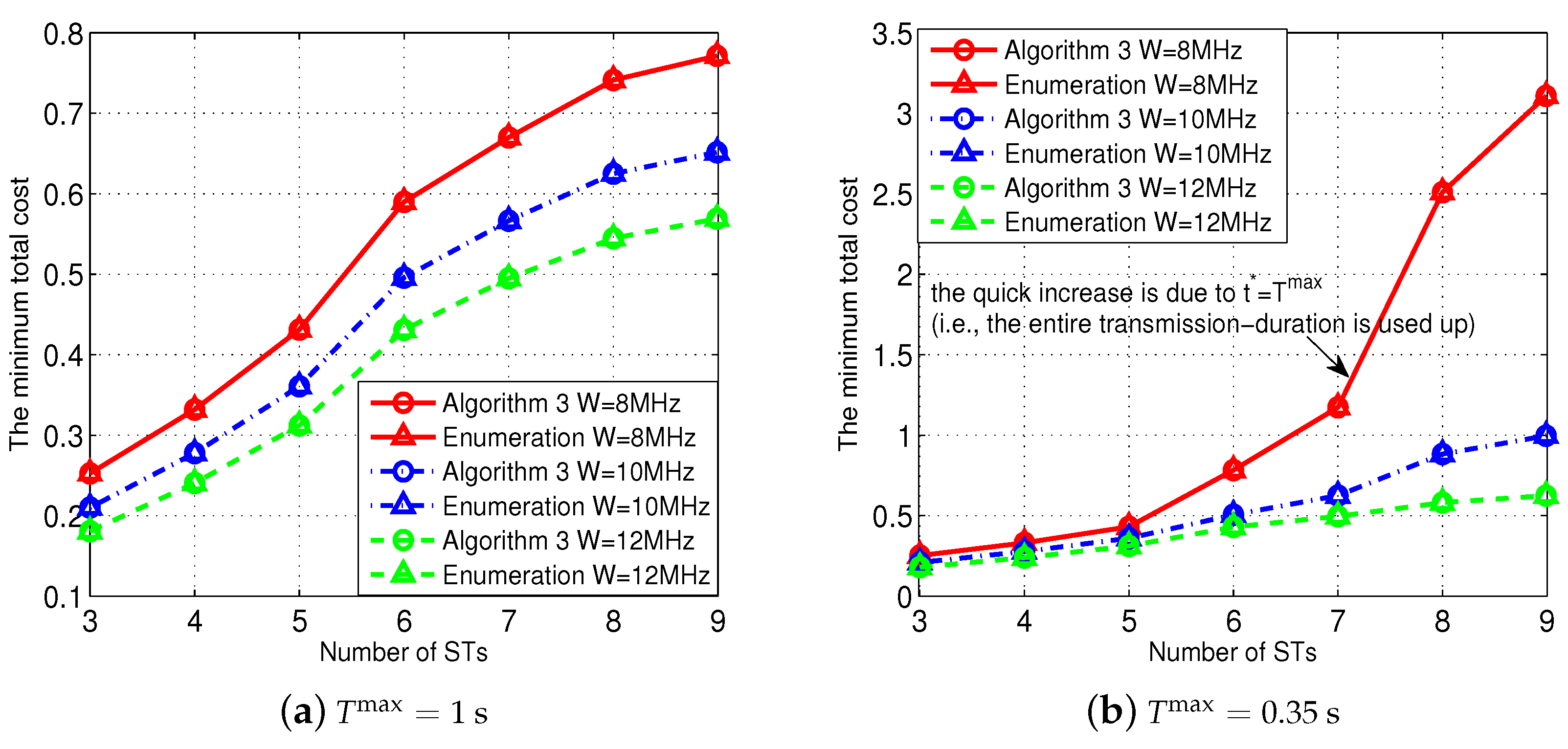
We next evaluate the effectiveness of our proposed Algorithm 3 to find the optimal decoding-order, i.e., solving Problem (P1-Order), in
Figure 6. Specifically,
Figure 6a shows the results when we set
, and
Figure 6b shows the results when we set
(meaning that there was a relatively smaller freedom in adjusting the STs’ uplink transmission-duration). As a benchmark for comparison, we enumerate all possible decoding-orders for the group of STs
. As we have explained before, each ST’s data requirement,
, was randomly generated according to a uniform distribution within
Mbits. All comparison results in
Figure 6a,b show that our Algorithm 3 can find the optimal decoding-order which is exactly same as the one obtained by the enumeration method, which thus validates the effectiveness of our proposed Algorithm 3.
