SHNN-CAD+: An Improvement on SHNN-CAD for Adaptive Online Trajectory Anomaly Detection


Abstract
:1. Introduction
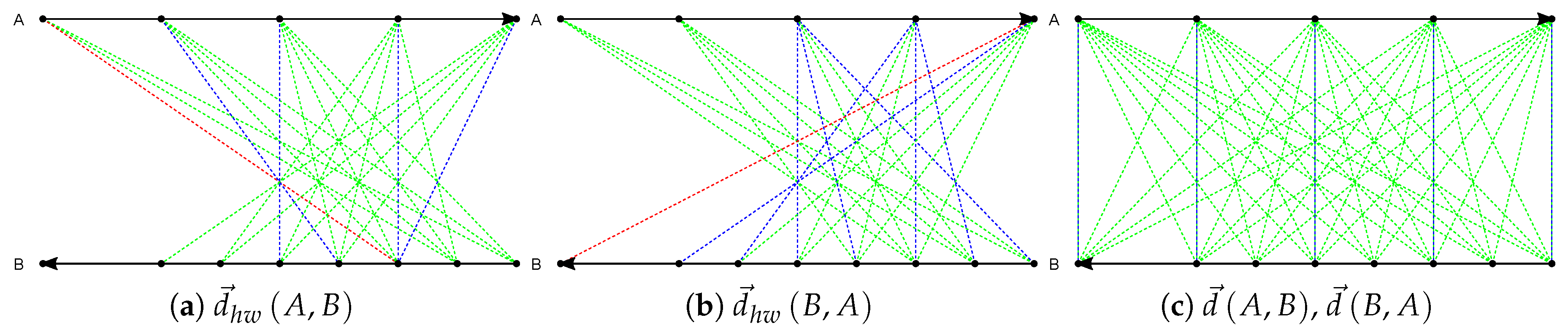
- The problems of applying Hausdorff distance directly to trajectory data are high computational cost as it visits every pairwise sample points in two trajectories, and that it cannot distinguish the direction while computing because the distance between two trajectories is defined as the distance between two sample points from the corresponding trajectories under a certain criterion. In [10], Voronoi diagram is used to speedup the calculation of Hausdorff distance, but it is complicated to implement. On the other hand, the direction attribute can be added when computing distance, but the extension of feature will increase the computational cost. To solve this, a modified distance measure based on directed Hausdorff distance is proposed to calculate the difference between trajectories. In addition, the modified measure has the advantage of a fast computation, which meets the requirement of performing online learning in a fast manner.
- According to the description in [10], when the data size is quite small, the new coming trajectory can be regarded to be abnormal, however, with time evolving, this trajectory may have enough similar neighbors to be identified as normal. Our solution is introducing a re-do step into the detection procedure to identify anomalous data more accurately.
- The anomaly threshold is a critical parameter since it controls the sensitivity to true anomalies and error rate. As aforementioned, in [10], the threshold is manually selected which relies on the user experience. Instead of predefining the anomaly threshold, an adaptive and data-based method is proposed to make the algorithm more parameter-light, which is more easily applicable for practical use.
- In order to evaluate the performance of anomaly detection, F1-score is used in [10] to compare SHNN-CAD with different approaches. We propose to apply more performance measures, such as, precision, recall, accuracy, and false alarm rate, in order to analyze the behaviour of anomaly detection algorithms comprehensively.
