Author Contributions
Conceptualization, X.L., R.D. and L.N.; methodology, X.L. and R.D.; software, R.D. and J.L.; validation, X.L. and X.S.; formal analysis, L.N.; investigation, X.L.; resources, X.S.; data curation, J.L.; writing—original draft preparation, R.D.; writing—review and editing, D.C. and G.L.; visualization, L.N.; supervision, D.Z.; project administration, D.Z.
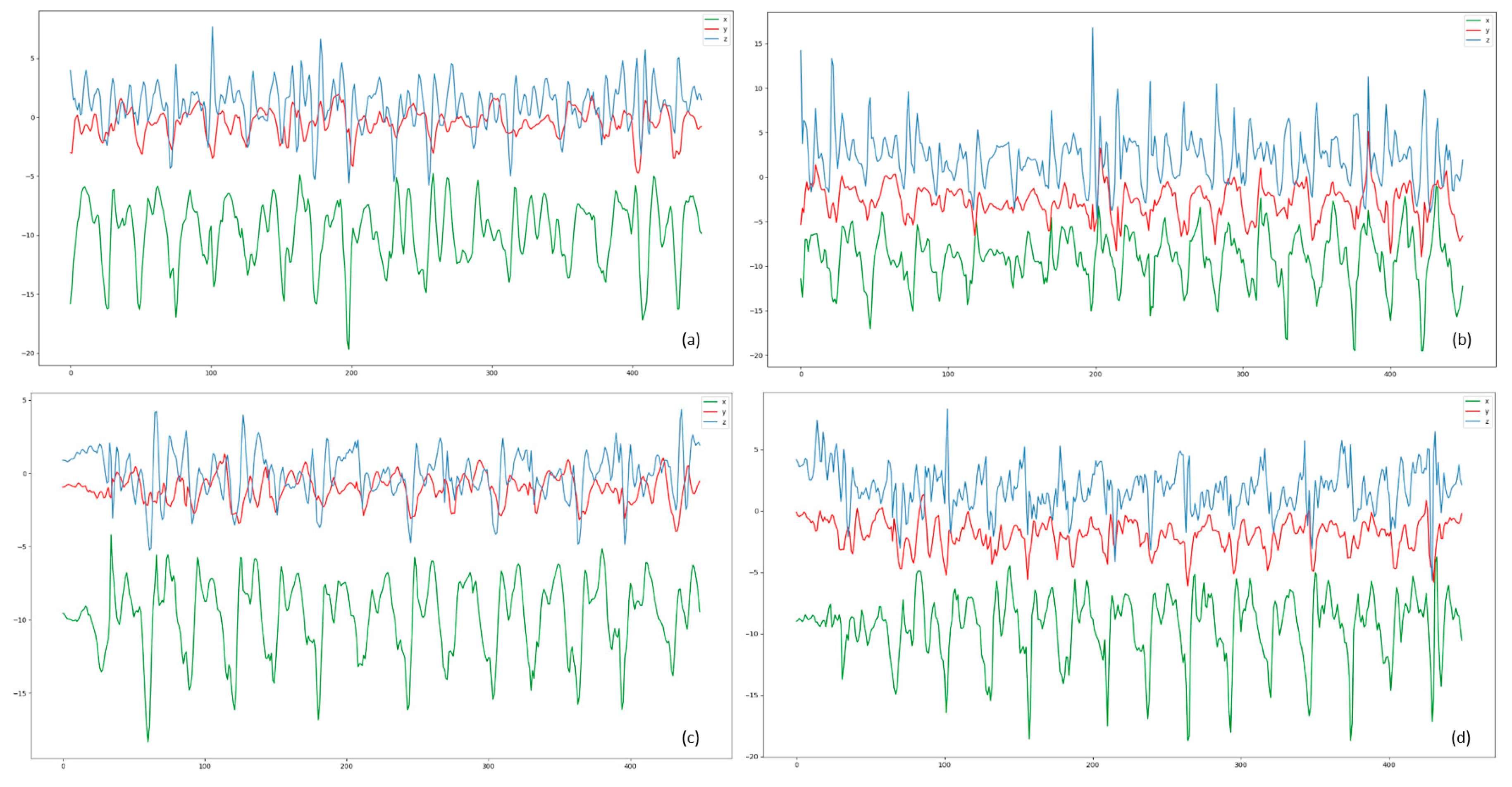
Figure 1.
The curve of data from acceleration. (a) User A downstairs. (b) User B downstairs. (c) User A upstairs. (d) User B upstairs.
Figure 1.
The curve of data from acceleration. (a) User A downstairs. (b) User B downstairs. (c) User A upstairs. (d) User B upstairs.
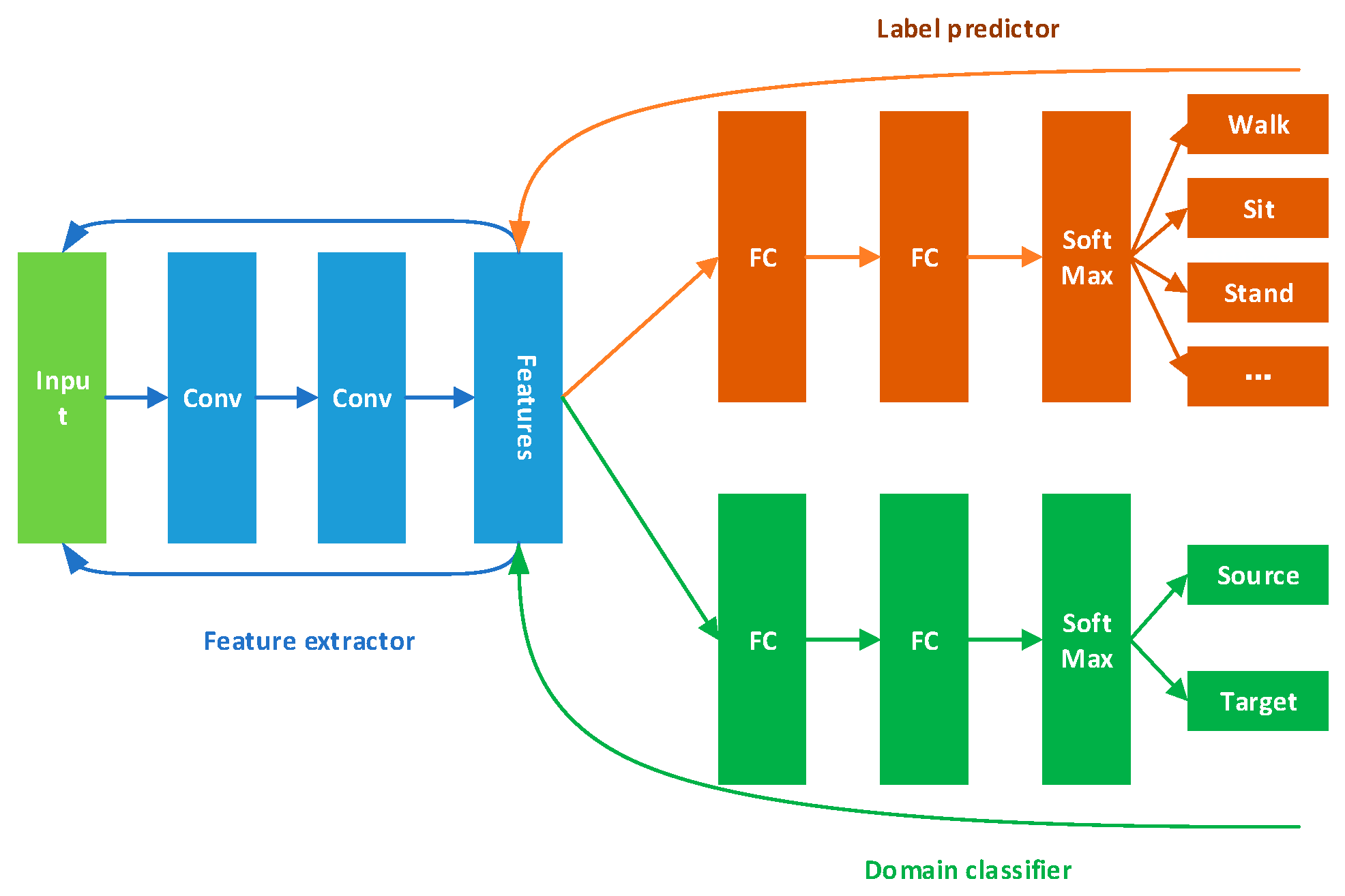
Figure 2.
CNN framework we used. We used two convolutional layers, two pooling layers, two fully connected layers. The last fully connected layer and Softmax form a classifier.
Figure 2.
CNN framework we used. We used two convolutional layers, two pooling layers, two fully connected layers. The last fully connected layer and Softmax form a classifier.
Figure 3.
