Pixel-Wise Crack Detection Using Deep Local Pattern Predictor for Robot Application

Abstract
:1. Introduction
2. Related Works
3. Work in This Paper
4. Proposed Method
4.1. Scheme of Proposed Method
4.2. Local Pattern Predictor
4.3. Convolutional Neural Networks for LPP
4.4. Post-Processing
5. Experimental Results
5.1. Data Set
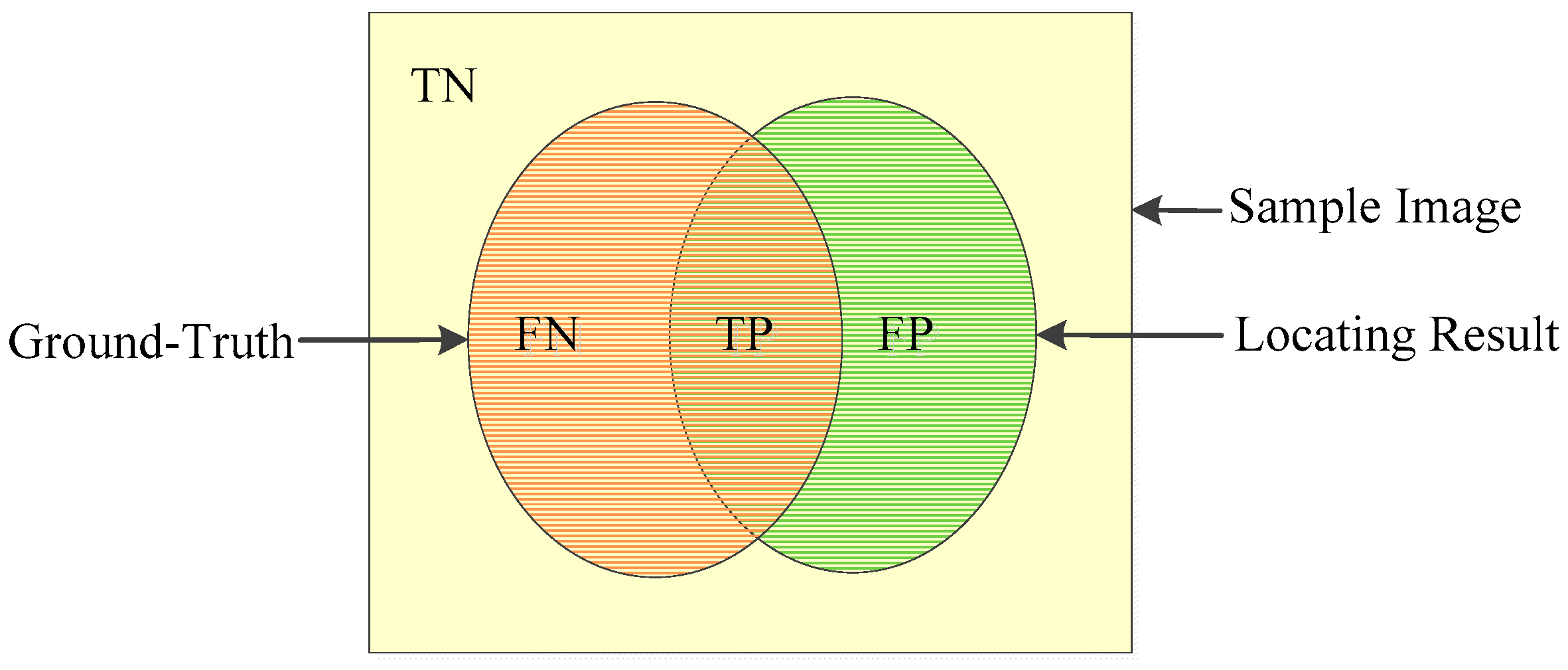
5.2. Metrics
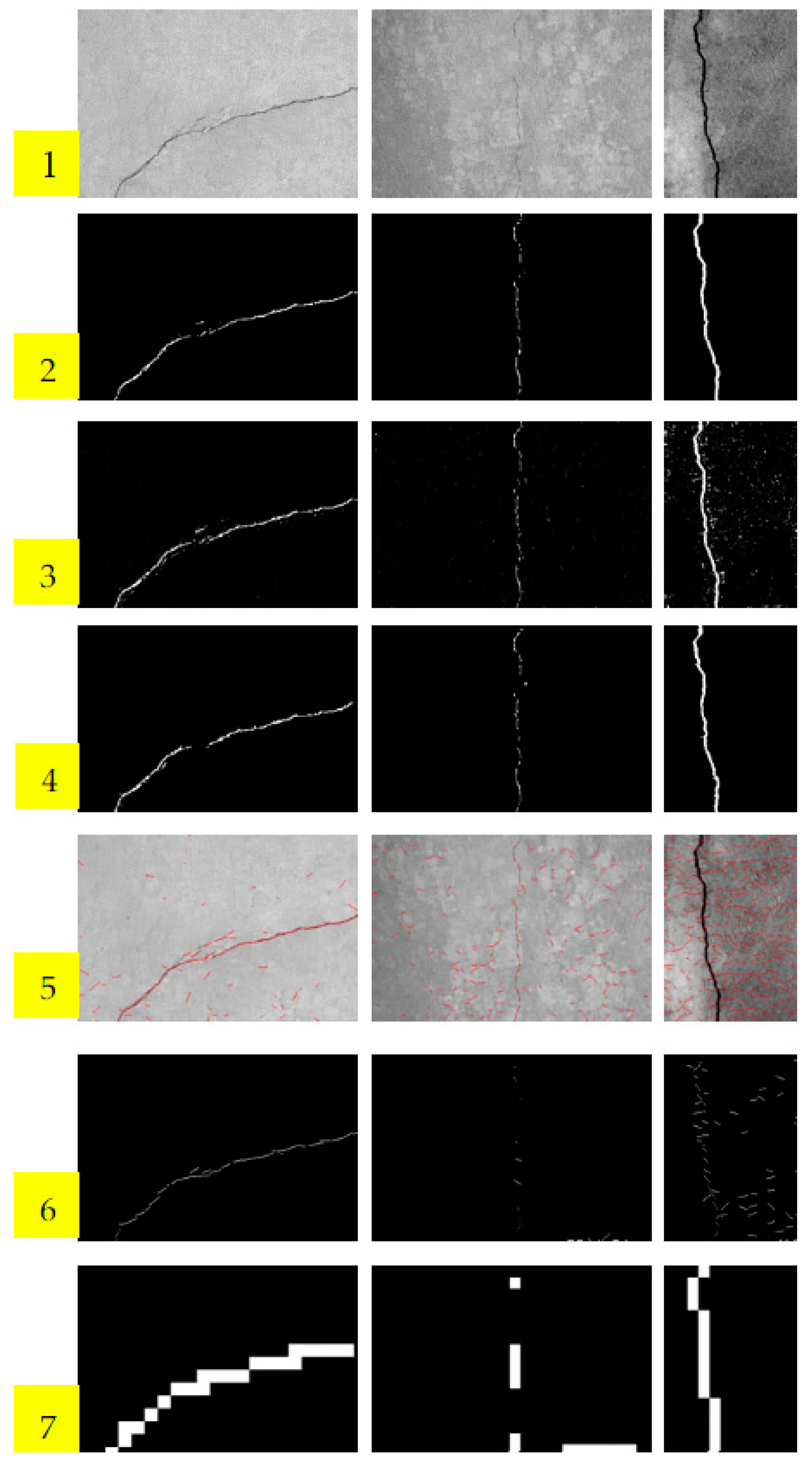
5.3. Performance Comparisons
6. Discussion
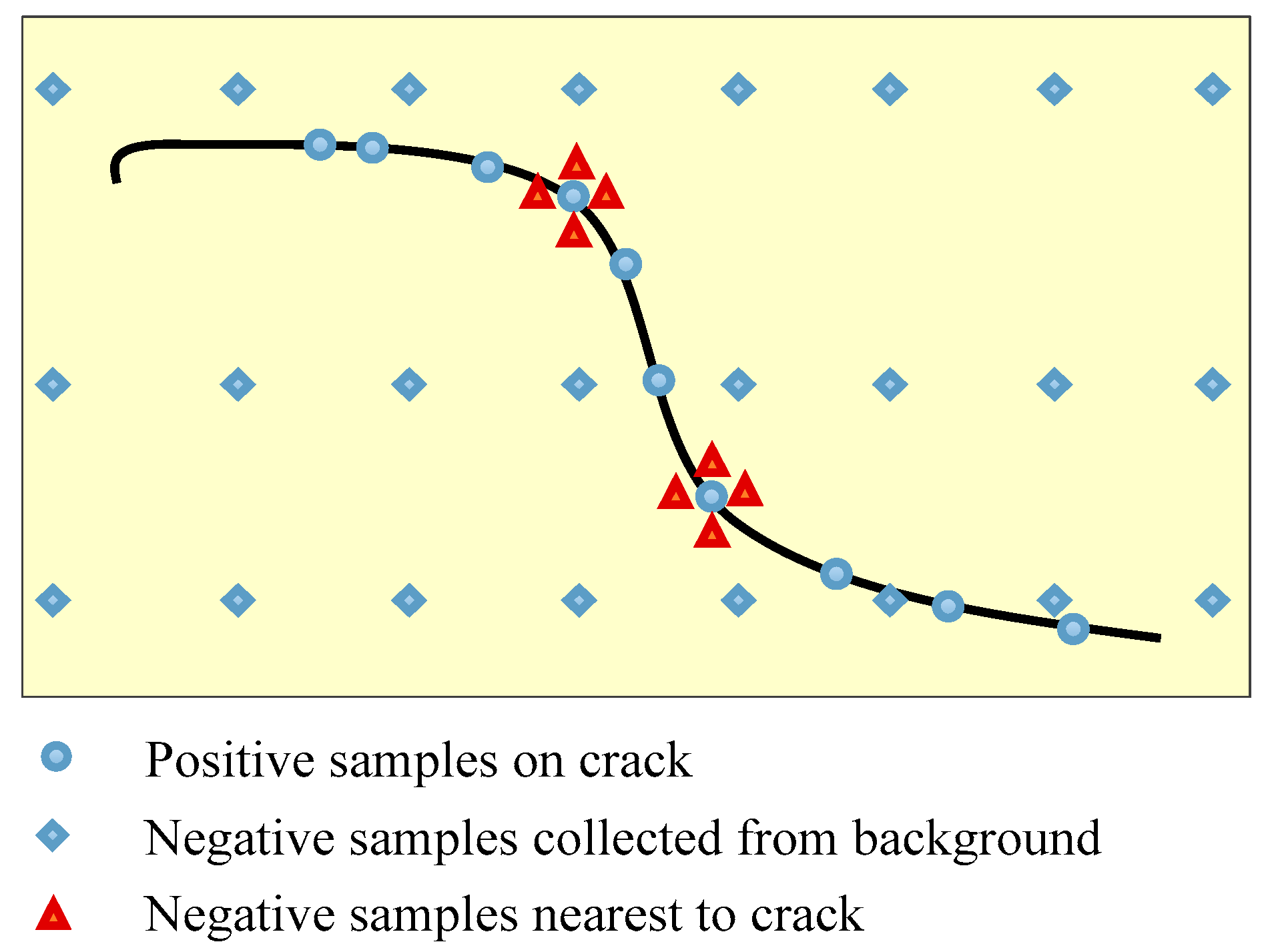
6.1. Principle of Training Samples Choosing
6.2. Performance Improvement when Dataset Is Limited
6.3. Computational Time Analysis
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated Crack Detection on Concrete Bridges. IEEE Trans. Autom. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Molina, M.; Frau, P.; Maravall, D. A Collaborative Approach for Surface Inspection Using Aerial Robots and Computer Vision. Sensors 2018, 18, 893. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Lim, R.S.; La, H.M.; Shan, Z.; Sheng, W. Developing a crack inspection robot for bridge maintenance. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 6288–6293. [Google Scholar]
- Hasan, M.; Roy-Chowdhury, A.K. A Continuous Learning Framework for Activity Recognition Using Deep Hybrid Feature Models. IEEE Trans. Multimed. 2015, 17, 1909–1922. [Google Scholar] [CrossRef]
- Viciana-Abad, R.; Marfil, R.; Perez-Lorenzo, J.M.; Bandera, J.P.; Romero-Garces, A.; Reche-Lopez, P. Audio-visual perception system for a humanoid robotic head. Sensors 2014, 14, 9522–9545. [Google Scholar] [CrossRef] [PubMed]
- Amatya, S.; Karkee, M.; Zhang, Q.; Whiting, M.D. Automated Detection of Branch Shaking Locations for Robotic Cherry Harvesting Using Machine Vision. Robotics 2017, 6, 31. [Google Scholar] [CrossRef]
