Implementation of a Depth from Light Field Algorithm on FPGA


Abstract
:1. Introduction
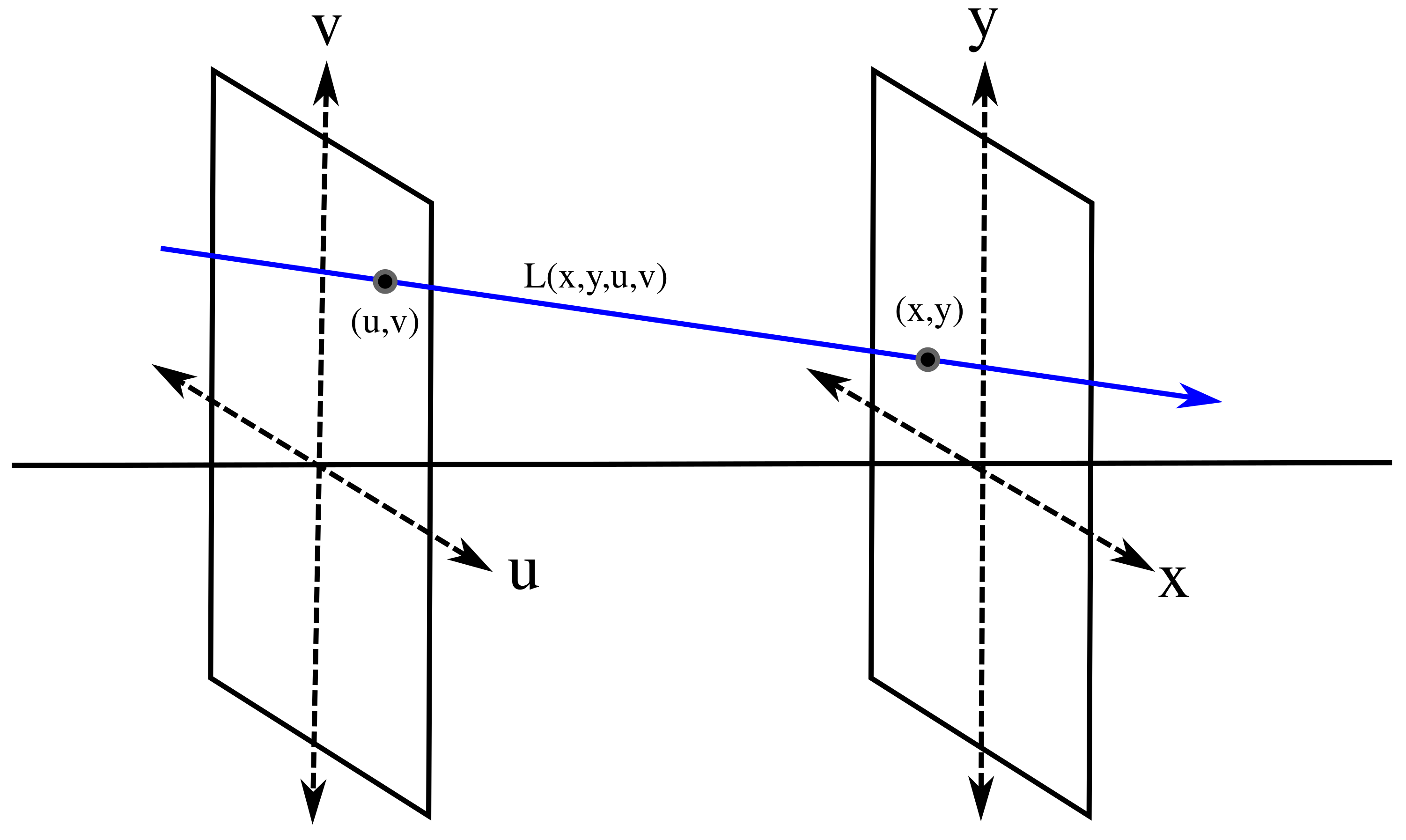
1.1. The Light Field and How It Encodes Depth
1.2. The Light-Field Pipeline
1.2.1. Capture
- Camera arrays: This technique consists of placing a set of cameras on a plane at equally spaced distances. Examples of this capture technique can be found in [6,7]. These kinds of devices were initially considered to be very bulky and difficult to operate, but with the advent of smart phones, the size of cameras has been considerably reduced and a portable camera array design is not so unrealistic.
- Plenoptic cameras (spatial multiplexing): The plenoptic camera is the most well known light-field capturing device [8,9,10,11]. It consists of a microlens array placed between the main lens and the sensor of a conventional camera. The microlenses spread the spatial information and the angular information contained in the light field over a 2D sensor. The main advantage is the compactness, since it is similar in size to a conventional camera. However, it has the drawback of having to trade-off between spatial resolution and angular resolution, because both are spread over the same sensor [12]. This means that the spatial resolution is reduced in comparison to conventional cameras.
1.2.2. Decoding and Rectification
1.2.3. Processing
- Light-field rendering: This type of algorithm computes a new 2D image or a set of such images from light-field data. Isaksen et al. [25] proposed a reparameterization to generate images on a general surface from light fields. However, the most prominent algorithm in this category, which is used for the computation of the focal stack, was proposed in [26]. The main drawback of this focal-stack algorithm is the low spatial resolution of the outcoming images. To overcome this drawback, superresolution algorithms were proposed [27,28,29,30,31,32]. Other authors have also proposed techniques to accelerate the computation or to make it more accurate [33,34].
