Vehicle Counting in Video Sequences: An Incremental Subspace Learning Approach

 , , , , , , and
, , , , , , and 
Abstract
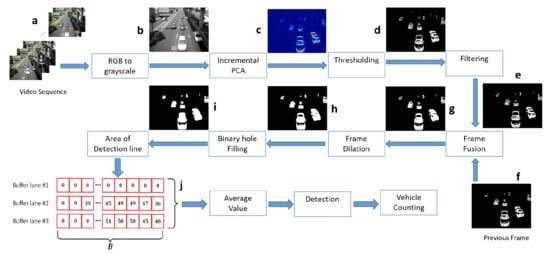
:
1. Introduction
2. Incremental Principal Component Analysis
| Algorithm 1 Incremental PCA with mean update |
|
3. Proposed Methodology
3.1. Motion Detection Using Incremental PCA
3.2. Post-Processing
| Algorithm 2 Binary denoising function |
|
| Algorithm 3 Binary hole filling |
|
3.3. Vehicle Counting
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Banerjee, S.; Dhar, M.; Sen, S. A novel technique to detect the number of ground vehicles along with respective speed of each vehicle from a given video. In Proceedings of the Emerging Trends in Electronic Devices and Computational Techniques (EDCT), Kolkata, West Bengal, India, 8–9 March 2018; pp. 1–6. [Google Scholar]
- Xu, Z.; Zhu, S.; Jin, D. Abnormal behavior detection in crowd scenes. In Proceedings of the Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 214–219. [Google Scholar]
- Shaikh, S.H.; Saeed, K.; Chaki, N. Moving object detection using background subtraction. In Moving Object Detection Using Background Subtraction; Springer Nature Switzerland AG: Basel, Switzerland, 2014; pp. 15–23. ISBN 978-3-319-07386-6. [Google Scholar]
- Mendizabal, A.; Salgado, L. A region based approach to background modeling in a wavelet multi-resolution framework. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 929–932. [Google Scholar]
- Wang, B.; Zhu, W.; Tang, S.; Zhao, Y.; Zou, W. Background subtraction using dual-class backgrounds. In Proceedings of the 14th International Conference on Control, Automation, Robotics and Vision (ICARCV), Phuket, Thailand, 13–15 November 2016; pp. 1–6. [Google Scholar]
- Deng, G.; Guo, K. Self-adaptive background modeling research based on change detection and area training. In Proceedings of the IEEE Workshop on Electronics, Computer and Applications, Ottawa, ON, Canada, 8–9 May 2014; pp. 59–62. [Google Scholar]
- Yadav, D.K. Efficient method for moving object detection in cluttered background using Gaussian Mixture Model. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014; pp. 943–948. [Google Scholar]
- Utasi, A.; Czúni, L. Reducing the foreground aperture problem in mixture of Gaussians based motion detection. In Proceedings of the 14th International Workshop on Systems, Signals and Image Processing and 6th EURASIP Conference focused on Speech and Image Processing, Multimedia Communications and Services, Maribor, Slovenia, 27–30 June 2007; pp. 157–160. [Google Scholar]
- Bouwmans, T. Traditional and recent approaches in background modeling for foreground detection: An overview. Comput. Sci. Rev. 2014, 11, 31–66. [Google Scholar] [CrossRef]
- Wei, S.; Chen, Z.; Li, M.; Zhuo, L. An improved method of motion detection based on temporal difference. In Proceedings of the International Workshop on Intelligent Systems and Applications, Pisa, Italy, 30 November–2 December 2009; pp. 1–4. [Google Scholar]
- Balid, W.; Tafish, H.; Refai, H.H. Intelligent Vehicle Counting and Classification Sensor for Real-Time Traffic Surveillance. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1784–1794. [Google Scholar] [CrossRef]
- Quesada, J.; Rodriguez, P. Automatic vehicle counting method based on principal component pursuit background modeling. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3822–3826. [Google Scholar] [CrossRef]
- Miller, N.; Thomas, M.A.; Eichel, J.A.; Mishra, A. A Hidden Markov Model for Vehicle Detection and Counting. In Proceedings of the 2015 12th Conference on Computer and Robot Vision, Halifax, NS, Canada, 3–5 June 2015; pp. 269–276. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, Y.; Zeng, W. CNN Based Vehicle Counting with Virtual Coil in Traffic Surveillance Video. In Proceedings of the 2015 IEEE International Conference on Multimedia Big Data, Beijing, China, 20–22 April 2015; pp. 280–281. [Google Scholar] [CrossRef]
