Stereo Vision Based Sensory Substitution for the Visually Impaired



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Sound of Vision System
- It helps VIPs both to perceive the environment and to move independently, without the need for predefined tags/sensors located in the surroundings;
- pervasiveness—the system works in any kind of environment (indoors and outdoors) and irrespective of the illumination conditions;
- it provides rich and naturalistic descriptions of the environment through original combinations of audio and haptic encodings;
- it provides a real-time description of the environment to the users, i.e., the description is continuously updated, fast enough such that the users are able to perceive the environment even when walking;
- it is accompanied by efficient training programs and tools, based on modern techniques (virtual and augmented reality, serious games), developed together with Orientation & Mobility instructors and specialists in behavioral science.
3. Stereo Based Reconstruction and Segmentation in Outdoor Environments
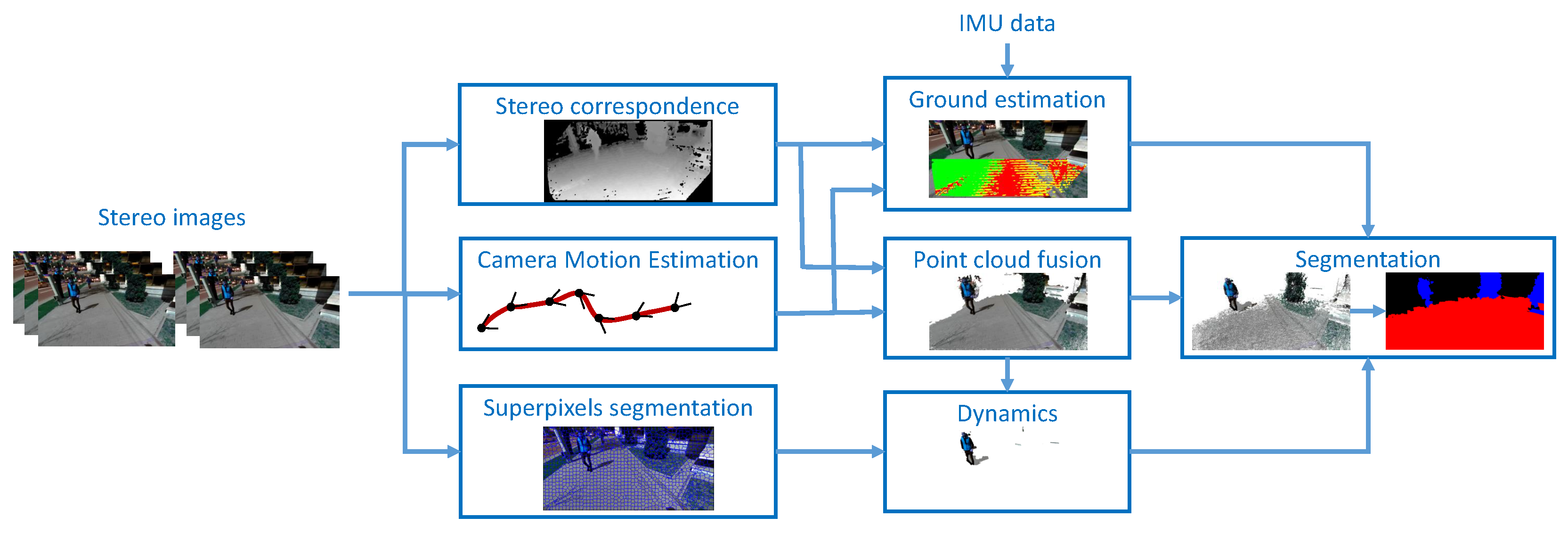
3.1. Overview of the 3D Processing Pipeline
3.2. 3D Reconstruction
- Updating existing points based on new measurements, in case they can be fused, i.e., their 3D measurements match within a predefined distance threshold; with each new update, the confidence of the 3D point is increased; these points are recorded in a 2D fusion map;
- Adding new points which have not been previously measured by the sensor;
- Removing garbage points, which either remain out of a volume of interest around the camera, or did not gain enough confidence since they have been first measured.
- The new 3D point could not be fused with an existing one because no measurement was previously performed for that position OR
- The fusion of the new 3D point with and existed one, marked as dynamic in the previous frame, was attempted but could not be performed OR
- The fusion of the new 3D point with an existing one, marked as static in the previous frame, was attempted but could not be performed AND the color difference map in that position contains a value larger than a threshold.
