Location Privacy Protection in Distributed IoT Environments Based on Dynamic Sensor Node Clustering



Abstract
:1. Introduction
2. Related Work
2.1. Privacy of Location in IoT Environments
2.2. User Anonymity and Authentication Privacy in IoT Systems
2.3. Storage System Architectures in IoT
2.4. Traffic Monitoring and Analysis of Privacy Issues in IoT Environments
2.5. Integration of IoT Devices with Cloud Systems
3. IoT Sensor Network Model
- When no message is received within an interval t2 − t1 sec, then I-state of time t2 is computed from the one of t1 by performing a Minkowski sum [32] between the I-state of time t1 and a circle of radius (t2 − t1)∙vmax, where vmax is the maximum velocity that the target object can reach. Intuitively, the I-state expands itself tο include the possibility that the target object may have moved outside the detection range the respective storage node may cover.
- When a storage node receives a message, its I-state is updated to the intersection of the previous I-state with the coverage area of the sensor node posting the message. Thus, the storage node always takes into account the region where the detection message is sent from.
4. Problem Concepts and Definition
4.1. Problem Concepts and Setting
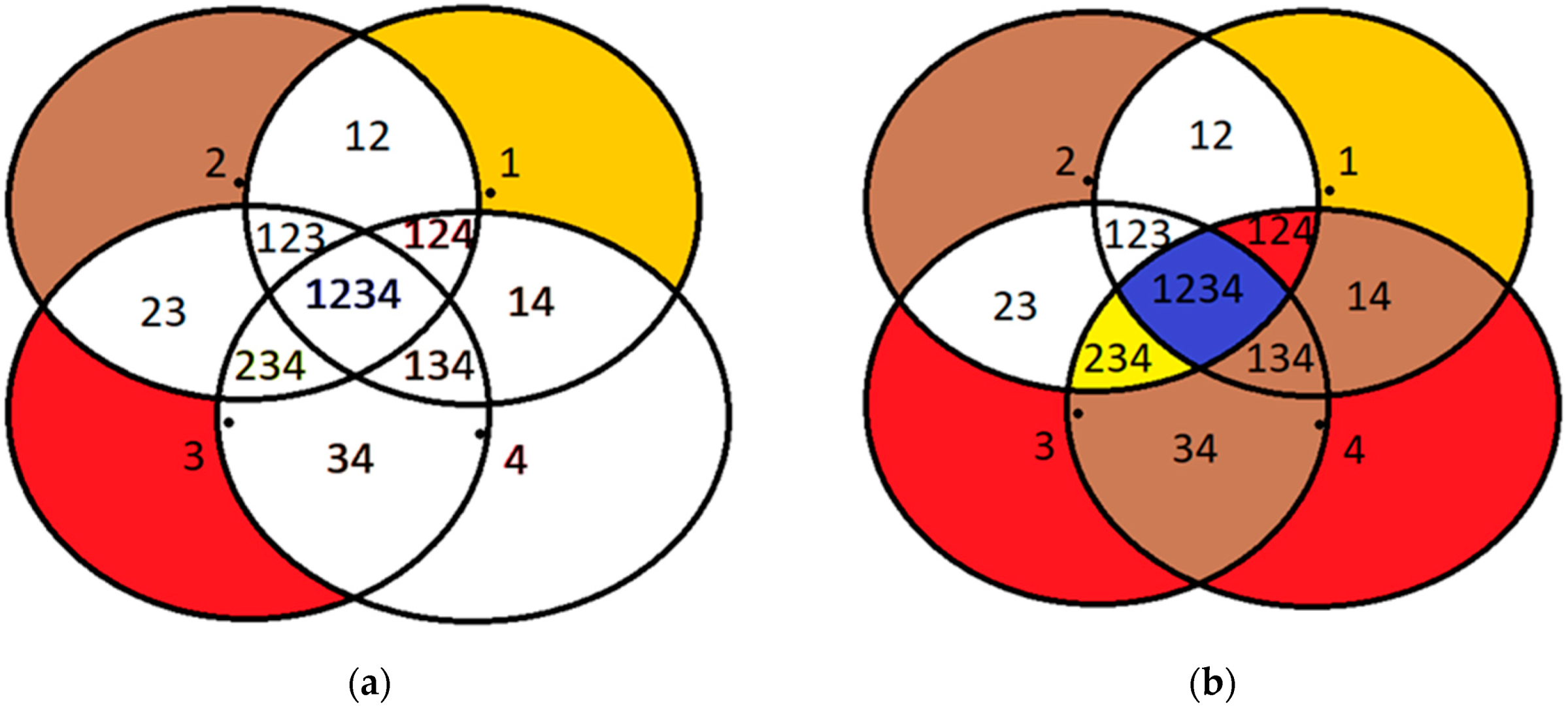
4.2. Evaluation Metrics
4.3. Formal Problem Statement
5. Proposed Solution
5.1. The Dynamic Clustering Algorithm (DCA)
5.1.1. DCA Phase 1: Initial Clustering
5.1.2. DCA Phase 2: Preprocessing Stage
5.1.3. DCA Phase 3: Dynamic Allocation
| Dynamic Clustering Algorithm (DCA). |
| Input: K: minimum number of clusters for which there are no conflicts i: indicates the sensor node that executes the algorithm size[k1, k2, …, kK]: the population of nodes that each cluster includes Cluster[C1, C2, …, Cn]: for each of the n sensor nodes it indicates the number of clusters the respective sensor belongs to m: indicates the number of expected cluster population DDist[(a, b), (a, c)…, (d, w)]: Pairs of