A Cascade Ensemble Learning Model for Human Activity Recognition with Smartphones



Abstract
:1. Introduction
2. Related Work
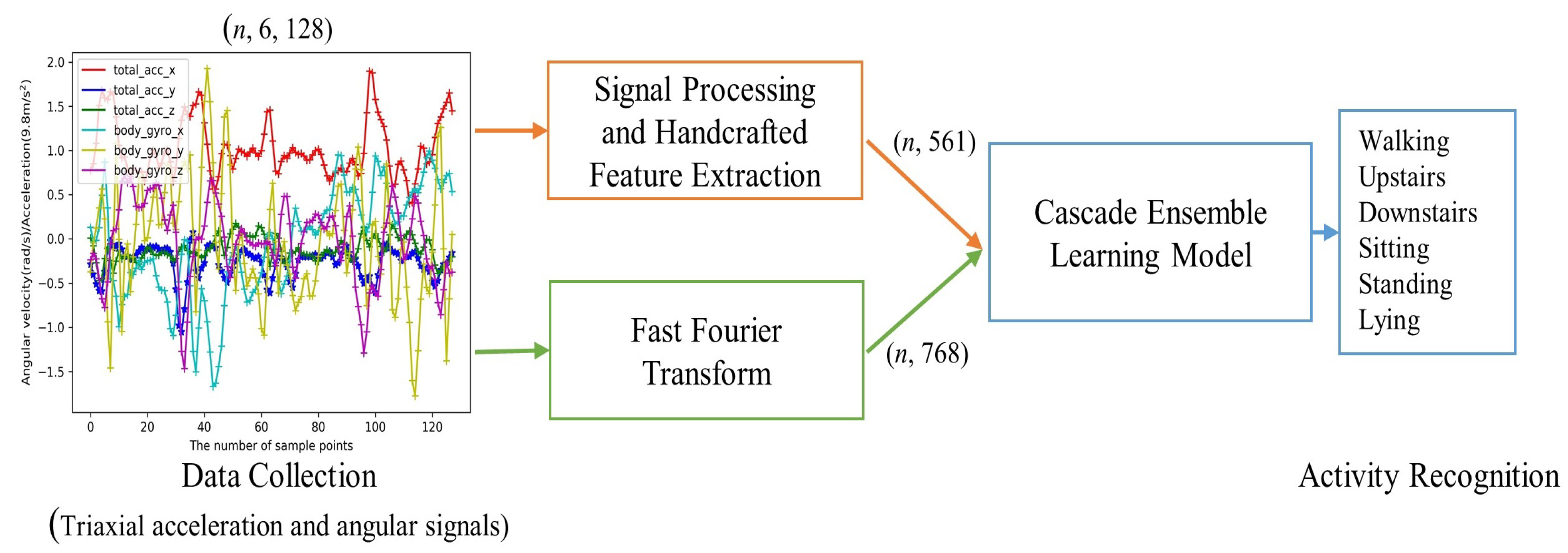
3. Overview of the Proposed HAR System
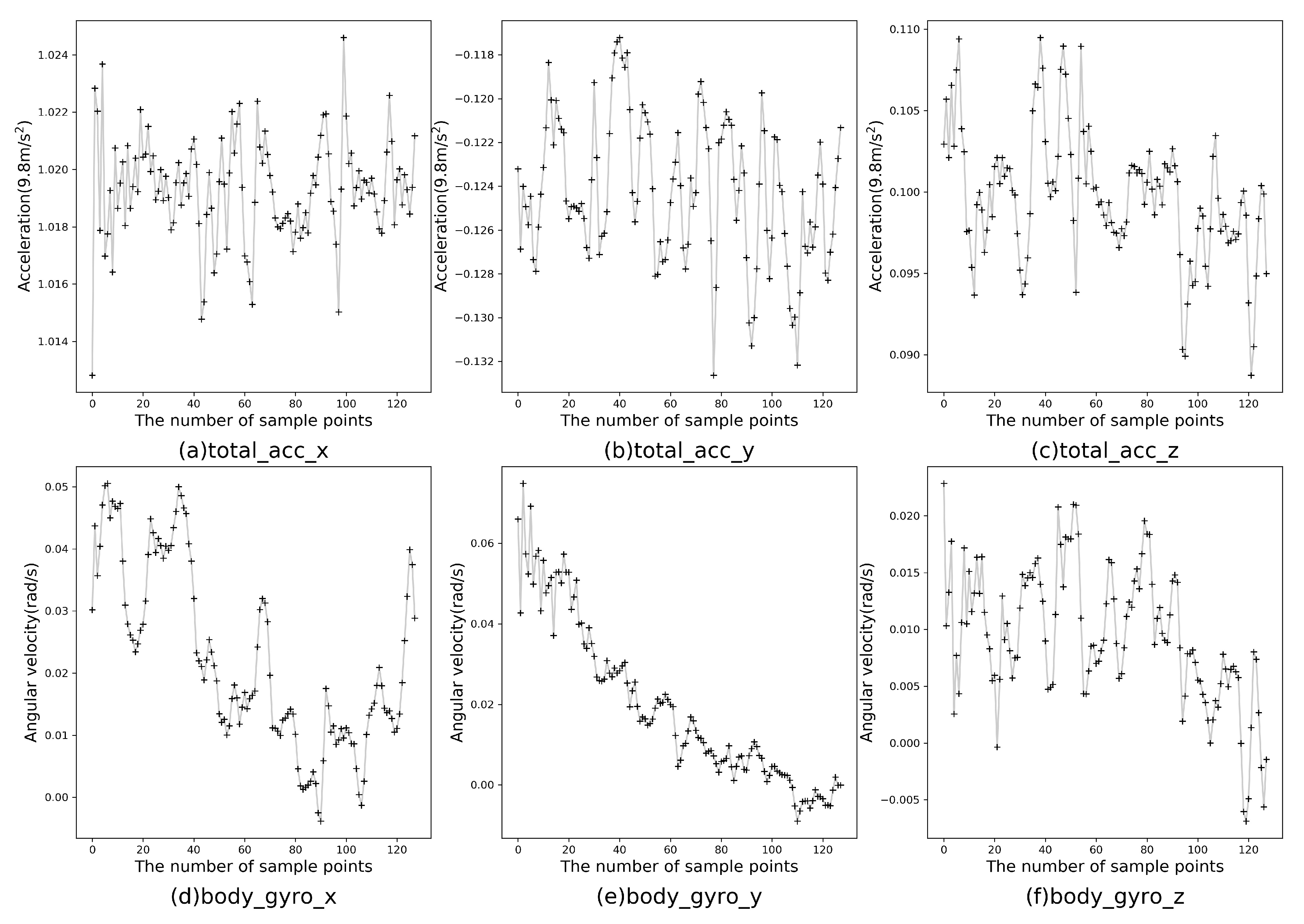
3.1. Data Collection, Signal Processing and Handcrafted Feature Extraction
3.2. FFT in Lower Pipeline
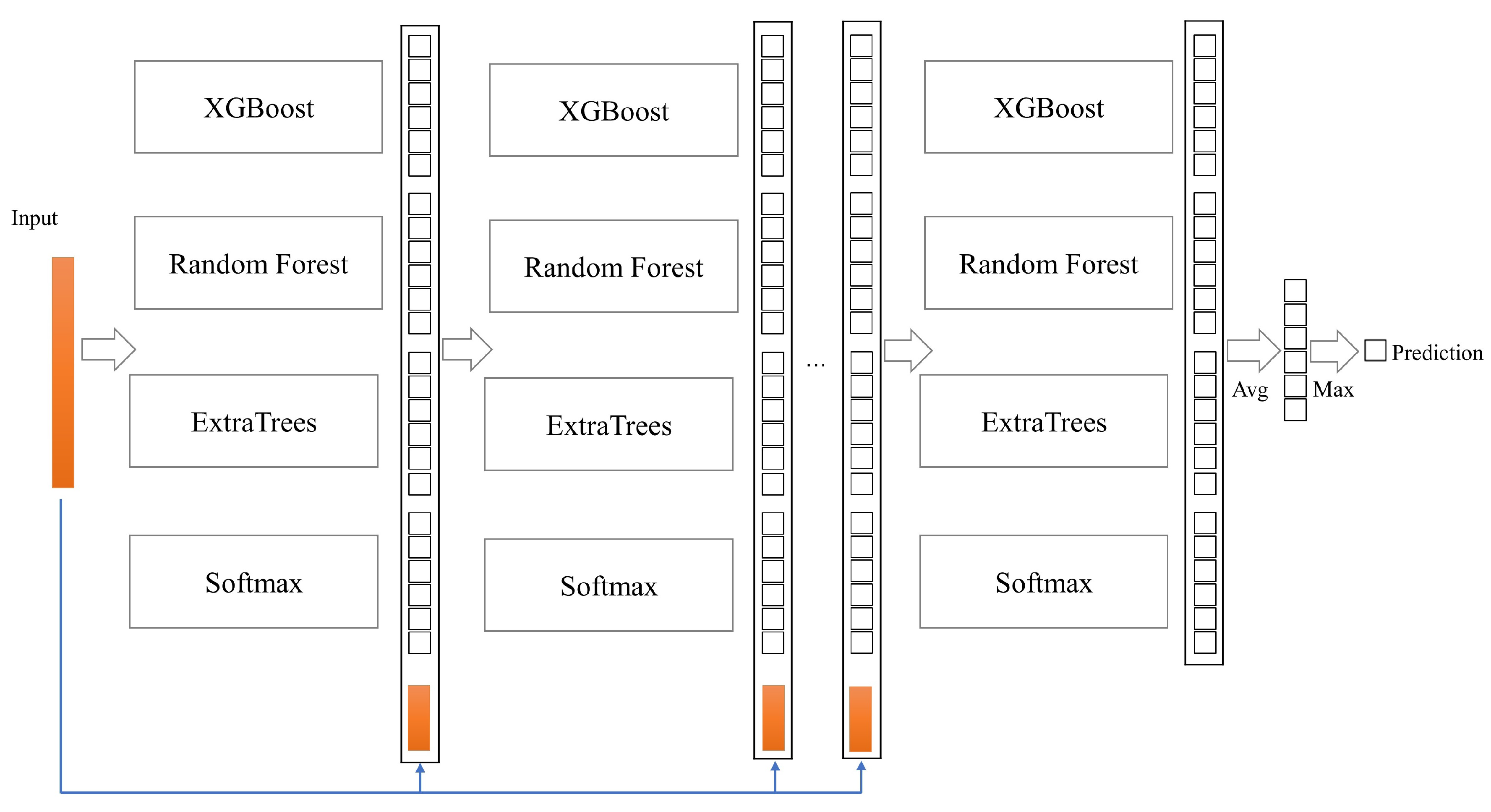
4. CELearning Model
4.1. XGBoost
4.2. Randomized Decision Trees
4.3. Softmax Regression
4.4. Augmented Features Generation
4.5. Confusion Matrix Definition
5. Experimental Results
5.1. HAR Based on Handcrafted Feature Extraction
5.2. HAR Based on Automatic Feature Extraction
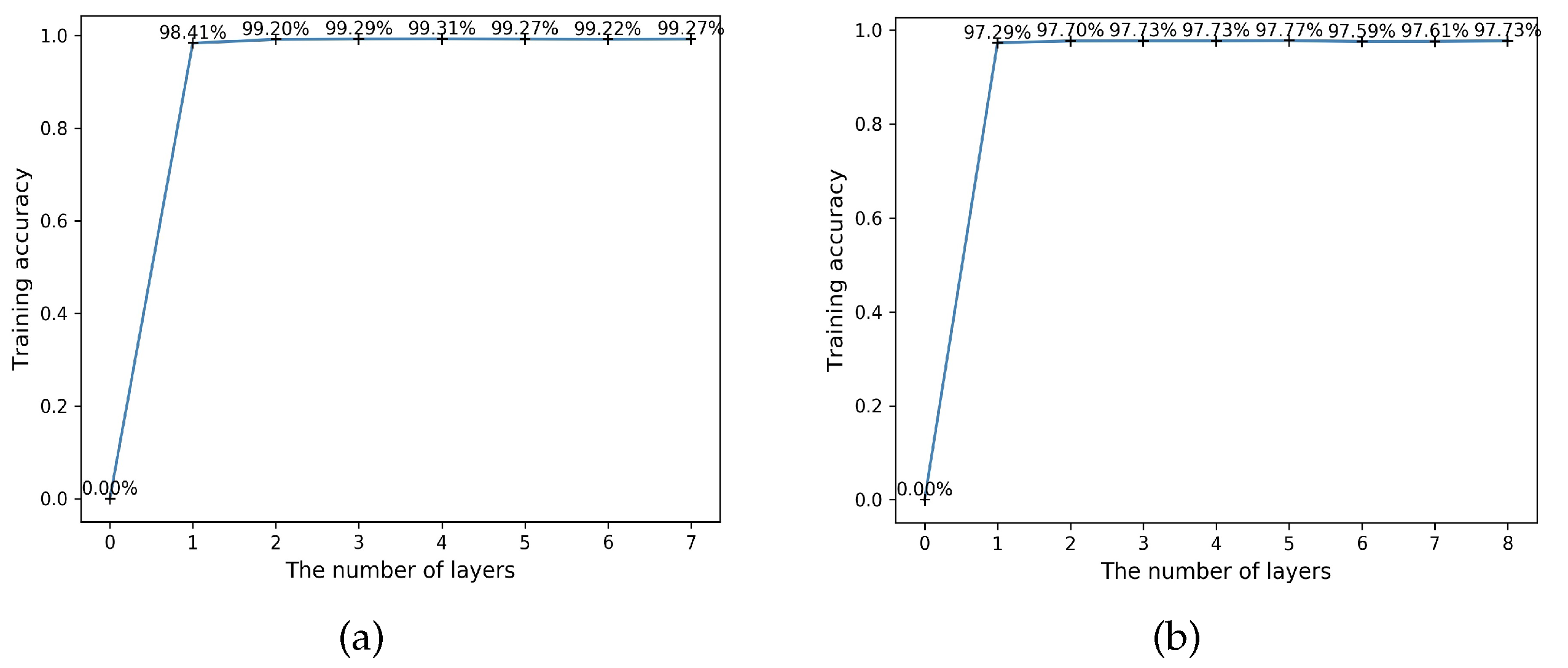
5.3. Convergence Analysis
5.4. Comparison of Different Combinations of Four Classifiers
5.5. Human Activities and Postural Transitions Recognition
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| CELearning | Cascade Ensemble Learning |
| CNN | Convolutional Neural Network |
| DBN | Deep Belief Network |
| ExtraTrees | Extremely Randomized Trees |
| FFT | Fast Fourier Transform |
| HAR | Human Activity Recognition |
| SAE | Stacked Autoencoder |
| SVM | Support Vector Machine |
| XGBoost | Extremely Gradient Boosting Trees |
References
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Onofri, L.; Soda, P.; Pechenizkiy, M.; Iannello, G. A Survey on Using Domain and Contextual Knowledge for Human Activity Recognition in Video Streams. Expert Syst. Appl. 2016, 63, 97–111. [Google Scholar] [CrossRef]
- Jia, Y.; Song, X.; Zhou, J.; Liu, L.; Nie, L.; Rosenblum, D.S. Fusing Social Networks with Deep Learning for Volunteerism Tendency Prediction. In Proceedings of the 30th AAAI Conference on Artificial Intelligence (AAAA-16), Phoenix, AZ, USA, 12–17 February 2016; pp. 165–171. [Google Scholar]
