Improving GIS-Based Landslide Susceptibility Assessments with Multi-temporal Remote Sensing and Machine Learning

Abstract
:1. Introduction
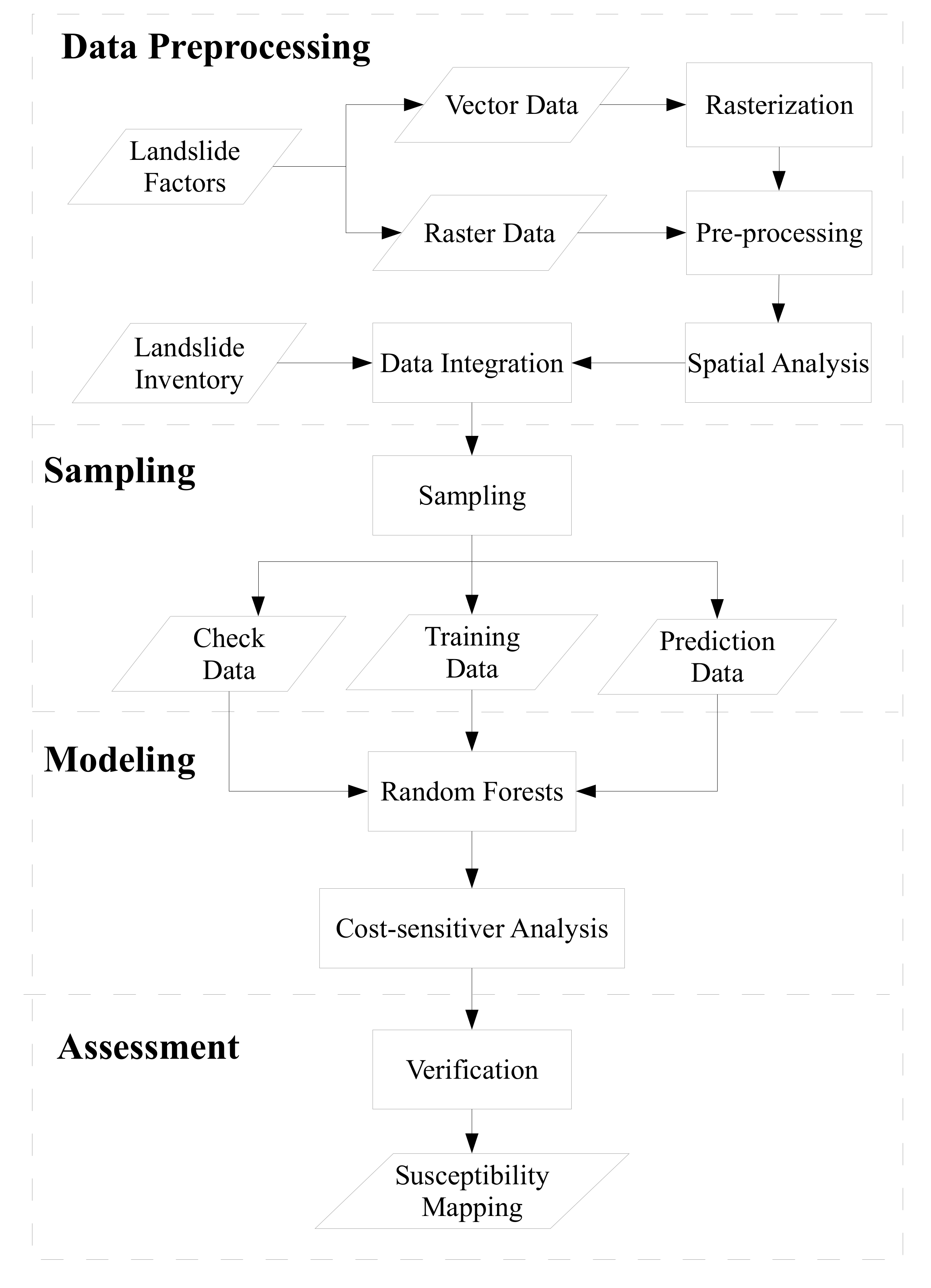
2. Materials and Methods
2.1. Study Site and Data Preprocessing
2.2. Developed Machine Learning Based Model
2.3. Verification and Mapping
3. Results
3.1. Multitemporal Landslide Susceptibility Assessments
3.1.1. Space-robustness Verification
3.1.2. Time-Robustness Verification with Multiple-Event Samples
3.1.3. Time-robustness Verification with Single-event Samples
3.1.4. Susceptibility Mapping
3.2. Event-Based Landslide Susceptibility Assessments
3.2.1. Space-Robustness Verification
3.2.2. Time-robustness Verification
3.2.3. Susceptibility Mapping
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fell, R.; Hartford, D. Landslide risk management. In Landslide Risk Assessment; Cruden, D., Fell, R., Eds.; Balkema: Rotterdam, The Netherlands, 1997; pp. 51–109. [Google Scholar]
- Dai, F.C.; Lee, C.F.; Ngai, Y.Y. Landslide risk assessment and management: An overview. Eng. Geol. 2002, 64, 65–87. [Google Scholar] [CrossRef]
- van Westen, C.J.; Castellanos, E.; Kuriakose, S.L. Spatial data for landslide susceptibility, hazard, and vulnerability assessment: An overview. Eng. Geol. 2008, 102, 112–131. [Google Scholar] [CrossRef]
- van Westen, C.J.; van Asch, T.W.J.; Soeters, R. Landslide hazard and risk zonation—Why is it still so difficult? Bull. Eng. Geol. Environ. 2006, 65, 167–184. [Google Scholar] [CrossRef]
- Brabb, E.E. Innovative approaches to landslide hazard mapping. In Proceedings of the 4th International Symposium on Landslides, Toronto, ON, Canada, 16–21 September 1984. [Google Scholar]
- Rossi, M.; Guzzetti, F.; Reichenbach, P.; Mondini, A.C.; Peruccacci, S. Optimal landslide susceptibility zonation based on multiple forecasts. Geomorphology 2010, 114, 129–142. [Google Scholar] [CrossRef]
- Guzzetti, F. Landslide Hazard and Risk Assessment. Ph.D. Dissertation, University of Bonn, Bonn, Germany, 2005. [Google Scholar]
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I. Landslide susceptibility assessment in Vietnam using support vector machines, decision tree, and Naïve Bayes models. Math. Probl. Eng. 2012, 2012, 974638. [Google Scholar]
- Wang, X.; Niu, R. Spatial forecast of landslides in Three Gorges based on spatial data mining. Sensors 2009, 9, 2035–2061. [Google Scholar] [CrossRef] [PubMed]
- Tsai, F.; Lai, J.-S.; Chen, W.W.; Lin, T.-H. Analysis of topographic and vegetative factors with data mining for landslide verification. Ecol. Eng. 2013, 61, 669–677. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. Selecting optimal conditioning factors in shallow translational landslide susceptibility mapping using genetic algorithm. Eng. Geol. 2015, 192, 101–112. [Google Scholar] [CrossRef]
- Nourani, V.; Pradhan, B.; Ghaffari, H.; Sharifi, S.S. Landslide susceptibility mapping at Zonouz Plain, Iran using genetic programming and comparison with frequency ratio, logistic regression, and artificial neural network models. Nat. Hazards 2014, 71, 523–547. [Google Scholar] [CrossRef]
