1. Introduction
Electronic nose (EN) refers to a system that simulates the olfactory system of humans and other mammals in structures and functions [
1] to achieve the qualitative and quantitative analysis of gases or odors, which is also called the artificial system of olfaction. At present, ENs have been widely studied and applied in medical diagnosis [
2], food quality testing [
3], environmental monitoring [
4], etc. Gas identification method plays a great important role in EN systems with a settled sensor array, which makes the study on gas identification approaches a research hot spot in gas detecting areas.
Lots of gas classification and identification methods based on pattern recognition technology have been studied, such as the Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), k-Nearest Neighbor (k-NN), and Artificial Neural Networks (ANNs). PCA is a generally used data dimension reduction and clustering method. LDA is a general linear statistical approach. Both PCA and LDA have been the traditional gas sensor array data processing methods. In Ref. [
5], k-NN has been proved to be a simple and effective method for clustering. ANNs can not only solve complex nonlinear mapping relationships, but also improve the accuracy of classifications, which have shown good results in the qualitative and quantitative identification of harmful gases [
6]. In ANNs, Multiple Layer Perception (MLP) is widely adopted to the study of gas classification [
7]. All these proposed gas classification approaches can be concluded into shallow models [
8] from the view of machine learning structures.
However, with the development of artificial intelligence, deep learning techniques have attracted a large amount of interest and shown better results than shallow models. Several deep learning models have been studied in the gas identification area. A Digital Multi-layer Neural Network (DMNN) was proposed in Ref. [
9], which can achieve over 93% classification performance. In Ref. [
10], Langkvist et al. put forward a deep-restricted Boltzmann machine (RBM) combined with an electronic nose to identify bacteria in blood. In Ref. [
11], gas identification research using a deep network is also introduced (deep Boltzmann Machine (DBM) and Sparse Auto-Encoder (SAE)), and the accuracy of the experimental results is higher than that of the traditional shallow model. In these articles, RBM, DBM and SAE are all unsupervised learning techniques that can learn higher-order features from large amounts of unlabeled data. As a supervised deep learning method, Convolutional Neural Network (CNN) shows attractive development in AI. A Deep Convolutional Neural Network (DCNN) was used to classify gases in Ref. [
12]. The authors designed a network with six convolutional blocks, a pooling layer and a fully connected layer to increase the depth of learning. Their final experimental result has an accuracy of 95.2%, which is higher than SVM and MLP. All these works show good prospective applications of deep learning methods in gas identification fields.
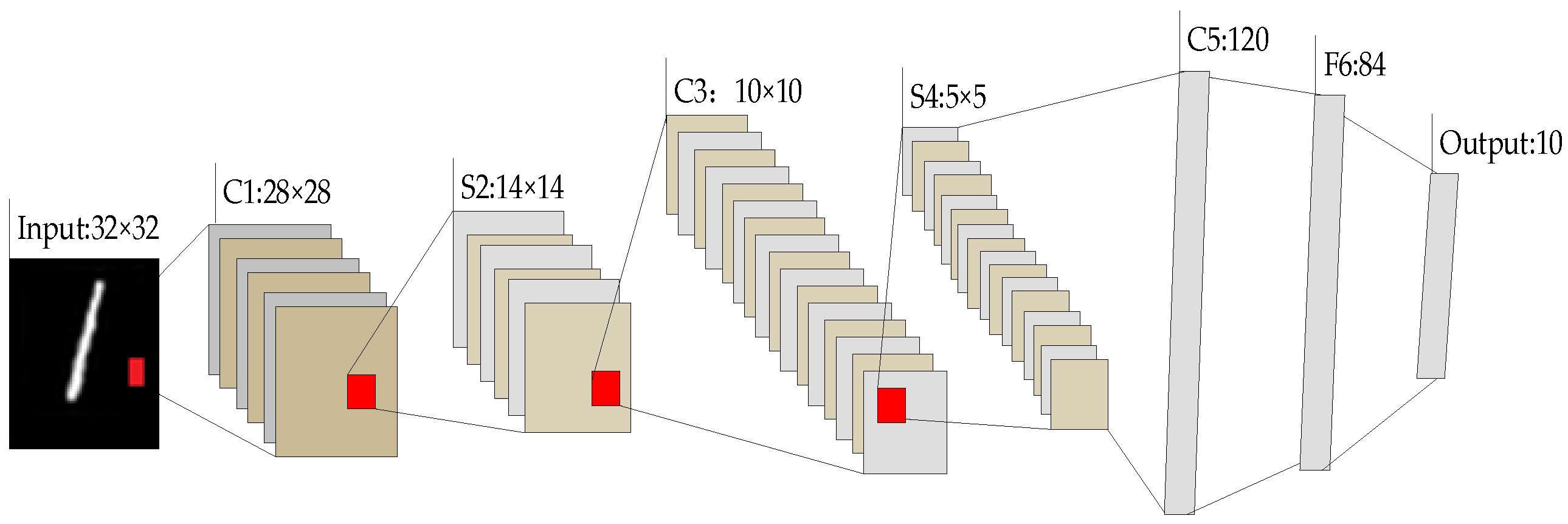
Recently, many typical and widely adopted CNN models have been proposed, such as LeNet-5 [
13], AlexNet [
14] and GoogLeNet [
15], which have been successfully applied in handwritten character recognition [
16], face detection [
17], pedestrian detection [
18] and robot navigation [
19] areas. Due to its high recognition rate and fast implementation speed, CNN continues to make efforts in many directions and breakthroughs.