- Savazzi, S.; Rampa, V.; Vicentini, F.; Giussani, M. Device-free Human Sensing and Localization in Collaborative Human–robot Workspaces: A Case Study. IEEE Sens. J. 2016, 16, 1253–1264. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition Using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based Activity Recognition. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Incel, O. Analysis of Movement, Orientation and Rotation-based Sensing for Phone Placement Recognition. Sensors 2015, 15, 25474–25506. [Google Scholar] [CrossRef] [PubMed]
- Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M. Preprocessing Techniques for Context Recognition from Accelerometer Data. Pers. Ubiquit Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI-15), Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Wang, L. Recognition of Human Activities Using Continuous Autoencoders with Wearable Sensors. Sensors 2016, 16, 189. [Google Scholar] [CrossRef]
- Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep Activity Recognition Models with Triaxial Accelerometers. In Proceedings of the Workshops at the 30th AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016; pp. 8–13. [Google Scholar]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep Learning Algorithms for Human Activity Recognition Using Mobile and Wearable Sensor Networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Krüger, F.; Nyolt, M.; Yordanova, K.; Hein, A.; Kirste, T. Computational State Space Models for Activity and Intention Recognition. A feasibility study. PLoS ONE 2014, 9, e109381. [Google Scholar] [CrossRef]
- Yordanova, K.; Lüdtke, S.; Whitehouse, S.; Krüger, F.; Paiement, A.; Mirmehdi, M.; Craddock, I.; Kirste, T. Analysing Cooking Behaviour in Home Settings: Towards Health Monitoring. Sensors 2019, 19, 646. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Nugent, C.; Okeyo, G. An Ontology-Based Hybrid Approach to Activity Modeling for Smart Homes. IEEE Trans. Hum. Mach. Syst. 2014, 44, 92–105. [Google Scholar] [CrossRef] [Green Version]
