High-Precision Indoor Visible Light Positioning Using Modified Momentum Back Propagation Neural Network with Sparse Training Point


 ,
, 
Abstract
:1. Introduction
2. Theory and Methods
2.1. Traditional RSS Algorithm
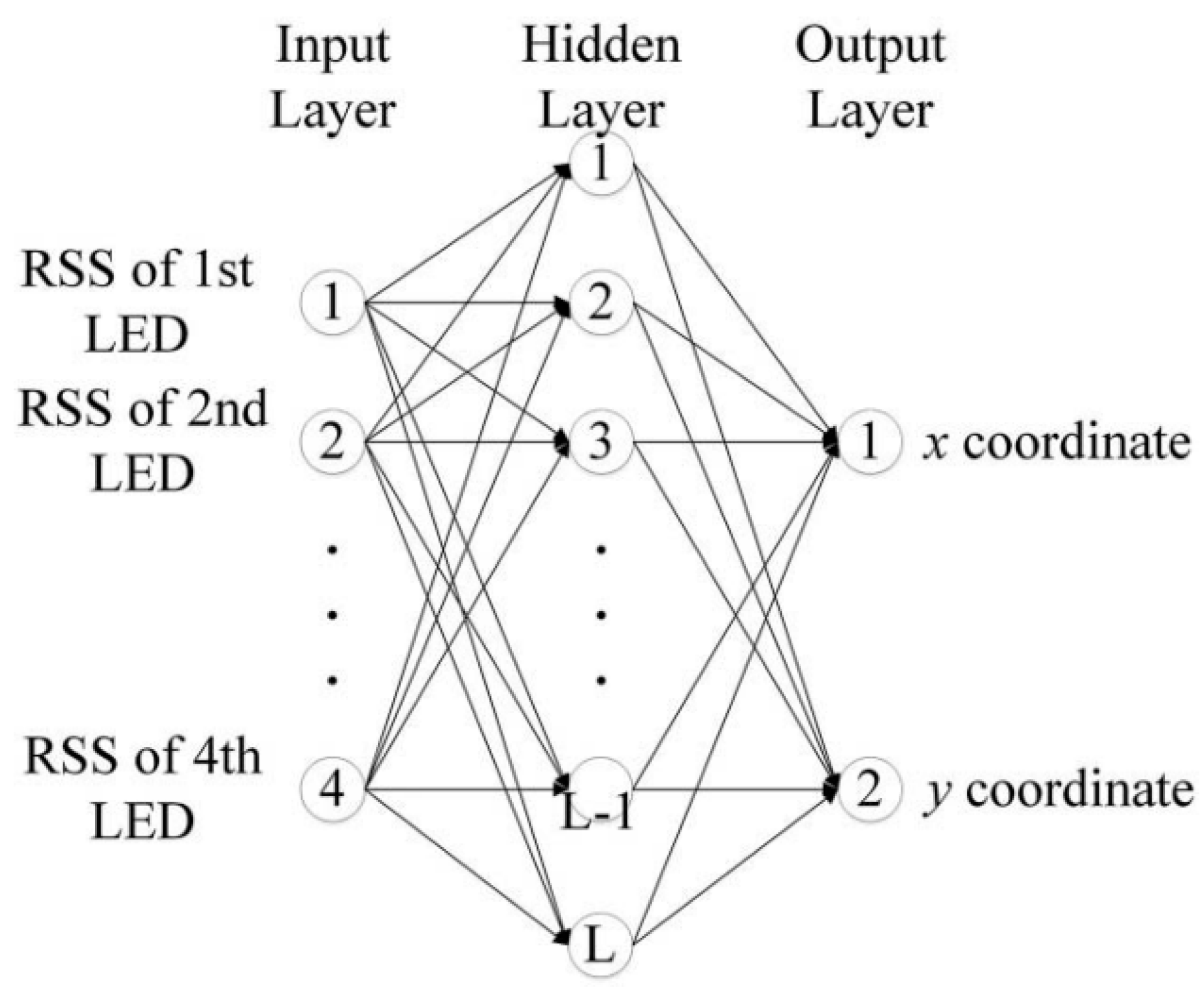
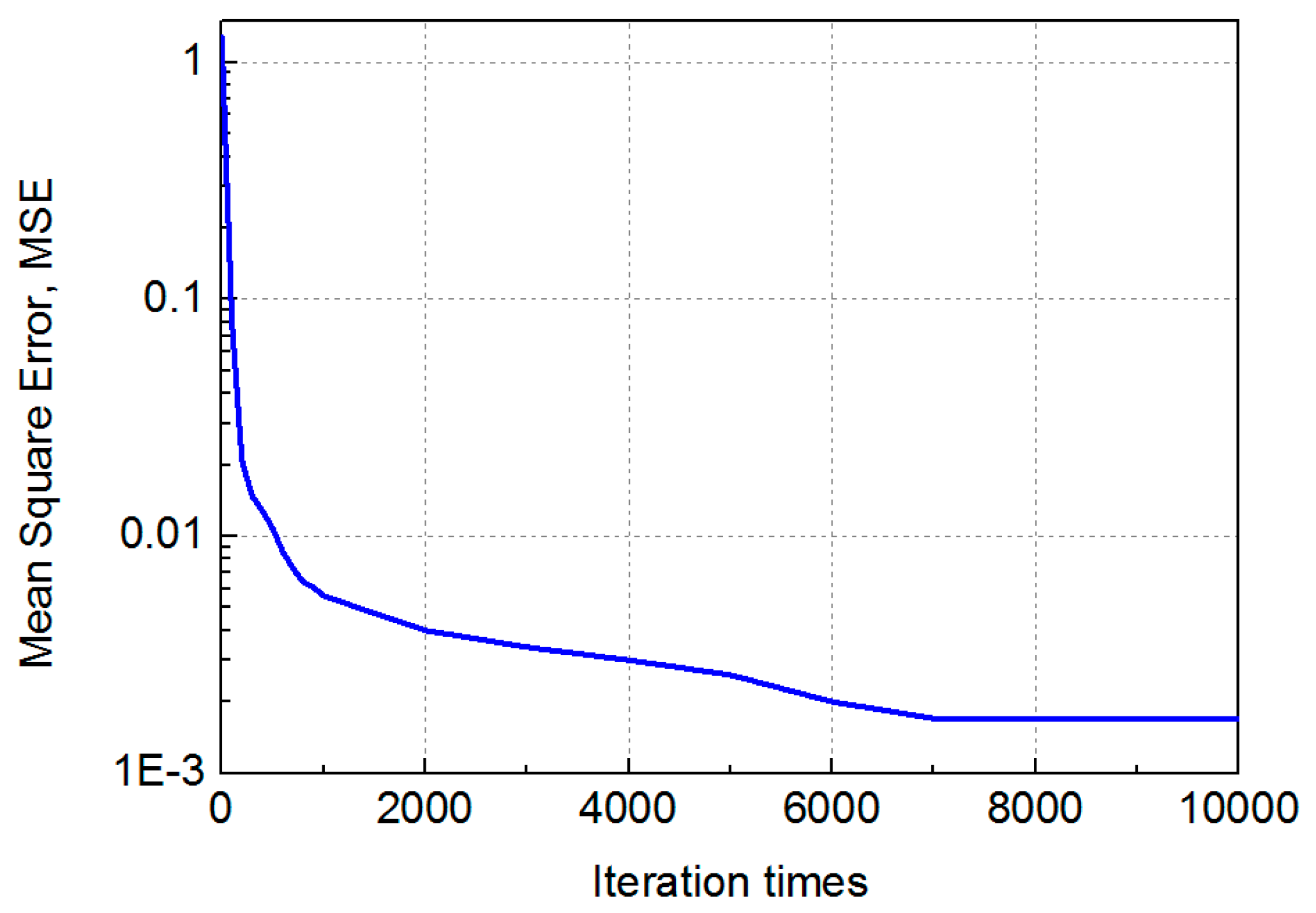
2.2. Modified Momentum Back Propagation (MMBP) Algorithm
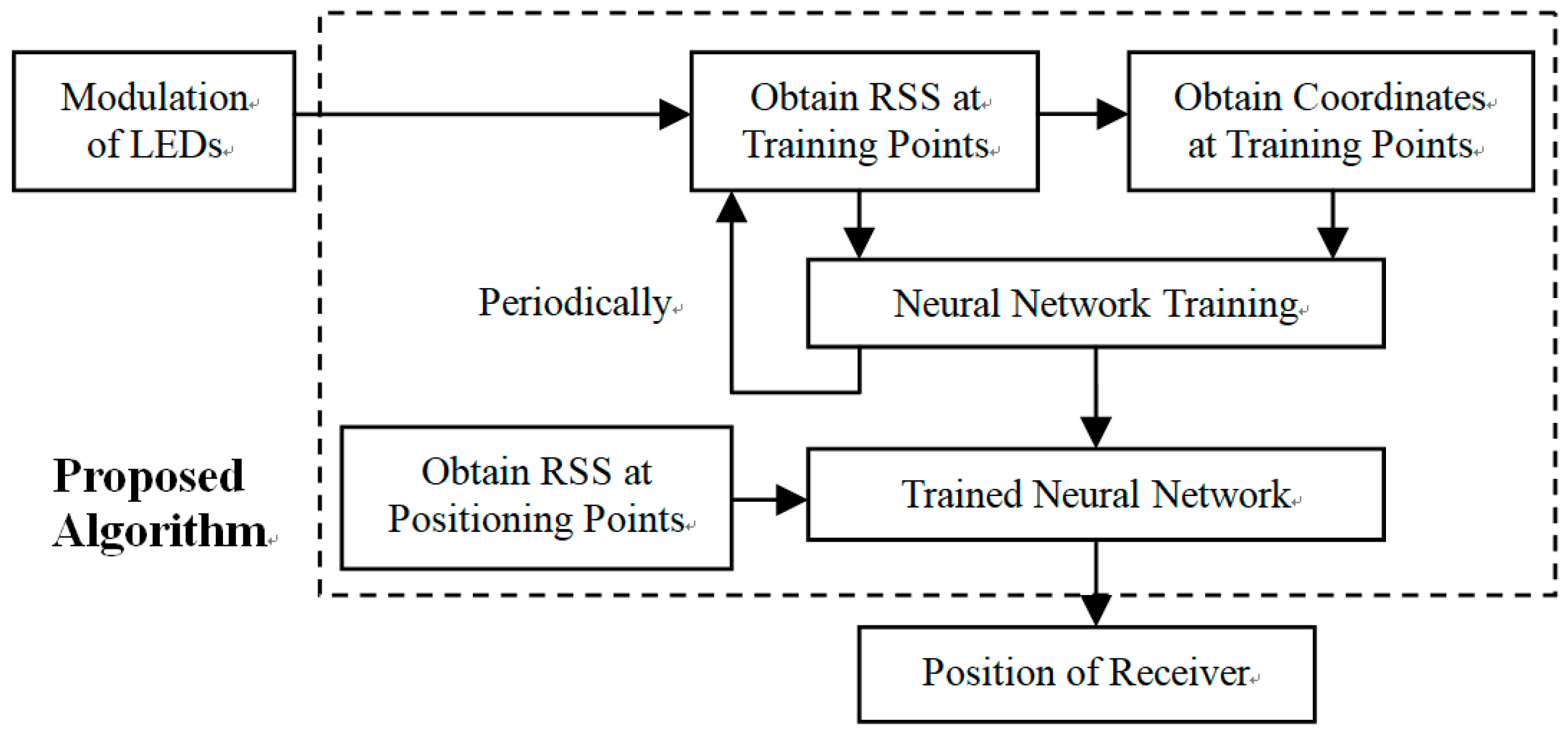
3. Experiment and Results
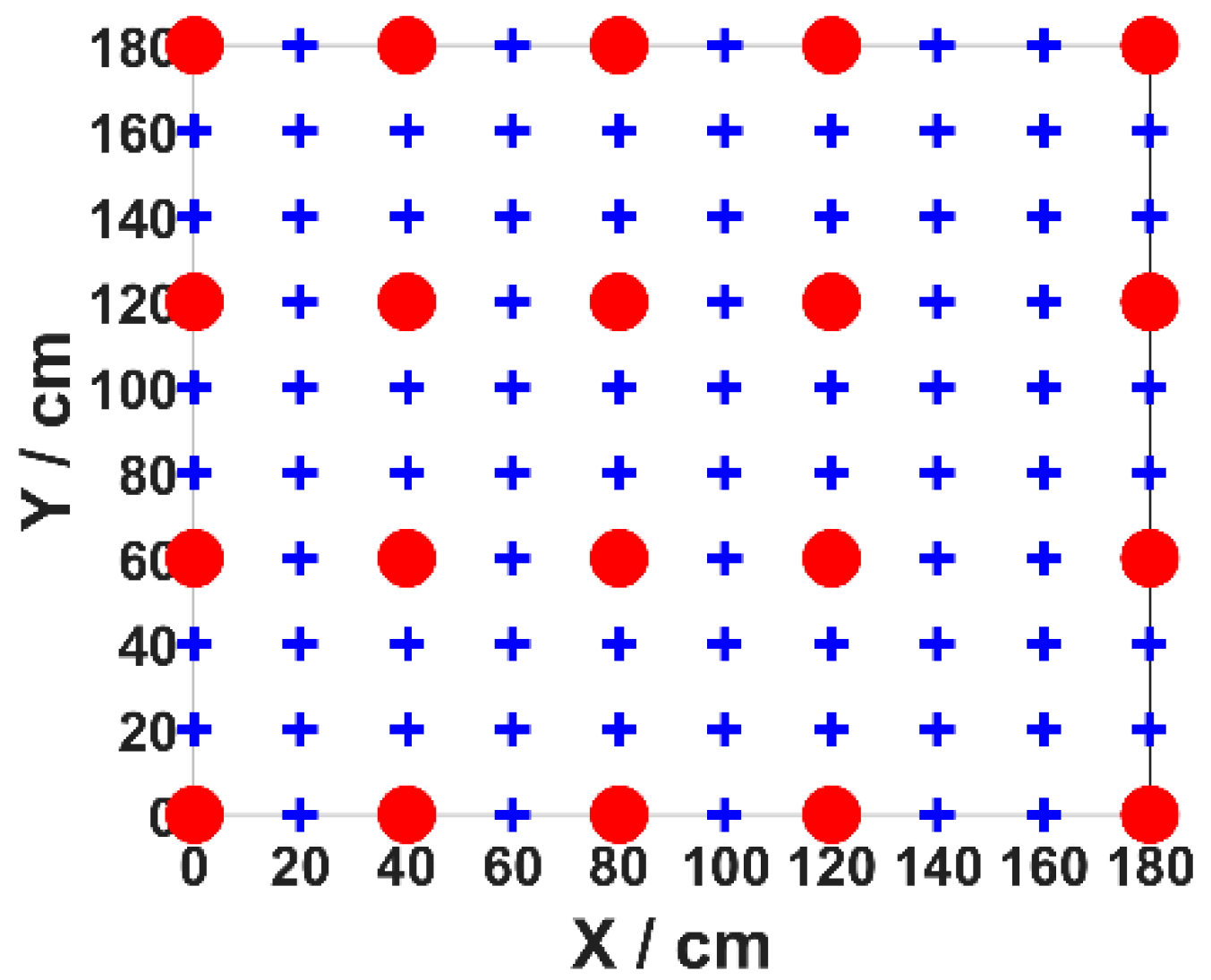
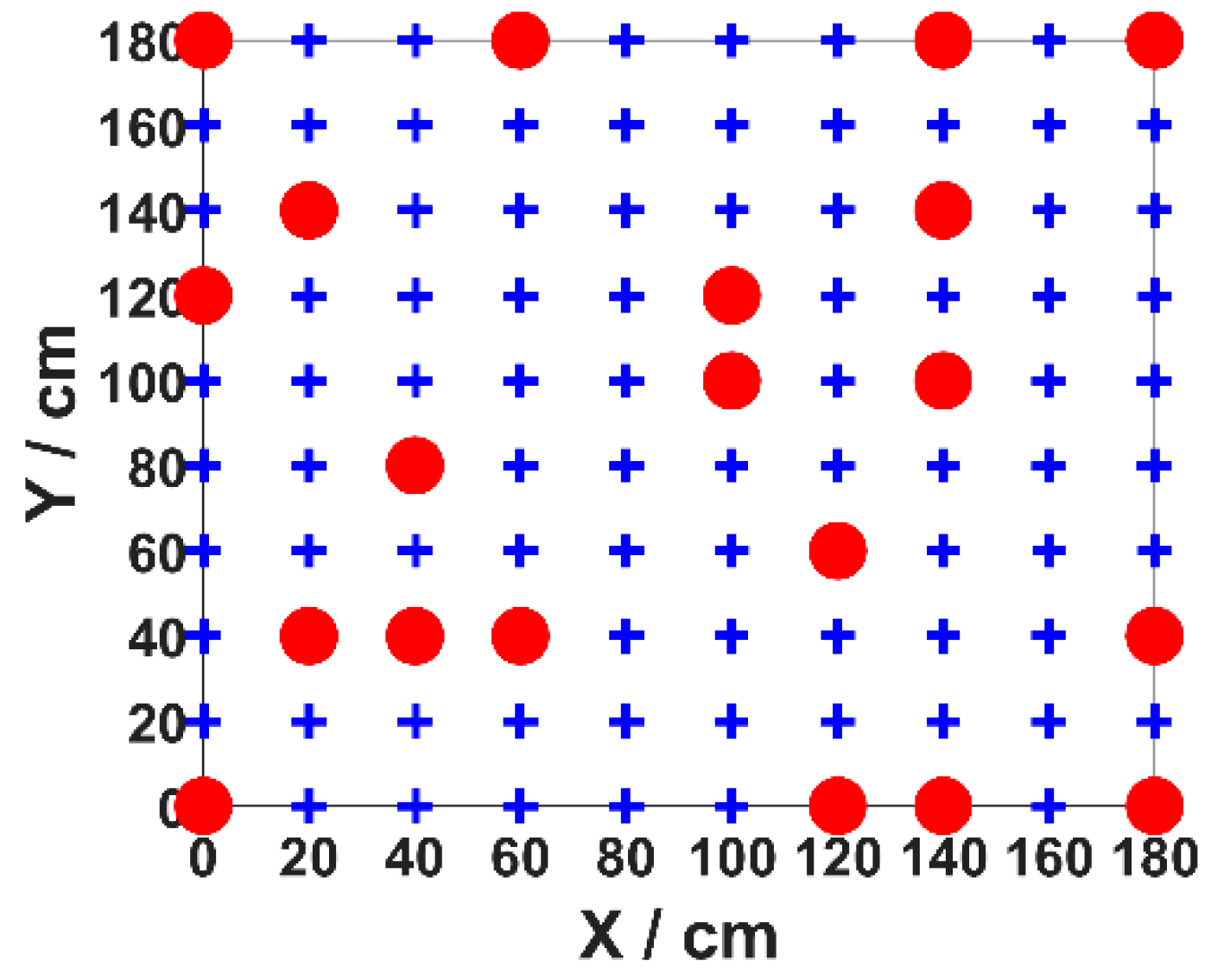
3.1. Experimental Facilities
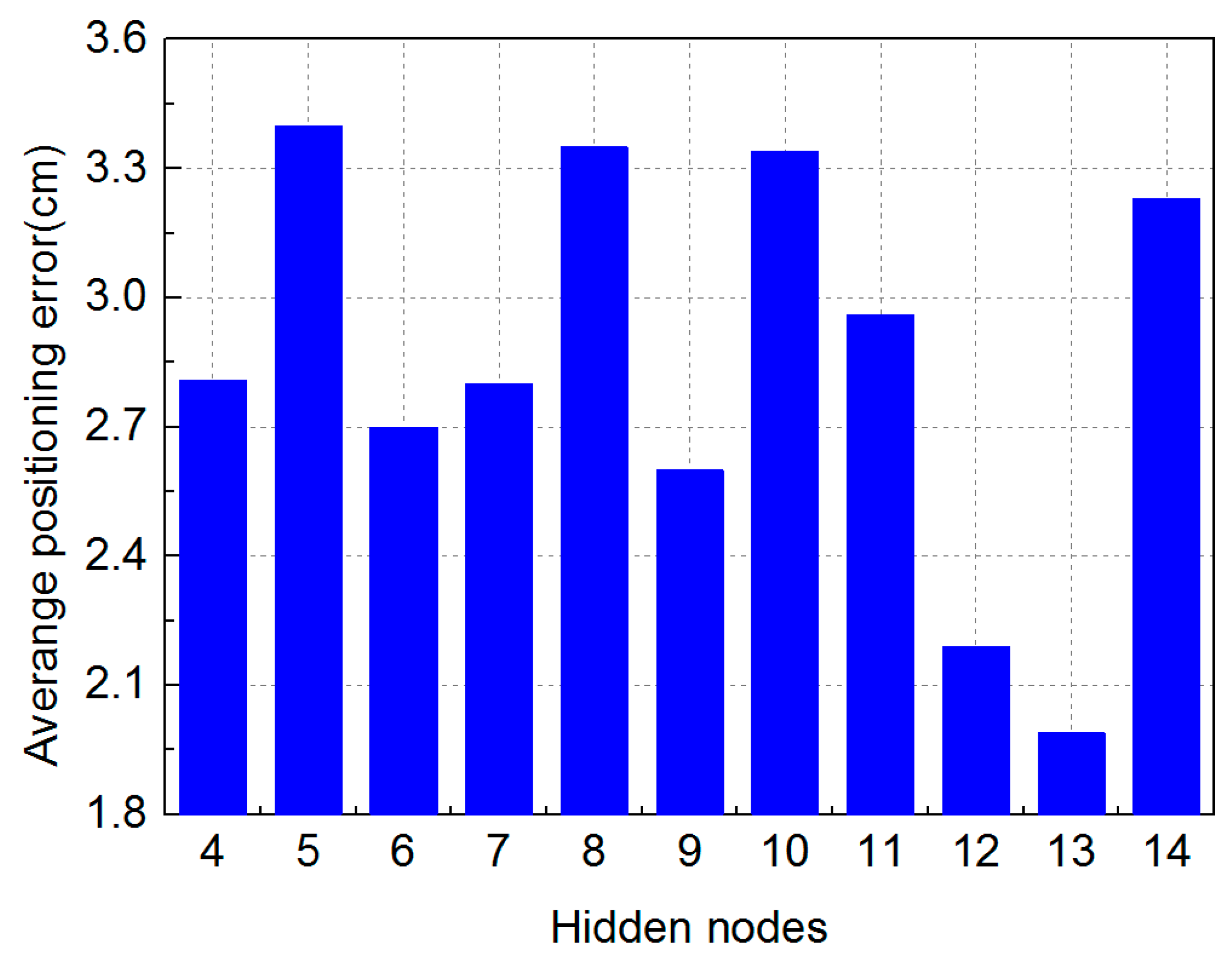
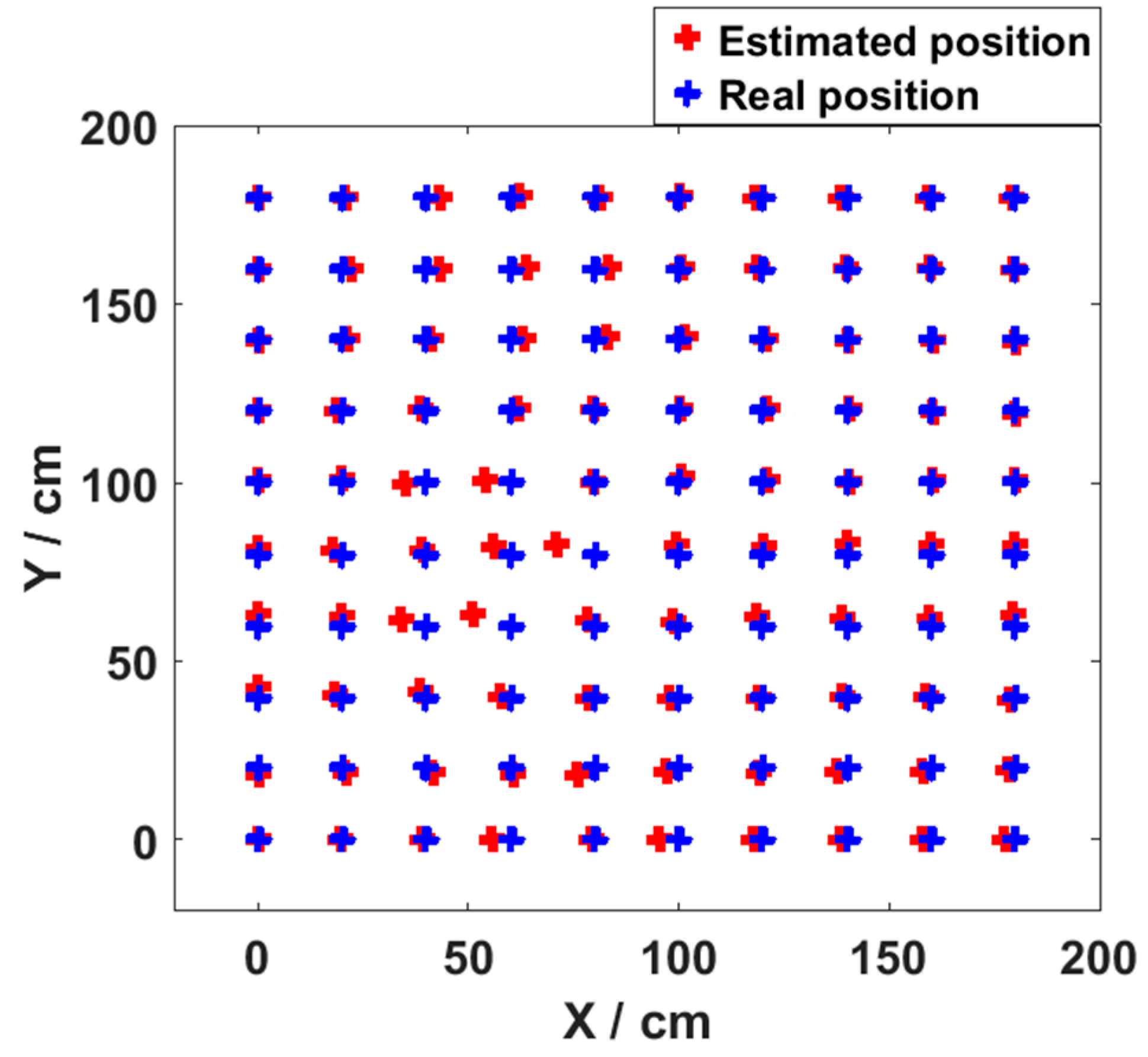
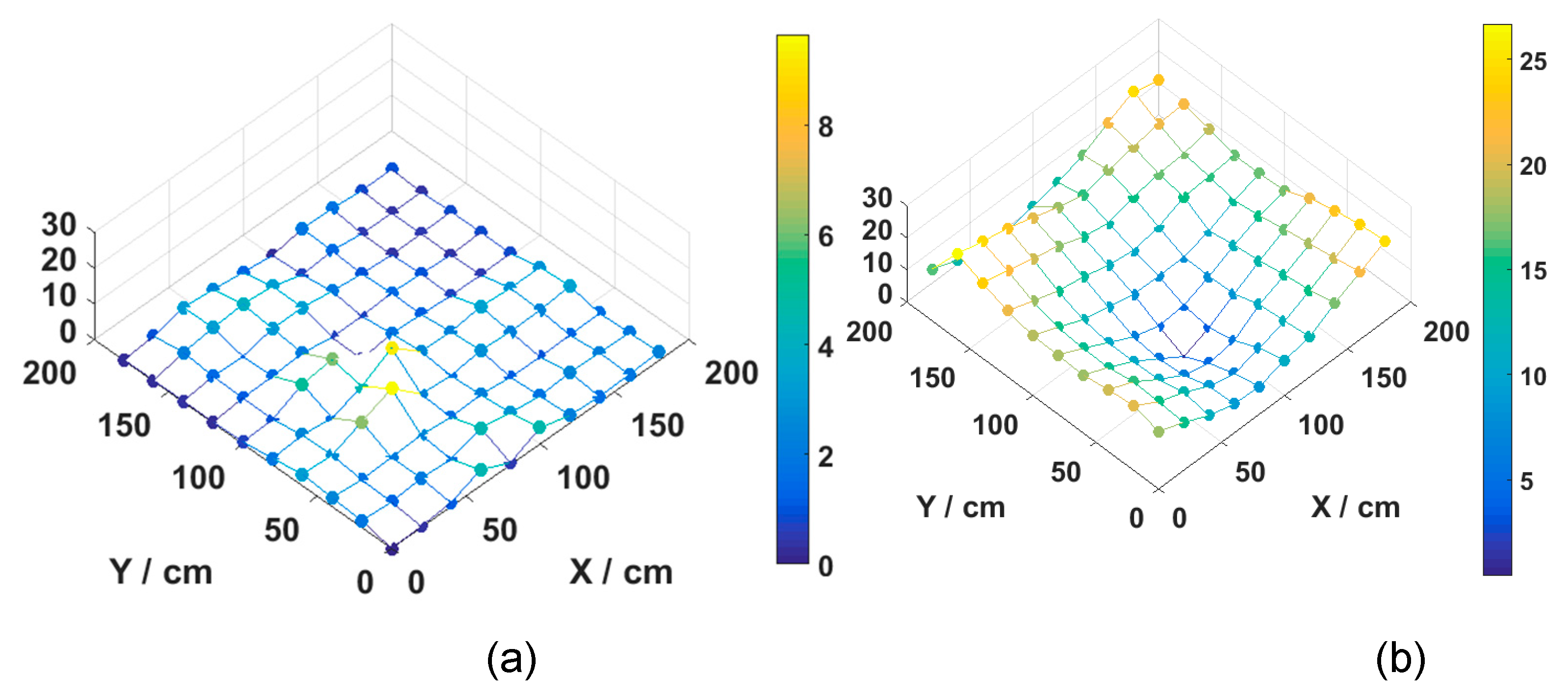
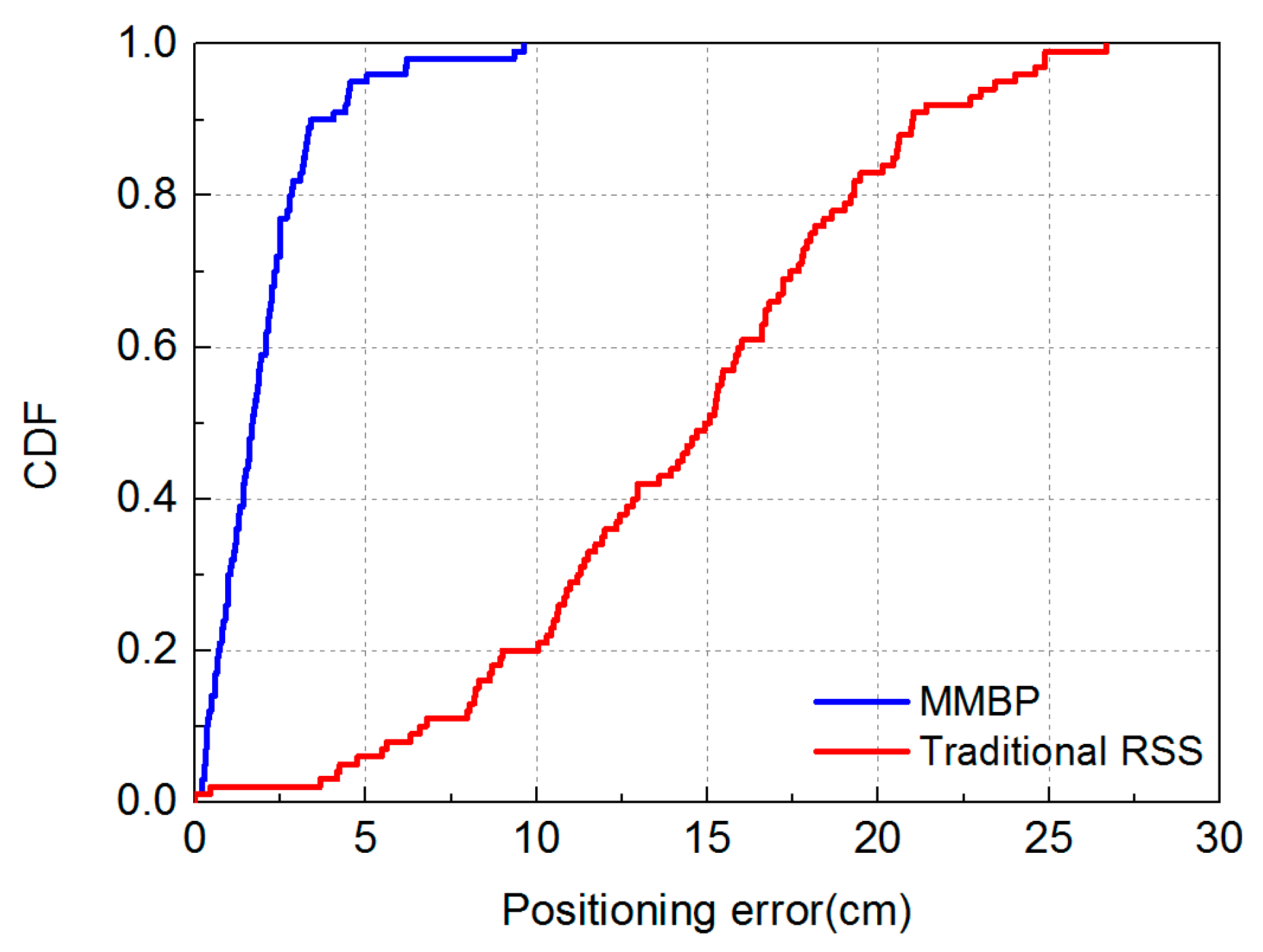
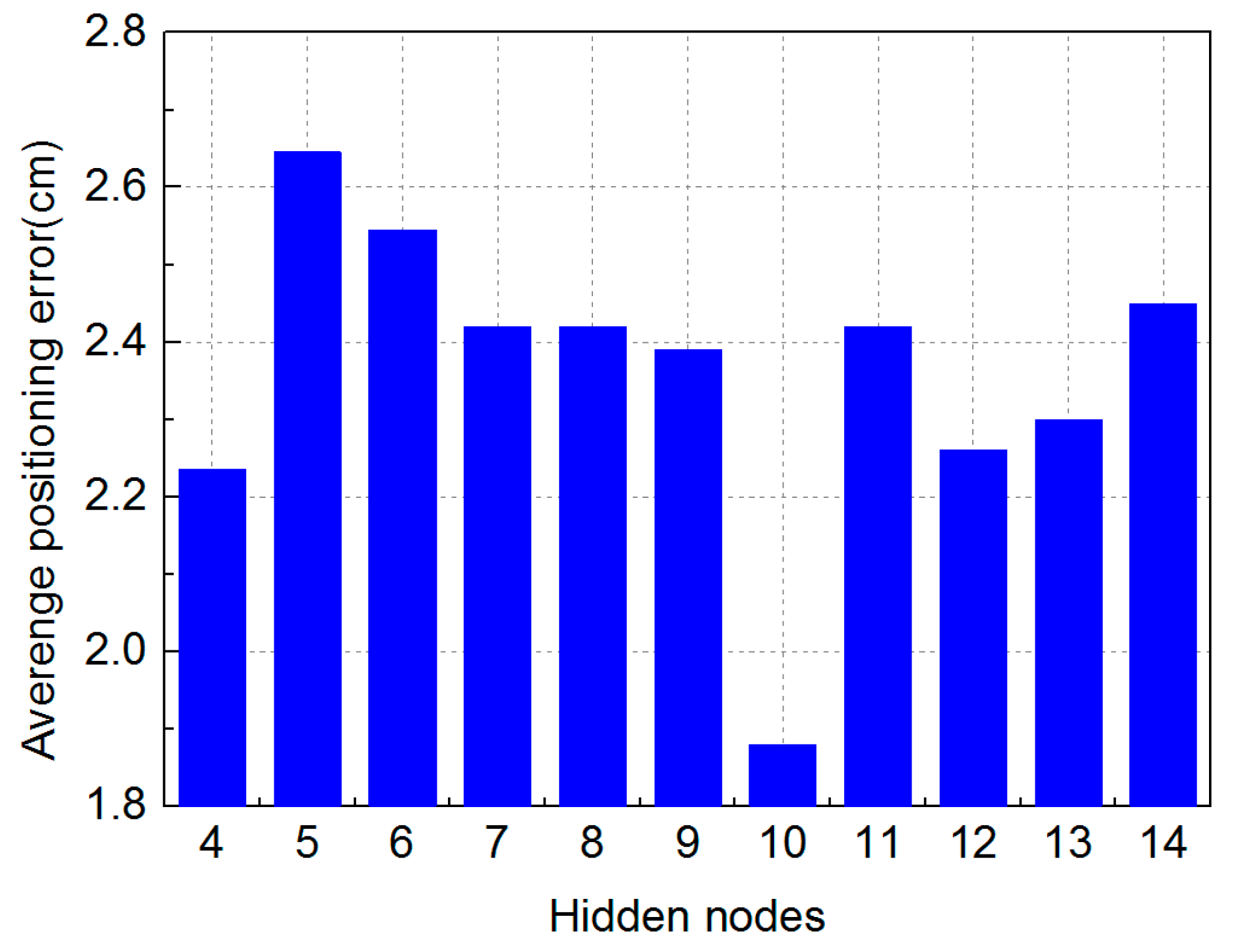
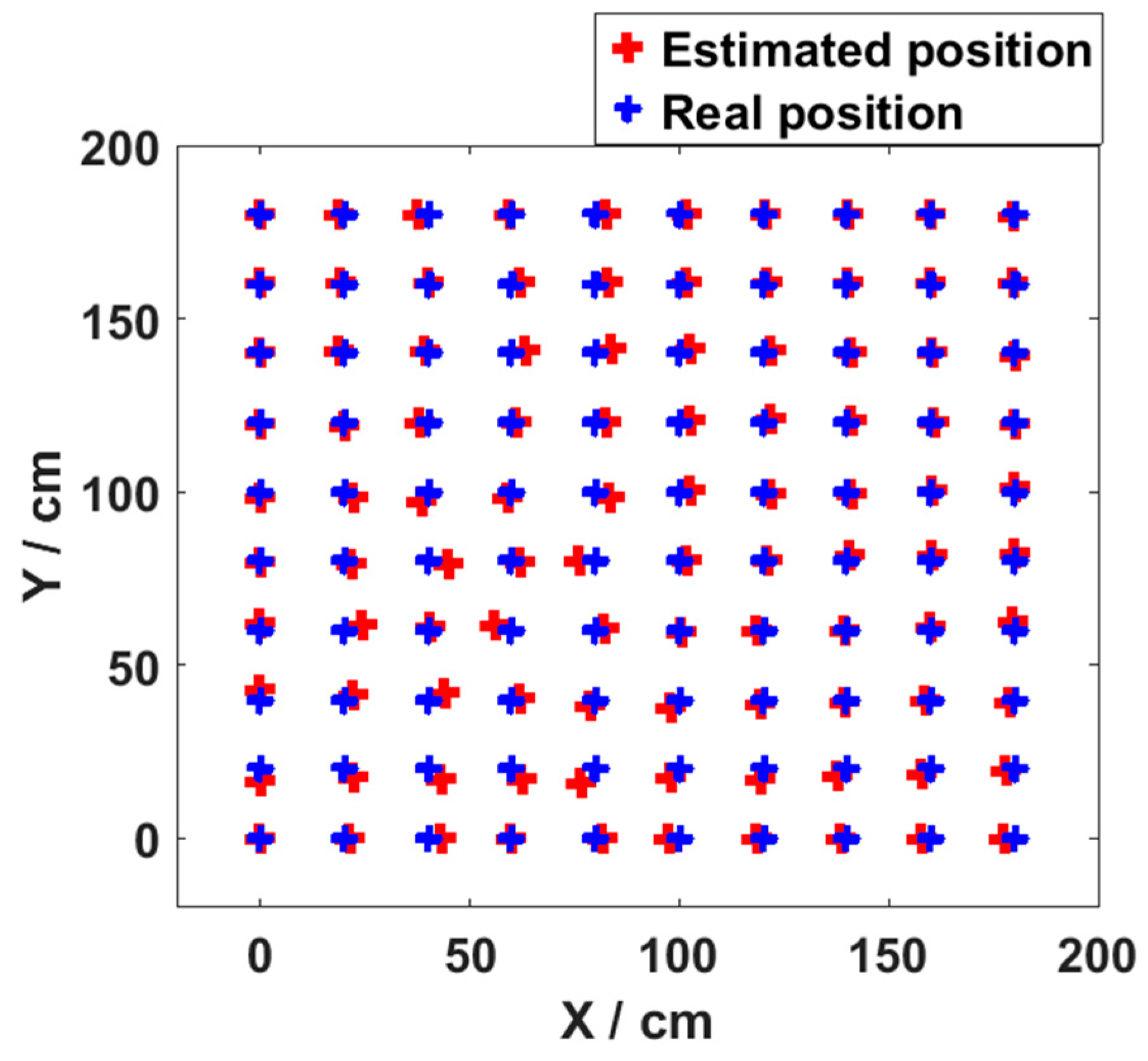
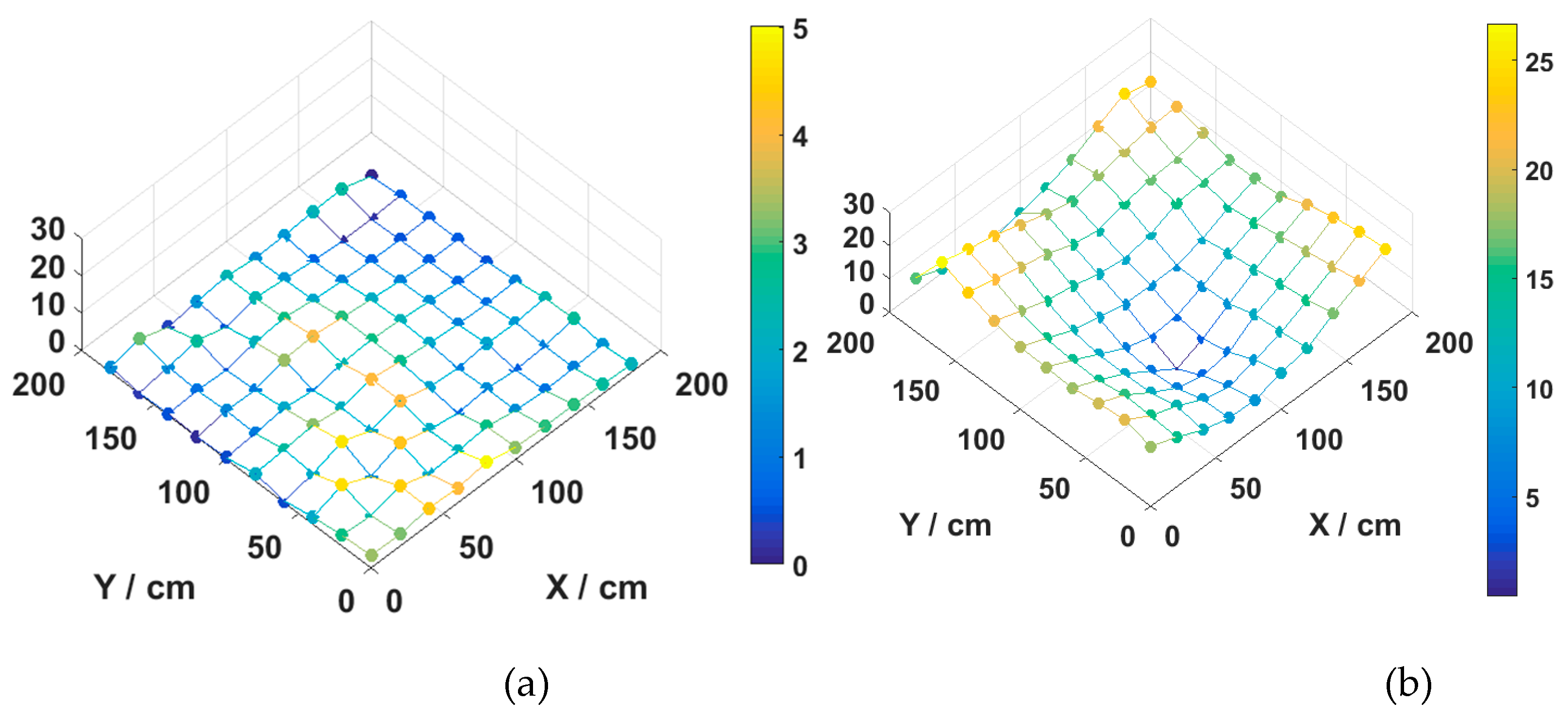
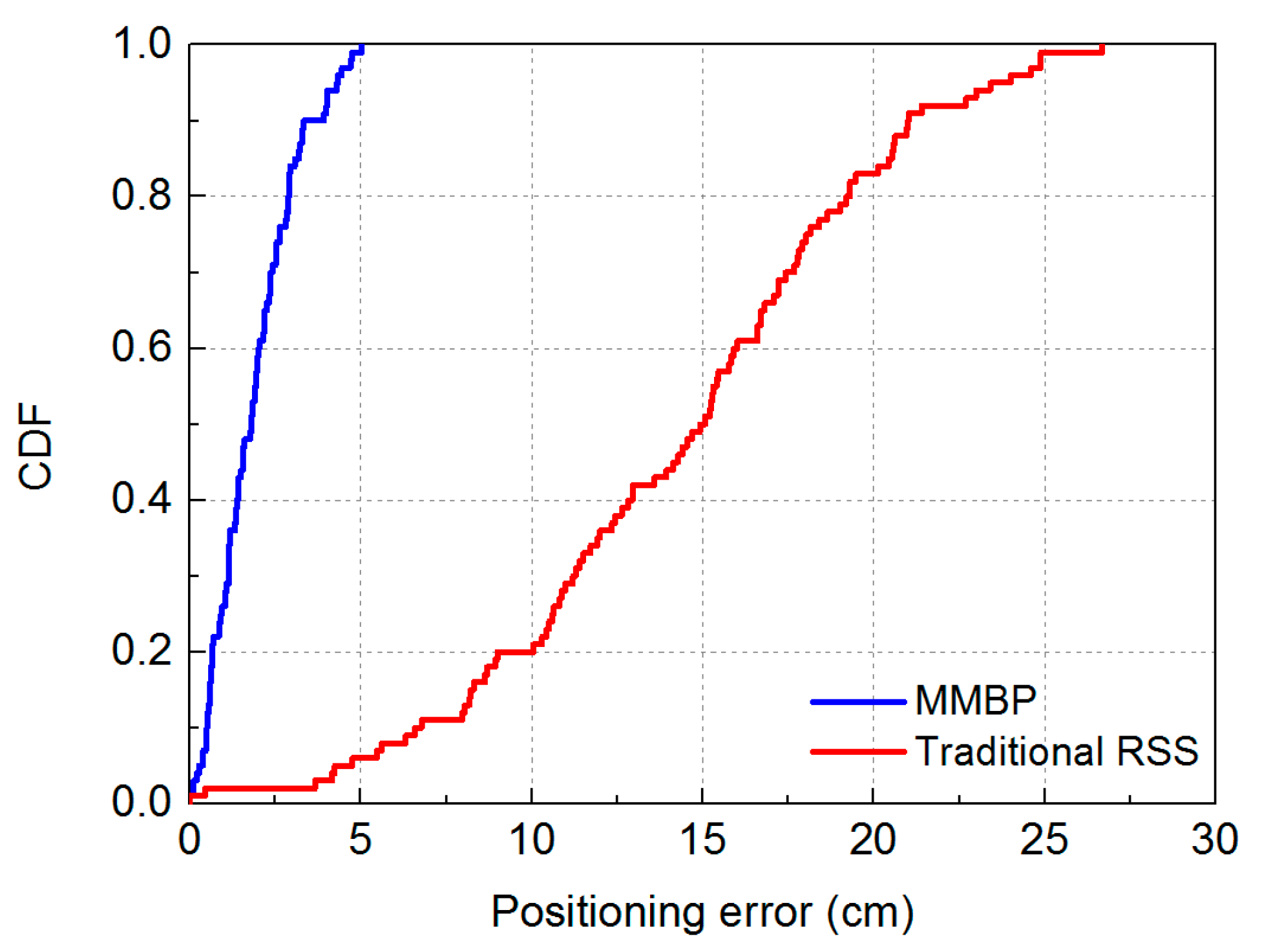
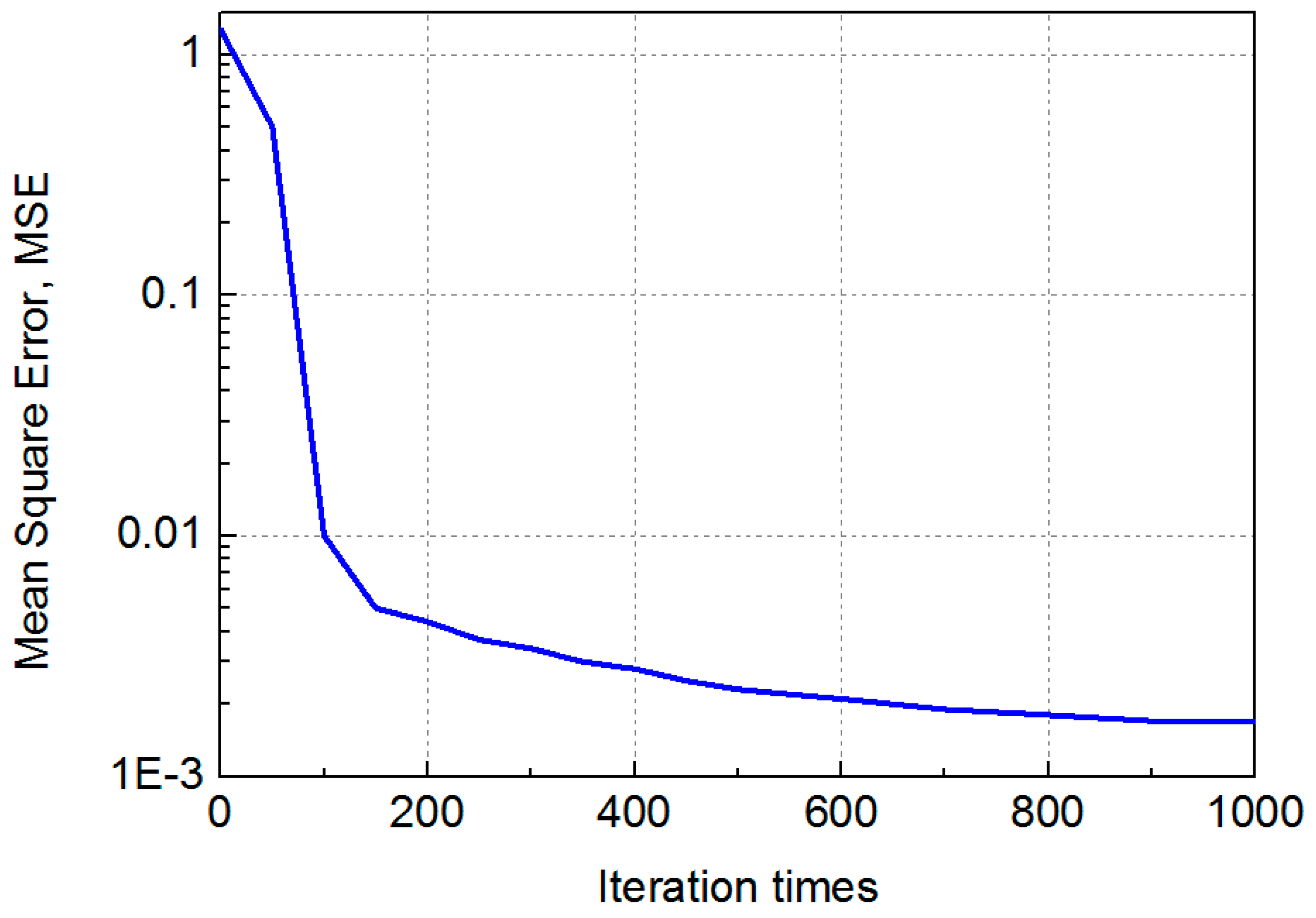
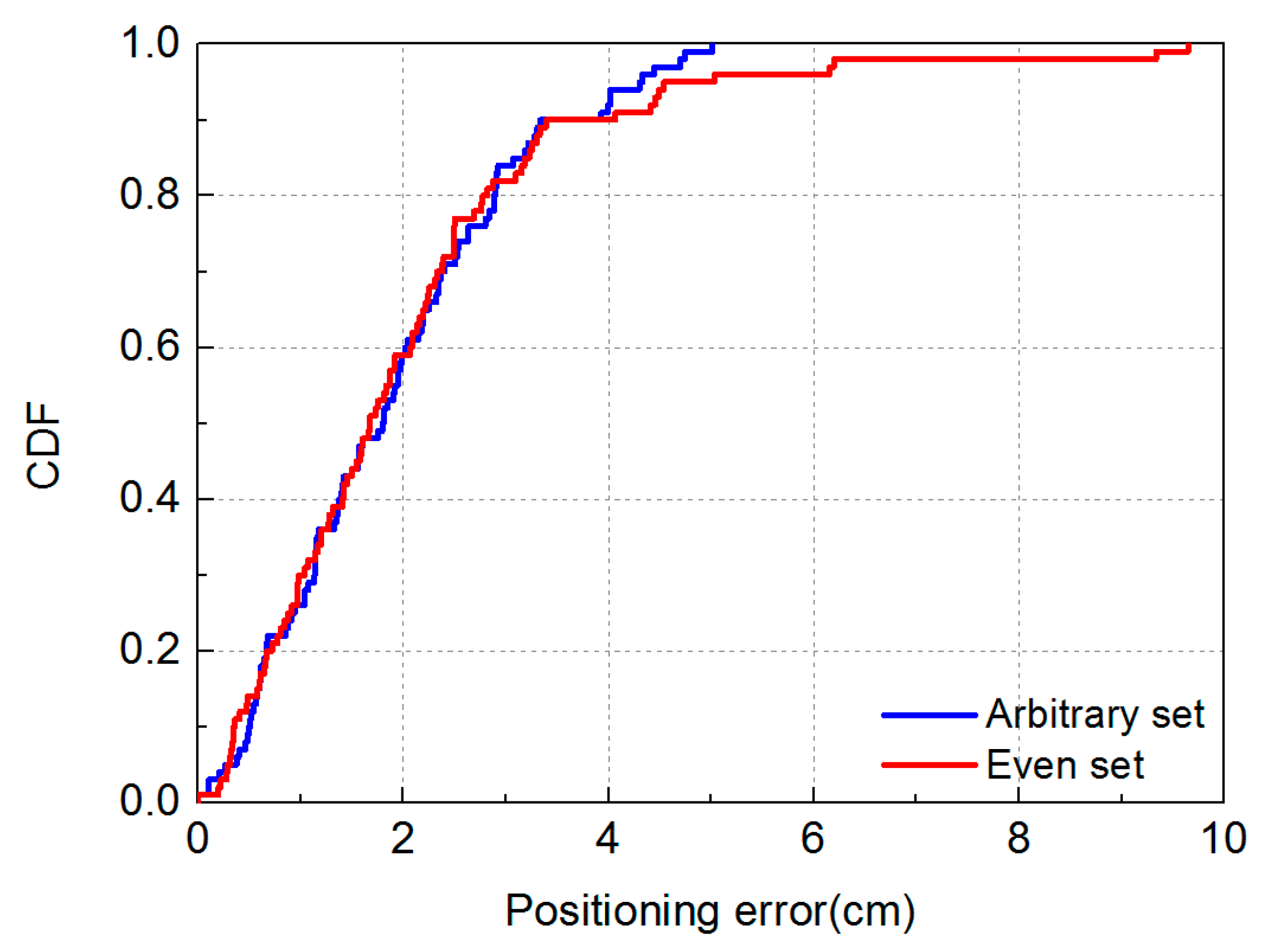
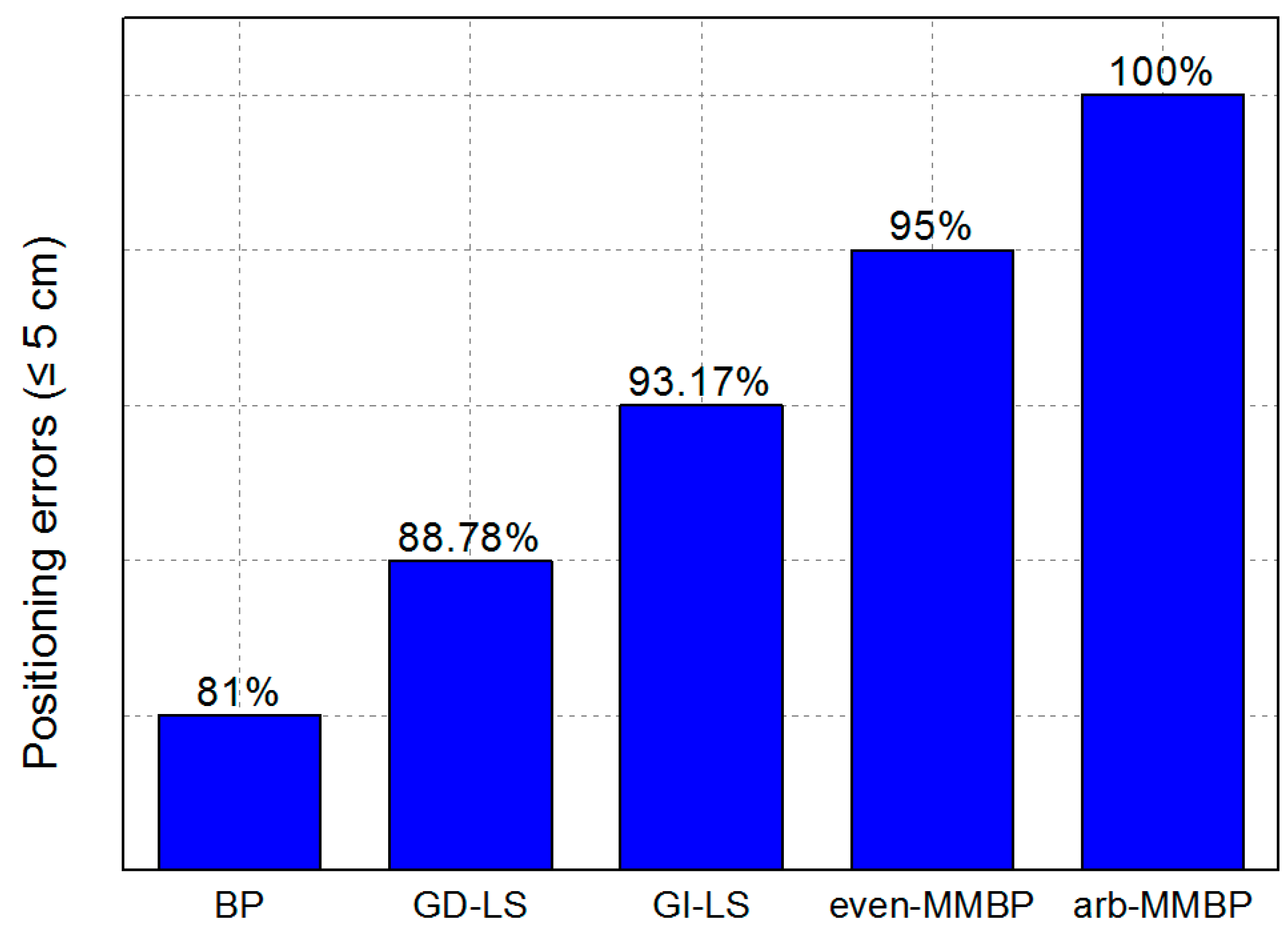