3.3. Segmentation
4. Implementation and Performance Evaluation
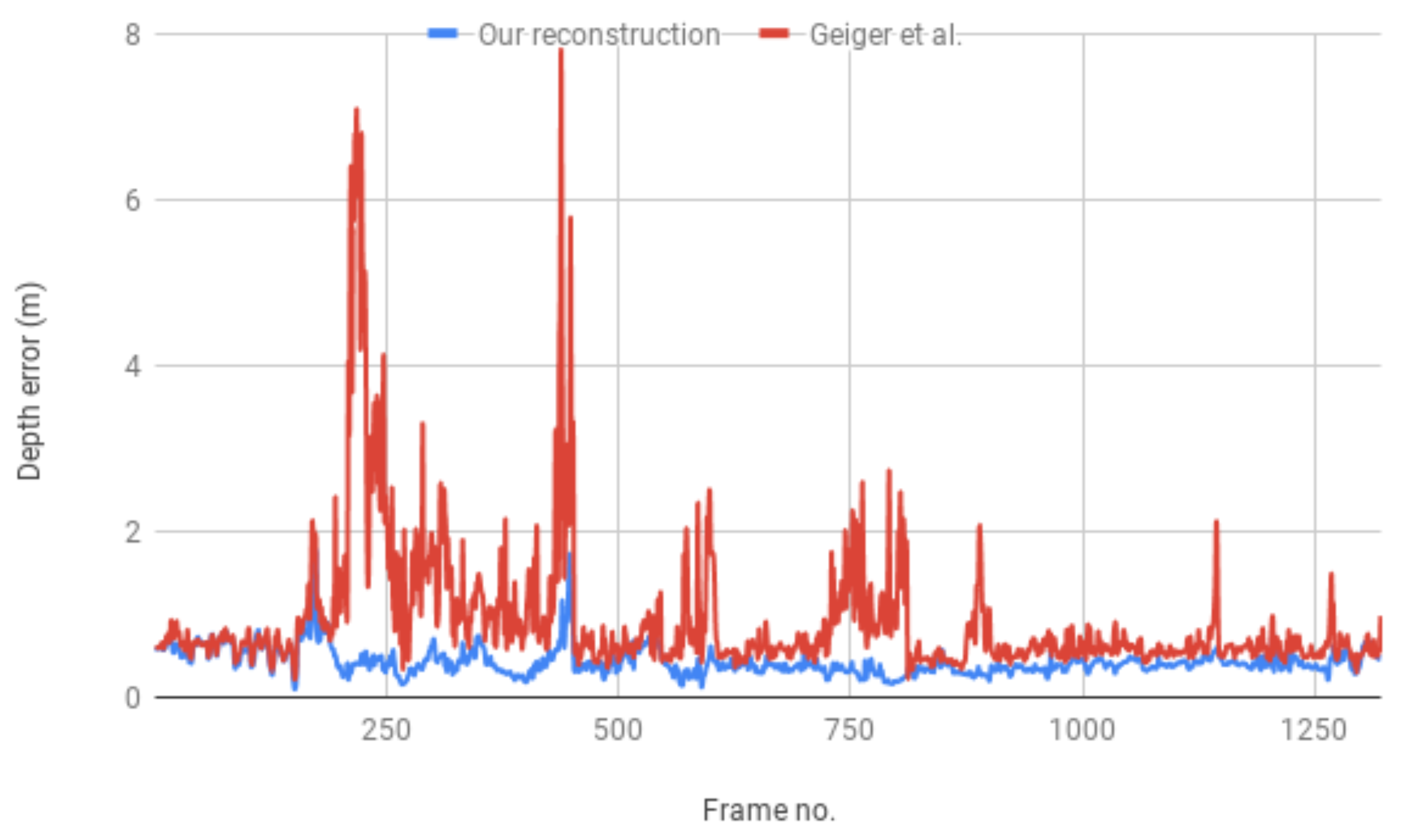
4.1. Technical Performance
4.2. Usability Assessment
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sound of Vision. Available online: https://soundofvision.net (accessed on 1 February 2019).