- Ye, J.; Stevenson, G.; Dobson, S. USMART: An Unsupervised Semantic Mining Activity Recognition Technique. ACM Trans. Inter. Intel. Syst. 2014, 4, 16. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity Recognition from User-annotated Acceleration Data. In Proceedings of the International Conference on Pervasive Computing, Vienna, Austria, 18–23 April 2004; pp. 1–17. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity Recognition Using Cell Phone Accelerometers. ACM SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Abidine, B.M.H.; Fergani, L.; Fergani, B.; Oussalah, M. The Joint Use of Sequence Features Combination and Modified Weighted SVM for Improving Daily Activity Recognition. Pattern Anal. Appl. 2018, 21, 119–138. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.; Scholten, H.; Havinga, P. Fusion of Smartphone Motion Sensors for Physical Activity Recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, W.; Dasgupta, S.; Ramirez, E.E.; Peterson, C.; Norman, G.J. Classification Accuracies of Physical Activities Using Smartphone Motion Sensors. J. Med. Internet Res. 2012, 14, e130. [Google Scholar] [CrossRef]
- Khan, A.M. Recognizing Physical Activities Using Wii Remote. Int. J. Inform. Educ. Technol. 2013, 3, 60–62. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition Using Smartphones. In Proceedings of the European Symposium on Artifical Neural Networks, Computational Intelligence and Machine Learning (ESANN 2013), Bruges, Belgium, 24–26 April 2013; pp. 437–442. [Google Scholar]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A Robust Human Activity Recognition System Using Smartphone Sensors and Deep Learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Yeh, R.A.; Chen, C.; Yian Lim, T.; Schwing, A.G.; Hasegawa-Johnson, M.; Do, M.N. Semantic Image Inpainting with Deep Generative Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 5485–5493. [Google Scholar]
