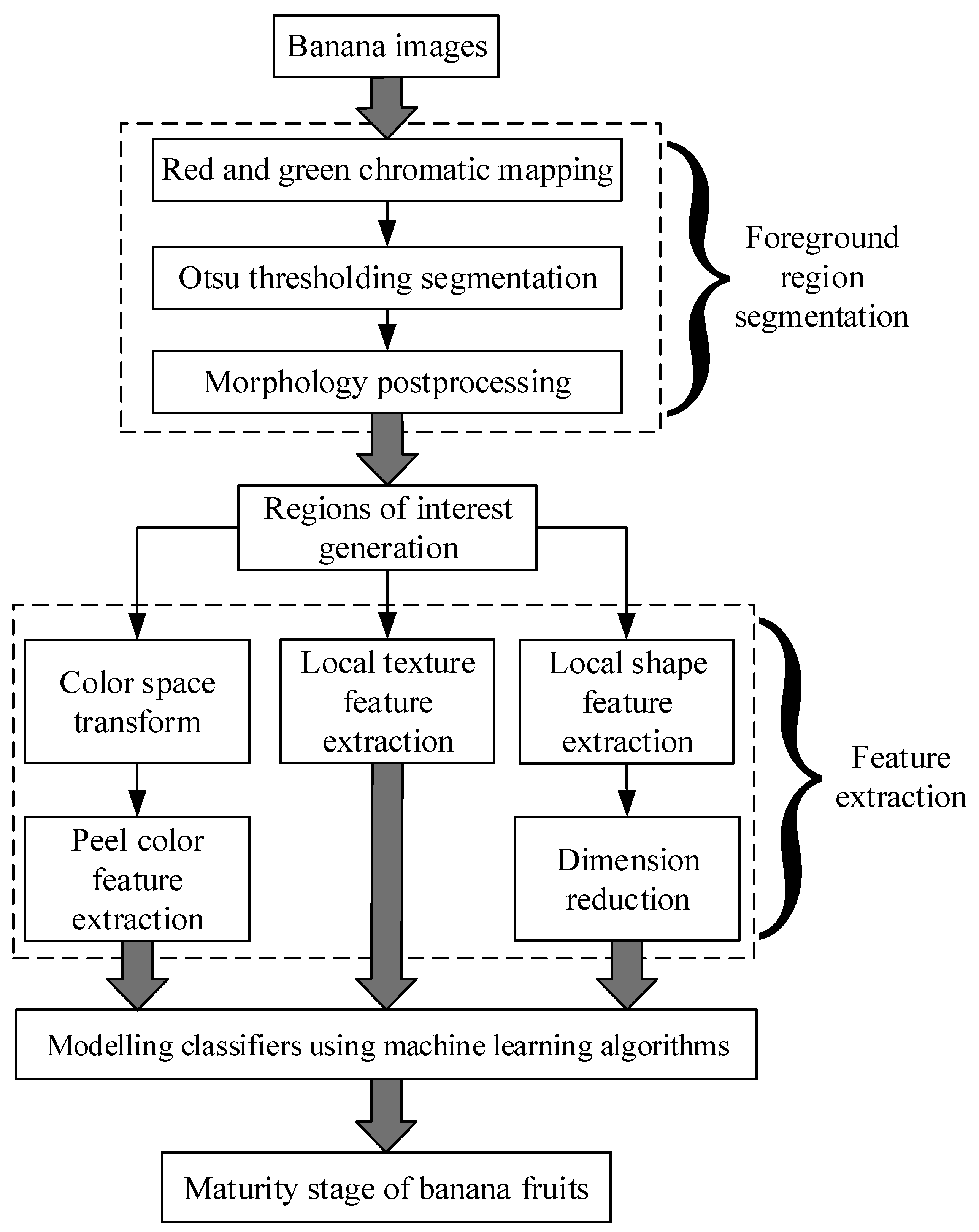
2.2.1. Foreground Region Segmentation
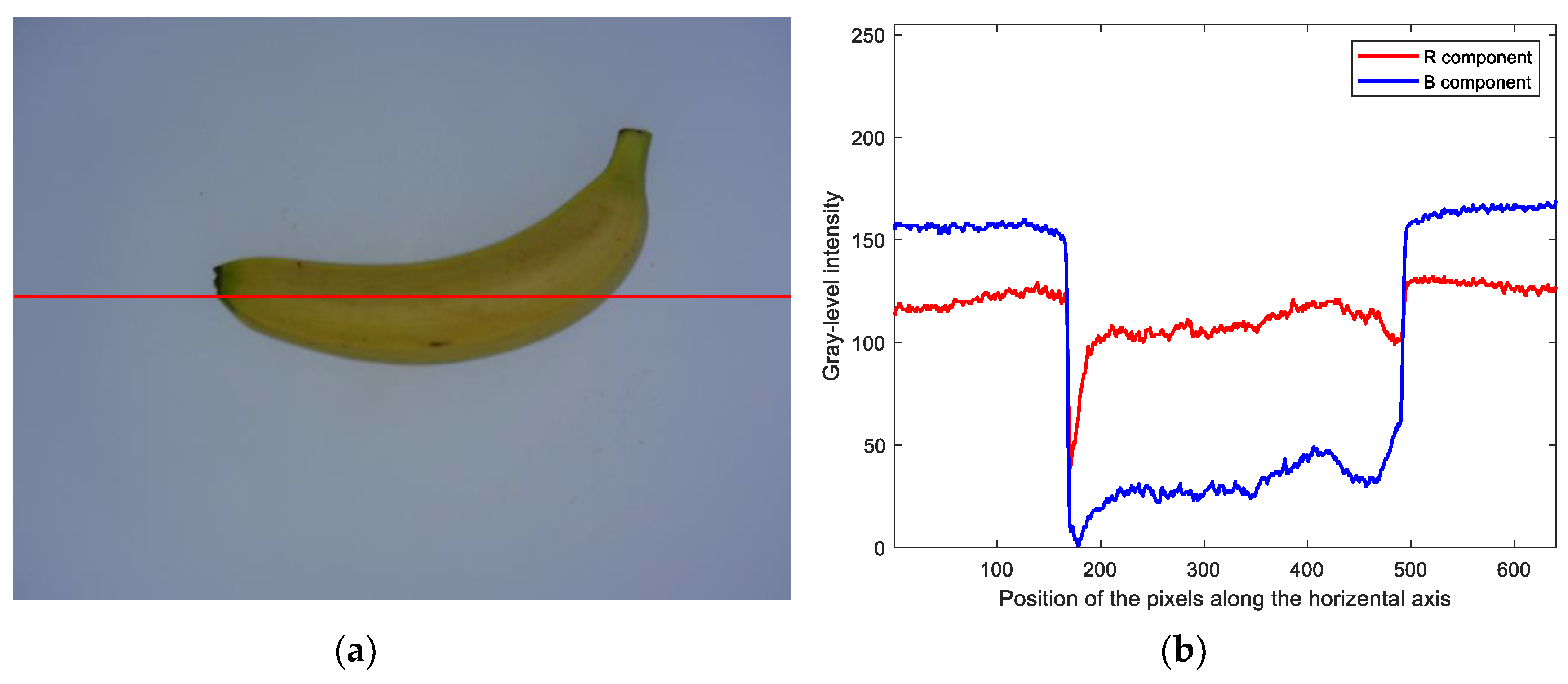
For any horizontal scan line across banana fruit, as shown in
Figure 4a, the color intensity of pixels of the banana is different from that of the background. Specifically, in RGB color space, the gray-level intensity of pixels within the banana region in the red (
R) component is always higher than that in the blue (
B) component, as shown in
Figure 4b, while the gray-level intensity of pixels within the background region in the
R component is always lower than that in the
B component. Therefore, the banana could be separated from the background using the following red and blue (RB) chromatic mapping:
where
IRB is the calculated RB chromatic map, and
R and
B refer to the red and blue components of the input image in RGB color space, respectively.
