Figure 1.
Comparison of images at non-operational and operational period: (a) railway intrusion sample at night; (b) images in operational period.
Figure 1.
Comparison of images at non-operational and operational period: (a) railway intrusion sample at night; (b) images in operational period.
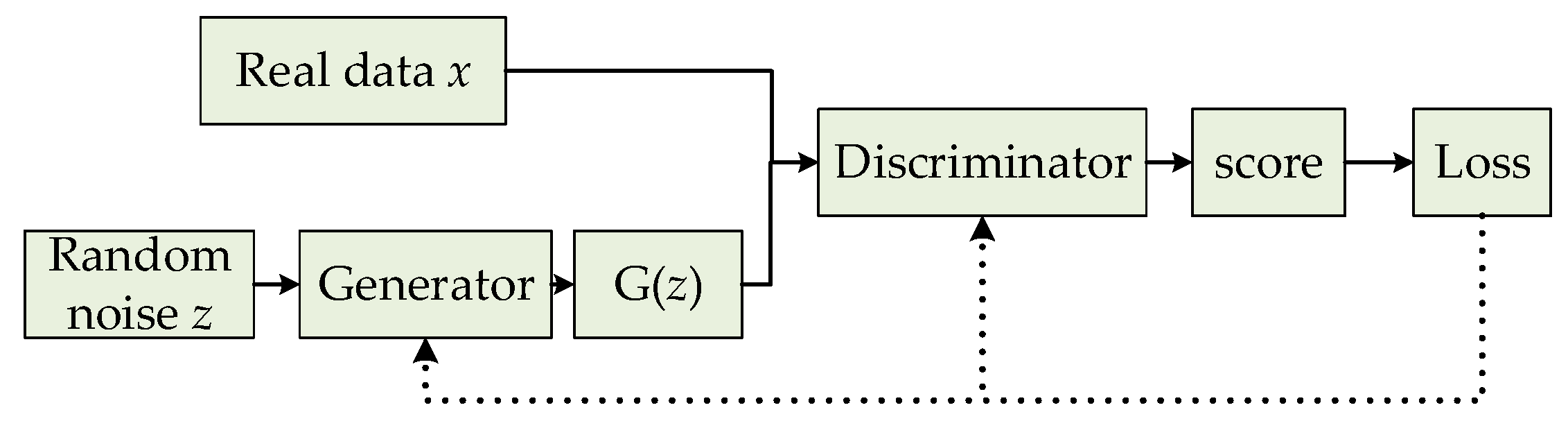
Figure 2.
Basic framework of generative adversarial networks (GAN).
Figure 2.
Basic framework of generative adversarial networks (GAN).
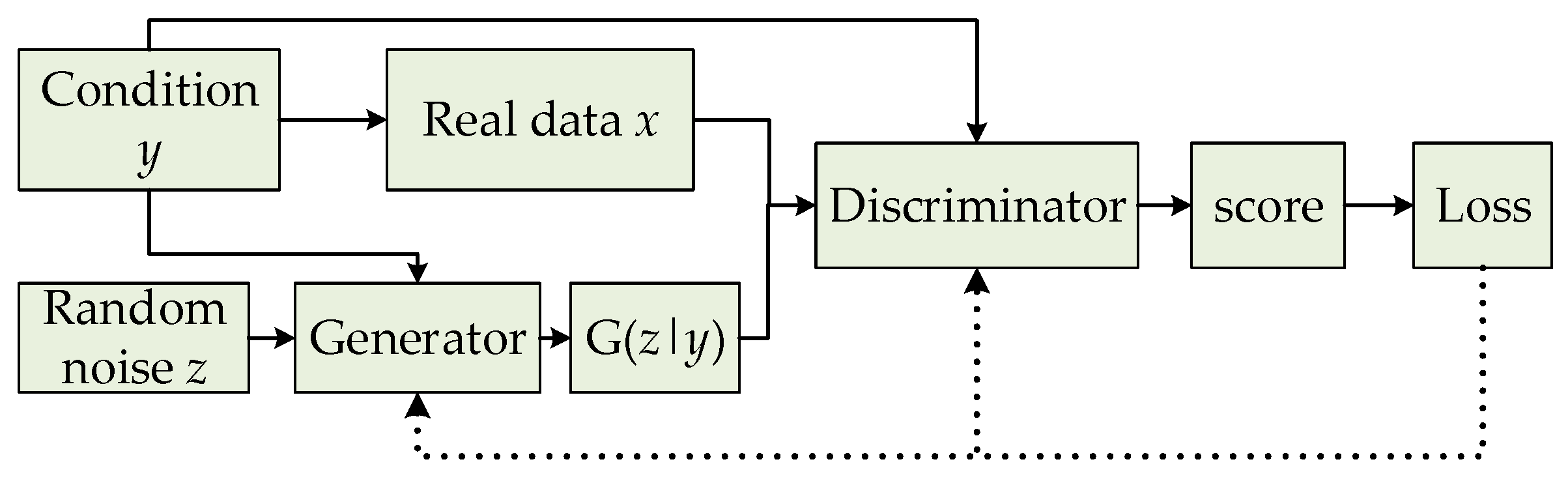
Figure 3.
Basic framework of conditional GAN (CGAN).
Figure 3.
Basic framework of conditional GAN (CGAN).