- Depth from light field: The goal of depth from light field algorithms is to extract depth information from the light field and provide a depth or disparity map that can be sparse or dense. Several approaches can be adopted to perform this processing task. One strategy is to convert the light field into a focal stack (that is, a set of images focused at different depths) using light-field rendering techniques and then estimate depth by applying a depth from focus algorithm [35,36,37]. Another group of techniques is based on the computation of the variance focal stack to extract depth information [28,34,38]. Berent and Dragotti [39] decided to use image segmentation techniques on light fields to detect the plenoptic structures that encode the depth information, as mentioned in Section 1.1. Other authors use differential operators to detect the slope of plenoptic structures [8,40,41,42]. In [43], robust PCA is used to extract depth information from plenoptic structures. On the other hand, Kim et al. [44] developed a depth estimator for high spatial angular resolution light fields, while Jeon et al. [45] present an accurate method for depth estimation from plenoptic camera. In [46], the authors proposed a pipeline that automatically determines the best configuration for the photo-consistency measure using a learning-based framework. Recently, the use of convolutional neural networks to estimate depths from a light field has been investigated [47,48,49].
- Tracking and pose estimation: As the light field encodes 3D information about the scene, it can be used in visual odometry and navigation. In [55], theoretical developments to extract pose information from light fields were presented. In [56], some algorithms for visual odometry were given. Further explorations in this application field can be found in [57,58,59]. Also some studies focused on using the technology in space applications [60,61]. The light field features in scale space and depth proposed in [62] can also be included in this category of algorithms.
1.3. Light-Field Processing on FPGA
1.4. Goals and Contributions of This Paper
2. Implementation
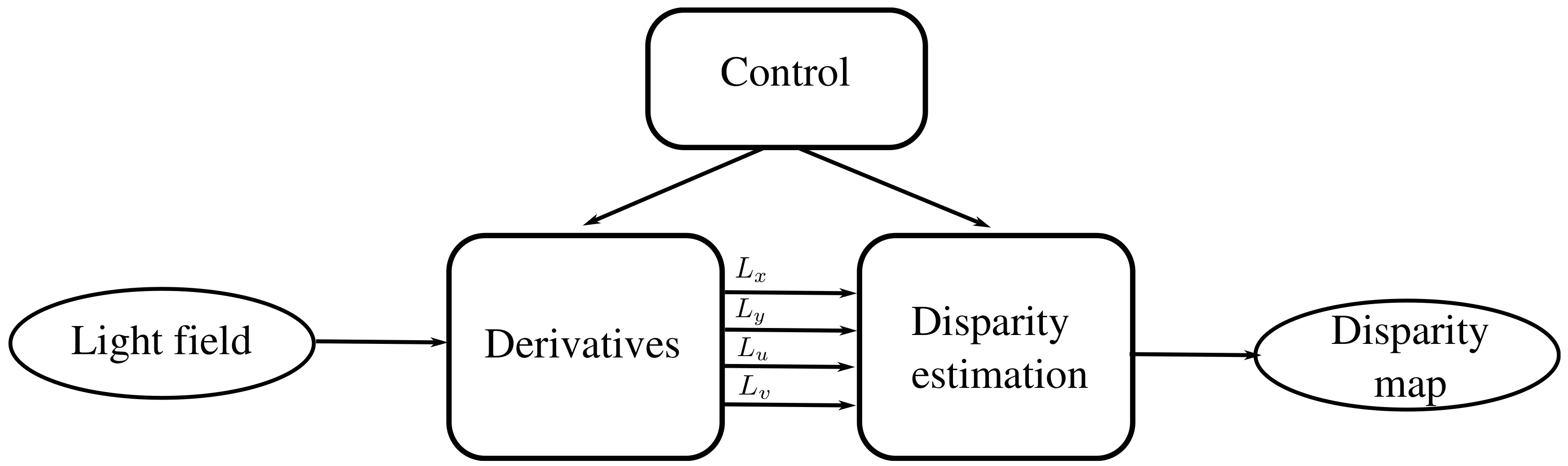
2.1. The Algorithm
| Algorithm 1: Local depth from light-field algorithm. |
 |
2.2. System Architecture
2.3. Data Input Format Considerations
2.3.1. Serial Input
| Algorithm 2: Computation of partial result for a given input pixel |
 |
- The four derivatives can be performed in parallel.
- The ‘for’ loops may be performed in parallel as there is no dependency between iterations.
- Each time a pixel arrives, its product with a subset of 9 of 81 possible filter coefficients must be calculated.