To further verify the computational efficiency of our Algorithm 3, in
Table 1, we compare the computation-time used by our Algorithm 3 with the enumeration method. The results show that the computation time used by the enumeration method increases explosively when the number of the STs increases (which is due to the fact that the total number of possible decoding-orders increases explosively when the number of the STs increases). In contrast, our Algorithm 3 consumes a significantly less computation time compared with the enumeration method. In particular, when the number of the STs large (e.g., larger than 7), the computation time used by our Algorithm 3 is almost negligible compared with the enumeration method.
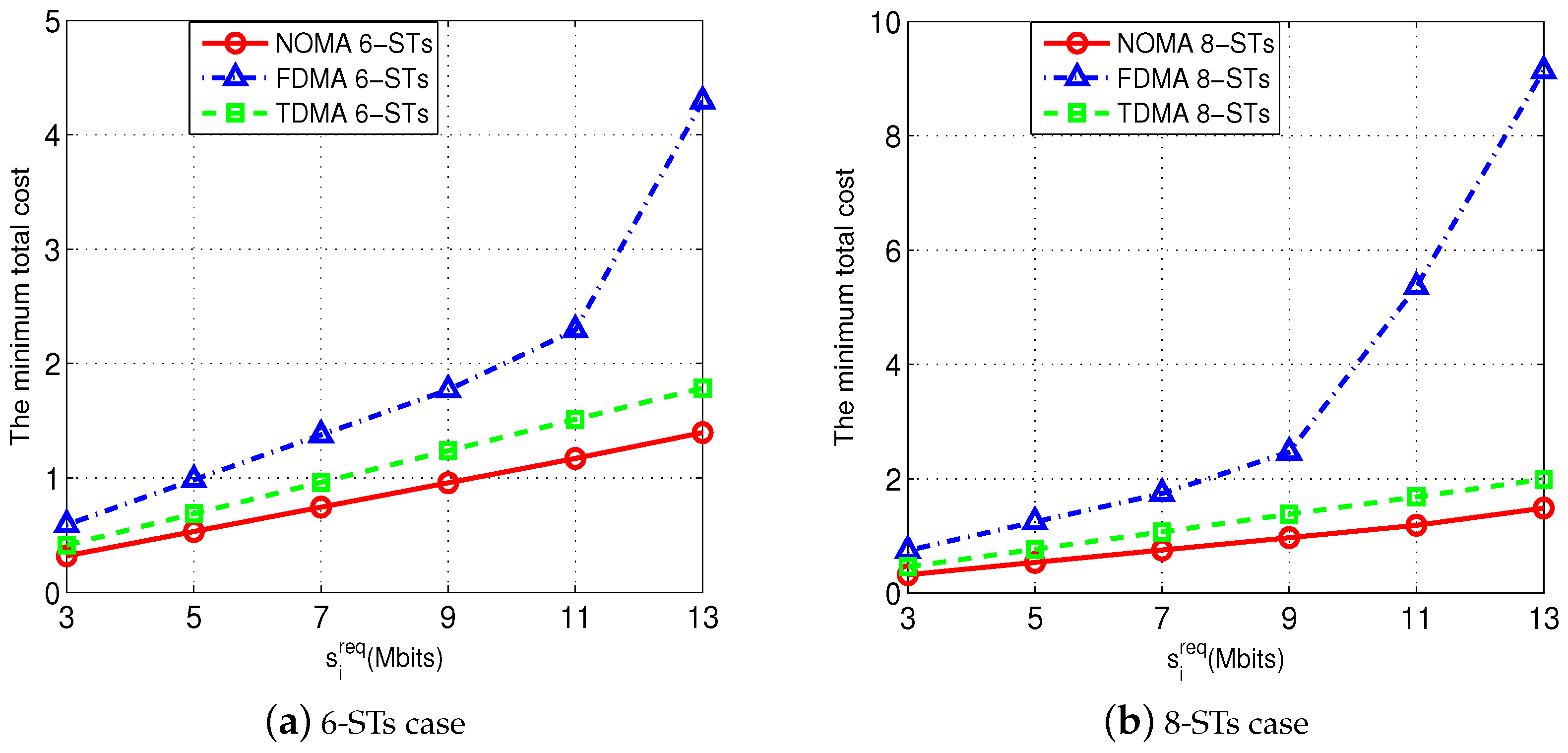
Furthermore,
Figure 7 shows the performance advantage of our proposed optimal NOMA transmission scheme in saving the total cost of resource utilization. For the purpose of comparison, we also use two other orthogonal multiple access (OMA) schemes, namely, the FDMA scheme and the TDMA scheme (notice that neither the frequency division multiple access (FDMA) scheme nor the time division multiple access (TDMA) scheme requires to order the STs). We set
MHz, and varied each ST’s
from 3 Mbits to 13 Mbits. We test two cases, namely, the 6-ST case in
Figure 7a and the 8-ST case in
Figure 7b. It is reasonable to observe that, for all the three schemes, the corresponding total costs increase when each ST
i’s
increases. Furthermore, the results show that our proposed NOMA-transmission scheme (i.e., the optimal solution obtained by our Algorithm 3) can significantly reduce the total cost, compared with the TDMA scheme and FDMA scheme.