Since the hue and appearance of the banana images in the dataset could differ to some extent due to slight changes in lighting conditions during imaging, it is hard to always ensure consistently high intensities of all the pixels within the banana, and thus, the resultant RB chromatic map is not a binary image that separates the banana fruit from the background. Therefore, the Otsu thresholding algorithm [
25] was adopted to segment the foreground banana region from
IRB. Then, the mathematical morphology open operation followed by the hole-filling operation was used to filter out noise and fill holes in the binary image obtained by the Otsu thresholding algorithm, respectively, and the foreground banana region was extracted from the morphologically postprocessed binary image.
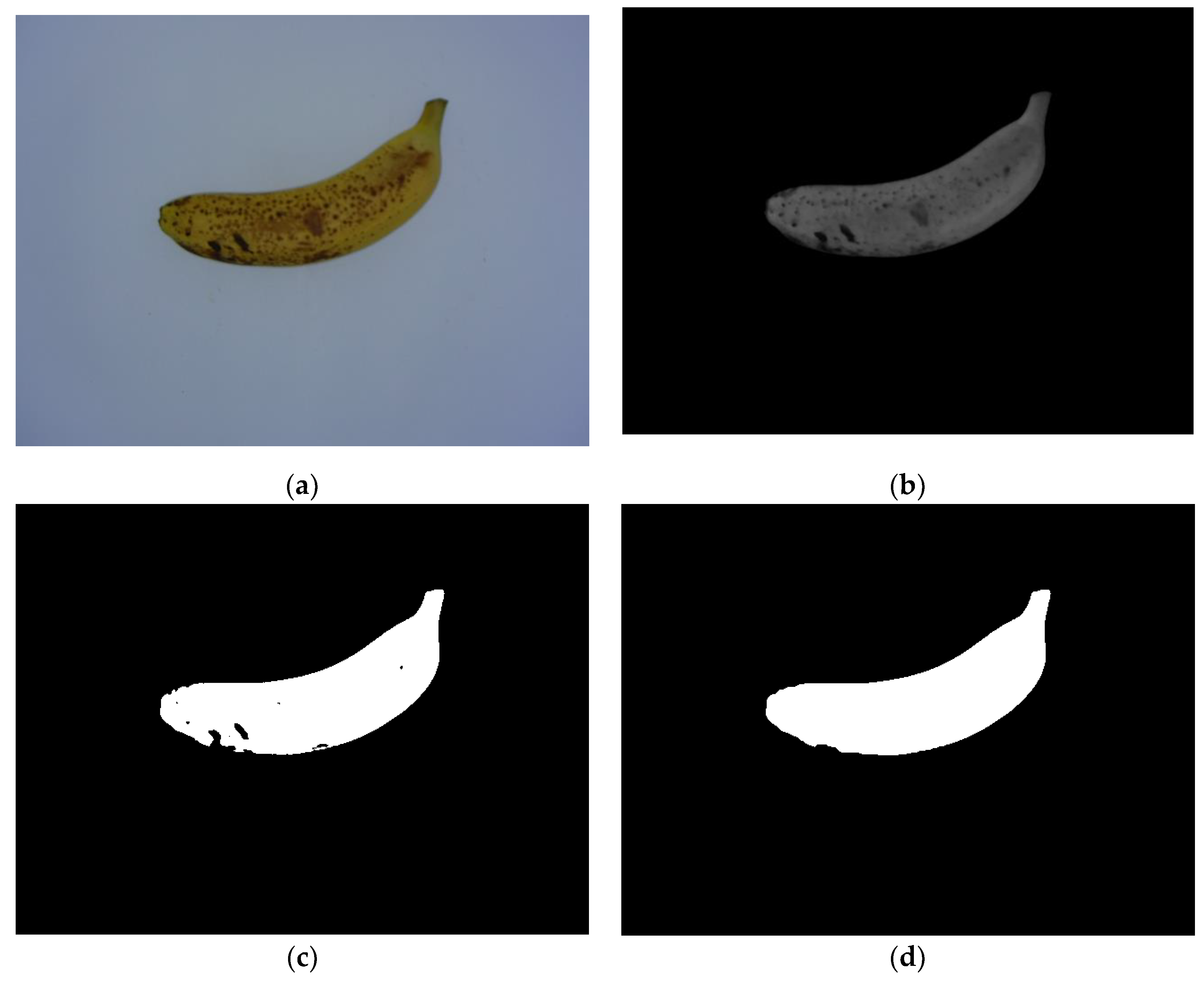
Figure 5 illustrates an example of banana fruit region segmentation using a sample image from MS4.