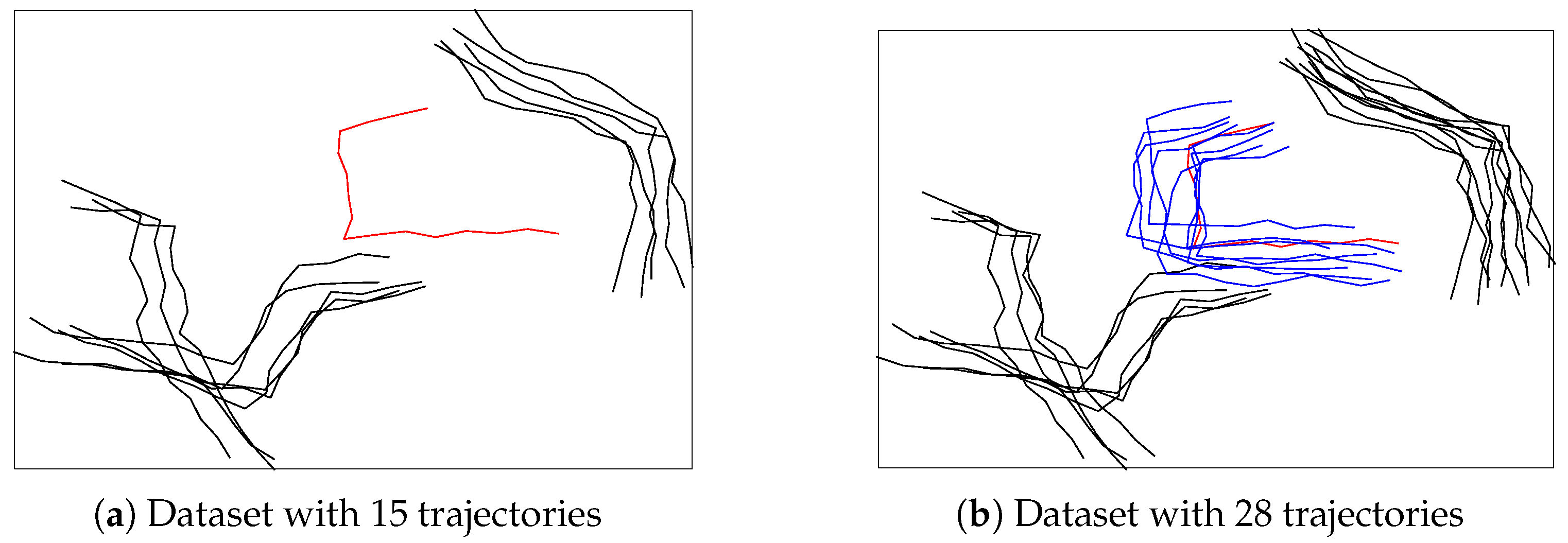
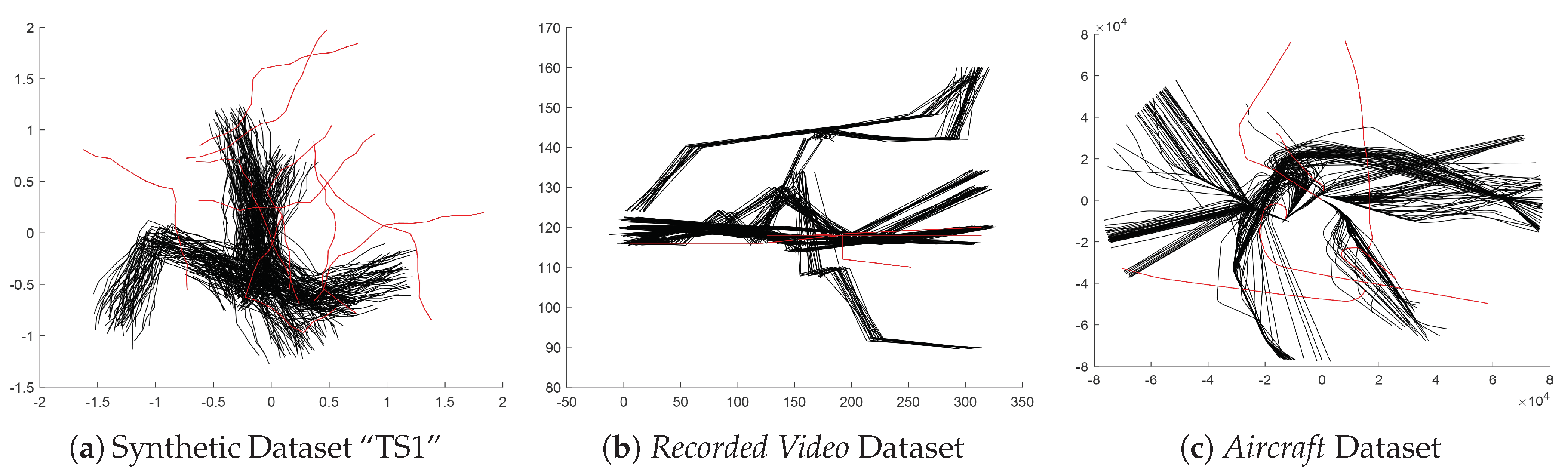
- One important advantage of Hausdorff distance is that it can deal with trajectory data with different number of sample points. However, in the experiments of evaluating SHNN-CAD [10], all the testing data have the same number of sample points. In this paper, the experiments are enriched by introducing more datasets with unequal length.