Enlightened by the above applications and developments of deep learning techniques, this paper pays attention to a detailed study of a CNN-based gas classification method for ENs. The general LeNet-5 structure is improved and developed for EN gas identification with less convolution blocks but higher computation speed. The feasibility of the network structure is verified by experiments.
Section 2 describes the EN system and experimental setup;
Section 3 describes the traditional LeNet5 structure;
Section 4 describes the algorithms;
Section 5 describes the Gas CNN algorithm.
Section 6 analyzes the experimental results and proposes the improved LeNet-5 structure for ENs;
Section 7 presents the conclusions.
2. The EN System
2.1. The EN Frame
Generally, an EN is composed of a gas sensor array and a gas quantification/qualification unit.
Figure 1 shows a typical frame diagram of an EN. The sensor array consists of a certain number of gas sensors, which plays the sensing role for gas mixtures. The sensor array responses are transferred and conditioned by the designed interface circuit and then acquired by a DAQ board [
20]. The characteristics of the response signals are then extracted out as the useful features, and the extracted features are continuously put into a pattern recognition unit for classification and quantification. Finally, information of the type and concentration of the gas components in mixtures can be obtained.
2.2. The EN System and Its Test Equipment
In this paper, 12 commercial metal oxide gas sensors from Figaro Ltd. (Minami, Japan) were selected to constitute the sensor array.
Table 1 shows the part numbers of the sensors used and their corresponding channel numbers. These sensors are widely responsive to general flammable or explosive gases in the environment. The array was placed into a stainless steel chamber with volume of 138 mL, which is 11.5 cm × 4 cm × 3 cm.
The sensors were operated at their recommended working temperatures, and are heated up by a RH with a fixed heating voltage of 5 V. The variance of sensor resistance is obtained through a voltage divider circuit with a bias resister
RL, while
V0 is the output of the sensor and acquired by a DAQ board.
Figure 2a shows the diagram of the gas distribution and EN detection equipment, and
Figure 2b shows the measurement circuit of gas sensors.
The NI USB6342 multi-functional DAQ board is adopted as the data acquisition device with a USB interface to facilitate connection with the PC control terminal. High-precision Mass Flow Controllers (MFCs, Alicat Ltd., Tucson, AZ, USA) were selected for airflow control, which was controlled by the PC through the RS-232 interface protocol. The conditioning board was designed between the DAQ and the sensors in chamber, for the purpose of adjusting the strength of the output signals. The analytes to be measured were diluted by zero air, and their concentrations were controlled through ratios of flow rate of each MFC. The assembled analytes are injected into the test chamber with stable total flow rate. Both the data acquisition and gas distribution were controlled by PC via a LabVIEW program.
2.3. Data Measurement
The analytes in this experiment are two flammable and explosive gases: CH4 and CO. Based on their harmful level and general industrial needs, the concentrations of CH4 are set at 500, 1000, 1500 and 2000 ppm and those of CO are set at 50, 100, 150 and 200 ppm, respectively. Binary mixtures are produced by respectively mixing CH4 at four concentrations and CO at 50, 100 and 150 ppm. Responses of the same composition with different concentrations of gases in the sensor array were considered as one category. Therefore, the classification purpose is to identify three kinds of gases, which are pure CO, pure CH4 and mixtures of CO and CH4.