Figure 5b shows that most of the background was filtered out in the resultant RB chromatic map because the difference in intensity between the
R and
B components of the background is much lower than that from the banana fruit region. Moreover, a large number of brown spots were distributed on the surface of the banana peel, and thus, no significant RB intensity difference between the brown spots and the background was found, which resulted in an incorrect segmentation of some brown spots, as shown in
Figure 5c. Fortunately, mathematical morphology image processing techniques, i.e., open operations (using the disk-shaped structural element with a 10-pixel radius) followed by hole filling, could fix the incorrectly segmented foreground regions, as shown in
Figure 5d, and more accurate banana fruit regions could be extracted for the following procedures.
2.2.2. Feature Extraction
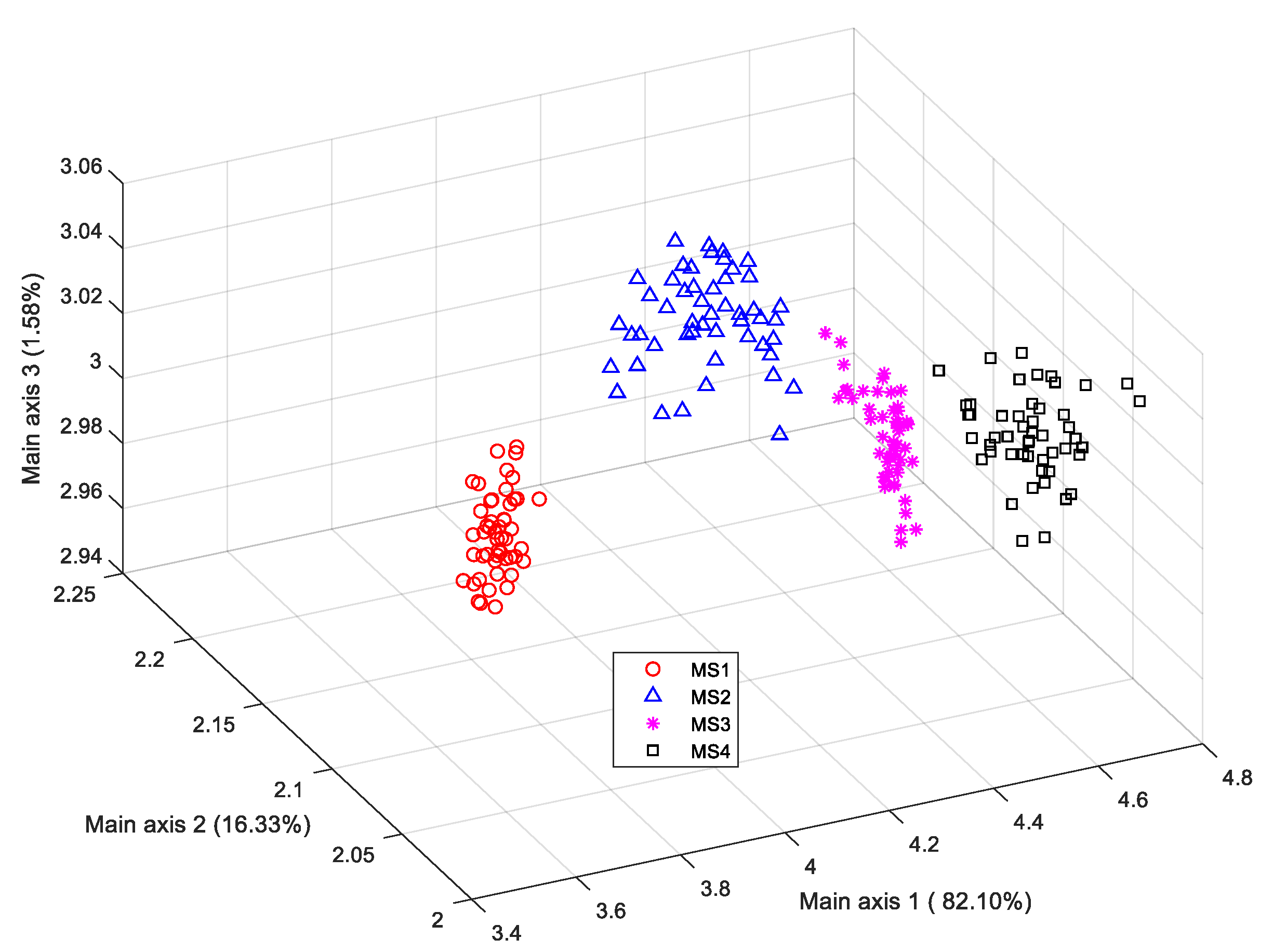
The external optical properties of bananas, including the color, local texture and shape features that were observed from samples belonging to various maturity stages in the training dataset, are potential criteria for identifying different maturity stages. For example, the local texture and shape structure are significantly affected by the distribution of brown spots on the peel at higher banana maturity stages.
