Kernel Sparse Representation with Hybrid Regularization for On-Road Traffic Sensor Data Imputation



Abstract
:1. Introduction
- We perform MVs imputation in kernel-induced high-dimensional feature space instead of the original input space [29,30]. By doing so, nonlinear relationship among data samples can be discovered and leveraged for recovery performance improvement. To the best of our knowledge, this is the first work to which KSR was applied for MVs imputation.
- We propose to apply the combination of l1-norm and l2-norm, namely elastic net in statistics literature [26], as regularization on the representation coefficients, with the hope that enough information can be extracted from those highly correlated samples for recovering MVs.
- The proposed model is evaluated on both synthetic data and real-work traffic sensor data. The results demonstrate that KSR-EN outperforms other competing algorithms in terms of MVs imputation.
2. Related Work
2.1. Probabilistic Model Based Methods
2.2. Regression Model Based Methods
2.3. Matrix Completion Based Methods
3. Kernel Sparse Representation with Elastic Net Regularization
3.1. Linear and Kernel SR-EN
3.2. Optimization Algorithm
| Algorithm 1. Monotone fast iterative shrinkage thresholding algorithm for solving (3) |
| Input: Estimated data matrix , trade-off parameters , , Gaussian kernel parameter |
| Initialize |
| Output: Coefficient matrix |
| Procedure |
| Calculate kernel matrix with , , , , |
| while not converge do |
| end while |
| Algorithm 2. Gradient descent algorithm for solving (14) |
| Input: Coefficient matrix |
| Output: Estimated data matrix |
| Procedure |
| Initialize data matrix |
| while not converge do |
| Compute the derivative of w.r.t. , that is using (17) |
| Let , for any |
| Find step size with Armijo rule, that is, choose such that |
| Update |
| end while |
4. Experiments
4.1. Configuration