- Bukhari, D.; Wang, Y.; Wang, H. Multilingual Convolutional, Long Short-term Memory, Deep Neural Networks for Low Resource Speech Recognition. Proc. Comput. Sci. 2017, 107, 842–847. [Google Scholar] [CrossRef]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015), Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Sannino, G.; De Pietro, G. A Deep Learning Approach for ECG-based Heartbeat Classification for Arrhythmia Detection. Future Gener. Comput. Syst. 2018, 86, 446–455. [Google Scholar] [CrossRef]
- Radu, V.; Lane, N.D.; Bhattacharya, S.; Mascolo, C.; Marina, M.K.; Kawsar, F. Towards Multimodal Deep Learning for Activity Recognition on Mobile Devices. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct (UbiComp 2016), Heidelberg, Germany, 12–16 September 2016; pp. 185–188. [Google Scholar]
- Li, H.; Trocan, M. Deep Learning of Smartphone Sensor Data for Personal Health Assistance. Microelectron. J. 2018. [Google Scholar] [CrossRef]
- Wang, A.; Chen, G.; Shang, C.; Zhang, M.; Liu, L. Human Activity Recognition in a Smart Home Environment with Stacked Denoising Autoencoders. In Proceedings of the International Conference on Web-Age Information Management (WAIM 2016), Nanchang, China, 3–5 June 2016; pp. 29–40. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human Activity Recognition with Smartphone Sensors Using Deep Learning Neural Networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Ha, S.; Yun, J.M.; Choi, S. Multi-modal Convolutional Neural Networks for Activity Recognition. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics (SMC 2015), Kowloon, China, 9–12 October 2015; pp. 3017–3022. [Google Scholar]
