1. Introduction
The continuous monitoring of wind turbine systems and their constituent components (e.g., drive trains, generators and blades) can be the most effective way to eliminate unplanned maintenance and increase availability. With advanced data acquisition technology and signal processing techniques, faults can be diagnosied in the early stage and suitable maintenance actions such as replacement and repair can be scheduled to prevent the damage from propagating to surrounding areas. Wind turbine systems are operating under adverse condition, such as vastly varying speeds, loads and temperatures. Bearings in wind turbine systems generally operate under adverse conditions such as chemical effects of lubricant, contamination and moisture, as a result, bearings are subject to performance degradation if no preventive actions are taken. In addition, the high demands for renewable energy resources has resulted in further demands on wind turbines availability and reliability, especially on the key components such as the gearbox and bearings [
1].
A gearbox is one of the most important units in the drive train system of a wind turbine. A gear box consists of gears, bearings and shafts that are subject to continual variable operational speed and loads. In a gearbox, the high-speed shaft is supported by the high-speed stage bearings located at the front and back end of the shaft. Typical operating speed of the shaft is between 1500 and 1800 rpm during power generation. It has been reported that a great number of wind turbine failures are related to the high-speed shaft bearings [
2]. Cyclic loads caused by the wind turbine rotor blades will drive the main shaft to bend, leading to misalignment between the generator and the high-speed shaft and accordingly misalignment within the bearings. High-speed shaft bearings are therefore subject to damage from the cyclic loads [
3,
4]. For inspection purposes, wind turbine gearboxes are largely inaccessible since these are situated at the top of high towers. Possible failure implications are compounded by the fact that once a bearing fails, it may cause damage to the surrounding components of the gearbox, and as a consequence, cause replacement of various components inside the gearbox [
5,
6].
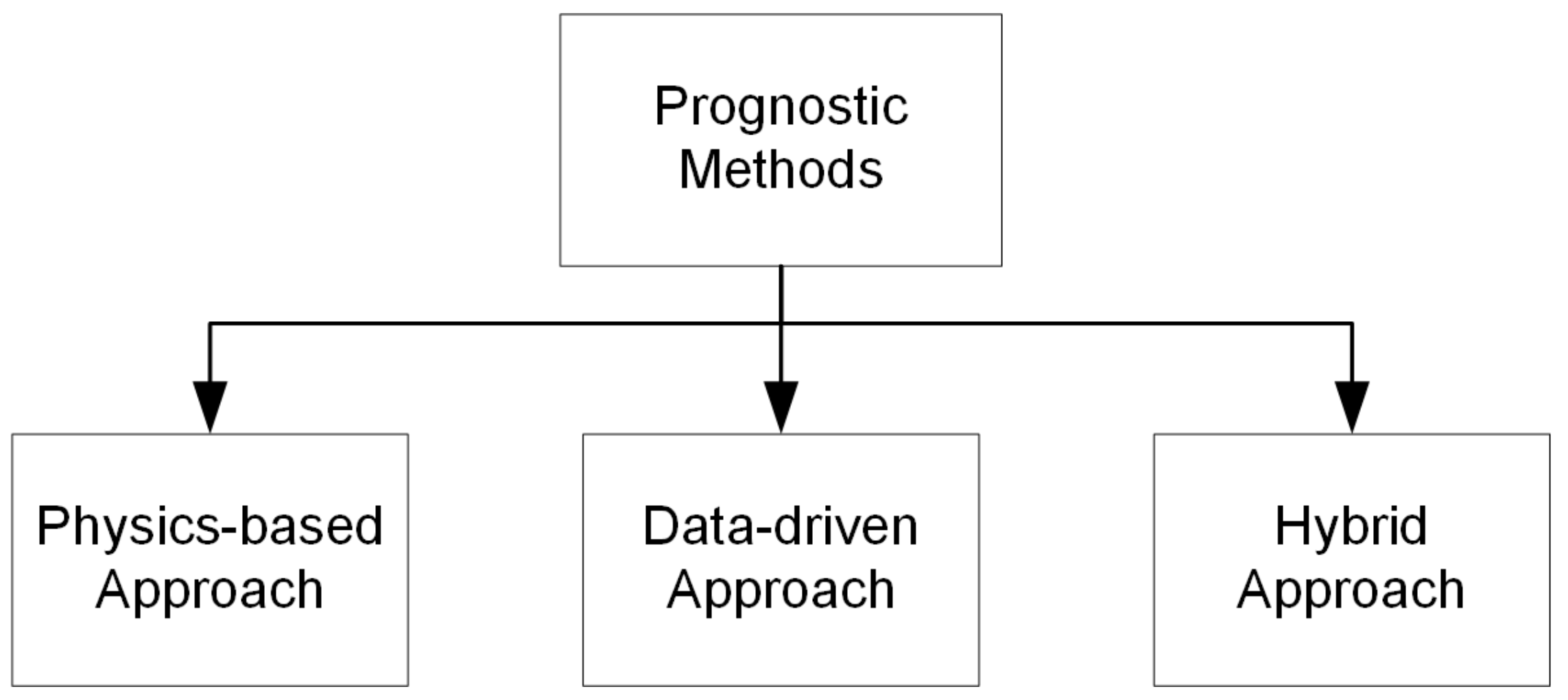
Over the past decades, much research has been dedicated to the development of health monitoring methods for rotating machinery, especially the bearings. Compared to fault detection, the literature of prognostics and health management is relatively limited, and effective implementation of prognostic techniques is still lacking. The increased interest on machinery prognostics has resulted in many successful tools, models and applications during the past few years. Basically, there are three types of prognostic approaches that can be employed to predict the RUL, namely, data-driven methods, physics-based models and hybrid models (see
Figure 1). Data-driven approaches utilize the historical failure data of the machine and/or similar machines to estimate how much time is left until a system malfunction occurs. This method does not require an in-depth understanding of the physics of system under study. Physics-based approaches predict the remaining life according to propagation of damage mechanism (i.e., physics of failure). A hybrid approach uses both data-driven and physics-based method so as to achieve an improved predictive performance in terms of improved predictive accuracy than when a single method is used.
Over recent years much efforts have been focused on developing regression-based prognostic methods that can be used to estimate the RUL of rotating machinery. Li et al. [
7] improved the performance of traditional exponential regression model and applied the developed regression model to vibration measurements collected from rolling element bearings to predict RUL. Wu et al. [
8] put forward a time-to-failure prognostic method based on empirical Bayesian algorithm an exponential regression model for rolling element bearings. Sutrisno et al. [
9] investigated the accuracy of three different techniques for predicting the RUL of bearings. Bayesian Monte Carlo and moving average spectral kurtosis, support vector regression (SVR) and an anomaly detection algorithm were compared according to their performance in estimating a ball bearing’s remaining life. The anomaly detection technique was found to be the most accurate among all methods compared. Goebel et al. [
10] conducted a comparative study of three prognostic methods RVM, Gaussian process regression (GPR) and a neural network. The study showed that the three techniques have resulted in significantly different RUL prediction results. Loukopoulos et al. [
11] studied the performance of several machine learning techniques, including linear regression, polynomial regression and K-Nearest Neighbors Regression. The results showed that an ensemble method which is based on the weighted average of the predicted RUL of each individual method offers a higher predictive accuracy. Kim et al. [
12] utilized Support Vector Regression to evaluate the bearing health condition by using real-world run-to-failure data obtained from bearings of gas pumps. The results showed that the developed probability estimation based prognostic method is potentially very effective for RUL prediction. A combined regression technique which is based on linear and quadratic regressions was put forward to deal with gas turbine engine’s degradation [
13]. An e-support vectors regression model was proposed in [
14] for the RUL estimation of rolling element bearings. The Logistic regression model was employed in [
15] for the estimation of RUL of CNC machine. More regression-based prognostic models can be found in the literature [
16,
17,
18,
19,
20].