- Roodposhti, M.S.; Aryal, J.; Pradhan, B. A Novel rule-based approach in mapping landslide susceptibility. Sensors 2019, 19, 2274. [Google Scholar] [CrossRef]
- Wan, S. Entropy-based particle swarm optimization with clustering analysis on landslide susceptibility mapping. Environ. Earth Sci. 2013, 68, 1349–1366. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Spatial prediction of landslide hazards in Hoa Binh province (Vietnam): A comparative assessment of the efficacy of evidential belief functions and fuzzy logic models. Catena 2012, 96, 28–40. [Google Scholar]
- Zhu, A.-X.; Wang, R.; Qiao, J.; Qin, C.-Z.; Chen, Y.; Liu, J.; Du, F.; Lin, Y.; Zhu, T. An expert knowledge-based approach to landslide susceptibility mapping using GIS and fuzzy logic. Geomorphology 2014, 214, 128–138. [Google Scholar] [CrossRef]
- Chalkias, C.; Ferentinou, M.; Polykretis, C. GIS supported landslide susceptibility modeling at regional scale: An expert-based fuzzy weighting method. ISPRS Int. J. Geo-Inf. 2014, 3, 523–539. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide susceptibility assessment in the Hoa Binh province of Vietnam: A comparison of the Levenberg–Marquardt and Bayesian regularized neural networks. Geomorphology 2012, 171–172, 12–29. [Google Scholar]
- Xu, K.; Guo, Q.; Li, Z.; Xiao, J.; Qin, Y.; Chen, D.; Kong, C. Landslide susceptibility evaluation based on BPNN and GIS: A case of Guojiaba in the Three Gorges Reservoir Area. Int. J. Geogr. Inf. Sci. 2015, 29, 1111–1124. [Google Scholar] [CrossRef]
- Merghadi, A.; Abderrahmane, B.; Bui, D.T. Landslide susceptibility assessment at Mila Basin (Algeria): Acomparative assessment of prediction capability of advanced machine learning methods. ISPRS Int. J. Geo-Inf. 2018, 7, 268. [Google Scholar] [CrossRef]
- Su, Q.; Zhang, J.; Zhao, S.; Wang, L.; Liu, J.; Guo, J. Comparative assessment of three nonlinear approaches for landslide susceptibility mapping in a coal mine area. ISPRS Int. J. Geo-Inf. 2017, 6, 228. [Google Scholar] [CrossRef]
- Xiao, L.; Zhang, Y.; Peng, G. Landslide susceptibility assessment using integrated deep learning algorithm along the China-Nepal highway. Sensors 2018, 18, 4436. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide susceptibility mapping at Hoa Binh province (Vietnam) using an adaptive neuro-fuzzy inference system and GIS. Comput. Geosci. 2012, 45, 199–211. [Google Scholar]
- Pradhan, B.; Sezer, E.A.; Gokceoglu, C.; Buchroithner, M.F. Landslide susceptibility mapping by neuro-fuzzy approach in a landslide-prone area (Cameron Highlands, Malaysia). IEEE Trans. Geosci. Remote Sens. 2010, 48, 4164–4177. [Google Scholar] [CrossRef]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random forest and rotation forest for fully polarized SAR image classification using polarimetric and spatial features. ISPRS J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Chan, J.C.; Beckers, P.; Spanhove, T.; Borre, J.V. An evaluation of ensemble classifiers for mapping Natura 2000 heathland in Belgium using spaceborne angular hyperspectral (CHRIS/Proba) imagery. Int. J. Appl. Earth Obs. Geoinform. 2012, 18, 13–22. [Google Scholar] [CrossRef]