- Rosas-Arias, L.; Portillo-Portillo, J.; Sánchez-Pérez, G.; Toscano-Medina, K.; Perez-Meana, H.M. A Practical Approach for Counting and Classifying Vehicles Using Rising/Falling Edge Thresholding in a Virtual Detection Line. In Proceedings of the 2018 IEEE International Autumn Meeting on Power, Electronics and Computing (ROPEC), Ixtapa, Mexico, 14–16 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Seenouvong, N.; Watchareeruetai, U.; Nuthong, C.; Khongsomboon, K.; Ohnishi, N. A computer vision based vehicle detection and counting system. In Proceedings of the 2016 8th International Conference on Knowledge and Smart Technology (KST), Chiangmai, Thailand, 3–6 February 2016; pp. 224–227. [Google Scholar] [CrossRef]
- Anandhalli, M.; Baligar, V.P. A novel approach in real-time vehicle detection and tracking using Raspberry Pi. Alex. Eng. J. 2018, 57, 1597–1607. [Google Scholar] [CrossRef]
- Sravan, M.S.; Natarajan, S.; Krishna, E.S.; Kailath, B.J. Fast and accurate on-road vehicle detection based on color intensity segregation. Procedia Comput. Sci. 2018, 133, 594–603. [Google Scholar] [CrossRef]
- Selim, S.; Sarikan, A. Murat Ozbayoglu, Anomaly Detection in Vehicle Traffic with Image Processing and Machine Learning. Procedia Comput. Sci. 2018, 140, 64–69. [Google Scholar]
- Zhang, S.; Wu, G.; Costeira, J.; Moura, J. FCN-rLSTM: Deep Spatio-Temporal Neural Networks for Vehicle Counting in City Cameras. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3687–3696. [Google Scholar] [CrossRef]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A Large Contextual Dataset for Classification, Detection and Counting of Cars with Deep Learning. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9907. [Google Scholar]
- Arinaldi, A.; Pradana, J.A.; Gurusinga, A.A. Detection and classification of vehicles for traffic video analytics. Procedia Comput. Sci. 2018, 144, 259–268. [Google Scholar] [CrossRef]
- Li, S.; Lin, J.; Li, G.; Bai, T.; Wang, H.; Yu, P. Vehicle type detection based on deep learning in traffic scene. Procedia Comput. Sci. 2018, 131, 564–572. [Google Scholar]
- Nguyen, V.; Kim, H.; Jun, S.; Boo, K. A Study on Real-Time Detection Method of Lane and Vehicle for Lane Change Assistant System Using Vision System on Highway. Eng. Sci. Technol. Int. J. 2018, 21, 822–833. [Google Scholar] [CrossRef]
- Liu, F.; Zeng, Z.; Jiang, R. A video-based real-time adaptive vehicle-counting system for urban roads. PLoS ONE 2017, 12, e0186098. [Google Scholar] [CrossRef] [PubMed]
- Portillo-Portillo, J.; Sánchez-Pérez, G.; Olivares-Mercado, J.; Pérez-Meana, H. Movement Detection of Vehicles in Video Sequences Based on the Absolute Difference Between Frames and Edge Combination. Información Tecnológica 2014, 25, 129–136. [Google Scholar] [CrossRef]
- Bouwmans, T. Subspace learning for background modeling: A survey. Recent Pat. Comput. Sci. 2009, 2, 223–234. [Google Scholar] [CrossRef]
- Guo, X.; Wang, X.; Yang, L.; Cao, X.; Ma, Y. Robust foreground detection using smoothness and arbitrariness constraints. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 535–550. [Google Scholar]
- He, J.; Balzano, L.; Szlam, A. Incremental gradient on the Grassmannian for online foreground and background separation in subsampled video. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1568–1575. [Google Scholar]
- Yuan, Y.; Pang, Y.; Pan, J.; Li, X. Scene segmentation based on IPCA for visual surveillance. Neurocomputing 2009, 72, 2450–2454. [Google Scholar] [CrossRef]
- Pang, Y.; Wang, S.; Yuan, Y. Learning regularized LDA by clustering. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 2191–2201. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Ithapu, V.K.; Mukherjee, L.; Rehg, J.M.; Singh, V. GOSUS: Grassmannian online subspace updates with structured-sparsity. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3376–3383. [Google Scholar]
- Pang, Y.; Ye, L.; Li, X.; Pan, J. Incremental Learning With Saliency Map for Moving Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 640–651. [Google Scholar] [CrossRef]
- Lim, J.; Ross, D.A.; Lin, R.S.; Yang, M.H. Incremental learning for visual tracking. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2005; pp. 793–800. [Google Scholar]
- Levey, A.; Lindenbaum, M. Sequential Karhunen-Loeve basis extraction and its application to images. IEEE Trans. Image Process. 2000, 9, 1371–1374. [Google Scholar] [CrossRef] [PubMed]