DANN framework, it contains feature extractor, label predictor and domain classifier.
Figure 3.
DANN framework, it contains feature extractor, label predictor and domain classifier.
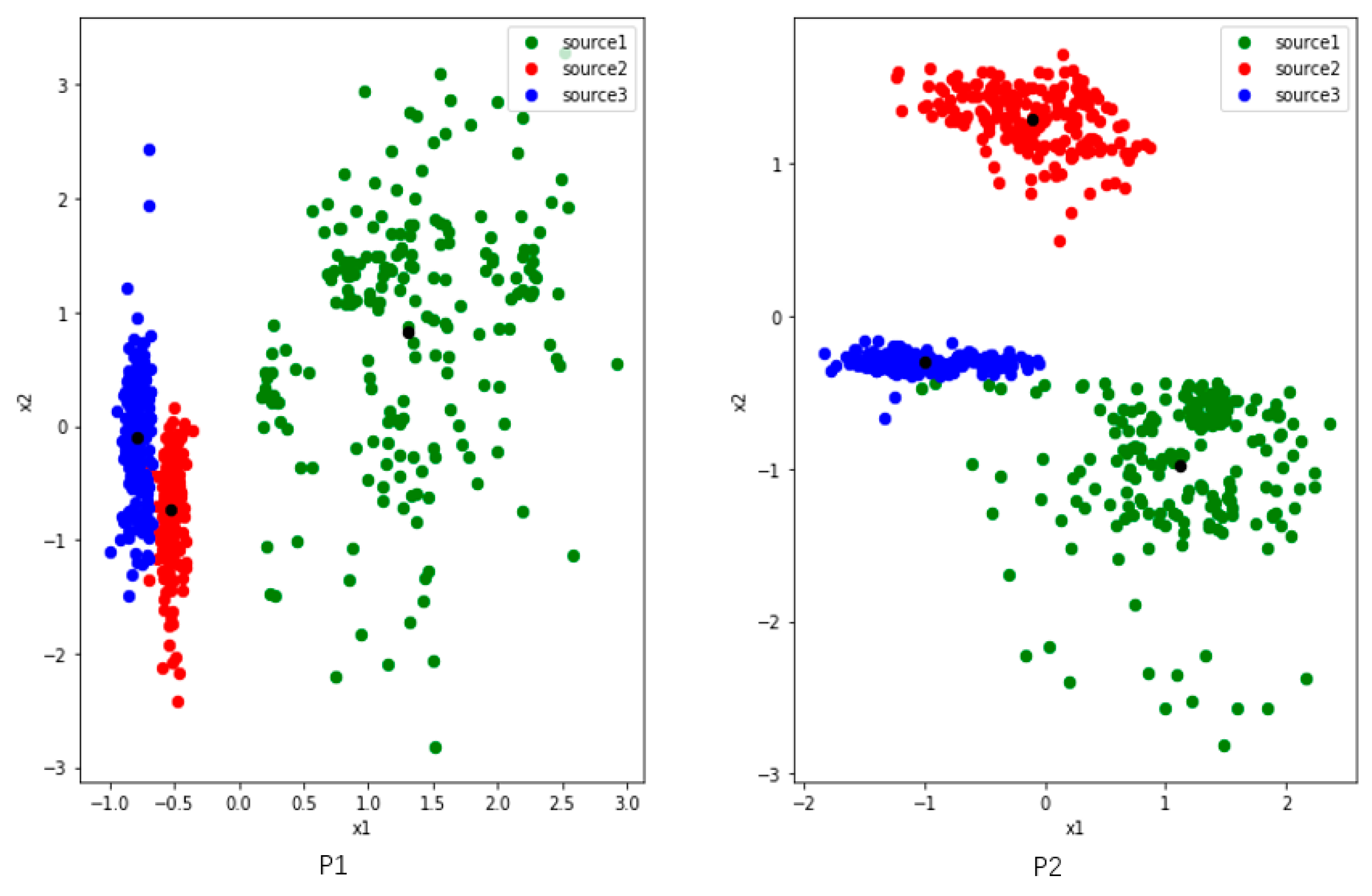
Figure 4.
The distribution of three activities features which are collected from users P1 (left) and P2 (right) in UCI. The red and blue points of P1 are close to each other, while the green one is dispersed and away from them. The blue and green activities of P2 are relatively close, and the green activity is also dispersed. The black points represent the center of features belong to same class. The black points are the centers of the three classes of features.
Figure 4.
The distribution of three activities features which are collected from users P1 (left) and P2 (right) in UCI. The red and blue points of P1 are close to each other, while the green one is dispersed and away from them. The blue and green activities of P2 are relatively close, and the green activity is also dispersed. The black points represent the center of features belong to same class. The black points are the centers of the three classes of features.
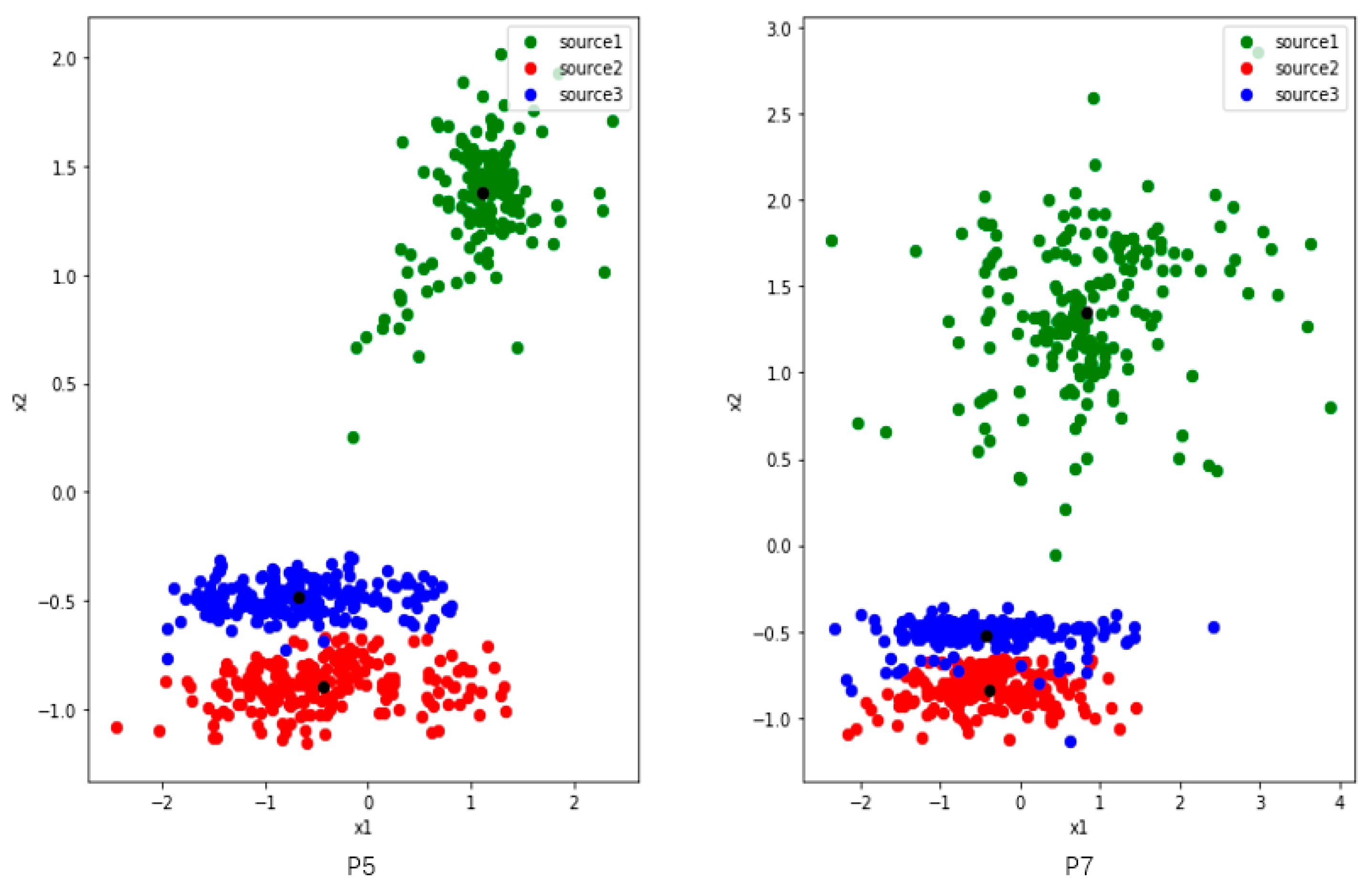
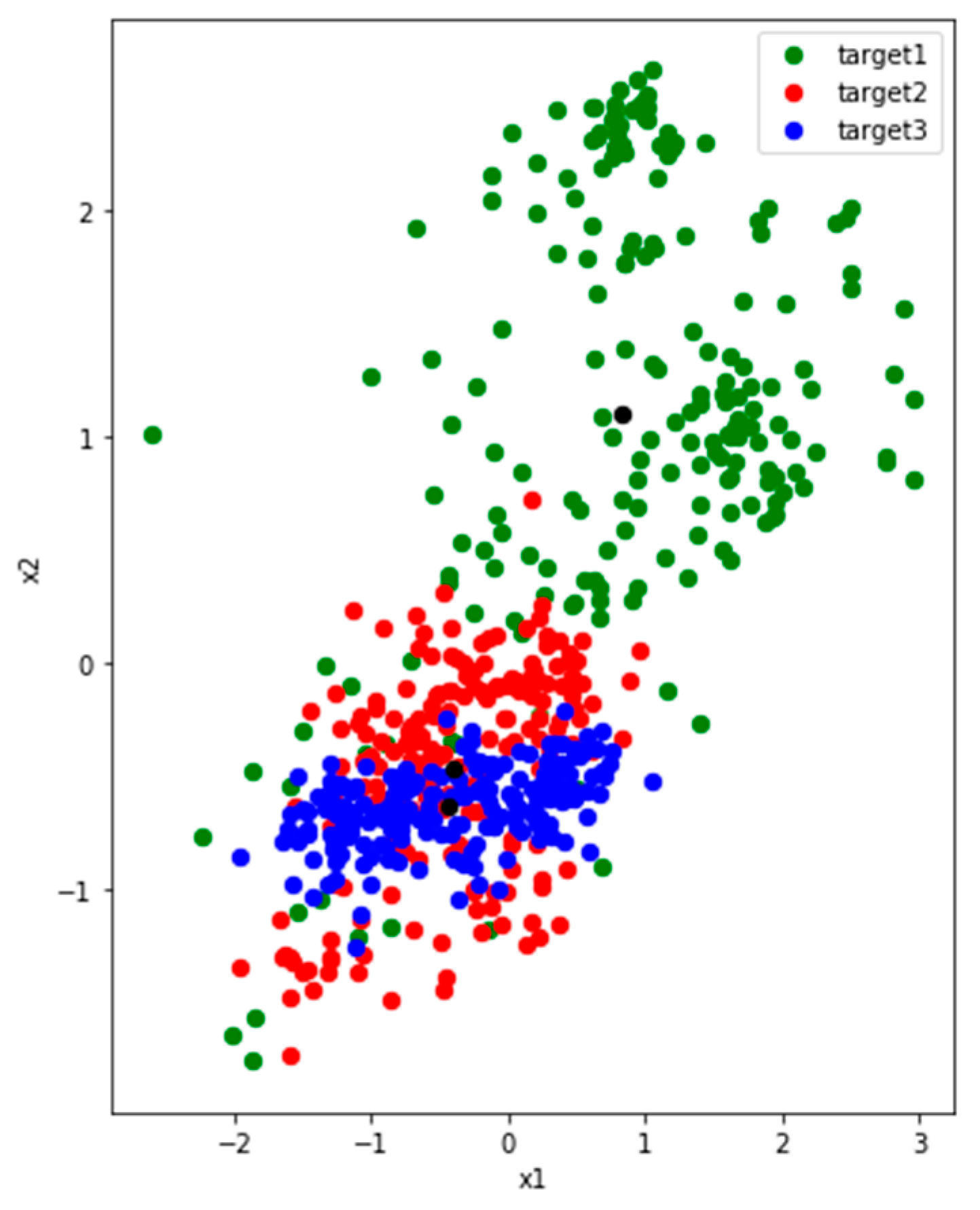
Figure 5.
The distribution of three activities features which are collected from users P5 (left) and P7 (right) in UCI. The distributions of the two users are very similar. The red and blue points are close to each other, while the green one is dispersed and away from them. The black points are the centers of the three classes of features.
