Using A Low-Cost Sensor Array and Machine Learning Techniques to Detect Complex Pollutant Mixtures and Identify Likely Sources



Abstract
:1. Introduction
2. Materials and Methods
2.1. Sensor Array Design
2.1.1. Metal Oxide (MOx) Sensors
2.1.2. Electrochemical Sensors
2.1.3. Other Sensor Types
2.2. Environmental Chamber Testing
2.2.1. Simulating Pollutant Sources
2.2.2. Simulating Other Environmental Parameters
2.3. Computational Methods
2.3.1. Initial Data Preprocessing
2.3.2. Regression Models Applied
2.3.3. Classification Models Applied
2.3.4. Determining the Best Combination of Classification and Regression Models
3. Results
3.1. Regression Results
3.2. Classification Results
4. Discussion
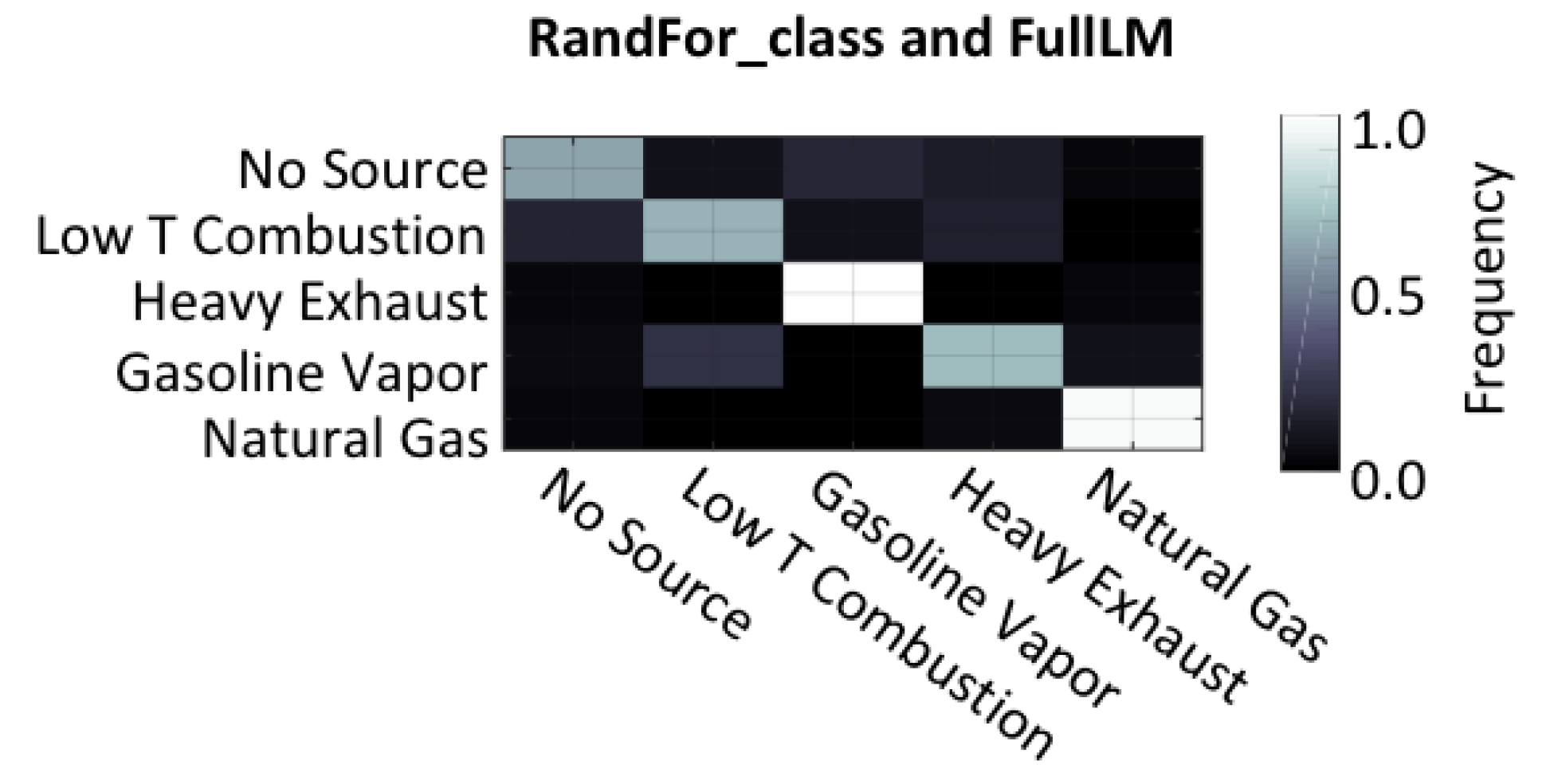
4.1. Classification Results
4.2. Sensor Importance for Different Compounds
4.2.1. Terms Selected by Stepwise Regression
4.2.2. Random Forest Unbiased Importance Estimates
4.2.3. Standardized Ridge Regression Coefficients
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- US EPA. Integrated Urban Air Toxics Strategy. Available online: https://www.epa.gov/urban-air-toxics/integrated-urban-air-toxics-strategy (accessed on 25 September 2018).