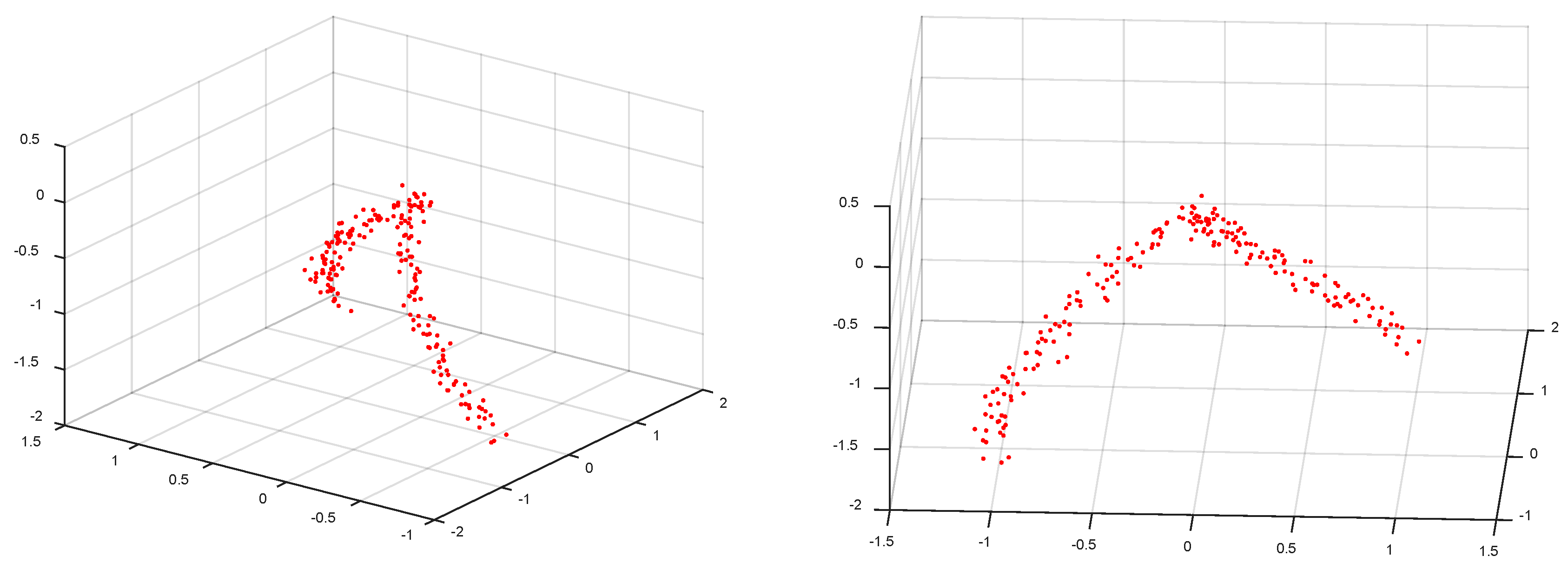
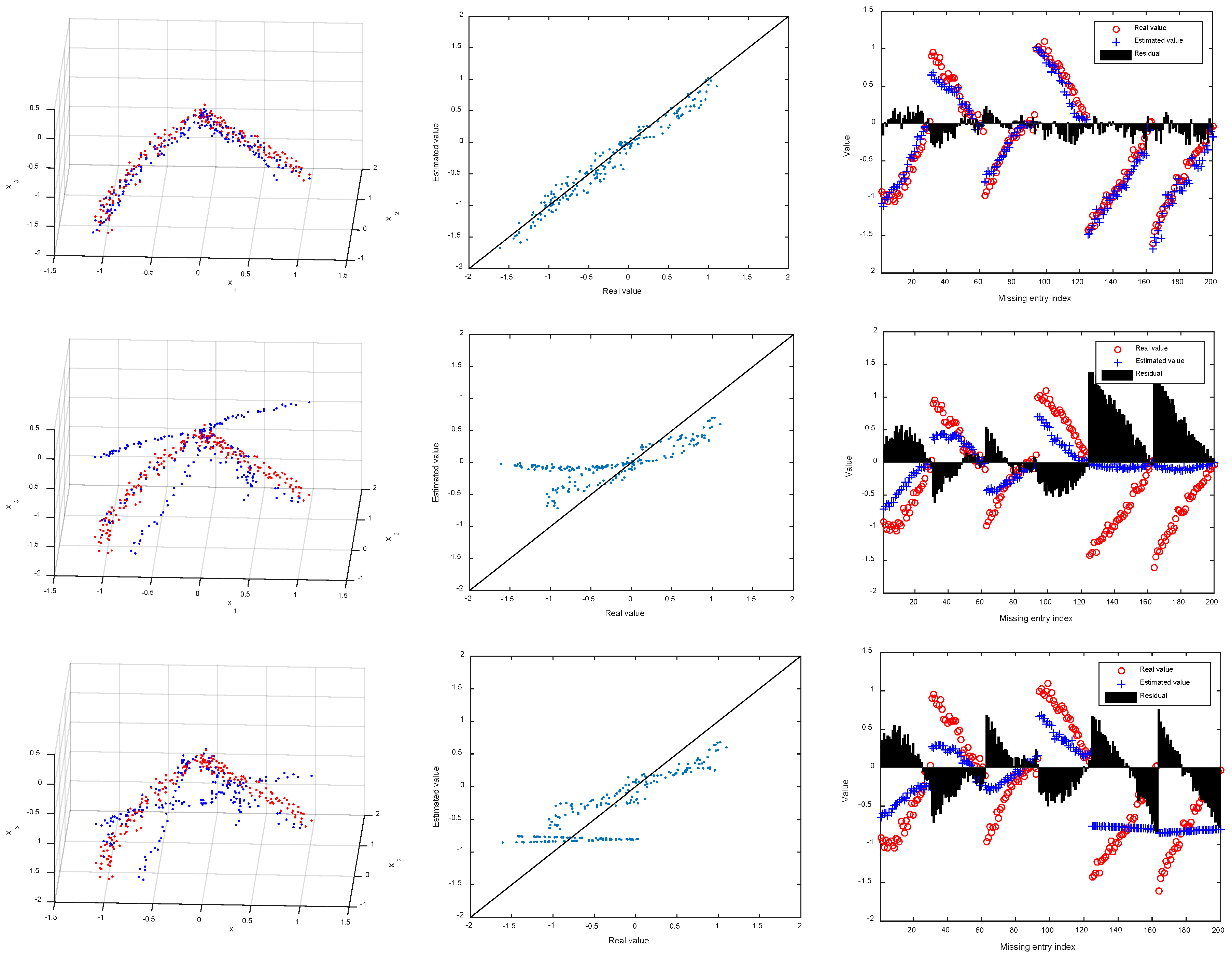
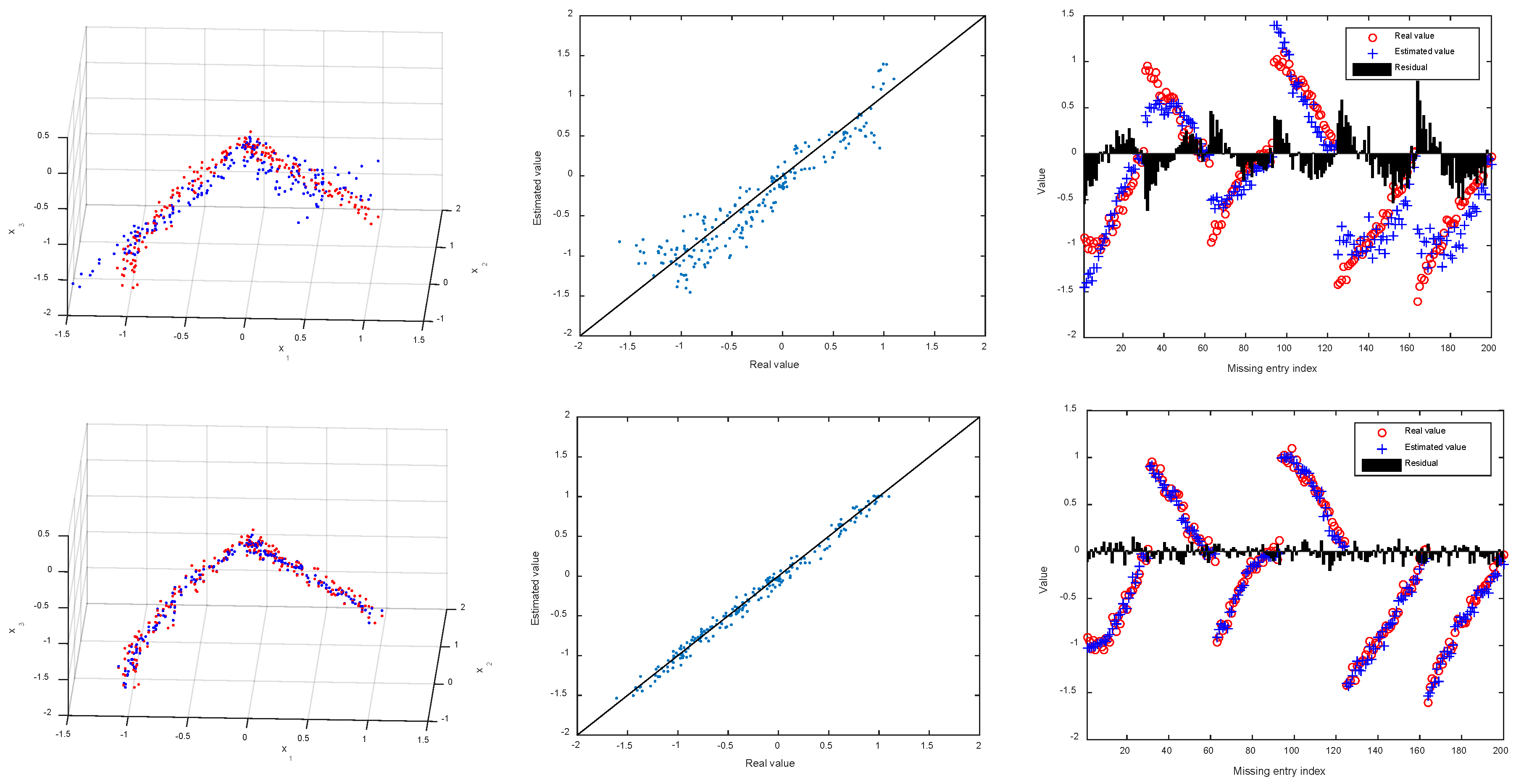
4.2. Synthetic Data
4.3. Traffic Sensor Data Imputation
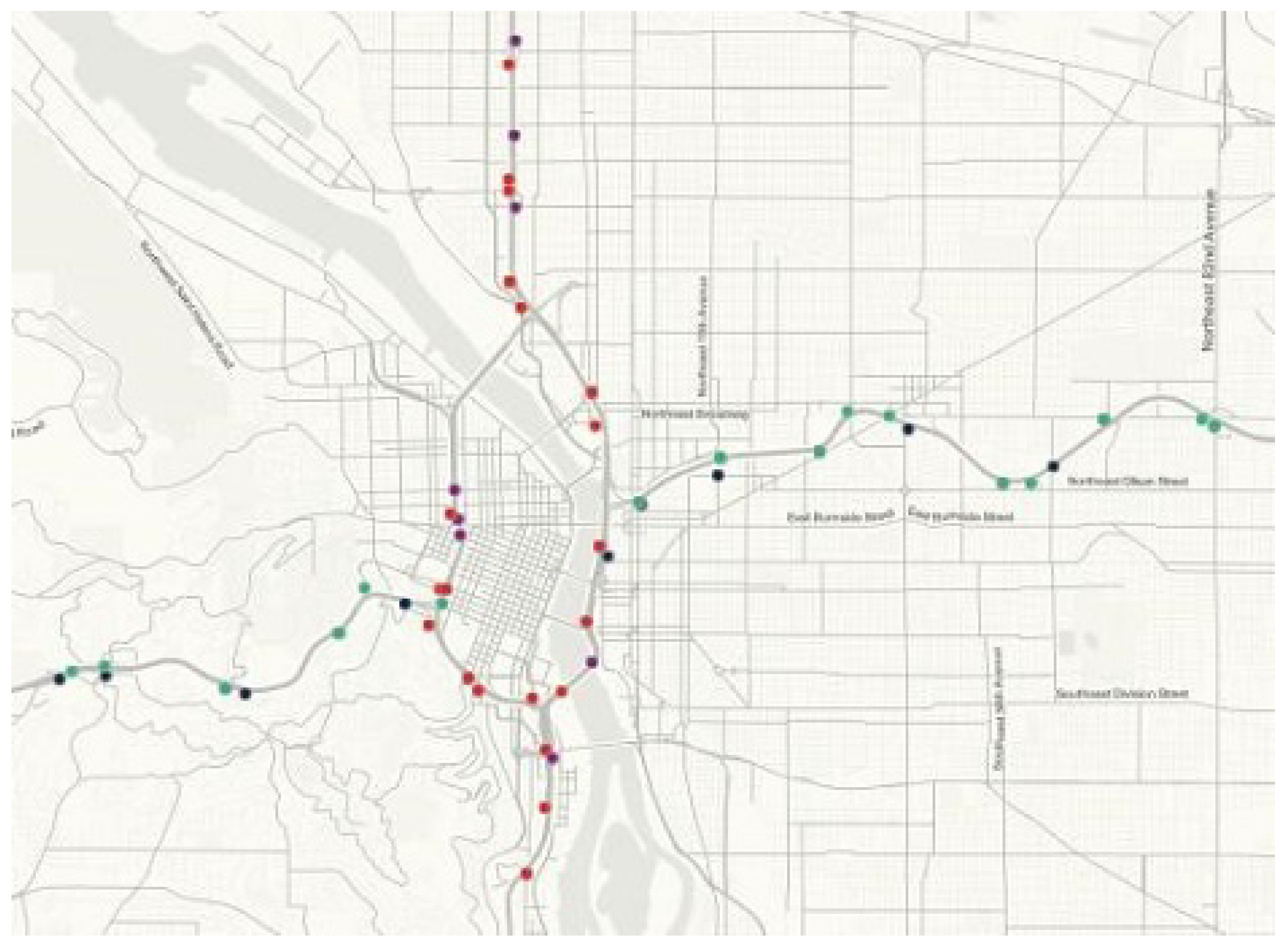
4.3.1. Data Collection
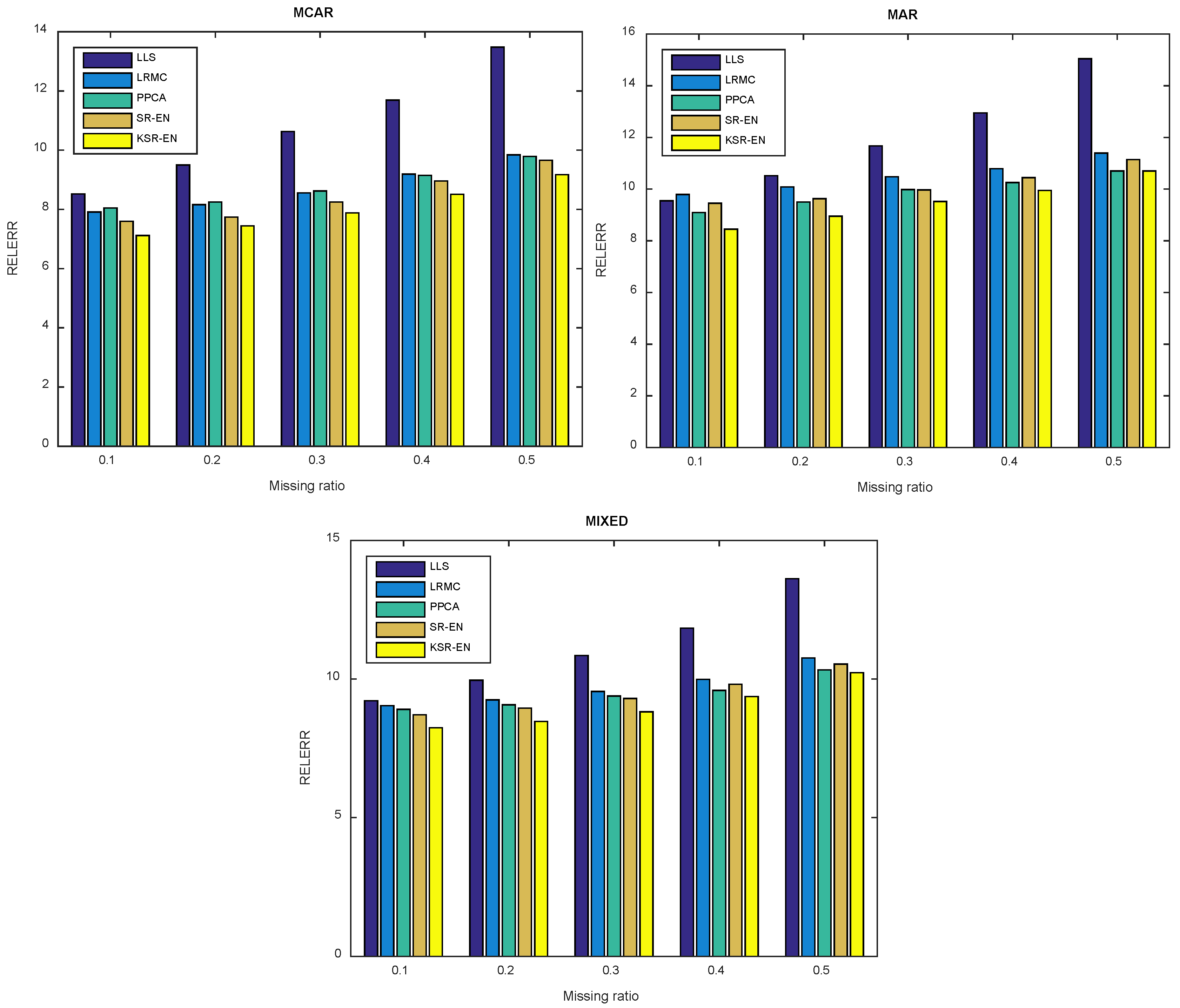
4.3.2. Imputation Error
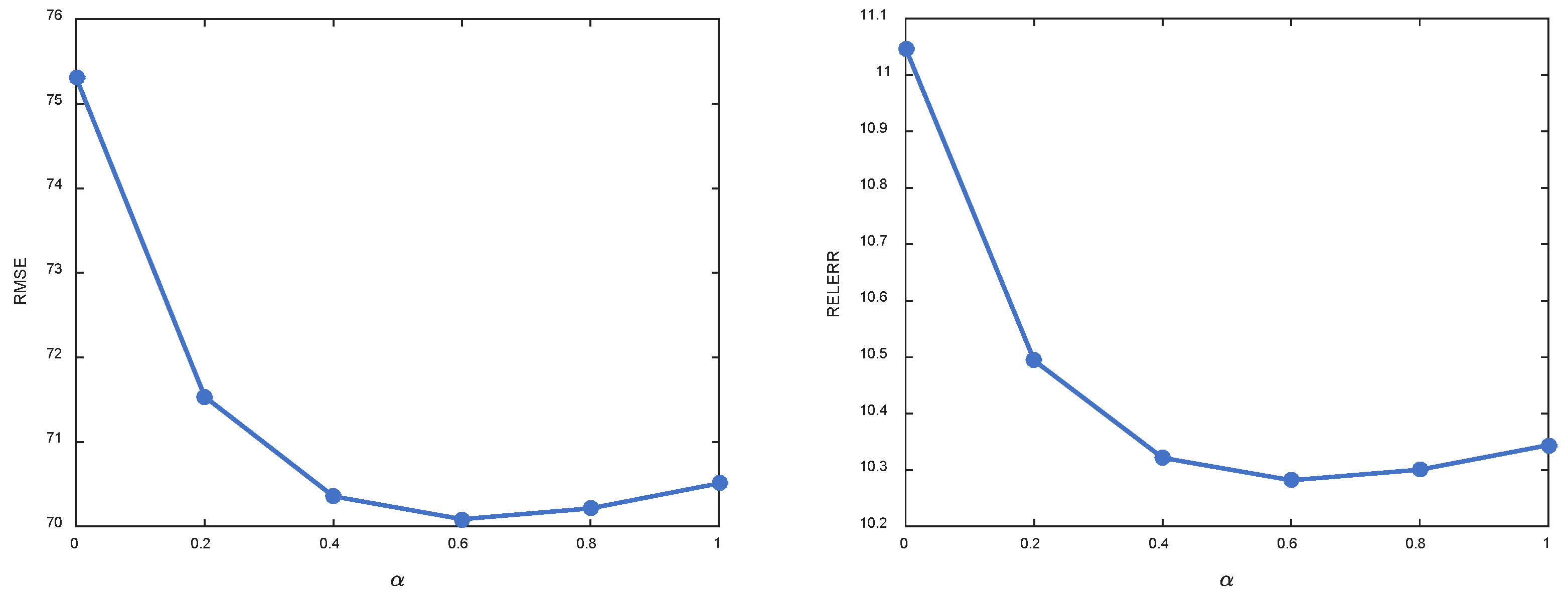
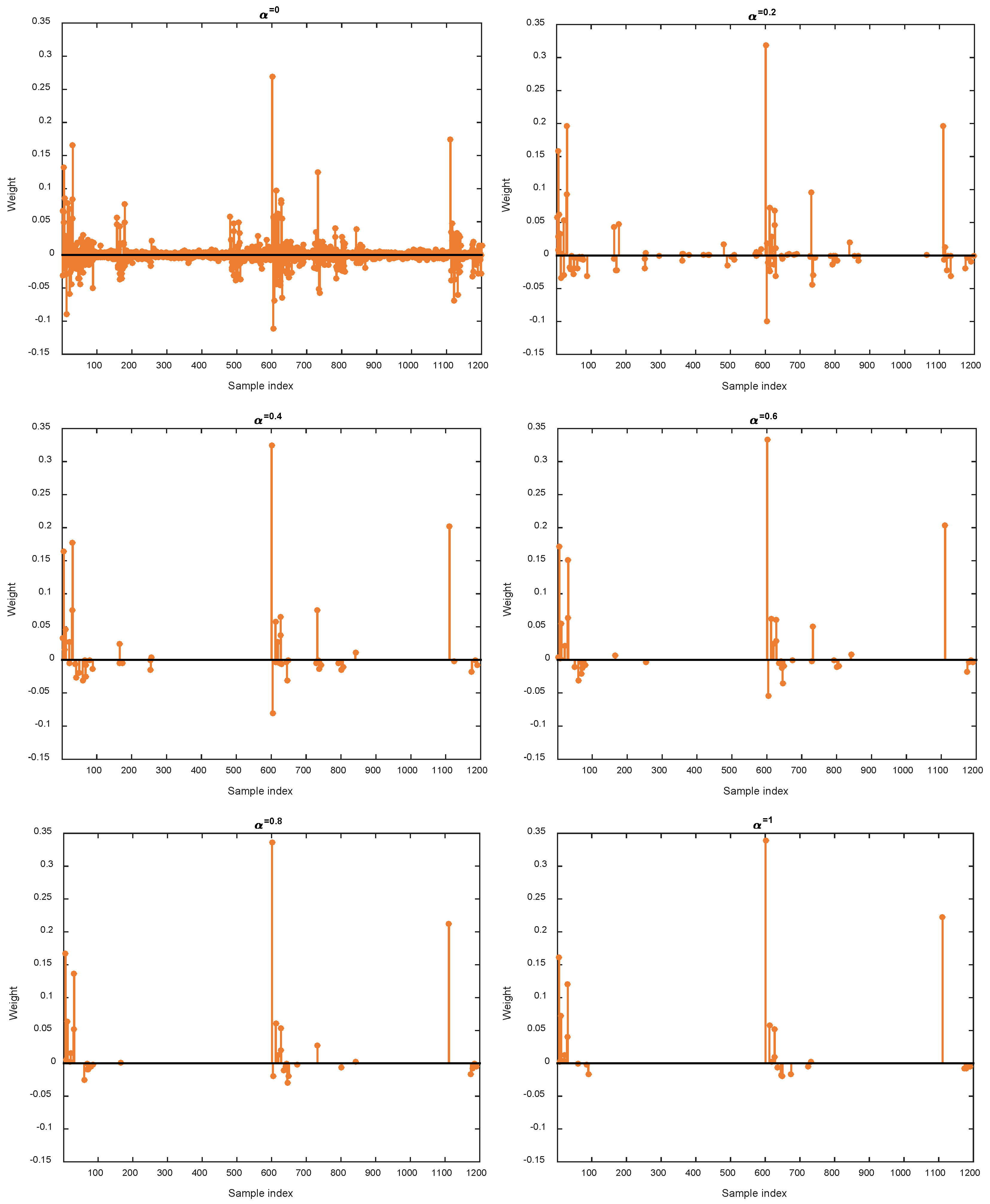
4.3.3. Influence of Parameters
4.3.4. Computational Time
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, J.; Wang, F.-Y.; Wang, K.; Lin, W.-H.; Xu, X.; Chen, C. Data-driven intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1624–1639. [Google Scholar] [CrossRef]
- Qu, L.; Li, L.; Zhang, Y.; Hu, J. PPCA-based missing data imputation for traffic flow volume: A systematical approach. IEEE Trans. Intell. Transp. Syst. 2009, 10, 512–522. [Google Scholar]
- Turner, S.; Albert, L.; Gajewski, B.; Eisele, W. Archived intelligent transportation system data quality: Preliminary analyses of San Antonio TransGuide data. Transp. Res. Rec. J. Transp. Res. Board 2000, 1719, 77–84. [Google Scholar] [CrossRef]
- Chen, X.; Wei, Z.; Liu, X.; Cai, Y.; Li, Z.; Zhao, F. Spatiotemporal variable and parameter selection using sparse hybrid genetic algorithm for traffic flow forecasting. Int. J. Distrib. Sens. Netw. 2017, 13. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.N. The Nature of Statistical Learning Theory, 2nd ed.; Springer: New York, NY, USA, 2000; 314p. [Google Scholar]
- Chen, X.; Yang, J.; Chen, L. An improved robust and sparse twin support vector regression via linear programming. Soft Comput. 2014, 18, 2335–2348. [Google Scholar] [CrossRef]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.-Y. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Ma, X.; Dai, Z.; He, Z.; Ma, J.; Wang, Y.; Wang, Y. Learning traffic as images: A deep convolutional neural network for large-scale transportation network speed prediction. Sensors 2017, 17, 818. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Wu, Z.; Wang, S.; Wang, Y.; Ma, X. Spatiotemporal recurrent convolutional networks for traffic prediction in transportation networks. Sensors 2017, 17, 1501. [Google Scholar] [CrossRef] [PubMed]
- Work, D.; Blandin, S.; Tossavainen, O.-P.; Piccoli, B.; Bayen, A. A distributed highway velocity model for traffic state reconstruction. Appl. Res. Math. eXpress 2010, 1, 1–35. [Google Scholar]
- Canepa, E.S.; Claudel, C.G. Networked traffic state estimation involving mixed fixed-mobile sensor data using Hamilton-Jacobi equations. Transp. Res. Part B Methodol. 2017, 104, 686–709. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Papageorgiou, M. Real-time freeway traffic state estimation based on extended Kalman filter: A general approach. Transp. Res. Part B Methodol. 2005, 39, 141–167. [Google Scholar] [CrossRef]
- Muñoz, L.; Sun, X.; Horowitz, R.; Alvarez, L. Traffic density estimation with the cell transmission model. In Proceedings of the 2003 American Control Conference, Denver, CO, USA, 4–6 June 2003; pp. 3750–3755. [Google Scholar]
- Batista, G.E.; Monard, M.C. An analysis of four missing data treatment methods for supervised learning. Appl. Artif. Intell. 2003, 17, 519–533. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y. Data imputation using least squares support vector machines in urban arterial streets. IEEE Signal Process. Lett. 2009, 16, 414–417. [Google Scholar] [CrossRef]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717–772. [Google Scholar] [CrossRef]
- Chen, X.; Wei, Z.; Li, Z.; Liang, J.; Cai, Y.; Zhang, B. Ensemble Correlation-Based Low-rank Matrix Completion with Applications to Traffic Data Imputation. Knowl.-Based Syst. 2017, 132, 249–262. [Google Scholar] [CrossRef]