2. Related Work
3. SHNN-CAD: An Improvement of SHNN-CAD
3.1. SHNN-CAD Based Anomaly Detection
3.2. Discussion of SHNN-CAD
3.3. SHNN-CAD
| Algorithm 1: Adaptive Online Trajectory Anomaly Detection with SHNN-CAD |
 |
4. Experiments
4.1. Comparison of Distance Measure
4.2. Comparison of Anomaly Detection Measures
4.3. Comparison of Online Anomaly Detection
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HD | Hausdorff distance |
| DHD | Directed Hausdorff distance |
| DHD() | Directed Hausdorff distance with constraint window |
| kNN | k-nearest neighbors |
| CAD | Conformal anomaly detector |
| NCM | Non-conformity measure |
| SNN-CAD | Similarity based Nearest Neighbour Conformal Anomaly Detector |
| SHNN-CAD | Sequential Hausdorff Nearest-Neighbor Conformal Anomaly Detector |
| SHNN-CAD | Enhanced version of Sequential Hausdorff Nearest-Neighbor Conformal Anomaly Detector |
Appendix A. 10-Fold Cross Validation Results on 65 Time Series Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Dataset | Data Size | Clusters Size | DHD | DHD() | ||
|---|---|---|---|---|---|---|---|
| Average | Std | Average | Std | ||||
| 1 | 50words | 905 | 50 | 86.52 | 0.0300 | 40.77 | 0.0391 |
| 2 | Adiac | 781 | 37 | 71.33 | 0.0603 | 36.48 | 0.0452 |
| 3 | ArrowHead | 210 | 3 | 50.00 | 0.0985 | 10.00 | 0.0613 |
| 4 | Beef | 60 | 5 | 55.00 | 0.2364 | 50.00 | 0.2606 |
| 5 | BeetleFly | 40 | 2 | 40.00 | 0.1748 | 22.50 | 0.2486 |
| 6 | BirdChicken | 40 | 2 | 22.50 | 0.3217 | 20.00 | 0.1581 |
| 7 | Car | 120 | 4 | 58.33 | 0.1521 | 29.17 | 0.0982 |
| 8 | CBF | 930 | 3 | 60.54 | 0.0608 | 3.44 | 0.0167 |
| 9 | Coffee | 56 | 2 | 25.33 | 0.1501 | 1.67 | 0.0527 |
| 10 | Computers | 500 | 2 | 26.40 | 0.0610 | 37.80 | 0.0614 |
| 11 | Cricket_X | 780 | 12 | 78.08 | 0.0293 | 48.33 | 0.0897 |
| 12 | Cricket_Y | 780 | 12 | 80.51 | 0.0550 | 50.51 | 0.0510 |
| 13 | Cricket_Z | 780 | 12 | 78.33 | 0.0333 | 48.08 | 0.0397 |
| 14 | DiatomSizeReduction | 322 | 4 | 8.39 | 0.0392 | 0.00 | 0.0000 |
| 15 | DistalPhalanxOutlineAgeGroup | 539 | 3 | 33.19 | 0.0637 | 23.38 | 0.0583 |
| 16 | DistalPhalanxOutlineCorrect | 876 | 2 | 34.60 | 0.0509 | 23.29 | 0.0425 |
| 17 | DistalPhalanxTW | 539 | 6 | 43.21 | 0.0563 | 29.68 | 0.0488 |
| 18 | Earthquakes | 461 | 2 | 32.34 | 0.0735 | 36.04 | 0.0797 |
| 19 | ECG200 | 200 | 2 | 31.50 | 0.1180 | 11.50 | 0.0914 |
| 20 | ECG5000 | 5000 | 5 | 13.70 | 0.0173 | 6.68 | 0.0114 |
| 21 | ECGFiveDays | 884 | 2 | 3.51 | 0.0125 | 0.00 | 0.0000 |
| 22 | FaceAll | 2247 | 14 | 64.49 | 0.0278 | 6.54 | 0.0149 |
| 23 | FaceFour | 112 | 4 | 50.91 | 0.1621 | 17.05 | 0.0911 |
| 24 | FacesUCR | 2247 | 14 | 64.53 | 0.0337 | 6.19 | 0.0135 |
| 25 | FISH | 350 | 7 | 69.43 | 0.0687 | 17.43 | 0.0888 |
| 26 | Gun_Point | 200 | 2 | 39.50 | 0.1012 | 2.00 | 0.0258 |
| 27 | Ham | 214 | 2 | 45.28 | 0.0894 | 27.62 | 0.0831 |
| 28 | Haptics | 463 | 5 | 69.77 | 0.0424 | 64.37 | 0.0510 |
| 29 | Herring | 128 | 2 | 45.45 | 0.1015 | 46.79 | 0.1380 |
| 30 | InsectWingbeatSound | 2200 | 11 | 87.91 | 0.0221 | 41.50 | 0.0263 |
| 31 | ItalyPowerDemand | 1096 | 2 | 32.39 | 0.0485 | 5.75 | 0.0206 |
| 32 | LargeKitchenAppliances | 750 | 3 | 51.33 | 0.0594 | 60.53 | 0.0623 |
| 33 | Lighting2 | 121 | 2 | 36.28 | 0.1149 | 35.64 | 0.1137 |
| 34 | Lighting7 | 143 | 7 | 52.43 | 0.0966 | 54.48 | 0.1559 |
| 35 | Meat | 120 | 3 | 10.83 | 0.0883 | 7.50 | 0.0730 |
| 36 | MedicalImages | 1140 | 10 | 47.72 | 0.0310 | 25.88 | 0.0262 |