3.2. Result and Analysis
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xie, Z.; Guan, W.; Zheng, J.; Zhang, X.; Chen, S.; Chen, B. A High-Precision, Real-Time, and Robust Indoor Visible Light Positioning Method Based on Mean Shift Algorithm and Unscented Kalman Filter. Sensors 2019, 19, 1094. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Zhong, W.; Qian, K.; Wu, D. Image Sensor Based Visible Light Positioning System With Improved Positioning Algorithm. IEEE Access 2017, 5, 6087–6094. [Google Scholar] [CrossRef]
- Şahin, A.; Eroğlu, Y.S.; Güvenç, İ.; Pala, N.; Yüksel, M. Hybrid 3-D Localization for Visible Light Communication Systems. J. Lightwave Technol. 2015, 33, 4589–4599. [Google Scholar] [CrossRef]
- Rahman, M.S.; Kim, K.-D. Indoor Location Estimation Using Visible Light Communication and Image Sensors. Int. J. Smart Home 2013, 7, 99–113. [Google Scholar]
- Zhang, W.; Kavehrad, M. A 2-D indoor localization system based on visible light LED. In Proceedings of the 2012 IEEE Photonics Society Summer Topical Meeting Series, Seattle, WA, USA, 9–11 July 2012; pp. 80–81. [Google Scholar]