nodes positioned in dangerous distance range Output: Clustering that is adapted according to the target position 1: sorting (size) //sorting clusters by size #1st phase: 2: If strategy = ”direct”: 3: If Cluster[i] <= m: Continue 4: Else: Cluster[i] = m + 1 5: Else if strategy = ”selective”: 6: For each link ∈ DDist: 7: t1 = link[0] 8: t2 = link[1] 9: If Cluster[t1] = Cluster[t2]: Cluster[t1] = m + 1 10: Else: 11: Steps 6–9 //hybrid 12: Steps 3–4 #2nd phase: 13: If cluster[i] = m + 1: 14: d = 0 15: For each link ∈ Nbr: //each sensor knows its neighbors 16: If Cluster[link] is not used from neighbors: 17: d = d + 1 18: If d < m: 19: Choose an unused cluster number #3rd phase: #Input: #target: position of mobile target at time t #counters[q1, q2, …, qn]: counting how many sensor nodes send data to specific storage node 20: If |target-xi| <= rd: 21: If Cluster[i] < m+1: 22: Send message to corresponding server 23: For each xi ∈ Nd:{C(xi) = m+1}: 24: If it is the beginning of detection: 25: Send message of interest to xi 26: If it is the end of detection: 27: Send message of not interest to xi 28: Else: 29: For each xi ∈ Nd: 30: d = 0 31: If cluster number is unused: 32: d = d + 1 33: If d < n: 34: Choose one of the rest 35: Else: 36: index = min(counters) // server which is least used 37: Send message to corresponding server |
5.2. Advantages of the DCA
5.3. Generalisation to Address Multiple Mobile Objects
6. Experiments and Evaluation
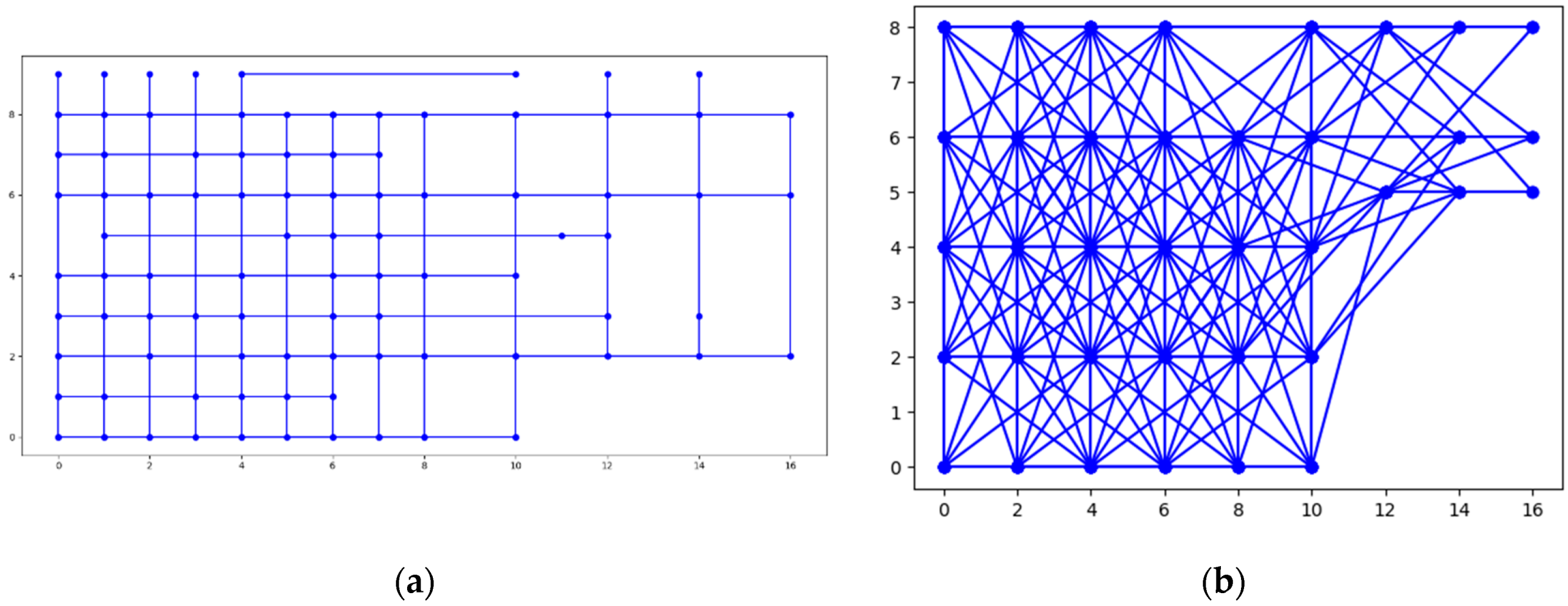
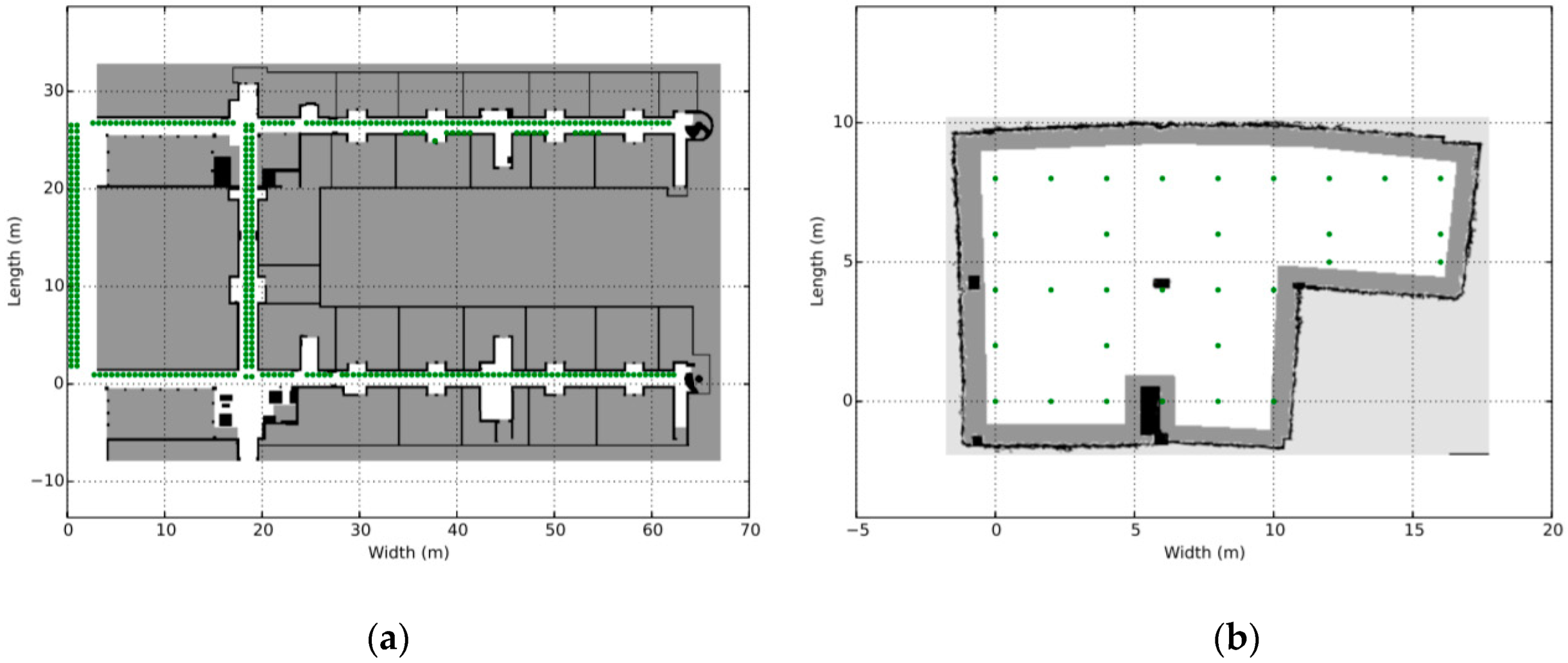
6.1. Experiments’ Setting
6.2. Experiments’ Execution
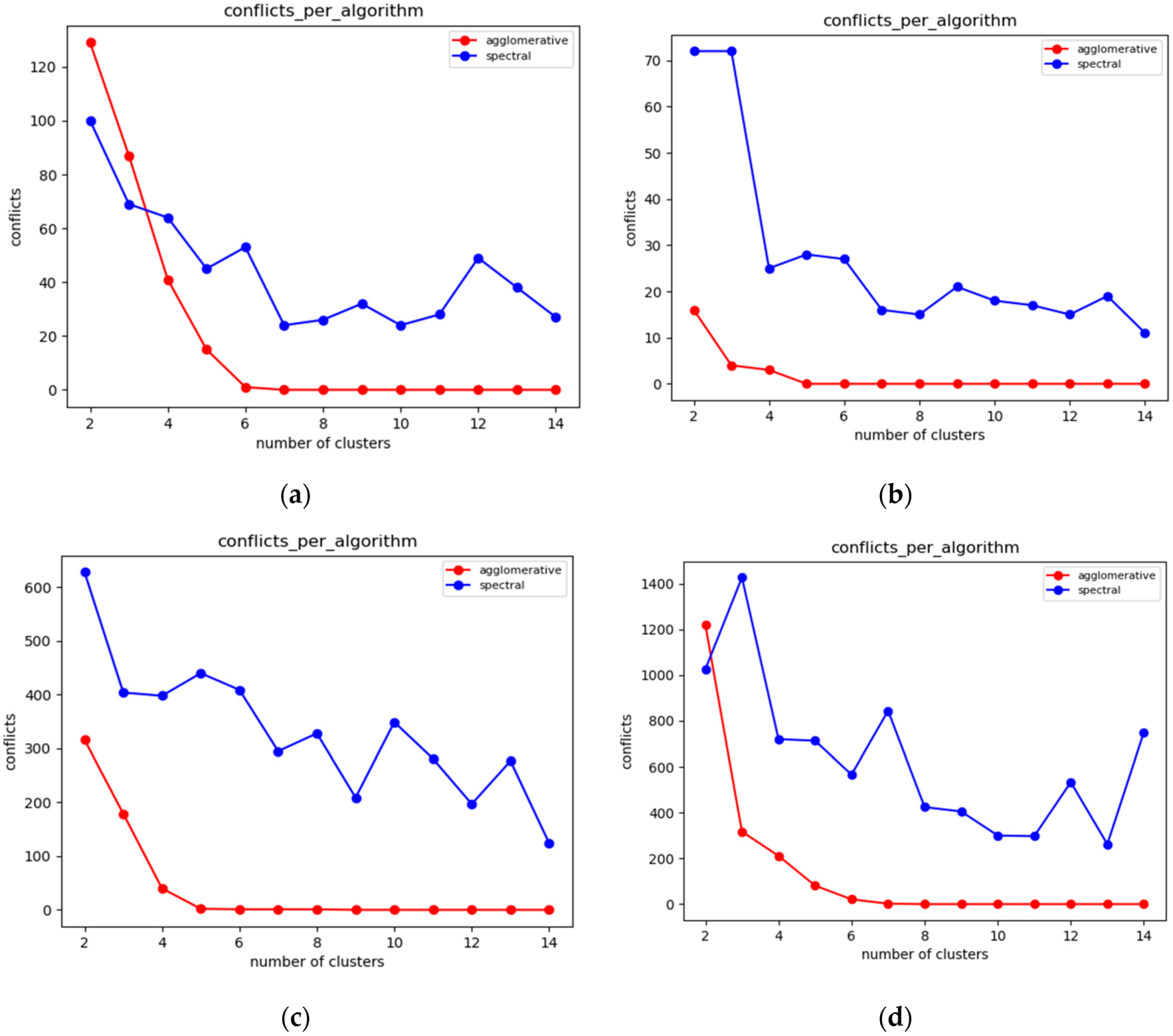
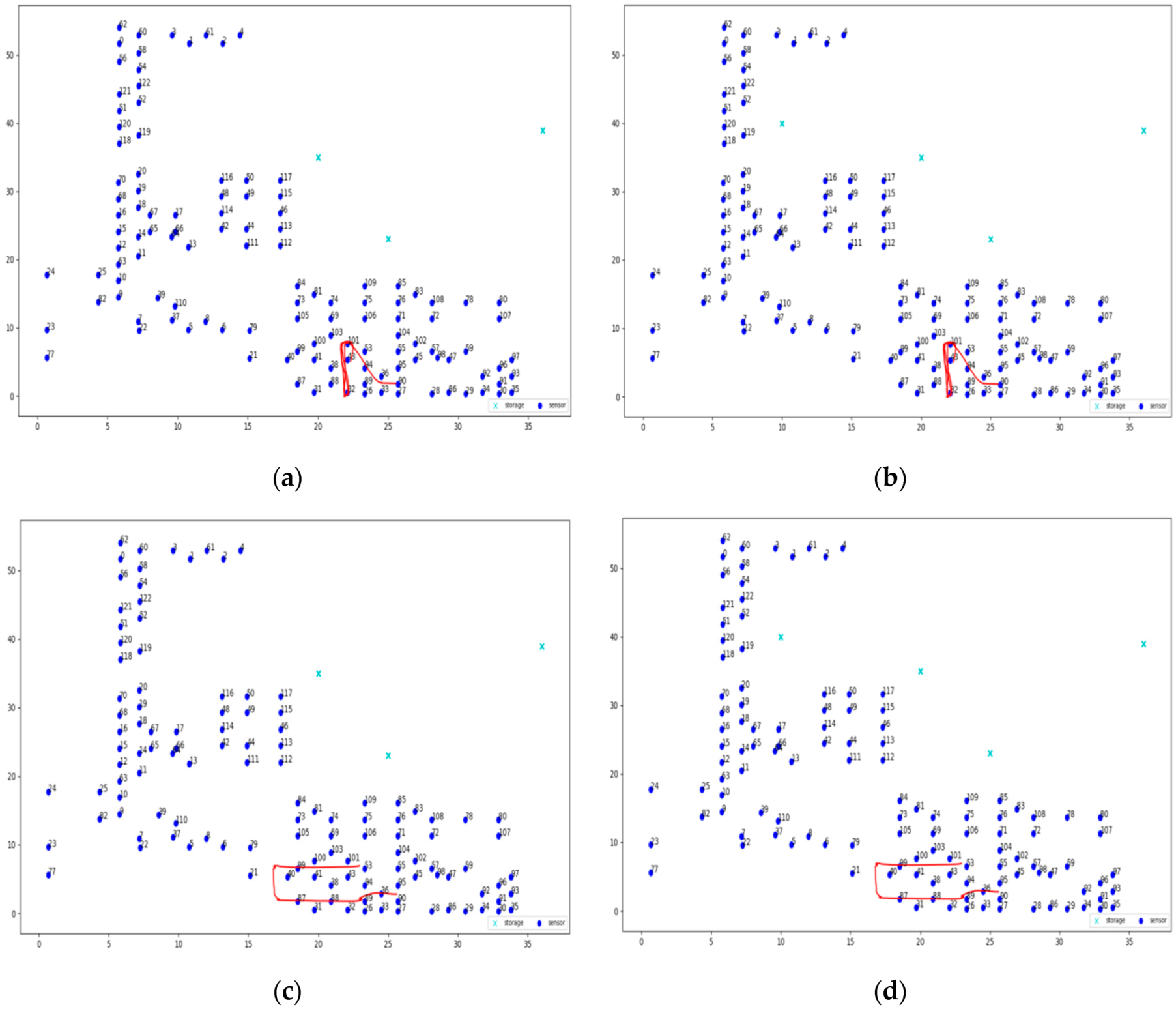
6.3. Static Clustering Evaluation
6.3.1. Experiments over 37 Node Topology
6.3.2. Experiments over 100 Node Topology
6.3.3. Experiments over 123 Node Topology
6.3.4. Overall Evaluation Results
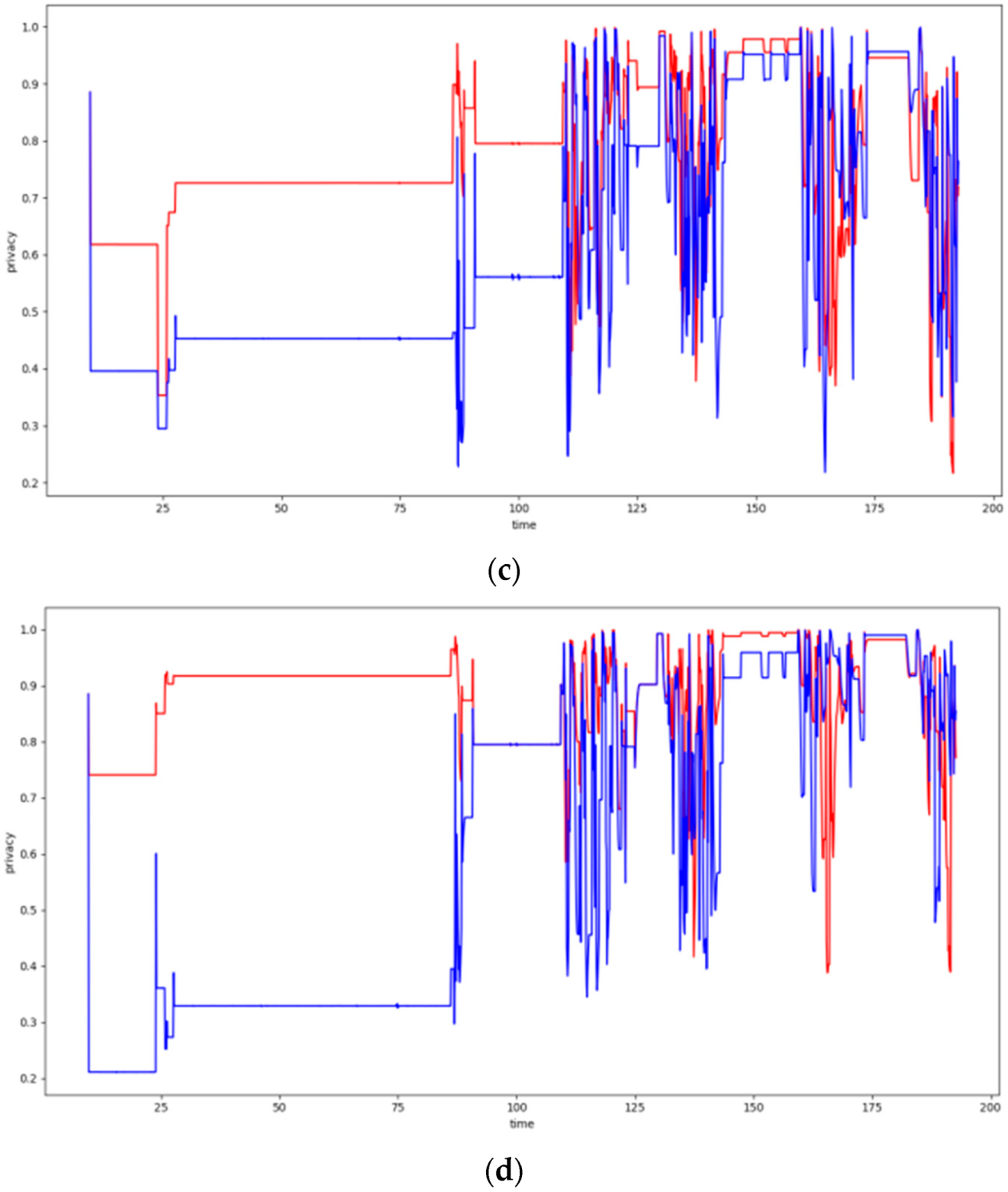
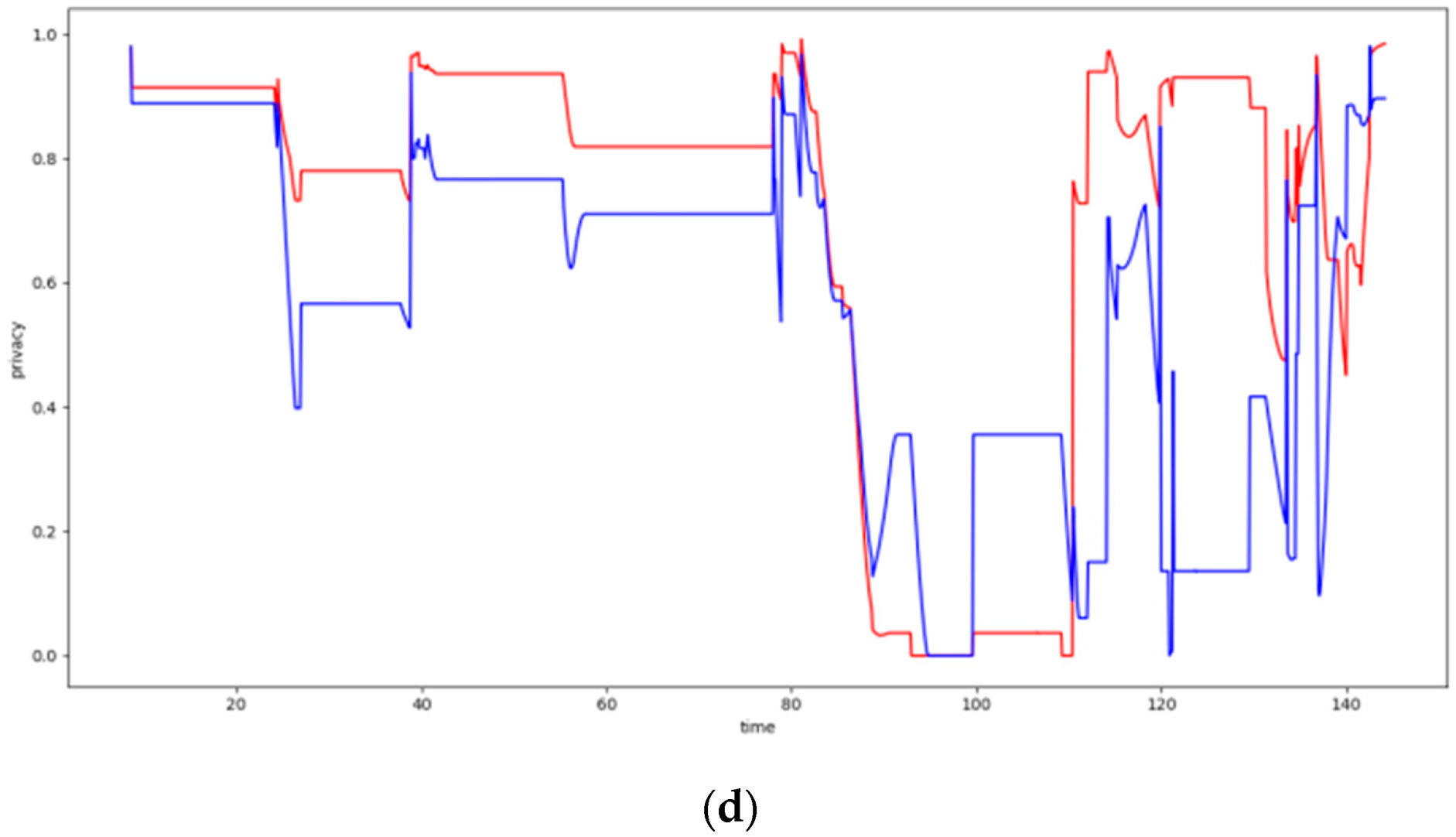
6.4. Dynamic Clustering Evaluation