| 37 | MiddlePhalanxOutlineAgeGroup | 554 | 3 | 44.42 | 0.0928 | 31.41 | 0.0662 |
| 38 | MiddlePhalanxOutlineCorrect | 891 | 2 | 39.73 | 0.0648 | 27.84 | 0.0480 |
| 39 | MiddlePhalanxTW | 553 | 6 | 49.19 | 0.0419 | 45.94 | 0.0434 |
| 40 | MoteStrain | 1272 | 2 | 27.51 | 0.0384 | 12.57 | 0.0285 |
| 41 | OliveOil | 60 | 4 | 26.67 | 0.1610 | 16.67 | 0.1361 |
| 42 | OSULeaf | 442 | 6 | 65.16 | 0.0443 | 38.71 | 0.0926 |
| 43 | PhalangesOutlinesCorrect | 2658 | 2 | 37.77 | 0.0409 | 24.08 | 0.0261 |
| 44 | Plane | 210 | 7 | 21.90 | 0.0784 | 2.86 | 0.0246 |
| 45 | ProximalPhalanxOutlineAgeGroup | 605 | 3 | 29.40 | 0.0554 | 23.64 | 0.0620 |
| 46 | ProximalPhalanxOutlineCorrect | 891 | 2 | 30.18 | 0.0493 | 18.30 | 0.0541 |
| 47 | ProximalPhalanxTW | 605 | 6 | 33.88 | 0.0560 | 26.42 | 0.0824 |
| 48 | RefrigerationDevices | 750 | 3 | 35.73 | 0.0439 | 63.60 | 0.0507 |
| 49 | ScreenType | 750 | 3 | 51.20 | 0.0467 | 65.60 | 0.0474 |
| 50 | ShapeletSim | 200 | 2 | 38.50 | 0.1435 | 47.00 | 0.0919 |
| 51 | ShapesAll | 1198 | 60 | 83.48 | 0.0225 | 21.37 | 0.0302 |
| 52 | SmallKitchenAppliances | 750 | 3 | 49.87 | 0.0706 | 59.33 | 0.0587 |
| 53 | SonyAIBORobotSurface | 621 | 2 | 18.69 | 0.0346 | 1.45 | 0.0119 |
| 54 | Strawberry | 983 | 2 | 7.63 | 0.0183 | 4.17 | 0.0170 |
| 55 | SwedishLeaf | 1122 | 15 | 67.21 | 0.0525 | 17.02 | 0.0359 |
| 56 | Symbols | 1000 | 6 | 77.90 | 0.0370 | 4.40 | 0.0222 |
| 57 | synthetic_control | 600 | 6 | 73.50 | 0.0552 | 3.33 | 0.0192 |
| 58 | ToeSegmentation1 | 252 | 2 | 30.51 | 0.0697 | 26.09 | 0.0912 |
| 59 | ToeSegmentation2 | 166 | 2 | 19.85 | 0.0784 | 21.25 | 0.1409 |
| 60 | Trace | 200 | 4 | 25.00 | 0.0943 | 6.50 | 0.0626 |
| 61 | TwoLeadECG | 1162 | 2 | 8.86 | 0.0269 | 0.95 | 0.011 |
| 62 | Wine | 111 | 2 | 5.45 | 0.0878 | 4.55 | 0.0643 |
| 63 | WordsSynonyms | 905 | 25 | 82.75 | 0.0458 | 38.12 | 0.0489 |
| 64 | Worms | 225 | 5 | 59.57 | 0.0839 | 69.94 | 0.1074 |
| 65 | WormsTwoClass | 225 | 2 | 40.45 | 0.1212 | 50.61 | 0.0490 |
| Average of all datasets | 44.36 | 0.0744 | 26.50 | 0.0640 | |||
References
- Haritaoglu, I.; Harwood, D.; Davis, L.S. W4: Real-Time Surveillance of People and Their Activities. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 809–830. [Google Scholar] [CrossRef]
- Majecka, B. Statistical Models of Pedestrian Behaviour in the Forum. Master’s Thesis, School of Informatics, University of Edinburgh, Edinburgh, UK, 2009. [Google Scholar]
- Wang, Q.; Chen, M.; Nie, F.; Li, X. Detecting Coherent Groups in Crowd Scenes by Multiview Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef]
- Gariel, M.; Srivastava, A.N.; Feron, E. Trajectory Clustering and an Application to Airspace Monitoring. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1511–1524. [Google Scholar] [CrossRef] [Green Version]
- Powell, M.D.; Aberson, S.D. Accuracy of United States Tropical Cyclone Landfall Forecasts in the Atlantic Basin (1976–2000). Bull. Am. Meteorol. Soc. 2001, 82, 2749–2768. [Google Scholar] [CrossRef]
- Meng, F.; Yuan, G.; Lv, S.; Wang, Z.; Xia, S. An Overview on Trajectory Outlier Detection. Artif. Intell. Rev. 2018. [Google Scholar] [CrossRef]
- Keogh, E.; Lonardi, S.; Ratanamahatana, C.A. Towards Parameter-free Data Mining. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 206–215. [Google Scholar] [CrossRef]