- Zheng, H.; Xu, Z.; Yu, C.; Gurusamy, M. Indoor three-dimensional positioning based on visible light communication using Hamming filter. In Proceedings of the Advanced Photonics Congress 2016, Vancouver, BC, Canada, 18–21 July 2016. [Google Scholar]
- Yang, A.; Feng, L.; Liu, X.; Feng, L. Combination of light-emitting diode positioning identification and time-division multiplexing scheme for indoor location-based service. Chin. Opt. Lett. 2015, 13, 12–17. [Google Scholar]
- Do, T.-H.; Yoo, M. An in-Depth Survey of Visible Light Communication Based Positioning Systems. Sensors 2016, 16, 678. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.J.; Yoo, J.H.; Jung, S.Y. VLC-based indoor location awareness using LED light and image sensors. In Proceedings of the 2012 Photonics Asia, Beijing, China, 5–7 November 2012. [Google Scholar]
- Hossen, M.S.; Park, Y.; Kim, K.D. Performance improvement of indoor positioning using light-emitting diodes and an image sensor for light-emitting diode communication. Opt. Eng. 2015, 54, 035108. [Google Scholar] [CrossRef]
- Fu, M.; Zhu, W.; Le, Z.; Manko, D.; Gorbov, I.; Beliak, I. Weighted average indoor positioning algorithm that uses LEDs and image sensors. Photonic Netw. Commun. 2017, 34, 202–212. [Google Scholar] [CrossRef]
- Huang, H.Q.; Yang, A.Y.; Feng, L.H.; Ni, G.Q.; Guo, P. Artificial neural-network-based visible light positioning algorithm with a diffuse optical channel. Chin. Opt. Lett. 2017, 15, 050601. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Liu, S.M.; Lu, F.; Chow, C.-W.; Yeh, C.-H.; Chang, G.-K. Accurate Indoor Visible Light Positioning System utilizing Machine Learning Technique with Height Tolerance. In Proceedings of the 2018 Optical Fiber Communications Conference and Exposition (OFC), San Diego, CA, USA, 11–15 March 2018. [Google Scholar]