- Dunai, L.; Garcia, B.; Lengua, I.; Peris-Fajarnes, G. 3D CMOS sensor based acoustic object detection and navigation system for blind people. In Proceedings of the IECON 2012—38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, 25–28 October 2012; pp. 4208–4215. [Google Scholar] [CrossRef]
- Bujacz, M.; Skulimowski, P.; Strumillo, P. Naviton—A Prototype Mobility Aid for Auditory Presentation of Three-Dimensional Scenes to the Visually Impaired. J. Audio Eng. Soc. 2012, 60, 696–708. [Google Scholar]
- Ribeiro, F.; Florencio, D.; Chou, P.; Zhang, Z. Auditory augmented reality: Object sonification for the visually impaired. In Proceedings of the IEEE 14th International Workshop on Multimedia Signal Processing (MMSP), Banff, AB, Canada, 17–19 September 2012; pp. 319–324. [Google Scholar]
- Saez Martinez, J.M.; Escolano Ruiz, F. Stereo-based Aerial Obstacle Detection for the Visually Impaired. In Proceedings of the Workshop on Computer Vision Applications for the Visually Impaired, Marseille, France, 18 October 2008. [Google Scholar]
- Rodriguez, A.; Yebes, J.J.; Alcantarilla, P.F.; Bergasa, L.M.; Almazan, J.; Cela, A. Assisting the Visually Impaired: Obstacle Detection and Warning System by Acoustic Feedback. Sensors 2012, 12, 17476–17496. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mattoccia, S.; Macri, P. 3D glasses as mobility aid for visually impaired people. In Computer Vision - ECCV 2014 Workshops, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–7 and 12 September 2014; Agapito, L., Bronstein, M., Rother, C., Eds.; Springer: Cham, Switzerland, 2014; Volume 8927, pp. 539–554. [Google Scholar]
- Balakrishnan, G.; Sainarayanan, G.; Nagarajan, R.; Yaacob, S. A Stereo Image Processing System for Visually Impaired. Int. J. Signal Process. 2006, 2, 136–145. [Google Scholar]
- Peng, E.; Peursum, P.; Li, L.; Venkatesh, S. A Smartphone-Based Obstacle Sensor for the Visually Impaired. In Ubiquitous Intelligence and Computing, Proceedings of the International Conference on Ubiquitous Intelligence and Computing, Xi’an, China, 26–29 October 2010; Yu, Z., Liscano, R., Chen, G., Zhang, D., Zhou, X., Eds.; Springer: Berlin/Heidelberg, Germnay, 2010; Volume 6406, pp. 590–604. [Google Scholar] [CrossRef]
- Jose, J.; Farrajota, M.; Rodrigues, J.M.; du Buf, J.H. The SmartVision local navigation aid for blind and visually impaired persons. JDCTA Int. J. Digit. Content Technol. Its Appl. 2011, 5, 362–375. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Guo, B.L.; Sun, W. Obstacle Detection System for Visually Impaired People Based on Stereo Vision. In Proceedings of the Fourth International Conference on Genetic and Evolutionary Computing (ICGEC), Shenzhen, China, 13–15 December 2010; pp. 723–726. [Google Scholar] [CrossRef]
- Saez Martinez, J.; Escolano, F.; Lozano, M. Aerial obstacle detection with 3D mobile devices. IEEE J. Biomed. Health Inform. 2015, 19, 74–80. [Google Scholar] [CrossRef] [PubMed]
- Tapu, R.; Mocanu, B.; Bursuc, A.; Zaharia, T. A Smartphone-Based Obstacle Detection and Classification System for Assisting Visually Impaired People. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Sydney, Australia, 1–8 December 2013; pp. 444–451. [Google Scholar]
- Costa, P.; Fernandez, H.; Martins, P.; Barroso, J.; Hadjileontiadis, L. Obstacle detection using stereo imaging to assist the navigation of visually impaired people. Procedia Comput. Sci. 2012, 12, 83–93. [Google Scholar] [CrossRef]
- Filipe, V.; Fernandes, F.; Fernandes, H.; Sousa, A.; Paredes, H.; Barroso, J. Blind Navigation Support System based on Microsoft Kinect. Procedia Comput. Sci. 2012, 14, 94–101. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Liu, H.; Wang, X.; Qian, Y. Segment and Label Indoor Scene Based on RGB-D for the Visually Impaired. In MultiMedia Modeling, Proceedings of the International Conference on Multimedia Modeling, Dublin, Ireland, 6–10 January 2014; Gurrin, C., Hopfgartner, F., Hurst, W., Johansen, H., Lee, H., O’Connor, N., Eds.; Springer: Cham, Switzerland, 2014; Volume 8325, pp. 449–460. [Google Scholar] [CrossRef]