6.4.1. Experiments over 37 Node Topology
6.4.2. Experiments over 100 Node Topology
6.4.3. Experiments over 123 Node Topology
6.4.4. Overall Evaluation Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Lee, I.; Lee, K. The Internet of Things (IoT): Applications, Investments, and Challenges for Enterprises, Business Horizons; Elsevier: Amsterdam, The Netherlands, 2015; Volume 58, pp. 431–440. ISSN 0007-6813. [Google Scholar]
- Miao, X.; Wenyuan, X.; O’Kane, J.M. Privacy Preservation Data Dissemination. In Security and Privacy in Internet of Things (IoTs): Models, Algorithms, and Implementations; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Zia, Q. A Survey of Data-Centric Protocols for Wireless Sensor Networks. In Computer Science Systems Biology; OMICS Publishing Group: Hyderabad, India, 2015; Volume 8, pp. 127–131. [Google Scholar]
- Chan, H.; Perrig, A. Security and privacy in sensor networks. IEEE Comput. 2003, 36, 103–105. [Google Scholar] [CrossRef]
- Perrig, A.; Szewczyk, R.; Tygar, J.D.; Wen, V.; Culler, D.E. SPINS: Security protocols for sensor networks. Wirel. Netw. 2002, 8, 521–534. [Google Scholar] [CrossRef]
- Lopez, J.; Rios, R.; Bao, F.; Wang, G. Evolving privacy: From sensors to the Internet of Things. Future Gener. Comput. Syst. 2017, 75, 46–57. [Google Scholar] [CrossRef]
- Chen, L.; Thombre, S.; Järvinen, K.; Lohan, E.S.; Alén-Savikko, A.; Leppäkoski, H.; Bu-Pasha, S.; Bhuiyan, M.Z.H.; Kuusniemi, H.; Korpisaari, P.; et al. Robustness, security and privacy in location-based services for future IoT: A survey. IEEE Access 2017, 5, 8956–8977. [Google Scholar] [CrossRef]
- Lin, H.; Bergmann, N. IoT privacy and security challenges for smart home environments. Information 2016, 7, 44. [Google Scholar] [CrossRef]
- Peng, T.; Liu, Q.; Meng, D.; Wang, G. Collaborative trajectory privacy preserving scheme in location-based services. Inf. Sci. 2017, 387, 165–179. [Google Scholar] [CrossRef]