- Garcia, C. AB-617 Nonvehicular Air Pollution: Criteria Air Pollutants and Toxic Air Contaminants. 2017. Available online: https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=201720180AB617 (accessed on 18 October 2018).
- Cheadle, L.; Deanes, L.; Sadighi, K.; Casey, J.G.; Collier-Oxandale, A.; Hannigan, M. Quantifying neighborhood-scale spatial variations of ozone at open space and urban sites in Boulder, Colorado using low-cost sensor technology. Sensors 2017, 17, 2072. [Google Scholar] [CrossRef] [PubMed]
- Tan, Y.; Lipsky, E.M.; Saleh, R.; Robinson, A.L.; Presto, A.A. Characterizing the spatial variation of air pollutants and the contributions of high emitting vehicles in Pittsburgh, PA. Environ. Sci. Technol. 2014, 48, 14186–14194. [Google Scholar] [CrossRef] [PubMed]
- Mead, M.I.; Popoola, O.A.M.; Stewart, G.B.; Landshoff, P.; Calleja, M.; Hayes, M.; Baldovi, J.J.; McLeod, M.W.; Hodgson, T.F.; Dicks, J.; et al. The use of electrochemical sensors for monitoring urban air quality in low-cost, high-density networks. Atmos. Environ. 2013, 70, 186–203. [Google Scholar] [CrossRef] [Green Version]
- Penza, M.; Suriano, D.; Pfister, V.; Prato, M.; Cassano, G. Urban air quality monitoring with networked low-cost sensor-systems. Proceedings 2017, 1, 573. [Google Scholar] [CrossRef]
- Popoola, O.A.M.; Carruthers, D.; Lad, C.; Bright, V.B.; Mead, M.I.; Stettler, M.E.J.; Saffell, J.R.; Jones, R.L. Use of networks of low cost air quality sensors to quantify air quality in urban settings. Atmos. Environ. 2018, 194, 58–70. [Google Scholar] [CrossRef]
- Sadighi, K.; Coffey, E.; Polidori, A.; Feenstra, B.; Lv, Q.; Henze, D.K.; Hannigan, M. Intra-urban spatial variability of surface ozone in Riverside, CA: Viability and validation of low-cost sensors. Atmos. Measur. Tech. 2018, 11, 1777–1792. [Google Scholar] [CrossRef]
- Martenies, S.E.; Milando, C.W.; Williams, G.O.; Batterman, S.A. Disease and health inequalities attributable to air pollutant exposure in Detroit, Michigan. Int. J. Environ. Res. Public Health 2017, 14, 1243. [Google Scholar] [CrossRef] [PubMed]
- De Vito, S.; Castaldo, A.; Loffredo, F.; Massera, E.; Polichetti, T.; Nasti, I.; Vacca, P.; Quercia, L.; Di Francia, G. Gas concentration estimation in ternary mixtures with room temperature operating sensor array using tapped delay architectures. Sens. Actuators B Chem. 2007, 124, 309–316. [Google Scholar] [CrossRef]
- De Vito, S.; Piga, M.; Martinotto, L.; Di Francia, G. CO, NO2 and NOx urban pollution monitoring with on-field calibrated electronic nose by automatic bayesian regularization. Sens. Actuators B Chem. 2009, 143, 182–191. [Google Scholar] [CrossRef]
- Akamatsu, T.I.T.; Tsuruta, A.; Shin, W. Selective detection of target volatile organic compounds in contaminated humid air using a sensor array with principal component analysis. Sensors 2017, 17, 1662. [Google Scholar] [CrossRef]
- Aleixandre, M.; Sayago, I.; Horrillo, M.C.; Fernández, M.J.; Arés, L.; García, M.; Santos, J.P.; Gutiérrez, J. Analysis of neural networks and analysis of feature selection with genetic algorithm to discriminate among pollutant gas. Sens. Actuators B Chem. 2004, 103, 122–128. [Google Scholar] [CrossRef]
- Capone, S.; Siciliano, P.; Bârsan, N.; Weimar, U.; Vasanelli, L. Analysis of CO and CH4 gas mixtures by using a micromachined sensor array. Sens. Actuators B Chem. 2001, 78, 40–48. [Google Scholar] [CrossRef]