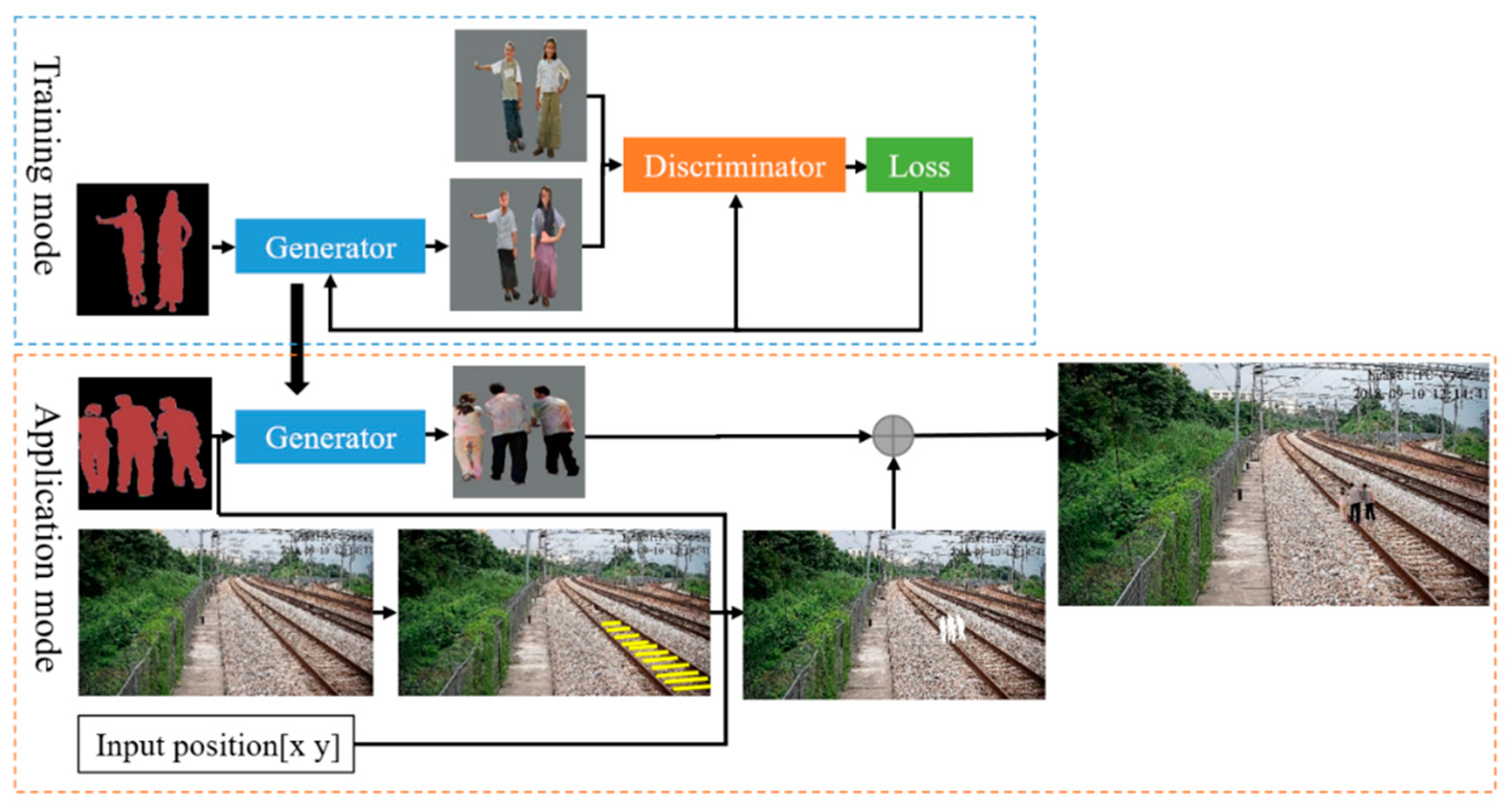
Figure 4.
Overview of the railway intruding object image generating algorithm. The conditional deep convolutional GAN (C-DCGAN) model is first trained with image pairs of semantic labels and real images. For application, the trained generator is used to translate the semantic labels to various real images. The semantic image is also used to segment the objects’ contours in the railway scene. After the object scale size is calculated at the position, the generated intruding object is synthesized to the railway scene.
Figure 4.
Overview of the railway intruding object image generating algorithm. The conditional deep convolutional GAN (C-DCGAN) model is first trained with image pairs of semantic labels and real images. For application, the trained generator is used to translate the semantic labels to various real images. The semantic image is also used to segment the objects’ contours in the railway scene. After the object scale size is calculated at the position, the generated intruding object is synthesized to the railway scene.
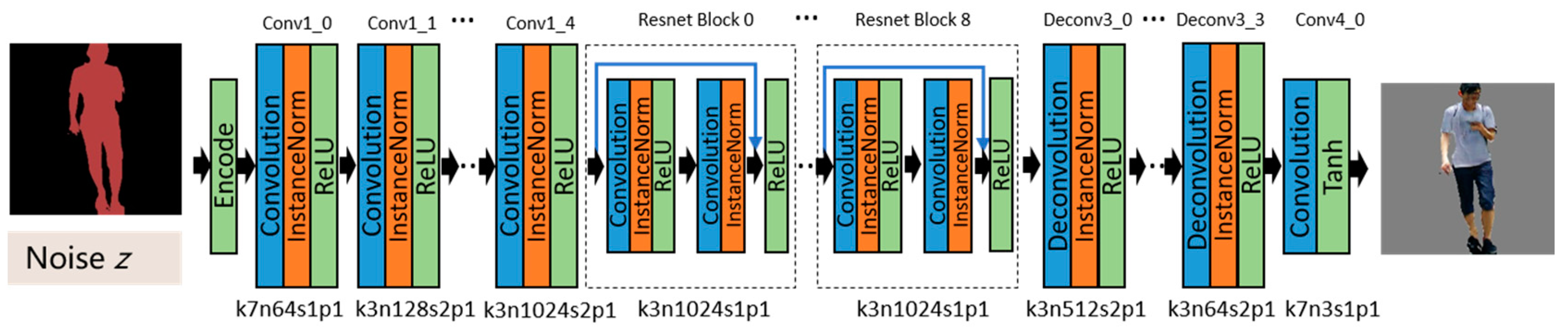
Figure 5.