- Liao, D.; Li, H.; Sun, G.; Zhang, M.; Chang, V. Location and trajectory privacy preservation in 5G-Enabled vehicle social network services. J. Netw. Comput. Appl. 2018, 110, 108–118. [Google Scholar] [CrossRef]
- Ma, T.; Jia, J.; Xue, Y.; Tian, Y.; Al-Dhelaan, A.; Al-Rodhaan, M. Protection of location privacy for moving kNN queries in social networks. Appl. Soft Comput. 2018, 66, 525–532. [Google Scholar] [CrossRef]
- Hashem, T.; Kulik, L.; Zhang, R. Privacy preserving group nearest neighbor queries. In Proceedings of the 13th International Conference on Extending Database Technology, Lausanne, Switzerland, 22–26 March 2010; pp. 489–500. [Google Scholar]
- Sun, G.; Liao, D.; Li, H.; Yu, H.; Chang, V. L2P2: A location-label based approach for privacy preserving in LBS. Future Gener. Comput. Syst. 2017, 74, 375–384. [Google Scholar] [CrossRef]
- Niu, B.; Li, Q.; Zhu, X.; Cao, G.; Li, H. Achieving k-anonymity in privacy-aware location-based services. In Proceedings of the IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 754–762. [Google Scholar]
- Sun, G.; Chang, V.; Ramachandran, M.; Sun, Z.; Li, G.; Yu, H.; Liao, D. Efficient location privacy algorithm for Internet of Things (IoT) services and applications. J. Netw. Comput. Appl. 2017, 89, 3–13. [Google Scholar] [CrossRef]
- González-Manzano, L.; de Fuentes, J.M.; Pastrana, S.; Peris-Lopez, P.; Hernández-Encinas, L. PAgIoT–Privacy-preserving aggregation protocol for Internet of Things. J. Netw. Comput. Appl. 2016, 71, 59–71. [Google Scholar] [CrossRef]
- Bettini, C.; Mascetti, S.; Wang, X.S.; Jajodia, S. Anonymity in location-based services: Towards a general framework. In Proceedings of the International Conference on Mobile Data Management, Mannheim, Germany, 7–11 May 2007; pp. 69–76. [Google Scholar]
- Lin, X.J.; Sun, L.; Qu, H. Insecurity of an anonymous authentication for privacy-preserving IoT target-driven applications. Comput. Secur. 2015, 48, 142–149. [Google Scholar] [CrossRef] [Green Version]
