1. Introduction
Aerospace synthetic aperture radar (SAR) can be all-time and all-weather to obtain high-precision microwave images and other value-added products over large areas, and it has an extensive range of applications in remote sensing, environmental monitoring, geographical mapping, war zone surveillance, precision guidance, and reconnaissance [
1,
2,
3,
4].
Extensions and modifications of the SAR technology have significantly increased its practicality and applications. The demand for high-resolution and wide-swath (HRWS) SAR imaging is growing, especially in the areas of ocean observation, geological survey, and environmental protection. In 1978, the United States launched the first spaceborne SAR named Seasat-1. It is a satellite specifically designed for telemetry of the Earth’s oceans, and is aimed at realizing the possibility of global satellite monitoring of the oceans and determining the system requirements for marine remote sensing satellites. RADARSAT-1 was successfully launched in Canada in 1995 [
5]. It not only provided Canada with a large amount of all-weather and all-time SAR data, but also provided useful information for commercial and scientific users in disaster management, agriculture, mapping, hydrology, forestry, oceanography, ice research, and coastal monitoring. In January 2006, Japan launched the Advanced Land Observing Satellite (ALOS) [
6]. The Phased Array type L-band Synthetic Aperture Radar (PALSAR) that it carried was an L-band SAR sensor that is not affected by atmospheric conditions, cloud cover, and other related conditions, so it can be used for ground observations around the clock. In June 2007, the Terra SAR-X was launched by the German National Space Center. Its X-band SAR radar reliably provided high-resolution weather conditions and wide-area radar images with superior geometric accuracy over any other spaceborne SAR sensor [
7]. Moreover, for both civil and military applications, it is desired to monitor moving targets, including ground moving target indication/ground moving target imaging (GMTI/GMTIm) [
8,
9].
For SAR processing systems, SAR imaging time accounts for most of the processing time, and directly brings a significant impact on system throughput and rapid response capability. The imaging delay of SAR will seriously affect the subsequent image processing, such as content analysis, risk diagnosis, and feature extraction. SAR imaging efficiency plays a very important role in the SAR system platform, and it can directly affect the throughput and rapid response capability of the entire platform.
Spaceborne and airborne real-time SAR imaging is the most direct and effective real-time imaging implementation approach, which can quickly provide SAR image data for SAR applications while significantly reducing the communication burden of air-to-ground data links [
10]. At the same time, the working environment of spaceborne and airborne imaging systems is harsh, and the power consumption of the processor is also severely limited. Therefore, real-time and low power consumption are two essential items that must be met by spaceborne/airborne SAR imaging processors.
Since SAR imaging requires a large amount of two-dimensional parallel computing, it is difficult for a single multi-core central processing unit (CPU) to meet its real-time requirements. The SAR imaging scheme with multiple CPU nodes has high power consumption and low processing efficiency, and cannot be applied in spaceborne/airborne SAR processing. Generally, heterogeneous schemes such as CPU + GPU, CPU + DSP (s), and CPU + FPGA (one or more) can meet the performance requirements of real-time processing, but their power consumption is above 10 W, or even more than 100 W. A dedicated chip that fully implements the imaging algorithm can achieve better results in real-time, and low power consumption and is suitable for applications with strict power constraints, but the scheme hardens the algorithm, resulting in poor flexibility. ASIP (Application Specific Instruction Set Processor) is a dedicated processor solution between a general-purpose processor and an application specific integrated circuit (ASIC). This processor combines the flexibility of a general-purpose processor and the efficiency of an ASIC. In order to achieve a good trade-off between flexibility and processing efficiency, the development of a dedicated processor that is capable of fully implementing the SAR imaging process is an effective solution to meet its power consumption and real-time requirements for spaceborne/airborne SAR processing.
The chirp scaling algorithm (CSA) is one of the most commonly used algorithms for SAR imaging [
11]. Its calculations mainly include Fast Fourier Transformation/Inverse Fast Fourier Transform (FFT/IFFT), phase multiplication, interpolation, etc., especially FFT/IFFT operations account for the highest proportion. The accuracy requirements and computing flow of these operations are different. Therefore, how to design an array structure and storage structure suitable for such processing is a key issue to be solved.
With the progress of integrated circuit (IC) technology, more processing units and memory blocks can be integrated on a single chip. Based on the abundant computational and memory resources on the chip, to make full use of bandwidth resources, this paper proposes a heterogeneous array structure that efficiently supports CSA imaging processing by combining block parallelism and pipeline processing while buffering the intermediate results on-chip.
It can support the parallel and pipeline processing and increases the maximum utilization of computing units. Moreover, we have designed an on-chip multi-level data buffer structure matching the heterogeneous array structure to ensure data supply for pipeline processing. This solution can reduce the complexity of the system while improving real-time performance.
The paper is organized as follows.
Section 2 outlines related work and background.
Section 3 analyzes the characteristics of CSA and proposes the design of the processor.
Section 4 presents the heterogeneous architecture implementations. We present the evaluation of experimental results in
Section 5, and the conclusions in
Section 6.
2. Related Work
Digital signal processors (DSPs), CPUs, and graphics processing units (GPUs) have respective advantages in real-time SAR processing. As the system adopts CPU, it has good flexibility and portability [
12]. However, their power efficiency for computing is quite low, which is a bottleneck in real-time SAR applications. Due to GPU’s powerful parallel computation capability and programmability, the new method makes full use of GPU’s powerful computation ability, which effectively improves the real-time quality of SAR scene generation [
13,
14,
15,
16]. At present, the GPU + CPU method can effectively combine the advantages of the two processors to improve imaging efficiency [
17,
18]. However, the average power consumption which is up to 150 W, limits the application of GPU in micro air vehicles.
Nowadays, high capability DSPs easily realize many complex theories and algorithms on hardware, and promote the development of SAR technology [
19,
20,
21]. In 2003, Hanover University implemented a SAR real-time processing system using a multi-DSP architecture. This system uses highly parallel digital signal processor technology (HiPAR-DSP) for SAR signal processing [
22]. The Indian Space Research Organization (IRSO) developed the SAR Specialized Processor (NRTP) based on Analog Devices’ DSP multiprocessor, which approximates the real-time imaging of SAR [
23]. However, for some applications with strictly constrained power, DSP has lower energy efficiency, resulting in lower imaging efficiency.
The rapid development of field-programmable gate array (FPGA) has been one of the most important technologies of realizing digital signal processing. With its rich on-chip memory and computational resources, FPGA can be configured as a SAR imaging platform to meet the high throughput rate SAR signal processing requirements [
24,
25,
26]. An FPGA based on fault-tolerant architecture (Xilinx Virtex-II Pro) is applied to SAR processing systems [
27,
28]. In 2006, the University of Florida developed a high-performance heterogeneous spatial computing framework based on hardware/software interfaces. In this architecture, the CPU is responsible for scheduling and task management, and the FPGA acts as a coprocessor for computational acceleration [
29]. With the rapid development of storage capacity and computing power of commercial FPGAs, SAR real-time imaging systems can all be built by FPGA (Xilinx Virtex-6) [
30]. However, for highly complex algorithms, the development cycle of FPGA is relatively long.
For the real-time requirements and physical implementation limitations of SAR imaging, ASIC implementation is generally employed [
31,
32]. The Massachusetts Institute of Technology (MIT) Lincoln Laboratory uses bit-level systolic-array technology to design a SAR signal processor with high throughput and low power consumption [
33]. The jet propulsion laboratory has also developed an airborne SAR processing system using a VLSI+SOC (very large scale integration+system on chip) hardware solution [
10]. The processor’s low power consumption and small size make it suitable for small SAR imaging systems.