Architecture of the generator network with the corresponding kernel size (k), number of feature maps (n), stride (s), and padding (p) indicated for each layer. Convolution is used to extract the features. The features are transformed from the semantic domain to the real one in the ResNet blocks. Low-level features are restored with the deconvolution, and the real image is ultimately generated.
Figure 5.
Architecture of the generator network with the corresponding kernel size (k), number of feature maps (n), stride (s), and padding (p) indicated for each layer. Convolution is used to extract the features. The features are transformed from the semantic domain to the real one in the ResNet blocks. Low-level features are restored with the deconvolution, and the real image is ultimately generated.
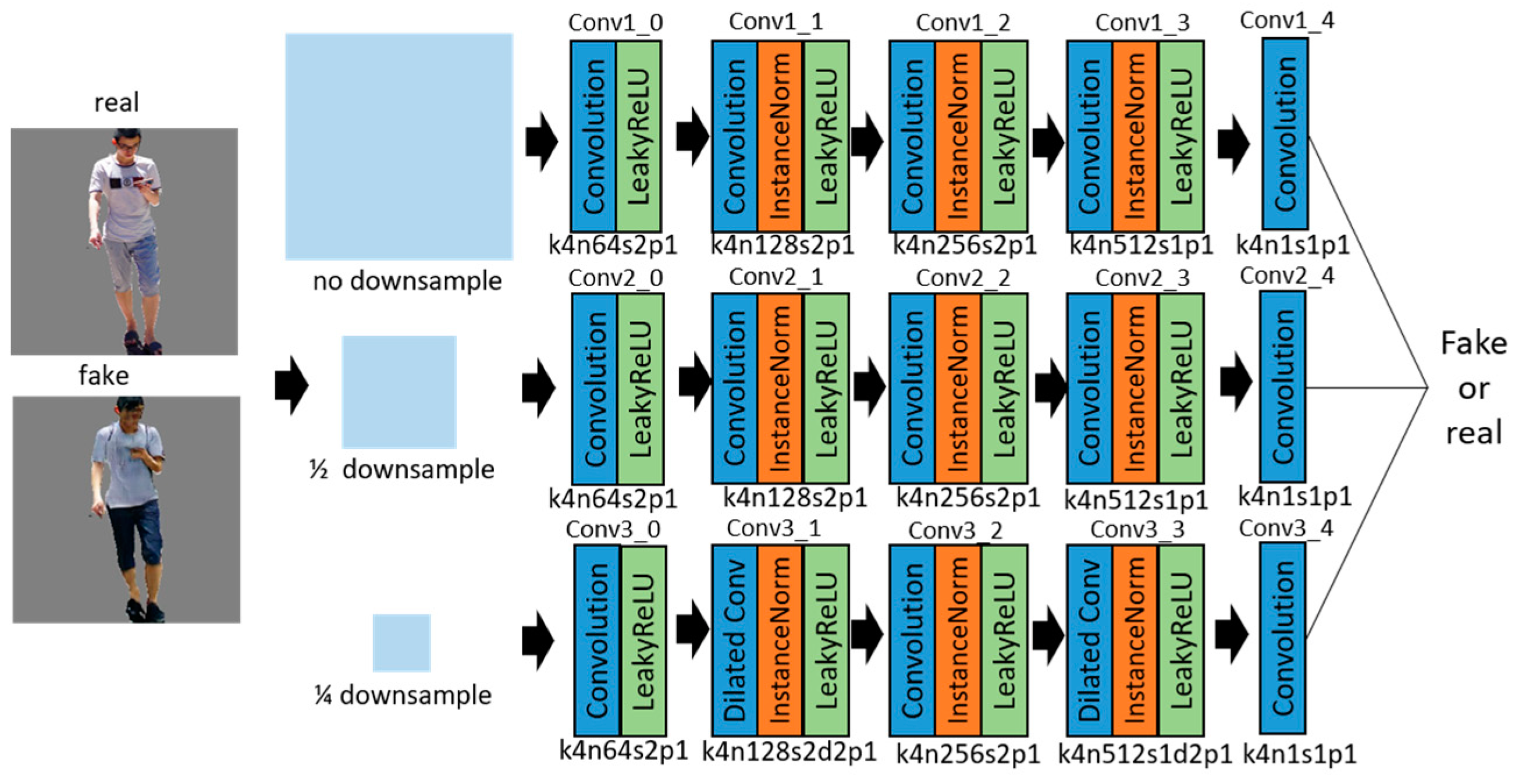
Figure 6.
Multi-scale discriminators network with the corresponding kernel size (k), number of feature maps (n), stride (s), and padding (p) indicated for each layer.
Figure 6.
Multi-scale discriminators network with the corresponding kernel size (k), number of feature maps (n), stride (s), and padding (p) indicated for each layer.