- Alcaide, A.; Palomar, E.; Montero-Castillo, J.; Ribagorda, A. Anonymous authentication for privacy-preserving IoT target-driven applications. Comput. Secur. 2013, 37, 111–123. [Google Scholar] [CrossRef]
- Elkhodr, M.; Shahrestani, S.; Cheung, H. A contextual-adaptive location disclosure agent for general devices in the internet of things. In Proceedings of the 38th Annual IEEE Conference on Local Computer Networks-Workshops, Sydney, Australia, 21–24 October 2013; pp. 848–855. [Google Scholar]
- Yick, J.; Mukherjee, B.; Ghosal, D. Wireless sensor network survey. Comput. Netw. 2008, 52, 2292–2330. [Google Scholar] [CrossRef]
- Kotla, R.; Alvisi, L.; Dahlin, M. Safestore: A durable and practical storage system. In Proceedings of the USENIX Annual Technical Conference, Santa Clara, CA, USA, 17–22 June 2007; pp. 7–20. [Google Scholar]
- Ganger, G.; Khosla, P.; Bakkaloglu, M.; Bigrigg, M.; Goodson, G.; Oguz, S.; Pandurangan, V.; Soules, C.; Strunk, J.; Wylie, J. Survivable storage systems. In Proceedings of the DARPA Information Survivability Conference and Exposition, Anaheim, CA, USA, 12–14 June 2001; Volume 2, pp. 184–195. [Google Scholar]
- Yang, Y.; Shao, M.; Zhu, S.; Urgaonkar, B.; Cao, G. Towards event source unobservability with minimum network traffic in sensor networks. In Proceedings of the Conference on Wireless Network Security (WiSec), Alexandria, VA, USA, 31 March–2 April 2008; pp. 77–88. [Google Scholar]
- Kamat, P.; Zhang, Y.; Trappe, W.; Ozturk, C. Enhancing source-location privacy in sensor network routing. In Proceedings of the 25th IEEE International Conference on Distributed Computing Systems (ICDCS’05), Columbus, OH, USA, 6–10 June 2005; pp. 599–608. [Google Scholar]
- Mehta, Κ.; Liu, D.; Wright, M. Location privacy in sensor networks against a global eavesdropper. In Proceedings of the Conference on Network Protocols (ICNP), Beijing, China, 16–19 October 2007; pp. 314–323. [Google Scholar]
