Understanding Collective Human Mobility Spatiotemporal Patterns on Weekdays from Taxi Origin-Destination Point Data


Abstract
:1. Introduction
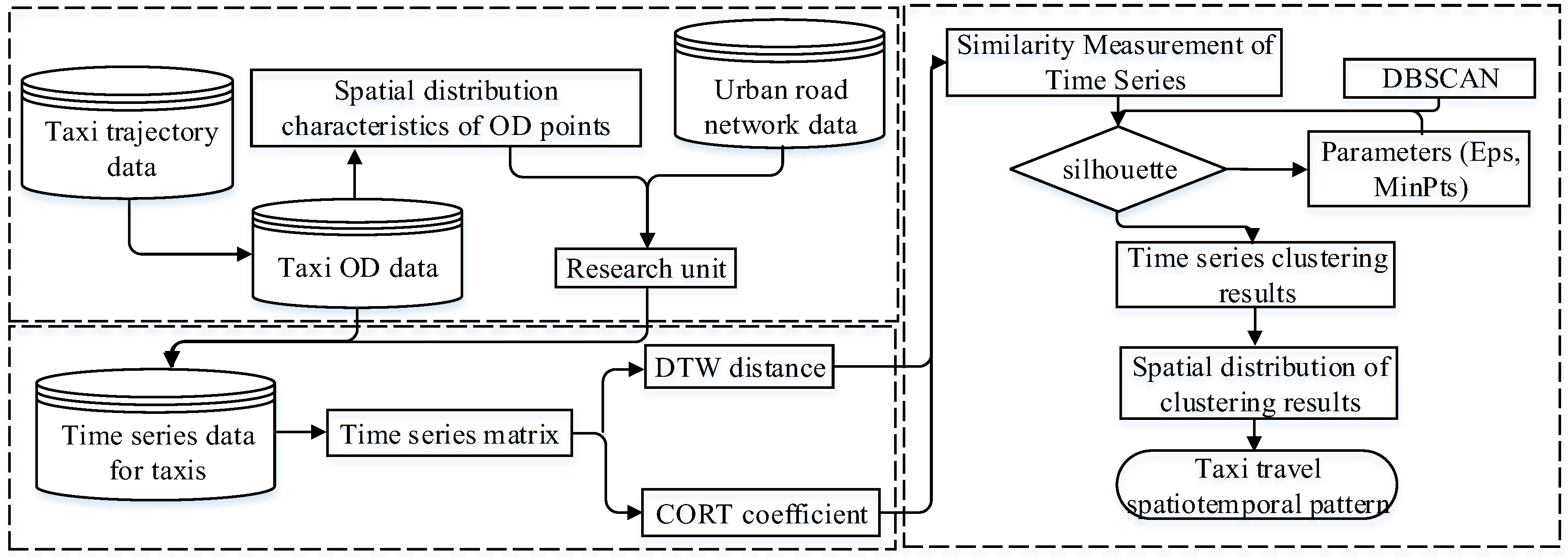
2. Materials and Methods
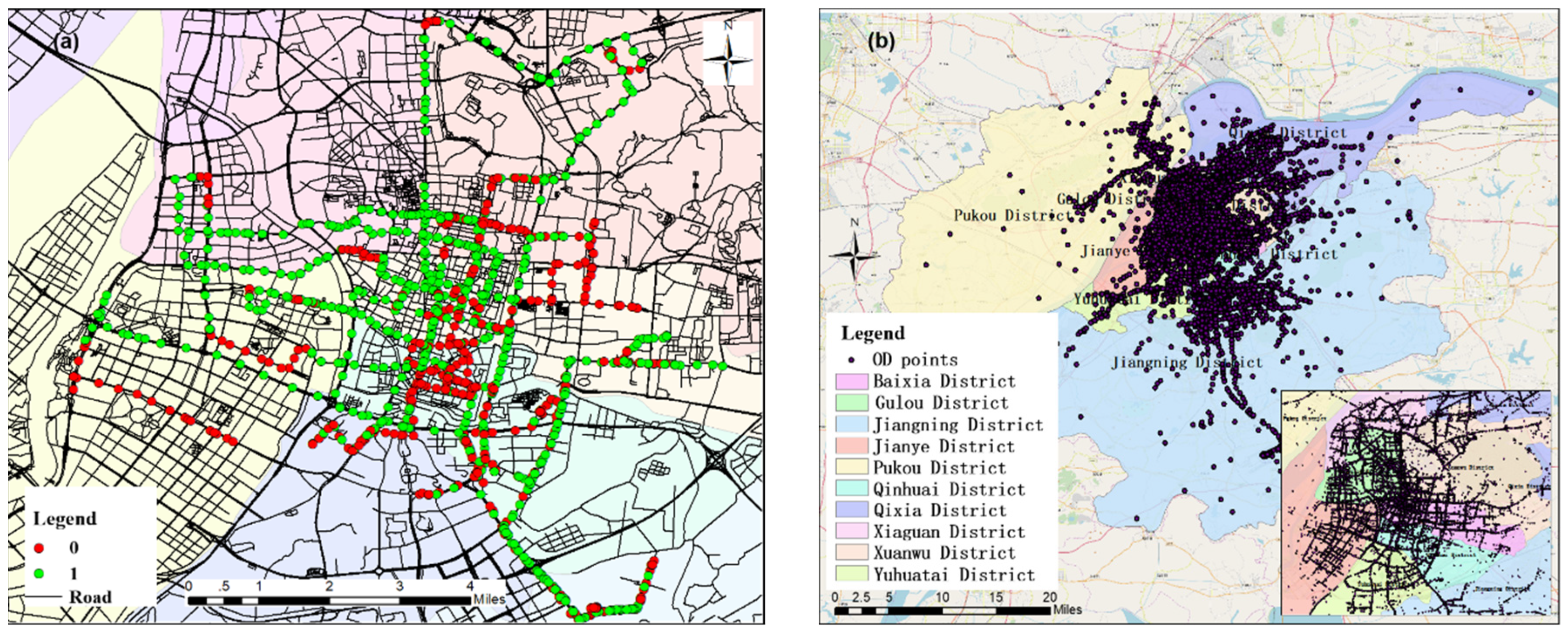
2.1. Study Area and Data Sources
2.2. Travel Time Series Similarity Measurement