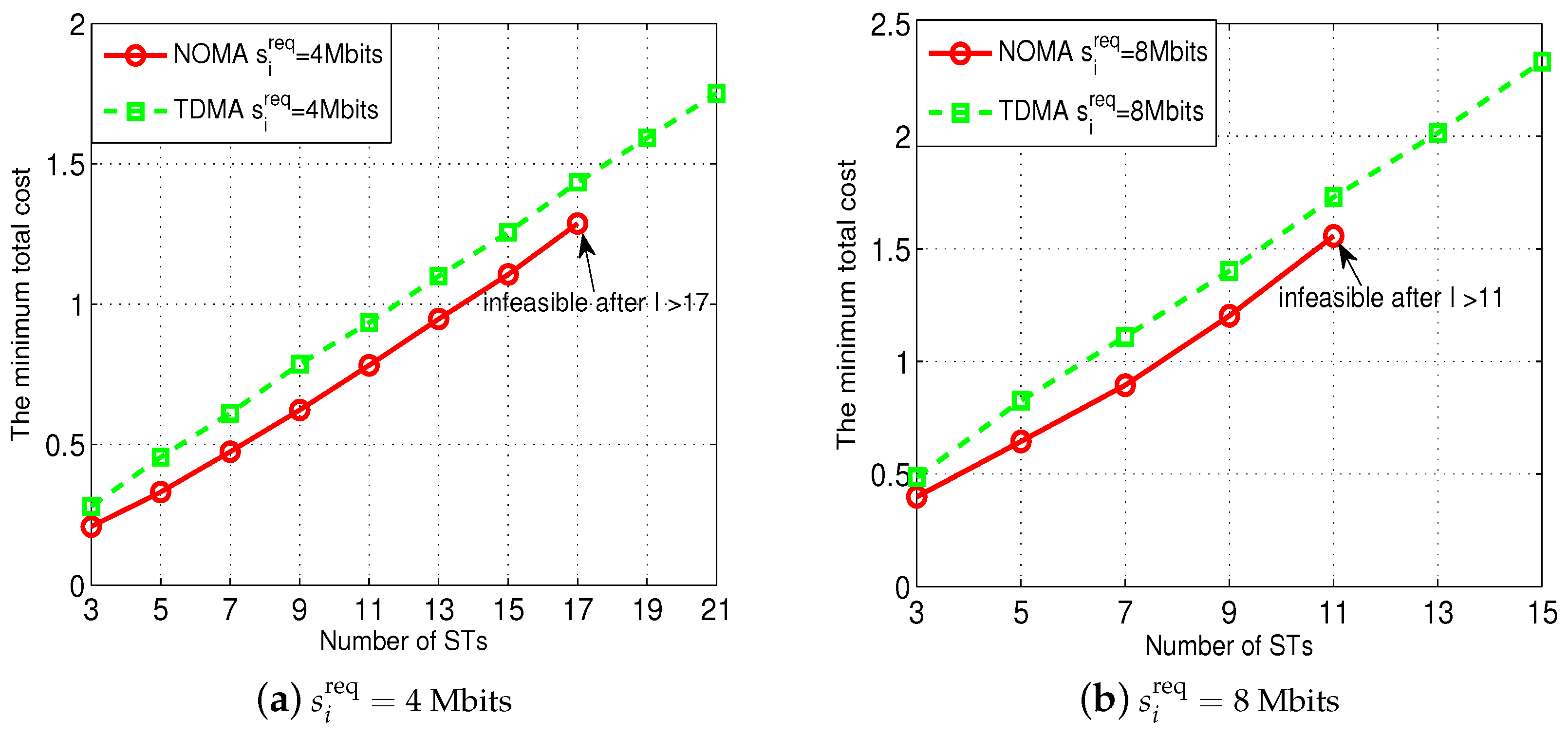
We finally show the impact of the number of the STs on the performance of our proposed NOMA transmission scheme in
Figure 8. In particular, the NOMA enables all STs to transmit to the AP simultaneously. As a result, the co-channel interference among the STs might negatively influence their throughput to the AP especially when the number of the STs is large. The results in
Figure 8 verify this intuition. Specifically, as shown in
Figure 8a (where each ST’s
Mbits) and
Figure 8b (where each ST’s
Mibts), when the number of the STs increase, the optimal total cost used by our proposed NOMA transmission scheme gradually increases and is always smaller than the cost used by the TDMA scheme. Nevertheless, as shown in
Figure 8a, our proposed NOMA transmission scheme becomes infeasible (meaning that the given
and
cannot satisfy all STs’
) when the number of the STs is larger than 17, while the TDMA scheme is always feasible.