2.3.2. View Parallel Input
| Algorithm 3: Computation of partial result for a given parallel input pixel set. |
 |
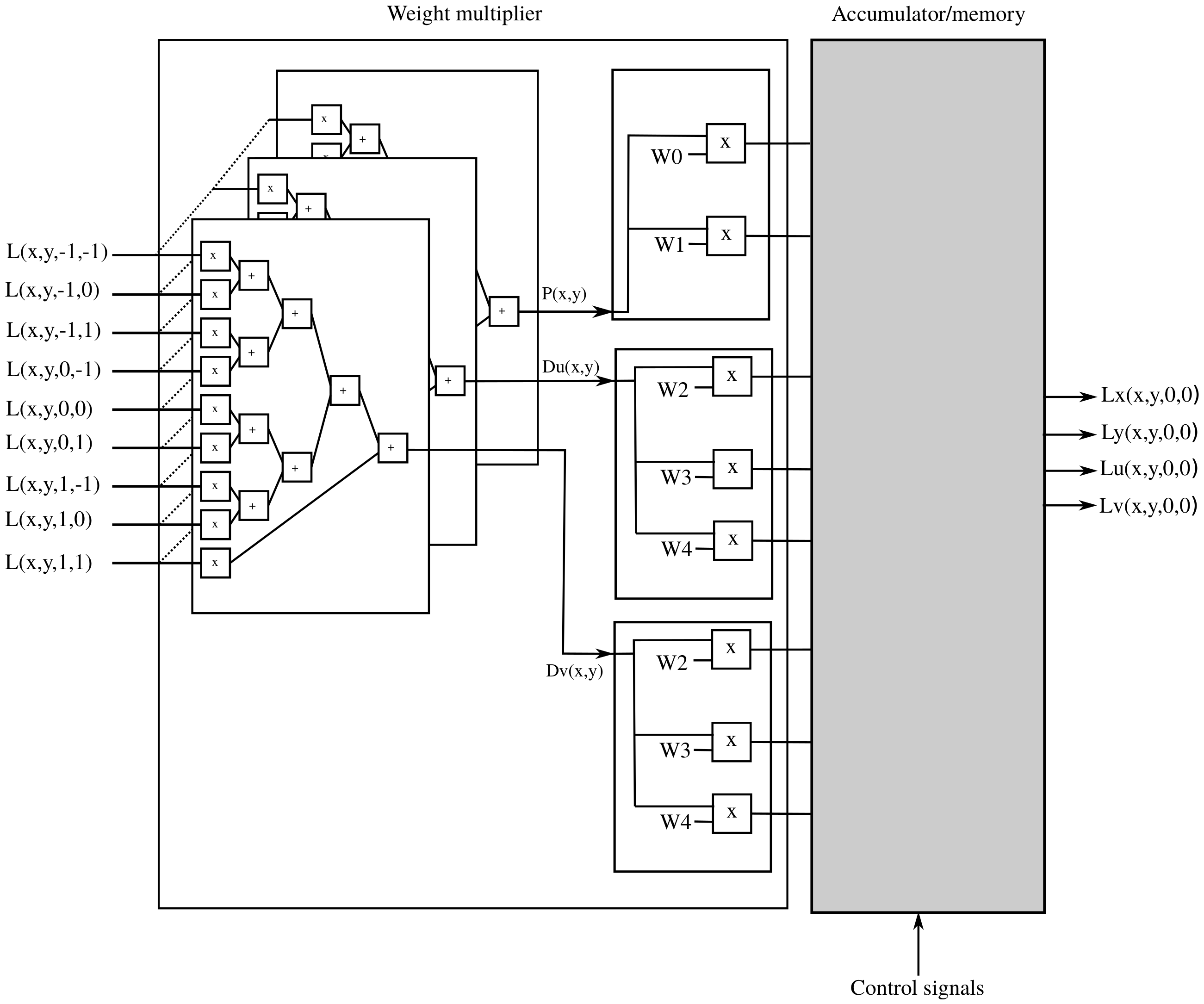
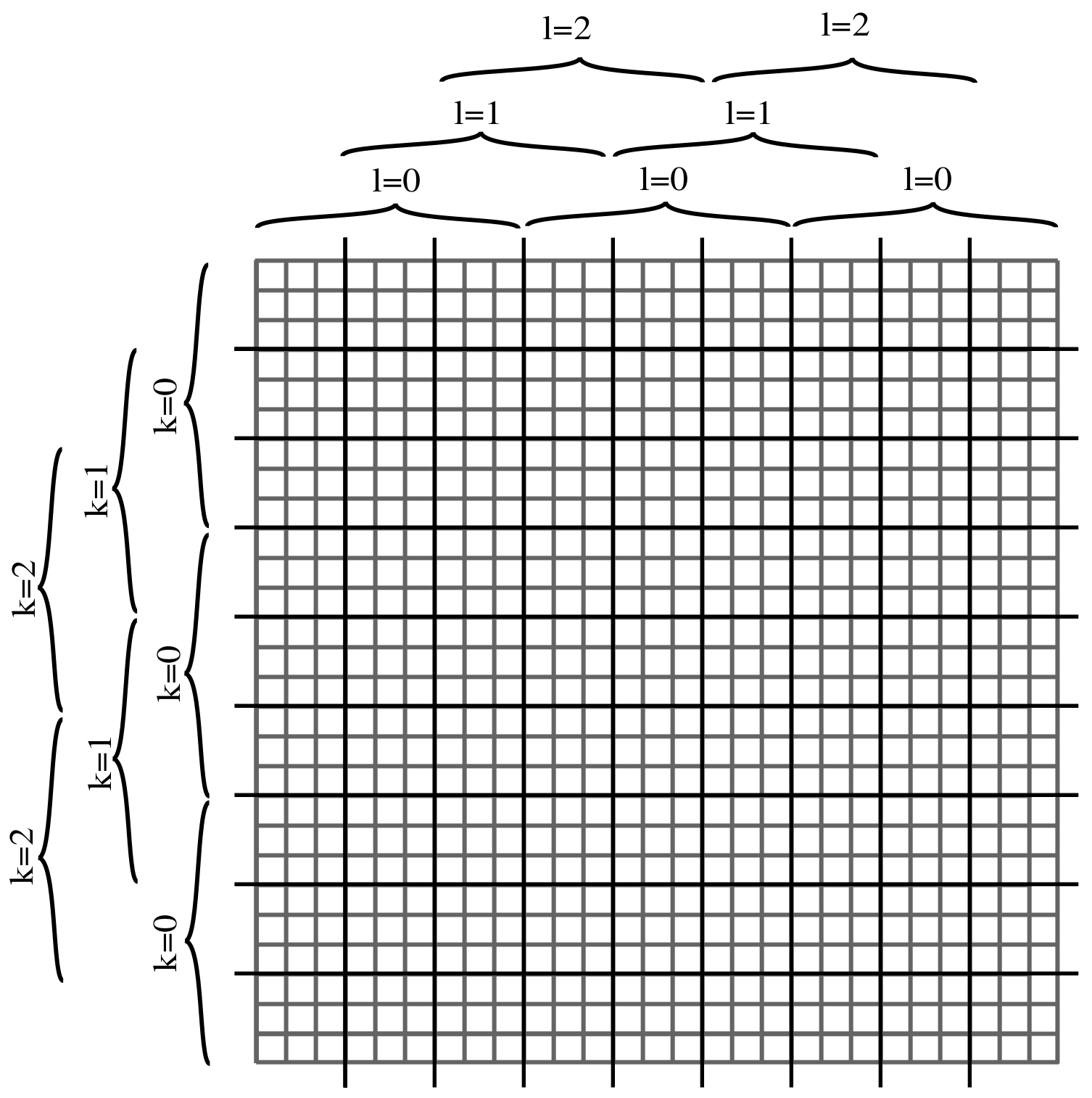
2.4. Accumulator Memory Grid
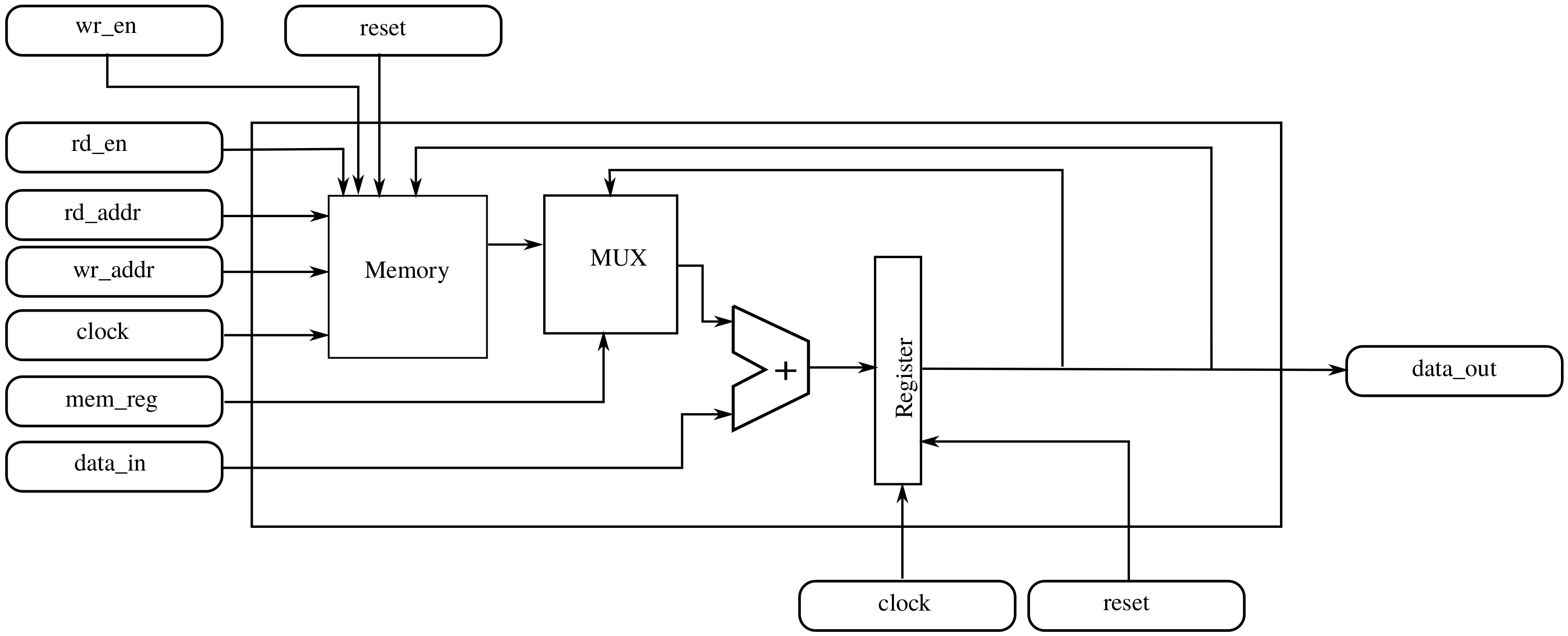
2.4.1. Basic Component
2.4.2. Basic-Component Grid
2.5. Disparity Estimation
3. Experiments and Testing
3.1. Material
3.2. Testing Methods
3.3. Test Data
4. Results
4.1. Logical Resources and Execution Times
4.2. Gradient Estimation
4.3. Disparity Estimation
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Adelson, E.H.; Bergen, J.R. The Plenoptic Function and the Elements of Early Vision. In Computational Models of Visual Processing; MIT Press: Cambridge, MA, USA, 1991; pp. 3–20. [Google Scholar]
- Levoy, M.; Hanrahan, P. Light Field Rendering; SIGGRAPH ’96; ACM: New York, NY, USA, 1996; pp. 31–42. [Google Scholar]
- Gortler, S.J.; Grzeszczuk, R.; Szeliski, R.; Cohen, M.F. The lumigraph. In Proceedings of the 23rd Annual Conference on Computer Graphics And Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; ACM: New York, NY, USA, 1996; pp. 43–54. [Google Scholar] [CrossRef] [Green Version]
- Bolles, R.C.; Baker, H.H.; Marimont, D.H. Epipolar-plane image analysis: An approach to determining structure from motion. Int. J. Comput. Vis. 1987, 1, 7–55. [Google Scholar] [CrossRef]
- Wetzstein, G.; Ihrke, I.; Heidrich, W. On Plenoptic Multiplexing and Reconstruction. Int. J. Comput. Vis. 2013, 101, 384–400. [Google Scholar] [CrossRef]
- Wilburn, B.; Smulski, M.; Lee, K.; Horowitz, M.A. The Light Field Video Camera. In Media Processors; International Society for Optics and Photonics: Bellingham, WA, USA, 2002; Volume 2002, pp. 29–36. [Google Scholar]
- Wilburn, B.; Joshi, N.; Vaish, V.; Talvala, E.V.; Antunez, E.; Barth, A.; Adams, A.; Horowitz, M.; Levoy, M. High performance imaging using large camera arrays. In Proceedings of the SIGGRAPH’05 ACM Siggraph 2005 Electronic Art and Animation Catalog, Los Angeles, CA, USA, 31 July–4 August 2005; ACM: New York, NY, USA, 2005; pp. 765–776. [Google Scholar]
- Adelson, E.H.; Wang, J.Y.A. Single Lens Stereo with a Plenoptic Camera. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 2, 99–106. [Google Scholar] [CrossRef]
- Ng, R.; Levoy, M.; Bredif, M.; Duval, G.; Horowitz, M.; Hanrahan, P. Stanford Tech Report CTSR 2005-02 Light Field Photography with a Hand-Held Plenoptic Camera; Technical Report; Stanford University: Stanford, CA, USA, 2005. [Google Scholar]
- Georgiev, T.; Lumsdaine, A. The Multi-Focus Plenoptic Camera. In Proceedings of the IS&T/SPIE Electronic Imaging, Burlingame, CA, USA, 22–26 January 2012. [Google Scholar]
- Perwass, C.; Wietzke, L. Single Lens 3D-Camera with Extended Depth-of-Field. In Human Vision and Electronic Imaging XVII; International Society for Optics and Photonics: Bellingham, WA, USA, 2012; p. 829108. [Google Scholar] [CrossRef]
- Georgiev, T.; Zheng, K.C.; Curless, B.; Salesin, D.; Nayar, S.; Intwala, C. Spatio-Angular Resolution Tradeoff in Integral Photography. In Proceedings of the Eurographics Symposium on Rendering, Nicosia, Cyprus, 26–28 June 2006; pp. 263–272. [Google Scholar]
- Unger, J.; Wenger, A.; Hawkins, T.; Gardner, A.; Debevec, P. Capturing and rendering with incident light fields. In Proceedings of the 14th Eurographics workshop on Rendering (EGRW’03), Leuven, Belgium, 25–27 June 2003; Eurographics Association: Aire-la-Ville, Switzerland, 2003; pp. 141–149. [Google Scholar]