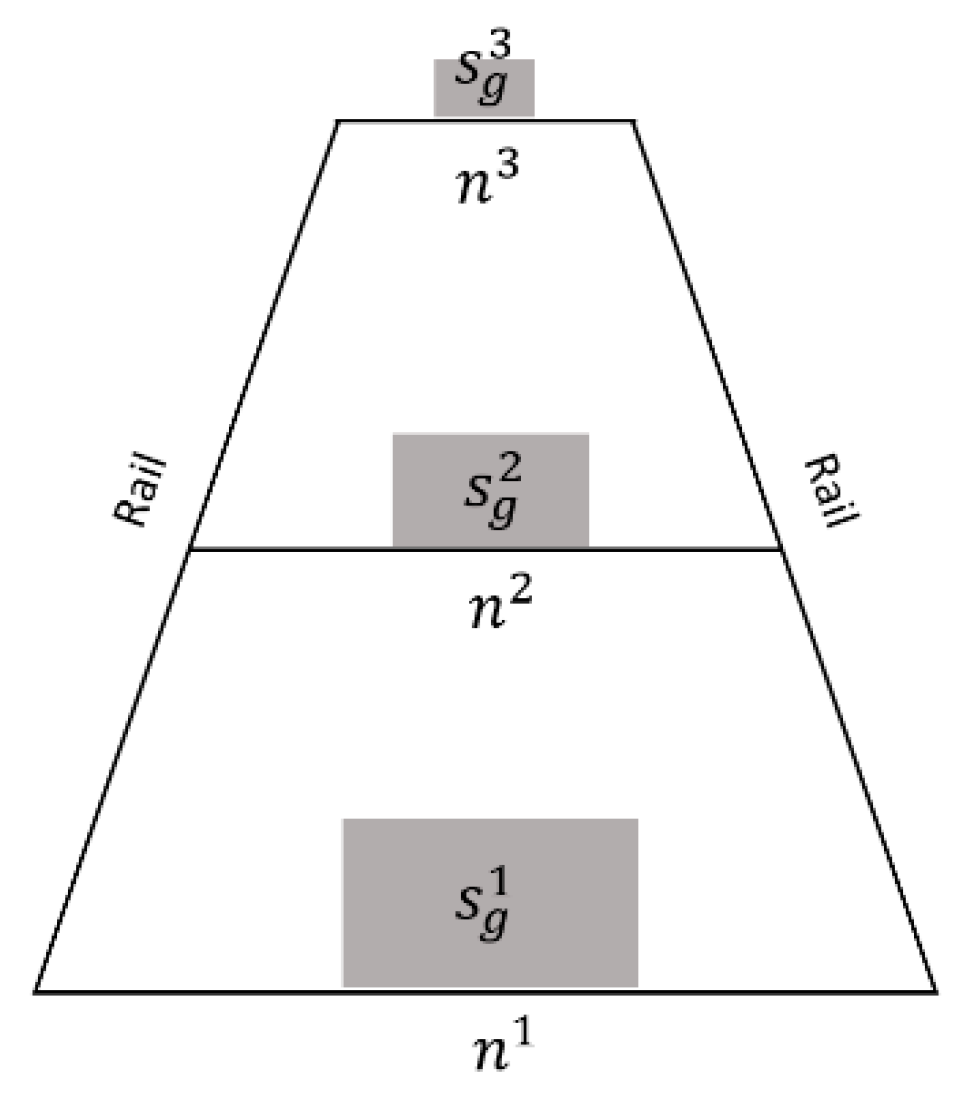
Figure 7.
Scale size estimation based on the gauge constant. n1, n2, and n3 represent the pixel numbers between two rails at different positions. With the invariant s/g, the pixel numbers of the generated objects at different positions of sg1, sg2, and sg3 can be calculated when n1, n2, and n3 are detected.
Figure 7.
Scale size estimation based on the gauge constant. n1, n2, and n3 represent the pixel numbers between two rails at different positions. With the invariant s/g, the pixel numbers of the generated objects at different positions of sg1, sg2, and sg3 can be calculated when n1, n2, and n3 are detected.
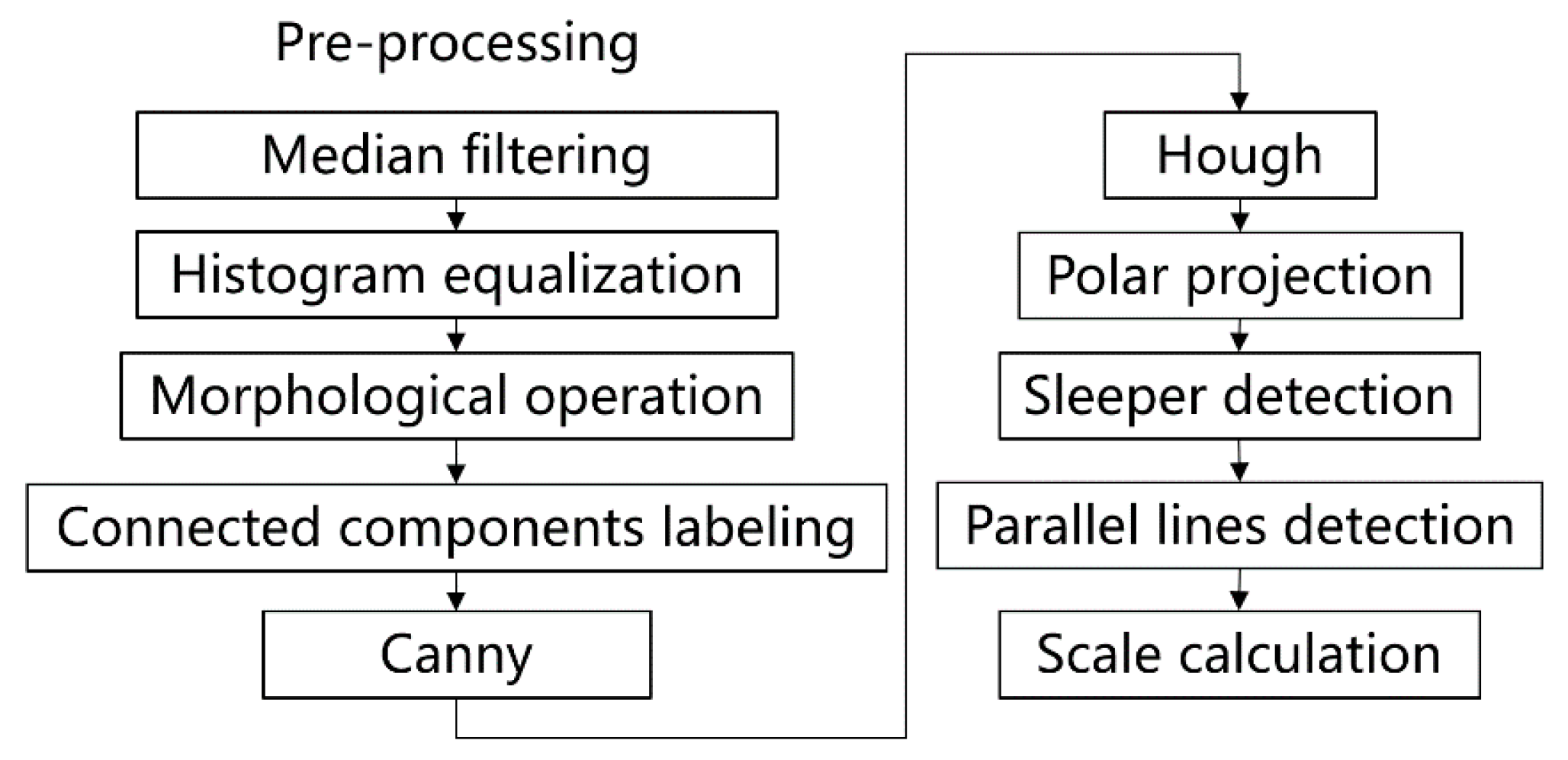
Figure 8.