- Shao, Y.; Campbell, J.B.; Taff, G.N.; Zheng, B. An analysis of cropland mask choice and ancillary data for annual corn yield forecasting using MODIS data. Int. J. Appl. Earth Obs. Geoinform. 2015, 38, 78–87. [Google Scholar] [CrossRef]
- Abdel-Rahman, E.M.; Mutanga, O.; Adam, E.; Ismail, R. Detecting Sirex noctilio grey-attacked and lightning-struck pine trees using airborne hyperspectral data, random forest and support vector machines classifiers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 45–59. [Google Scholar] [CrossRef]
- Shang, X.; Chisholm, L.A. Classification of Australian native forest species using hyperspectral remote sensing and machine-learning classification algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2481–2489. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabeling on random forest performance for large area land cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Heckmann, T.; Gegg, K.; Gegg, A.; Becht, M. Sample size matters: Investigating the effect of sample size on a logistic regression susceptibility model for debris flows. Nat. Hazards Earth Syst. Sci. 2014, 14, 259–278. [Google Scholar] [CrossRef]
- Berry, M.J.; Linoff, G.S. Mastering Data Mining: The Art and Science of Customer Relationship Management; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Aksoy, B.; Ercanoglu, M. Landslide identification and classification by object-based image analysis and fuzzy logic: An example from the Azdavay region (Kastamonu, Turkey). Comput. Geosci. 2012, 38, 87–98. [Google Scholar] [CrossRef]
- Dou, J.; Chang, K.-T.; Chen, S.; Yunus, A.P.; Liu, J.-K.; Xia, H.; Zhu, Z. Automatic case-based reasoning approach for landslide detection: Integration of object-oriented image analysis and a genetic algorithm. Remote Sens. 2015, 7, 4318. [Google Scholar] [CrossRef]
- Mondini, A.C.; Chang, K.-T. Combing spectral and geoenvironmental information for probabilistic event landslide mapping. Geomorphology 2014, 213, 183–189. [Google Scholar] [CrossRef]
- Mondini, A.C.; Chang, K.-T.; Yin, H.-Y. Combing multiple change detection indices for mapping landslides triggered by typhoons. Geomorphology 2011, 134, 440–451. [Google Scholar] [CrossRef]
- Mondini, A.C.; Guzzetti, F.; Reichenbach, P.; Rossi, M.; Cardinali, M.; Ardizzone, F. Semi-automatic recognition and mapping of rainfall induced shallow landslides using optical satellite images. Remote Sens. Environ. 2011, 115, 1743–1757. [Google Scholar] [CrossRef]
- Mondini, A.C.; Marchesini, I.; Rossi, M.; Chang, K.-T.; Pasquariello, G.; Guzzetti, F. Bayesian framework for mapping and classifying shallow landslides exploiting remote sensing and topographic data. Geomorphology 2013, 201, 135–147. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Wang, X.; Niu, R. Landslide intelligent prediction using object-oriented method. Soil Dyn. Earthq. Eng. 2010, 30, 1478–1486. [Google Scholar] [CrossRef]