- Fan, J.; Chow, T. Matrix completion by least-square, low-rank, and sparse self-representations. Pattern Recognit. 2017, 71, 290–305. [Google Scholar] [CrossRef]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef] [PubMed]
- Vidal, R.; Favaro, P. Low rank subspace clustering (LRSC). Pattern Recognit. Lett. 2014, 43, 47–61. [Google Scholar] [CrossRef] [Green Version]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. Pattern Anal. Mach. Intell. IEEE Trans. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Cai, Y.; Liu, Q.; Chen, L. Nonconvex lp-Norm Regularized Sparse Self-Representation for Traffic Sensor Data Recovery. IEEE Access 2018, 6, 24279–24290. [Google Scholar] [CrossRef]
- Chen, X.; Cai, Y.; Ye, Q.; Chen, L.; Li, Z. Graph regularized local self-representation for missing value imputation with applications to on-road traffic sensor data. Neurocomputing 2018, 303, 47–59. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Bian, X.; Li, F.; Ning, X. Kernelized Sparse Self-Representation for Clustering and Recommendation. In Proceedings of the 2016 SIAM International Conference on Data Mining, Miami, FL, USA, 5–7 May 2016; pp. 10–17. [Google Scholar]
- Gao, S.; Tsang, I.W.-H.; Chia, L.-T. Kernel sparse representation for image classification and face recognition. In Computer Vision—ECCV 2010; Springer: New York, NY, USA, 2010; pp. 1–14. [Google Scholar]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Thiagarajan, J.J.; Ramamurthy, K.N.; Spanias, A. Multiple kernel sparse representations for supervised and unsupervised learning. IEEE Trans. Image Process. 2014, 23, 2905–2915. [Google Scholar] [CrossRef] [PubMed]
- Combettes, P.L.; Wajs, V.R. Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 2005, 4, 1168–1200. [Google Scholar] [CrossRef]