- Laxhammar, R.; Falkman, G. Conformal Prediction for Distribution-independent Anomaly Detection in Streaming Vessel Data. In Proceedings of the International Workshop on Novel Data Stream Pattern Mining Techniques, Washington, DC, USA, 25 July 2010; pp. 47–55. [Google Scholar] [CrossRef]
- Laxhammar, R.; Falkman, G. Sequential Conformal Anomaly Detection in Trajectories Based on Hausdorff Distance. In Proceedings of the International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 1–8. [Google Scholar]
- Laxhammar, R.; Falkman, G. Online Learning and Sequential Anomaly Detection in Trajectories. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1158–1173. [Google Scholar] [CrossRef] [PubMed]
- Gupta, M.; Gao, J.; Aggarwal, C.C.; Han, J. Outlier Detection for Temporal Data: A Survey. IEEE Trans. Knowl. Data Eng. 2014, 26, 2250–2267. [Google Scholar] [CrossRef] [Green Version]
- Parmar, J.D.; Patel, J.T. Anomaly Detection in Data Mining: A Review. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2017, 7, 32–40. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Birant, D.; Kut, A. ST-DBSCAN: An Algorithm for Clustering Spatial-Temporal Data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Zhu, Y.; Ming, K.T.; Angelova, M. Angelova, M. A Distance Scaling Method to Improve Density-Based Clustering. In Advances in Knowledge Discovery and Data Mining; Phung, D., Tseng, V.S., Webb, G.I., Ho, B., Ganji, M., Rashidi, L., Eds.; Springer: Cham, Switzerland, 2018; pp. 389–400. [Google Scholar]
- Kumar, D.; Bezdek, J.C.; Rajasegarar, S.; Leckie, C.; Palaniswami, M. A Visual-Numeric Approach to Clustering and Anomaly Detection for Trajectory Data. Vis. Comput. 2017, 33, 265–281. [Google Scholar] [CrossRef]
- Annoni, R.; Forster, C.H.Q. Analysis of Aircraft Trajectories Using Fourier Descriptors and Kernel Density Estimation. In Proceedings of the International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 1441–1446. [Google Scholar] [CrossRef]
- Guo, Y.; Xu, Q.; Li, P.; Sbert, M.; Yang, Y. Trajectory Shape Analysis and Anomaly Detection Utilizing Information Theory Tools. Entropy 2017, 19, 323. [Google Scholar] [CrossRef]
- Keogh, E.; Lin, J.; Fu, A. HOT SAX: Efficiently Finding the Most Unusual Time Series Subsequence. In Proceedings of the IEEE International Conference on Data Mining, Houston, TX, USA, 27–30 November 2005; pp. 226–233. [Google Scholar] [CrossRef] [Green Version]
- Yankov, D.; Keogh, E.; Rebbapragada, U. Disk Aware Discord Discovery: Finding Unusual Time Series in Terabyte Sized Datasets. Knowl. Inf. Syst. 2008, 17, 241–262. [Google Scholar] [CrossRef]
- Lee, J.G.; Han, J.; Li, X. Trajectory Outlier Detection: A Partition-and-Detect Framework. In Proceedings of the International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; pp. 140–149. [Google Scholar] [CrossRef]
- Guo, Y.; Xu, Q.; Luo, X.; Wei, H.; Bu, H.; Sbert, M. A Group-Based Signal Filtering Approach for Trajectory Abstraction and Restoration. Neural Comput. Appl. 2018, 29, 371–387. [Google Scholar] [CrossRef]
- Banerjee, P.; Yawalkar, P.; Ranu, S. MANTRA: A Scalable Approach to Mining Temporally Anomalous Sub-trajectories. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1415–1424. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, D.; Wang, Q. Anomaly Detection in Traffic Scenes via Spatial-Aware Motion Reconstruction. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1198–1209. [Google Scholar] [CrossRef]