Figure 8b shows similar infeasible results when using our NOMA transmission scheme if the number of the STs is larger than 11. Such a result essentially stems from the co-channel interference introduced by the NOMA transmission, while there is no co-channel interference in the TDMA scheme.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
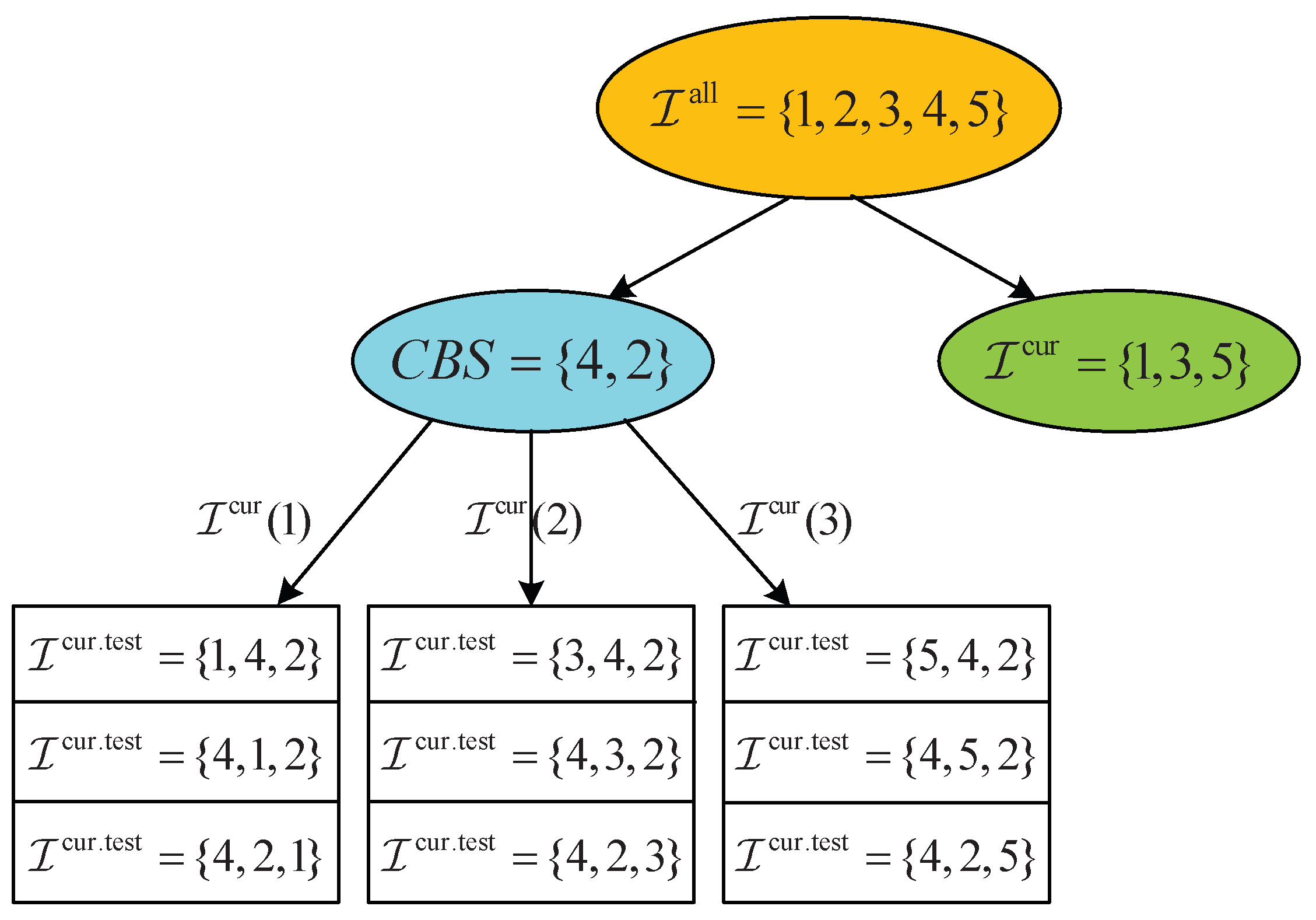{kind=link}
{kind=link}
{kind=link}
{kind=link}