Figure 5.
The distribution of three activities features which are collected from users P5 (left) and P7 (right) in UCI. The distributions of the two users are very similar. The red and blue points are close to each other, while the green one is dispersed and away from them. The black points are the centers of the three classes of features.
Figure 6.
The features for P7 extracted by model trained only with P5 data, which are mixed, dispersed, and indistinguishable. The black points are the centers of the three classes of features.
Figure 6.
The features for P7 extracted by model trained only with P5 data, which are mixed, dispersed, and indistinguishable. The black points are the centers of the three classes of features.
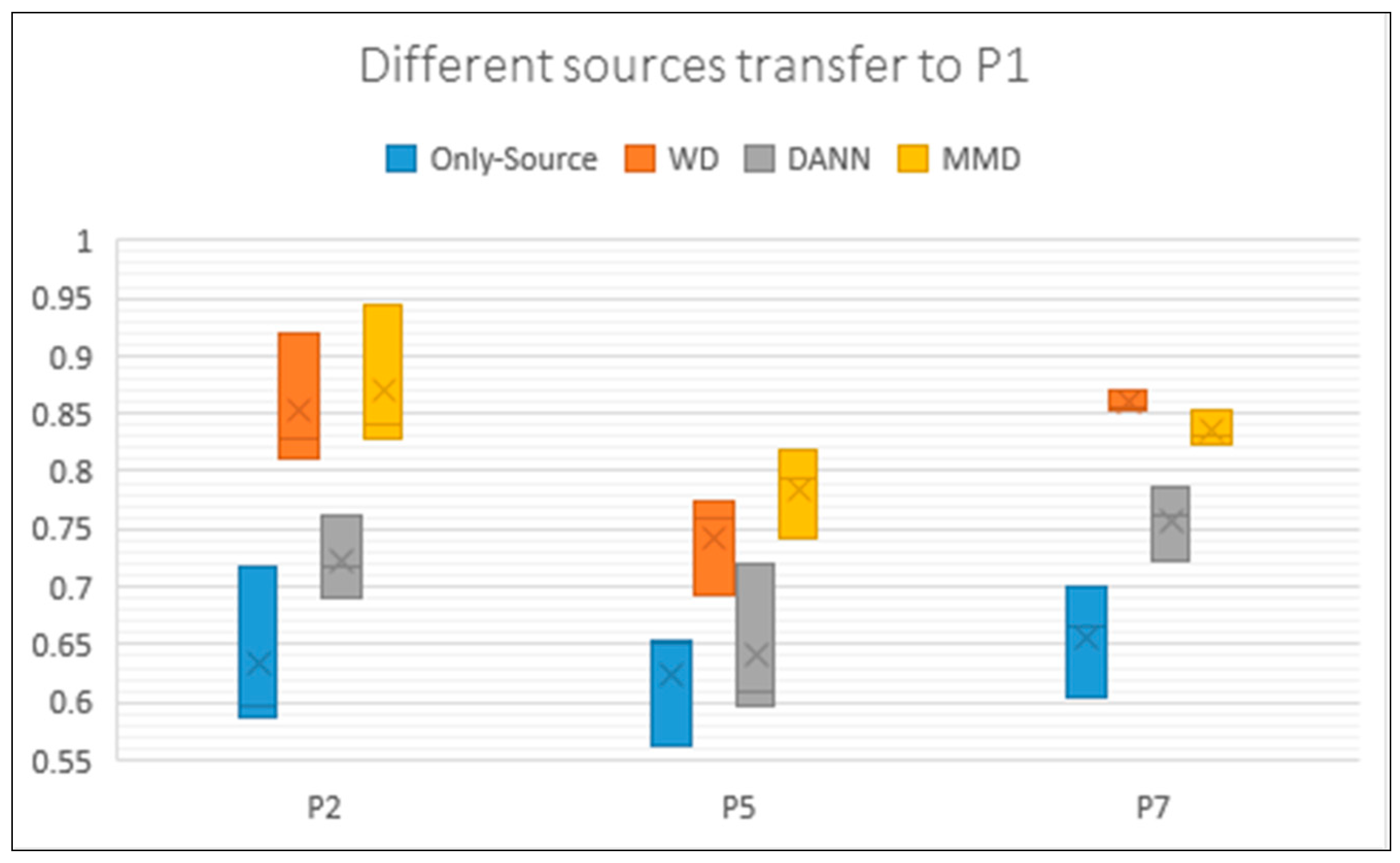
Figure 7.
Box plot of the accuracy of P2, P5, and P7 transfer to P1. Each Box feeds back the results of three experiments. It can be seen that some box lines are long and show obvious fluctuations. The y axis represents the accuracy rate of these experiments. The same with the following tables.
Figure 7.
Box plot of the accuracy of P2, P5, and P7 transfer to P1. Each Box feeds back the results of three experiments. It can be seen that some box lines are long and show obvious fluctuations. The y axis represents the accuracy rate of these experiments. The same with the following tables.