Overview of the generated object size estimation algorithm. The rail line features are highlighted with the pre-processing, including median filtering, histogram equalization, morphological operation, and connected components labeling. Then, the edges are extracted by the Canny. The rail lines are detected by Hough based on polar projection. Parallel sleepers are also detected for the scale size calculation.
Figure 8.
Overview of the generated object size estimation algorithm. The rail line features are highlighted with the pre-processing, including median filtering, histogram equalization, morphological operation, and connected components labeling. Then, the edges are extracted by the Canny. The rail lines are detected by Hough based on polar projection. Parallel sleepers are also detected for the scale size calculation.
Figure 9.
Railway scene image pre-processing: (a) original railway scene; (b) median filtered and binarization; (c) dilation; (d) erosion; (e) eight-connected components labeling; (f) Canny.
Figure 9.
Railway scene image pre-processing: (a) original railway scene; (b) median filtered and binarization; (c) dilation; (d) erosion; (e) eight-connected components labeling; (f) Canny.
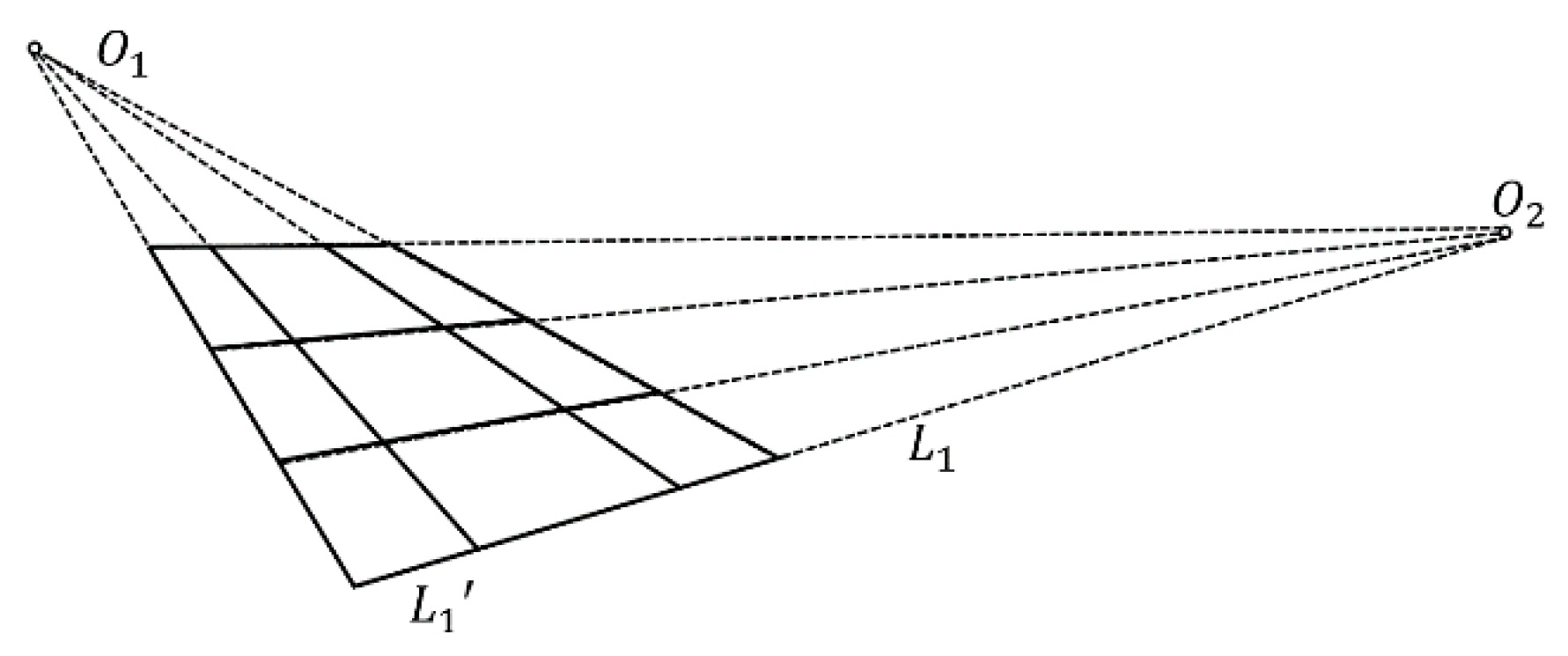
Figure 10.
Vanishing point model for rails and sleepers [
44].
Figure 10.
Vanishing point model for rails and sleepers [
44].