- Goyette, N.; Jodoin, P.-M.; Porikli, F.; Konrad, J.; Ishwar, P. Changedetection.net: A new change detection benchmark dataset. In Proceedings of the IEEE Workshop on Change Detection (CDW-2012), Providence, RI, USA, 16–21 June 2012; pp. 1–8. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video No. 1 | Detected Vehicles/ Total Vehicles | False Positives | False Negatives | Accuracy |
|---|---|---|---|---|
| Lane #1 | 9/9 | 0 | 0 | 100% |
| Lane #2 | 10/10 | 0 | 0 | 100% |
| Lane #3 | 13/13 | 0 | 0 | 100% |
| Total | 32/32 | 0 | 0 | 100% |
| Video No. 2 | Detected Vehicles/ Total Vehicles | False Positives | False Negatives | Accuracy |
|---|---|---|---|---|
| Lane #1 | 6/6 | 0 | 0 | 100% |
| Lane #2 | 7/7 | 0 | 0 | 100% |
| Lane #3 | 12/12 | 0 | 0 | 100% |
| Lane #4 | 6/7 | 0 | 1 | 85.71% |
| Total | 31/32 | 0 | 1 | 96.87% |
| Video No. 3 | Detected Vehicles/ Total Vehicles | False Positives | False Negatives | Accuracy |
|---|---|---|---|---|
| Lane #1 | 7/7 | 0 | 0 | 100% |
| Lane #2 | 15/13 | 2 | 0 | 84.61% |
| Lane #3 | 10/10 | 0 | 0 | 100% |
| Total | 32/30 | 2 | 0 | 93.33% |
| Video No. 4 | Detected Vehicles/ Total Vehicles | False Positives | False Negatives | Accuracy |
|---|---|---|---|---|
| Lane #1 | 17/17 | 0 | 0 | 100% |
| Lane #2 | 9/10 | 0 | 1 | 90% |
| Total | 26/27 | 0 | 1 | 96.29% |
| Method | Accuracy | fps | Hardware |
|---|---|---|---|
| Liu, F., et al. [25] | 99% | 10 fps | Not reported |
| L. Rosas-Arias, et al. [15] | 100% | Not reported | 2.0 GHz Intel CPU |
| Mundhenk T.N., et al. [21] | Not reported | 1 fps | Nvidia Titan X GPU |
| N. Seenouvong, et al. [16] | 96% | 30 fps | 2.4 GHz Intel CPU |
| N. Miller, et al. [13] | 93% | Not reported | Not reported |
| J. Quesada, et al. [12] | 91% | 26 fps | 3.5 GHz Intel CPU |
| J. Zheng, et al. [14] | 90% | Not reported | 3.2 GHz Intel CPU |
| Ahmad Arinaldi, et al. [22] | 70% (at most) | Not reported | Not reported |
| Ours | 96.6% | 26 fps | 2.0 GHz Intel CPU |
| Method | Comments |
|---|---|
| Liu, F., et al. [25] | Reaches 99% of accuracy only under ideal situations. |
| L. Rosas-Arias, et al. [15] | Reaches 100% of accuracy only under ideal situations. |
| Mundhenk T.N., et al. [21] | High aerial coverage area. Vehicles are counted as individual hi-res images. |
| N. Seenouvong, et al. [16] | Does not update the background model and is not robust to illumination changes. |
| N. Miller, et al. [13] | The counting process uses a very complex configuration of ROIs. |
| J. Quesada, et al. [12] | Utilizes an incremental approach for detecting motion in aerial images (top-view). |
| J. Zheng, et al. [14] | Although it is not reported, authors claim their proposed method runs in real-time. |
| Ahmad Arinaldi, et al. [22] | The system is evaluated under both standard and very challenging environments. |
| Ours | Balanced methodology between accuracy, fps, hardware, and robustness. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosas-Arias, L.; Portillo-Portillo, J.; Hernandez-Suarez, A.; Olivares-Mercado, J.; Sanchez-Perez, G.; Toscano-Medina, K.; Perez-Meana, H.; Sandoval Orozco, A.L.; García Villalba, L.J. Vehicle Counting in Video Sequences: An Incremental Subspace Learning Approach. Sensors 2019, 19, 2848. https://doi.org/10.3390/s19132848
Rosas-Arias L, Portillo-Portillo J, Hernandez-Suarez A, Olivares-Mercado J, Sanchez-Perez G, Toscano-Medina K, Perez-Meana H, Sandoval Orozco AL, García Villalba LJ. Vehicle Counting in Video Sequences: An Incremental Subspace Learning Approach. Sensors. 2019; 19(13):2848. https://doi.org/10.3390/s19132848
Chicago/Turabian StyleRosas-Arias, Leonel, Jose Portillo-Portillo, Aldo Hernandez-Suarez, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, Karina Toscano-Medina, Hector Perez-Meana, Ana Lucila Sandoval Orozco, and Luis Javier García Villalba. 2019. "Vehicle Counting in Video Sequences: An Incremental Subspace Learning Approach" Sensors 19, no. 13: 2848. https://doi.org/10.3390/s19132848
APA StyleRosas-Arias, L., Portillo-Portillo, J., Hernandez-Suarez, A., Olivares-Mercado, J., Sanchez-Perez, G., Toscano-Medina, K., Perez-Meana, H., Sandoval Orozco, A. L., & García Villalba, L. J. (2019). Vehicle Counting in Video Sequences: An Incremental Subspace Learning Approach. Sensors, 19(13), 2848. https://doi.org/10.3390/s19132848