- Alzarok, H.; Fletcher, S.; Longstaff, A.P. 3D Visual Tracking of an Articulated Robot in Precision Automated Tasks. Sensors 2017, 17, 104. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Zhu, J.; Wang, Y.; Jia, W.; Sun, M.; Tang, Y. Obstacle classification and 3D measurement in unstructured environments based on ToF cameras. Sensors 2014, 14, 10753–10782. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Indri, M.; Trapani, S.; Lazzero, I. Development of a Virtual Collision Sensor for Industrial Robots. Sensors 2017, 17, 1148. [Google Scholar] [CrossRef] [PubMed]
- Sivcev, S.; Rossi, M.; Coleman, J.; Omerdic’, E.; Dooly, G.; Toal, D. Collision Detection for Underwater ROV Manipulator Systems. Sensors 2018, 18, 1117. [Google Scholar] [CrossRef] [PubMed]
- Leite, A.; Pinto, A.; Matos, A. A Safety Monitoring Model for a Faulty Mobile Robot. Robotics 2018, 7, 32. [Google Scholar] [CrossRef]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P.W. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef] [Green Version]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Li, G.; He, S.; Ju, Y.; Du, K. Long-distance precision inspection method for bridge cracks with image processing. Autom. Constr. 2014, 41, 83–95. [Google Scholar] [CrossRef]
- Tong, X.; Guo, J.; Ling, Y.; Yin, Z. A new image-based method for concrete bridge bottom crack detection. In Proceedings of the 2011 International Conference on Image Analysis and Signal Processing, Wuhan, Hubei, China, 21–23 October 2011; pp. 568–571. [Google Scholar]
- Oh, J.K.; Jang, G.; Oh, S.; Lee, J.H.; Yi, B.J.; Moon, Y.S.; Lee, J.S.; Choi, Y. Bridge inspection robot system with machine vision. Autom. Constr. 2009, 18, 929–941. [Google Scholar] [CrossRef]
- Hutchinson, T.C.; Chen, Z.Q. Improved Image Analysis for Evaluating Concrete Damage. J. Comput. Civ. Eng. 2006, 20, 210–216. [Google Scholar] [CrossRef]
- Adhikari, R.; Moselhi, O.; Bagchi, A. Image-based retrieval of concrete crack properties for bridge inspection. Autom. Constr. 2014, 39, 180–194. [Google Scholar] [CrossRef]