- Clements, A.L.; Griswold, W.G.; Rs, A.; Johnston, J.E.; Herting, M.M.; Thorson, J.; Collier-Oxandale, A.; Hannigan, M. Low-cost air quality monitoring tools: from research to practice (a workshop summary). Sensors 2017, 17, 2478. [Google Scholar] [CrossRef] [PubMed]
- Robinson, J.A.; Kocman, D.; Horvat, M.; Bartonova, A. End-user feedback on a low-cost portable air quality sensor system—Are we there yet? Sensors 2018, 18, 3768. [Google Scholar] [CrossRef]
- Woodall, G.M.; Hoover, M.D.; Williams, R.; Benedict, K.; Harper, M.; Soo, J.C.; Jarabek, A.M.; Stewart, M.J.; Brown, J.S.; Hulla, J.E.; et al. Interpreting mobile and handheld air sensor readings in relation to air quality standards and health effect reference values: Tackling the challenges. Atmosphere 2017, 8, 182. [Google Scholar] [CrossRef]
- Piedrahita, R.; Xiang, Y.; Masson, N.; Ortega, J.; Collier, A.; Jiang, Y.; Li, K.; Dick, R.P.; Lv, Q.; Hannigan, M.; et al. The next generation of low-cost personal air quality sensors for quantitative exposure monitoring. Atmos. Measur. Tech. Katlenburg Lindau 2014, 7, 3325. [Google Scholar] [CrossRef]
- Collier-Oxandale, A.; Coffey, E.; Thorson, J.; Johnston, J.; Hannigan, M. Comparing building and neighborhood-scale variability of CO2 and O3 to inform deployment considerations for low-cost sensor system use. Sensors 2018, 18, 1346. [Google Scholar] [CrossRef]
- Yoo, K.S. Gas Sensors for Monitoring Air Pollution, Monitoring, Control and Effects of Air Pollution; InTech: Shangai, China, 2011; ISBN 978-953-307-526-6. [Google Scholar]
- Lee, A.P.; Reedy, B.J. Temperature modulation in semiconductor gas sensing. Sens. Actuators B Chem. 1999, 60, 35–42. [Google Scholar] [CrossRef]
- Korotcenkov, G. Handbook of Gas Sensor Materials; Korotcenkov, G., Ed.; Integrated Analytical Systems; Springer: New York, NY, USA, 2013; ISBN 978-1-4614-7165-3. [Google Scholar]
- Schultealbert, C.; Baur, T.; Schütze, A.; Sauerwald, T. Facile quantification and identification techniques for reducing gases over a wide concentration range using a mos sensor in temperature-cycled operation. Sensors 2018, 18, 744. [Google Scholar] [CrossRef]
- Korotcenkov, G.; Cho, B.K. Instability of metal oxide-based conductometric gas sensors and approaches to stability improvement (short survey). Sens. Actuators B Chem. 2011, 156, 527–538. [Google Scholar] [CrossRef]
- Tangirala, V.K.K.; Gómez-Pozos, H.; Rodríguez-Lugo, V.; Olvera, M.D.L.L. A Study of the CO sensing responses of Cu-, Pt- and Pd-Activated SnO2 sensors: effect of precipitation agents, dopants and doping methods. Sensors 2017, 17, 1011. [Google Scholar] [CrossRef] [PubMed]
- Molino, A.; Elen, B.; Theunis, J.; Ingarra, S.; Van den Bossche, J.; Reggente, M.; Loreto, V. The EveryAware SensorBox: A tool for community-based air quality monitoring. In Proceedings of the Workshop Sensing a Changing World, Wageningen, The Netherlands, 9–11 May 2012. [Google Scholar]
- Spinelle, L.; Gerboles, M.; Kok, G.; Persijn, S.; Sauerwald, T. Performance evaluation of low-cost BTEX sensors and devices within the EURAMET key-VOCs project. Proceedings 2017, 1, 425. [Google Scholar] [CrossRef]
- Lewis, A.C.; Lee, J.D.; Edwards, P.M.; Shaw, M.D.; Evans, M.J.; Moller, S.J.; Smith, K.R.; Buckley, J.W.; Ellis, M.; Gillot, S.R.; et al. Evaluating the performance of low cost chemical sensors for air pollution research. Faraday Discuss 2016, 189, 85–103. [Google Scholar] [CrossRef] [PubMed]