In general, the DSP solution is used to implement SAR imaging through software programming. Since the DSP is designed for general purposes, this implementation has high flexibility and a short design cycle. It is more suitable for real-time SAR imaging than a CPU, but for low power applications, it is still not the most suitable choice. The ASIC solution for SAR imaging has the optimal power and performance for a single computational process. However, SAR imaging is a combination of multiple calculations on one device, which causes the design cost and power consumption of SAR imaging to soar, the design cycle to become longer, and poor flexibility. ASIP makes a good trade-off between the high flexibility of a general purpose processor and the high processing efficiency of an ASIC, and can be tailored and optimized for a certain type of algorithm or domain application to meet constraints such as performance, area, and power consumption. Moreover, it can effectively reduce design cycles and the design risk. Thus, many advantages of ASIP make it a very important implementation method in the field of signal processing.
Making trade-offs between speed, cost, power consumption, and flexibility, ASIP design methodology in the design of SAR real-time signal processing system can not only satisfy the real-time and performance requirements of aerospace systems, but also shorten the lead time of the processors. ASIP, when designed with a specific architecture with higher parallelism and higher complexity, also has good scalability. Therefore, we have designed a dedicated processor that can fully implement the SAR imaging process to meet the power consumption and real-time requirements of the application environment.
3. Processor Architecture Design
The CSA is one of the most commonly used algorithms for SAR imaging [
11]. Compared with other algorithms, the CSA has the advantages of a simple operation process, low computational complexity, and high imaging efficiency. On the other hand, the CSA improves the fidelity of the image, especially the preservation of the phase information. Moreover, the CSA can adapt to different radar scanning modes, for example, spotlight, strip-map, scan SAR, sliding spotlight, Tops, and Mosaic modes [
34,
35].
3.1. CSA Flow Analysis
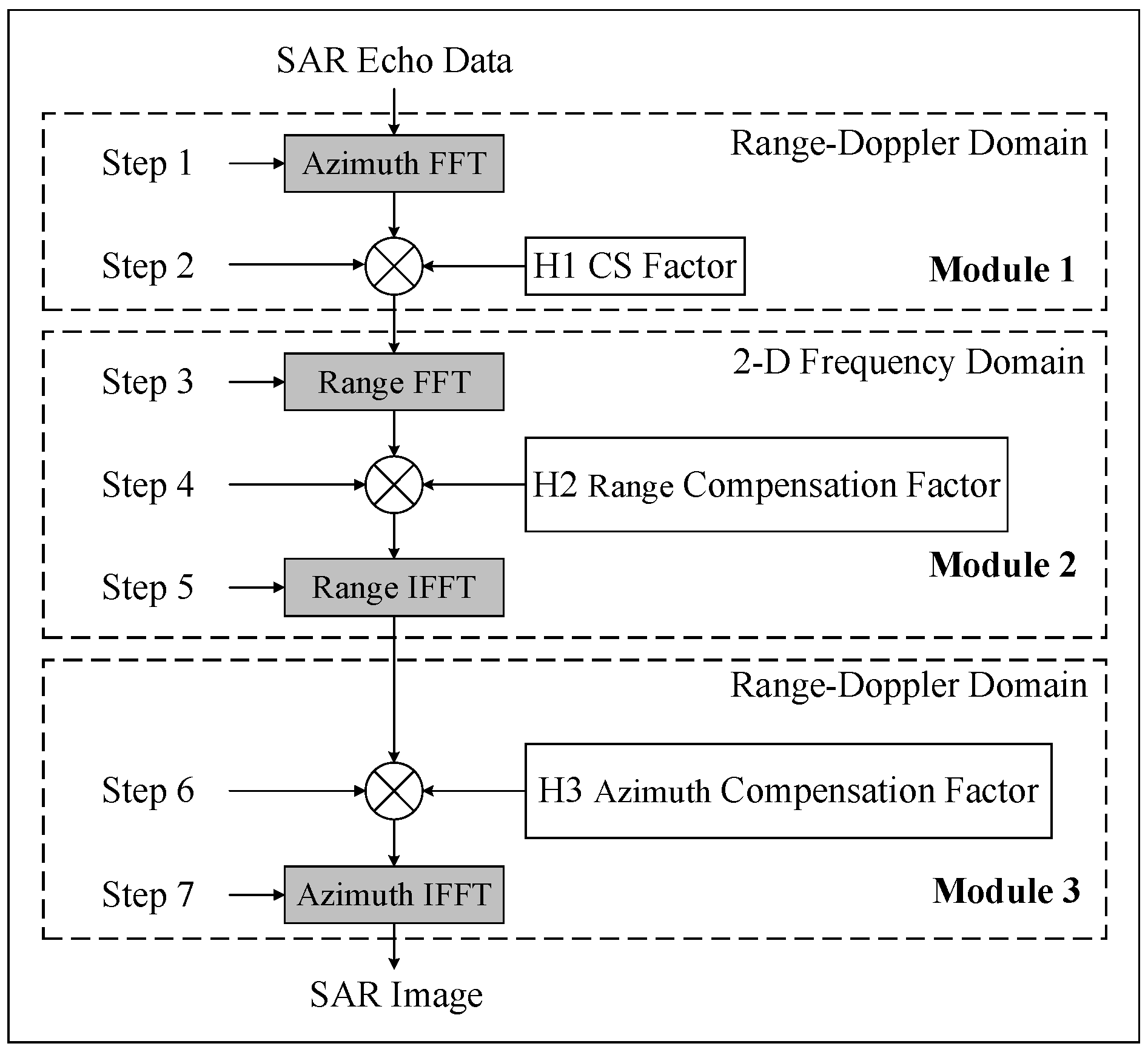
The imaging principle of the CSA is shown in
Figure 1. The CSA can be divided into three modules according to functions, or divided into seven steps according to the operation sequence. The algorithm is executed step by step, and in the algorithm process, we perform the alternating operation of FFT/IFFT and phase compensation. To perform a SAR imaging, four Fourier transform and three-phase multiplication are needed.
The Q-point FFT/IFFT can be decomposed into
real multiplications and
real additions [
36].
Table 1 lists the computation quantity of the seven-step operation.
From
Table 1, we can see that the proportion of FFT(IFFT) in all operations is:
For different imaging matrix sizes, the proportion W of FFT(IFFT) is slightly different, as shown in
Table 2. It can be shown from
Table 2 that the W values are basically above 90% and can reach up to 95% as the matrix size becomes larger. Therefore, accelerating the FFT/IFFT operation will inevitably reduce the imaging time and optimize the imaging efficiency.