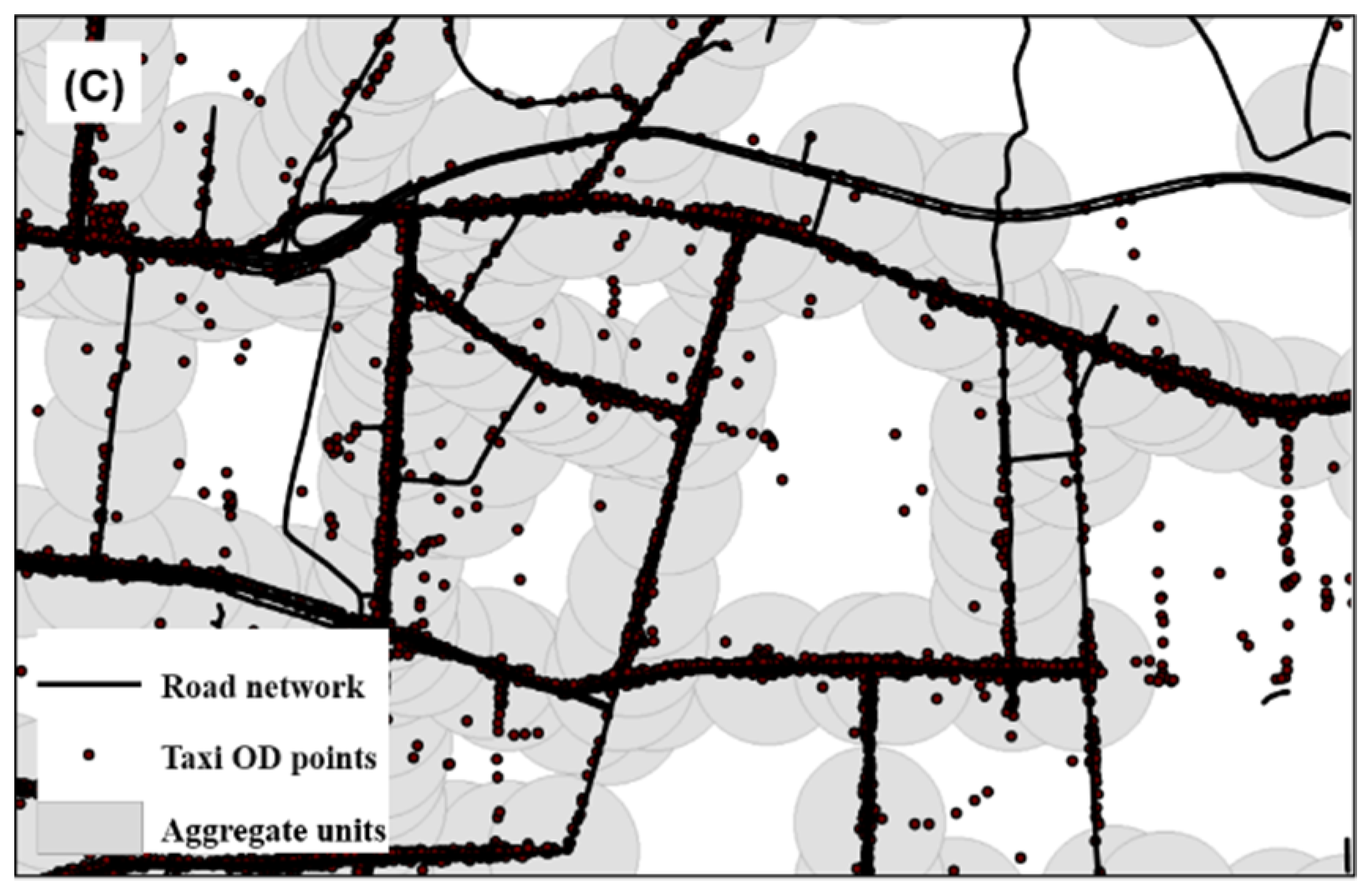
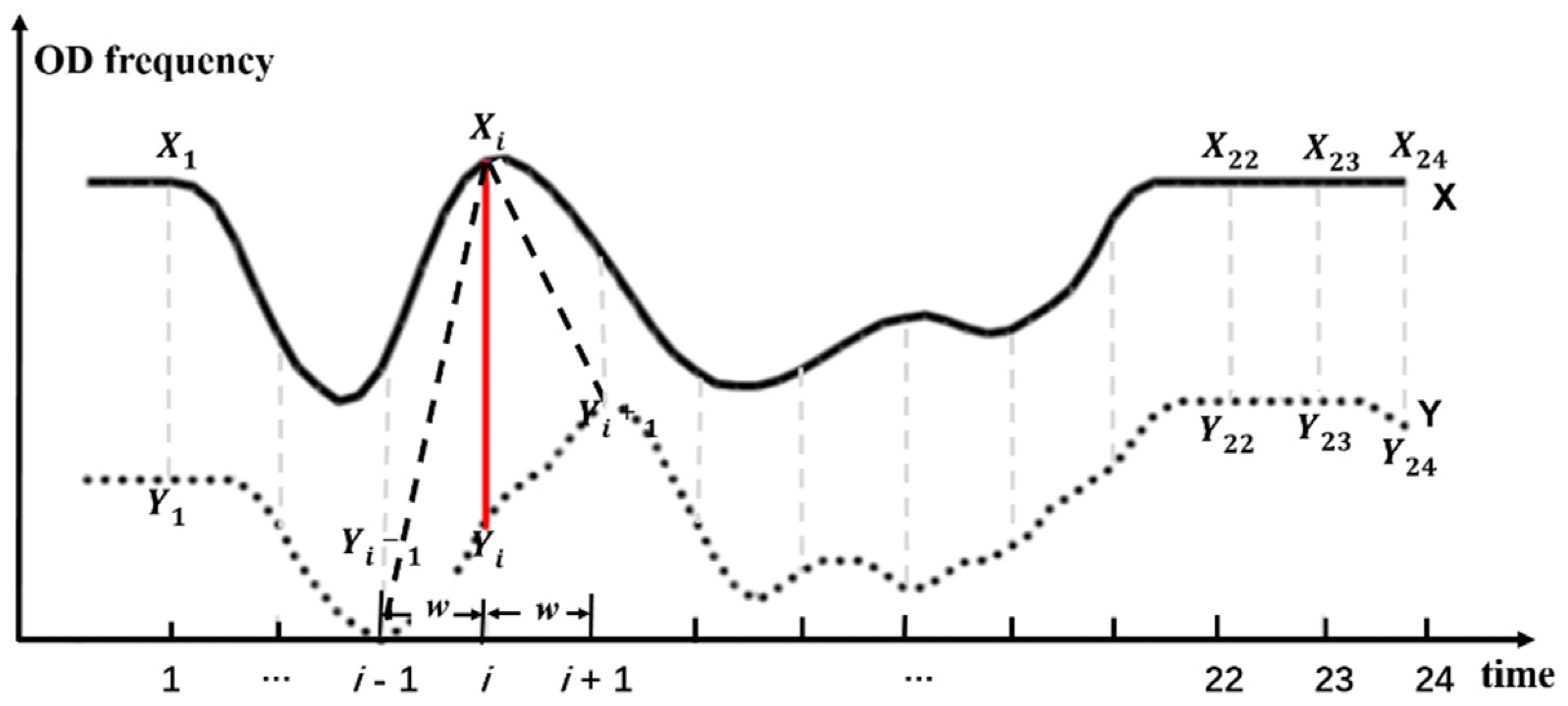
2.2.1. Determination of an Aggregate Unit
2.2.2. Distance Function Based on Dynamic Time Warping
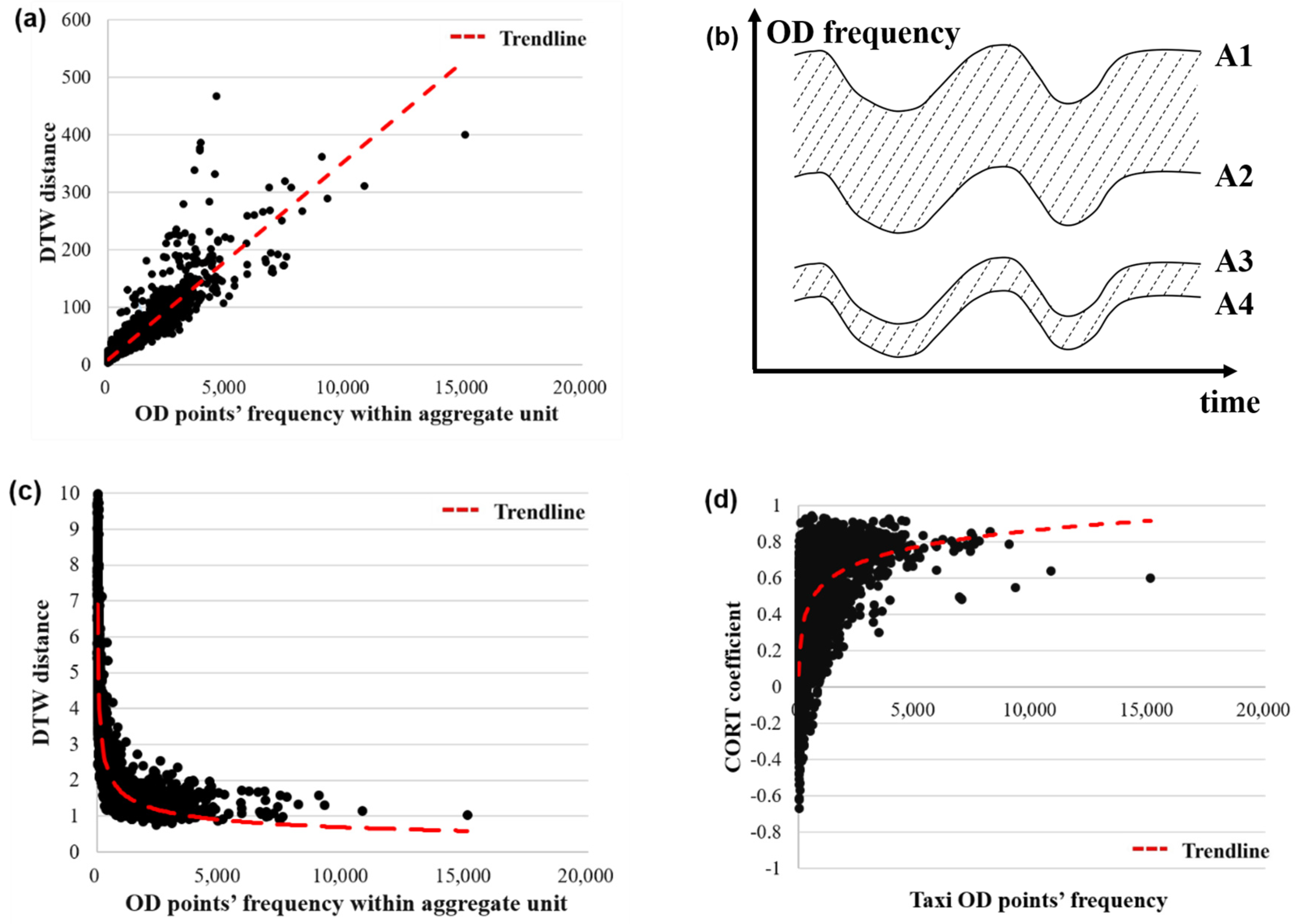
2.2.3. Adaptive Dissimilarity Index
2.2.4. Construction of the Similarity Measurement Function