- Deng, J.; Han, R.; Mishra, S. Intrusion tolerance and anti-traffic analysis strategies for wireless sensor networks. In Proceedings of the International Conference on Dependable Systems and Networks, Florence, Italy, 28 June–1 July 2004; pp. 637–646. [Google Scholar]
- Shao, M.; Zhu, S.; Zhang, W.; Cao, G.; Yang, Y. pDCS: Security and privacy support for data-centric sensor networks. IEEE Trans. Mob. Comput. 2009, 8, 1023–1038. [Google Scholar] [CrossRef]
- Stergiou, C.; Psannis, K.E.; Kim, B.G.; Gupta, B. Secure integration of IoT and cloud computing. Future Gener. Comput. Syst. 2018, 78, 964–975. [Google Scholar] [CrossRef]
- Henze, M.; Hermerschmidt, L.; Kerpen, D.; Häußling, R.; Rumpe, B.; Wehrle, K. A comprehensive approach to privacy in the cloud-based Internet of Things. Future Gener. Comput. Syst. 2016, 56, 701–718. [Google Scholar] [CrossRef] [Green Version]
- Fu, Z.J.; Shu, J.G.; Wang, J.; Liu, Y.L.; Lee, S.Y. Privacy-preserving smart similarity search based on simhash over encrypted data in cloud computing. J. Internet Technol. 2015, 16, 453–460. [Google Scholar]
- Varadhan, G.; Manocha, D. Accurate Minkowski sum approximation of polyhedral models. In Proceedings of the 12th IEEE Pacific Conference on Computer Graphics and Applications, Seoul, South Korea, 6–8 October 2004; pp. 392–401. [Google Scholar]
- Pawar, S.; El Rouayheb, S.; Ramchandran, K. On secure distributed data storage under repair dynamics. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 122–18 June 2010; pp. 2543–2547. [Google Scholar]
- Balas, E.; Xue, J. Weighted and unweighted maximum clique algorithms with upper bounds from fractional coloring. Algorithmica 1996, 15, 397–412. [Google Scholar] [CrossRef]
- Matsui, T. Approximation algorithms for maximum independent set problems and fractional coloring problems on unit disk graphs. In Proceedings of the Japanese Conference on Discrete and Computational Geometry, Tokyo, Japan, 9–12 December 1998; pp. 194–200. [Google Scholar]
- Jensen, T.R.; Toft, B. Graph Coloring Problems (Wiley Series in Discrete Mathematics and Optimization); John Wiley & Sons: New York, NY, USA, 2011; Volume 39. [Google Scholar]