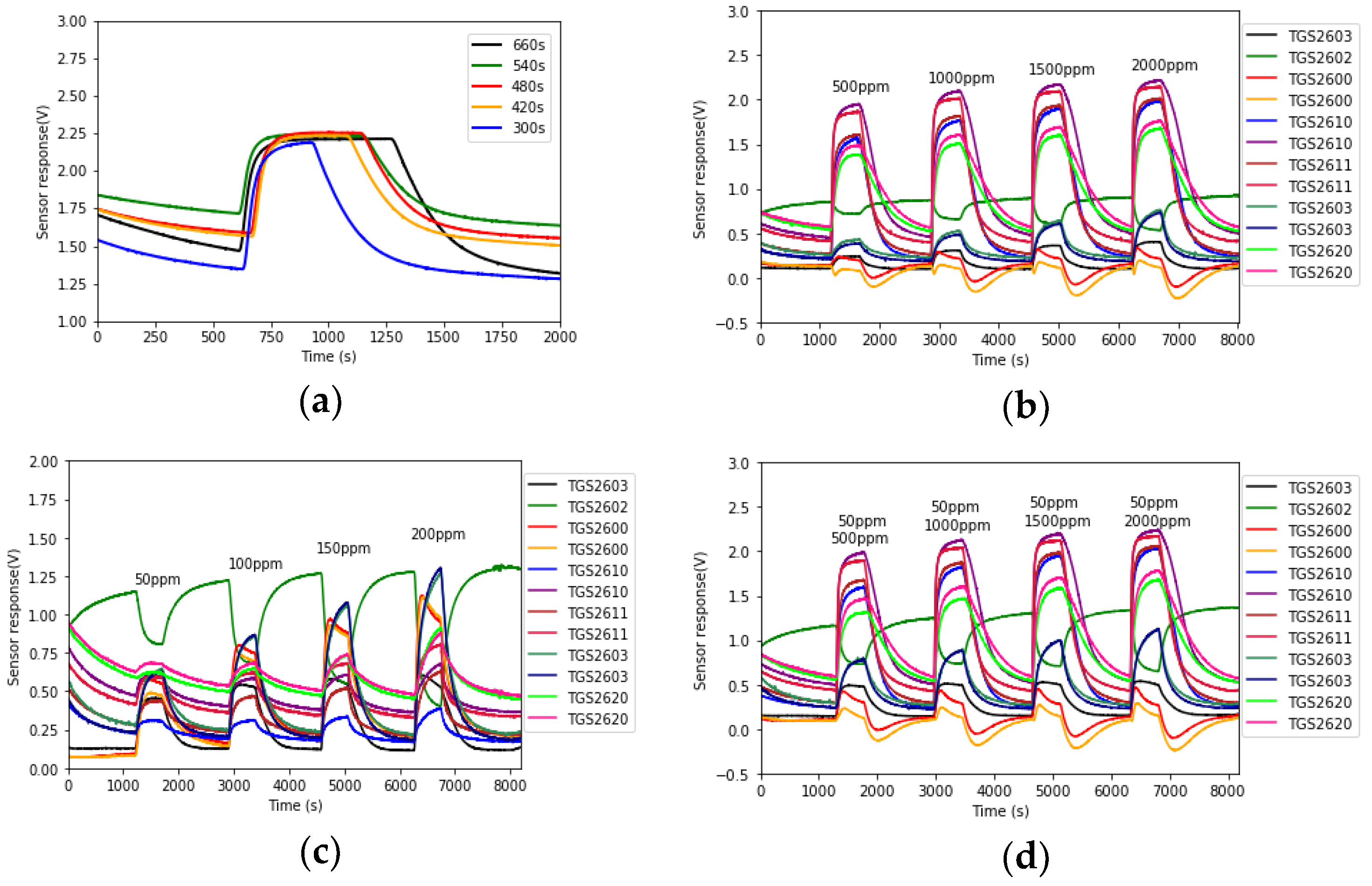
For each analyte test, a process of zero air cleansing was performed first for the purpose of cleaning the chamber and stabilizing the gas sensor baseline. This period is set at least at 20 min based on the experiment results. Then the analyte was injected into the chamber. The sensors’ response time is around 30–120 s, and the recovery time is a bit longer. An experiment on the injection time was performed. The CO at 50 ppm concentration was injected into the chamber for 660, 540, 480, 420 and 300 s, respectively.