- Dinh, T.H.; Ha, Q.P.; La, H.M. Computer vision-based method for concrete crack detection. In Proceedings of the 2016 14th International Conference on Control, Automation, Robotics and Vision (ICARCV), Phuket, Thailand, 13–15 November 2016; pp. 1–6. [Google Scholar]
- Lim, R.S.; La, H.M.; Sheng, W. A Robotic Crack Inspection and Mapping System for Bridge Deck Maintenance. IEEE Trans. Autom. Sci. Eng. 2014, 11, 367–378. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Hashimoto, S. Fast crack detection method for large-size concrete surface images using percolation-based image processing. Mach. Vis. Appl. 2010, 21, 797–809. [Google Scholar] [CrossRef]
- Nguyen, H.N.; Kam, T.Y.; Cheng, P.Y. An Automatic Approach for Accurate Edge Detection of Concrete Crack Utilizing 2D Geometric Features of Crack. Signal Process. Syst. 2014, 77, 221–240. [Google Scholar] [CrossRef]
- Kapela, R.; Sniatala, P.; Turkot, A.; Rybarczyk, A.; Pozarycki, A.; Rydzewski, P.; Wyczalek, M.; Bloch, A. Asphalt surfaced pavement cracks detection based on histograms of oriented gradients. In Proceedings of the 2015 22nd International Conference Mixed Design of Integrated Circuits Systems (MIXDES), Torun, Poland, 25–27 June 2015; pp. 579–584. [Google Scholar]
- Wi, H.; Nguyen, V.; Lee, J.; Guan, H.; Loo, Y.C.; Blumenstein, M. Enhancing Visual-based Bridge Condition Assessment for Concrete Crack Evaluation Using Image Processing Techniques. IABSE Symp. Rep. 2013, 101, 479–480. [Google Scholar] [CrossRef]
- Zhao, H.; Ge, W.; Li, X. Detection of crack defect based on minimum error and pulse coupled neural networks. Chin. J. Sci. Instrum. 2012, 33, 637–642. [Google Scholar]
- Abdel-Qader, I.; Pashaie-Rad, S.; Abudayyeh, O.; Yehia, S. PCA-Based algorithm for unsupervised bridge crack detection. Adv. Eng. Softw. 2006, 37, 771–778. [Google Scholar] [CrossRef]