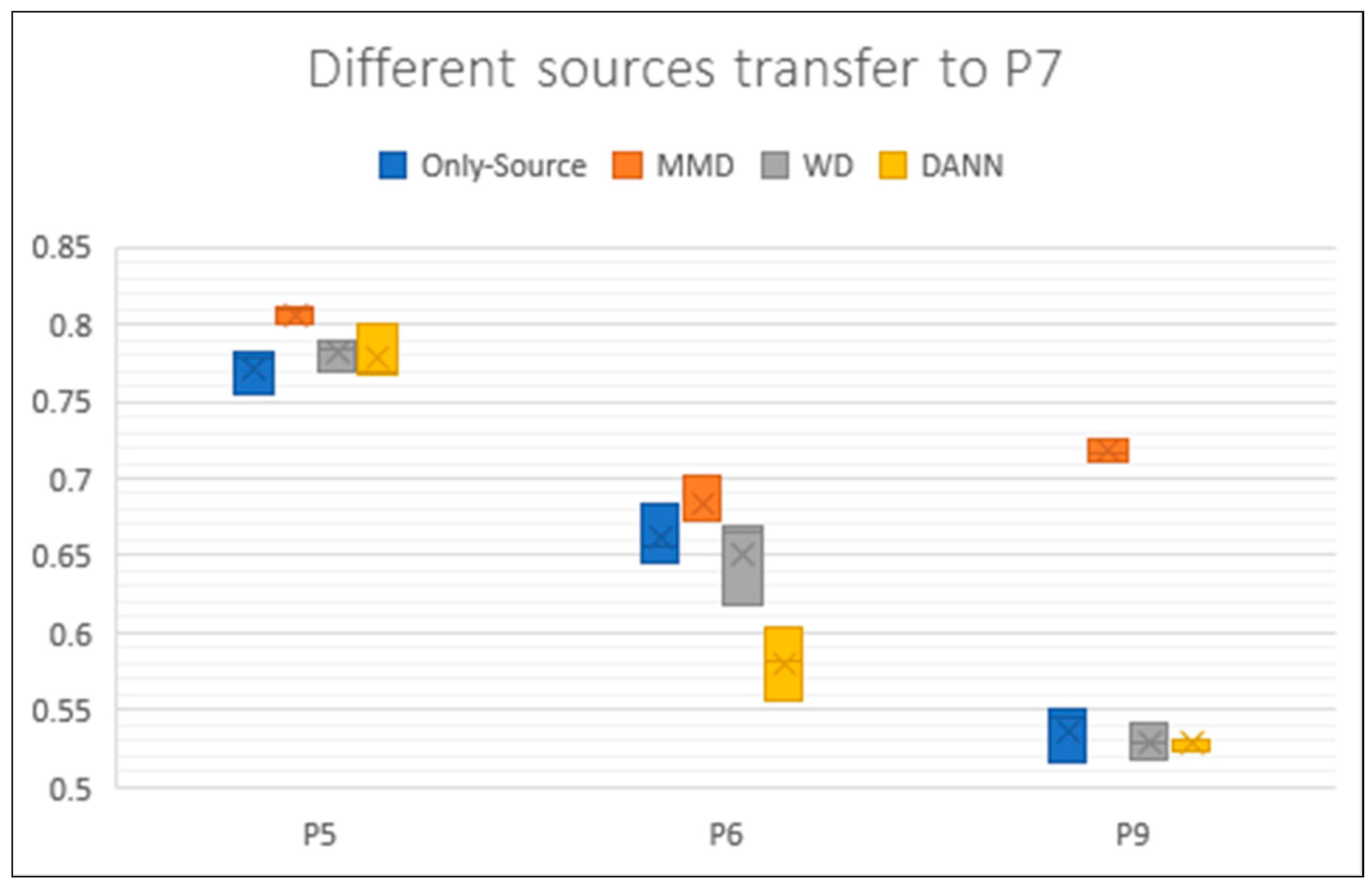
Figure 8.
Boxplot of results for P5, P6 and P9 transferring to P7. Each box contains three results. Different colors represent different methods. The y axis represents the accuracy rate of these experiments.
Figure 8.
Boxplot of results for P5, P6 and P9 transferring to P7. Each box contains three results. Different colors represent different methods. The y axis represents the accuracy rate of these experiments.
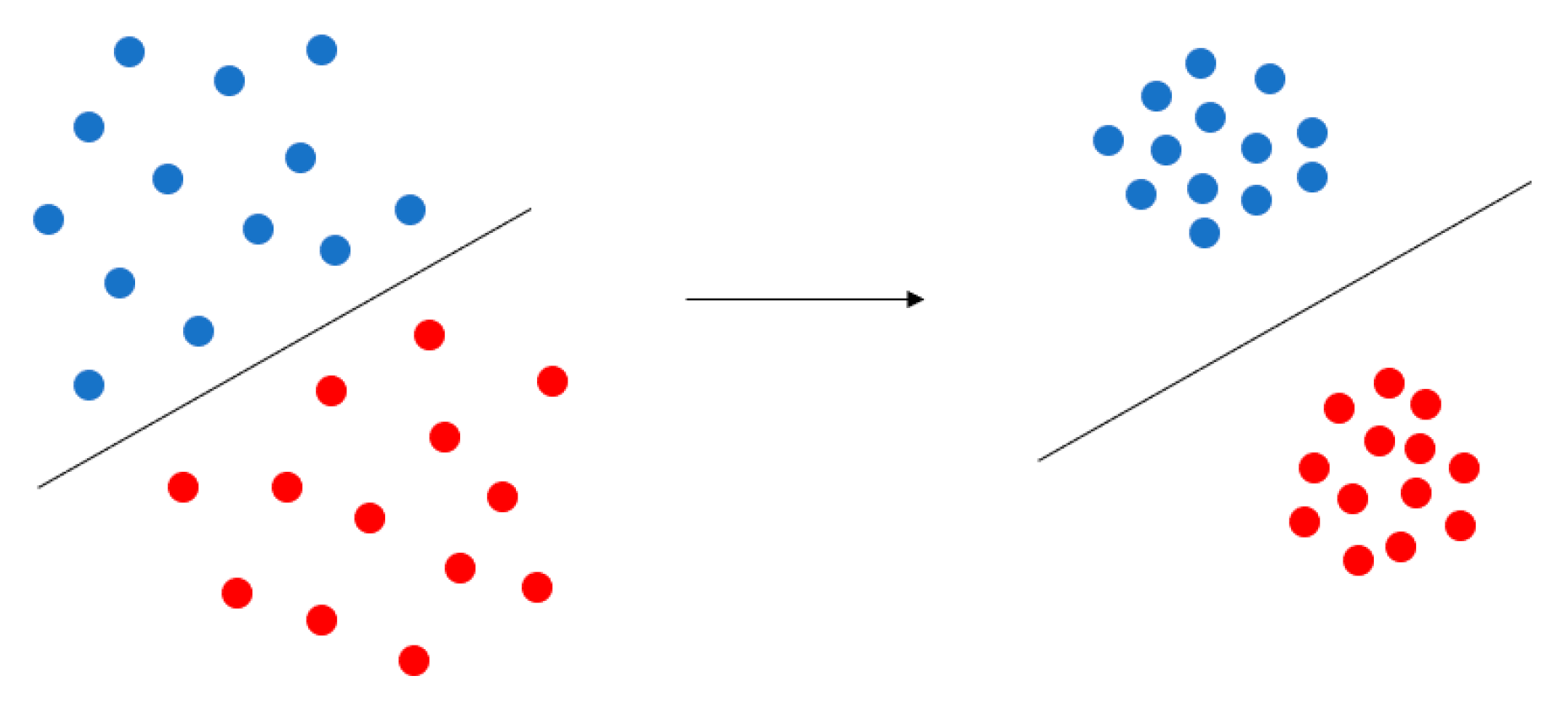
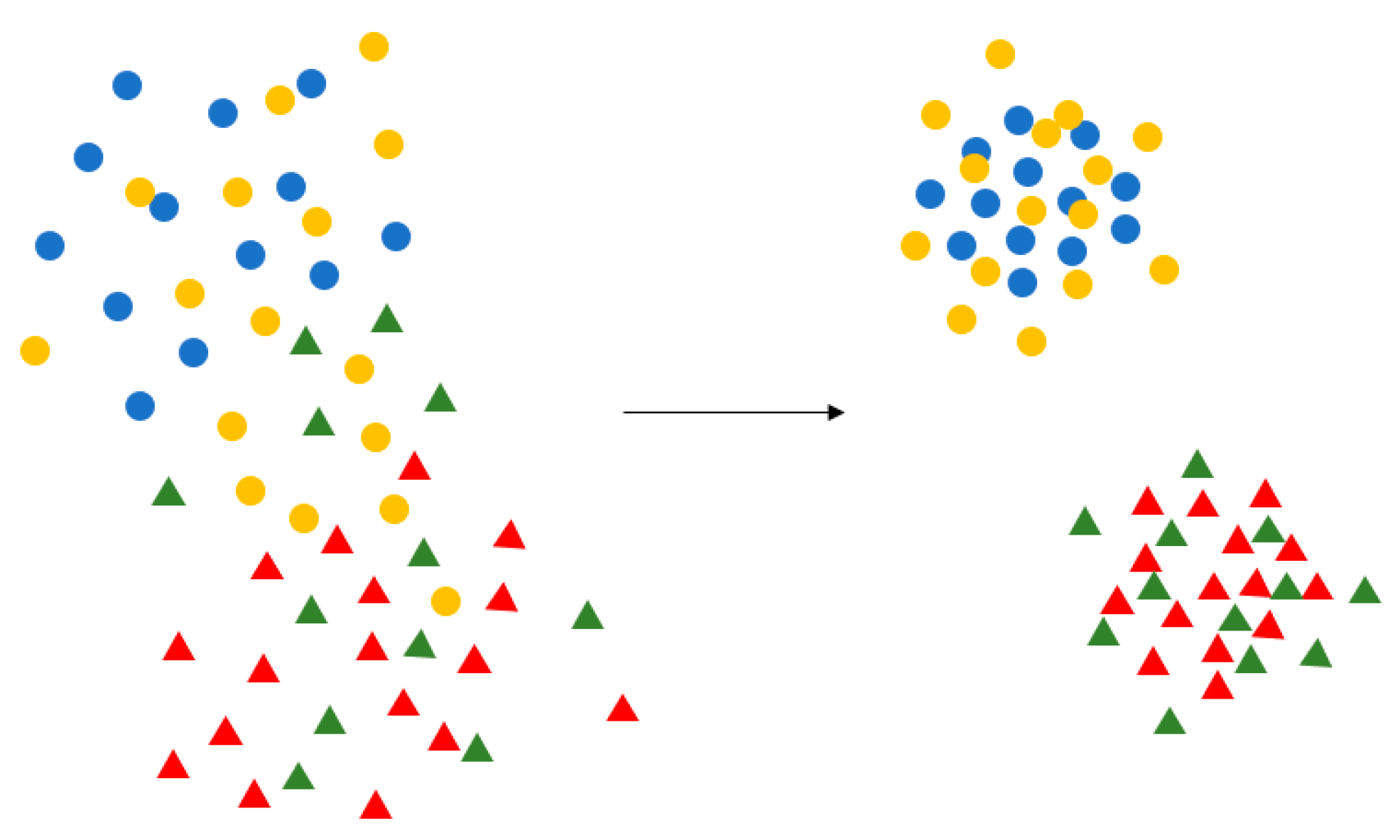
Figure 9.