- Kanarachos, S.; Christopoulos, S.R.G.; Chroneos, A.; Fitzpatrick, M.E. Detecting anomalies in time series data via a deep learning algorithm combining wavelets, neural networks and Hilbert transform. Expert Syst. Appl. 2017, 85, 292–304. [Google Scholar] [CrossRef]
- Ding, H.; Trajcevski, G.; Scheuermann, P.; Wang, X.; Keogh, E. Querying and Mining of Time Series Data: Experimental Comparison of Representations and Distance Measures. VLDB Endow. 2008, 1, 1542–1552. [Google Scholar] [CrossRef]
- Gammerman, A.; Vovk, V. Hedging Predictions in Machine Learning. Comput. J. 2007, 50, 151–163. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 15:1–15:58. [Google Scholar] [CrossRef]
- Faloutsos, C.; Ranganathan, M.; Manolopoulos, Y. Fast Subsequence Matching in Time-Series Databases. SIGMOD Rec. 1994, 23, 419–429. [Google Scholar] [CrossRef]
- Alt, H. The Computational Geometry of Comparing Shapes. In Efficient Algorithms: Essays Dedicated to Kurt Mehlhorn on the Occasion of His 60th Birthday; Albers, S., Alt, H., Näher, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 235–248. [Google Scholar] [CrossRef]
- Guo, Y. Matlab Code of Experiments. Available online: http://gilabparc.udg.edu/trajectory/experiments/Experiments.zip (accessed on 13 December 2018).
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Pearson Education: Noida, India, 2007. [Google Scholar]
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Synthetic Trajectories by Piciarelli et al. 2008. Available online: https://avires.dimi.uniud.it/papers/trclust/ (accessed on 14 December 2018).
- Morris, B.; Trivedi, M. Trajectory Clustering Datasets. 2009. Available online: http://cvrr.ucsd.edu/bmorris/datasets/dataset_trajectory_clustering.html (accessed on 14 December 2018).
- Morris, B.; Trivedi, M. Learning Trajectory Patterns by Clustering: Experimental Studies and Comparative Evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 312–319. [Google Scholar] [CrossRef]
- Kruskal, W.H.; Wallis, W.A. Use of Ranks in One-Criterion Variance Analysis. Am. Stat. Assoc. 1952, 47, 583–621. [Google Scholar] [CrossRef]
- Antunes, C.M.; Oliveira, A.L. Temporal Data Mining: An Overview. In Proceedings of the KDD Workshop on Temporal Data Mining, San Francisco, CA, USA, 26–29 August 2001; Volume 1, pp. 1–13. [Google Scholar]
- Lazarević, A. First Set of Recorded Video Trajectories. 2007. Available online: https://www-users.cs.umn.edu/~lazar027/inclof/ (accessed on 14 December 2018).
- Laxhammar, R. Synthetic Trajectories by Laxhammar. Available online: https://www.researchgate.net/publication/236838887_Synthetic_trajectories (accessed on 14 December 2018).
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Synthetic Trajectory Generator. 2008. Available online: https://avires.dimi.uniud.it/papers/trclust/create_ts2.m (accessed on 14 December 2018).
- Guo, Y. Synthetic Trajectories by Guo. Available online: http://gilabparc.udg.edu/trajectory/data/SyntheticTrajectories.zip (accessed on 14 December 2018).
- Nandeshwar, A.; Menzies, T.; Nelson, A. Learning patterns of university student retention. Expert Syst. Appl. 2011, 38, 14984–14996. [Google Scholar] [CrossRef]
- Chen, Y.; Keogh, E.; Hu, B.; Begum, N.; Bagnall, A.; Mueen, A.; Batista, G. The UCR Time Series Classification Archive. 2015. Available online: www.cs.ucr.edu/~eamonn/time_series_data/ (accessed on 14 December 2018).