- Alphasense Ltd. AAN 109-02: Interfering Gases. Available online: http://www.alphasense.com/WEB1213/wp-content/uploads/2013/07/AAN_109-02.pdf (accessed on 18 October 2018).
- Kim, J.; Shusterman, A.A.; Lieschke, K.J.; Newman, C.; Cohen, R.C. The Berkeley atmospheric CO2 observation network: Field calibration and evaluation of low-cost air quality sensors. Atmos. Meas. Tech. Discuss 2017, 2017, 1–20. [Google Scholar]
- Cross, E.S.; Williams, L.R.; Lewis, D.K.; Magoon, G.R.; Onasch, T.B.; Kaminsky, M.L.; Worsnop, D.R.; Jayne, J.T. Use of electrochemical sensors for measurement of air pollution: Correcting interference response and validating measurements. Atmos. Meas. Tech. 2017, 10, 3575–3588. [Google Scholar] [CrossRef]
- Hagler, G.S.W.; Williams, R.; Papapostolou, V.; Polidori, A. Air quality sensors and data adjustment algorithms: When is it no longer a measurement? Environ. Sci. Technol. 2018, 52, 5530–5531. [Google Scholar] [CrossRef]
- Vergara, A.; Llobet, E.; Brezmes, J.; Ivanov, P.; Vilanova, X.; Gracia, I.; Cané, C.; Correig, X. Optimised temperature modulation of metal oxide micro-hotplate gas sensors through multilevel pseudo random sequences. Sens. Actuators B Chem. 2005, 111, 271–280. [Google Scholar] [CrossRef]
- Fonollosa, J.; Sheik, S.; Huerta, R.; Marco, S. Reservoir computing compensates slow response of chemosensor arrays exposed to fast varying gas concentrations in continuous monitoring. Sens. Actuators B Chem. 2015, 215, 618–629. [Google Scholar] [CrossRef]
- Schüler, M.; Sauerwald, T.; Schütze, A. Metal oxide semiconductor gas sensor self-test using Fourier-based impedance spectroscopy. J. Sens.Sens. Syst. 2014, 3, 213–221. [Google Scholar] [CrossRef] [Green Version]
- Spinelle, L.; Gerboles, M.; Villani, M.G.; Aleixandre, M.; Bonavitacola, F. Field calibration of a cluster of low-cost commercially available sensors for air quality monitoring. Part B: NO, CO and CO2. Sens. Actuators B Chem. 2017, 238, 706–715. [Google Scholar] [CrossRef]
- Borrego, C.; Ginja, J.; Coutinho, M.; Ribeiro, C.; Karatzas, K.; Sioumis, T.; Katsifarakis, N.; Konstantinidis, K.; De Vito, S.; Esposito, E.; et al. Assessment of air quality microsensors versus reference methods: The EuNetAir Joint Exercise–Part II. Atmos. Environ. 2018, 193, 127–142. [Google Scholar] [CrossRef]
- Heimann, I.; Bright, V.B.; McLeod, M.W.; Mead, M.I.; Popoola, O.A.M.; Stewart, G.B.; Jones, R.L. Source attribution of air pollution by spatial scale separation using high spatial density networks of low cost air quality sensors. Atmos. Environ. 2015, 113, 10–19. [Google Scholar] [CrossRef] [Green Version]
- Lewis, A.; Peltier, W.R.; von Schneidemesser, E. Low-cost sensors for the measurement of atmospheric composition: overview of topic and future applications; World Meteorological Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Zimmerman, N.; Presto, A.A.; Kumar, S.P.N.; Gu, J.; Hauryliuk, A.; Robinson, E.S.; Robinson, A.L.; Subramanian, R. Closing the gap on lower cost air quality monitoring: machine learning calibration models to improve low-cost sensor performance. Atmos. Meas. Tech. Discuss 2017, 2017, 1–36. [Google Scholar] [CrossRef]
- Alphasense Ltd. AAN 105-03: Designing a Potentiostatic Circuit. Available online: http://www.alphasense.com/WEB1213/wp-content/uploads/2013/07/AAN_105-03.pdf (accessed on 18 October 2018).