Purpose of Center Loss. Center Loss aggregates the feature of each category to their respective central points, which makes the similar feature more aggregated, and the different types of features spread out, making the classification clearer.
Figure 9.
Purpose of Center Loss. Center Loss aggregates the feature of each category to their respective central points, which makes the similar feature more aggregated, and the different types of features spread out, making the classification clearer.
Figure 10.
Purpose of Center Loss + MMD.
Figure 10.
Purpose of Center Loss + MMD.
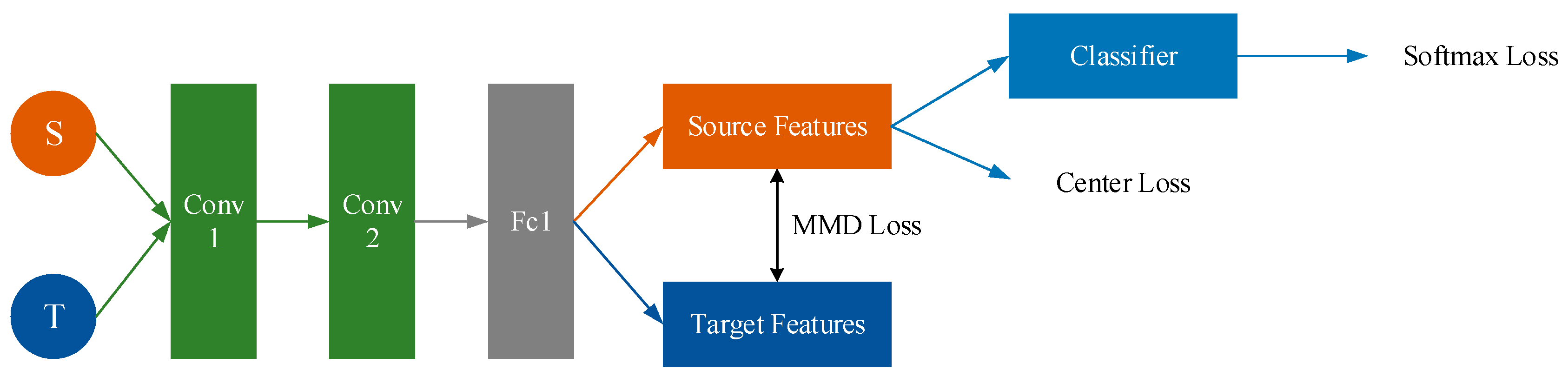
Figure 11.
Framework of Center Loss + MMD.
Figure 11.
Framework of Center Loss + MMD.
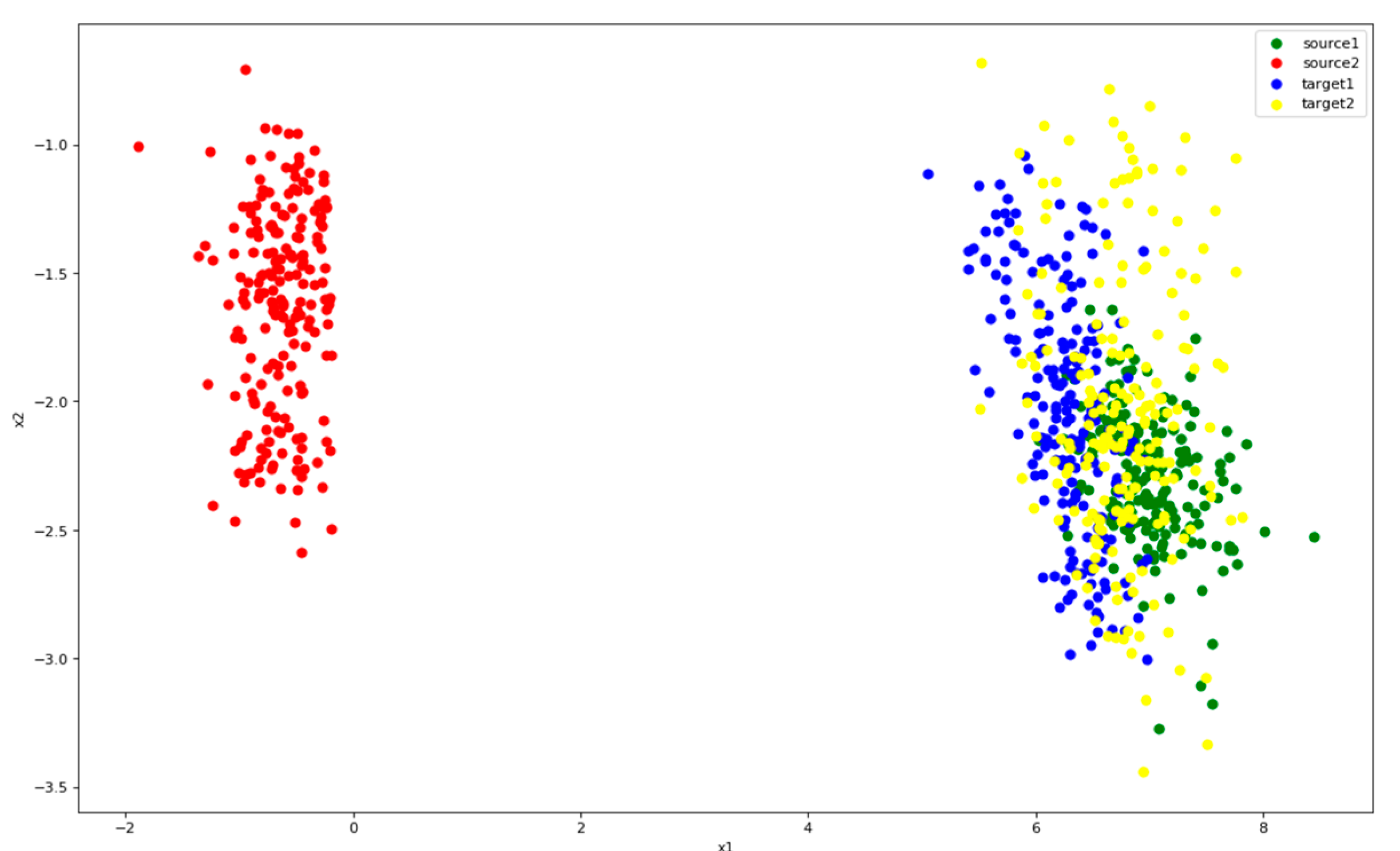
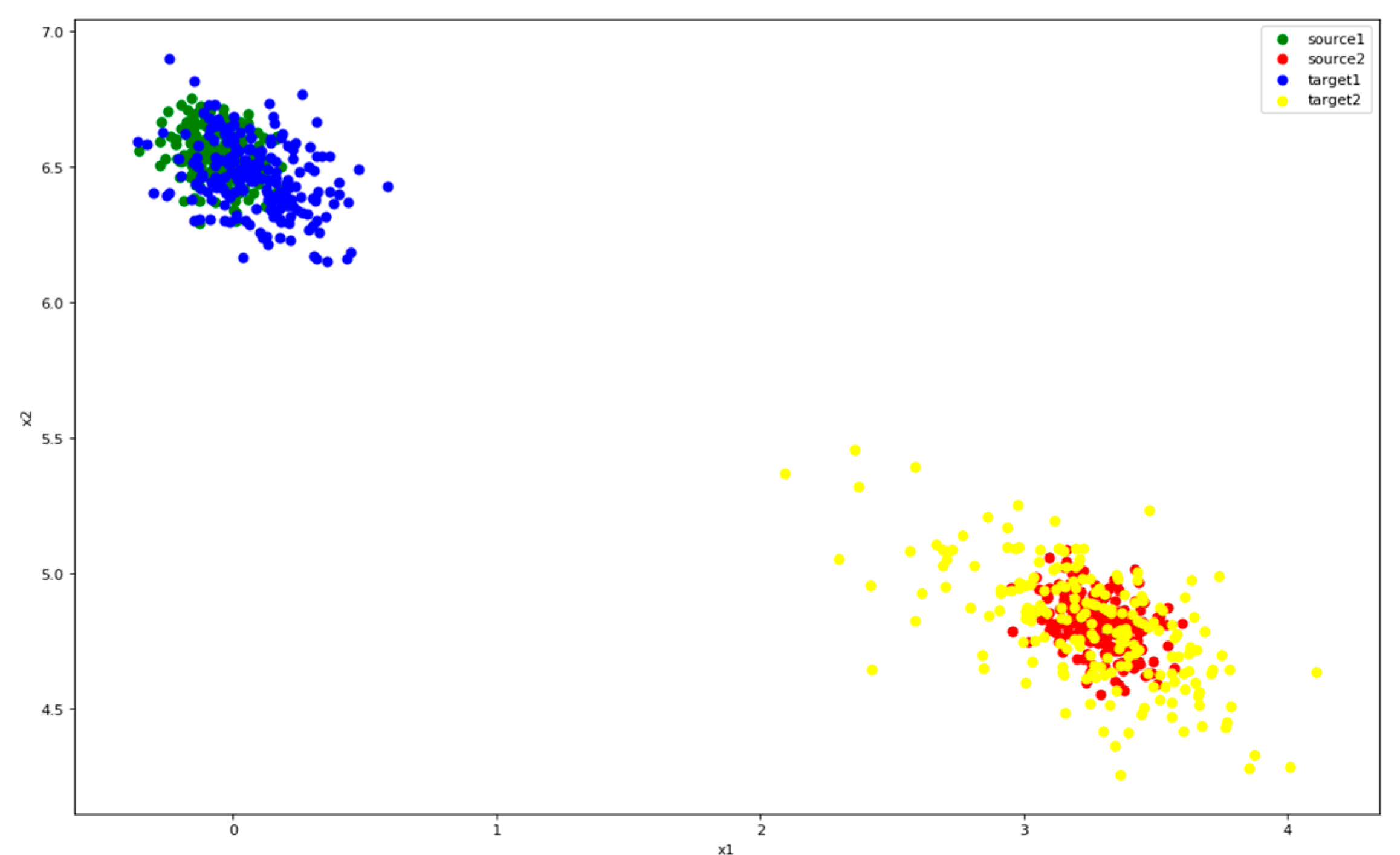
Figure 12.
Distribution of features after Only-Source. Color green represents class 1 of source and red represents class 2. Blue is the class 1 of target and yellow the class 2.
Figure 12.