3.2. Computation Flow Strategy
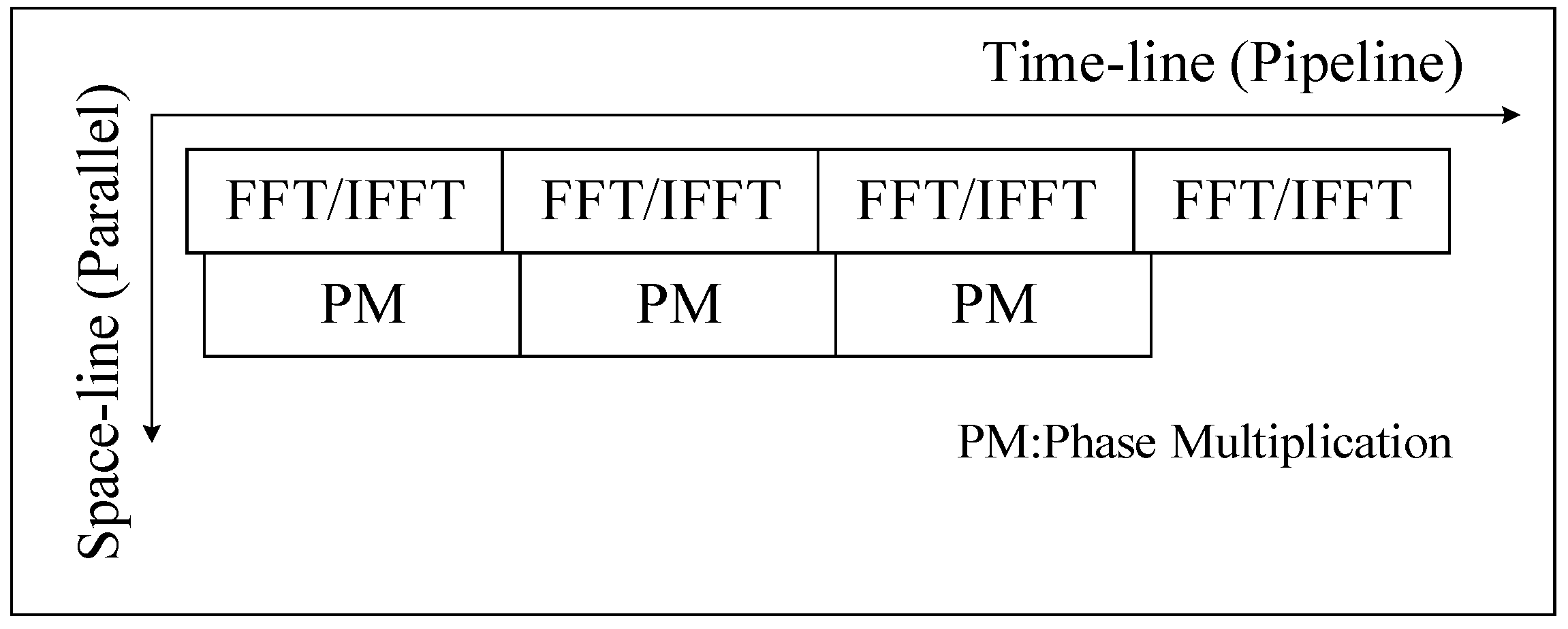
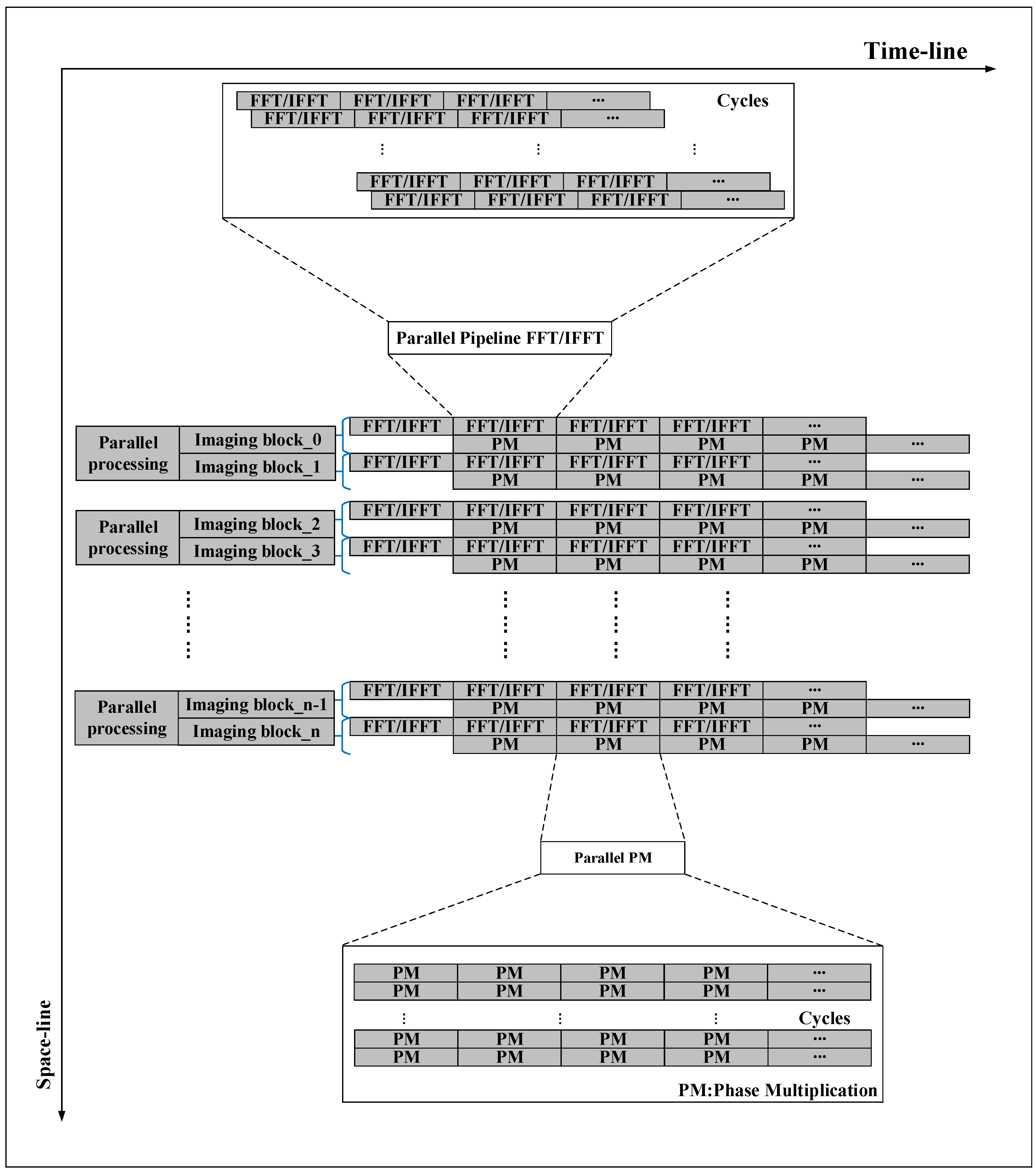
In the imaging process, we take the block imaging method and perform parallel processing between blocks. In the algorithm process, four FFT/IFFT and three phase operations are pipelined according to the algorithm flow, while each multi-range (multi-azimuth) FFT/IFFT and phase operation can be parallel processing individually. To organize the pipeline processing of two types of operations in SAR imaging, we designed a calculation process based on space–time flow (ST-Flow), as shown in
Figure 2. At a time, in space, multi-line FFT/IFFT can be performed in parallel, and phase compensation operation can be calculated simultaneously at multiple points, so no calculation unit is idle. On the timeline, data is continuously fed into the processing unit, and the calculation unit does not have a stall due to waiting for data. With this ST-Flow, SAR imaging can be done in a continuous process.
3.3. Heterogeneous Arrays
CSA includes scalar operation for phase multiplication and vector operation FFT (IFFT). As
Table 2 shown, FFT/IFFT operations account for up to 95% of SAR imaging, so accelerating the FFT/IFFT operation efficiently is the most important approach for imaging processors.
The fixed-point FFT/IFFT operation with lower accuracy has a small loss of imaging accuracy, and can significantly improve the processing throughput. In [
37], the quantization error power of the fixed-point processing CSA was evaluated in detail. The analysis results showed that as the word length increases from 12 to 16, the quantization error power remains essentially unchanged, and the imaging quality with a 15 or 16-bit word length is very close to that of a single precision floating-point. Therefore, we design PE arrays to support 12-bit, 14-bit, and 16-bit fixed-point FFT/IFFT. For applications with lower accuracy requirements, low-bit width operation can be selected.