- Bach, F.; Jenatton, R.; Mairal, J.; Obozinski, G. Optimization with sparsity-inducing penalties. Found. Trends Mach. Learn. 2012, 4, 1–106. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Tipping, M.E.; Bishop, C.M. Probabilistic principal component analysis. J. R. Stat. Soc. Ser. B 1999, 61, 611–622. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis; Wiley Online Library: New York, NY, USA, 2005. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Shi, F.; Zhang, D.; Chen, J.; Karimi, H.R. Missing value estimation for microarray data by Bayesian principal component analysis and iterative local least squares. Math. Prob. Eng. 2013, 2013, 162938. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, G.; Jin, J.; Zhao, Q.; Wang, X.; Cichocki, A. Sparse Bayesian classification of EEG for brain-computer interface. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 2256–2267. [Google Scholar] [CrossRef] [PubMed]
- Tan, H.; Feng, G.; Feng, J.; Wang, W.; Zhang, Y.-J.; Li, F. A tensor-based method for missing traffic data completion. Transp. Res. Part C Emerg. Technol. 2013, 28, 15–27. [Google Scholar] [CrossRef]
- Honghai, F.; Guoshun, C.; Cheng, Y.; Bingru, Y.; Yumei, C. A SVM regression based approach to filling in missing values. In Proceedings of the International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, Melbourne, Australia, 14–16 September 2005; Springer: New York, NY, USA, 2005; pp. 581–587. [Google Scholar]
- Chen, X.; Yang, J.; Ye, Q.; Liang, J. Recursive projection twin support vector machine via within-class variance minimization. Pattern Recognit. 2011, 44, 2643–2655. [Google Scholar] [CrossRef]
- Silva-Ramírez, E.-L.; Pino-Mejías, R.; López-Coello, M.; Cubiles-de-la-Vega, M.-D. Missing value imputation on missing completely at random data using multilayer perceptrons. Neural Netw. 2011, 24, 121–129. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Golub, G.H.; Park, H. Missing value estimation for DNA microarray gene expression data: Local least squares imputation. Bioinformatics 2005, 21, 187–198. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.-F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Ma, S.; Goldfarb, D.; Chen, L. Fixed point and Bregman iterative methods for matrix rank minimization. Math. Program. 2011, 128, 321–353. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Patel, V.M.; Vidal, R. Kernel sparse subspace clustering. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 2849–2853. [Google Scholar]
- Wen, X.; Qiao, L.; Ma, S.; Liu, W.; Cheng, H. Sparse subspace clustering for incomplete images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 19–27. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002; 626p. [Google Scholar]
- Asif, M.T.; Mitrovic, N.; Dauwels, J.; Jaillet, P. Matrix and Tensor Based Methods for Missing Data Estimation in Large Traffic Networks. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1816–1825. [Google Scholar] [CrossRef]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 1993 Conference Record of the Twenty-Seventh Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; pp. 40–44. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Compared Methods | Ours | |||
|---|---|---|---|---|---|
| LLS | LRMC | PPCA | SR-EN | KSR-EN | |
| RMSE | 13.89 ± 1.30 | 56.05 ± 1.86 | 37.77 ± 1.55 | 25.07 ± 2.80 | 7.00 ± 0.37 |
| RELERR | 19.23 ± 1.85 | 77.60 ± 2.79 | 52.23 ± 2.24 | 34.68 ± 3.60 | 9.69 ± 0.51 |
| δ | Metrics | Compared Methods | Ours | |||
|---|---|---|---|---|---|---|
| LLS | LRMC | PPCA | SR-EN | KSR-EN | ||
| 0.1 | RMSE | 76.62 ± 0.60 | 80.63 ± 0.86 | 79.06 ± 1.36 | 74.12 ± 1.22 | 67.52 ± 0.43 |
| RELERR | 11.22 ± 0.09 | 11.80 ± 0.08 | 11.58 ± 0.15 | 10.85 ± 0.21 | 9.89 ± 0.04 | |
| 0.2 | RMSE | 82.26 ± 0.70 | 83.30 ± 0.24 | 82.98 ± 0.24 | 76.43 ± 0.23 | 70.65 ± 0.33 |
| RELERR | 12.06 ± 0.12 | 12.21 ± 0.05 | 12.16 ± 0.05 | 11.20 ± 0.02 | 10.36 ± 0.06 | |