2.3. Collective Human Mobility Spatial-Temporal Pattern Recognition
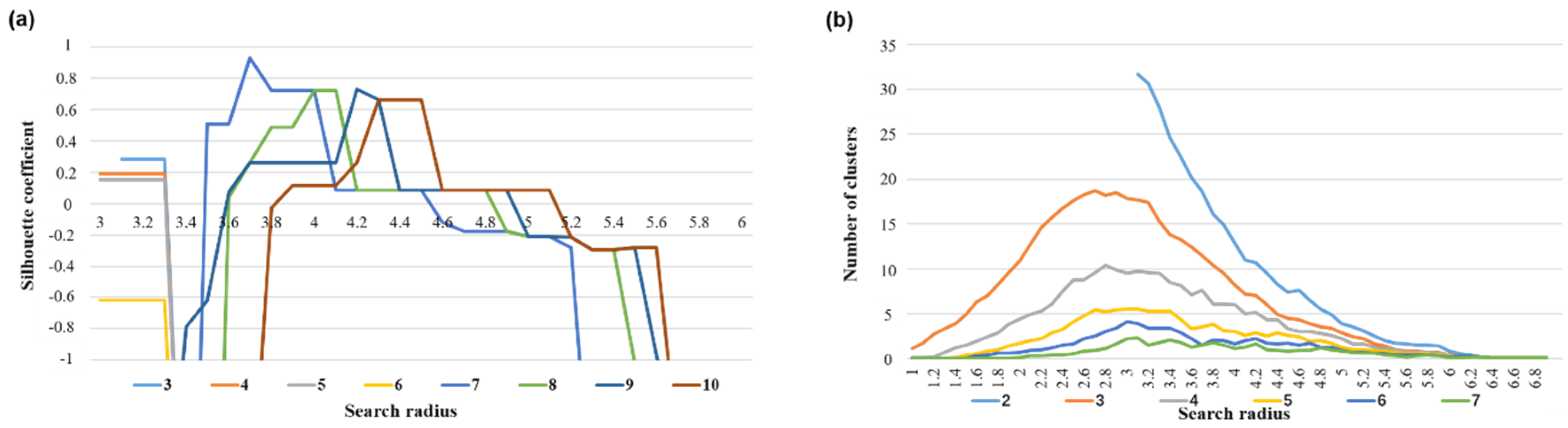
2.3.1. Clustering Method for the Travel Time Series
2.3.2. Comparing the Results with the K-Means Method
3. Results
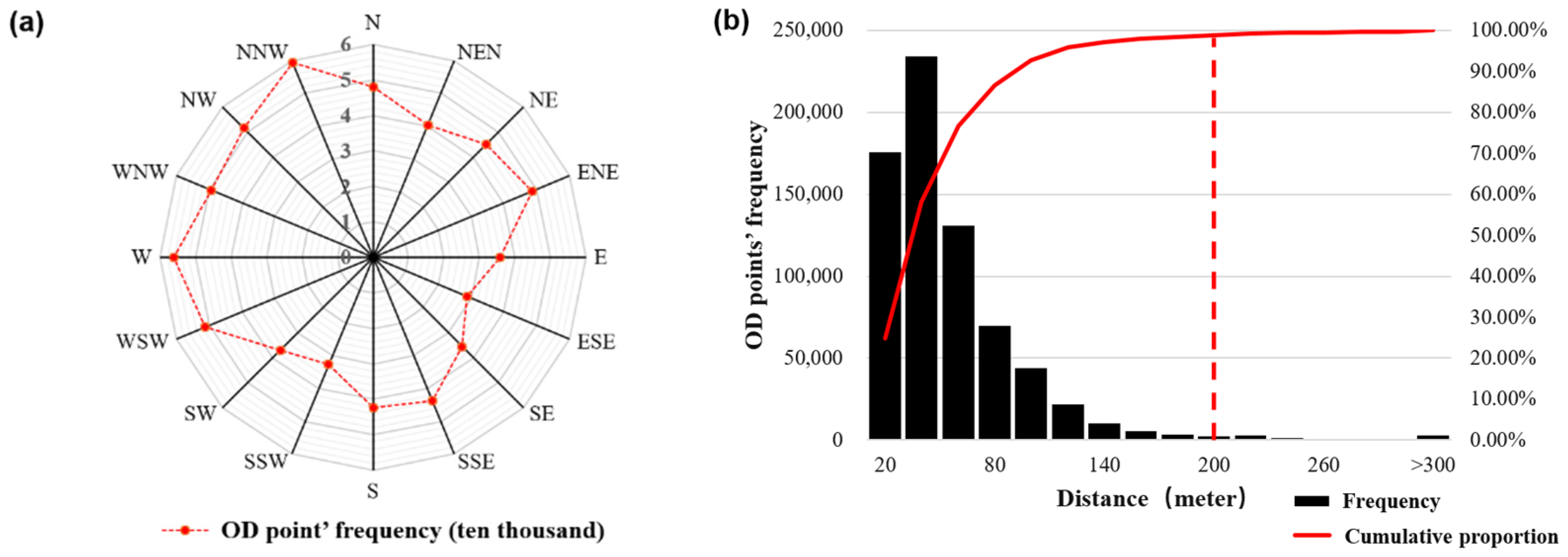
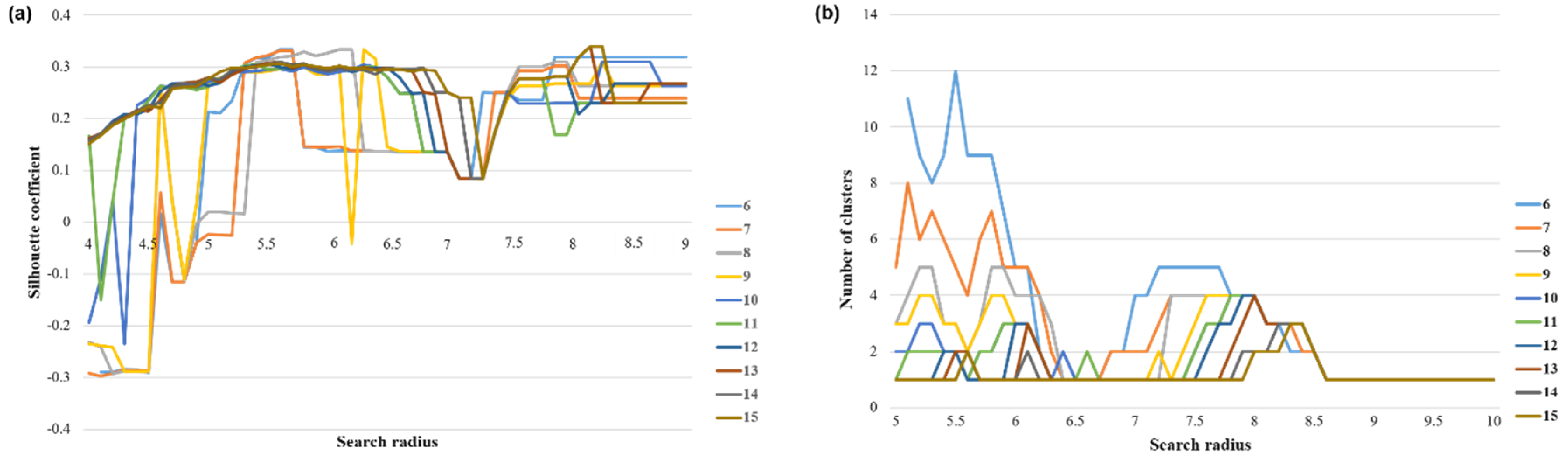
3.1. Screening the Aggregate Units