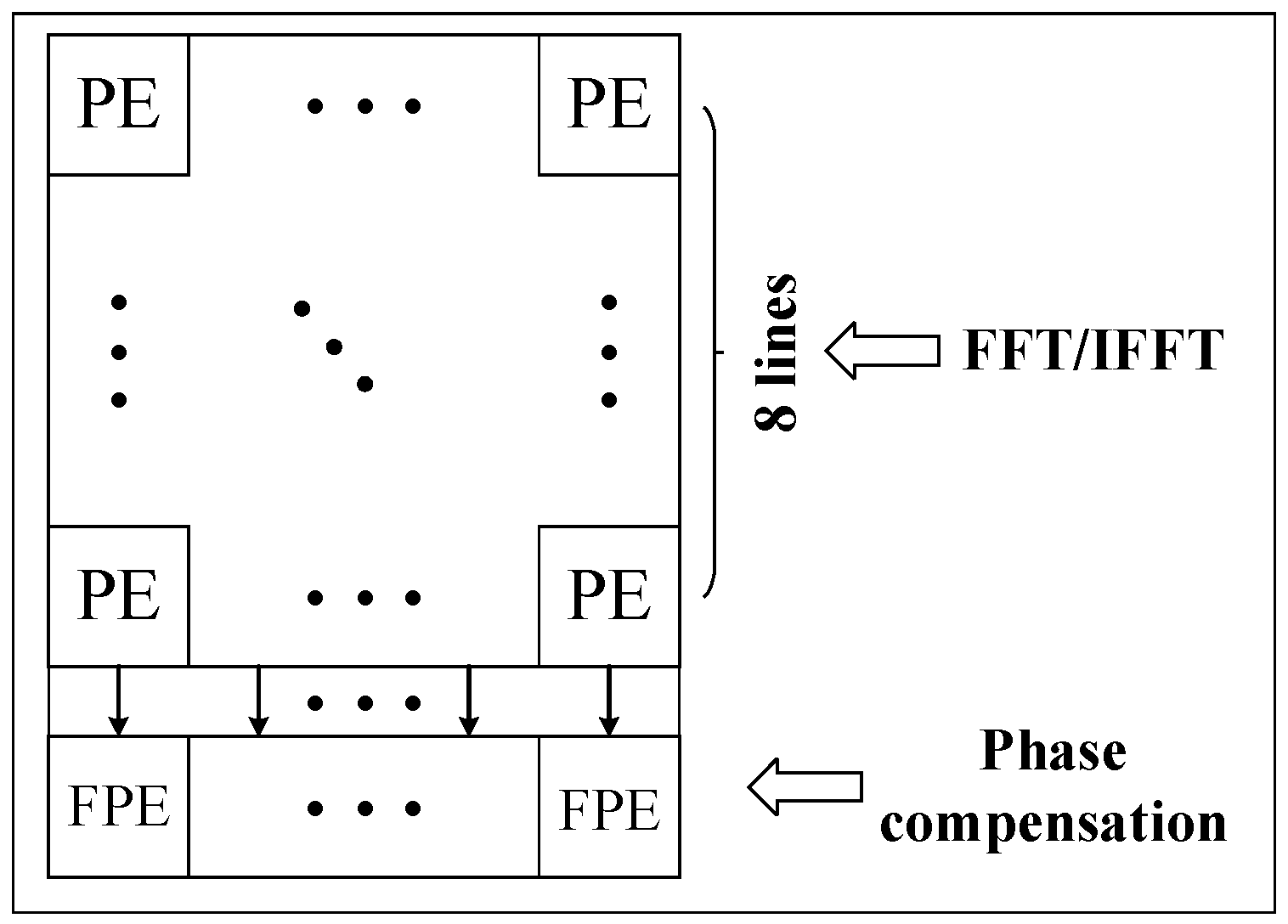
However, the phase compensation operation requires high precision and must use floating-point arithmetic operations. Based on the earlier description and discussion, a heterogeneous array is designed, which includes two types of computing units named PE and FPE. PE is used for FFT/IFFT operation and FPE is used for phase compensation operation.
Since the operation ratio of FFT/IFFT against phase compensation is approximately 9:1, the configuration of PE and FPE should also follow this proportional relationship. For smaller matrix sizes, the ratio is near 90%; to meet the different matrix sizes, we design the processing array, in which the ratio of PE and FPE is 8:1, as shown in
Figure 3.
In CSA flow, each range/azimuth FFT/IFFT operation is relatively independent, and there is no data dependency between range/azimuth, so each range/azimuth FFT/IFFT operation can be performed in parallel. Moreover, in the FFT/IFFT operation, each butterfly operation is relatively independent, and multiple butterfly operations can be performed in parallel. The phase compensation process performs independent operations at a single point so that multiple independent operations can be performed in parallel.
In CSA flow, four FFT/IFFT and three phase operations are data dependent; they are processed in the pipeline. As shown in