- Romain, A.C.; Nicolas, J. Long term stability of metal oxide-based gas sensors for e-nose environmental applications: An overview. Sens. Actuators B Chem. 2010, 146, 502–506. [Google Scholar] [CrossRef] [Green Version]
- Miskell, G.; Salmond, J.; Grange, S.; Weissert, L.; Henshaw, G.; Williams, D. Reliable long-Term data from low-cost gas sensor networks in the environment. Proceedings 2017, 1, 400. [Google Scholar] [CrossRef]
- Shamasunder, B.; Collier-Oxandale, A.; Blickley, J.; Sadd, J.; Chan, M.; Navarro, S.; Hannigan, M.; Wong, N.J. Community-based health and exposure study around urban oil developments in South Los Angeles. Int. J. Environ. Res. Public Health 2018, 15, 138. [Google Scholar] [CrossRef] [PubMed]
- Airgas Specialty Gases and Equipment Product Reference Guide. Available online: http://airgassgcatalog.com/catalog/ (accessed on 2 December 2018).
- Westerholm, R.; Egebäck, K.E. Exhaust emissions from light- and heavy-duty vehicles: Chemical composition, impact of exhaust after treatment, and fuel parameters. Environ. Health Perspect. 1994, 102, 13–23. [Google Scholar]
- Akagi, S.K.; Yokelson, R.J.; Wiedinmyer, C.; Alvarado, M.J.; Reid, J.S.; Karl, T.; Crounse, J.D.; Wennberg, P.O. Emission factors for open and domestic biomass burning for use in atmospheric models. Atmos. Chem. Phys. 2011, 11, 4039–4072. [Google Scholar] [CrossRef] [Green Version]
- US Environmental Protection Agency. 2014 National Emission Inventory (NEI) Report. 2016. Available online: https://www.epa.gov/air-emissions-inventories/2014-national-emission-inventory-nei-report (accessed on 9 December 2018).