Distribution of features after Only-Source. Color green represents class 1 of source and red represents class 2. Blue is the class 1 of target and yellow the class 2.
Figure 13.
Distribution of features after MMD. Color green represents class 1 of source and red represents class 2. Blue is the class 1 of target and yellow the class 2.
Figure 13.
Distribution of features after MMD. Color green represents class 1 of source and red represents class 2. Blue is the class 1 of target and yellow the class 2.
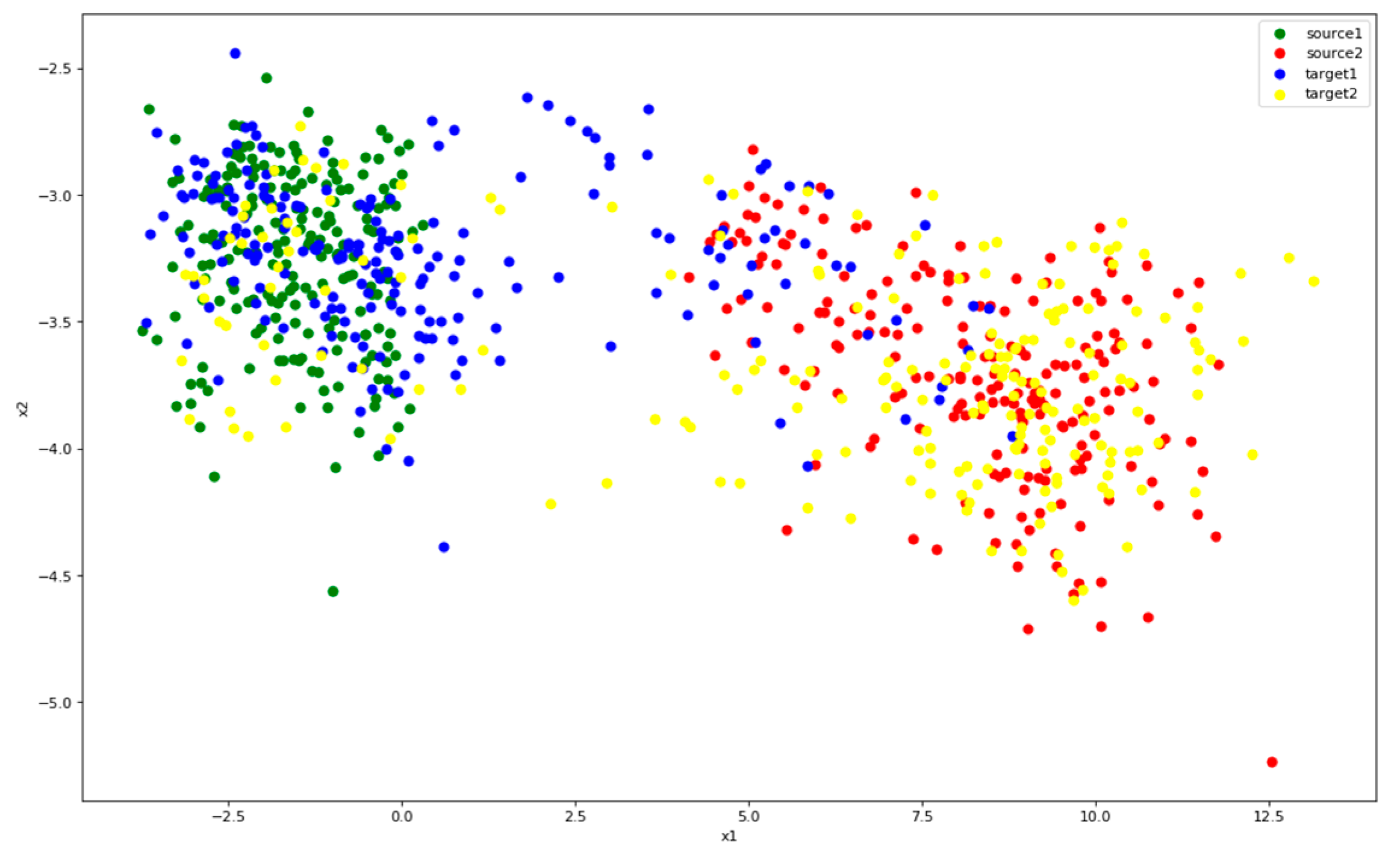
Figure 14.
Distribution of features after CMMD. Color green represents class 1 of source and red represents class 2. Blue is the class 1 of target and yellow the class 2.
Figure 14.
Distribution of features after CMMD. Color green represents class 1 of source and red represents class 2. Blue is the class 1 of target and yellow the class 2.
Table 1.
Information of the datasets we used. The link of them is on the name.