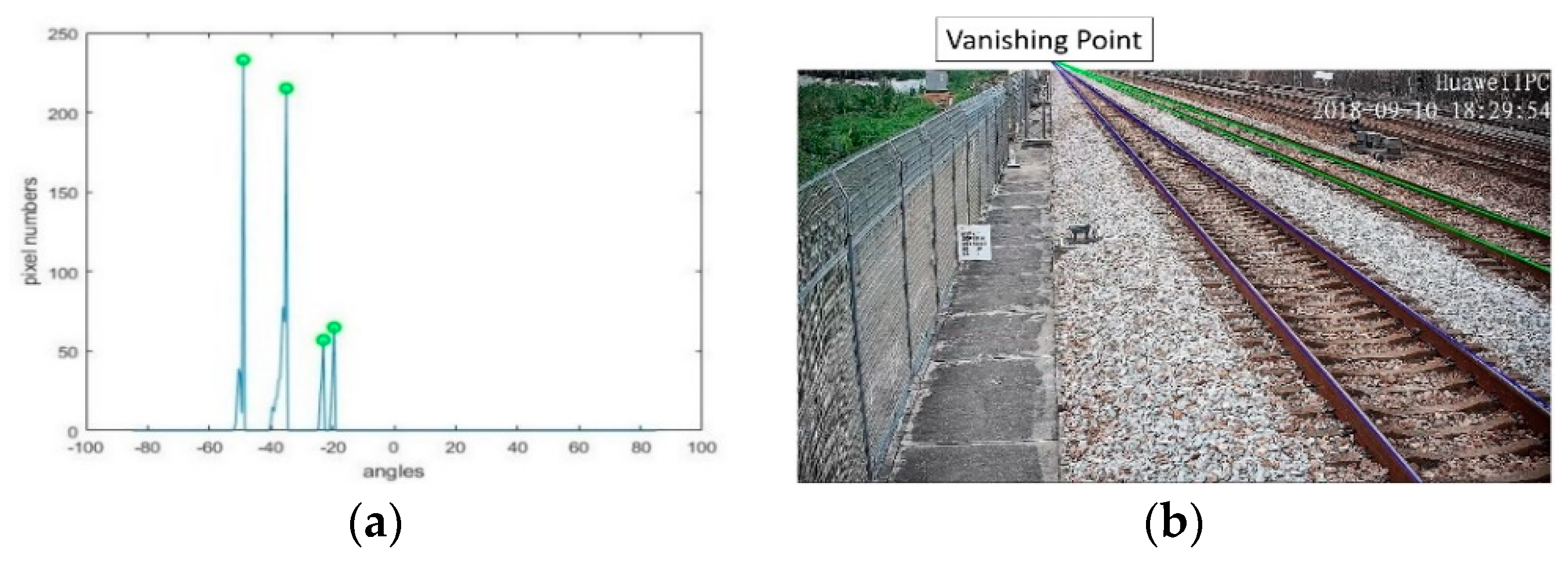
Figure 11.
Parallel rails detection: (a) statistics of pixel numbers at different angles in polar projection; (b) rails detection.
Figure 11.
Parallel rails detection: (a) statistics of pixel numbers at different angles in polar projection; (b) rails detection.
Figure 12.
Scaled objects and sleeper lines at different positions.
Figure 12.
Scaled objects and sleeper lines at different positions.
Figure 13.
Samples of railway intruding object dataset.
Figure 13.
Samples of railway intruding object dataset.
Figure 14.
Samples of the railway scene dataset.
Figure 14.
Samples of the railway scene dataset.
Figure 15.
Generated intruding objects from the input semantic labels.
Figure 15.
Generated intruding objects from the input semantic labels.
Figure 16.
Intersection-over-union (IoU).
Figure 16.
Intersection-over-union (IoU).
Figure 17.
Generated samples: (from left to right) input semantic labels, and the generated samples by the C-DCGAN, Pix2pix, CycleGAN, and DualGAN, respectively.
Figure 17.
Generated samples: (from left to right) input semantic labels, and the generated samples by the C-DCGAN, Pix2pix, CycleGAN, and DualGAN, respectively.
Figure 18.
Samples of generated railway objects intruding on the image’s dataset. (a) A generated pedestrian in railway. (b) Three generated pedestrians on a railway. (c) Two generated pedestrians on a railway. (d) A generated horse on a railway.
Figure 18.
Samples of generated railway objects intruding on the image’s dataset. (a) A generated pedestrian in railway. (b) Three generated pedestrians on a railway. (c) Two generated pedestrians on a railway. (d) A generated horse on a railway.
Figure 19.
Samples of real railway objects intruding images dataset. (a) A real pedestrian on a railway. (b) Two real pedestrians on a railway.
Figure 19.
Samples of real railway objects intruding images dataset. (a) A real pedestrian on a railway. (b) Two real pedestrians on a railway.
Figure 20.
Detection results of generated intruding objects using our method.
Figure 20.
Detection results of generated intruding objects using our method.