- Georgiev, T.; Intwala, C.; Babacan, D. Light-Field Capture by Multiplexing in the Frequency Domain; Technical Report; Adobe Systems, Inc.: San Jose, CA, USA, 2006. [Google Scholar]
- Veeraraghavan, A.; Raskar, R.; Agrawal, A.; Mohan, A.; Tumblin, J. Dappled photography: Mask enhanced cameras for heterodyned light fields and coded aperture refocusing. ACM Trans. Graph 2007, 26, 69. [Google Scholar] [CrossRef]
- Kamal, M.H.; Golbabaee, M.; Vandergheynst, P. Light Field Compressive Sensing in Camera Arrays. In Proceedings of the 37th International Conference on Acoustics, Speech, and Signal Processing, Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Babacan, S.; Ansorge, R.; Luessi, M.; Mataran, P.; Molina, R.; Katsaggelos, A. Compressive Light Field Sensing. IEEE Trans. Image Process. 2012, 21, 4746–4757. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dansereau, D.G.; Pizarro, O.; Williams, S.B. Decoding, Calibration and Rectification for Lenselet-Based Plenoptic Cameras. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 1027–1034. [Google Scholar] [CrossRef]
- Cho, D.; Lee, M.; Kim, S.; Tai, Y.W. Modeling the Calibration Pipeline of the Lytro Camera for High Quality Light-Field Image Reconstruction. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3280–3287. [Google Scholar] [CrossRef]
- Bok, Y.; Jeon, H.G.; Kweon, I.S. Geometric Calibration of Micro-Lens-Based Light-Field Cameras Using Line Features. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 47–61. [Google Scholar]
- Xu, S.; Zhou, Z.L.; Devaney, N. Chapter Multi-view Image Restoration from Plenoptic Raw Images. In Proceedings of the Computer Vision–ACCV 2014 Workshops, Singapore, 1–2 November 2014; Revised Selected Papers, Part II. Springer International Publishing: Cham, Switzerland, 2015; pp. 3–15. [Google Scholar] [CrossRef]
- Zhang, C.; Ji, Z.; Wang, Q. Decoding and calibration method on focused plenoptic camera. Comput. Vis. Med. 2016, 2, 57–69. [Google Scholar] [CrossRef] [Green Version]
- David, P.; Pendu, M.L.; Guillemot, C. White lenslet image guided demosaicing for plenoptic cameras. In Proceedings of the 19th IEEE International Workshop on Multimedia Signal Processing, MMSP 2017, Luton, UK, 16–18 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Cho, H.; Bae, J.; Jung, H.; Oh, E.; Yoo, H. Improvement on Demosaicking in Plenoptic Cameras by Use of Masking Information. In Proceedings of the 2018 the 2Nd International Conference on Video and Image Processing, Hong Kong, Hong Kong, 29–31 December 2018; ACM: New York, NY, USA, 2018; pp. 161–164. [Google Scholar] [CrossRef]
- Isaksen, A.; McMillan, L.; Gortler, S.J. Dynamically reparameterized light fields. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000; ACM Press/Addison-Wesley Publishing Co.: New York, NY, USA, 2000; pp. 297–306. [Google Scholar] [CrossRef] [Green Version]
- Ng, R. Digital Light Field Photography. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2006. [Google Scholar]
- Lumsdaine, A.; Georgiev, T. Full Resolution Lightfield Rendering; Technical Report; Adobe Systems, Inc.: San Jose, CA, USA, 2008. [Google Scholar]
- Pérez Nava, F.; Lüke, J. Simultaneous estimation of super-resolved depth and all-in-focus images from a plenoptic camera. In Proceedings of the 3DTV Conference: The True Vision–Capture, Transmission and Display of 3D Video, Potsdam, Germany, 4–6 May 2009; pp. 1–4. [Google Scholar]
