3.1. Proposed Optimization Algorithm for Link Weight
With the increase in traffic in the network, if the traffic cannot be reasonably allocated, it is possible that some links may be congested, whereas other links are not fully utilized. In order to make full use of network resources, the setting of link weight is decisive for path cost and load balance. In this paper, we use multi-objective particle swarm optimization (MOPSO) algorithm [
10] to optimize the link weight for path cost and load balance. We set up multiple populations to find the optimal solution through the evolution of collaboration between populations. The two objective functions are used to measure path cost and load balance, respectively. Then, we calculate the first
k shortest paths between the source node and the destination node. Finally, an optimal path is selected from the first
k shortest paths according to the comprehensive evaluation model. We refer to the whole procedure above as Algorithm 1. In addition, we propose an improved MOPSO algorithm in order to better optimize the link weight in the first step. And we call Algorithm 2.
| Algorithm 1: Find the optimal path p |
| 1. Input: objective function fitness1, fitness2, source node and destination node |
| 2. Traffic matrix G is updated by SDN controller after a certain number of requests |
| 3. Weighted matrix G1 ← MOPSO (fitness1, fitness2, G, source, destination) |
| 4. Find the first k shortest paths from the source to the destination based on the weight matrix G1 |
| 5. Find the optimal path p according to the comprehensive performance evaluation model. |
| 6. Output: the path p |
| Algorithm 2: Find the optimal path p |
| 1. Input: objective function fitness1, fitness2, source node and destination node |
| 2. Traffic matrix G is updated by SDN controller after a certain number of requests |
| 3. Weighted matrix G1 ← the improved MOPSO (fitness1, fitness2, G, source, destination) |
| 4. Find the first k shortest paths from the source to the destination based on the weight matrix G1 |
| 5. Find the optimal path p according to the comprehensive performance evaluation model. |
| 6. Output: the path p |
The particle swarm optimization (PSO) algorithm is a group of intelligent algorithms that achieves optimization through collective collaboration between birds. The MOPSO algorithm is used to solve the multi-objective optimization problem [
22] and set up multiple populations. The optimal solution is found by the cooperative evolution between populations. The main steps of the MOPSO algorithm are as follows:
- (1)
Initialize the population of particles, and customize the particle initial velocity and position;
- (2)
According to the objective function, determine the value of objective function of each particle initialized;
- (3)
According to the definition of the Pareto dominance relationship, the non-inferior solution is stored in an external archive;
- (4)
Select the global optimal value from the external archive;
- (5)
Update the velocity and position of the particle at the next moment by the updating formula of velocity and position;
- (6)
Calculate the new fitness of particles;
- (7)
Update the individual extremum and global extremum;
- (8)
Update the external archive;
- (9)
If the termination conditions are not satisfied, then jump to the third step and then run.
Recently, various improved approaches to MOPSO have been developed, e.g., in [
23,
24,
25,
26]. Wu et al. [
23] propose a MOPSO algorithm with asynchronous updates. When a particle in the swarm is regulated, the Pareto front is immediately evaluated. New positions of the subsequent particles not only depend on the message of the previous iteration but are also partially based on the optimal solutions of the current iteration. In [
24], aiming at multi-objective large-scale optimization, many-objective optimization, and distributed parallelism, the authors propose some methodologies and discuss other prospective research trends. In [
25], multi-objective optimization problems (MOPs) are transformed into a set of sub-problems based on a decomposition approach, and then each particle is allocated according to each optimized sub-problem. Han et al. [
26] propose an adaptive MOPSO (AMOPSO) algorithm based on a hybrid framework to solve the distribution entropy and population spacing (SP) information. The proposed algorithm improves the search performance in terms of convergent speed and precision.