- Kierstead, H.A. A simple competitive graph coloring algorithm. J. Comb. Theoryseries 2000, 78, 57–68. [Google Scholar] [CrossRef]
- Leighton, F.T. A graph coloring algorithm for large scheduling problems. J. Res. Natl. Bur. Stand. 1979, 84, 489–506. [Google Scholar] [CrossRef]
- Ares Brea, M.E. Constrained Clustering Algorithms: Practical Issues and Applications. Ph.D. Thesis, Universidade da Coruña, A Coruña, Spain, 2013. [Google Scholar]
- Bair, E. Semi-supervised clustering methods. Wiley Interdiscip. Rev. Comput. Stat. 2013, 5, 349–361. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adjih, C.; Baccelli, E.; Fleury, E.; Harter, G.; Mitton, N.; Noel, T.; Pissard-Gibollet, R.; Saint-Marcel, F.; Schreiner, G.; Vandaele, J.; et al. FIT IoT-LAB: A large scale open experimental IoT testbed. In Proceedings of the 2nd IEEE World Forum on Internet of Things (WF-IoT), Milan, Italy, 14–16 December 2015; pp. 459–464. [Google Scholar]
- Fleury, E.; Mitton, N.; Noel, T.; Adjih, C. FIT IoT-LAB: The largest IoT open experimental testbed. Ercim News 2015, 101, 4. [Google Scholar]
- Fambon, O.; Fleury, E.; Harter, G.; Pissard-Gibollet, R.; Saint-Marcel, F. FIT IoT-LAB tutorial: Hands-on practice with a very large scale testbed tool for the Internet of Things. In Proceedings of the 10èmes Journées Francophones Mobilité et Ubiquité (UbiMob2014), Sophia-Antipolis, France, 5–6 June 2014. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–19 May 2009; Volume 3. [Google Scholar]
- Brooks, R. A robust layered control system for a mobile robot. IEEE J. Robot. Autom. 1986, 2, 14–23. [Google Scholar] [CrossRef] [Green Version]
- Gerkey, B.; Vaughan, R.T.; Howard, A. The player/stage project: Tools for multi-robot and distributed sensor systems. In Proceedings of the 11th International Conference on Advanced Robotics, Coimbra, Portugal, 30 June–3 July 2003; Volume 1, pp. 317–323. [Google Scholar]