- Georgiev, T.; Lumsdaine, A. Reducing Plenoptic Camera Artifacts. Comput. Graph. Forum 2010, 29, 1955–1968. [Google Scholar] [CrossRef]
- Yoon, Y.; Jeon, H.G.; Yoo, D.; Lee, J.Y.; So Kweon, I. Learning a Deep Convolutional Network for Light-Field Image Super-Resolution. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Farrugia, R.A.; Galea, C.; Guillemot, C. Super Resolution of Light Field Images Using Linear Subspace Projection of Patch-Volumes. IEEE J. Sel. Top. Signal Process. 2017, 11, 1058–1071. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Liu, F.; Zhang, K.; Hou, G.; Sun, Z.; Tan, T. LFNet: A Novel Bidirectional Recurrent Convolutional Neural Network for Light-Field Image Super-Resolution. IEEE Trans. Image Process. 2018, 27, 4274–4286. [Google Scholar] [CrossRef]
- Marichal-Hernández, J.; Lüke, J.; Rosa, F.; Pérez Nava, F.; Rodríguez-Ramos, J. Fast approximate focal stack transform. In Proceedings of the 3DTV Conference: The True Vision–Capture, Transmission and Display of 3D Video, Potsdam, Germany, 4–6 May 2009; pp. 1–4. [Google Scholar] [CrossRef]
- Pérez Nava, F. Super-Resolution in Plenoptic Cameras by the Integration of Depth from Focus and Stereo. In Proceedings of the 2010 Proceedings of 19th International Conference on Computer Communications and Networks (ICCCN), Zurich, Switzerland, 2–5 August 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Favaro, P.; Soatto, S. 3-D Shape Estimation and Image Restoration–Exploiting Defocus and Motion Blur; Springer: Berlin, Germany, 2007. [Google Scholar]
- Hasinoff, S.W.; Kutulakos, K.N. Confocal Stereo. Int. J. Comput. Vis. 2009, 81, 82–104. [Google Scholar] [CrossRef]
- Marichal-Hernández, J.G. Obtención de InformacióN Tridimensional de una Escena a Partir de Sensores PlenóPticos Usando Procesamiento de SeñAles Con Hardware Gráfico. Ph.D. Thesis, University of La Laguna, San Cristóbal de La Laguna, Spain, 2012. [Google Scholar]
- Lüke, J.P.; Nava, F.P.; Marichal-Hernández, J.G.; Rodríguez-Ramos, J.M.; Rosa, F. Near Real-Time Estimation of Super-resolved Depth and All-In-Focus Images from a Plenoptic Camera Using Graphics Processing Units. Int. J. Digit. Multimed. Broadcast. 2010. [Google Scholar] [CrossRef]
- Berent, J.; Dragotti, P. Plenoptic Manifolds. IEEE Signal Process. Mag. 2007, 24, 34–44. [Google Scholar] [CrossRef]
- Dansereau, D. 4D Light Field Processing and Its Application to Computer Vision. Master’s Thesis, University of Calgary, Calgary, Alberta, 2003. [Google Scholar]
- Wanner, S.; Goldluecke, B. Globally Consistent Depth Labeling of 4D Lightfields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Lüke, J.P.; Rosa, F.; Marichal-Hernández, J.G.; Sanluís, J.C.; Conde, C.D.; Rodríguez-Ramos, J.M. Depth From Light Fields Analyzing 4D Local Structure. J. Display Technol. 2015, 11, 900–907. [Google Scholar] [CrossRef]
- Heber, S.; Pock, T. Shape from Light Field Meets Robust PCA. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part VI. Springer International Publishing: Cham, Switzerland, 2014; pp. 751–767. [Google Scholar] [CrossRef]
- Kim, C.; Zimmer, H.; Pritch, Y.; Sorkine-Hornung, A.; Gross, M. Scene Reconstruction from High Spatio-angular Resolution Light Fields. ACM Trans. Graph. 2013, 32, 73:1–73:12. [Google Scholar] [CrossRef]