- Lattanzi, D.; Miller, G.R. Robust Automated Concrete Damage Detection Algorithms for Field Applications. J. Comput. Civ. Eng. 2014, 28, 253–262. [Google Scholar] [CrossRef]
- Bu, G.P.; Chanda, S.; Guan, H.; Jo, J.; Blumenstein, M.; Loo, Y.C. Crack detection using a texture analysis-based technique for visual bridge inspection. Electron. J. Struct. Eng. 2015, 14, 41–48. [Google Scholar]
- Chaudhury, S.; Nakano, G.; Takada, J.; Iketani, A. Spatial-Temporal Motion Field Analysis for Pixelwise Crack Detection on Concrete Surfaces. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 336–344. [Google Scholar]
- Li, G.; Zhao, X.; Du, K.; Ru, F.; Zhang, Y. Recognition and evaluation of bridge cracks with modified active contour model and greedy search-based support vector machine. Autom. Constr. 2017, 78, 51–61. [Google Scholar] [CrossRef]
- Qian, B.; Tang, Z.; Xu, W. Pavement crack detection based on sparse autoencoder. Trans. Beijing Inst. Technol. 2015, 35, 800–804. [Google Scholar]
- Schmugge, S.J.; Rice, L.; Nguyen, N.R.; Lindberg, J.; Grizzi, R.; Joffe, C.; Shin, M.C. Detection of cracks in nuclear power plant using spatial-temporal grouping of local patches. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–7. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Maher, A.; Taha, H.; Zhang, B. Realtime multi-aircraft tracking in aerial scene with deep orientation network. J. Real-Time Image Process. 2018, 1–13. [Google Scholar] [CrossRef]
- Zhang, B.; Luan, S.; Chen, C.; Han, J.; Wang, W.; Perina, A.; Shao, L. Latent Constrained Correlation Filter. IEEE Trans. Image Process. 2018, 27, 1038–1048. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luan, S.; Zhang, B.; Zhou, S.; Chen, C.; Han, J.; Yang, W.; Liu, J. Gabor Convolutional Networks. IEEE Trans. Image Process. 2017, 27, 4357–4366. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Yang, Y.; Chen, C.; Yang, L.; Han, J.; Shao, L. Action Recognition Using 3D Histograms of Texture and A Multi-Class Boosting Classifier. IEEE Trans. Image Process. 2017, 26, 4648–4660. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Zhao, W.; Pan, J. Deformable Patterned Fabric Defect Detection with Fisher Criterion-Based Deep Learning. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1256–1264. [Google Scholar] [CrossRef]
- Li, Y.; Ai, J.; Sun, C. Online Fabric Defect Inspection Using Smart Visual Sensors. Sensors 2013, 13, 4659–4673. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Zhang, C. Automated vision system for fabric defect inspection using Gabor filters and PCNN. SpringerPlus 2016, 5, 765. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Zhang, J.; Lin, Y. Combining Fisher Criterion and Deep Learning for Patterned Fabric Defect Inspection. IEICE Trans. Inform. Syst. 2016, 99, 2840–2842. [Google Scholar] [CrossRef]
- LÉcun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Images | Method | Acc (%) | Recall | Precision |
|---|---|---|---|---|
| No. 1 | STRUM+AdaBoost | 99.05 | 24.87 | 83.19 |
| Block-wise CNN | 93.87 | 86.97 | 14.73 | |
| LPP | 99.67 | 84.17 | 73.38 | |
| No. 2 | STRUM+AdaBoost | 97.91 | 13.61 | 78.42 |
| Block-wise CNN | 95.48 | 58.59 | 27.56 | |
| LPP | 99.52 | 78.83 | 79.86 | |
| No. 3 | STRUM+AdaBoost | 96.64 | 14.75 | 48.03 |
| Block-wise CNN | 90.88 | 56.90 | 15.94 | |
| LPP | 99.15 | 83.15 | 49.20 | |
| No. 4 | STRUM+AdaBoost | 99.38 | 3.24 | 25.00 |
| Block-wise CNN | 97.17 | 30.01 | 6.81 | |
| LPP | 99.90 | 74.78 | 82.89 | |
| No. 5 | STRUM+AdaBoost | 97.08 | 8.20 | 20.13 |
| Block-wise CNN | 93.67 | 93.42 | 26.22 | |
| LPP | 99.64 | 89.99 | 95.17 |
| Test Images | Sampling Processes | Acc (%) | Recall | Precision |
|---|---|---|---|---|
| No. 1 | Uniform | 97.83 | 95.40 | 34.89 |