Several other artificial intelligence approaches applied to machinery prognostics have been considered by researchers. For instance, a self-organizing neural network was employed by Zhang and Ganesan [
21] for extrapolating the fault progression and estimating the remnant life of a bearing. Loukopoulos et al. [
11] applied a Self-Organizing Map (SOM) model to predict the RUL of industrial pumps using temperature measurements. Dong et al. [
22] developed a condition prediction method based on grey model and back-propagation neural network. Elasha et al. [
23] put forward a life assessment approach for tidal turbine gearboxes. The method was validated on data generated using a Blade Element Momentum Theory (BEMT) model. They predicted the RUL of a gearbox based on the turbine loading conditions. The results of their investigation show life variations between the gears due to differences in stress cycles and differing rotational speeds. Li et al. [
24] put forward a hybrid method in which a long short-term memory model and a state-space model was combined to predict the pro-fault performance of a centrifugal compressor. An adaptive neuro-fuzzy inference system (ANFIS) was used together with the particle filtering (PF) algorithm in [
25] to predict the RUL of a gearbox. The authors concluded that the ANFIS model outperforms the recurrent neural network through a comparative study. Elforjani and Shanbr [
26] employed three supervised machine learning techniques—artificial neural network (ANN), SVR and GPR—to correlate vibration measurement features with the natural wear of bearings. They concluded that the back-propagation neural network model outperforms the other methods in predicting the RUL of bearings. A prognostic framework based on auto-adaptive dynamical clustering was put forward by Chammas et al. [
27]. This method allows the estimation of remnant life of incipient failure of a wind turbine benchmark. The RUL is estimated by using an auto-regressive integrated model to predict the future values of a severity indicator. A feed-forward neuro network was developed to learn the correlation between the lifetime and the health indicator extracted from the raw sensor signals [
28]. Similarly, self-organizing map (SOM) and a feed-forward neural network were combined for effective bearing failure life prediction [
29]. More prognostic methods based on feed-forward neural network can be found in [
30,
31,
32]. Moreover, neuro-fuzzy systems whose membership functions are tuned by ANNs have also gain popularity in machinery prognostics. In [
33], a multi-step forecasting model based on a weighted recurrent neuro-fuzzy system was put forward. A neuro-fuzzy system was utilized in combination with regression trees and particle filter in [
34,
35] for machine remaining useful life prediction. More research related to neuro-fuzzy based prognostics can be found in [
36,
37]. The aforementioned prognostic techniques offer a tradeoff between reliability, speed and applicability. Other techniques exit with wide ranging advantages and disadvantages [
38], however this paper focuses on combining two supervised machine learning techniques, namely, regression model and artificial neural network (ANN) model to correlate vibration features with the corresponding fault stages during the natural run-to-failure process of rolling element bearings. One of the main contributions of this study is to improve the fitting of features obtained from vibration signals using appropriate regression models. This study also aims to ascertain the feasibility of using ANN models to estimate the RUL of rolling element bearings, and to explore the feasibility of combining regression models with ANNs for a better RUL prediction. The proposed combined technique leverages the strengths of both ANN and regression models, and is able to provide more accurate RUL estimations compared to traditional exponential regression models. Compared with traditional artificial intelligent methods, the proposed model takes advantages of the exponential regression approach in that the fitted prognostic features ensure precise modelling of the bearing degradation process. The effectiveness of the proposed prognostic method was validated on vibration measurements captured from an operational wind turbine gearbox.
2. Working Methodology
In condition monitoring applications, the vibration signals of bearing damage often present multiple modulation characteristics, and therefore the features extracted by the general methods from one bearing may not necessarily correlate to fault characteristics extracted from another bearing. The internal reasons behind this include, for example, different observed trends from different cases. As a result, there is still a need to apply and validate bearing fault indicators such as root mean square (RMS) and Kurtosis (KU) for different applications. Furthermore, due to the measurement noise, variation of operating conditions and stochasticity of the system deterioration, the extracted condition indicators from the raw vibration signals generally contain fluctuations, which would incur inaccurate RUL predictions. Thus, one of the main contributions of this study is to improve the fitting of the features extracted from vibration measurements through the use of appropriate regression models. This study also aims to ascertain the feasibility of ANN models to predict the RUL of rolling element bearings used in real-world applications, and to explore the possibility of combining regression models with ANNs to form a better prognostic model.