Figure 3a shows the response curves of TGS2603 for these periods. It can be seen that the sensor response was stable during all these periods. Hence as long as the injection time is longer than the sensors’ response time, the sensor response curves could reach a stable point. In the following experiments, the injection time was settled at 480 s.
According to the test process, each concentration of each analyte was measured five times repeatedly. A total of 100 sets of raw data were obtained. The 12 sensor response signals were acquired by the DAQ at a sampling frequency of 1Hz. Some typical measured raw data are shown in
Figure 3b–d.
4. The Algorithm of CNN
The general algorithm contains two sub-algorithms, which are the forward propagation and the backward propagation one.
4.1. The Forward Propagation Algorithm
The forward propagation algorithm is presented in Algorithm 1. The output of the forward algorithm is E, which represents the error between the expected output and the actual output. In training set, xn represents the input of data matrix and yn represents the label of data.
| Algorithm 1 The forward propagation algorithm of CNN |
| 1 //process of the forward propagation |
| 2 Input: training set ; the number of CNN layers is L, each layer denoted as ; represents the input sample corresponding to the output of layer ; expected output . |
| 3 Process: |
| 4 Initialization: Initialize all layers of convolutional kernel and offset term . |
| 5 for all do |
| 6 for do |
| 7 if ( is the convolutional layer) then |
| 8 for (all ) do |
| 9 get according to (1) |
| 10 end |
| 11 end |
| 12 if ( is the pooling layer) then |
| 13 for (all ) do |
| 14 get according to (7) |
| 15 end |
| 16 end |
| 17 if ( is fully connected layer) |
| 18 for(all ) do |
| 19 get according to (8) |
| 20 end |
| 21 end |
| 22 if ( is output layer) then |
| 23 get or according to (9) |
| 24 end |
| 25 end |
| 26 end |
| 27 Output: Calculate the error of the output layer by the loss function, according to (11). |
4.2. The Reverse Propagation of CNN
Let , , and of the previous hidden layers can then be obtained by the reverse propagation. The reverse propagation algorithm of CNN is summarized in Algorithm 2, which is mainly to update the weight w and offset b of the convolutional layers and the fully connected layers.
| Algorithm 2 The reverse propagation algorithm of CNN |
| 1 //process of the reverse propagation |
| 2 Input: The error of the output layer calculated by the loss function, the learning rate . |
| 3 Process: |
| 4 for do |
| 5 if ( is fully connected layer) then |
| 6 get according to |
| 7 end |
| 8 if ( is the convolutional layer) then |
| 9 get according to |
| 10 end |
| 11 if ( is the pooling layer) then |
| 12 get according to |
| 13 end |
| 14 end |
| 15 for do |
| 16 if( is fully connected layer) then |
| 17 |
| 18 |
| 19 end |
| 20 if( is the convolutional layer) then |
| 21 |
| 22 |
| 23 end |
| 24 end |
| 25 Output: Updated values for and . |
5. Design of Gas Recognition Algorithm Based on CNN
5.1. Gas Data Preprocessing
Based on the data measurement process in
Section 2.3, the sensor array was exposed to the test analyte for a specified period and response curves were sampled at a rate of 1 Hz. Hence the response curves at the analyte injection time contain the sensor response information. This part of the array curves was extracted as the raw data. In our experiments, the injection time was set at 8 min and 12 sensors were used, which means that each raw data has a size of 480 × 12. Suppose
X represents the raw response matrix, and
, where
represents the sample time and
represents 12 sensors. It can be seen from
Figure 3 that gas sensor response curves vary slowly when injecting the target gases. Therefore, we can use less data to represent the information.
To further reduce the dimensions of the input data, the sensor response curves are resampled by , where N is the sampling interval. If N takes 40, 30, 20 and 10, the data is then downsampled with sizes of 12 × 12, 16 × 12, 24 × 12 and 48 × 12. If the original data size is not 480, downsampling can also be performed with other intervals. Here the uniform downsampling is performed.
The downsampled data matrix is then normalized to the space of (0, 1) and rescaled to the space of (0, 255) by Equation (12):
where min(
x) and max(
x) are the minimum value and maximum value of
X for each sensor
j. Then the rescaled data are transformed to the integers and can be shown as grayscale patterns.