In this paper, three improvements are put forward based on the AMOPSO algorithm:
(1) The solution distribution entropy at the
tth iteration is calculated by the probability distribution function of the cell with non-dominated solutions in the archive. The variation in distribution entropy determines the evolutionary tendency of the population. However, the method is only suitable for the optimization of two goals. We use a parallel cell coordinate system (PCCS) [
27] to calculate the distribution entropy, which can be used for multi-dimensional data analysis and visualization. The difference in entropy represents the change in the approximate Pareto front redistribution, which is then used to assess the diversity and convergence and thus infer the potentiality of finding a new solution to the current population. The Pareto entropy and the difference in entropy change greatly, indicating that the new solution dominates a large number of old solutions in the external archive. So, this leads to a wide range of approximate Pareto front changes, and the convergence of the approximate Pareto front needs to be enhanced. The smaller the difference in entropy, the smaller the range of the approximate Pareto front redistribution. The diversity of the Pareto front needs to be enhanced.
(2) In [
26], the convergence degree is evaluated by the dominate strength of the
ith solution at the
tth iteration and the difference between solution and dominated solutions. In our algorithm, we use a more intuitive way to evaluate the convergence of solutions. The essence of convergence performance is to calculate the average distance of the target vector from the optimal Pareto front to the real Pareto; thus, the average distance obtained is used to measure the degree of proximity of the final solution and the non-dominated optimal solution. So, we evaluate the convergence of solutions by finding the distance between each solution and the optimal Pareto frontier.
(3) The authors in [
26] do not evaluate the diversity of solutions in detail. In this paper, we use the distribution of indicators, namely, the variance of the distance between adjacent target vectors, to measure the diversity of non-dominated solutions obtained. The smaller the variance is, the better the diversity.
denotes the
m-th target value of the
k-th non-dominant solution in the Pareto optimal solution set, and
can be mapped into a two-dimensional planar grid with
K ×
M cells according to (1):
where
is the rounding function;
k = 1, 2, ...,
K,
K is the number of members in the current iteration for external archive.
m = 1, 2, ...,
M,
M is the problem of the number of goals to be optimized;
is an integer number in which
is mapped to PCCS. The data set on the Pareto front can all be mapped into the PCCS by using (1), as shown in
Figure 1.
represents the
m-th cell coordinate component of the
kth target vector.
Figure 2 shows the parallel cell coordinate system of five cell coordinates and three objective functions.
During the
t-th iteration, the Pareto entropy
Ent(
t) of the approximate Pareto front stored in the external archive can be calculated according to (2):
where
denotes the number of cell coordinate components falling to the
m column of the
k-th row after the approximate Pareto front is mapped to the PCCS.
In the two adjacent iterations
t − 1 and
t, Δ
E(
t) denotes the difference in entropy, which indicates the degree of change in the approximate Pareto front. Δ
E(
t) can be calculated by (3):
The global optimal solution is given as:
where dgbest(
t) is the solution with the best diversity at the
t-th iteration; cgbest(
t) is the solution with the best convergence at the
t-th iteration.
where
denotes the diversity degree of the
ith solution
.
where
is the average value of all
, and the operation formula of
is as follows:
where
M represents the number of objective functions;
P represents the best solution set on the approximate Pareto front;
represents
m-th objective function value of
.
where
is the convergence degree of the
i-th solution.
is defined as:
where
represents the best solution set on the real Pareto front.
In the following part, we set the objective functions. We use a weighted graph
to present the network topology of SDN, where
V represents the set of nodes and
E represents the set of edges. For each link, there is a link capacity
c(
e) and weight
w(
e). Let
f(
e) denote the total amount of traffic flows carried by the link
e. Thus,
denotes the link utilization of the link
e. The goal of traffic engineering is to maintain
for any
, but this goal is too general. We define the function in (10), which describes the link cost:
According to (10), we can see that the cost increases faster and faster with the growth in link utilization. When the link utilization rate is close to 1 (the link is congested), the cost rises sharply. A link with high link utilization rate has a high cost, which imposes a punitive high cost on the overloaded link. Therefore, when seeking a path, the allocation scheme to avoid link overload will be chosen. The cost of a path is not only related to link utilization but also to the length of the path. We take the sum of the cost of all the links on a path as the cost of this path. The cost function of path
p is defined as follows [
28]:
The variance of the link utilization expresses the load balance. The smaller the variance, the more balanced the load distribution is. Let
denote the average link utilization. The formula of load balance is expressed as:
where
h(
p) denotes the hop counts of path
p. So, we set two objective functions as follows:
As SDN has a global view of the network resource, it is able to get the global network traffic to formulate a better strategy for network optimization. Under the condition of a given traffic demand matrix from the SDN controller, link weight determines the shortest path between the source node and the destination node and further influences the path cost and load distribution in the network. Therefore, the optimization of link weight has become an effective way to realize traffic engineering. In this paper, we use the path cost and load balance of the network as the two optimization objectives for the MOPSO algorithm and improved MOPSO algorithm. The improved MOPSO algorithm for optimization of link weight is summarized in Algorithm 3. The traffic matrix G1 can be updated by the controller after each routing request.