2.1. Statistical Condition Indicators
Vibration-based health monitoring schemes are applicable for monitoring many constituent components of a gearbox, such as shafts, gears and bearings. To achieve a better signal-to-noise ratio (SNR), vibration measurements are processed using filtering and amplifying techniques. Two condition indicators, RMS and KU, are often generated from the vibration signals. Then the extracted condition indicators are fitted using regression methods to provide useful information about the bearing degradation. There are several fault indicators (statistical features) that could be used for fault diagnostics using vibration data, such as RMS, KU, crest factor and energy operator, to name a few [
39]. Among the aforementioned fault indicators, RMS and KU are the most widely used [
40,
41,
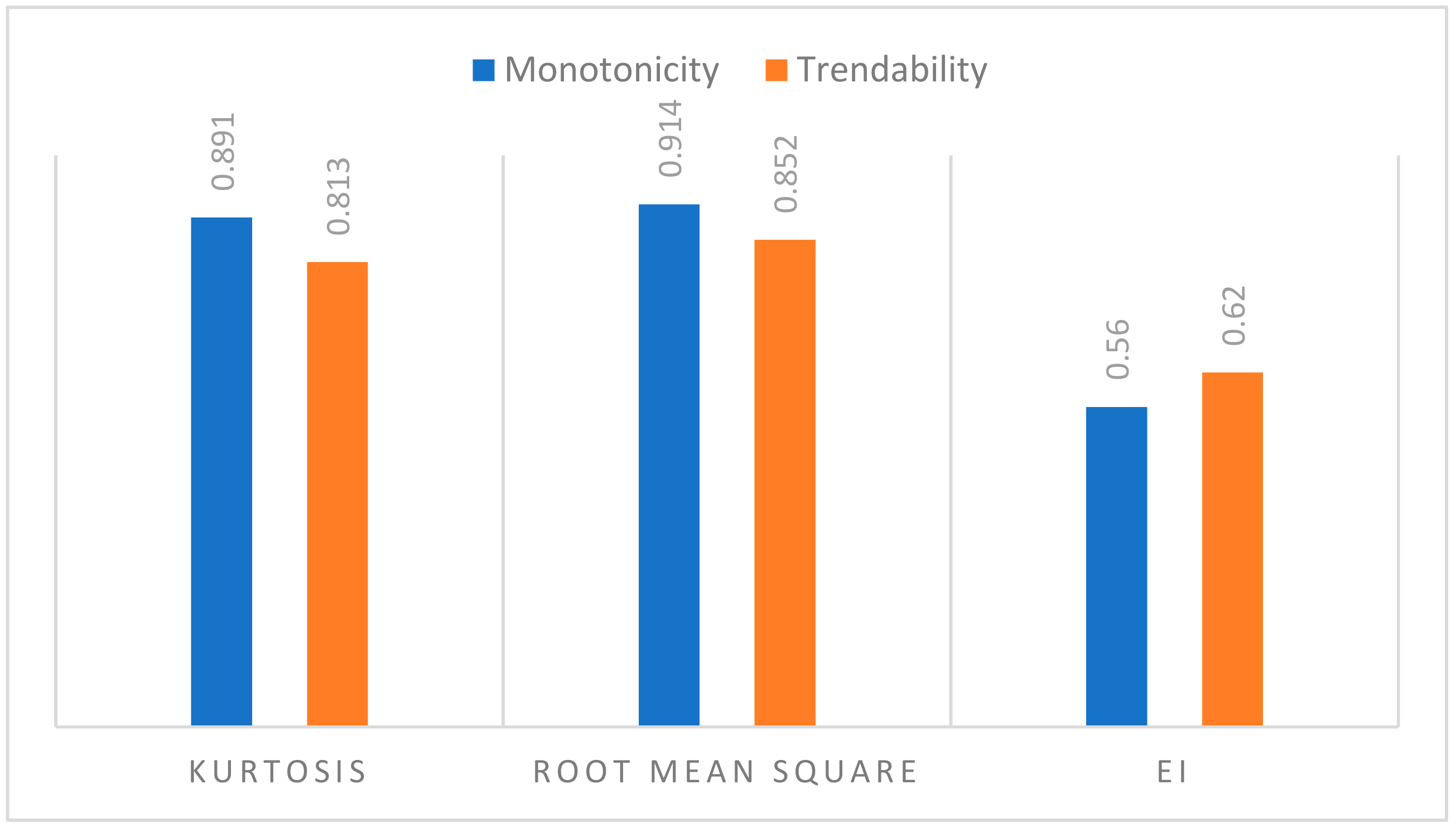
42]. In this study, we compared the suitability of three different fault indicators (i.e., RMS, KU and energy index) for prognostic analysis. Monotonicity and trendability were utilized as the performance metrics for measuring the suitability of these indicators. Based on the obtained results, RMS and KU were eventually found to be most suitable indicators for the prediction of RUL in this study.
2.1.1. Kurtosis
Each mechanical failure has an associated “signature” that can be found in the frequency or time domain representations of vibration signals. Kurtosis is such a “signature” which is referred to as the fourth statistical moment of a given signal, reflecting the peakness of the histogram [
43]. A kurtosis value greater than three is an indicator of a sharp peak signal. A kurtosis value smaller than three indicates vibration signals with flat peaks. In some cases, the occurrence of background noise and other sources of vibration signals may prevent bearing faults from being detected through the observation of changes in the kurtosis. To solve this problem, the kurtosis value needs to be computed across different frequency bands [
44]. The Kurtosis of a random signal is computed as:
where
is the number of samples in the signal,
refers to the amplitude of the signal of the
th sample, and
denotes the mean sample amplitude.
2.1.2. Root Mean Square
The root mean square (RMS) value describes the energy content of a signal. RMS is one of the most common used statistical parameter that describe the change in the dynamic of the machine [
45]. For the signal of sample size
, the RMS value is calculated using the equation below:
It is well known that the RMS value is a weak method to detect the failure at its early stage because of the small energy generated by the defect which makes a small difference to the value of RMS. However, RMS is capable of reflecting the increase of the vibration energy as the fault progresses [
7]. Consequently, RMS is employed as the prediction indicator in this study. In other words, the RUL is predicted by extrapolating the trajectory of RMS values.
2.1.3. Energy Index
Energy Index (EI) is defined as the square of the ratio of the RMS value of a signal segment to the overall
RMS value of the same signal. This technique has been effectively applied to detect incipient failure of bearings [
46]. In practice, an EI value of one indicates non-transient type waveforms, whereas and an EI value larger than one is often associated with transient characteristics. EI can be computed using the following equation:
2.2. Definition of the Remaining Bearing Life
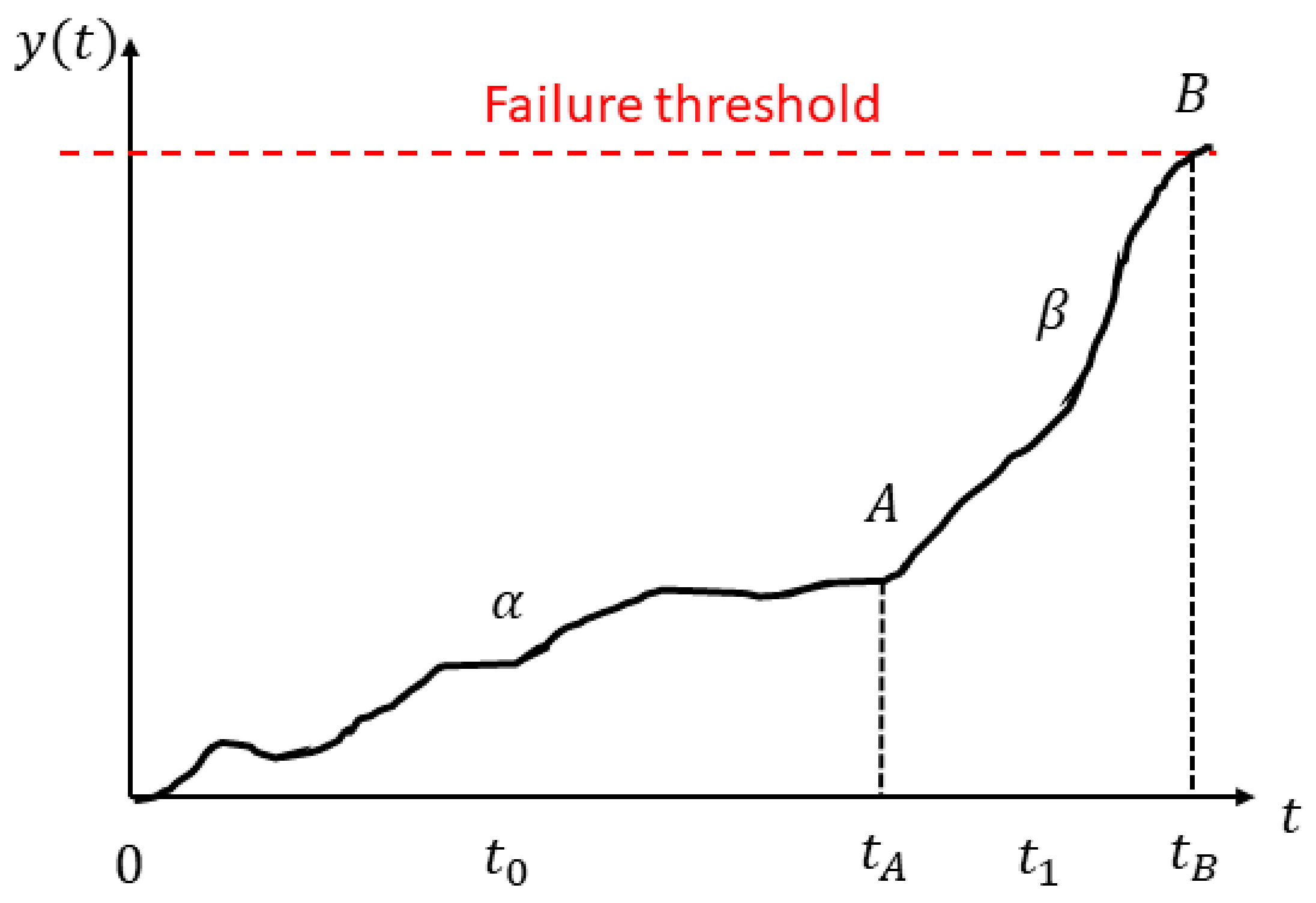
The RUL of a bearing is generally defined either as the total number of revolutions before a failure occurs or the total number of hours that the bearing can run until the first sign of failure develops [
47]. The RUL is estimated based on measured and calculated bearing condition variables such as vibration amplitude and frequency. As shown in
Figure 2, if a certain condition indicator x is calculated or monitored continuously from
t = 0 to
t =
, then a continuous time series
y(
t) can be obtained, which represents the deterioration process of the component under study. This time series consists of two parts,
α and
β, which indicates the healthy running stage and the fault degradation stage, respectively. Prognostic analysis is usually based on the analysis of the time series from point A to point B. Ideally, if the RUL of a bearing (i.e., the total running time between point A to B) can be accurately estimated by using only the past data covered by α, then the optimal maintenance schedule can be made easily.