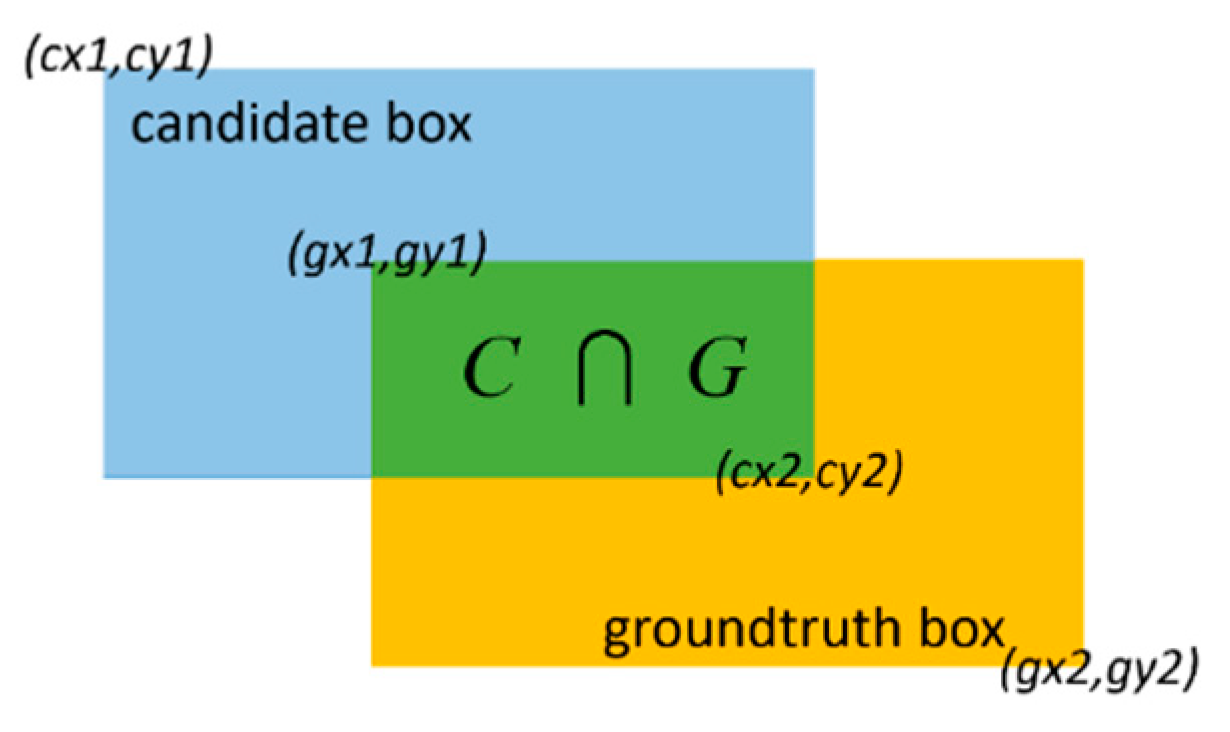
Figure 21.
Scale evaluation of real and generated pedestrians. (Left) Real pedestrians (groundtruth boxes) and (right) generated pedestrians (candidate boxes) at corresponding positions.
Figure 21.
Scale evaluation of real and generated pedestrians. (Left) Real pedestrians (groundtruth boxes) and (right) generated pedestrians (candidate boxes) at corresponding positions.
Table 1.
Architecture of the generator.
Table 1.
Architecture of the generator.
| Layer_Name | Input_Size | Filters | Kernel_Size | Stride | Output_Size | Others |
|---|
| ReflectionPad0 | 512 × 512 | - | - | - | 518 × 518 | - |
| Conv1_0 | 518 × 518 | 64 | 7 × 7 | 1.1 | 512 × 512 | - |
| Conv1_1 | 512 × 512 | 128 | 3 × 3 | 2.2 | 256 × 256 | - |
| Conv1_2 | 256 × 256 | 256 | 3 × 3 | 2.2 | 128 × 128 | - |
| Conv1_3 | 128 × 128 | 512 | 3 × 3 | 2.2 | 64 × 64 | - |
| Conv1_4 | 64 × 64 | 1024 | 3 × 3 | 2.2 | 32 × 32 | - |
| Conv | 32 × 32 | 1024 | 3 × 3 | 1.1 | 32 × 32 | ResNet blocks × 9 |
| Conv | 32 × 32 | 1024 | 3 × 3 | 1.1 | 32 × 32 |
| Shortcuts | 32 × 32 | 1024 | 3 × 3 | 1.1 | 32 × 32 |
| Deconv3_0 | 32 × 32 | 512 | 3 × 3 | 2.2 | 64 × 64 | - |
| Deconv3_1 | 64 × 64 | 256 | 3 × 3 | 2.2 | 128 × 128 | - |
| Deconv3_2 | 128 × 128 | 128 | 3 × 3 | 2.2 | 256 × 256 | - |
| Deconv3_3 | 256 × 256 | 64 | 3 × 3 | 2.2 | 512 × 512 | - |
| ReflectionPad1 | 512 × 512 | - | - | - | 518 × 518 | - |
| Conv4 | 518 × 518 | 3 | 7 × 7 | 1.1 | 512 × 512 | - |
Table 2.
Architecture of the multi-scale discriminators.
Table 2.
Architecture of the multi-scale discriminators.
| Module | Layers | Input_Size | Filters | Kernel_Size | Dilation | Stride | Output_Size |
|---|
| D1 | Conv1_0 | 512 × 512 | 64 | 4 × 4 | 1 | 2.2 | 256 × 256 |
| Conv1_1 | 256 × 256 | 128 | 4 × 4 | 1 | 2.2 | 128 × 128 |
| Conv1_2 | 128 × 128 | 256 | 4 × 4 | 1 | 2.2 | 64 × 64 |
| Conv1_3 | 64 × 64 | 512 | 4 × 4 | 1 | 1,1 | 63 × 63 |
| Conv1_4 | 63 × 63 | 1 | 4 × 4 | 1 | 1.1 | 62 × 62 |
| D2 | Conv2_0 | 256 × 256 | 64 | 4 × 4 | 1 | 2.2 | 128 × 128 |
| Conv2_1 | 128 × 128 | 128 | 4 × 4 | 1 | 2.2 | 64 × 64 |
| Conv2_2 | 64 × 64 | 256 | 4 × 4 | 1 | 2.2 | 32 × 32 |
| Conv2_3 | 32 × 32 | 512 | 4 × 4 | 1 | 1.1 | 31 × 31 |
| Conv2_4 | 31 × 31 | 1 | 4 × 4 | 1 | 1.1 | 30 × 30 |
| D3 | Conv3_0 | 128 × 128 | 64 | 4 × 4 | 1 | 2.2 | 64 × 64 |
| Conv3_1 | 64 × 64 | 128 | 4 × 4 | 2 | 2.2 | 32 × 32 |
| Conv3_2 | 32 × 32 | 256 | 4 × 4 | 1 | 2.2 | 16 × 16 |
| Conv3_3 | 16 × 16 | 512 | 4 × 4 | 2 | 1.1 | 15 × 15 |
| Conv3_4 | 15 × 15 | 1 | 4 × 4 | 1 | 1.1 | 14 × 14 |
Table 3.