| Algorithm 3: Improved MOPSO algorithm |
Input: objective function fitness1, fitness2, traffic matrix G, source node and destination node. Initializing the population size, the positions and velocity of particles, the flight parameters, the maximal size of archive, and maximal iterations. While iteration <= maximal iterations Calculate the value of fitness1 and fitness2. Calculate the non-dominated solutions and update the archive. If the number of archive > maximal size Pruning the archive End The external archive is mapped to PCCS. Calculate the entropy and the difference of entropy. Choose the gbest according to the difference of entropy. Update the flight parameters. Update the positions and velocity of particles. End Output: the best position, namely weighted matrix G1
|
Through the MOPSO algorithm or improved MOPSO algorithm, the path cost and load balance are optimized. After calculating the weight of the traffic matrix, the first k shortest paths from the source and the destination node are calculated. This reduces the length of the sub-list to decrease the consumption of the packet header to a certain extent. Then, the optimal path is selected from the first k shortest paths according to the comprehensive evaluation model.
3.2. Comprehensive Evaluation Model
The optimization of link weight by the MOPSO algorithm or improved MOPSO algorithm ensures network service quality in terms of path cost and load balance. Next, we fully consider the different requirement of different businesses for transmission quality and evaluate path quality through the hierarchical comprehensive evaluation model. The comprehensive evaluation model has been applied in many fields [
29,
30], and the performance is evaluated comprehensively by establishing a hierarchical model according to multiple indicators [
31,
32]. In order to provide users with highly reliable network service, it is useful to establish an effective and feasible evaluation method for the network application service. In the evaluation process of network performance, the network evaluation is mainly based on many indexes such as delay, jitter, and packet loss rate. However, different indicators cannot be compared uniformly. So, this cannot fully reflect the operation of the measured network. In this paper, we use a comprehensive evaluation model for network service performance [
33]. The model takes the preferences of users into account and takes the application service of the network as the orientation. First, we set up an evaluation hierarchy and establish the criterion weight and the scheme weight in the hierarchical structure. Then, the actual measurement data are normalized. Finally, the fuzzy analytic hierarchy process (AHP) is used to evaluate the performance of each service in the target path.
3.2.1. Establish the Hierarchical Structure of Evaluation of Network Application Business
In this paper, we establish a three-layer evaluation model for network applications. We select the evaluation key performance index (KPI) set for delay, jitter, and packet loss rate for the QoS evaluation criteria. Thus, it overcome the one-sidedness of a single evaluation index and achieve multi-index fusion. The layer of the business scheme is divided into three network applications G = {web interactive service, voice communications service, streaming media service}.
Figure 3 shows the hierarchical structure of the network performance evaluation model based on application service.
3.2.2. Calculate the Scheme Weight and the Criterion Weight
In the fuzzy AHP hierarchy, the importance of different evaluation indicators of the same business is relevant, so we adopt the method of pairwise comparison to judge the matrix. But the values of different business programs are independent of each other. Therefore, we divide the scheme weight and the criterion weight separately in the fuzzy AHP. The weight of the business scheme is calculated by user preference or actual demand, but the criterion weight is still obtained through the establishment of the fuzzy judgment matrix.
First, we determine the scheme weight. According to user preference or the network application, three weight values of the network application are given. Different users or business needs lead to different weight values of the network business.
Then, we determine the criterion weight. Different network applications have different levels of sensitivity to each index. The business of voice communication requires data latency and jitter to be as small as possible; the real-time streaming media business has certain requirements for bandwidth and packet loss rates; the web interactive business requires a rapid response network. To provide differentiated service and high network availability, the evaluation performance of a network is necessary for each network application business. The specific steps are as follows:
(1) Establish a fuzzy judgment matrix , where represents the relevance between the i element and the j element in this hierarchy. We use the number in the range of 0.1 to 0.9 to quantitatively describe the relative importance of any two QoS indicators. The greater the value of , the greater is the importance of the i element than the j element.