2.3. Regression
Regression models, as one of the most popular data-driven techniques for RUL prediction, attempt to fit available data of deterioration by regression functions and then extrapolate the fault propagation until the fitted curve reaches a pre-defined threshold. The objective of regression analysis is to find an empirical relation for predicting the bearing degradation thought time series. Due to measurement noise, variation of operational conditions and the stochastic nature of the degradation processes, the acquired data are usually accompanied by fluctuations that may have a significant impact on the model’s ability to interpret the degradation trend. In this case, the raw condition indicators cannot be directly used as the inputs of the prediction models. This is due to the fact that any fluctuations in the condition indicators will cause the model to follow the randomness, and consequently, its ability to accurately estimate the health status of the bearings may be very weak [
48]. Therefore, in this study, we first conduct a comparative study of two regression models, namely polynomial and exponential regression, and then choose the one with the best fitting performance to fit the condition indicators extracted from the data.
The polynomial models are suitable for situations where the correlation between explanatory and study variables is curvilinear. Polynomial regression belongs to the least-squares curve fitting family. It takes a set of data as inputs and generate an approximation between the input data and time. To be specific, it estimates the coefficients of a polynomial function in that the function approximates the curve closely. The formula of polynomial regression is as follows:
where
y is the response variable,
x is the predictor variable, and
,
, …,
are model coefficients. The degree of the polynomial function is determined by the number of non-zero coefficients in Equation (4), which in turn determines how accurate the data can be fit. If the number of coefficients is one or two, then the fitted curve is known as a linear regression. If the number of coefficients is larger than two, a non-linear polynomial regression will be implemented.
The exponential regression model is a fitting process that finds the equation of the exponential function which can present the best fit for a set of data [
48]. The function form of the exponential is shown in Equation (5):
where
,
b are model constants and
x is the predictor variable.
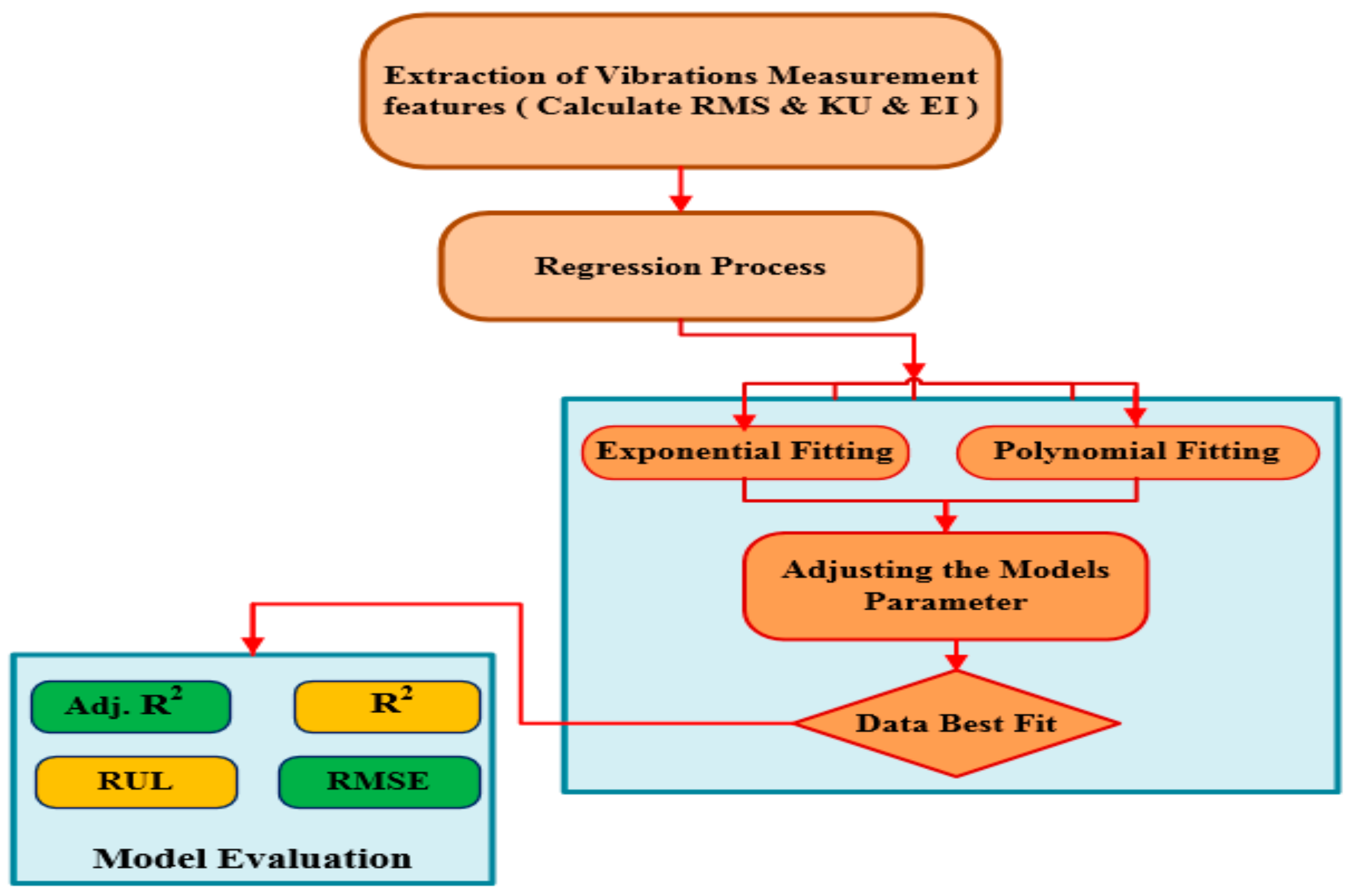
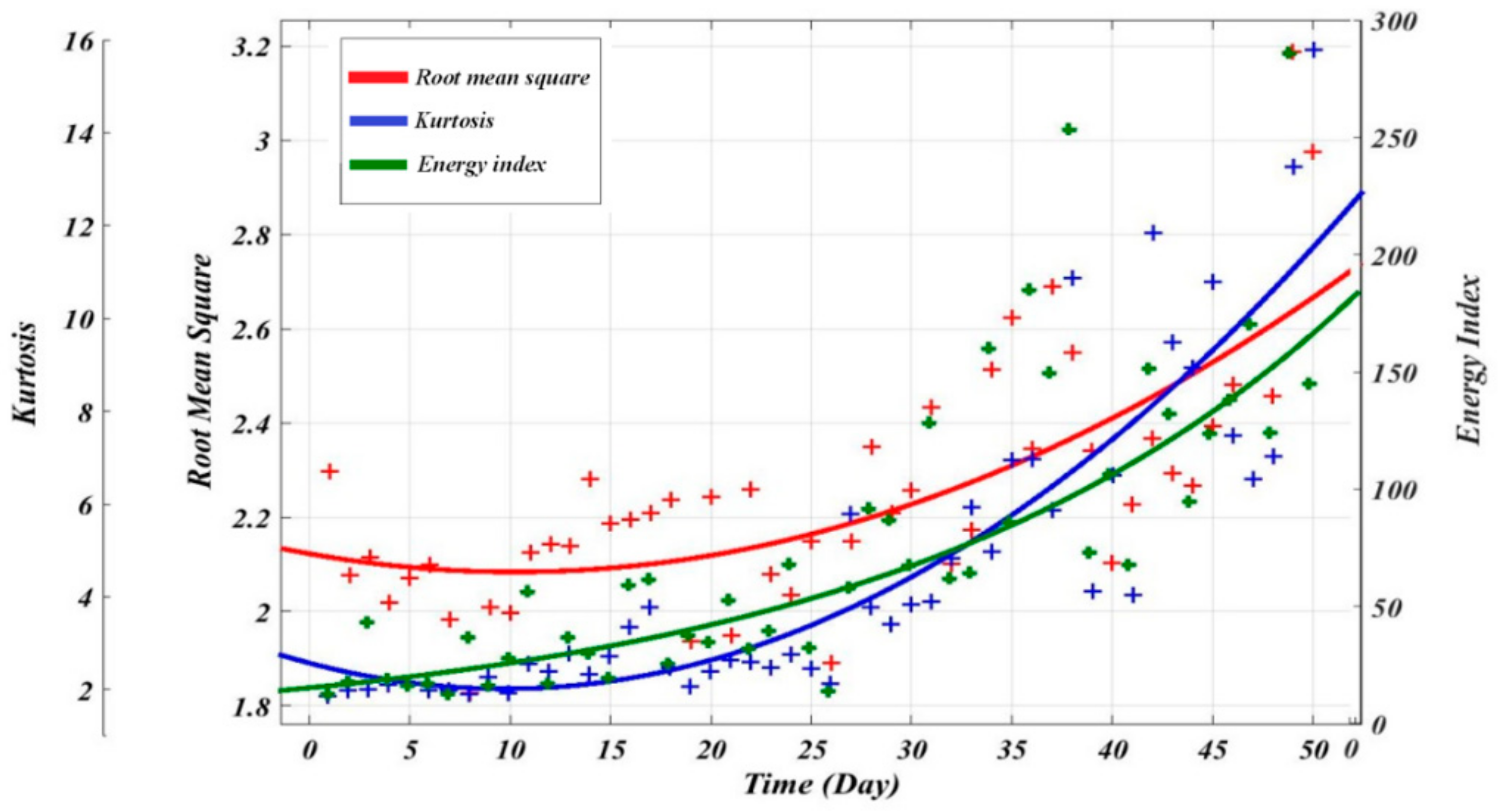
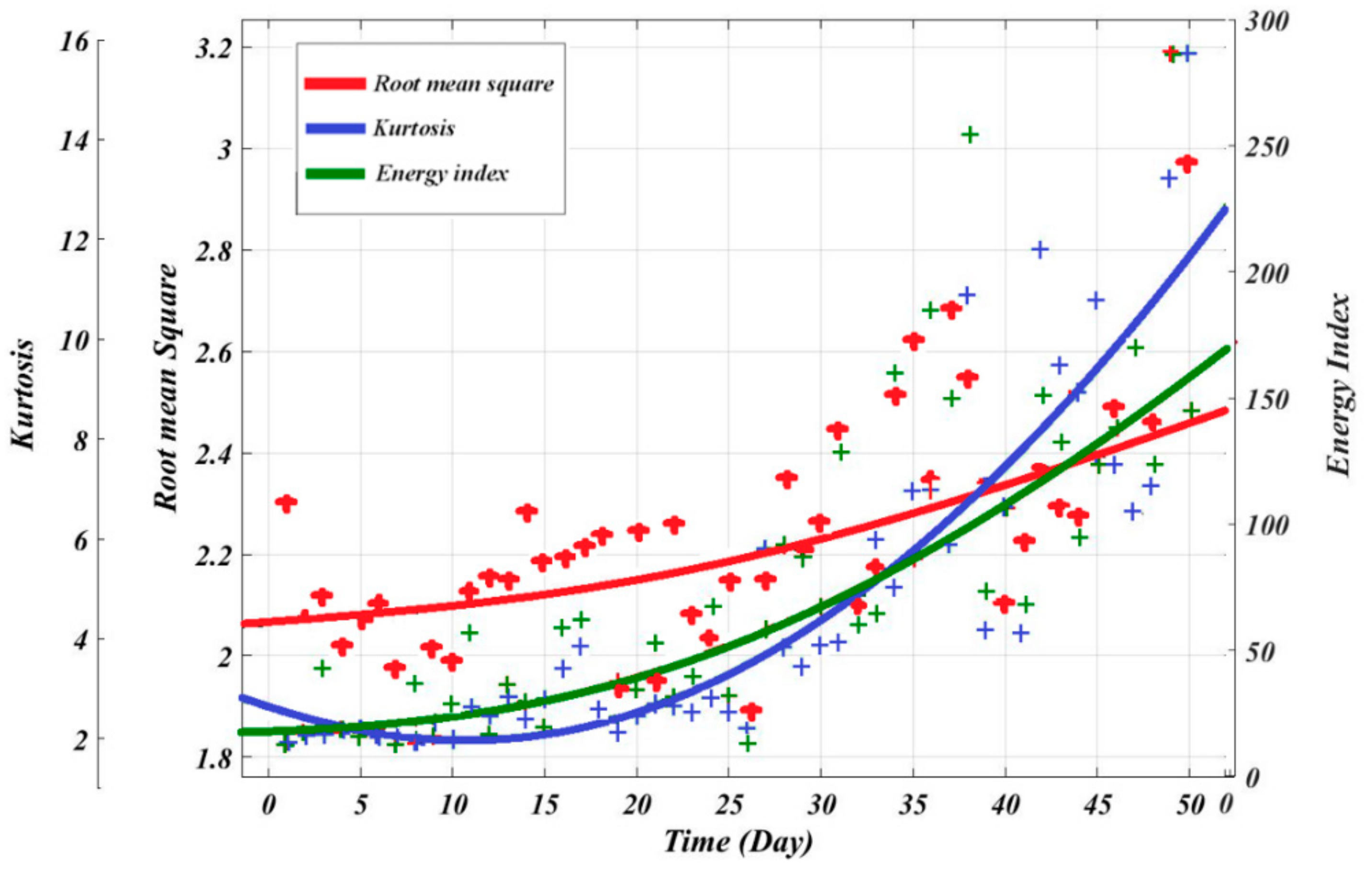
Figure 3 shows the process of two regression models that were used to extract the best fit from the scatters statistical parameters. In which the vibration signals have been processed to obtain the condition indicators. And then the exponential and polynomial functions have been used to determine the best fit and estimate the coefficients in Equations (4) and (5).