- Chen, Y.; Zhong, K.; Zhang, J.; Sun, Q.; Zhao, X. Lstm Networks for Mobile Human Activity Recognition. In Proceedings of the 2016 International Conference on Artificial Intelligence: Technologies and Applications (ICAITA 2016), Bangkok, Thailand, 24–25 January 2016; pp. 50–53. [Google Scholar]
- Zhou, Z.H.; Feng, J. Deep forest: Towards an Alternative to Deep Neural Networks. arXiv 2017, arXiv:1702.08835. [Google Scholar]
- Zhou, Z.H. Diversity. In Ensemble Methods: Foundations and Algorithms; Herbrich, R., Graepel, T., Eds.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2012; pp. 99–118. ISBN 9781439830031. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2016), San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Bishop, C.M. Linear Models for Classification. In Pattern Recognition and Machine Learning; Jordan, M., Kleinerg, J., Schölkopf, B., Eds.; Springer: New York, NY, USA, 2006; pp. 179–224. ISBN 978-0387-31073-2. [Google Scholar]
- Lockhart, J.W.; Weiss, G.M.; Xue, J.C.; Gallagher, S.T.; Grosner, A.B.; Pulickal, T.T. Design Considerations for the WISDM Smart Phone-based Sensor Mining Architecture. In Proceedings of the Fifth International Workshop on Knowledge Discovery from Sensor Data (SensorKDD ’11), San Diego, CA, USA, 21 August 2011; pp. 25–33. [Google Scholar]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millán, J.D.R.; Roggen, D. The Opportunity Challenge: A Benchmark Database for On-body Sensor-based Activity Recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef]
- Recognising User Actions During Cooking Task (Cooking Task Dataset)–IMU Data. Available online: http://purl.uni-rostock.de/rosdok/id00000154 (accessed on 18 October 2017).
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-aware Human Activity Recognition Using Smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Class | ||||||||
|---|---|---|---|---|---|---|---|---|