- Chen, Z.; Wang, J. GROF: Indoor Localization Using a Multiple-Bandwidth General Regression Neural Network and Outlier Filter. Sensors 2018, 18, 3723. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Shao, S.; Ansari, N.; Khreishah, A. Indoor Localization Using Visible Light Via Fusion of Multiple Classifiers. IEEE Photonics J. 2017, 9, 1–16. [Google Scholar] [CrossRef]
- Guo, X.; Hu, F.; Elikplim, N.R.; Li, L. Indoor Localization Using Visible Light via Two-Layer Fusion Network. IEEE Access 2019, 7, 16421–16430. [Google Scholar] [CrossRef]
- Horikawa, S.; Furuhashi, T.; Uchikawa, Y. On fuzzy modeling using fuzzy neural networks with the back-propagation algorithm. IEEE Trans. Neural Networks 1992, 3, 801–806. [Google Scholar] [CrossRef] [PubMed]
- Miao, K.; Chen, Y.; Miao, X. An indoor positioning technology based on GA-BP Neural Network. In Proceedings of the 2011 6th International Conference on Computer Science & Education (ICCSE), Singapore, 3–5 August 2011; pp. 305–309. [Google Scholar]
- Wang, C.; Wu, F.; Shi, Z.; Zhang, D. Indoor positioning technique by combining RFID and particle swarm optimization-based back propagation neural network. Optik 2016, 127, 6839–6849. [Google Scholar] [CrossRef]
- Mehmood, H.; Tripathi, N.K. Optimizing artificial neural network-based indoor positioning system using genetic algorithm. Int. J. Digital Earth 2013, 6, 158–184. [Google Scholar] [CrossRef]
- Guan, W.; Wu, Y.; Xie, C.; Chen, H.; Cai, Y.; Chen, Y. High-precision approach to localization scheme of visible light communication based on artificial neural networks and modified genetic algorithms. Opt. Eng. 2017, 56, 106103. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Lv, H.; Feng, L.; Yang, A.; Guo, P.; Huang, H.; Chen, S. High Accuracy VLC Indoor Positioning System With Differential Detection. IEEE Photonics J. 2017, 9, 1–13. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Injection current of LEDs (A) | 1 |
| Receiver active area diameter (mm) | 1 |
| Responsivity of detector (A/W) | 25 (@600 nm) |