- Lee, Y.H.; Leung, T.S.; Medioni, G. Real-time staircase detection from a wearable stereo system. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR 2012), Tsukuba, Japan, 11–15 November 2012; pp. 3770–3773. [Google Scholar]
- Kurata, T.; Kourogi, M.; Ishikawa, T.; Kameda, Y.; Aoki, K.; Ishikawa, J. Indoor-Outdoor Navigation System for Visually-Impaired Pedestrians: Preliminary Evaluation of Position Measurement and Obstacle Display. In Proceedings of the 15th Annual International Symposium onWearable Computers (ISWC), San Francisco, CA, USA, 12–15 June 2011; pp. 123–124. [Google Scholar] [CrossRef]
- Chippendale, P.; Tomaselli, V.; D’Alto, V.; Urlini, G.; Modena, C. Personal Shopping Assistance and Navigator System for Visually Impaired People. In Computer Vision - ECCV 2014 Workshops, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–7 and 12 September 2014; Agapito, L., Bronstein, M., Rother, C., Eds.; Springer: Cham, Switzerland, 2014; Volume 8927, pp. 375–390. [Google Scholar]
- Yang, K.; Wang, K.; Cheng, R.; Hu, W.; Huang, X.; Bai, J. Detecting Traversable Area and Water Hazards for the Visually Impaired with a pRGB-D Sensor. Sensors 2017, 17, 1890. [Google Scholar] [CrossRef] [PubMed]
- Ran, L.; Helal, S.; Moore, S. Drishti: An integrated indoor/outdoor blind navigation system and service. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications, Orlando, FL, USA, 17 March 2004; pp. 23–32. [Google Scholar]
- Gomez, V. A Computer-Vision Based Sensory Substitution Device for the Visually Impaired (See ColOr). Ph.D. Thesis, Universite de Geneve, Geneva, Switzerland, 2014. [Google Scholar]
- Aladren, A.; Lopez-Nicolas, G.; Puig, L.; Guerrero, J. Navigation Assistance for the Visually Impaired Using RGB-D Sensor With Range Expansion. IEEE Syst. J. 2014, 10, 922–932. [Google Scholar] [CrossRef]
- Vineet, V.; Miksik, O.; Lidegaard, M.; Nießner, M.; Golodetz, S.; Prisacariu, V.A.; Kähler, O.; Murray, D.W.; Izadi, S.; Pérez, P.; et al. Incremental dense semantic stereo fusion for large-scale semantic scene reconstruction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 75–82. [Google Scholar] [CrossRef]
- Tapu, R.; Mocanu, B.; Zaharia, T. Seeing Without Sight—An Automatic Cognition System Dedicated to Blind and Visually Impaired People. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, K.; Wang, K.; Bergasa, L.M.; Romera, E.; Hu, W.; Sun, D.; Sun, J.; Cheng, R.; Chen, T.; López, E. Unifying Terrain Awareness for the Visually Impaired through Real-Time Semantic Segmentation. Sensors 2018, 18, 1506. [Google Scholar] [CrossRef] [PubMed]
- Moldoveanu, A.D.B.; Ivascu, S.; Stanica, I.; Dascalu, M.; Lupu, R.; Ivanica, G.; Balan, O.; Caraiman, S.; Ungureanu, F.; Moldoveanu, F.; et al. Mastering an advanced sensory substitution device for visually impaired through innovative virtual training. In Proceedings of the IEEE 7th International Conference on Consumer Electronics—Berlin (ICCE-Berlin), Berlin, Germany, 3–6 September 2017; pp. 120–125. [Google Scholar] [CrossRef]
- Caraiman, S.; Morar, A.; Owczarek, M.; Burlacu, A.; Rzeszotarski, D.; Botezatu, N.; Herghelegiu, P.; Moldoveanu, F.; Strumillo, P.; Moldoveanu, A. Computer Vision for the Visually Impaired: The Sound of Vision System. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Botezatu, N.; Caraiman, S.; Rzeszotarski, D.; Strumillo, P. Development of a versatile assistive system for the visually impaired based on sensor fusion. In Proceedings of the 21st International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 19–21 October 2017; pp. 540–547. [Google Scholar] [CrossRef]
- Bujacz, M.; Kropidlowski, K.; Ivanica, G.; Moldoveanu, A.; Saitis, C.; Csapo, A.; Wersenyi, G.; Spagnol, S.; Johannesson, O.I.; Unnthorsson, R.; et al. Sound of Vision—Spatial Audio Output and Sonification Approaches. Computers Helping People with Special Needs; Miesenberger, K., Bühler, C., Penaz, P., Eds.; Springer: Cham, Switzerland, 2016; pp. 202–209. [Google Scholar]