| Walking | Upstairs | Downstairs | Sitting | Standing | Lying | Precision | ||
| Predicted Class | Walking | 492 16.69% | 22 0.75% | 4 0.14% | 0 0.00% | 0 0.00% | 0 0.00% | 94.98% 5.02% |
| Upstairs | 1 0.03% | 448 15.20% | 17 0.58% | 0 0.00% | 0 0.00% | 0 0.00% | 96.14% 3.86% | |
| Downstairs | 3 0.10% | 1 0.03% | 399 13.54% | 0 0.00% | 0 0.00% | 0 0.00% | 99.01% 0.99% | |
| Sitting | 0 0.00% | 0 0.00% | 0 0.00% | 464 15.74% | 17 0.58% | 0 0.00% | 96.47 3.53% | |
| Standing | 0 0.00% | 0 0.00% | 0 0.00% | 27 0.92% | 515 17.48% | 0 0.00% | 95.02% 4.98% | |
| Lying | 0 0.00% | 0 0.00% | 0 0.00% | 0 0.00% | 0 0.00% | 537 18.22% | 100.00% 0.00% | |
| Recall | 99.19% 0.81% | 95.12% 4.88% | 95.00% 5.00% | 94.50% 5.50% | 96.80% 3.20% | 100.00% 0.00% | 96.88% 3.12% | |
| Approach | Accuracy |
|---|---|
| ANN (as reported in [32]) | 91.08% |
| SVM [23] | 96.00% |
| DBN (as reported in [30]) | 95.80% |
| SAE [30] | 96.50% |
| CELearning (proposed) | 96.88% |
| Target Class | ||||||||
|---|---|---|---|---|---|---|---|---|
| Walking | Upstairs | Downstairs | Sitting | Standing | Lying | Precision | ||
| Predicted Class | Walking | 493 16.73% | 3 0.10% | 12 0.41% | 0 0.00% | 0 0.00% | 0 0.00% | 97.05% 2.95% |
| Upstairs | 1 0.03% | 464 15.74% | 27 0.92% | 1 0.03% | 0 0.00% | 0 0.00% | 94.12% 5.88% | |
| Downstairs | 2 0.07% | 4 0.14% | 381 12.93% | 0 0.00% | 0 0.00% | 0 0.00% | 98.45% 1.55% | |
| Sitting | 0 0.00% | 0 0.00% | 0 0.00% | 432 14.66% | 12 0.41% | 0 0.00% | 97.30% 2.70% | |
| Standing | 0 0.00% | 0 0.00% | 0 0.00% | 58 1.97% | 520 17.65% | 0 0.00% | 89.97% 10.03% | |
| Lying | 0 0.00% | 0 0.00% | 0 0.00% | 0 0.00% | 0 0.00% | 537 18.22% | 100.00% 0.00% | |
| Recall | 99.40% 0.60% | 98.51% 1.49% | 90.71% 9.29% | 87.98% 12.02% | 97.74% 2.26% | 100.00% 0.00% | 95.93% 4.07% | |
| Approach | Accuracy |
|---|---|
| CNN [32] | 95.75% |