Figure 7 shows some typical patterns of CH
4, CO and gas mixtures. Each preprocessed grayscale pattern represents the information of sensor array corresponding to the test analyte.
5.2. The Dataset Augmentation
Deep learning methods usually need large amounts of training data, which is quite a challenge for EN detection. As we can see, the time for each test was 28 min in our case. Before each test, chamber cleansing also needs time. The gas sensors will need a preheating time of 3 days at least if they are not used for a long time. Therefore, the data measurements of ENs are quite time-consuming. Hence data augmentation techniques were considered.
For small sampling data set, data augmentation techniques such as cropping, panning, scaling and rotation are usually used to augment the data size. In our case, translation and cropping were performed on the 100 sets of raw data. Another reason for considering data translation is that gas sensor response curves vary slowly when injecting the target gases and downsampling has been used to reduce the data. Therefore data translation will not change the gas information clearly but some baseline drift could be added into the augmented dataset. In our case,
X is translated with a step of
, shown in (13), then 100 × 10 = 1000 data sets
are obtained:
5.3. The Gas Recognition Algorithm Based on CNN
In Algorithm 3, E represents the error; e represents the set error value; the k represents the number of iterations. If the error E is greater than the set error e by the forward propagation Algorithm 1, the weight w and the threshold b are updated and the forward propagation algorithm is returned to calculate a new error E. If , the iteration is stopped and the weight w and threshold b are output.
| Algorithm 3 The gas recognition algorithm based on CNN |
| 1 Input: E represents the error; e represents the set error value; k represents the number of iterations and K represents the maximum batch; represents all data sets. |
| 2 Process: |
| //training the LeNet-5 |
| 3 for do |
| 4 One-Hot encoding and data set partition |
| 5 training dataset and testing dataset are obtained |