(2) Transform into a fuzzy consistency matrix. First, according to (15), we calculate the sum of the rows of the judgment matrix, that is:
Then, we calculate fuzzy consistency matrix
Q by using (16):
(3) Based on the normalization process of the sum of the rows, the weight vector is calculated by using (17):
3.2.3. The Indicators Are Normalized
We measure the delay, jitter, and packet loss rate of the first
k shortest paths after calculating the weighted optimal matrix. In the system of the quality evaluation index of the network, the index value of the different classes is standardized by using (18):
3.2.4. Calculate the Value of Performance Evaluation
denotes the value of the performance evaluation matrix of the three types of network business at each moment of each link
is given by:
where
Wi (
i = web, voice, stream) represents the weight vector of the
i business scheme; and
represents the vector of function fraction of
j link at the corresponding time.
3.2.5. Calculate the Performance Evaluation of Entire Network
The value of the performance evaluation of the whole network is calculated according to the preference of weight vector of the three types of application business. The result of comparison between the paths is obtained according to (20):
where
Pj represents the assessed value of total network performance of path
j;
W′ represents the weight vector of the business scheme;
A represents the vector of the assessed value of the business performance of the path in the web interaction, voice communication, and multimedia service.
3.3. Algorithm Summary
In this paper, we focus on the evaluation of path quality in order to get a better transmission quality under the condition of satisfying the overall service quality of the network. So, we combine the optimization of link weight with the comprehensive evaluation of paths to find the best path for SR in SDN. In order to avoid partial link congestion caused by excessive energy consumption and the unbalance of traffic distribution in the network, we take the path cost and load balance as the two optimization objectives to establish the optimization algorithm model and apply the MOPSO algorithm or our proposed improved MOPSO algorithm to solve the optimal link weight. Then, in order to guarantee the specific need of the business performance of the users or the actual requirement, we use a performance assessment model to make a comprehensive assessment from the first k shortest paths to find the path of best performance. For example, there is a routing request whose source address is A and destination address is B. The SDN controller first uses the improved MOPSO algorithm to optimize the weight of the link, and make the path cost and load balancing index in the network smaller. Then the first k shortest path is calculated. Assuming that user uses Web interactive services to book online tickets, user requires the network to respond quickly, minimizes network delay and packet loss rate. At this time, the weight of the scheme can be set to . Then the fuzzy judgment matrix can be established according to the importance of network parameters to determine the weight vector of the criterion. Through the measurement of the indicators of k paths (bandwidth, jitter, packet loss rate), the indicators can be standardized, and the service performance evaluation value of k paths can be calculated. That is, an optimal path is chosen according to the user’s requirement for service and the network performance index of k paths.