- Jeon, H.G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.W.; So Kweon, I. Accurate Depth Map Estimation From a Lenslet Light Field Camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Jeon, H.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.; Kweon, I.S. Depth from a Light Field Image with Learning-Based Matching Costs. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 297–310. [Google Scholar] [CrossRef] [PubMed]
- Chandramouli, P.; Noroozi, M.; Favaro, P. ConvNet-Based Depth Estimation, Reflection Separation and Deblurring of Plenoptic Images. In Computer Vision–ACCV 2016; Lai, S.H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 129–144. [Google Scholar]
- Alperovich, A.; Johannsen, O.; Goldluecke, B. Intrinsic Light Field Decomposition and Disparity Estimation with Deep Encoder-Decoder Network. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Roma, Italy, 3–7 September 2018; pp. 2165–2169. [Google Scholar] [CrossRef]
- Shin, C.; Jeon, H.; Yoon, Y.; Kweon, I.S.; Kim, S.J. EPINET: A Fully-Convolutional Neural Network Using Epipolar Geometry for Depth from Light Field Images. arXiv 2018, arXiv:1804.02379. [Google Scholar]
- Clare, R.; Lane, R. Wave-front sensing from subdivision of the focal plane with a lenslet array. J. Opt. Soc. Am. 2005, A 22, 117–125. [Google Scholar] [CrossRef]
- Rodríguez-Ramos, J.M.; Femenía Castelló, B.; Pérez Nava, F.; Fumero, S. Wavefront and Distance Measurement Using the CAFADIS Camera. In Adaptive Optics Systems; International Society for Optics and Photonics: Bellingham, WA, USA, 2008; p. 70155Q. [Google Scholar] [CrossRef]
- Rodríguez-Ramos, L.F.; Martín, Y.; Díaz, J.J.; Piqueras, J.; Rodríguez-Ramos, J.M. The Plenoptic Camera as a Wavefront Sensor for the European Solar Telescope (EST). In Adaptive Optics Systems; International Society for Optics and Photonics: Bellingham, WA, USA, 2009; p. 74390I. [Google Scholar] [CrossRef]
- Rodríguez-Ramos, J.; Femenía, B.; Montilla, I.; Rodríguez-Ramos, L.; Marichal-Hernández, J.; Lüke, J.; López, R.; Díaz, J.; Martín, Y. The CAFADIS camera: A new tomographic wavefront sensor for Adaptive Optics. In Proceedings of the 1st AO4ELT Conference–Adaptative Optics for Extremely Large Telescopes, Paris, France, 22–26 June 2009. [Google Scholar] [CrossRef]
- Rodríguez-Ramos, L.F.; Montilla, I.; Lüke, J.P.; López, R.; Marichal-Hernández, J.G.; Trujillo-Sevilla, J.; Femenía, B.; López, M.; Fernández-Valdivia, J.J.; Puga, M.; et al. Atmospherical Wavefront Phases Using the Plenoptic Sensor (Real Data). In Three-Dimensional Imaging, Visualization, and Display 2012; International Society for Optics and Photonics: Bellingham, WA, USA, 2012; p. 83840D. [Google Scholar] [CrossRef]
- Neumann, J.; Fermüller, C. Plenoptic video geometry. Vis. Comput. 2003, 19, 395–404. [Google Scholar] [CrossRef] [Green Version]
- Dansereau, D.G.; Mahon, I.; Pizarro, O.; Williams, S.B. Plenoptic Flow: Closed-Form Visual Odometry for Light Field Cameras. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 4455–4462. [Google Scholar]
- Dong, F.; Ieng, S.H.; Savatier, X.; Etienne-Cummings, R.; Benosman, R. Plenoptic Cameras in Real-Time Robotics. Int. J. Robot. Res. 2013, 32, 206–217. [Google Scholar] [CrossRef]
- Zeller, N.; Quint, F.; Stilla, U. Narrow Field-of-view visual odometry based on a focused plenoptic camera. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2015, II-3/W4, 285–292. [Google Scholar] [CrossRef]