Dataset of railway intrusion objects.
Table 3.
Dataset of railway intrusion objects.
| Categories | Number | Size (Pixels) |
|---|
| Pedestrian | 4897 | 512 × 512 |
| Sheep | 1594 | 512 × 512 |
| Cow | 2055 | 512 × 512 |
| Horse | 3069 | 512 × 512 |
Table 4.
Parameters of conditional deep convolutional generative adversarial networks (C-DCGAN) model training.
Table 4.
Parameters of conditional deep convolutional generative adversarial networks (C-DCGAN) model training.
| Size | Batch Size | λ1 | λ2 | k | Optimizer | Learning Rate | Momentum |
|---|
| 512 × 512 | 1 | 10 | 9 | 1:3 | Adam | 0.0002 | 0.5 |
Table 5.
Semantic segmentation scores of different generators. IoU—intersection-over-union.
Table 5.
Semantic segmentation scores of different generators. IoU—intersection-over-union.
| Architectures | Pixel Acc (%) | Mean IoU |
|---|
| U-net | 74.094 | 0.403 |
| CRN | 68.259 | 0.428 |
| Ours (6 blocks) | 76.549 | 0.547 |
| Ours (9 blocks) | 80.458 | 0.651 |
Table 6.
Semantic segmentation scores of different discriminators.
Table 6.
Semantic segmentation scores of different discriminators.
| Architectures | Pixel Acc (%) | Mean IoU |
|---|
| Single D | 72.142 | 0.504 |
| Double Ds | 76.981 | 0.591 |
| Triple Ds (without dilated conv) | 79.452 | 0.640 |
| Ours (with dilated conv) | 80.458 | 0.651 |
Table 7.
Semantic segmentation scores of different losses.
Table 7.
Semantic segmentation scores of different losses.
| Architectures | Pixel Acc (%) | Mean IoU |
|---|
| Only GAN loss | 70.843 | 0.457 |
| GAN loss + feature matching loss | 77.824 | 0.602 |
| GAN loss+ VGG loss | 72.176 | 0.483 |
| Ours | 80.458 | 0.651 |
Table 8.
Semantic segmentation scores of generated samples by different methods.
Table 8.
Semantic segmentation scores of generated samples by different methods.
| | Pix2pix | CycleGAN | DualGAN | Ours | Real Samples |
|---|
| Pixel acc (%) | 72.653 | 63.441 | 63.885 | 80.458 | 85.782 |
| Mean IoU | 0.441 | 0.347 | 0.358 | 0.651 | 0.724 |
Table 9.
Fréchet-Inception Distance (FID) scores of the different methods.
Table 9.
Fréchet-Inception Distance (FID) scores of the different methods.
| | Pix2pix | CycleGAN | DualGAN | Ours | Real Samples |
|---|
| FID | 45.42 | 47.13 | 48.62 | 26.87 | 13.59 |
Table 10.
Detection results of generated and real datasets. AP—average precision.
Table 10.
Detection results of generated and real datasets. AP—average precision.
| Categories | Input Size | Datasets | Amount | AP |
|---|
| Pedestrian | 320 | Real | 1265 | 0.534 |
| Generated | 1198 | 0.578 |
| 416 | Real | 1265 | 0.656 |
| Generated | 1198 | 0.691 |
| 608 | Real | 1265 | 0.823 |
| Generated | 1198 | 0.847 |
| Horse | 320 | Generated | 447 | 0.625 |
| 416 | Generated | 0.721 |
| 608 | Generated | 0.829 |
| Cow | 320 | Generated | 472 | 0.611 |
| 416 | Generated | 0.695 |
| 608 | Generated | 0.844 |
| Sheep | 320 | Generated | 412 | 0.592 |
| 416 | Generated | 0.631 |
| 608 | Generated | 0.818 |
Table 11.
Confusion matrices of generated samples using Yolov3.
Table 11.
Confusion matrices of generated samples using Yolov3.
| | | Prediction |
|---|
| | Pedestrian | Horse | Cow | Sheep |
|---|
| True labels | Pedestrian | 868 | 48 | 61 | 68 |
| Horse | 20 | 319 | 38 | 25 |
| Cow | 25 | 29 | 335 | 19 |
| Sheep | 24 | 20 | 15 | 328 |
Table 12.
AP scores of the generated samples using a different method.
Table 12.
AP scores of the generated samples using a different method.
| Models | AP-Pedestrian | AP-Sheep | AP-Cow | AP-Horse | mAP |
|---|
| Pix2pix | 0.625 | 0.558 | 0.593 | 0.627 | 0.601 |
| CycleGan | 0.501 | 0.498 | 0.519 | 0.526 | 0.511 |
| DualGan | 0.516 | 0.511 | 0.508 | 0.522 | 0.514 |
| Ours | 0.691 | 0.631 | 0.695 | 0.721 | 0.685 |
Table 13.
IoU scores of pedestrian pairs.
Table 13.
IoU scores of pedestrian pairs.
| Pedestrians | Position | Pair numbers | mIoU |
|---|
| Single | Far | 198 | 0.889 |
| Middle | 213 | 0.875 |
| Close | 189 | 0.821 |
| Double | Far | 197 | 0.891 |
| Middle | 230 | 0.862 |
| Close | 196 | 0.812 |
| Multiple | Far | 195 | 0.857 |
| Middle | 205 | 0.861 |
| Close | 214 | 0.814 |
| Total | — | 1837 | 0.854 |
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}