| Ref. | Category of Algorithm | Type of Data | Threshold | Evaluation Measure |
|---|---|---|---|---|
| [4] | clustering-based (DBSCAN) | trajectory data | implied | discuss with data managers |
| [13] | clustering-based (DBSCAN) | point set | implied | compare result with groundtruth, running time |
| [14] | clustering-based (ST-DBSCAN) | spatial-temporal data | implied | running time complexity, interpret results in application |
| [15] | clustering-based (DBSCAN/OPTICS/DP) | point set | implied | F-measure |
| [16] | clustering-based (iVAT+/clusiVAT+) | trajectory data | predefined | partition accuracy, false alarm, true positive |
| [17] | clustering-based (DBSCAN+KDE) | trajectory data | predefined | 10-fold cross validation test, interpret results in application |
| [18] | clustering-based (IB+Shannon entropy) | trajectory data | automatic | accuracy, precision recall, F-measure |
| [19] | non-clustering-based (HOT SAX) | time series | automatic | interpret results with data, running time complexity |
| [20] | non-clustering-based (disk aware algorithm) | time series | automatic | running time |
| [21] | non-clustering-based (TRAOD) | trajectory data | predefined | pruning power, accuracy of pruning, speedup ratio |
| [22] | non-clustering-based (trajectory abstraction) | trajectory data | predefined | degree of redundancy, informativeness, precision, recall |
| [23] | non-clustering-based (MANTRA) | trajectory data | predefined | growth rate of running time/number of anomalous edges, accuracy, 5-fold cross validation, F-measure |
| [24] | non-clustering-based (anomaly detection in traffic scenes) | video data | automatic | pixel-wise receiver of characteristics (ROC), area under ROC |
| [25] | non-clustering-based (an algorithm combining wavelets, neural networks and Hilbert transform) | time series | automatic | false positive/alarm rate, true positive rate (hit rate), interpret results with data |
| Distance Measures | DHD | DHD() | p-Value | |||
|---|---|---|---|---|---|---|
| Datasets | Average | Std | Average | Std | ||
| Synthetic Trajectories I (average) | 0.1634 | 0.0032 | 0.1566 | 0.0031 | ||
| CROSS | 0.6100 | 0.0792 | 0.5937 | 0.0694 | 0.2182 | |
| LABOMNI | 31.23 | 1.37 | 10.20 | 0.87 | ||
| Datasets | Nonconformity Measures | # of Most Similar Neighbors Considered | ||||
|---|---|---|---|---|---|---|
| Synthetic Trajectories I (average) | DH-kNN NCM | 96.42 | 97.09 | 97.05 | 96.95 | 96.77 |
| using DHD() | 96.45 | 97.85 | 97.81 | 97.74 | 97.65 | |
| Recorded Video Trajectories | DH-kNN NCM | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| using DHD() | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| Aircraft Trajectories | DH-kNN NCM | 80.00 | 80.00 | 80.00 | 80.00 | 80.00 |
| using DHD() | 80.00 | 80.00 | 80.00 | 80.00 | 80.00 | |
| Trajectory Datasets | Approaches | Precision | Recall | F1 | Accuracy | False Alarm Rate | |
|---|---|---|---|---|---|---|---|
| Synthetic Trajectories II () | SHNN-CAD | 98.70 | 40.39 | 54.75 | 99.39 | 0.01 | |
| 87.15 | 77.48 | 79.80 | 99.63 | 0.13 | |||
| 50.24 | 94.59 | 64.35 | 98.98 | 0.98 | |||
| SHNN-CAD | 88.41 | 89.64 | 86.38 | 99.77 | 0.13 | ||
| Synthetic Trajectories III () | SHNN-CAD | 97.34 | 55.51 | 67.92 | 98.19 | 0.10 | |
| 91.52 | 73.95 | 79.36 | 98.63 | 0.38 | |||
| 80.01 | 83.40 | 79.83 | 98.39 | 1.01 | |||
| SHNN-CAD | 84.75 | 82.70 | 79.39 | 98.68 | 0.70 | ||
| Synthetic Trajectories IV () | SHNN-CAD | 90.97 | 54.53 | 63.78 | 99.73 | 0.03 | |