- Zeller, N.; Quint, F.; Stilla, U. Scale-Awareness of Light Field Camera based Visual Odometry. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lingenauber, M.; Strobl, K.; Oumer, N.W.; Kriegel, S. Benefits of plenoptic cameras for robot vision during close range on-orbit servicing maneuvers. In Proceedings of the IEEE Aerospace Conference 2017 on Institute of Electrical and Electronics Engineers (IEEE), Big Sky, MT, USA, 4–11 March 2017; pp. 1–18. [Google Scholar]
- Hernández Delgado, A.; Martínez Rey, N.; Lüke, J.; Rodríguez Ramos, J.; Sánchez Gestido, M.; Bullock, M. On the use of plenoptic imaging technology for 3D vision based relative navigation in space. In Proceedings of the 10th ESA Conference on Guidance, Navigation & Control Systems, Salzburg, Austria, 29 May–2 June 2017. [Google Scholar]
- Dansereau, D.G.; Girod, B.; Wetzstein, G. LiFF: Light Field Features in Scale and Depth. arXiv 2019, arXiv:1901.03916. [Google Scholar]
- Xilinx, Inc. Xilinx Zynq-7000 SoC Product Brief. 2016. Available online: https://www.xilinx.com/support/documentation/product-briefs/zynq-7000-product-brief.pdf (accessed on 4 July 2019).
- Intel Corporation. Intel FPGAs. 2018. Available online: https://www.intel.com/content/www/us/en/products/programmable/soc.html (accessed on 4 July 2019).
- Pérez-Izquierdo, J.; Magdaleno, E.; Perez, F.; Valido, M.; Hernández, D.; Corrales, J. Super-Resolution in Plenoptic Cameras Using FPGAs. Sensors (Basel, Switzerland) 2014, 14, 8669–8685. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wimalagunarathne, R.; Wijenayake, C.; Madanayake, A.; Dansereau, D.G.; Bruton, L.T. Integral form 4-D light field filters using Xilinx FPGAs and 45 nm CMOS technology. Multidimens. Syst. Signal Process. 2015, 26, 47–65. [Google Scholar] [CrossRef]
- Hahne, C.; Lumsdaine, A.; Aggoun, A.; Velisavljevic, V. Real-Time Refocusing Using an FPGA-Based Standard Plenoptic Camera. IEEE Trans. Ind. Electron. 2018, 65, 9757–9766. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez-Ramos, L.F.; Marín, Y.; Díaz, J.J.; Piqueras, J.; García-Jiménez, J.; Rodríguez-Ramos, J.M. FPGA-based real time processing of the Plenoptic Wavefront Sensor. In Proceedings of the Adaptative Optics for Extremely Large Telescopes, Paris, France, 22–26 June 2009; p. 07007. [Google Scholar] [CrossRef]
- Martin, Y.; Rodriguez-Ramos, L.F.; García, J.; Díaz García, J.J.; Rodriguez-Ramos, J.M. FPGA-based real time processing of the plenoptic wavefront sensor for the european solar telescope (EST). In Proceedings of the 2010 VI Southern Programmable Logic Conference (SPL), Pernambuco, Brazil, 24–26 May 2010; pp. 87–92. [Google Scholar] [CrossRef]
- Magdaleno, E.; Lüke, J.; Valido, M.; Rodríguez-Ramos, J. Design of belief propagation based on FPGA for the multistereo CAFADIS camera. Sensors (Basel, Switzerland) 2010, 10, 9194–9210. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.; Chen, M.; Hsu, P.; Lu, Y. A pixel-based depth estimation algorithm and its hardware implementation for 4-D light field data. In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, Australia, 1–5 June 2014; pp. 786–789. [Google Scholar] [CrossRef]
- Farid, H.; Simoncelli, E.P. Differentiation of Discrete Multidimensional Signals. IEEE Trans. Image Process. 2004, 13, 496–508. [Google Scholar] [CrossRef] [PubMed]
- Digilent, Inc. Zybo Reference Manual. 2018. Available online: https://reference.digilentinc.com/reference/programmable-logic/zybo/reference-manual (accessed on 4 July 2019).