| Nearest neighbors | 99.67 | 84.17 | 73.38 | |
| No. 2 | Uniform | 97.58 | 80.19 | 48.59 |
| Nearest neighbors | 99.52 | 78.83 | 79.86 | |
| No. 3 | Uniform | 96.72 | 85.52 | 50.40 |
| Nearest neighbors | 99.15 | 83.15 | 49.20 | |
| No. 4 | Uniform | 99.17 | 47.90 | 34.91 |
| Nearest neighbors | 99.90 | 74.78 | 82.89 | |
| No. 5 | Uniform | 96.42 | 99.93 | 39.64 |
| Nearest neighbors | 99.64 | 89.99 | 95.17 |
| Test Images | Methods | Acc (%) | Recall | Precision |
|---|---|---|---|---|
| No. 1 | CNN | 99.27 | 49.74 | 81.68 |
| Fisher-based CNN | 99.29 | 53.83 | 80.20 | |
| No. 2 | CNN | 98.34 | 31.51 | 91.05 |
| Fisher-based CNN | 98.40 | 35.47 | 88.90 | |
| No. 3 | CNN | 96.84 | 5.79 | 76.92 |
| Fisher-based CNN | 97.02 | 12.79 | 83.33 | |
| No. 4 | CNN | 99.37 | 2.88 | 22.22 |
| Fisher-based CNN | 99.69 | 5.74 | 34.78 | |
| No. 5 | CNN | 99.01 | 93.10 | 72.66 |
| Fisher-based CNN | 99.05 | 93.23 | 73.40 |
| Index | Methods | Training Epoch | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|
| 1 | STRUM AdaBoost | 1000 | 138 | 5.1 |
| 2 | Block-wise CNN | 600 | 33,084 | 0.2 |
| 3 | LPP | 200 | 15411 | 10.7 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, H.; Wang, H. Pixel-Wise Crack Detection Using Deep Local Pattern Predictor for Robot Application. Sensors 2018, 18, 3042. https://doi.org/10.3390/s18093042
Li Y, Li H, Wang H. Pixel-Wise Crack Detection Using Deep Local Pattern Predictor for Robot Application. Sensors. 2018; 18(9):3042. https://doi.org/10.3390/s18093042
Chicago/Turabian StyleLi, Yundong, Hongguang Li, and Hongren Wang. 2018. "Pixel-Wise Crack Detection Using Deep Local Pattern Predictor for Robot Application" Sensors 18, no. 9: 3042. https://doi.org/10.3390/s18093042
APA StyleLi, Y., Li, H., & Wang, H. (2018). Pixel-Wise Crack Detection Using Deep Local Pattern Predictor for Robot Application. Sensors, 18(9), 3042. https://doi.org/10.3390/s18093042