| 6 Begin of training time |
| 7 for all training dataset do |
| 8 for do |
| 9 Algorithm 1 |
| 10 if then do |
| 11 Algorithm 2 and return to step 8 |
| 12 else |
| 13 break; |
| 14 end |
| 15 end |
| 16 end |
| 17 End of training time |
| 18 store all and all |
| // test the LeNet-5 |
| 19 Load all and all to the LeNet-5 then do |
| 20 Begin of test time |
| 21 for all testing dataset do |
| 22 Algorithm 1 which is forward propagation |
| 23 end |
| 24 End of test time |
| 25 Calculate the accuracy |
| 26 Output: training time, test time and accuracy. |
6. Results and Analysis
The CNN for ENs is trained by the preprocessed data, and the parameters of Gas CNN are studied by detailed experiments. In the training process, 20% of the data is randomly taken out as the verification data set. Therefore, the number of training data sets is 800 and the number of testing data sets is 200.
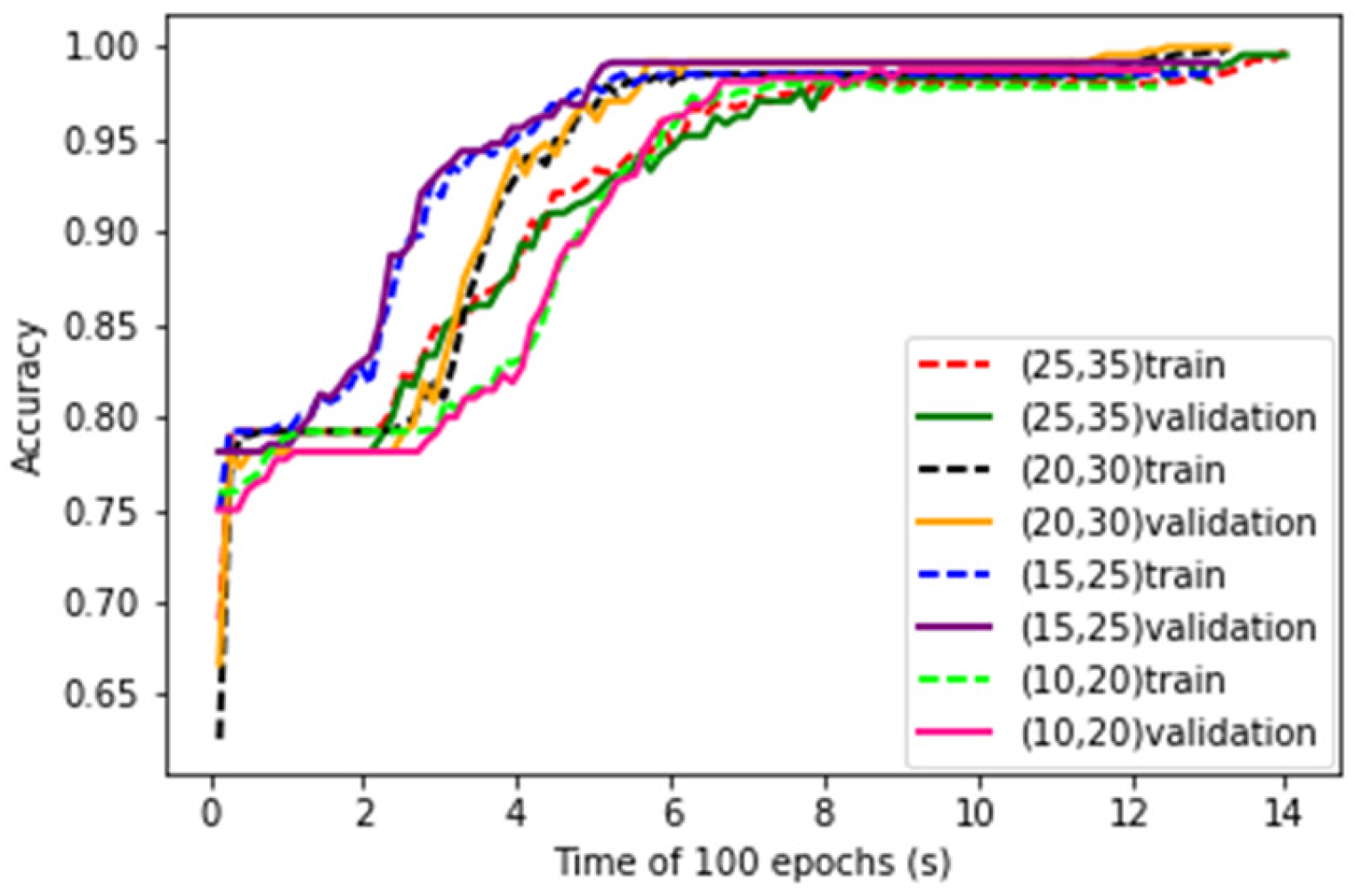
6.1. Influence of the Number of Convolutional Kernels of Gas CNN
The numbers of convolutional kernels are key parameters of LeNet-5 structure. Four kinds of parameter combinations are studied. The convergence curves of training process of the LeNet-5 at the four combinations are shown in
Figure 8. It can be seen that with the increase of number of kernels, the convergence speed of the learning curves decreases.
After training, the test data are put into the LeNet-5. The test accuracy and running time of the LeNet-5 at four combinations of convolution kernels are obtained and shown in
Table 2. It can be seen that as the number of convolution kernels increases, the accuracy rate increases during the early stage and then decreases, but the running time has been increasing.
It is conceivable that the greater the number of convolution kernels, the more amount of each convolution process will increase, so the curve fitting time will become longer. As each time the feature is extracted from the data becomes more specific, the accuracy will also increase. Trading off the accuracy and the training time, the number of convolutional kernels of C1 and C3 are set to 20 and 30 respectively for the following experiments.