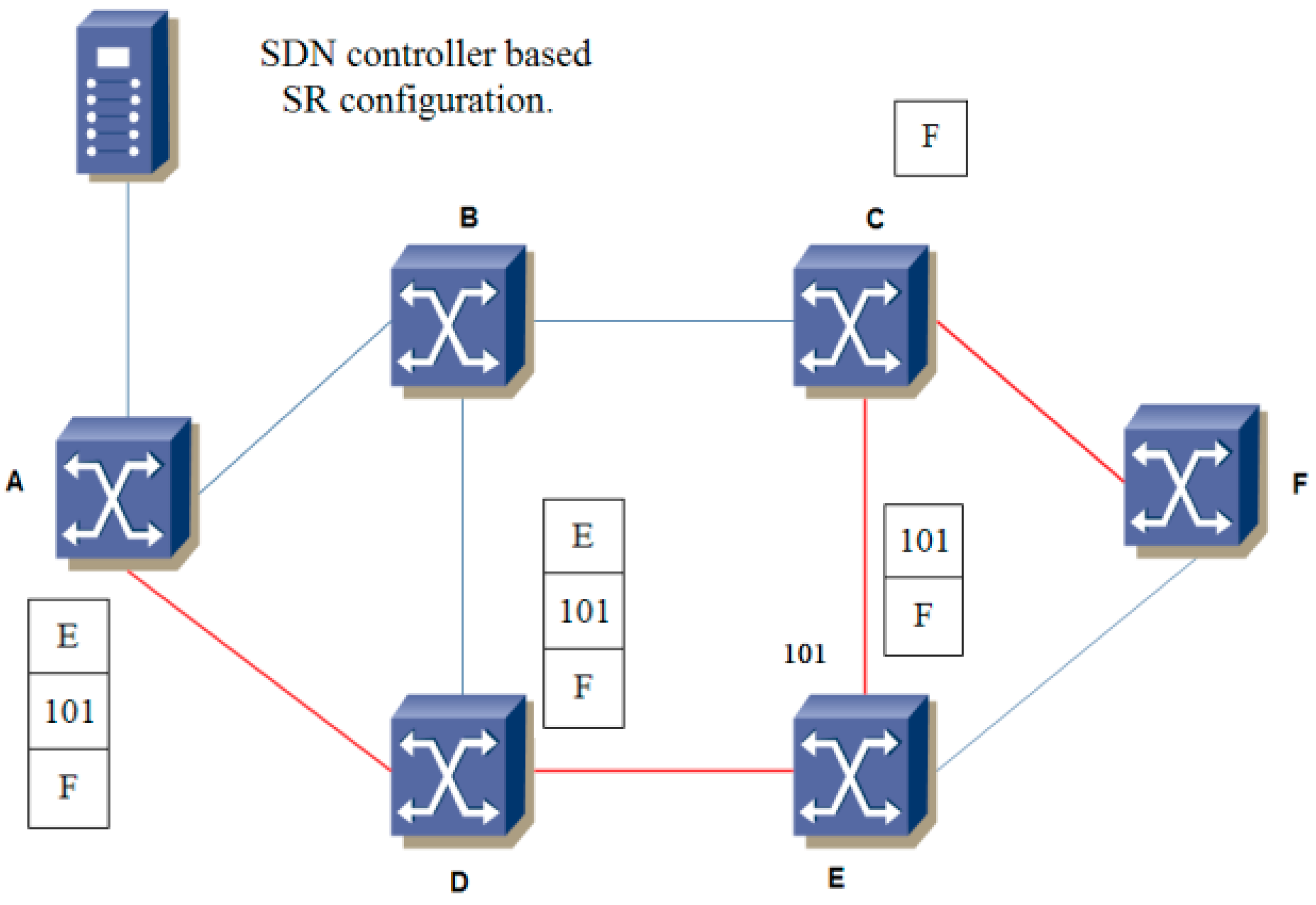
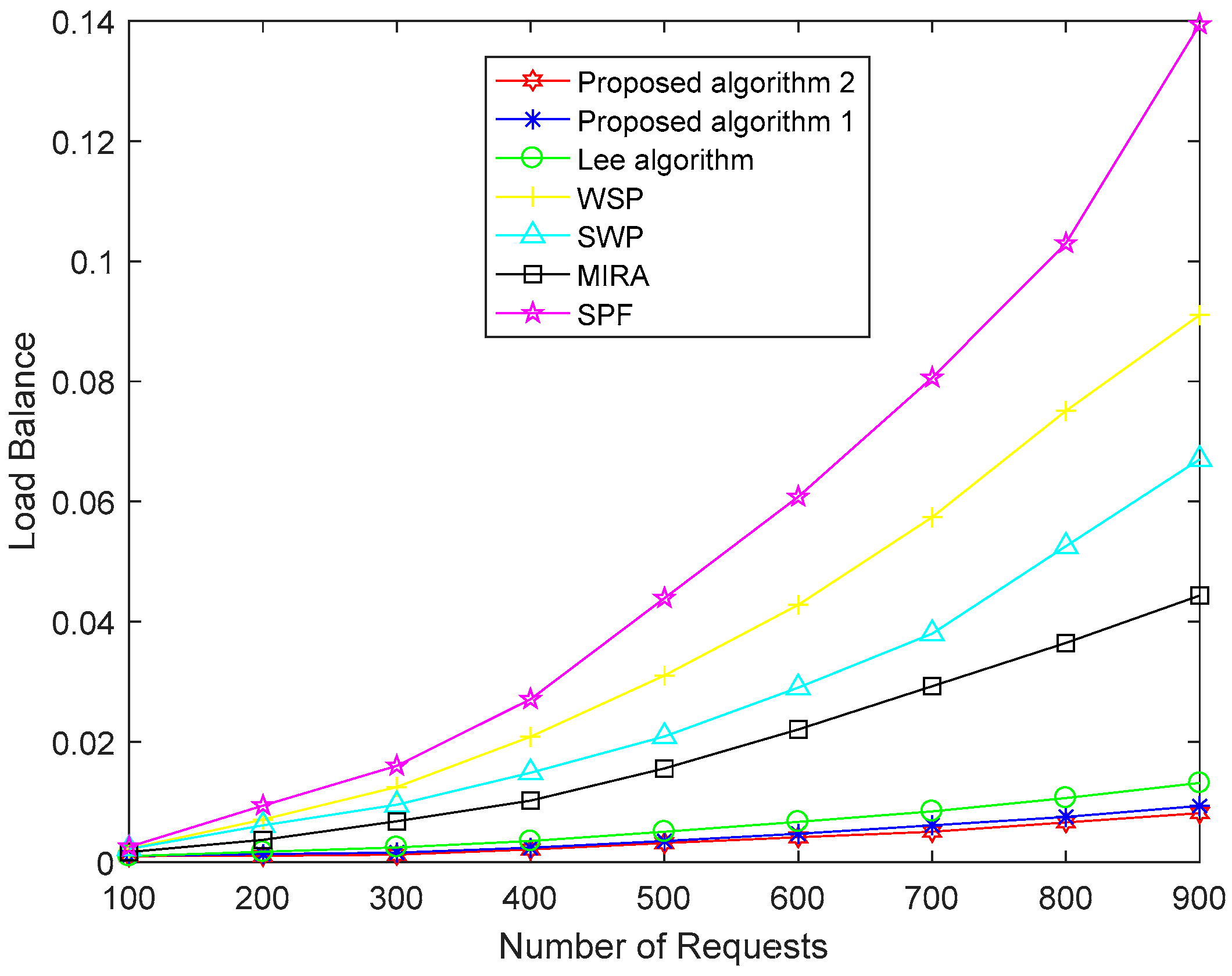
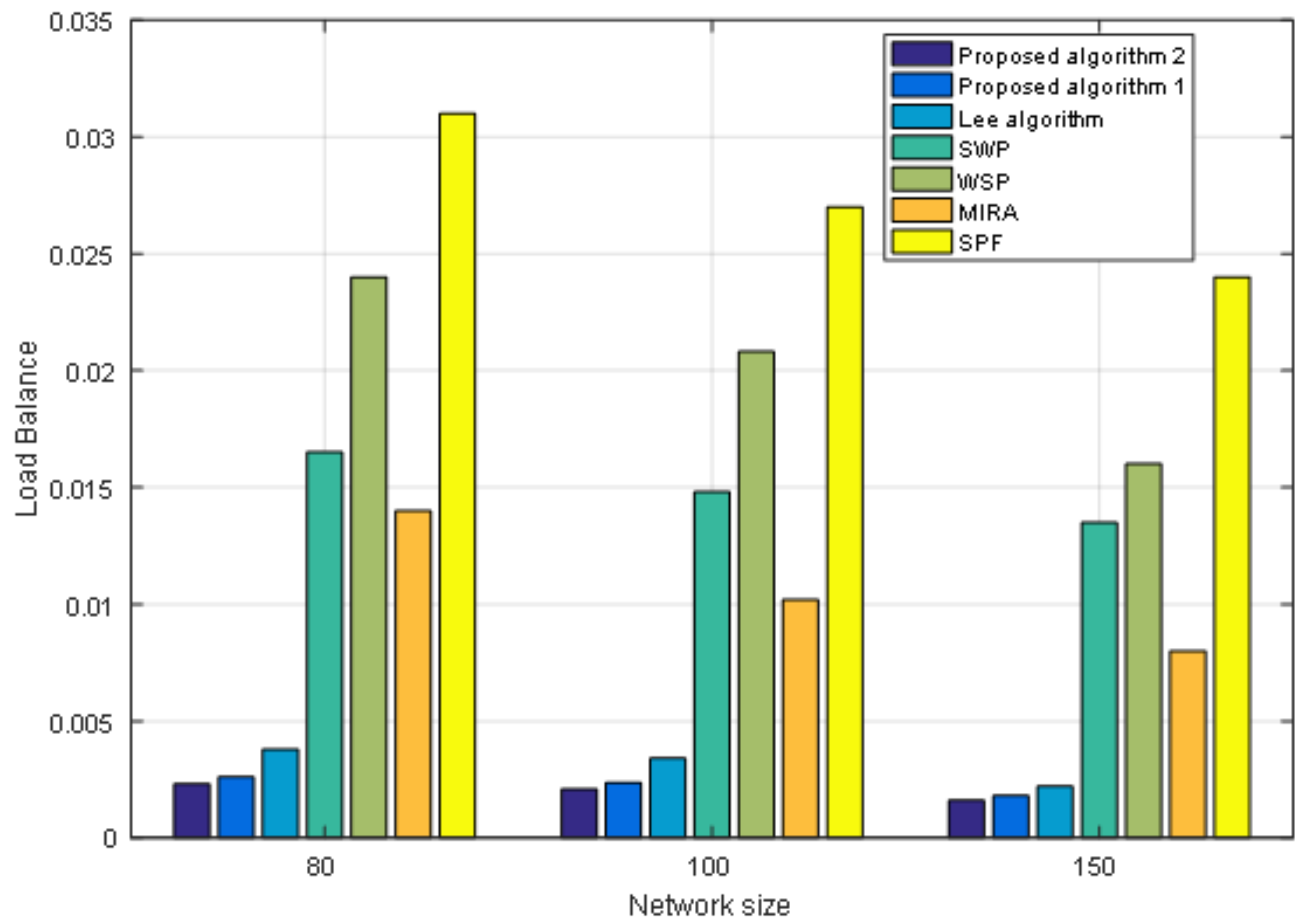
The steps of Algorithm 1 are as follows: First, we use the MOPSO algorithm to optimize the link weight for link cost and load balance. Then, we find the first k shortest paths. Finally, we use the comprehensive evaluation model to find the best path. Furthermore, in order to make the optimization result more accurate, we propose an improved MOPSO algorithm in the first step of Algorithm 2. The MOPSO algorithm and the improved MOPSO algorithm both need multiple iterations to update the velocity and position of a large number of particles to find the optimal solution. If the size of the archive is not restricted, all non-inferior solutions that satisfy the basic conditions can be entered into the archive. However, as the archive is updated in each iteration, the disadvantage of establishing the archive according