- Digilent, Inc. Petalinux Support for Digilent Boards. 2018. Available online: https://reference.digilentinc.com/reference/software/petalinux/start (accessed on 4 July 2019).
- Xilinx, Inc. Vivado Design Suite. 2018. Available online: https://www.xilinx.com/products/design-tools/vivado.html (accessed on 4 July 2019).
- Xilinx, Inc. ISE Design Suite. 2018. Available online: https://www.xilinx.com/products/design-tools/ise-design-suite.html (accessed on 4 July 2019).
- Blender Foundation. Blender. 2013. Available online: http://www.blender.org (accessed on 4 July 2019).
- Raspberry PI Foundation. Raspberry PI3 Model B+ Datasheet. 2018. Available online: https://static.raspberrypi.org/files/product-briefs/Raspberry-Pi-Model-Bplus-Product-Brief.pdf (accessed on 4 July 2019).
- Lüke, J.; Rosa, F.; Sanluis, J.; Marichal-Hernández, J.; Rodríguez-Ramos, J. Error analysis of depth estimations based on orientation detection in EPI-representations of 4D light fields. In Proceedings of the 2013 12th Workshop on Information Optics (WIO), Puerto de la Cruz, Spain, 15–19 July 2013; pp. 1–3. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coeff. | Value |
|---|---|
| Coeff. | Value |
|---|---|
| Signal | Function |
|---|---|
| clock | System clock, block receives one datum at each rising edge. |
| reset | Restarts the system. |
| data_in | Pixel × coefficient, after selection based on position and clock cycle. |
| mem_reg | Indicates if data_in must be added to the value stored in the register or the value read from memory. |
| wr_en | Indicates that the block must write data to memory. |
| rd_en | Enables reading from memory. If this signal is low, the memory output is zero. |
| rd_addr | Read address |
| wr_addr | Write address (one less than rd_addr) |
| data_out | Output data |
| Name | Size | Disparity | Focal Length | |
|---|---|---|---|---|
| Min. | Max. | |||
| cone | 35 mm | |||
| cubes | 50 mm | |||
| plane | 35 mm | |||
| mirror | 35 mm | |||
| semi | 35 mm | |||
| Light Field | Shape |
|---|---|
| wool ball | |
| flowers | |
| turtle |
| Resource | Serial Input | Parallel Input | ||
|---|---|---|---|---|
| # | % | # | % | |
| Slice registers | 2436 | 6% | 3386 | 9% |
| Slice LUTs | 6086 | 34% | 6227 | 35% |
| LUT-FF pairs | 1235 | 16% | 1675 | 21% |
| BUFG/BUFGCTRLs | 1 | 3% | 1 | 3% |
| BlockRam | 36 | 60% | 36 | 60% |
| DSP48E1s | 8 | 10% | 58 | 72% |
| Light-Field Shape | CPU (fps) | Embedded CPU (fps) | Proposed Serial Input (fps) | Proposed Parallel Input (fps) |
|---|---|---|---|---|
| cone | ||||
| cubes | ||||
| plane | ||||
| mirror | ||||
| semi | ||||
| AVERAGE | ||||
| cone | ||||
| cubes | ||||
| plane | ||||
| mirror | ||||
| semi | ||||
| AVERAGE | ||||
| Scene | F.P. | Serial | V. Parallel |
|---|---|---|---|
| cone | |||
| cubes | |||
| plane | |||
| mirror | |||
| semi |
| Proposed Serial Design | Proposed View Parallel Design | Magdaleno et al. [70] | Chang et al. [71] | |
|---|---|---|---|---|
| Output size | ||||
| Colour channels | Intensity | Intensity | – | Intensity |
| Processing time (clock cycles) | ||||
| On-chip memory | Not specified | |||
| Off-chip memory | Not used | Not used | Not used | Required |
| Delay (clock cyles) | 5 | 9 | ||
| Frame rate (fps) @ 100 MHz clock and output size: | ~36 | (@38 MHz 123 fps) | ~25 () | ~27 () |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Domínguez Conde, C.; Lüke, J.P.; Rosa González, F. Implementation of a Depth from Light Field Algorithm on FPGA. Sensors 2019, 19, 3562. https://doi.org/10.3390/s19163562
Domínguez Conde C, Lüke JP, Rosa González F. Implementation of a Depth from Light Field Algorithm on FPGA. Sensors. 2019; 19(16):3562. https://doi.org/10.3390/s19163562
Chicago/Turabian StyleDomínguez Conde, Cristina, Jonas Philipp Lüke, and Fernando Rosa González. 2019. "Implementation of a Depth from Light Field Algorithm on FPGA" Sensors 19, no. 16: 3562. https://doi.org/10.3390/s19163562
APA StyleDomínguez Conde, C., Lüke, J. P., & Rosa González, F. (2019). Implementation of a Depth from Light Field Algorithm on FPGA. Sensors, 19(16), 3562. https://doi.org/10.3390/s19163562