- Guzzetti, F.; Mondini, A.C.; Cardinali, M.; Fiorucci, F.; Santangelo, M.; Chang, K.T. Landslide inventory maps: New tools for an old problem. Earth-Sci. Rev. 2012, 112, 42–66. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.-T.; Huang, C.-C.; Lee, J.-F.; Pan, K.-L.; Lin, M.-L.; Dong, J.J. Statistical approach to storm event-induced landslide susceptibility. Nat. Hazards Earth Syst. Sci. 2008, 8, 941–960. [Google Scholar] [CrossRef]
- Wang, H.; Liu, G.; Xu, W.; Wang, G. GIS-based landslide hazard assessment: An overview. Prog. Phys. Geog. 2005, 29, 548–567. [Google Scholar]
- Chang, K.-T.; Chiang, S.-H.; Chen, Y.-C.; Mondini, A.C. Modeling the spatial occurrence of shallow landslides triggered by typhoons. Geomorphology 2014, 208, 137–148. [Google Scholar] [CrossRef]
- Highland, L.M.; Bobrowsky, P. The Landslide Handbook—A Guide to Understanding Landslides; U.S. Geological Survey Circular: Reston, VA, USA, 2008; Volume 1325.
- Tsai, F.; Chen, L.C. Long-term landcover monitoring and disaster assessment in the Shiman reservoir watershed using satellite images. In Proceedings of the 13th CeRES International Symposium on Remote Sensing, Chiba, Japan, 29–30 October 2007. [Google Scholar]
- Deng, Y.C.; Tsai, F.; Hwang, J.H. Landslide characteristics in the area of Xiaolin Village during Morakot typhoon. Arab. J. Geosci. 2016, 9, 332. [Google Scholar] [CrossRef]
- Chen, X.; Vierling, L.; Deering, D. A simple and effective radiometric correction method to improve landscape change detection across sensors and across time. Remote Sens. Environ. 2005, 98, 63–79. [Google Scholar] [CrossRef]
- Schott, J.R.; Salvaggio, C.; Volchok, W.J. Radiometric scene normalization using pseudo invariant features. Remote Sens. Environ. 1988, 26, 1–16. [Google Scholar] [CrossRef]
- Minnaert, M. The reciprocity principle in lunar photometry. Astrophys. J. 1941, 93, 403–410. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Desai, A.; Jadav, P.M. An empirical evaluation of Adaboost extensions for cost-sensitive classification. Int. J. Comput. Appl. 2012, 44, 34–41. [Google Scholar]
- Tsai, F.; Lai, J.-S.; Lu, Y.-H. Land-cover classification of full-waveform LiDAR point cloud with volumetric texture measures. Terr. Atmos. Ocean. Sci. 2016, 27, 549–563. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann: San Francisco, CA, USA, 2011. [Google Scholar]
- Elkan, C. The foundations of cost-sensitive learning. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001. [Google Scholar]
- Gigović, L.; Drobnjak, S.; Pamučar, D. The application of the hybrid GIS spatial multi-criteria decision analysis best–worst methodology for landslide susceptibility mapping. ISPRS Int. J. Geo-Inf. 2019, 8, 79. [Google Scholar] [CrossRef]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Pham, B.T.; Pradhan, B.; et al. Novel GIS based machine learning algorithms for shallow landslide susceptibility mapping. Sensors 2018, 18, 3777. [Google Scholar] [CrossRef]