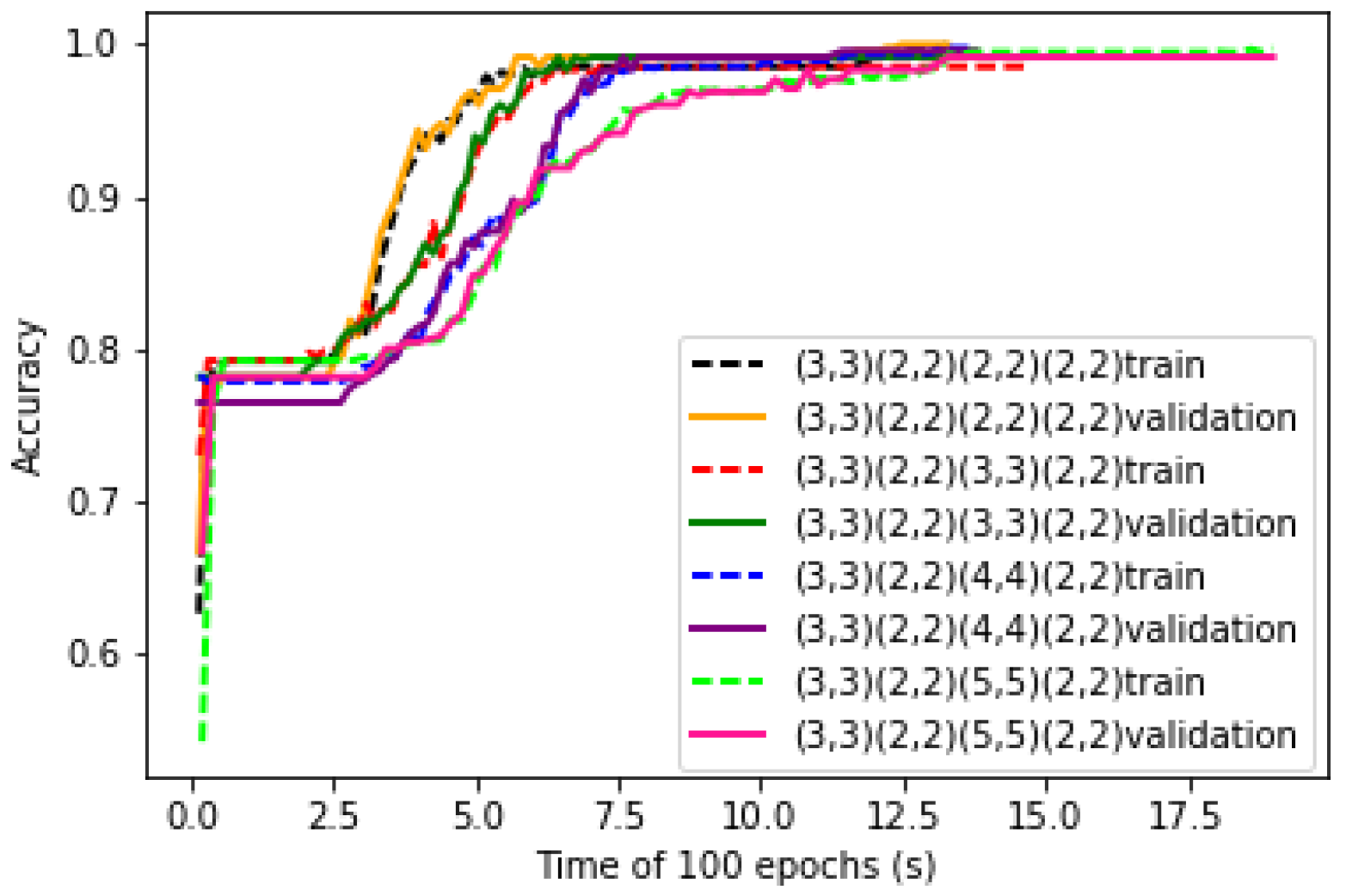
6.2. Influence of the Size of Convolutional Kernels of Gas CNN
The sizes of convolutional kernels are also key parameters of the LeNet-5 structure. Four different sizes of convolutional kernels in C3 are studied in the structure of CNN. The convergence curves of the training process of four different sizes of convolutional kernels are shown in
Figure 9. It can be seen that as the size of the convolutional kernel increases, the convergence rate of the learning curve decreases.
For the convolutional layer and the pooling layer, there are two padding ways to fill the data which are the ‘Valid’ padding and the ‘Same’ padding. The ‘Same’ padding method is to enhance the extraction of edged data features, while its input data and output data are equal in size. The disadvantage is that its convolutional kernel size only can be odd number. But for the ‘Valid’ padding, the size of the convolutional kernel can be even.
Based on the LeNet-5 structure and the input characteristic of gas data, four different sizes of convolutional kernels are studied and the ‘Valid’ padding approach is adopted. The experimental results are shown in
Table 3. The time becomes longer as the size of convolutional kernel becomes larger. The accuracy of the 2 × 2 convolutional kernel is the highest. It shows that it has a more comprehensive extraction function. When the output of the 3 × 3 convolutional kernel is used as the input to the pooling layer, the outermost features are lost and the accuracy is the lowest. Therefore, a 2 × 2 convolutional kernel is most optimal in the C3 layer with the ‘Valid’ padding approach.