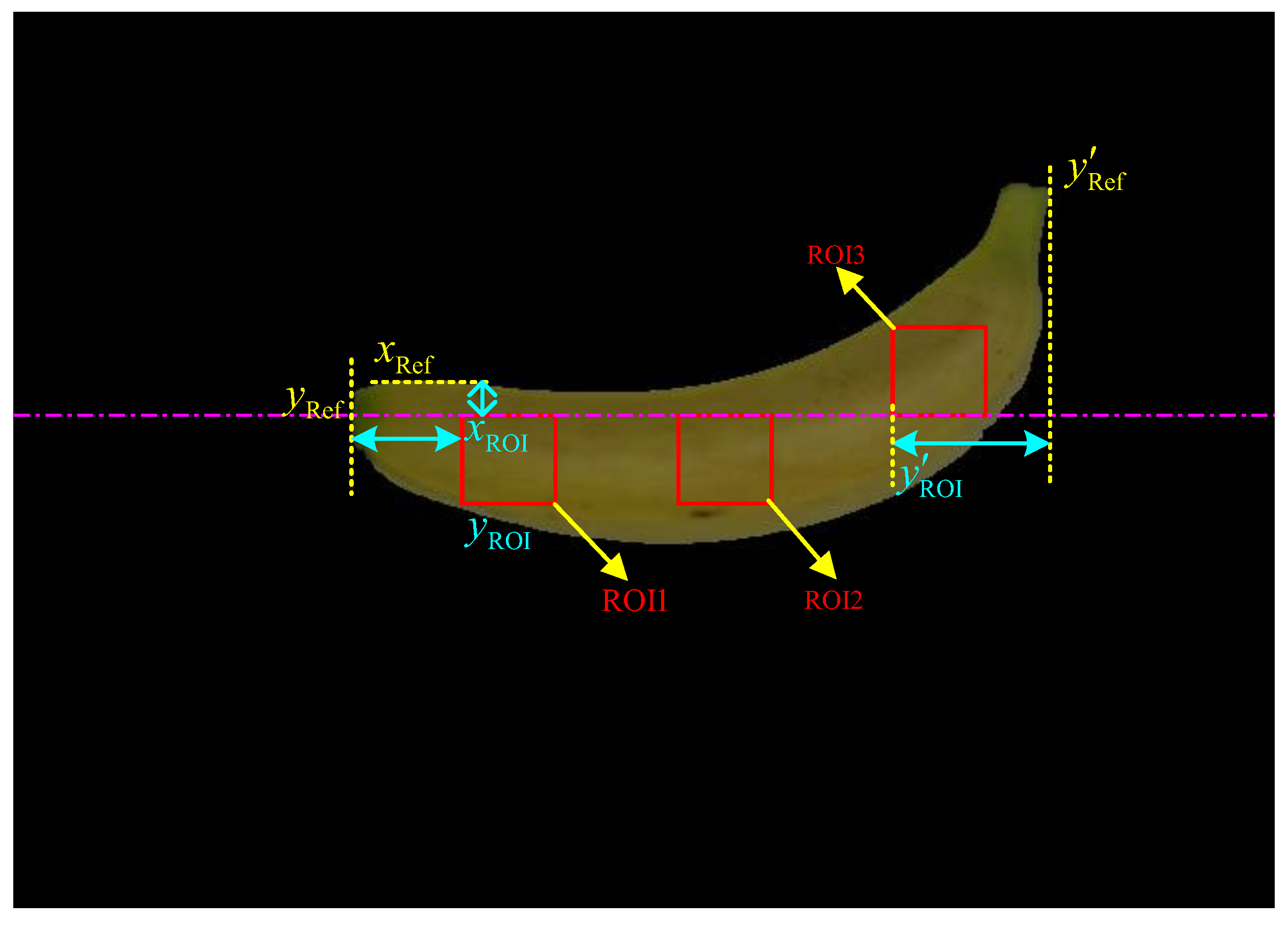
First, as illustrated in
Figure 6, three regions of interest (ROIs) were sampled and extracted from the segmented foreground banana region, where
is the upper-left horizontal boundary of the segmented banana,
and
represent the left and right vertical boundaries of the segmented banana, respectively,
is the abscissa of the image origin of both ROI1 and ROI2,
and
refer to the ordinate of the image origin of ROI1 and ROI3, respectively. The sizes of each ROI were assigned as 48 pixels × 48 pixels to simplify the following feature extraction process. By introducing different offsets, the value of
was determined by the value of
, where
a is an integer ranging from 15 to 35 pixels, the value of
was determined from
, where
α is a random floating value ranging from 0.1 to 0.2, and the value of
was determined from
, where
β is a floating value ranging from 0.15 to 0.25. Furthermore, the ordinate of the image origin of ROI2 was calculated by
, and the abscissa of the image origin of ROI3 was determined by the value of