Figure 4, to establish a pipeline between the FFT and the phase operation, the parallel FFT/IFFT differ by 1/8 computation cycles.
3.4. Data Placement and Simultaneous Access
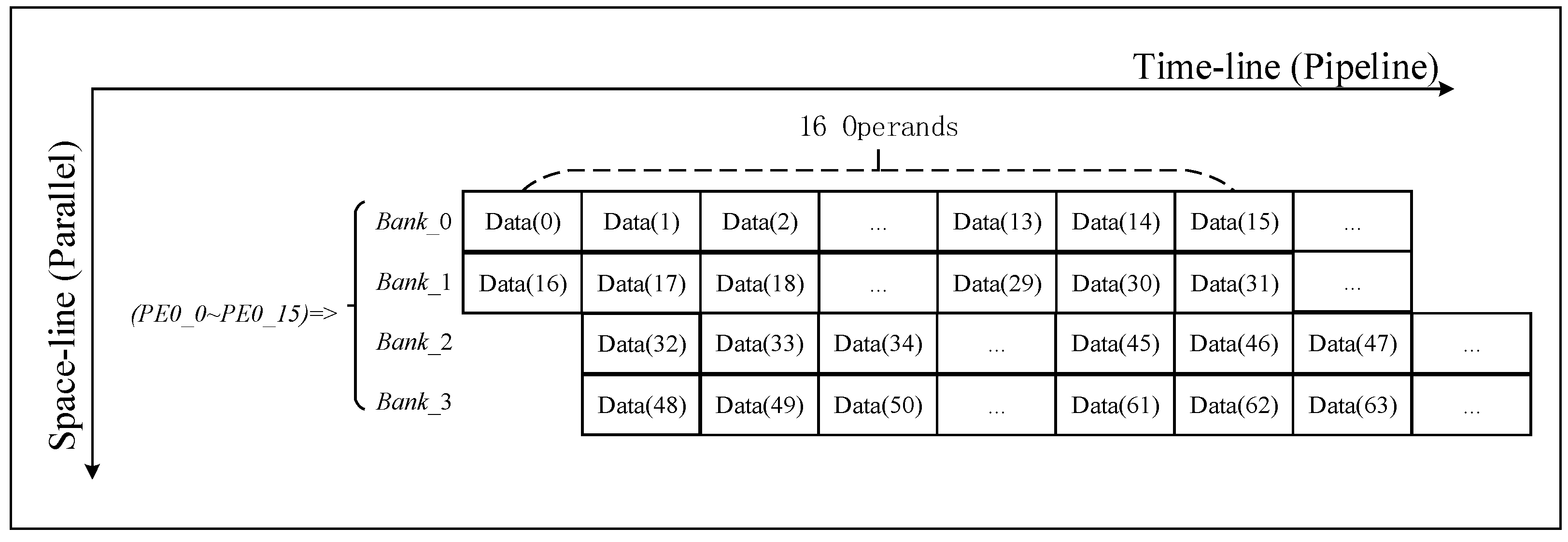
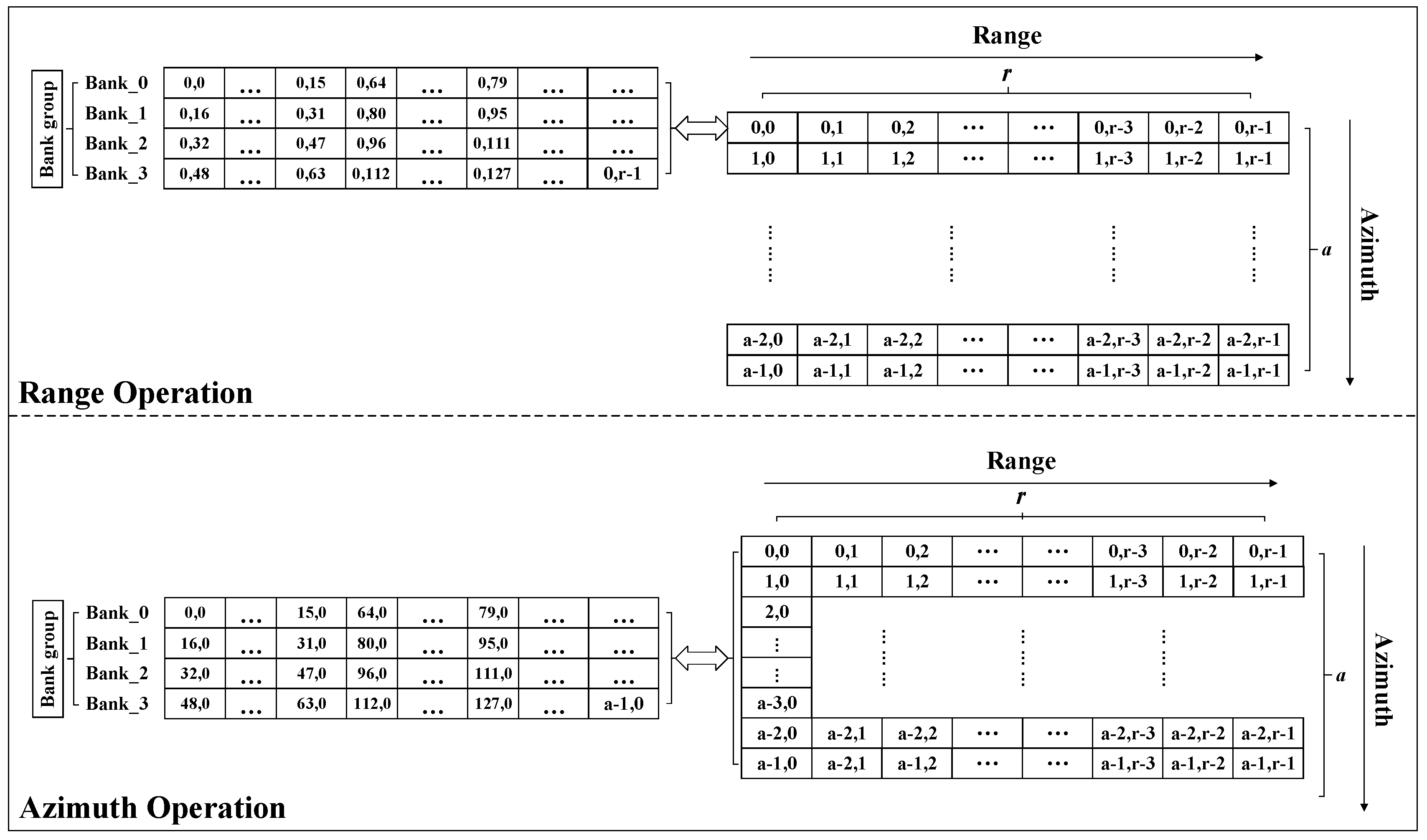
In the FFT/IFFT process, the data transfer has a bit-reverse address sequence. To support this data access pattern, we use a multi-bank distributed data placement strategy, as shown in
Table 3. According to the calculation requirements, one row of PE parallel performs 16 butterfly operations, and needs to provide 32 data at the same time. Therefore, data access is performed in parallel. As shown in
Figure 5, 32 data are simultaneously accessed from Bank 0 and Bank 1 in the first cycle. In the second cycle, data are read simultaneously from Bank 2 and Bank 3. Bank selection and the address in a bank are generated to follow each step in the FFT/IFFT processing flow. Although each PE performs a different FFT/IFFT operation, they use similar data placement and access strategies.
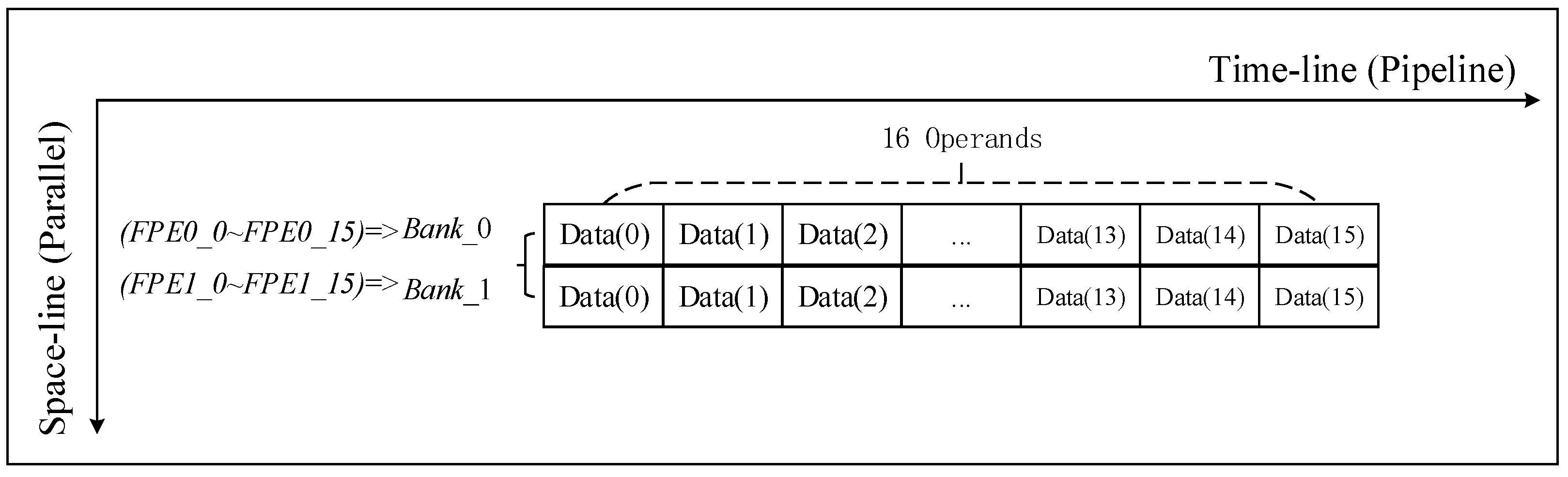
There is no special requirement for the sequence of data in the phase compensation calculation process; therefore, as shown in
Figure 6, the calculation process only needs to access the data in parallel.