3.2. Extraction of the Spatiotemporal Travel Patterns
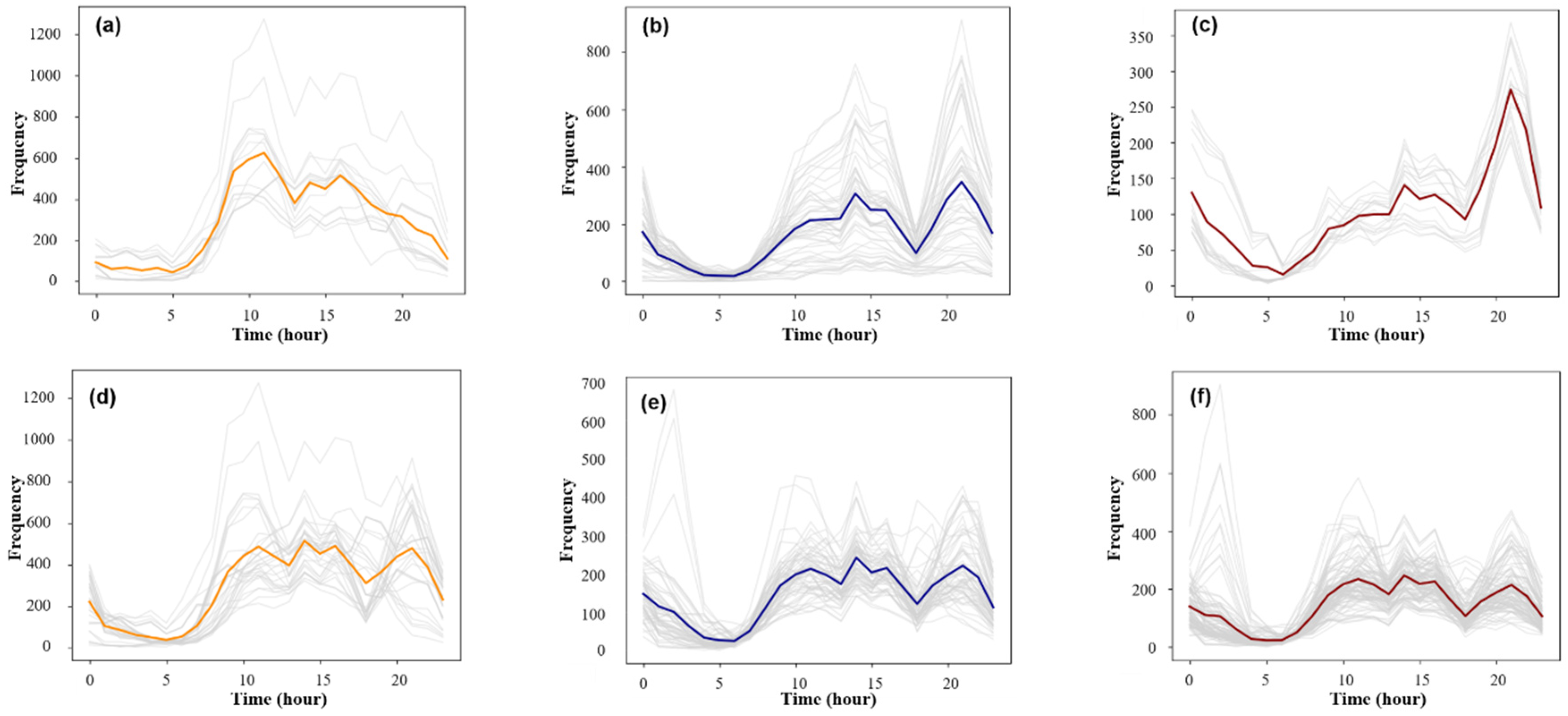
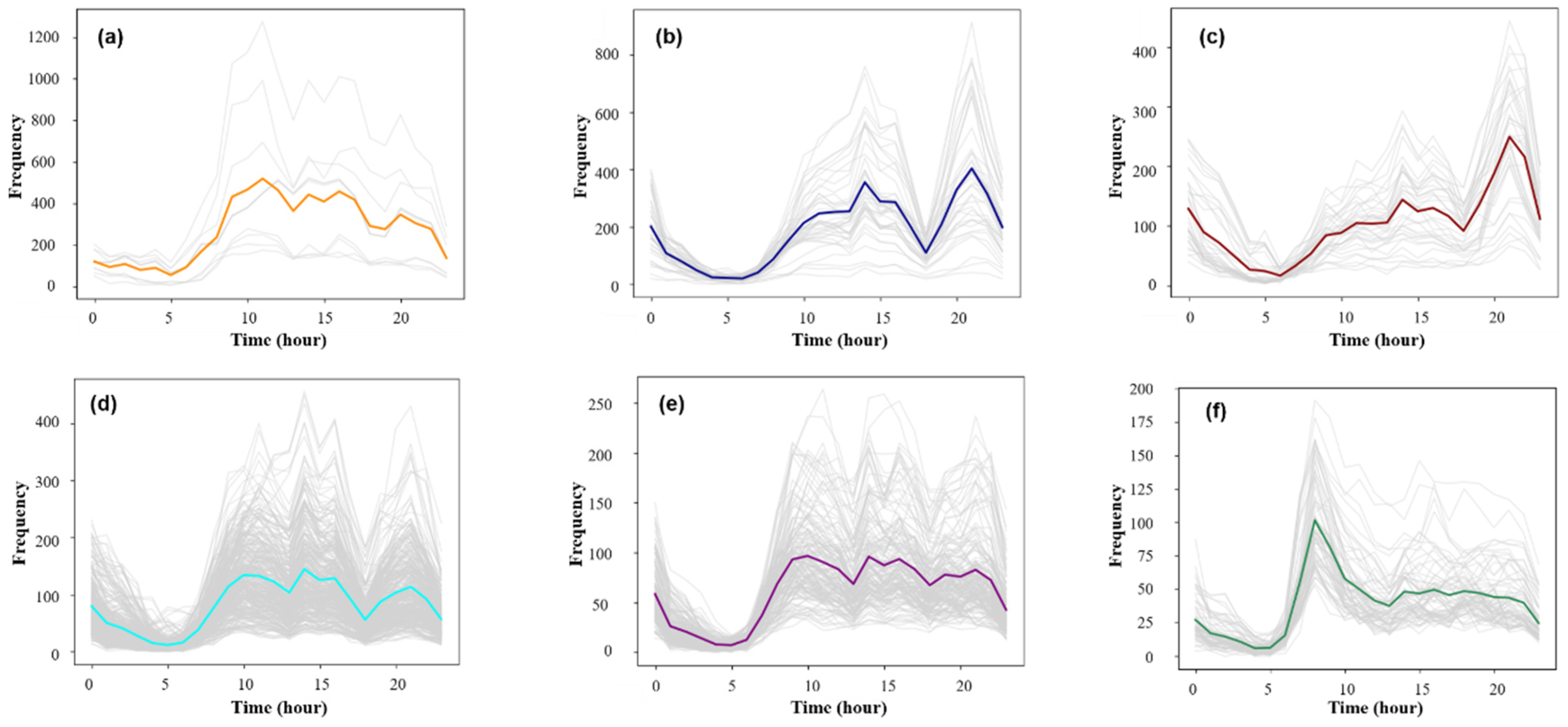
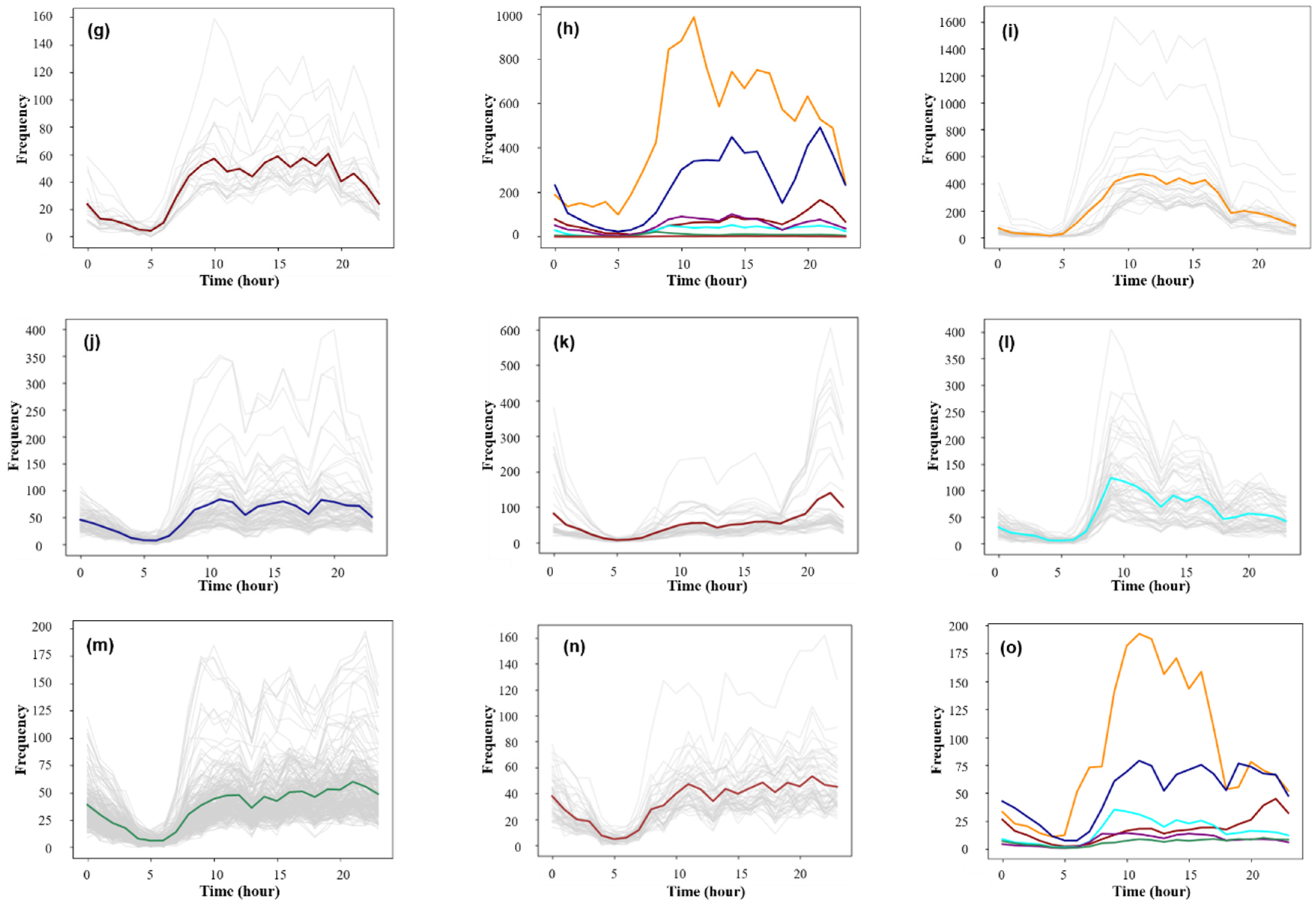
3.2.1. Classification of the Travel Time Series
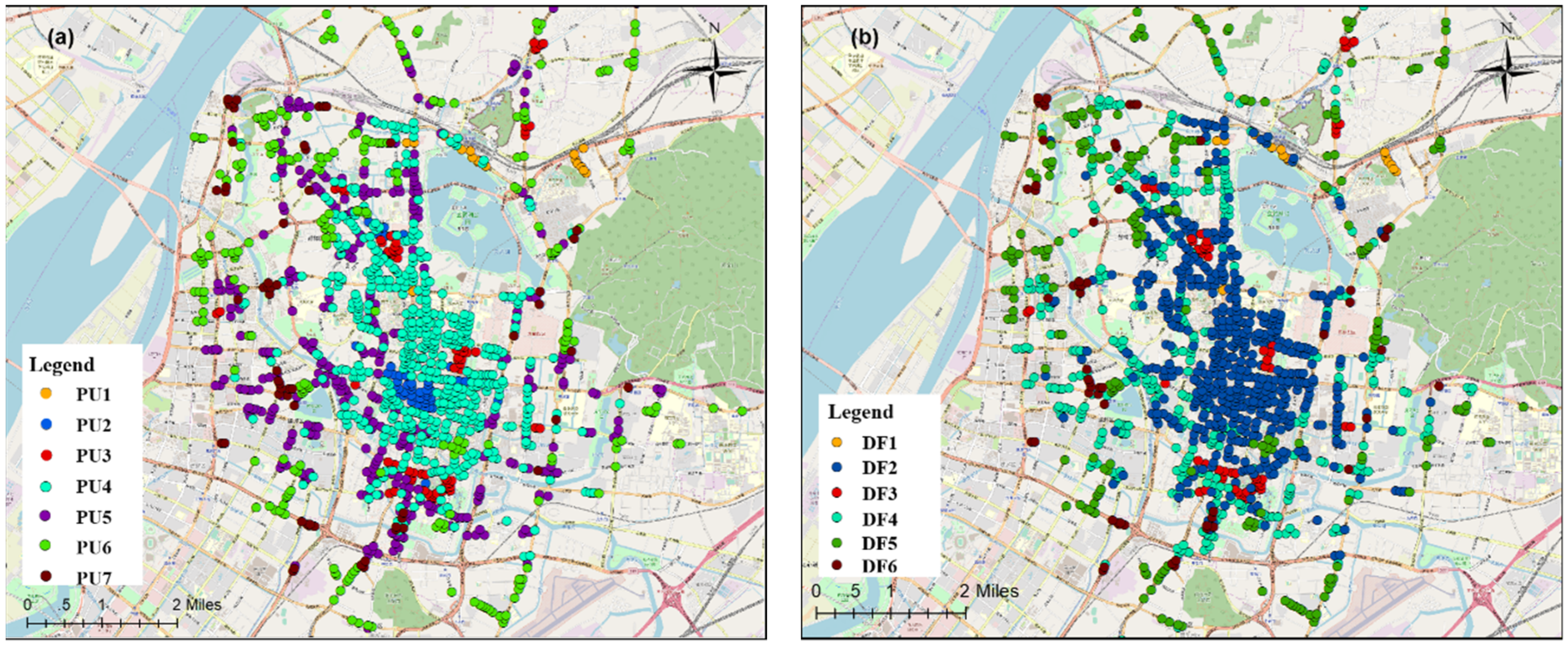
3.2.2. Spatial Distribution of the Travel Patterns
4. Discussion
5. Conclusions
- We used the DBSCAN algorithm, which can effectively eliminate noise, to cluster the taxi travel time series data, and seven departure patterns and six arrival patterns were obtained. Finally, seven human mobility patterns were delimited through spatial matching based on the aggregate units.