- He, H.; Hu, D.; Sun, Q.; Zhu, L.; Liu, Y. A landslide susceptibility assessment method based on GIS technology and an AHP-weighted information content method: A case study of southern Anhui, China. ISPRS Int. J. Geo-Inf. 2019, 8, 266. [Google Scholar] [CrossRef]
- Di, B.; Stamatopoulos, C.A.; Dandoulaki, M.; Stavrogiannopoulou, E.; Zhang, M.; Bampina, P. A method predicting the earthquake-induced landslide risk by back analyses of past landslides and its application in the region of the Wenchuan 12/5/2008 earthquake. Nat. Hazards 2017, 85, 903–992. [Google Scholar] [CrossRef]
- Sorbino, G.; Sica, C.; Cascini, L. Susceptibility analysis of shallow landslides source areas using physically based models. Nat. Hazards 2010, 53, 313–332. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typhoon | Date | Accumulated Precipitation (mm) | No. of Landslide Samples |
|---|---|---|---|
| Mindulle | 2004/7/1–7/2 | 57–188 | 184 |
| Aere | 2004/8/25–8/26 | 85–1100 | 32,020 |
| Nock-ten | 2004/10/25 | 119–399 | <50 |
| Haitang | 2005/7/18–7/20 | 278–799 | 100 |
| Matsa | 2005/8/4–8/5 | 188–636 | 2,112 |
| Talim | 2005/9/1 | 135–535 | 201 |
| Bilis | 2006/7/13–7/15 | 44–151 | <50 |
| Kaemi | 2006/7/24 | 6–96 | 109 |
| Bopha | 2006/8/9 | 9–108 | <50 |
| Sepat | 2007/8/16–8/19 | 38–340 | 331 |
| Wipha | 2007/9/18–9/19 | 104–360 | 309 |
| Korsa | 2007/10/6–10/7 | 265–512 | 430 |
| Kalmaegi | 2008/7/17–7/18 | 265–512 | 83 |
| Fung-wong | 2008/7/28–7/19 | 65–251 | 330 |
| Sinlaku | 2008/9/14–9/15 | 235–515 | 943 |
| Jangmi | 2008/9/28–9/29 | 258–473 | 308 |
| Original Data | Original Resolution/Scale | Used Factor (Raster Format) |
|---|---|---|
| DEM | 20 m × 20 m | Aspect |
| Curvature | ||
| Elevation | ||
| Slope | ||
| Geology map | 1/50,000 | Geology |
| Land-cover map | 1/5000 | Land-cover |
| Soil map | 1/25,000 | Soil |
| Fault map | 1/50,000 | Distance to fault |
| Rainfall-gage | Accumulative hourly rainfall maps (IDW) | |
| Accumulative hourly rainfall maps (Kriging) | ||
| Maximum hourly rainfall maps (IDW) | ||
| River map | 1/5000 | Distance to river |
| Road map | 1/5000 | Distance to road |
| Satellite imagery | 10 m × 10 m | NDVI |
| L:N | Cost | Low | Medium to Low | Medium to High | High | Very High |
|---|---|---|---|---|---|---|
| 1:1 | 1 | 42.0 | 28.5 | 21.0 | 8.2 | 0.3 |
| 50 | 2.9 | 6.7 | 26.9 | 26.7 | 36.8 | |
| 1:4 | 1 | 71.4 | 15.6 | 11.6 | 1.4 | 0.0 |
| 500 | 2.7 | 7.8 | 27.7 | 26.5 | 35.3 | |
| 1:7 | 1 | 73.1 | 18.9 | 7.1 | 0.9 | 0 |
| 1000 | 3.6 | 14.5 | 25.4 | 26.3 | 30.2 | |
| 1:10 | 1 | 79.1 | 16.2 | 4.7 | 0.0 | 0.0 |
| 3000 | 2 | 2.8 | 12.5 | 32.6 | 50.1 |
| Typhoon | L:N | Cost | Low | Medium to Low | Medium to High | High | Very High |
|---|---|---|---|---|---|---|---|
| Fung-wong | 1:1 | 10 | 0 | 9.1 | 54.2 | 29.1 | 7.6 |
| 1:4 | 500 | 0 | 3.6 | 14.2 | 39.4 | 42.8 | |