| 83.82 | 65.04 | 69.40 | 99.75 | 0.07 | |||
| 52.63 | 88.21 | 64.01 | 99.53 | 0.41 | |||
| SHNN-CAD | 78.43 | 91.76 | 81.47 | 99.82 | 0.15 | ||
| Synthetic Trajectories IV () | SHNN-CAD | 99.17 | 37.31 | 52.39 | 99.33 | 0.00 | |
| 89.31 | 74.31 | 79.31 | 99.61 | 0.11 | |||
| 52.27 | 92.09 | 65.60 | 99.01 | 0.92 | |||
| SHNN-CAD | 88.64 | 89.52 | 85.66 | 99.75 | 0.14 | ||
| Synthetic Trajectories IV () | SHNN-CAD | 98.99 | 45.79 | 61.64 | 98.91 | 0.01 | |
| 87.47 | 83.88 | 84.62 | 99.42 | 0.26 | |||
| 63.18 | 93.02 | 74.53 | 98.78 | 1.10 | |||
| SHNN-CAD | 95.36 | 78.75 | 81.45 | 99.48 | 0.10 | ||
| Trajectory Datasets | Approaches | Precision | Recall | F1 | Accuracy | False Alarm Rate | |
|---|---|---|---|---|---|---|---|
| Synthetic Trajectories II () | Objective 1 | 98.86 | 40.23 | 54.89 | 99.38 | 0.01 | |
| 87.93 | 77.91 | 80.38 | 99.64 | 0.12 | |||
| 50.77 | 95.16 | 64.89 | 98.99 | 0.97 | |||
| Objective 2 | 98.70 | 40.39 | 54.75 | 99.39 | 0.01 | ||
| 87.15 | 77.48 | 79.80 | 99.63 | 0.13 | |||
| 50.24 | 94.59 | 64.35 | 98.98 | 0.98 | |||
| Objective 3 | 87.08 | 87.21 | 84.97 | 99.75 | 0.13 | ||
| Synthetic Trajectories III () | Objective 1 | 97.01 | 55.78 | 67.99 | 98.21 | 0.10 | |
| 91.86 | 74.31 | 79.81 | 98.66 | 0.37 | |||
| 80.41 | 83.94 | 80.30 | 98.43 | 1.00 | |||
| Objective 2 | 97.34 | 55.51 | 67.92 | 98.19 | 0.10 | ||
| 91.52 | 73.95 | 79.36 | 98.63 | 0.38 | |||
| 80.01 | 83.40 | 79.83 | 98.39 | 1.01 | |||
| Objective 3 | 85.10 | 82.25 | 79.02 | 98.64 | 0.72 | ||
| Synthetic Trajectories IV () | Objective 1 | 93.88 | 58.22 | 67.45 | 99.75 | 0.02 | |
| 87.23 | 69.39 | 73.28 | 99.78 | 0.06 | |||
| 52.75 | 91.08 | 65.01 | 99.54 | 0.41 | |||
| Objective 2 | 90.97 | 54.53 | 63.78 | 99.73 | 0.03 | ||
| 83.82 | 65.04 | 69.40 | 99.75 | 0.07 | |||
| 52.63 | 88.21 | 64.01 | 99.53 | 0.41 | |||
| Objective 3 | 77.90 | 86.10 | 78.30 | 99.79 | 0.14 | ||
| Synthetic Trajectories IV () | Objective 1 | 99.53 | 37.74 | 53.20 | 99.34 | 0.00 | |
| 92.35 | 77.94 | 82.84 | 99.68 | 0.08 | |||
| 53.80 | 94.76 | 67.59 | 99.07 | 0.89 | |||
| Objective 2 | 99.17 | 37.31 | 52.39 | 99.33 | 0.00 | ||
| 89.31 | 74.31 | 79.31 | 99.61 | 0.11 | |||
| 52.27 | 92.09 | 65.60 | 99.01 | 0.92 | |||
| Objective 3 | 87.55 | 84.08 | 82.63 | 99.69 | 0.14 | ||
| Synthetic Trajectories IV () | Objective 1 | 99.60 | 45.80 | 61.70 | 98.92 | 0.01 | |
| 90.18 | 86.59 | 87.38 | 99.52 | 0.20 | |||
| 65.68 | 95.28 | 77.02 | 98.91 | 1.02 | |||
| Objective 2 | 98.99 | 45.79 | 61.64 | 98.91 | 0.01 | ||
| 87.47 | 83.88 | 84.62 | 99.42 | 0.26 | |||
| 63.18 | 93.02 | 74.53 | 98.78 | 1.10 | |||
| Objective 3 | 95.05 | 72.66 | 77.94 | 99.37 | 0.10 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Bardera, A. SHNN-CAD+: An Improvement on SHNN-CAD for Adaptive Online Trajectory Anomaly Detection. Sensors 2019, 19, 84. https://doi.org/10.3390/s19010084
Guo Y, Bardera A. SHNN-CAD+: An Improvement on SHNN-CAD for Adaptive Online Trajectory Anomaly Detection. Sensors. 2019; 19(1):84. https://doi.org/10.3390/s19010084
Chicago/Turabian StyleGuo, Yuejun, and Anton Bardera. 2019. "SHNN-CAD+: An Improvement on SHNN-CAD for Adaptive Online Trajectory Anomaly Detection" Sensors 19, no. 1: 84. https://doi.org/10.3390/s19010084
APA StyleGuo, Y., & Bardera, A. (2019). SHNN-CAD+: An Improvement on SHNN-CAD for Adaptive Online Trajectory Anomaly Detection. Sensors, 19(1), 84. https://doi.org/10.3390/s19010084