The performance of the regression models was assessed using three statistics: Root Mean Square Error (RMSE), R2 and Adjusted R2. The RMSE is the square root of the variance of the residuals. RMSE measure how close the measured data to the predicted values. The R2 is defined as the ratio between the difference between the sum square total (SST) and sum square error (SSE) to the SST. SST measures the data deviation from the sample mean, and SSE measures the deviation of the data from the model’s predicted values. Therefore, the R2 value provides the goodness of the data. One of the disadvantages of the R2 is that it can increase if there are more than one predictor, but this increase does not reflect the model improvement. Therefore, adjusted R2 has been used in this research. Adjusted R2 is defined as the ratio between the residual mean square errors to the total mean square error (which is the variance of the predicted values).
Indicator Performance Quantification
Identification of a suitable indicator simplifies the degradation assessment and prognostics. Parameter features include monotonicity and trendability can be used to compare candidate prognostic parameters to determine which parameter is most useful for prognosis task [
29]. Monotonicity and trendability are a type of metrics used to quantify the indicators suitableness and are defined as the following.
a) Monotonicity
The monotonicity metric indicates the principal whether or not the sequence is increasing or decreasing (positive or negative trend of the indicator). Due to the fact that the bearing degradation is considered to be an irreversible process, monotonicity measures whether or not a condition indicator is suitable for representing a degradation process. Monotonicity is calculated as per Equation (6):
where n denotes the number of measurement time instances. #
denotes the number of positive derivatives, and #
is the number of negatives derivatives.
The monotonicity of a sensor population is calculated by the average difference of the fraction of positive and negative derivatives for each path. A monotonicity value close to one means that the condition indicator is monotonic and suitable for RUL prediction, whereas a monotonicity value close to zero indicates that the condition indicator is non-monotonic and not appropriate for RUL prediciton.
b) Trendability
The trendability metric indicates the degree to which the condition indicator values at different times have the same fundamental shape and can be defined using similar function form. Its value is determined by the minimum absolute correlation calculated among all the condition indicators [
18]. A condition indicator can be considered trendable if all the parameters can be modelled by the same function (Equation (7)):
2.4. Multilayer Artificial Neural Network
ANNs belong to the supervised machine learning family. They are inspired by biological neural networks and each neuron is represented by a node [
28]. An ANN generally contains an input layer, multiple hidden layers, one output layer, biases and connection nodes. When the known inputs and target outputs are repetitively presented to an ANN, the connection weights between nodes will be adjusted automatically such that the difference between the network outputs and the targets is as small as possible.
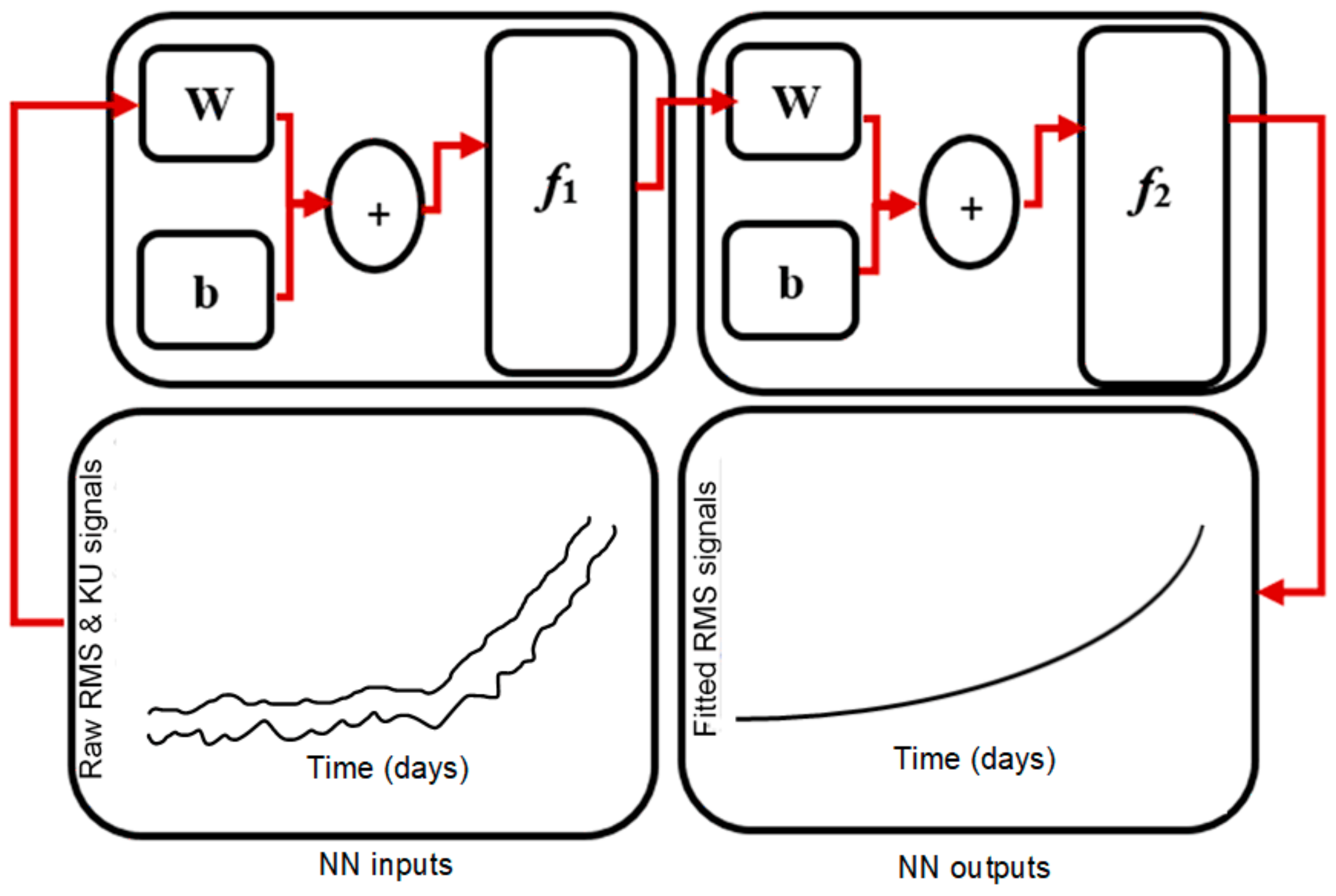
In this study, the ANN that we implemented is a multilayer back-propagation neural network.