- Jóhannesson, Ó.I.; Balan, O.; Unnthorsson, R.; Moldoveanu, A.; Kristjánsson, Á. The Sound of Vision Project: On the Feasibility of an Audio-Haptic Representation of the Environment, for the Visually Impaired. Brain Sci. 2016, 6, 20. [Google Scholar] [CrossRef] [PubMed]
- Spagnol, S.; Baldan, S.; Unnthorsson, R. Auditory depth map representations with a sensory substitution scheme based on synthetic fluid sounds. In Proceedings of the IEEE 19th International Workshop on Multimedia Signal Processing (MMSP), Luton, UK, 16–18 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Geiger, A.; Roser, M.; Urtasun, R. Efficient Large-Scale Stereo Matching. In Computer Vision–ACCV 2010, Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; Kimmel, R., Klette, R., Sugimoto, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6492, pp. 25–38. [Google Scholar]
- Geiger, A.; Ziegler, J.; Stiller, C. StereoScan: Dense 3D reconstruction in real-time. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 963–968. [Google Scholar] [CrossRef]
- Keller, M.; Lefloch, D.; Lambers, M.; Izadi, S.; Weyrich, T.; Kolb, A. Real-Time 3D Reconstruction in Dynamic Scenes Using Point-Based Fusion. In Proceedings of the International Conference on 3D Vision, Seattle, WA, USA, 29 June–1 July 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Hamilton, O.K.; Breckon, T.P. Generalized dynamic object removal for dense stereo vision based scene mapping using synthesised optical flow. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3439–3443. [Google Scholar] [CrossRef]
- Herghelegiu, P.; Burlacu, A.; Caraiman, S. Robust ground plane detection and tracking in stereo sequences using camera orientation. In Proceedings of the 20th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 13–15 October 2016; pp. 514–519. [Google Scholar] [CrossRef]
- Burlacu, A.; Baciu, A.; Manta, V.I.; Caraiman, S. Ground geometry assessment in complex stereo vision based applications. In Proceedings of the 21st International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 19–21 October 2017; pp. 558–563. [Google Scholar] [CrossRef]
- Herghelegiu, P.; Burlacu, A.; Caraiman, S. Negative obstacle detection for wearable assistive devices for visually impaired. In Proceedings of the 21st International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 19–21 October 2017; pp. 564–570. [Google Scholar] [CrossRef]
- Burlacu, A.; Bostaca, S.; Hector, I.; Herghelegiu, P.; Ivanica, G.; Moldoveanul, A.; Caraiman, S. Obstacle detection in stereo sequences using multiple representations of the disparity map. In Proceedings of the 20th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 13–15 October 2016; pp. 854–859. [Google Scholar] [CrossRef]
- Ren, C.Y.; Prisacariu, V.; Reid, I. gSLICr: SLIC superpixels at over 250 Hz. arXiv 2015, arXiv:1509.04232. [Google Scholar]
- Maidenbaum, S.; Abboud, S.; Amedi, A. Sensory substitution: Closing the gap between basic research and widespread practical visual rehabilitation. Neurosci. Biobehav. Rev. 2014, 41, 3–15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kristjansson, A.; Moldoveanu, A.; Johannesson, O.I.; Balan, O.; Spagnol, S.; Valgeirsdottir, V.V.; Unnthorsson, R. Designing sensory-substitution devices: Principles, pitfalls and potential. Restor. Neurol. Neurosci. 2016, 34, 769–787. [Google Scholar] [CrossRef] [PubMed]








© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caraiman, S.; Zvoristeanu, O.; Burlacu, A.; Herghelegiu, P. Stereo Vision Based Sensory Substitution for the Visually Impaired. Sensors 2019, 19, 2771. https://doi.org/10.3390/s19122771
Caraiman S, Zvoristeanu O, Burlacu A, Herghelegiu P. Stereo Vision Based Sensory Substitution for the Visually Impaired. Sensors. 2019; 19(12):2771. https://doi.org/10.3390/s19122771
Chicago/Turabian StyleCaraiman, Simona, Otilia Zvoristeanu, Adrian Burlacu, and Paul Herghelegiu. 2019. "Stereo Vision Based Sensory Substitution for the Visually Impaired" Sensors 19, no. 12: 2771. https://doi.org/10.3390/s19122771
APA StyleCaraiman, S., Zvoristeanu, O., Burlacu, A., & Herghelegiu, P. (2019). Stereo Vision Based Sensory Substitution for the Visually Impaired. Sensors, 19(12), 2771. https://doi.org/10.3390/s19122771