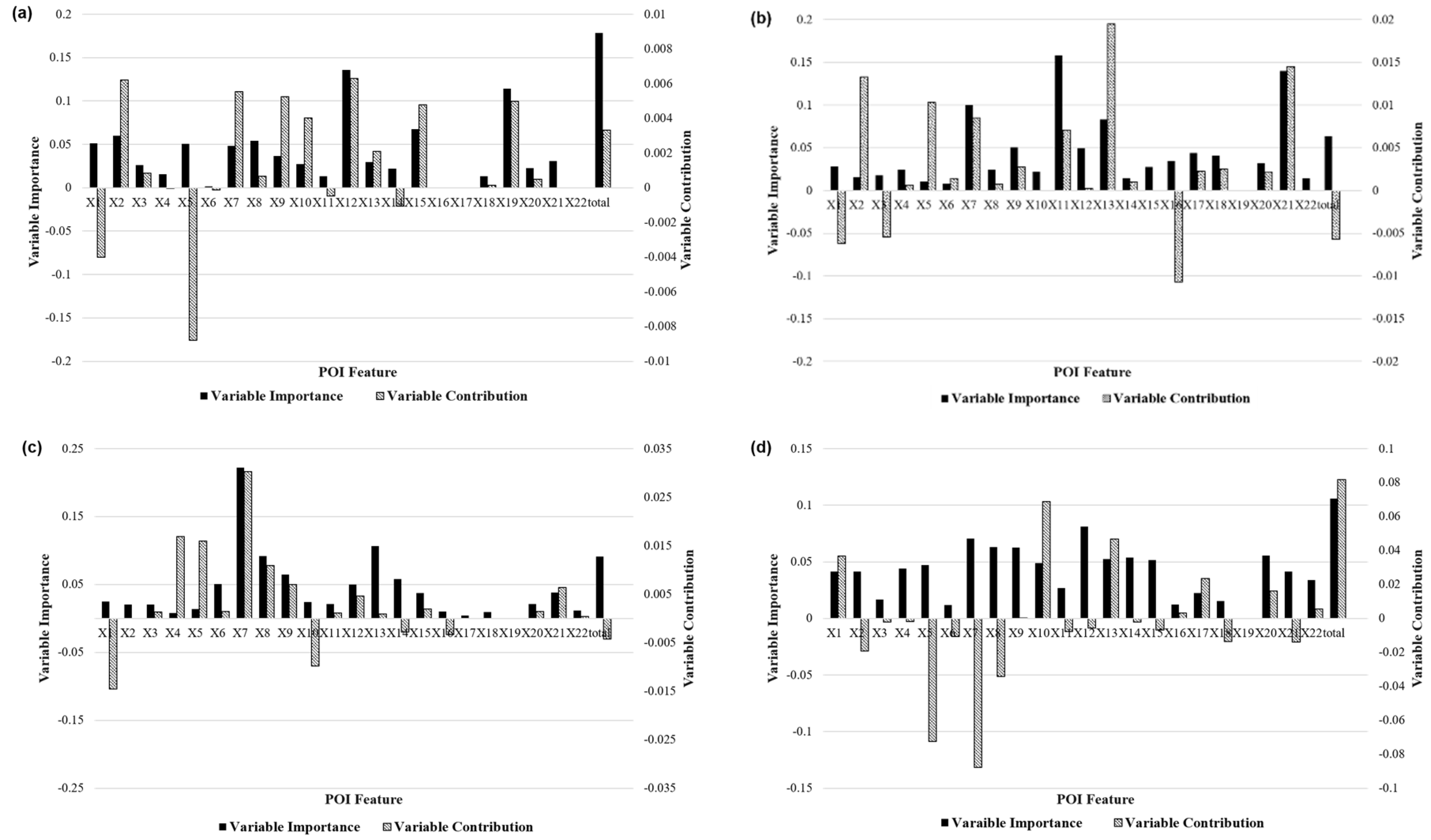
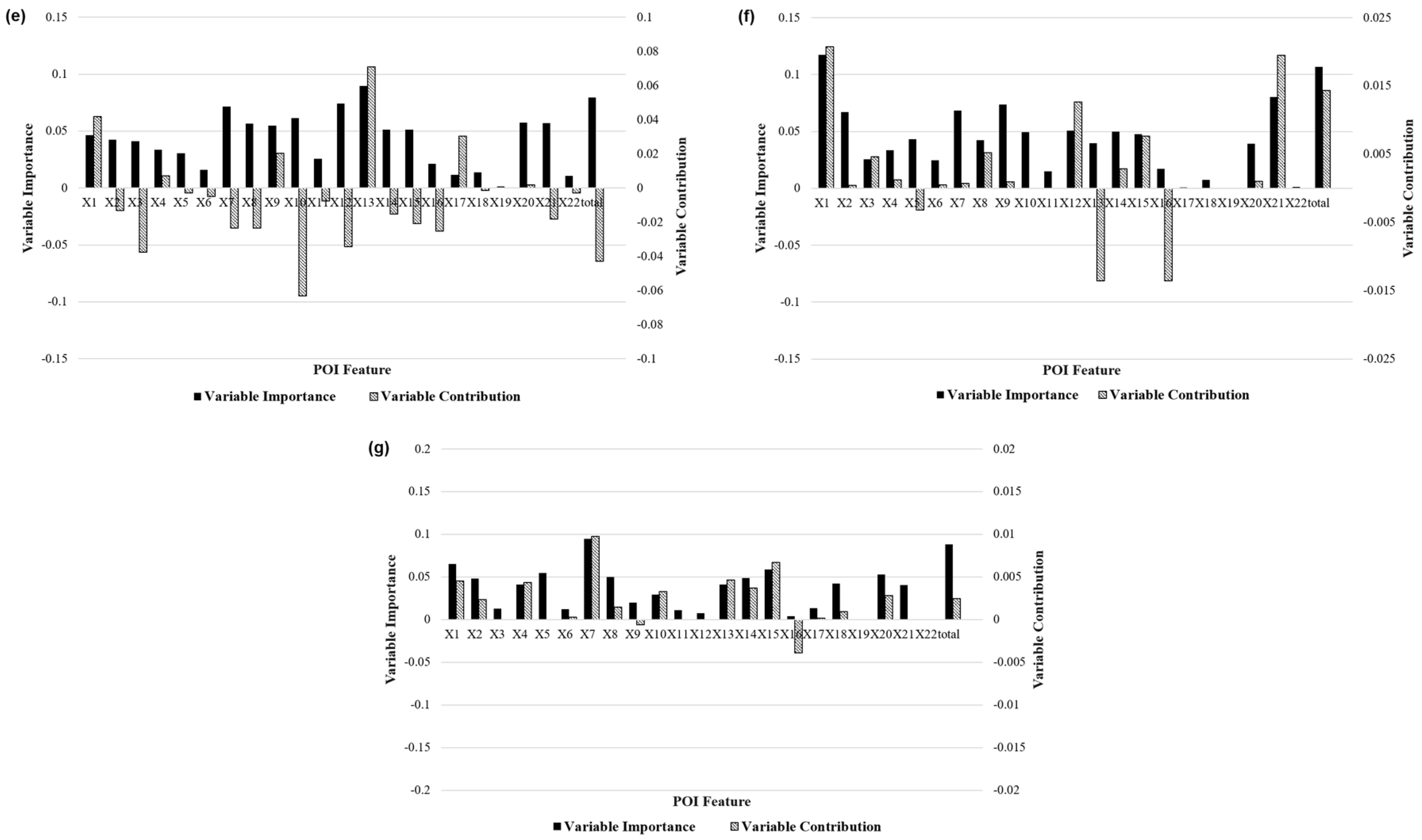
- Using the random forest algorithm, this paper established a correlation model between the mobility patterns and POI features. Using the feature importance and feature contribution measures as indicators, it was verified that the different urban regional functions had different driving mechanisms for the various taxi travel patterns.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zheng, Y.; Liu, Y.; Yuan, J.; Xie, X. Urban computing with taxicabs. In Proceedings of the 13th International Conference on UBIQUITOUS Computing, Beijing, China, 17–21 September 2011; ACM: New York, NY, USA, 2011; pp. 89–98. [Google Scholar]
- Kindberg, T.; Chalmers, M.; Paulos, E. Guest editors introduction: Urban computing. IEEE Pervasive Comput. 2007, 6, 18–20. [Google Scholar] [CrossRef]
- Shklovski, I.; Chang, M.F. Guest Editors’ Introduction: Urban Computing—Navigating Space and Context. Computer 2006, 39, 36–37. [Google Scholar] [CrossRef]
- Yue, Y.; Lan, T.; Yeh, A.G.O.; Li, Q.Q. Zooming into individuals to understand the collective: A review of trajectory-based travel behaviour studies. Travel Behav. Soc. 2014, 1, 69–78. [Google Scholar] [CrossRef]
- Richardson, E.A.; Pearce, J.; Mitchell, R.; Kingham, S. Role of physical activity in the relationship between urban green space and health. Public Health 2013, 127, 318–324. [Google Scholar] [CrossRef] [Green Version]
- Tian, G.; Wu, J.; Yang, Z. Spatial pattern of urban functions in the Beijing metropolitan region. Habitat Int. 2010, 34, 249–255. [Google Scholar] [CrossRef]
- Rapoport, A. Human Aspects of Urban Form: Towards a Man—Environment Approach to Urban Form and Design; Elsevier: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Candia, J.; González, M.C.; Wang, P.; Schoenharl, T.; Madey, G.; Barabási, A.L. Uncovering individual and collective human dynamics from mobile phone records. J. Phys. A Math. 2008, 41, 224015. [Google Scholar] [CrossRef]
- Sekara, V.; Stopczynski, A.; Lehmann, S. Fundamental structures of dynamic social networks. Proc. Natl. Acad. Sci. USA 2016, 113, 9977–9982. [Google Scholar] [CrossRef] [Green Version]
- Palla, G.; Barabási, A.L.; Vicsek, T. Quantifying social group evolution. Nature 2007, 446, 664–667. [Google Scholar] [CrossRef] [Green Version]
- Atzmueller, M.; Ernst, A.; Krebs, F.; Scholz, C.; Stumme, G. Formation and Temporal Evolution of Social Groups during Coffee Breaks. In Big Data Analytics in the Social and Ubiquitous Context; Springer: Cham, Switzerland, 2015; pp. 90–108. [Google Scholar]
- Snepenger, D.J.; Murphy, L.; O’Connell, R.; Gregg, E. Tourists and residents use of a shopping space. Ann. Tour. Res. 2003, 30, 567–580. [Google Scholar] [CrossRef]
- Shen, Y.; Chai, Y.W. Daily activity space of suburban mega-community residents in Beijing based on GPS data. Acta Geogr. Sin. 2013, 68, 506–516. [Google Scholar]
- Peng, C.; Jin, X.; Wong, K.C.; Shi, M.; Liò, P. Collective human mobility pattern from taxi trips in urban area. PLoS ONE 2012, 7, e34487. [Google Scholar]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; ACM: New York, NY, USA, 2012; pp. 186–194. [Google Scholar]
- Fu, Y.; Liu, G.; Ge, Y.; Wang, P.; Zhu, H.; Li, C.; Xiong, H. Representing urban forms: A collective learning model with heterogeneous human mobility data. IEEE Trans. Knowl. Data Eng. 2018, 31, 535–548. [Google Scholar] [CrossRef]
- Zhong, C.; Arisona, S.M.; Huang, X.; Batty, M.; Schmitt, G. Detecting the dynamics of urban structure through spatial network analysis. Int. J. Geogr. Inf. Sci. 2014, 28, 2178–2199. [Google Scholar] [CrossRef]
- Liu, X.; Kang, C.; Gong, L.; Liu, Y. Incorporating spatial interaction patterns in classifying and understanding urban land use. Int. J. Geogr. Inf. Sci. 2016, 30, 334–350. [Google Scholar] [CrossRef]
- Foell, S.; Phithakkitnukoon, S.; Kortuem, G.; Veloso, M.; Bento, C. Catch me if you can: Predicting mobility patterns of public transport users. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 Octorber 2014; pp. 1995–2002. [Google Scholar]
- Giannotti, F.; Nanni, M.; Pedreschi, D.; Pinelli, F.; Renso, C.; Rinzivillo, S.; Trasarti, R. Unveiling the complexity of human mobility by querying and mining massive trajectory data. VLDB J. Int. J. Data Bases 2011, 20, 695–719. [Google Scholar] [CrossRef]
- Brockmann, D.; Hufnagel, L.; Geisel, T. The scaling laws of human travel. Nature 2006, 439, 462–465. [Google Scholar] [CrossRef]
- Liang, X.; Zheng, X.; Lv, W.; Zhu, T.; Xu, K. The scaling of human mobility by taxis is exponential. Phys. A Stat. Mech. Appl. 2012, 391, 2135–2144. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Zhao, J.; Dong, L.; Xu, K. Unraveling the origin of exponential law in intra-urban human mobility. Sci. Rep. 2013, 3, 2983. [Google Scholar] [CrossRef]