4. Architectural Implementations
4.1. Overall Architecture
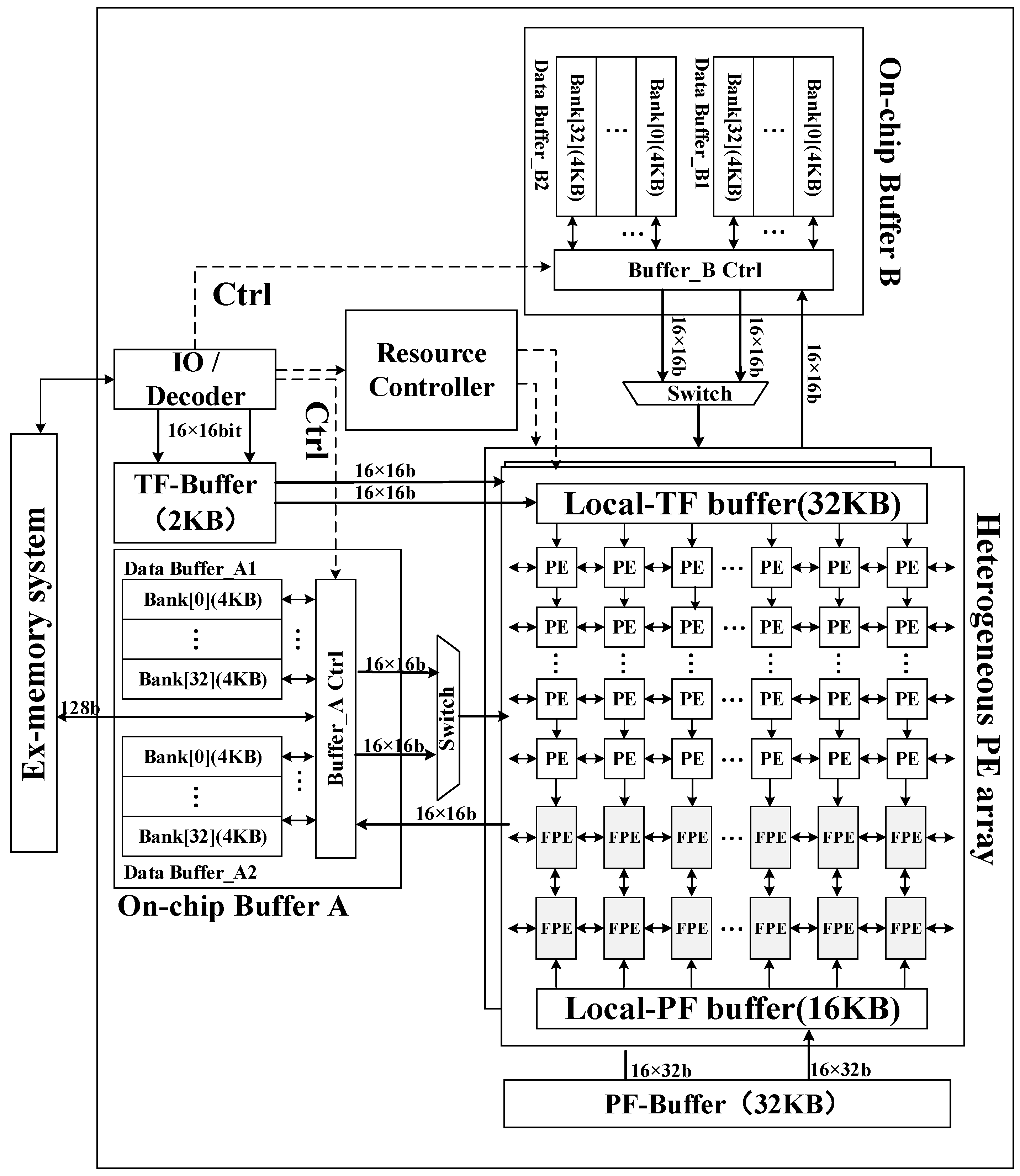
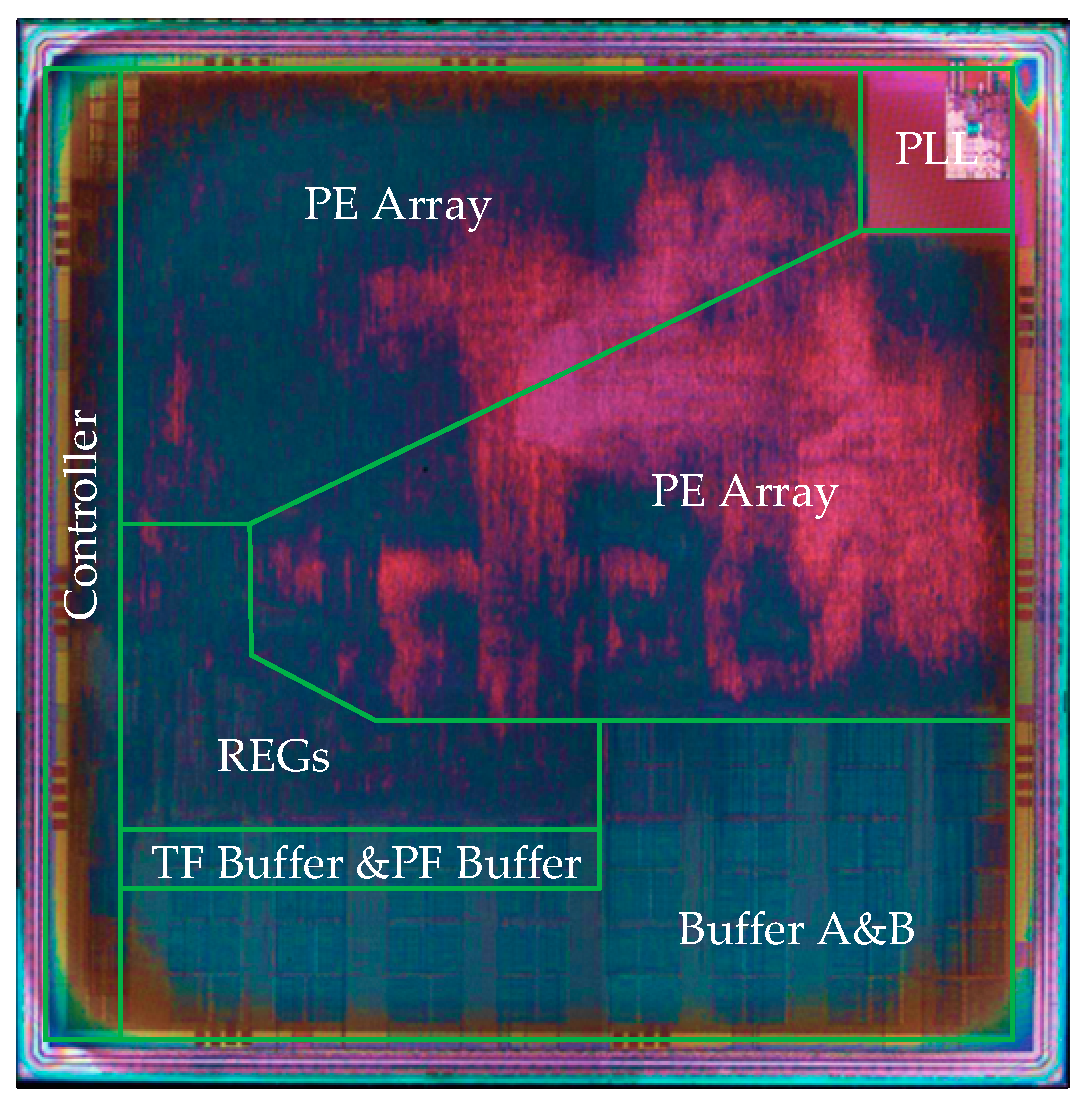
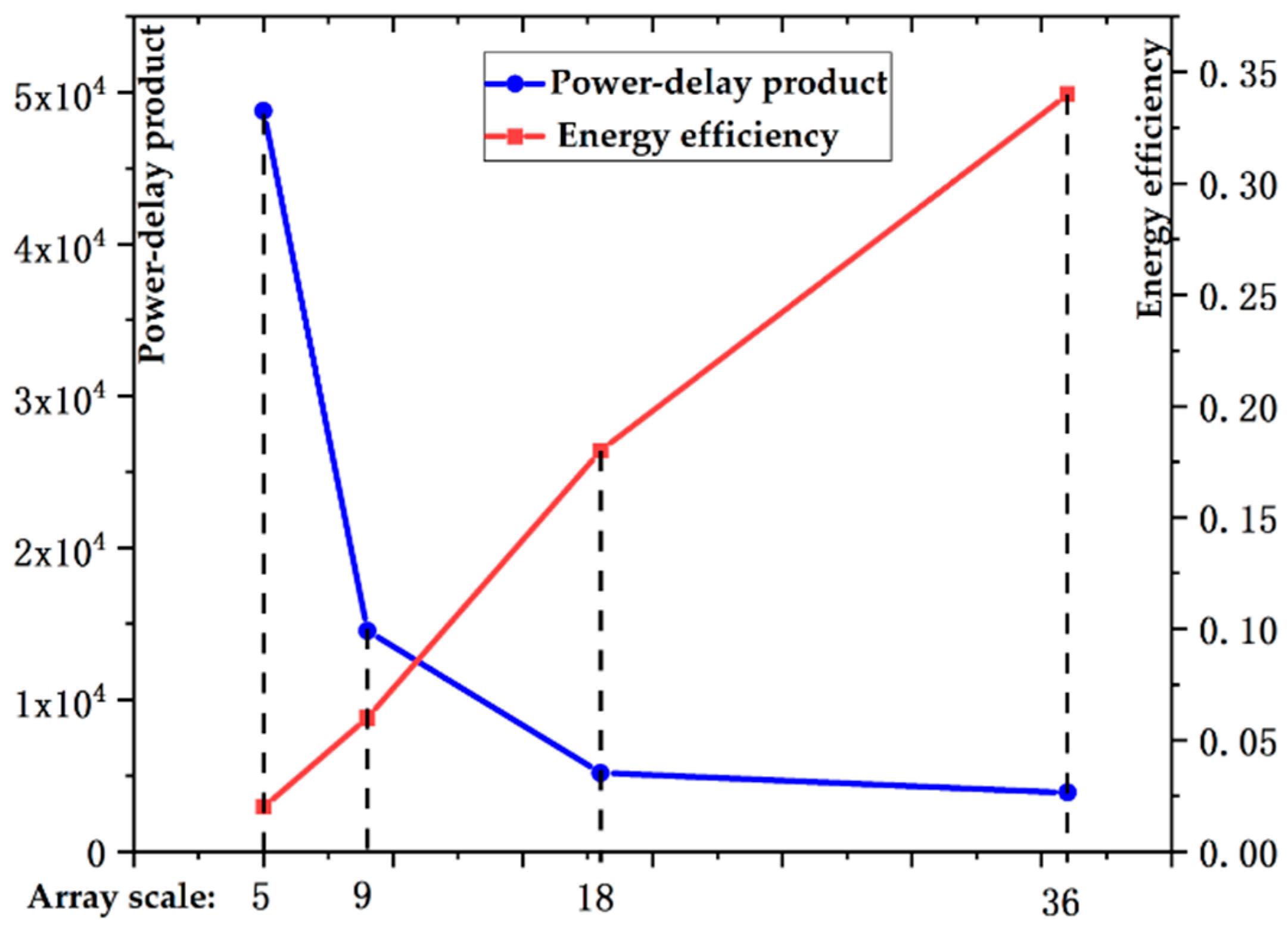
A highly efficient heterogeneous processor for SAR imaging is designed.