| 0.3 | RMSE | 89.94 ± 0.70 | 86.58 ± 0.74 | 85.47 ± 0.72 | 82.62 ± 1.84 | 75.05 ± 0.96 |
| RELERR | 13.18 ± 0.08 | 12.69 ± 0.06 | 12.53 ± 0.06 | 12.11 ± 0.23 | 11.00 ± 0.10 | |
| 0.4 | RMSE | 99.01 ± 0.56 | 90.94 ± 0.50 | 89.69 ± 0.63 | 85.83 ± 1.46 | 80.42 ± 0.63 |
| RELERR | 14.49 ± 0.08 | 13.31 ± 0.04 | 13.13 ± 0.06 | 12.56 ± 0.19 | 11.77 ± 0.07 | |
| 0.5 | RMSE | 113.03 ± 0.36 | 95.91 ± 0.44 | 95.83 ± 0.69 | 91.85 ± 1.46 | 87.11 ± 0.43 |
| RELERR | 16.54 ± 0.04 | 14.04 ± 0.04 | 14.02 ± 0.07 | 13.46 ± 0.25 | 12.75 ± 0.04 | |
| δ | Metrics | Compared Methods | Ours | |||
|---|---|---|---|---|---|---|
| LLS | LRMC | PPCA | SR-EN | KSR-EN | ||
| 0.1 | RMSE | 84.31 ± 1.11 | 98.31 ± 0.46 | 90.14 ± 0.88 | 87.44 ± 0.75 | 77.84 ± 0.99 |
| RELERR | 12.00 ± 0.16 | 13.99 ± 0.10 | 12.83 ± 0.03 | 12.45 ± 0.22 | 11.08 ± 0.20 | |
| 0.2 | RMSE | 91.89 ± 0.56 | 100.86 ± 1.17 | 95.13 ± 1.27 | 90.57 ± 1.41 | 82.41 ± 0.97 |
| RELERR | 13.12 ± 0.04 | 14.40 ± 0.13 | 13.58 ± 0.17 | 12.93 ± 0.16 | 11.76 ± 0.11 | |
| 0.3 | RMSE | 100.07 ± 1.51 | 103.06 ± 1.32 | 97.45 ± 1.28 | 94.56 ± 1.16 | 87.63 ± 0.85 |
| RELERR | 14.34 ± 0.19 | 14.77 ± 0.15 | 13.96 ± 0.15 | 13.55 ± 0.16 | 12.56 ± 0.12 | |
| 0.4 | RMSE | 112.54 ± 1.17 | 106.19 ± 0.79 | 101.50 ± 1.21 | 99.54 ± 0.73 | 92.12 ± 1.73 |
| RELERR | 16.18 ± 0.17 | 15.26 ± 0.12 | 14.59 ± 0.16 | 14.31 ± 0.11 | 13.24 ± 0.27 | |
| 0.5 | RMSE | 130.85 ± 1.96 | 109.78 ± 0.69 | 105.50 ± 0.87 | 104.55 ± 1.00 | 99.21 ± 0.98 |
| RELERR | 18.84 ± 0.27 | 15.81 ± 0.11 | 15.19 ± 0.10 | 15.06 ± 0.15 | 14.29 ± 0.14 | |
| δ | Metrics | Compared Methods | Ours | |||
|---|---|---|---|---|---|---|
| LLS | LRMC | PPCA | SR-EN | KSR-EN | ||
| 0.1 | RMSE | 79.48 ± 1.67 | 89.57 ± 1.01 | 84.40 ± 2.17 | 80.48 ± 1.09 | 71.98 ± 1.79 |
| RELERR | 11.46 ± 0.28 | 12.91 ± 0.18 | 12.17 ± 0.32 | 11.60 ± 0.18 | 10.38 ± 0.29 | |
| 0.2 | RMSE | 86.60 ± 0.47 | 92.73 ± 0.05 | 89.37 ± 0.71 | 84.96 ± 1.44 | 77.36 ± 1.38 |