- Wu, L.; Zhi, Y.; Sui, Z.; Liu, Y. Intra-urban human mobility and activity transition: Evidence from social media check-in data. PLoS ONE 2014, 9, e97010. [Google Scholar] [CrossRef]
- Calabrese, F.; Di Lorenzo, G.; Ratti, C. Human mobility prediction based on individual and collective geographical preferences. In Proceedings of the 13th international IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; pp. 312–317. [Google Scholar]
- Abbasi, O.; Alesheikh, A.; Sharif, M. Ranking the city: The role of location-based social media check-ins in collective human mobility prediction. ISPRS Int. J. Geo-Inf. 2017, 6, 136. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B.; Yin, J.; Zhao, S. Characterizing the human mobility pattern in a large street network. Phys. Rev. E 2009, 80, 021136. [Google Scholar] [CrossRef] [Green Version]
- Kitamura, R.; Chen, C.; Pendyala, R.M.; Narayanan, R. Micro-simulation of daily activity-travel patterns for travel demand forecasting. Transportation 2000, 27, 25–51. [Google Scholar] [CrossRef]
- Qi, G.; Li, X.; Li, S.; Pan, G.; Wang, Z.; Zhang, D. Measuring social functions of city regions from large-scale taxi behaviors. In Proceedings of the 2011 IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), Seattle, WA, USA, 21–25 March 2011; pp. 384–388. [Google Scholar]
- Veloso, M.; Phithakkitnukoon, S.; Bento, C. Sensing urban mobility with taxi flow. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Location-Based Social Networks, Chicago, IL, USA, 1 November 2011; pp. 41–44. [Google Scholar]
- Kang, C.; Sobolevsky, S.; Liu, Y.; Ratti, C. Exploring human movements in Singapore: A comparative analysis based on mobile phone and taxicab usages. In Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing, Chicago, IL, USA, 11 August 2013; p. 1. [Google Scholar]
- Han, X.P.; Hao, Q.; Wang, B.H.; Zhou, T. Origin of the scaling law in human mobility: Hierarchy of traffic systems. Phys. Rev. E 2011, 83, 036117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Kang, C.; Gao, S.; Xiao, Y.; Tian, Y. Understanding intra-urban trip patterns from taxi trajectory data. J. Geogr. Syst. 2012, 14, 463–483. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, F.; Xiao, Y.; Gao, S. Urban land uses and traffic ‘source-sink areas’: Evidence from GPS-enabled taxi data in Shanghai. Landsc. Urban Plan. 2012, 106, 73–87. [Google Scholar] [CrossRef]
- Tanahashi, Y.; Rowland, J.R.; North, S.; Ma, K.L. Inferring human mobility patterns from anonymized mobile communication usage. In Proceedings of the 10th International Conference on Advances in Mobile Computing Multimedia, Bali, Indonesia, 3–5 December 2012; pp. 151–160. [Google Scholar]
- Roth, C.; Kang, S.M.; Batty, M.; Barthélemy, M. Structure of urban movements: Polycentric activity and entangled hierarchical flows. PLoS ONE 2011, 6, e15923. [Google Scholar] [CrossRef] [PubMed]
- Guo, D.; Zhu, X.; Jin, H.; Gao, P.; Andris, C. Discovering spatial patterns in origin-destination mobility data. Trans. Gis 2012, 16, 411–429. [Google Scholar] [CrossRef]
- Fang, Z.; Shaw, S.L.; Tu, W.; Li, Q.; Li, Y. Spatiotemporal analysis of critical transportation links based on time geographic concepts: A case study of critical bridges in Wuhan, China. J. Transp. Geogr. 2012, 23, 44–59. [Google Scholar] [CrossRef]
- Gao, S.; Wang, Y.; Gao, Y.; Liu, Y. Understanding urban traffic-flow characteristics: A rethinking of betweenness centrality. Env. Plan. B Plan. Des. 2013, 40, 135–153. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, T.; Wang, H.; Zeng, Z. Dynamic accessibility mapping using floating car data: A network-constrained density estimation approach. J. Transp. Geogr. 2011, 19, 379–393. [Google Scholar] [CrossRef]
- Yue, Y.; Zhuang, Y.; Li, Q.; Mao, Q. Mining time-dependent attractive areas and movement patterns from taxi trajectory data. In Proceedings of the 2009 17th International Conference on Geoinformatics, Fairfax, VA, USA, 12–14 August 2009; pp. 1–6. [Google Scholar]
- Wang, H.; Zou, H.; Yue, Y.; Li, Q. Visualizing hot spot analysis result based on mashup. In Proceedings of the 2009 International Workshop on Location Based Social Networks, Seattle, WA, USA, 3 November 2009; pp. 45–48. [Google Scholar]
- Veloso, M.; Phithakkitnukoon, S.; Bento, C. Urban mobility study using taxi traces. In Proceedings of the 2011 International Workshop on Trajectory Data Mining and Analysis, Beijing, China, 18 September 2011; pp. 23–30. [Google Scholar]
- Liu, X.; Gong, L.; Gong, Y.; Liu, Y. Revealing travel patterns and city structure with taxi trip data. J. Transp. Geogr. 2015, 43, 78–90. [Google Scholar] [CrossRef] [Green Version]
- Shen, J.; Liu, X.; Chen, M. Discovering spatial and temporal patterns from taxi-based Floating Car Data: A case study from Nanjing. Gisci. Remote Sens. 2017, 54, 617–638. [Google Scholar] [CrossRef]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Sankoff, D. Time warps, string edits, and macromolecules. Theory Pract. Seq. Comp. Read. 1983, 11, 356. [Google Scholar]