– 48. Similar to the sampling method adopted in most destructive analysis methods, the sampling of three ROIs from several nonintersecting parts (i.e., the stalk, middle and tip positions) could improve the sequent identification performance.
(1) Color Feature Extraction
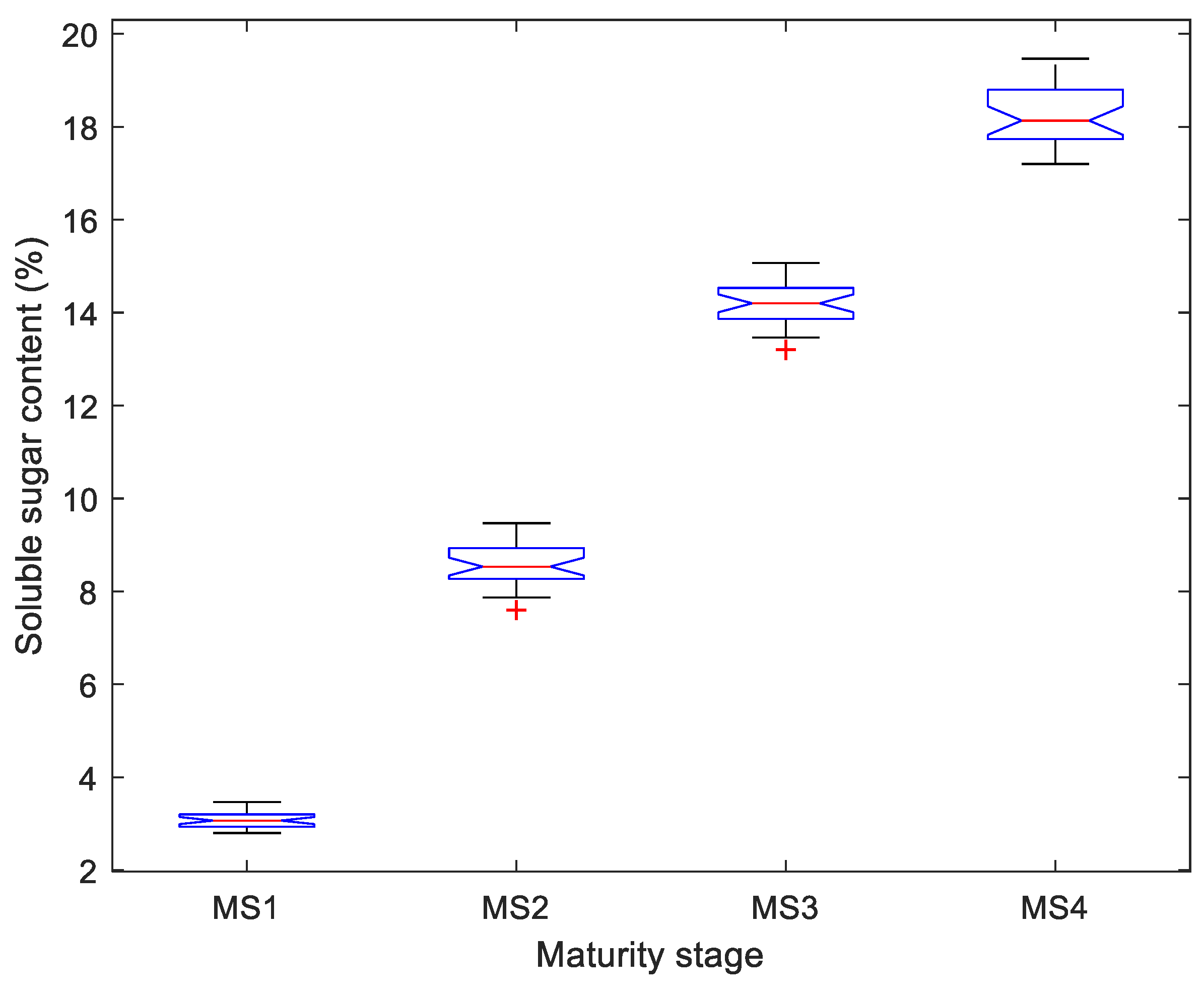
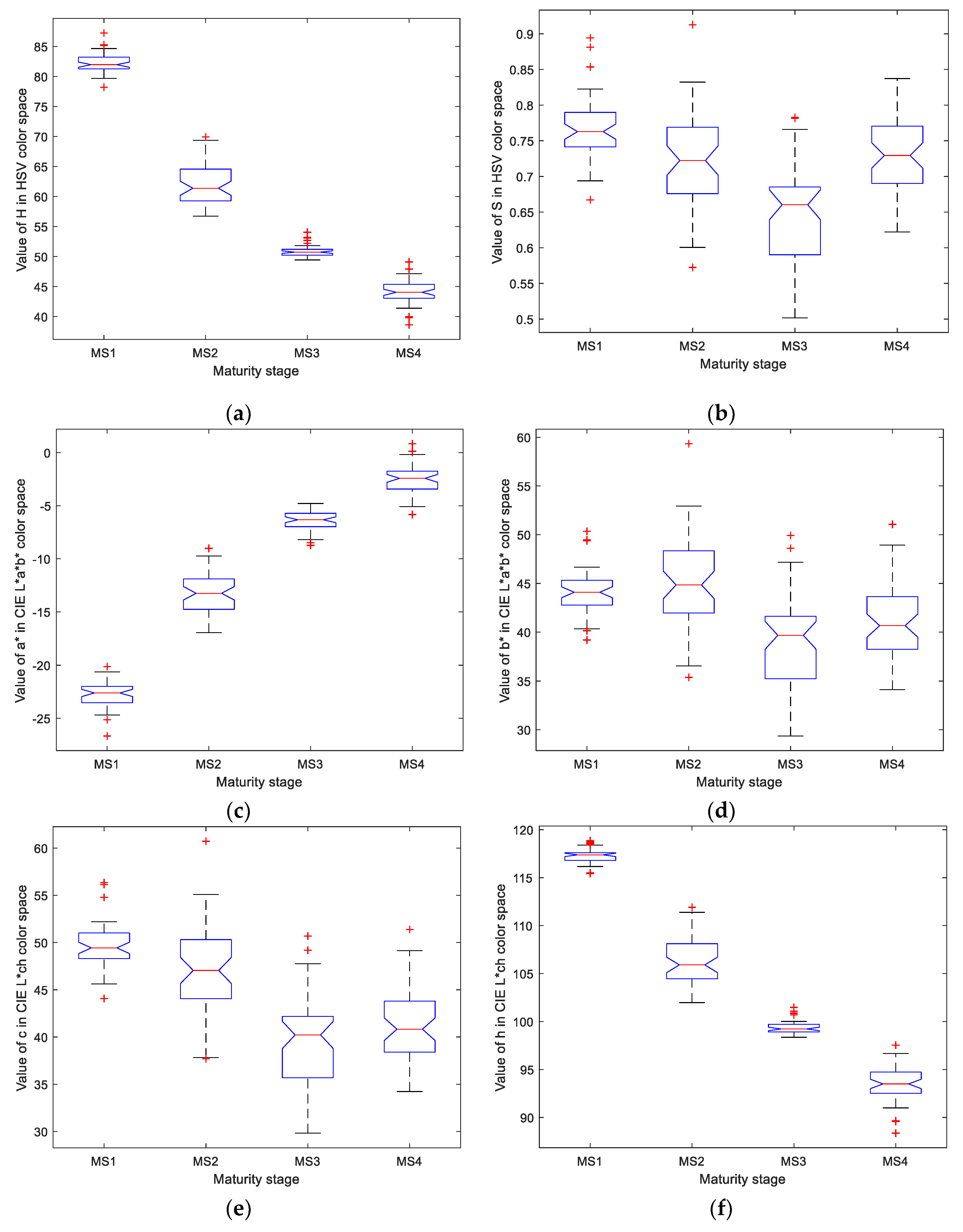
As the banana maturity changes from MS1 to MS4, the hue color gradually changes from full green to yellow, which is an important visual clue to discriminate various maturity stages. However, all the red, green and blue components in RGB color space contain both the color and brightness information of objects at the same time, where the brightness information might not be helpful for identifying the maturity stage. Therefore, to isolate only the color component, the hue-saturation-value (HSV), CIE L*a*b* and CIE L*ch color spaces were introduced to provide the pure color information because the color components in these spaces are independent of the corresponding brightness component.