| Sampling rate of oscilloscope (MSa/s) | 100 |
| Half power angle of LEDs | 45° |
| LED 3dB bandwidth | 3 MHz |
| Parameter | Value |
|---|---|
| Hidden layer () | 13 |
| Learning rate () | 0.0003 |
| Momentum factor | 0.9 |
| Iteration times | 6594 |
| Constant increment factor () | 1.01 |
| Constant decrement factor () | 0.75 |
| Parameters | MMBP Algorithm | Traditional RSS-Based Algorithm |
|---|---|---|
| Training time (s) | 2.36 | NAN |
| Positioning time (s) | 0.007 | 2.25 |
| Parameter | Value |
|---|---|
| Hidden layer () | 10 |
| Learning rate () | 0.001 |
| Momentum factor () | 0.9 |
| Iteration times | 975 |
| Constant increment factor () | 1.065 |
| Constant increment factor () | 0.4 |
| Parameters | MMBP Algorithm | Traditional RSS-Based Algorithm |
|---|---|---|
| Training time (s) | 0.403 | NAN |
| Positioning time (s) | 0.005 | 2.25 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Cui, J.; Feng, L.; Yang, A.; Lv, H.; Lin, B.; Huang, H. High-Precision Indoor Visible Light Positioning Using Modified Momentum Back Propagation Neural Network with Sparse Training Point. Sensors 2019, 19, 2324. https://doi.org/10.3390/s19102324
Zhang H, Cui J, Feng L, Yang A, Lv H, Lin B, Huang H. High-Precision Indoor Visible Light Positioning Using Modified Momentum Back Propagation Neural Network with Sparse Training Point. Sensors. 2019; 19(10):2324. https://doi.org/10.3390/s19102324
Chicago/Turabian StyleZhang, Haiqi, Jiahe Cui, Lihui Feng, Aiying Yang, Huichao Lv, Bo Lin, and Heqing Huang. 2019. "High-Precision Indoor Visible Light Positioning Using Modified Momentum Back Propagation Neural Network with Sparse Training Point" Sensors 19, no. 10: 2324. https://doi.org/10.3390/s19102324
APA StyleZhang, H., Cui, J., Feng, L., Yang, A., Lv, H., Lin, B., & Huang, H. (2019). High-Precision Indoor Visible Light Positioning Using Modified Momentum Back Propagation Neural Network with Sparse Training Point. Sensors, 19(10), 2324. https://doi.org/10.3390/s19102324