Figure 7 shows the top-level architecture of the proposed SAR imaging processor. This section describes the overall hardware block diagram and functional modules. Essentially, the architecture consists of three major components: a hybrid–PE array, an on-chip buffer module, and a data systolic engine.
To meet the throughput requirement of SAR imaging, two identical sets of heterogeneous arrays are implemented, which can perform different block imaging processing computations in parallel. Each of the heterogeneous arrays contains 16 × 16 PEs and 2 × 16 FPEs. The number ratio of PE and FPE satisfies the proportional relationship of 8:1.
To feed the processing array with adequate data supply, three types of buffers are implemented on chip. In a processing array, all the data banks for 16-line PEs and two-line FPEs are organized as a 264-KB data buffer with two sub-buffers, each of which contains 32 banks for PEs and one bank for an FPE. A 32-KB twiddle factor dedicated local buffer (Local-TF buffer) and a 16-KB phase factor dedicated local buffer (Local-PF buffer) for the phase compensation operation is also implemented inside a processing array.
To organize the data transfer between off-chip RAM and on-chip buffers, a data systolic engine is implemented. With this data systolic engine, the input raw image echo can be read and the imaging output can be written back following the processing flow.
4.2. Heterogeneous PE Arrays
Each PE pipelined performs a four-point butterfly operation in six cycles, and all of the PE in a row parallel perform butterfly operations in a block. During the FFT/IFFT operation, all 64 input data are sent to one row of PEs in two cycles from the data buffer, and the 64 output data are written back to the data buffer in two cycles.
In a heterogeneous array, as shown in
Figure 7, PEs are interconnected to pass a twiddle factor, the Local-TF buffer distributes the twiddle factor to the PE from top to bottom. The twiddle factor passes two rows down each cycle, and the required twiddle factors are assigned to 16 rows of PEs in eight cycles. Besides, each PE supports zero-padding to expand the raw data to an integer power of two.
During the phase compensation operation, the two input data banks send 32 input data to two rows of FPEs (32 FPEs) in parallel. The Local-PF buffer passes and distributes the phase compensation factor from bottom to top.
4.3. Alternate Systolic-Memory and On-Chip Buffer Organization
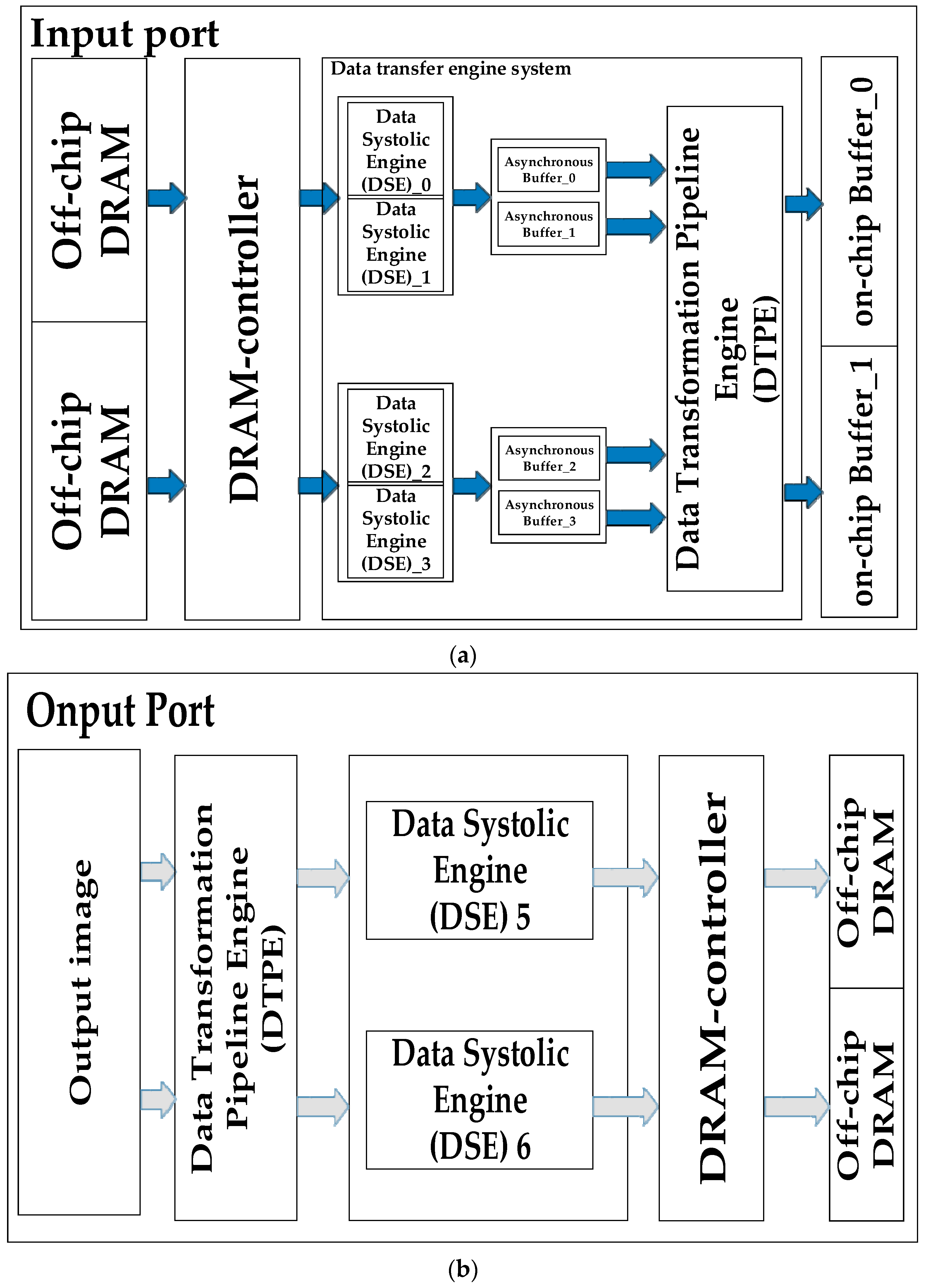
Since on-chip memory space is limited, all of the radar echo data is stored in the external memory first. As shown in
Figure 8, the data systolic engine (DSE) fetches the data from dynamic random access memory (DRAM) and pushes the data into on-chip memory. To hide the communication latency of data transfer between DSEs and arithmetic components, we employ the alternate systolic technique. In order to avoid DSE competition in hardware resources, we use two alternate systolic memory modules for each of the input/output interfaces for the whole system. At the same time, we adopt two DSE channels for input data and weight at the input end. The proposed memory architecture can provide 4 GB/s of read/write memory bandwidth at 250-MHz frequency to satisfy the data requirements of the processor.