For the three ROIs located at any segmented foreground banana region, the corresponding ROI images were first transformed from RGB color space into HSV, CIE L*a*b* and CIE L*ch color spaces. The hue component H and the saturation component S of the HSV color space, the a* color component and the b* color component of the CIE L*a*b* color space, and the chromatic degree component c and the hue component h of the CIE L*ch color space were extracted. Thus, the average intensity of all the pixels in each color component was calculated and served as a corresponding color feature value. All the feature values obtained from different color components (i.e., H, S, a*, b*, c and h) formed a 6-dimension color descriptor. Since there were three ROIs in each banana sample, the three color descriptors generated from different ROIs were then successively concatenated into a color feature vector with a dimension of 6 × 3 = 18.
(2) Local Texture Feature Extraction
The increase in the maturity could alter the local texture of a banana peel, which might be attributed to (i) a slight change in local gray-level intensity discontinuity caused by the color change across adjacent maturity stages or (ii) a gradual increase in brown spots while banana fruits reach close to the overmature stage. Therefore, textural information described by the local binary pattern (LBP) algorithm [
26] was adopted to identify the maturity stage of banana fruits.
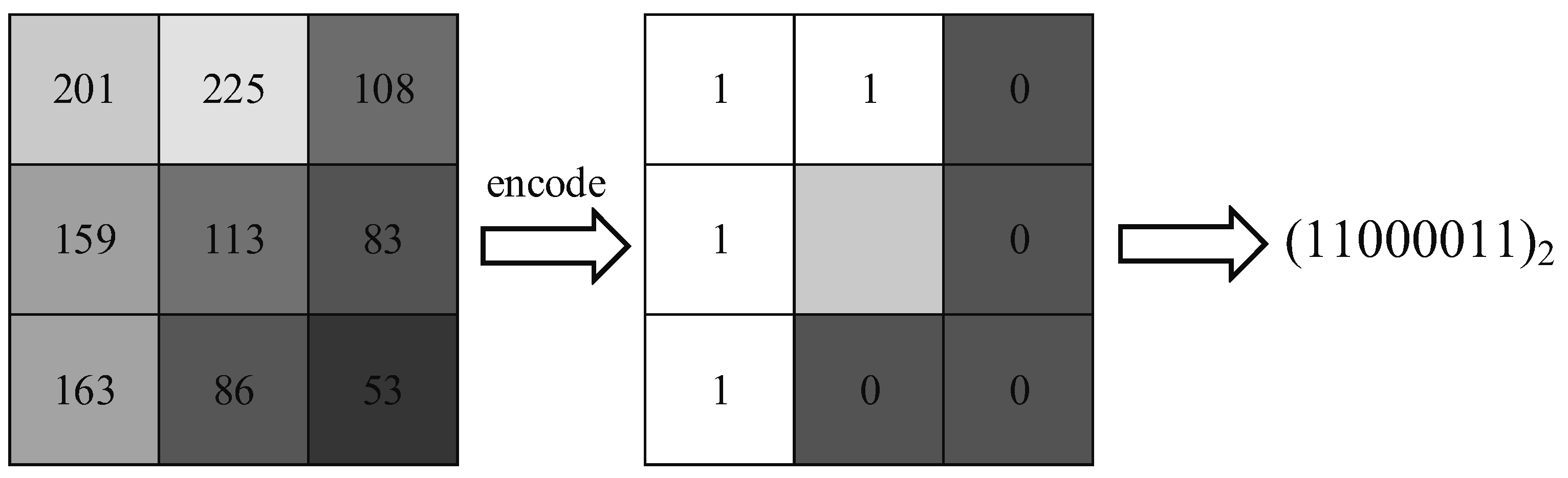
LBP encodes any local 3 × 3 image region into a specific binary pattern, as shown in
Figure 7. Basically, LBP compares the intensity of a center pixel
ic and that of the 8 surrounded neighboring pixels
ik (
k = 1, 2,…, 8). The
k-th neighboring pixel would be given a value of 1 if
is true; otherwise, it would be given a value of 0. All the encoded values form an 8-bit binary pattern to depict the local intensity continuity in terms of equation (2). Therefore, a 256-dimension texture feature vector could be generated. However, it is not advisable to extract 256-dimensional LBP features from small ROIs; the result would be too sparse. Therefore, an LBP with a uniform pattern (UP-LBP) [
27] was adopted to reduce the dimension of the resultant texture feature vector, where at most two conversions between adjacent encoded values (e.g., converting from a value of 1 to a value of 0 or vice versa) in an 8-bit binary number were considered. In total, 58 binary patterns meet the conversion rules, and the remaining 198 patterns are considered the 59th pattern. A 59-dimensional texture descriptor could be extracted from each ROI, and the resulting three texture descriptors generated from different ROIs were then successively concatenated into an UP-LBP texture feature vector with a dimension of 59 × 3 = 177.
(3) Local Shape Feature Extraction
Similar to the change in local textures, the local shapes of the banana peel could also be influenced by the increase in the maturity stage. For example, the change in the gray-level intensity discontinuity across adjacent maturity stages would influence the distribution of local intensity gradients. Therefore, histogram of oriented gradients (HOG) [
28] was adopted. The main idea of HOG is that local shape information can be well described by calculating the distribution of local edge directions and intensity gradients on a dense grid.
When extracting the HOG features, each ROI was equally divided into 4 × 4 image cells of 12 pixels × 12 pixels. Adjacent 2 × 2 cells formed an image block, and thus 3 × 3 blocks were generated. The size of the intersection area between two adjacent blocks was assigned by 1 cell × 2 cells in the horizontal dense scan or by 2 cells × 1 cell in the vertical dense scan. The gradients of the pixels within each cell were calculated using the Prewitt operator, and then the magnitude of the gradients was cumulatively voted into 9 uniformly spaced bins ranging from 0 to π according to the gradients’ direction. Thus, a 36-dimensional histogram was generated for each block and further normalized by the L1-norm. Therefore, a shape descriptor with a dimension of 36 × 3 × 3 = 324 could be extracted from each ROI, and the three shape descriptors generated from different ROIs were then successively concatenated into a HOG feature vector with a dimension of 324 × 3 = 972.