| DBN (as reported in [30]) | 95.50% |
| SAE [30] | 95.59% |
| CELearning (proposed) | 95.93% |
| Approach | Mean Value (%) | Standard Deviation (%) |
|---|---|---|
| XGBoost | 90.87 | 0.00 |
| ExtraTrees | 94.12 | 0.15 |
| Random Forest | 92.77 | 0.19 |
| Softmax Regression | 95.89 | 0.00 |
| CELearning (Softmax Regression + ExtraTrees) | 96.64 | 0.08 |
| CELearning (Softmax Regression + ExtraTrees + Random Forest) | 96.65 | 0.11 |
| CELearning (proposed) | 96.67 | 0.11 |
| Approach | Mean Value (%) | Standard Deviation (%) |
|---|---|---|
| XGBoost | 94.33 | 0.00 |
| ExtraTrees | 91.40 | 0.12 |
| Random Forest | 92.12 | 0.20 |
| Softmax Regression | 90.77 | 0.00 |
| CELearning (XGBoost + Softmax Regression) | 95.45 | 0.15 |
| CELearning (XGBoost + Softmax Regression + Random Forest) | 95.56 | 0.15 |
| CELearning (proposed) | 95.82 | 0.06 |
| Approach | Total Rightly Classified Samples | Overall Accuracy | Total Wrongly Classified Samples |
|---|---|---|---|
| ANN | 2816 | 89.06% | 346 |
| SVM | 2976 | 94.12% | 186 |
| CELearning | 3007 | 95.10% | 155 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Tang, Q.; Jin, L.; Pan, Z. A Cascade Ensemble Learning Model for Human Activity Recognition with Smartphones. Sensors 2019, 19, 2307. https://doi.org/10.3390/s19102307
Xu S, Tang Q, Jin L, Pan Z. A Cascade Ensemble Learning Model for Human Activity Recognition with Smartphones. Sensors. 2019; 19(10):2307. https://doi.org/10.3390/s19102307
Chicago/Turabian StyleXu, Shoujiang, Qingfeng Tang, Linpeng Jin, and Zhigeng Pan. 2019. "A Cascade Ensemble Learning Model for Human Activity Recognition with Smartphones" Sensors 19, no. 10: 2307. https://doi.org/10.3390/s19102307
APA StyleXu, S., Tang, Q., Jin, L., & Pan, Z. (2019). A Cascade Ensemble Learning Model for Human Activity Recognition with Smartphones. Sensors, 19(10), 2307. https://doi.org/10.3390/s19102307