As shown in
Figure 8, our storage architecture consists of three layers: DRAM, a data transfer engine system, and an on-chip buffer. Since the on-chip storage resources are limited in size, all the pending radar echo data is first stored in off-chip memory (DRAM). During data processing, the data is first cached by the data transfer engine system into the on-chip buffer, and then sent to the PE array for processing by the on-chip buffer. As shown in
Figure 8, in order to hide the communication latency between the off-chip memory and the on-chip buffer, we use the double-buffered data alternate transmission method.
4.4. Resource Controller
The resource controller is responsible for allocating the execution unit and arranging the access flow of the on-chip buffer.
Two imaging blocks are respectively assigned to two arrays for parallel processing. The FFT/IFFT and phase compensation operations are involved in the intra-block processing, so the PE is assigned to the FFT/IFFT during the calculation and the FPE is assigned to the phase compensation operation.
According to the designed data mapping and access strategy, in order to support the parallel access of data, the resource controller allocates bank and bank addresses for each range of data. When performing range FFT/IFFT, each row of data is stored in four banks according to a distributed storage strategy.
As shown in
Figure 9, we take a row of 1024 points as an example (
r = 1024). When performing FFT/IFFT, 1024 points are segmented and stored in four banks according to the distributed storage strategy. A total of 16 consecutive points are used as a segment, in which approximately 0 to 15 are placed in Bank_0, 16 to 31 are placed in Bank_1, 32 to 47 are placed in Bank_2, and 48 to 63 are placed in Bank_3; the above operation is repeated until all data of 256 segments are stored. A base-4 FFT/IFFT operation at 1024 points requires a total of five levels of operation. The calculation process uses multi-bank parallel data access. Taking the first stage as an example, data 0 to 31 is read from Bank_0 and Bank_1 in the first cycle, and data 992 to 1023 is read from Bank_2 and Bank_3 in the second cycle. The latter four levels of the operational data access process are similar to the first level.
Similarly, when performing azimuth FFT/IFFT, each azimuth of data is stored in four banks according to the storage strategy (taking 1024 points as an example, a = 1024). The data access process is similar to the FFT/IFFT range.
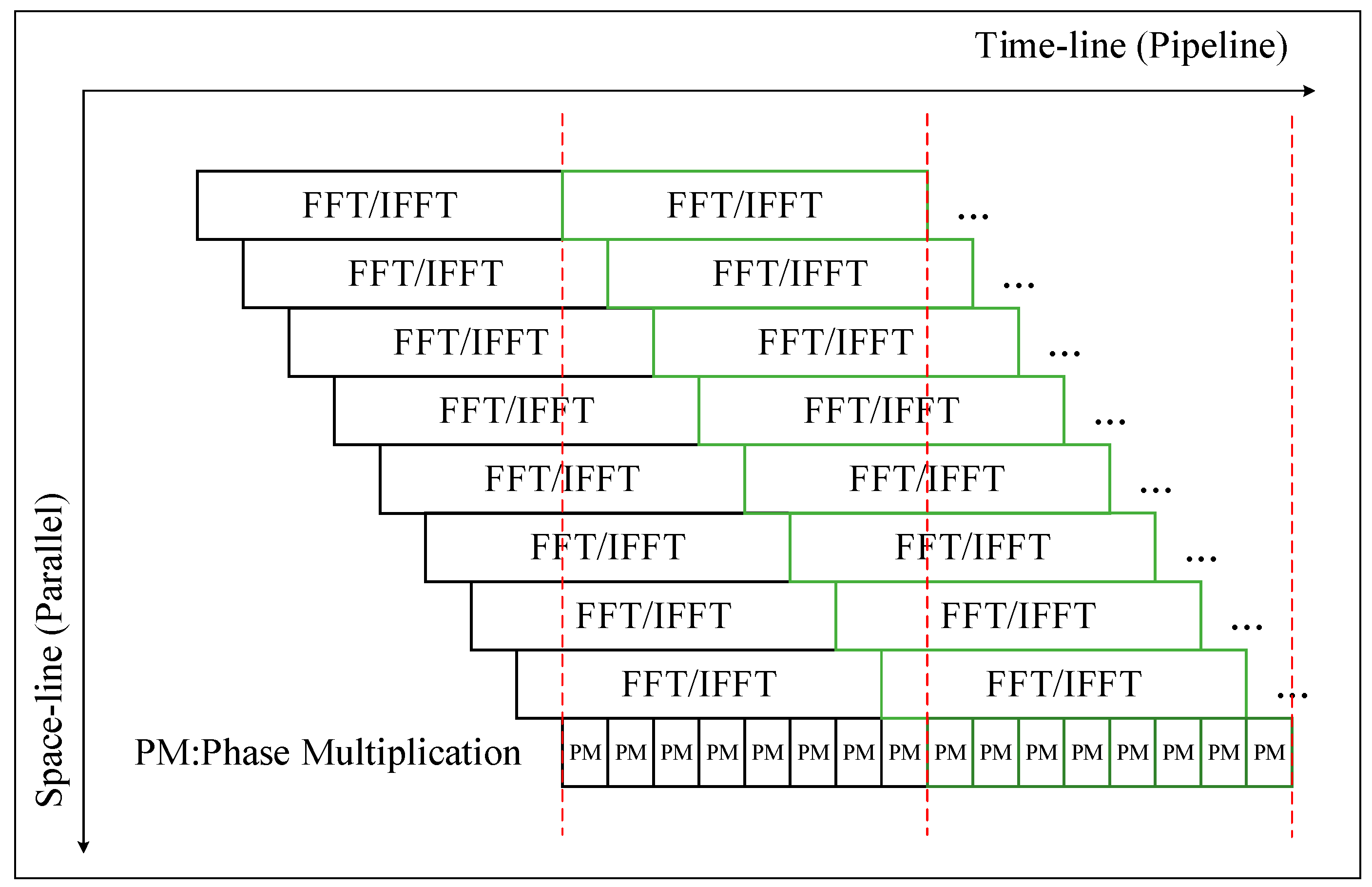
SAR imaging is a continuous process with huge differences in operational density between FFT/IFFT and the phase compensation operation. For the characteristics of the computational process, we have designed a way to organize the processing of SAR imaging in space and time flow (ST-Flow), as shown in
Figure 10.
Taking 1024 points FFT/IFFT as an example, each FPE performs a one-point phase compensation operation in one cycle, and all the FPE in a row parallel perform phase compensation operations. During the phase compensation operation, all 16-input data are sent to one row of FPEs in one cycle from the data buffer, and 16 output data are written back to the data buffer in one cycle. It can be seen that the 1024-point phase compensation operation requires 64 cycles. In order to satisfy the task saturation and parallelism of the parallel pipeline between phase compensation and FFT/IFFT, the resource controller sets the start time for each row of PE to be delayed by 64 cycles from the previous row. Considering the different matrix sizes, the ratio of PEs to FPEs is configured to be 8:1, so for larger matrices, the FPE will be idle. During the processing of the FPE, it is necessary to wait for the PE to complete the FFT operation before starting the processing of the next frame.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}