Table 1.
Information of the datasets we used. The link of them is on the name.
| Name | Sensors | Users | Activities |
|---|
| UCI daily and sports | A G M 1 | 8 | 19 |
| USC-HAD | A G | 14 | 12 |
Table 2.
Neural network parameters on different datasets. We only make convolution calculation on rows and keep the information of columns.
Table 2.
Neural network parameters on different datasets. We only make convolution calculation on rows and keep the information of columns.
| Parameter | UCI | USC |
|---|
| Number of convolution kernels | 50 | 50 |
| Size of convolution kernels | 5 × 1 | 5 × 1 |
| Size of pooling kernels | 3 × 1 | 3 × 1 |
| Number of neurons in FC layer | 1024 | 500 |
Table 3.
The inter-class distance and the maximum inner-class distance of each class collected from all 4 users. Distance_a_b represents the inter-class distance between class a and class b. Max_a represents the maximum inner-class distance of class a.
Table 3.
The inter-class distance and the maximum inner-class distance of each class collected from all 4 users. Distance_a_b represents the inter-class distance between class a and class b. Max_a represents the maximum inner-class distance of class a.
| Distance | P1 | P2 | P5 | P7 |
|---|
| Distance_1_2 | 2.4066 | 2.5843 | 2.7499 | 2.4965 |
| Distance_1_3 | 2.2896 | 2.2208 | 2.5856 | 2.2583 |
| Distance_2_3 | 0.6839 | 1.8230 | 0.4716 | 0.3203 |
| Max_1 | 3.6419 | 2.1996 | 1.6846 | 3.2121 |
| Max_2 | 1.1788 | 1.0435 | 1.1338 | 1.2189 |
| Max_3 | 1.5911 | 0.9664 | 1.2174 | 1.2210 |
Table 4.
The first round of experiment results of UCI. In this table, we show the accuracy of four methods for Target. P1 is Source, P2 is Target, and P1~P2 means transfer from P1 to P2. Because of the cross-validation used, each data in the table is the mean value of three experiments. The bold number is the best result for the experiments in the same row.
Table 4.
The first round of experiment results of UCI. In this table, we show the accuracy of four methods for Target. P1 is Source, P2 is Target, and P1~P2 means transfer from P1 to P2. Because of the cross-validation used, each data in the table is the mean value of three experiments. The bold number is the best result for the experiments in the same row.
| Pairs | Only-Source | MMD | DANN | WD |
|---|
| P1~P2 | 0.6037 | 0.9367 | 0.7381 | 0.8611 |
| P2~P1 | 0.6340 | 0.8711 | 0.7230 | 0.8525 |
| P1~P5 | 0.6154 | 0.9265 | 0.7781 | 0.9247 |
| P5~P1 | 0.6228 | 0.7847 | 0.6421 | 0.7421 |
| P1~P7 | 0.6877 | 0.9019 | 0.8205 | 0.8656 |
| P7~P1 | 0.6570 | 0.8356 | 0.7565 | 0.8596 |
| P2~P5 | 0.6916 | 0.8925 | 0.8218 | 0.7988 |
| P5~P2 | 0.6100 | 0.8516 | 0.7016 | 0.8374 |
| P2~P7 | 0.7440 | 0.9507 | 0.8161 | 0.9598 |
| P7~P2 | 0.6839 | 0.9163 | 0.7086 | 0.9253 |
| P5~P7 | 0.5397 | 0.7788 | 0.6453 | 0.8188 |
| P7~P5 | 0.5637 | 0.7982 | 0.7030 | 0.8100 |
| Average | 0.6378 | 0.8704 | 0.7379 | 0.8546 |
Table 5.
The second round of experiment results of UCI. In this round of experiments, we reduced the amount of Target unlabeled data for training transfer to 1/3 and increased the test set to 2/3. The bold number is the best result for the experiments in the same row.
Table 5.
The second round of experiment results of UCI. In this round of experiments, we reduced the amount of Target unlabeled data for training transfer to 1/3 and increased the test set to 2/3. The bold number is the best result for the experiments in the same row.
| Pairs | Only-Source | MMD | DANN | WD |
|---|
| P1~P2 | 0.7226 | 0.8527 | 0.7209 | 0.8112 |
| P2~P1 | 0.7340 | 0.8241 | 0.6671 | 0.8135 |
| P1~P5 | 0.6451 | 0.9141 | 0.6591 | 0.8968 |
| P5~P1 | 0.6375 | 0.7667 | 0.6615 | 0.7425 |
| P1~P7 | 0.7710 | 0.8608 | 0.7625 | 0.8660 |
| P7~P1 | 0.7254 | 0.8425 | 0.7255 | 0.8593 |
| P2~P5 | 0.7797 | 0.8930 | 0.7559 | 0.8413 |
| P5~P2 | 0.7074 | 0.8275 | 0.6823 | 0.8088 |
| P2~P7 | 0.8079 | 0.9542 | 0.7974 | 0.9483 |
| P7~P2 | 0.7199 | 0.9099 | 0.7127 | 0.9186 |
| P5~P7 | 0.5857 | 0.7364 | 0.6254 | 0.7847 |
| P7~P5 | 0.7220 | 0.8411 | 0.6674 | 0.8346 |
| Average | 0.7132 | 0.8519 | 0.7031 | 0.8438 |
Table 6.
The first round of experiment results of USC. We also randomly selected 4 users from the USC, namely P5, P6, P7 and P8, and transferred between each pair. In this round of experiments, Target used 60% of the unlabeled data to participate in the training, using the remaining 40% for testing. The bold number is the best result for the experiments in the same row.
Table 6.
The first round of experiment results of USC. We also randomly selected 4 users from the USC, namely P5, P6, P7 and P8, and transferred between each pair. In this round of experiments, Target used 60% of the unlabeled data to participate in the training, using the remaining 40% for testing. The bold number is the best result for the experiments in the same row.
| Pairs | Only-Source | MMD | DANN | WD |
|---|
| P5~P6 | 0.5965 | 0.6232 | 0.6205 | 0.5775 |
| P6~P5 | 0.5639 | 0.5855 | 0.5318 | 0.6084 |
| P5~P7 | 0.7713 | 0.8063 | 0.7788 | 0.7814 |
| P7~P5 | 0.6400 | 0.7099 | 0.6912 | 0.7292 |
| P5~P9 | 0.5543 | 0.6627 | 0.5429 | 0.5331 |
| P9~P5 | 0.4874 | 0.6787 | 0.5224 | 0.5744 |
| P6~P7 | 0.6625 | 0.6828 | 0.5802 | 0.6507 |
| P7~P6 | 0.5342 | 0.5641 | 0.5580 | 0.6434 |
| P6~P9 | 0.3492 | 0.4483 | 0.4145 | 0.2995 |
| P9~P6 | 0.4370 | 0.6640 | 0.5495 | 0.4818 |
| P7~P9 | 0.4244 | 0.5808 | 0.4994 | 0.4485 |
| P9~P7 | 0.5370 | 0.7174 | 0.5286 | 0.5293 |
| Average | 0.5465 | 0.6436 | 0.5682 | 0.5714 |
Table 7.
The second round of experiment results of USC. In this round of experiments, Target only used 20% of the unlabeled data to participate in the training, using the remaining 80% for testing. The bold number is the best result for the experiments in the same row.
Table 7.
The second round of experiment results of USC. In this round of experiments, Target only used 20% of the unlabeled data to participate in the training, using the remaining 80% for testing. The bold number is the best result for the experiments in the same row.
| Pairs | Only-Source | MMD | DANN | WD |
|---|
| P5~P6 | 0.6001 | 0.6152 | 0.6074 | 0.5925 |
| P6~P5 | 0.5698 | 0.5761 | 0.5280 | 0.6109 |
| P5~P7 | 0.7694 | 0.8063 | 0.7754 | 0.7735 |
| P7~P5 | 0.6472 | 0.7217 | 0.6873 | 0.7351 |
| P5~P9 | 0.5549 | 0.6561 | 0.5405 | 0.5965 |
| P9~P5 | 0.4825 | 0.6793 | 0.4792 | 0.6235 |
| P6~P7 | 0.6591 | 0.6753 | 0.5691 | 0.6596 |
| P7~P6 | 0.5245 | 0.5645 | 0.5323 | 0.6165 |
| P6~P9 | 0.3469 | 0.4431 | 0.4173 | 0.3001 |
| P9~P6 | 0.4442 | 0.6665 | 0.5102 | 0.4751 |
| P7~P9 | 0.4387 | 0.6658 | 0.4963 | 0.4401 |
| P9~P7 | 0.5436 | 0.7235 | 0.5256 | 0.4931 |
| Average | 0.5484 | 0.6495 | 0.5557 | 0.5764 |
Table 8.
The flow of the CMMD algorithm.
Table 8.