| 1:7 | 500 | 0 | 7.2 | 56.4 | 15.8 | 20.6 | |
| 1:10 | 1000 | 0 | 10.9 | 34.2 | 33.9 | 21 | |
| Sinlaku | 1:1 | 50 | 5.2 | 8.8 | 33.1 | 20 | 32.9 |
| 1:4 | 500 | 4.9 | 8.1 | 30.5 | 22.4 | 34.1 | |
| 1:7 | 3000 | 3.5 | 5.1 | 14.5 | 34.4 | 42.5 | |
| 1:10 | 3000 | 5.7 | 5.4 | 32.4 | 22.8 | 33.7 | |
| Jangmi | 1:1 | 50 | 0 | 9.1 | 23.4 | 27.6 | 39.9 |
| 1:4 | 500 | 0 | 13 | 24.7 | 25 | 37.3 | |
| 1:7 | 3000 | 0 | 0 | 18.5 | 22.7 | 58.8 | |
| 1:10 | 3000 | 0 | 8.7 | 28.9 | 23.4 | 39 |
| P | L:N | T | Method. | Cost | OA (%) | AUC | UA (N) | PA (N) | UA (L) | PA (L) |
|---|---|---|---|---|---|---|---|---|---|---|
| Matsa | 1:1 | Sinlaku | RF | 50 | 73.48 | 0.83 | 0.72 | 0.77 | 0.75 | 0.70 |
| 1:4 | BN | 500 | 0.82 | 0.98 | 0.71 | 0.45 | 0.95 | |||
| 1:7 | DT | 50 | 0.78 | 0.95 | 0.94 | 0.59 | 0.63 | |||
| 1:10 | DT | 100 | 0.78 | 0.96 | 0.93 | 0.48 | 0.65 | |||
| Sinlaku | 1:1 | Aere | Logistic | 5 | 76.62 | 0.8 | 0.78 | 0.74 | 0.75 | 0.79 |
| 1:4 | RF | 1000 | 0.86 | 0.90 | 0.86 | 0.53 | 0.63 | |||
| 1:7 | RF | 3000 | 0.86 | 0.95 | 0.88 | 0.43 | 0.65 | |||
| 1:10 | RF | 5000 | 0.84 | 0.96 | 0.89 | 0.36 | 0.60 | |||
| Aere | 1:1 | Sinlaku | RF | 50 | 83.43 | 0.9 | 0.8 | 0.89 | 0.88 | 0.78 |
| 1:4 | RF | 300 | 0.89 | 0.92 | 0.95 | 0.78 | 0.68 | |||
| 1:7 | Logistic | 70000 | 0.92 | 0.96 | 0.96 | 0.74 | 0.73 | |||
| 1:10 | RF | 700 | 0.89 | 0.97 | 0.96 | 0.65 | 0.66 |
| P | T | L:N | Cost | Low | Medium to Low | Medium to High | High | Very High |
|---|---|---|---|---|---|---|---|---|
| Matsa | Sinlaku | 1:1 | 50 | 0 | 0.7 | 6.8 | 83.1 | 9.4 |
| 1:4 | 700 | 0 | 1.7 | 34.6 | 60.1 | 3.6 | ||
| 1:7 | 3000 | 0 | 0.2 | 28.1 | 50 | 21.7 | ||
| 1:10 | 3000 | 0 | 8.2 | 64.5 | 20.8 | 6.5 | ||
| Sinlaku | Aere | 1:1 | 100 | 5.1 | 13.9 | 29 | 27 | 25.1 |
| 1:4 | 1000 | 4.7 | 17.6 | 27.6 | 25.1 | 25 | ||
| 1:7 | 3000 | 5.7 | 17.3 | 22.7 | 25 | 29.3 | ||
| 1:10 | 5000 | 8.1 | 20.3 | 28.7 | 19.3 | 23.6 | ||
| Aere | Sinlaku | 1:1 | 50 | 1.8 | 11.4 | 23.8 | 62.5 | 0.5 |
| 1:4 | 300 | 6 | 19.3 | 26.5 | 48.2 | 0 | ||
| 1:7 | 500 | 10.2 | 14.4 | 17.9 | 56.4 | 1.1 | ||
| 1:10 | 700 | 16.5 | 8.8 | 21.4 | 52.7 | 0.6 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, J.-S.; Tsai, F. Improving GIS-Based Landslide Susceptibility Assessments with Multi-temporal Remote Sensing and Machine Learning. Sensors 2019, 19, 3717. https://doi.org/10.3390/s19173717
Lai J-S, Tsai F. Improving GIS-Based Landslide Susceptibility Assessments with Multi-temporal Remote Sensing and Machine Learning. Sensors. 2019; 19(17):3717. https://doi.org/10.3390/s19173717
Chicago/Turabian StyleLai, Jhe-Syuan, and Fuan Tsai. 2019. "Improving GIS-Based Landslide Susceptibility Assessments with Multi-temporal Remote Sensing and Machine Learning" Sensors 19, no. 17: 3717. https://doi.org/10.3390/s19173717
APA StyleLai, J. -S., & Tsai, F. (2019). Improving GIS-Based Landslide Susceptibility Assessments with Multi-temporal Remote Sensing and Machine Learning. Sensors, 19(17), 3717. https://doi.org/10.3390/s19173717