| RELERR | 12.52 ± 0.12 | 13.40 ± 0.09 | 12.92 ± 0.07 | 12.28 ± 0.26 | 11.18 ± 0.16 | |
| 0.3 | RMSE | 93.75 ± 0.86 | 95.18 ± 1.10 | 91.37 ± 1.22 | 87.88 ± 0.92 | 81.06 ± 2.35 |
| RELERR | 13.58 ± 0.11 | 13.78 ± 0.13 | 13.23 ± 0.15 | 12.73 ± 0.14 | 11.74 ± 0.31 | |
| 0.4 | RMSE | 104.31 ± 0.52 | 99.00 ± 0.57 | 95.26 ± 0.62 | 93.85 ± 0.71 | 88.28 ± 1.68 |
| RELERR | 15.13 ± 0.06 | 14.36 ± 0.05 | 13.82 ± 0.09 | 13.61 ± 0.07 | 12.80 ± 0.24 | |
| 0.5 | RMSE | 118.92 ± 1.31 | 103.14 ± 0.96 | 100.83 ± 0.65 | 98.33 ± 0.78 | 94.02 ± 1.00 |
| RELERR | 17.28 ± 0.17 | 14.99 ± 0.12 | 14.65 ± 0.08 | 14.23 ± 0.10 | 13.66 ± 0.12 | |
| δ | Compared Methods | Ours | |||
|---|---|---|---|---|---|
| LLS | LRMC | PPCA | SR-EN | KSR-EN | |
| 0.1 | 2.281 | 3.008 | 2.815 | 75.153 | 178.690 |
| 0.2 | 3.576 | 4.098 | 3.520 | 76.455 | 192.777 |
| 0.3 | 5.662 | 5.993 | 5.325 | 78.657 | 223.926 |
| 0.4 | 8.453 | 8.654 | 8.138 | 80.897 | 249.088 |
| 0.5 | 12.483 | 12.381 | 11.961 | 81.419 | 274.759 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Chen, C.; Cai, Y.; Wang, H.; Ye, Q. Kernel Sparse Representation with Hybrid Regularization for On-Road Traffic Sensor Data Imputation. Sensors 2018, 18, 2884. https://doi.org/10.3390/s18092884
Chen X, Chen C, Cai Y, Wang H, Ye Q. Kernel Sparse Representation with Hybrid Regularization for On-Road Traffic Sensor Data Imputation. Sensors. 2018; 18(9):2884. https://doi.org/10.3390/s18092884
Chicago/Turabian StyleChen, Xiaobo, Cheng Chen, Yingfeng Cai, Hai Wang, and Qiaolin Ye. 2018. "Kernel Sparse Representation with Hybrid Regularization for On-Road Traffic Sensor Data Imputation" Sensors 18, no. 9: 2884. https://doi.org/10.3390/s18092884
APA StyleChen, X., Chen, C., Cai, Y., Wang, H., & Ye, Q. (2018). Kernel Sparse Representation with Hybrid Regularization for On-Road Traffic Sensor Data Imputation. Sensors, 18(9), 2884. https://doi.org/10.3390/s18092884