6.3. Influence of Size of Inputs
Four sizes of input matrix are studied. These data sets are used to train the LeNet-5 structure. The convergence curves of training process of LeNet-5 with four sizes of inputs are shown in
Figure 10. It can be seen that with the increase of input matrix sizes, the convergence speed of LeNet-5 increases, which means that larger size of data input contains more information. However, with smaller size of input, after enough time of generalization of the structure, satisfied accuracy could also be reached.
Test data sets are taken as the input of LeNet-5, the accuracy and running time are shown in
Table 4. It can be seen that with the increase of input data size, the accuracy increases, while the running time increases greatly. It is conceivable that the input data does not lose important features and achieve the desired minimum. Although the accuracy rate will be reduced, the running time will be greatly reduced. Hence, the suitable size of the selected data is set at 12 × 12.
6.4. Improved LeNet-5 Structure for ENs
In order to adapt to the practical EN in our case, the improved structure and design of LeNet-5 are shown in
Figure 11. The input layer is the gas sensor feature matrix with size of 12 × 12. C1 and C3 are the convolutional layers with kernel size of 3 × 3 and 2 × 2, respectively, and their numbers of convolutional kernels are 20 and 30, respectively. The outputs of C1 and C3 after convolution are 20 matrices with size of 10 × 10 and 30 matrices with size of 4 × 4, respectively. S2 and S4 are pooling layers with the same kernel size of 2 × 2. The dropout coefficient is 0.3, hence the number of neurons is 120 in the F5 layer and 84 in the F6 layer. The output layer contains three neurons based on the targets, corresponding to three target categories of CH
4, CO and their mixtures, respectively.
Each layer in the designed CNN structure has parameters that require training. In each layer of the network structure, the parameters are shown in
Table 5. And the number of neurons is shown in Equation (14), where
filterw and
filterh represent the width and the height of the convolutional kernel, respectively.
numberfilters represents the number of convolutional kernels.
6.5. Comparison with Other Shallow Models
To verify the performance of the improved Gas CNN structure, the same processes are performed on the generally used shallow models MLP, PNN and SVM. MLP is a generally used feed- forward artificial neural network model in gas recognition. For effective comparison, two kinds of MLP NN structures are set while their numbers of hidden layers were set to 50 and 10, respectively.
Figure 12 shows the structure of MLP NN with 10 hidden neurons. In addition to MLP, PNN and SVM are also used as comparison algorithms. All the shallow models are processed with the same input and the ReLU activation function is adopted, which is the same as the Gas LeNet-5.
Comparison results are shown in
Table 6. It can be seen that higher accuracy is obtained by improved LeNet-5, and the training time of LeNet-5 is the longest. However, after training the test time of the improved LeNet-5 is at the same level with the MLP, PNN and SVM. This infers that higher accuracy can be obtained by deep CNN models while the shallow models that are commonly used have almost the same recognition time.
6.6. Influence of Data Augmentation
All the above analyses are based on a 10-times augmented dataset by translation of the original sensor curves. In order to measure the influence of the data augmentation, 10 percent of original data set was randomly selected out and their translated sampling data were used as the test set, and the remaining data and their translated sampling data were used as the training set. The performances of the models were measured and shown in
Table 7. Compared with
Table 6, it can be seen that the accuracy of all the models decreases, because none of the information of test set had been put into the training part. The influence of the data augmentation is the lowest. But the improved LeNet-5 still has the highest accuracy compared with other shallow models.
7. Conclusions
The current research aim was to identify CH4, CO and gas mixtures of CH4 and CO by means of electronic nose and LeNet-5 in CNN. Firstly, according to the characteristics of gas data and CNN structure, an algorithm suitable for gas identification is designed. Then, we discussed the parameters of CNN structure, including the size of input data, the number of convolution kernels and the size of convolution kernels. Finally, considering the accuracy and computation time, the LeNet-5 for ENs is developed.
After parameter setting, a complete improved LeNet-5 structure is obtained for gas identification. In order to avoid overfitting and obtain more reliable statistical results, we extend the gas data by means of translation. The matrix data is transformed into gray image to make the difference between different kinds of data more considerable. Based on the improved gas LeNet-5, the test accuracy of three categories of gases could reach 99.67% with the fully augmented dataset and 98.67% with unused original dataset. Compared with general MLPs, PNN and SVM, the improved gas CNN obtained higher classification accuracy, which proves the effectiveness of the structure and algorithm, while requiring a same time cost level.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}