- Fréchet, M.M. Sur quelques points du calcul fonctionnel. Rendiconti del Circolo Matematico di Palermo (1884–1940) 1906, 22, 1–72. [Google Scholar] [Green Version]
- Chouakria, A.D.; Nagabhushan, P.N. Adaptive dissimilarity index for measuring time series proximity. Adv. Data Anal. Classif. 2007, 1, 5–21. [Google Scholar] [CrossRef]
- Hennig, C.; Hausdorf, B. Design of Dissimilarity Measures: A New Dissimilarity between Species Distribution Areas. In Data Science and Classification; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Montero, P.; Vilar, J.A. TSclust: An R Package for Time Series Clustering. J. Stat. Softw. 2014, 62, 1–43. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random forests. In Ensemble Machine Learning: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Strobl, C.; Boulesteix, A.L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef]
- Reif, D.M.; Motsinger, A.A.; McKinney, B.A.; Crowe, J.E.; Moore, J.H. Feature selection using a random forests classifier for the integrated analysis of multiple data types. In Proceedings of the 2006 IEEE Symposium on Computational Intelligence in Bioinformatics and Computational Biology, CIBCB’06, Toronto, ON, Canada, 28–29 September 2006. [Google Scholar]
- Khalilia, M.; Chakraborty, S.; Popescu, M. Predicting disease risks from highly imbalanced data using random forest. BMC Med. Inf. Decis. Mak. 2011, 11, 51. [Google Scholar] [CrossRef] [PubMed]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Kuz’min, V.E.; Polishchuk, P.G.; Artemenko, A.G.; Andronati, S.A. Interpretation of QSAR models based on random forest methods. Mol. Inf. 2011, 30, 593–603. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhu, J.; Sun, Y.; Zhao, J. Delimitating Urban Commercial Central Districts by Combining Kernel Density Estimation and Road Intersections: A Case Study in Nanjing City, China. ISPRS Int. J. Geo-Inf. 2019, 8, 93. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature ID | Feature Description | Urban Construction Land Category |
|---|---|---|
| X1 | Residential area | Residential |
| X2 | Government agency | Administrative office |
| X3 | Cultural facilities | Cultural facility |
| X4 | School/research institute | Educational /Research |
| X5 | Hospital | Medical |
| X6 | Scenic area | Cultural relics and historic sites; religious facilities |
| X7 | Restaurant | Commercial facility |
| X8 | Hostel | Commercial facility |
| X9 | Entertainment venue | Commercial facility |
| X10 | Supermarket | Commercial facility |
| X11 | Department store | Commercial facility |
| X12 | Retail store | Commercial facility |
| X13 | Commercial Building | Commercial facility |
| X14 | Bank | Commercial facility |
| X15 | Company | Commercial facility; Industrial |
| X16 | Cinema | Recreation and wellness facilities |
| X17 | Wellness facility | Recreation and wellness facilities |
| X18 | Subway station | Urban rail transit |
| X19 | Transportation hub | Transportation hub |
| X20 | Bus station | Traffic station site |
| X21 | Parking lot | Traffic station site |
| X22 | Park/garden | Green space |
| Simulation Mode | Mode 1 | Mode 2 | Mode 3 | Mode 4 | Mode 5 | Mode 6 | Mode 7 | |
|---|---|---|---|---|---|---|---|---|
| Actual Mode | ||||||||
| Mode 1 | 7 | 0 | 0 | 1 | 1 | 0 | 0 | |
| Mode 2 | 0 | 9 | 0 | 0 | 6 | 0 | 0 | |
| Mode 3 | 0 | 0 | 7 | 0 | 5 | 0 | 0 | |
| Mode 4 | 0 | 0 | 0 | 22 | 14 | 1 | 1 | |
| Mode 5 | 0 | 0 | 0 | 15 | 92 | 4 | 0 | |
| Mode 6 | 0 | 0 | 0 | 1 | 2 | 15 | 0 | |
| Mode 7 | 0 | 0 | 0 | 3 | 3 | 1 | 2 | |
| Mode | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Mode 1 | 1.00 | 0.78 | 0.88 | 9 |
| Mode 2 | 1.00 | 0.60 | 0.75 | 15 |
| Mode 3 | 1.00 | 0.58 | 0.74 | 12 |
| Mode 4 | 0.52 | 0.58 | 0.55 | 38 |
| Mode 5 | 0.75 | 0.83 | 0.79 | 111 |
| Mode 6 | 0.71 | 0.83 | 0.77 | 18 |
| Mode 7 | 0.67 | 0.22 | 0.33 | 9 |
| Weighted average | 0.74 | 0.73 | 0.72 | 212 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Sun, Y.; Shang, B.; Wang, L.; Zhu, J. Understanding Collective Human Mobility Spatiotemporal Patterns on Weekdays from Taxi Origin-Destination Point Data. Sensors 2019, 19, 2812. https://doi.org/10.3390/s19122812
Yang J, Sun Y, Shang B, Wang L, Zhu J. Understanding Collective Human Mobility Spatiotemporal Patterns on Weekdays from Taxi Origin-Destination Point Data. Sensors. 2019; 19(12):2812. https://doi.org/10.3390/s19122812
Chicago/Turabian StyleYang, Jing, Yizhong Sun, Bowen Shang, Lei Wang, and Jie Zhu. 2019. "Understanding Collective Human Mobility Spatiotemporal Patterns on Weekdays from Taxi Origin-Destination Point Data" Sensors 19, no. 12: 2812. https://doi.org/10.3390/s19122812
APA StyleYang, J., Sun, Y., Shang, B., Wang, L., & Zhu, J. (2019). Understanding Collective Human Mobility Spatiotemporal Patterns on Weekdays from Taxi Origin-Destination Point Data. Sensors, 19(12), 2812. https://doi.org/10.3390/s19122812