to the MOPSO algorithm is that the size of archive is too large and the cost of calculation is increased. In the worst case, if the location of all the particles found in every generation can be entered into the archive, the computing complexity of each generation is O(mN2), where m is the number of objects, and N is the size of the population. So the calculation complexity of running an algorithm is O(mTmaxN2), of which Tmax is the largest iteration. The improved MOPSO algorithm restricts the size of the archive. When the size of the archive reaches a predetermined upper limit, it is necessary to delete some non-inferior solutions in the archive and reduce the computational complexity to a certain extent. So the computational complexity of two algorithms is large. And the two algorithms need a longer running time than other traditional algorithms when link weights are optimized. So, our proposed algorithms are more suitable for systems that require more accurate experimental results, better equipment performance, and real-time requirements that are not too strong. How to design a multi-target algorithm with lower complexity and faster speed is also a problem to be solved in the future. As the computing power of hardware devices increases, the problem of large computational complexity will be solved. Moreover, with the expansion of the network scale, the deployment of distributed multi-controllers architecture in SDN will solve the problem of large control plane overhead. Our proposed routing algorithms in the paper is designed for SR in SDN. Of course, our method can also be applied to traditional distributed networks and networks not using SR. In the traditional distributed networks, our proposed routing algorithm can be applied in the route calculation module of router by online or offline.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}