2.2.3. Classification of the Maturity Stages
In the maturity stage identification task, it is interesting to evaluate the benefits from different types of external optical properties. The naïve Bayes (NB), linear discriminant analysis (LDA) and support vector machine (SVM) classifiers were used to model the extracted color, the local texture and the local shape features, respectively.
(1) NB Classifier
Let
m labeled samples (extracted feature vectors) from
c different classes in the training dataset be denoted by
, where
and
, and a test sample be denoted by
. The NB classifier [
29] is a supervised machine learning algorithm that is derived from Bayes’ theorem. The label of the
d-dimensional feature vector
can be predicted as follows:
where
P(
c) is the prior probability of each class and
refers to the conditional probability of the feature
. Both
P(
c) and
can be estimated from the training dataset.
(2) LDA Classifier
LDA is a variant of Fisher’s discriminant analysis [
30] and is suitable for multiclass classifications; the basic idea is to minimize the within-class variance and maximize the between-class variance in the training samples. Suppose that the average feature vector for the
i-th class
is
and the population average feature vector for all the
c classes is
μ. LDA aims to find the optimal classification hyperplane from the projected feature space indicated by:
where
is the projecting matrix and
Sw and
refer to the within-class and between-class scatter matrix, respectively, which is denoted as follows:
Once the test feature vector
is projected using
, the label of
will be assigned to that of the class whose cluster center is closest to the projected
. Note that the small sample size problem [
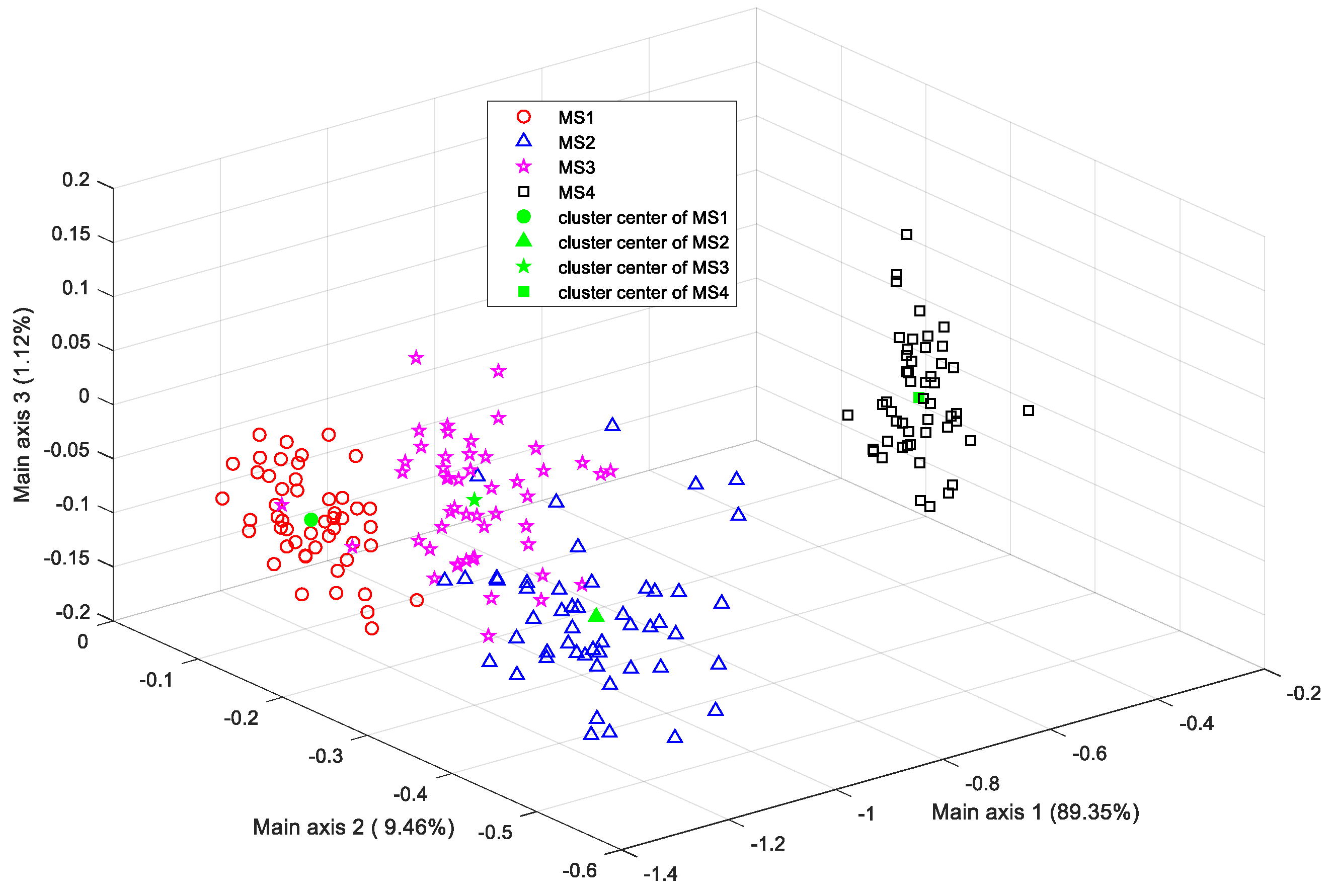
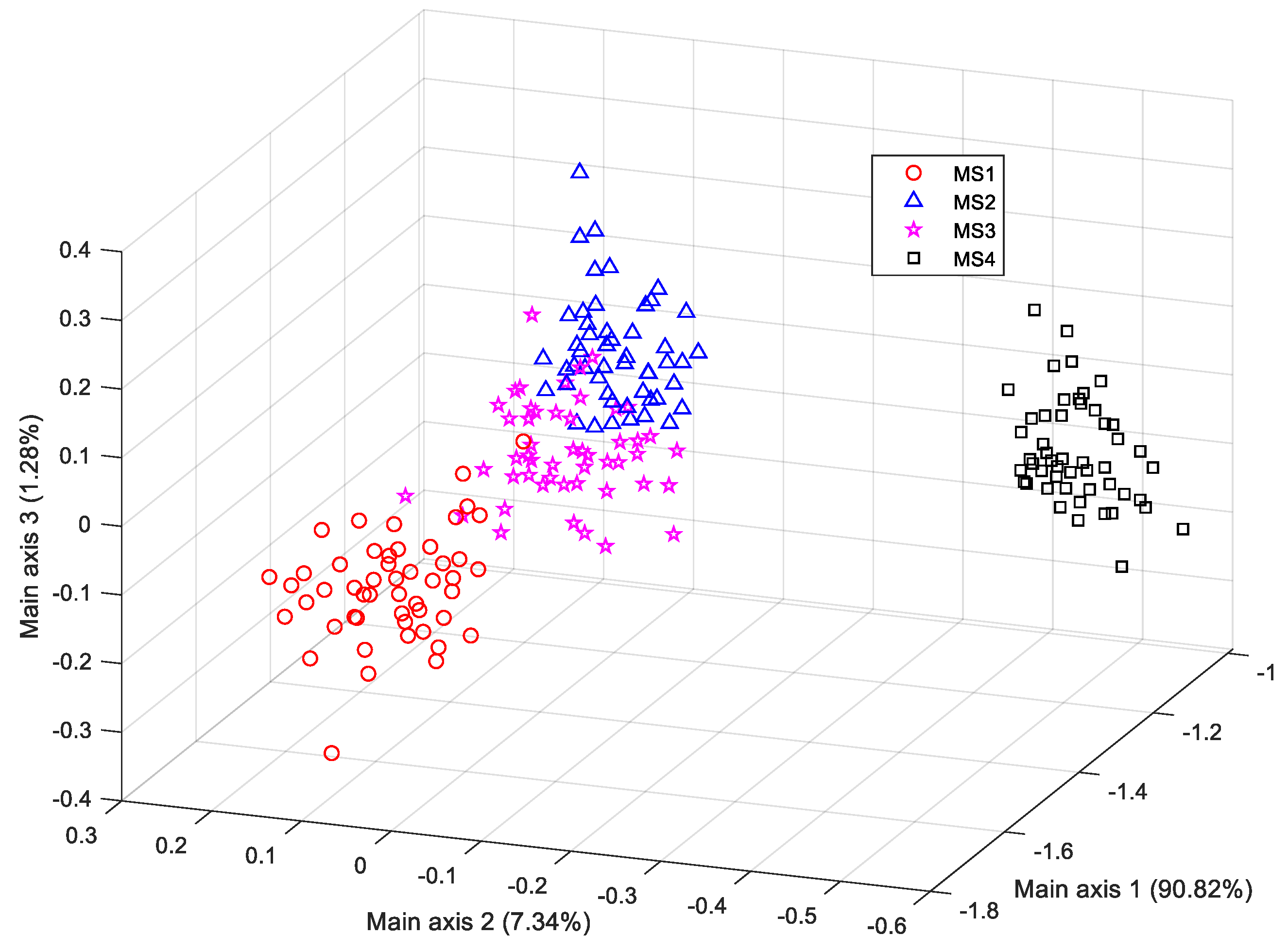
31] would occur if the number of training samples is less than the dimension of the feature vectors, and thus, the objective function indicated by Equation (4) cannot be directly solved. To avoid this problem, when higher-dimensional feature vectors are provided, principal component analysis (PCA) is first adopted to reduce the feature dimension, and then the resultant lower-dimensional feature vectors will be fed to the LDA for classification.
(3) SVM Classifier
The SVM algorithm was first introduced for binary classification task based on structural risk minimization rules [
32]. Suppose that the training dataset
is restricted by the condition
, the SVM aims to find the optimal classification hyperplane by solving the following objection function:
The solution of Equation (7) can be obtained by maximizing its dual form as follows:
where
K(·) is a kernel function. To guarantee a fair comparison between the SVM and LDA classifiers, a linear kernel function was adopted, i.e.,
. The label of the test feature vector
is predicted by the following decision function:
To extend the SVM to multiclass classification task, the one-against-one technique was adopted to model a multiclass SVM classifier.
2.2.4. Evaluation Metrics
The maturity stage identification performance from different combinations of external optical properties and classification algorithms was evaluated using the recall rate (
RR) and the overall accuracy (
OA) metrics, which are defined by:
respectively, where
NMSi is the total number of samples in the
i-th maturity stage in the test dataset and
nMSi is the number of correctly classified samples from the
i-th maturity stage. The
RR is a local evaluation metric indicating how accurately a classifier predicts each class of samples, while the
OA is a global evaluation metric that measures the ratio of the total number of correctly classified samples in the whole test dataset to
NMSi. A combination (e.g., color feature + SVM) of different features and classifiers is regarded as performing better in identifying banana maturity stages when higher values of both its
RR and
OA are achieved. Additionally, 10-fold cross-validation was first adopted using the training dataset to evaluate the training performance on different combinations of features and classifiers, which can help to observe the overfitting phenomenon [
33]. Specifically, all the training samples would be randomly divided into ten disjoint sub-sets, where nine of the sub-sets were used to train different validation models and the remaining one was served as the validation data; note that, each model referred to a combination of one type of feature extraction algorithm and one type of classification algorithm, e.g., color feature + SVM, local texture feature + SVM, local shape feature + SVM, etc., and there were nine different models in total. To reduce the randomness of the samples partitioned in one single cross-validation procedure, the aforementioned 10-fold cross-validation was run 20 times independently for each validation model, in which the average recall rate of the 20 independent runs as well as the corresponding standard deviation were calculated. Furthermore, all the samples in the training dataset were used to train nine different identification models (e.g., color feature + NB, etc.), whose performance of identifying banana maturity stages would be evaluated using the test dataset.

 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}