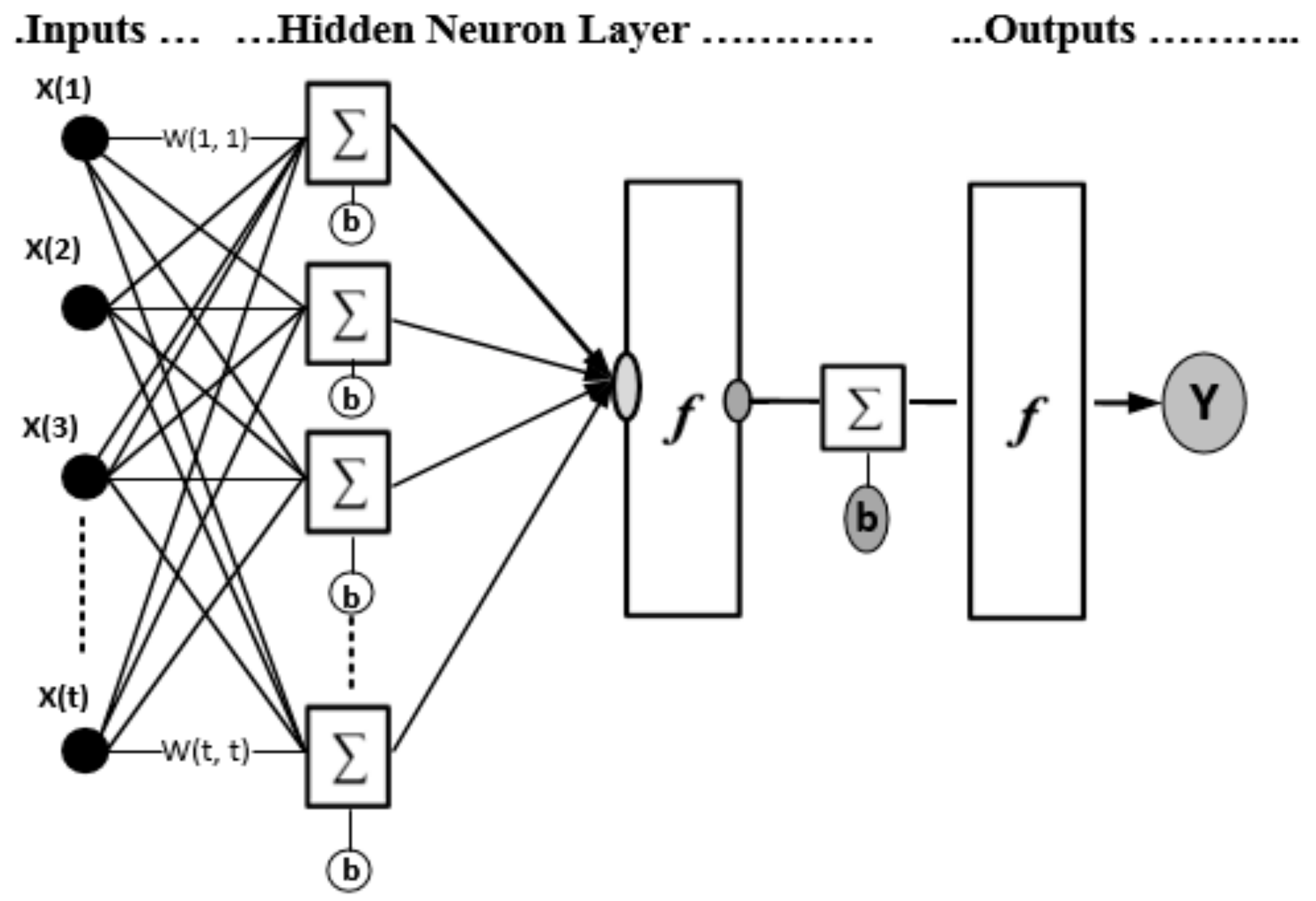
Figure 4 illustrates an exemplary architecture of the multiple-layer neural network model. It is observable from the figure that each layer consists of its own inputs and outputs nodes (x & y), weighting coefficients (
w) and bias (
b). The input layer doesn’t involve any processing and it is utilized to directly feed information to the subsequent network layers. In contrast, the output layer involves weighting and biases calculations and is employed to produce the network outputs. The hidden layers aim at adding additional processing to the network so as to avoid solutions that do not converge. As shown in
Figure 4, the main purpose of the bias neurons is to prevent the network from generating zero results even if the network inputs are not zero. The exemplary network structure is formed of a feed-forward model. The following equation explains how the network inputs are correlated with the outputs:
where
is the network output vector and the input vector is represented by
,
C denotes the weighting matrix between the hidden layer and the output layer.
B is the connection matrix from the input layer to the hidden layer. The bias vectors of the hidden and output layers are represented by
and
, respectively.
and
denote the activation functions of the nodes in the hidden and output layers, respectively. Feedforward neural network models also take the form of Equation (9):
where
(·) denotes a nonlinear transformation from
to
. Interestingly, the structure of a feedforward neural network is similar to that of a nonlinear regression model. Levenberg Marquardt (LM) learning algorithm was chosen as the network training function in this study for adjusting the weighting and bias matrices during the training process. LM optimization has been applied intensively for feedforward neural network training and has been proven to be able to deal with many difficult and diverse problems in practice. This algorithm minimizes functions that are sums of squares of nonlinear functions. One of the advantages of this optimization method is that the second-order convergence point can be approached without calculating the Hessian matrix.
5. Conclusions
A data-driven prognostic method has been developed and tested using vibration signals collected from an operational wind turbine gearbox. This paper has addressed bearing prognosis with the aim of predicting the RUL of high-speed shaft bearings. Two types of prediction methods, namely, regression and back-propagation neural network, have been used to model and estimate the remnant life. The regression model’s results have been used to feed the neural network to enable better predictions.