- Papadopoulos, G.Z.; Gallais, A.; Schreiner, G.; Jou, E.; Noel, T. Thorough IoT testbed characterization: From proof-of-concept to repeatable experimentations. Comput. Netw. 2017, 119, 86–101. [Google Scholar] [CrossRef] [Green Version]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Privacy | square_1 | h_line_2 |
|---|---|---|
| 2 storage nodes | 0.1643 | 0.5108 |
| 3 storage nodes | 0.3489 | 0.7018 |
| Average Privacy | square_1 | h_line_2 |
|---|---|---|
| 2 storage nodes | 0.3830 | 0.7180 |
| 3 storage nodes | 0.4108 | 0.7898 |
| Average Privacy | square_1_plus | h_line_2 |
|---|---|---|
| 2 storage nodes | - | 0.6088 |
| 3 storage nodes | 0.8477 | 0.6084 |
| 4 storage nodes | 0.7917 | - |
| Average Privacy | square_1_plus | h_line_2 |
|---|---|---|
| 2 storage nodes | - | 0.7707 |
| 3 storage nodes | 0.9135 | 0.8817 |
| 4 storage nodes | 0.9248 | - |
| Average Privacy | square_1 | v_line_5 |
|---|---|---|
| 3 storage nodes | 0.5608 | 0.5708 |
| 4 storage nodes | 0.5978 | 0. 6877 |
| Average Privacy | square_1 | v_line_5 |
|---|---|---|
| 3 storage nodes | 0.7039 | 0.7289 |
| 4 storage nodes | 0.7046 | 0.7989 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dimitriou, K.; Roussaki, I. Location Privacy Protection in Distributed IoT Environments Based on Dynamic Sensor Node Clustering. Sensors 2019, 19, 3022. https://doi.org/10.3390/s19133022
Dimitriou K, Roussaki I. Location Privacy Protection in Distributed IoT Environments Based on Dynamic Sensor Node Clustering. Sensors. 2019; 19(13):3022. https://doi.org/10.3390/s19133022
Chicago/Turabian StyleDimitriou, Konstantinos, and Ioanna Roussaki. 2019. "Location Privacy Protection in Distributed IoT Environments Based on Dynamic Sensor Node Clustering" Sensors 19, no. 13: 3022. https://doi.org/10.3390/s19133022
APA StyleDimitriou, K., & Roussaki, I. (2019). Location Privacy Protection in Distributed IoT Environments Based on Dynamic Sensor Node Clustering. Sensors, 19(13), 3022. https://doi.org/10.3390/s19133022