The flow of the CMMD algorithm.
| Center Loss with MMD |
|---|
| Input: Training Data [] Label |
| Hyperparameter learning rate , epochs t |
| Output: Neural network parameter |
1: while not converge do
2: tt+1 |
3: compute total loss: + +
4: compute gradient: = + + |
5: update central points:
6: update network parameter: .
7: end while |
Table 9.
Experiment result of MMD and CMMD on UCI. Large indicates that the Target uses more unlabeled data under the experimental conditions shown in
Table 4. Small indicates that the Target uses less unlabeled data under the experimental conditions shown in
Table 5. The bold result means it is bigger than another result in the same row with the same condition (Large or Small). The same with
Table 10.
Table 9.
Experiment result of MMD and CMMD on UCI. Large indicates that the Target uses more unlabeled data under the experimental conditions shown in
Table 4. Small indicates that the Target uses less unlabeled data under the experimental conditions shown in
Table 5. The bold result means it is bigger than another result in the same row with the same condition (Large or Small). The same with
Table 10.
| Pairs | MMD-Large | CMMD-Large | MMD-Small | CMMD-Small |
|---|
| P1~P2 | 0.9367 | 0.9289 | 0.8527 | 0.9061 |
| P2~P1 | 0.8711 | 0.8781 | 0.8241 | 0.8344 |
| P1~P5 | 0.9265 | 0.9625 | 0.9141 | 0.9634 |
| P5~P1 | 0.7847 | 0.7961 | 0.7667 | 0.7954 |
| P1~P7 | 0.9019 | 0.8788 | 0.8608 | 0.8873 |
| P7~P1 | 0.8356 | 0.8449 | 0.8425 | 0.8403 |
| P2~P5 | 0.8925 | 0.9209 | 0.8930 | 0.9725 |
| P5~P2 | 0.8516 | 0.8570 | 0.8275 | 0.8132 |
| P2~P7 | 0.9507 | 0.9437 | 0.9542 | 0.9525 |
| P7~P2 | 0.9163 | 0.9421 | 0.9099 | 0.9325 |
| P5~P7 | 0.7788 | 0.8589 | 0.7364 | 0.8469 |
| P7~P5 | 0.7982 | 0.8586 | 0.8411 | 0.8890 |
| Average | 0.8704 | 0.8892 | 0.8519 | 0.8861 |
Table 10.
Experiment result of CMMD on USC. Large indicates that the Target uses more unlabeled data under the experimental conditions shown in
Table 6. Small indicates that the Target uses less unlabeled data under the experimental conditions shown in
Table 7.
Table 10.
Experiment result of CMMD on USC. Large indicates that the Target uses more unlabeled data under the experimental conditions shown in
Table 6. Small indicates that the Target uses less unlabeled data under the experimental conditions shown in
Table 7.
| Pairs | MMD-Large | CMMD-Large | MMD-Small | CMMD-Small |
|---|
| P5~P6 | 0.6232 | 0.6242 | 0.6152 | 0.6181 |
| P6~P5 | 0.5855 | 0.5871 | 0.5761 | 0.5958 |
| P5~P7 | 0.8063 | 0.8089 | 0.8063 | 0.8111 |
| P7~P5 | 0.7099 | 0.7597 | 0.7217 | 0.7614 |
| P5~P9 | 0.6627 | 0.6409 | 0.6561 | 0.6329 |
| P9~P5 | 0.6787 | 0.6849 | 0.6793 | 0.6575 |
| P6~P7 | 0.6828 | 0.6772 | 0.6753 | 0.6750 |
| P7~P6 | 0.5641 | 0.6020 | 0.5645 | 0.5984 |
| P6~P9 | 0.4483 | 0.4922 | 0.4431 | 0.4938 |
| P9~P6 | 0.6640 | 0.6700 | 0.6665 | 0.6718 |
| P7~P9 | 0.5808 | 0.5992 | 0.6658 | 0.6728 |
| P9~P7 | 0.7174 | 0.7216 | 0.7235 | 0.7303 |
| Average | 0.6436 | 0.6557 | 0.6495 | 0.6599 |
Table 11.
The experiments on UCI with the fixed random seed for initialization and the other conditions unchanged as MMD-Small and CMMD-small in
Table 9. The bold number in this table means the biggest average in the same row for the two methods with three experiments.
Table 11.
The experiments on UCI with the fixed random seed for initialization and the other conditions unchanged as MMD-Small and CMMD-small in
Table 9. The bold number in this table means the biggest average in the same row for the two methods with three experiments.
| Pairs | MMD | CMMD |
|---|
| Expt1 | Expt2 | Expt3 | Average | Expt1 | Expt2 | Expt3 | Average |
|---|
| P1~P2 | 0.8316 | 0.9289 | 0.9347 | 0.8984 | 0.8476 | 0.9476 | 0.9329 | 0.9094 |
| P2~P1 | 0.8032 | 0.8571 | 0.8482 | 0.8361 | 0.8134 | 0.8374 | 0.8405 | 0.8304 |
| P1~P5 | 0.8550 | 0.8745 | 0.9318 | 0.8871 | 0.9471 | 0.9674 | 0.9568 | 0.9571 |
| P5~P1 | 0.7861 | 0.7616 | 0.7482 | 0.7653 | 0.7597 | 0.8216 | 0.7953 | 0.7922 |
| P1~P7 | 0.8424 | 0.8587 | 0.8721 | 0.8577 | 0.8613 | 0.8779 | 0.8600 | 0.8664 |
| P7~P1 | 0.8276 | 0.8397 | 0.8437 | 0.8370 | 0.8105 | 0.8482 | 0.8182 | 0.8256 |
| P2~P5 | 0.8145 | 0.8276 | 0.8187 | 0.8203 | 0.9726 | 0.9889 | 0.9589 | 0.9735 |
| P5~P2 | 0.8195 | 0.8979 | 0.8584 | 0.8586 | 0.7942 | 0.8089 | 0.7679 | 0.7904 |
| P2~P7 | 0.9100 | 0.9453 | 0.9692 | 0.9415 | 0.9129 | 0.9355 | 0.9476 | 0.9320 |
| P7~P2 | 0.9168 | 0.9350 | 0.8721 | 0.9080 | 0.8987 | 0.9539 | 0.9029 | 0.9185 |
| P5~P7 | 0.7718 | 0.7266 | 0.7468 | 0.7484 | 0.8379 | 0.7732 | 0.7679 | 0.7930 |
| P7~P5 | 0.7637 | 0.7679 | 0.7766 | 0.7694 | 0.8634 | 0.8724 | 0.8350 | 0.8569 |
| Average | | | | 0.8440 | | | | 0.8705 |
Table 12.
The final Center Loss value in each experiment.
Table 12.
The final Center Loss value in each experiment.
| Pairs | Center Loss in MMD | Center Loss in CMMD |
|---|
| Expt1 | Expt2 | Expt3 | Average | Expt1 | Expt2 | Expt3 | Average |
|---|
| P1~P2 | 7.0641 | 6.0552 | 5.8829 | 6.3341 | 2.5095 | 3.9016 | 4.3656 | 3.5923 |
| P2~P1 | 4.3023 | 4.0079 | 3.9652 | 4.0918 | 3.3859 | 2.4400 | 2.1673 | 2.6644 |
| P1~P5 | 5.6797 | 5.7204 | 6.2997 | 5.8999 | 2.0288 | 2.6139 | 2.1705 | 2.2711 |
| P5~P1 | 3.0684 | 3.1343 | 2.8156 | 3.0061 | 1.3397 | 1.5934 | 1.3735 | 1.4356 |
| P1~P7 | 5.8804 | 4.4947 | 6.2086 | 5.5279 | 2.3206 | 2.7495 | 2.3340 | 2.4680 |
| P7~P1 | 3.0229 | 3.0714 | 2.8922 | 2.9955 | 1.3355 | 1.2104 | 1.2586 | 1.2682 |
| P2~P5 | 3.7914 | 3.7328 | 3.8657 | 3.7966 | 1.5664 | 1.3864 | 1.6750 | 1.5426 |
| P5~P2 | 3.2929 | 4.1160 | 3.8489 | 3.7526 | 1.3598 | 1.4336 | 0.5780 | 1.1238 |
| P2~P7 | 4.1270 | 3.6414 | 3.3205 | 3.6963 | 1.6238 | 1.4944 | 1.4380 | 1.5187 |
| P7~P2 | 2.7896 | 3.5230 | 3.0606 | 3.1244 | 1.2902 | 1.2553 | 1.2591 | 1.2682 |
| P5~P7 | 3.6943 | 3.9466 | 4.1478 | 3.9296 | 1.3651 | 1.2760 | 1.4209 | 1.3540 |
| P7~P5 | 3.7604 | 3.6678 | 3.7770 | 3.7351 | 1.4640 | 1.4026 | 1.4796 | 1.4487 |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}