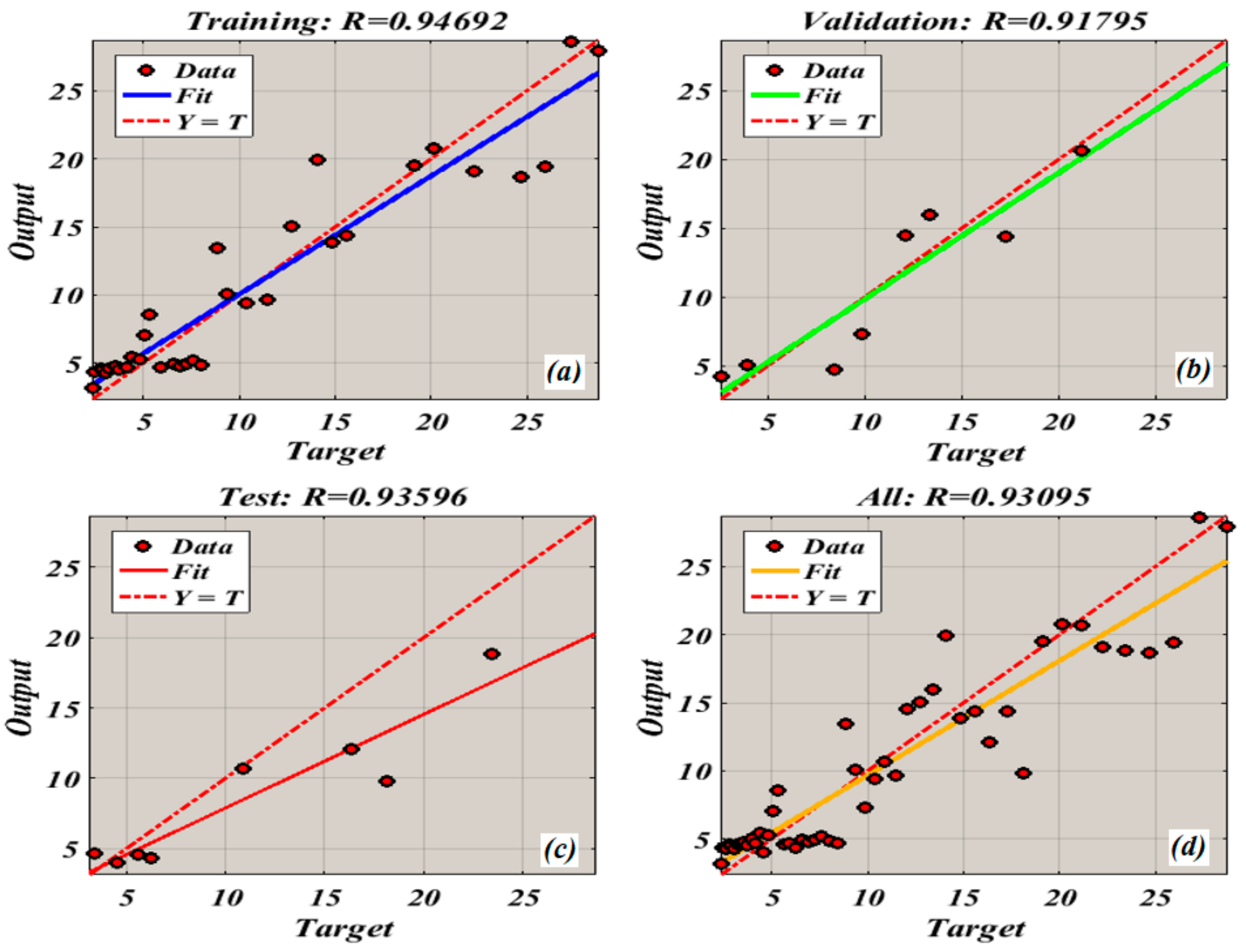
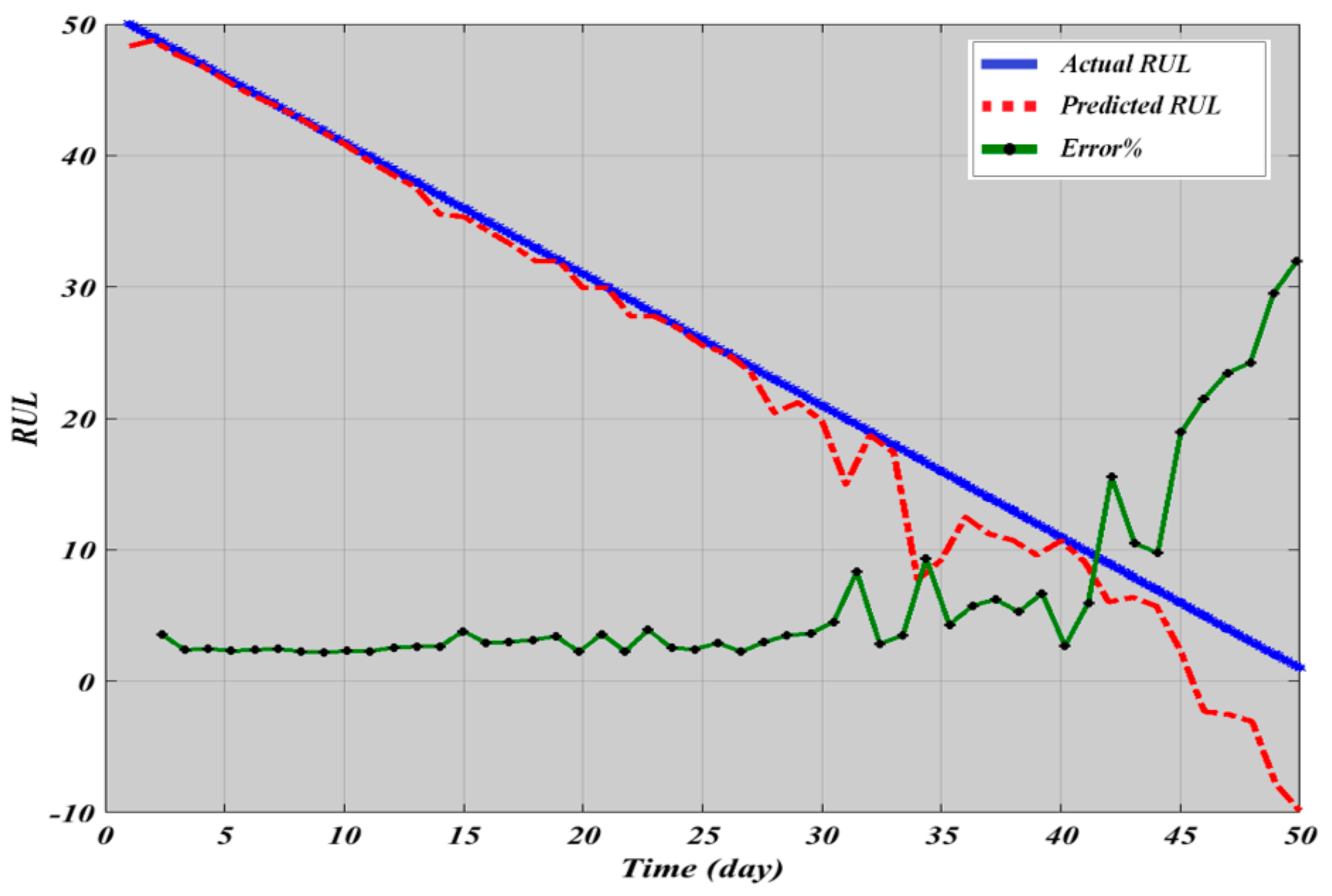
The proposed model was tested on real-world vibration data collected from a 2 MW wind turbine (degradation of bearing operating at speed of 1800 rpm). The obtained results using regression and ANN models have been compared. The regression was based on three condition indicators RMS, Kurtosis, and EI. The performance of each regression model was compared using three parameters: RMSE, R2 and adjusted-R2. The result showed that the exponential model has the best performance. The ability of condition indicators to be used for prognosis has been evaluated using monotonicity and trendability parameters. The results showed RMS has the best overall performance, therefore the RMS was used as best fit output data for neural network.
The results obtained using the proposed ANN model indicate that it has good performance in predicting the remaining useful life of a bearing, and this success can be attributed to the link created between the regression model to the ANN through the best fit condition indicator. Comparing the performance of regression model and the ANN it can be seen that the ANN model was able to provide more accurate predictions, however, this performance cannot be achieved without the regression model. Therefore, the regression model is considered necessary to improve the predictive performance of the ANN model. The stochastic nature of the degradation processes cannot be mitigated by just fitting a regression model. The use of a probabilistic model can overcome this limitation. Efforts will be made in future research to explore the RUL prediction using a probabilistic approach.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}