- Yokelson, R.J.; Burling, I.R.; Gilman, J.B.; Warneke, C.; Stockwell, C.E.; Gouw, J.D.; Akagi, S.K.; Urbanski, S.P.; Veres, P.; Roberts, J.M.; et al. Coupling field and laboratory measurements to estimate the emission factors of identified and unidentified trace gases for prescribed fires. Atmos. Chem. Phys. 2013, 13, 89–116. [Google Scholar] [CrossRef] [Green Version]
- Tsujita, W.; Yoshino, A.; Ishida, H.; Moriizumi, T. Gas sensor network for air-pollution monitoring. Sens. Actuators B Chem. 2005, 110, 304–311. [Google Scholar] [CrossRef]
- Suárez, J.I.; Arroyo, P.; Lozano, J.; Herrero, J.L.; Padilla, M. Bluetooth gas sensing module combined with smartphones for air quality monitoring. Chemosphere 2018, 205, 618–626. [Google Scholar] [CrossRef] [PubMed]
- Casey, J.G.; Collier-Oxandale, A.; Hannigan, M.P. Performance of artificial neural networks and linear models to quantify 4 trace gas species in an oil and gas production region with low-cost sensors. Sens. Actuators B Chem. 2019, 283, 504–514. [Google Scholar] [CrossRef]
- De Vito, S.; Esposito, E.; Salvato, M.; Popoola, O.; Formisano, F.; Jones, R.; Di Francia, G. Calibrating chemical multisensory devices for real world applications: An in-depth comparison of quantitative machine learning approaches. Sens. Actuators B Chem. 2018, 255, 1191–1210. [Google Scholar] [CrossRef]
- Bigi, A.; Mueller, M.; Grange, S.K.; Ghermandi, G.; Hueglin, C. Performance of NO, NO2 low cost sensors and three calibration approaches within a real world application. Atmos. Measur. Tech. 2018, 11, 3717–3735. [Google Scholar] [CrossRef]
- Marco, S.; Gutierrez-Galvez, A. Signal and data processing for machine olfaction and chemical sensing: A review. IEEE Sens. J. 2012, 12, 3189–3214. [Google Scholar] [CrossRef]
- Vembu, S.; Vergara, A.; Muezzinoglu, M.K.; Huerta, R. On time series features and kernels for machine olfaction. Sens. Actuators B Chem. 2012, 174, 535–546. [Google Scholar] [CrossRef]
- Tomchenko, A.A.; Harmer, G.P.; Marquis, B.T.; Allen, J.W. Semiconducting metal oxide sensor array for the selective detection of combustion gases. Sens. Actuators B Chem. 2003, 93, 126–134. [Google Scholar] [CrossRef]
- Schüler, M.; Fricke, T.; Sauerwald, T.; Schütze, A. E8.4-Detecting poisoning of metal oxide gas sensors at an early stage by temperature cycled operation. Proceedings SENSOR 2015, 2015, 735–739. [Google Scholar]
- Bastuck, M.; Bur, C.; Lloyd Spetz, A.; Andersson, M.; Schütze, A. Gas identification based on bias induced hysteresis of a gas-sensitive SiC field effect transistor. J. Sens. Sens. Syst. 2014, 3, 9–19. [Google Scholar] [CrossRef] [Green Version]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: New York, NY, USA, 2014; ISBN 978-1-107-05713-5. [Google Scholar]
- Morel, P. Gramm: Grammar of graphics plotting in Matlab. J. Open Source Softw. 2018, 3, 568. [Google Scholar] [CrossRef]
- Collier-Oxandale, A.; Hannigan, M.P.; Casey, J.G.; Piedrahita, R.; Ortega, J.; Halliday, H.; Johnston, J. Assessing a low-cost methane sensor quantification system for use in complex rural and urban environments. Atmos. Meas. Tech. Discuss 2018, 2018, 1–35. [Google Scholar] [Green Version]
- Masson, N.; Piedrahita, R.; Hannigan, M. Approach for quantification of metal oxide type semiconductor gas sensors used for ambient air quality monitoring. Sens. Actuators B Chem. 2015, 208, 339–345. [Google Scholar] [CrossRef]
- Schütze, A.; Baur, T.; Leidinger, M.; Reimringer, W.; Jung, R.; Conrad, T.; Sauerwald, T. Highly sensitive and selective VOC sensor systems based on semiconductor gas sensors: How to? Environments 2017, 4, 20. [Google Scholar] [CrossRef]
- Zimmerman, N.; Presto, A.A.; Kumar, S.P.N.; Gu, J.; Hauryliuk, A.; Robinson, E.S.; Robinson, A.L.; Subramanian, R. A machine learning calibration model using random forests to improve sensor performance for lower-cost air quality monitoring. Atmos. Measur. Tech. Katlenburg Lindau 2018, 11, 291–313. [Google Scholar] [CrossRef] [Green Version]
- Szczurek, A.; Szecówka, P.M.; Licznerski, B.W. Application of sensor array and neural networks for quantification of organic solvent vapours in air. Sens. Actuators B Chem. 1999, 58, 427–432. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Manufacturer | Model | Target Gas | Technology |
|---|---|---|---|
| Baseline Mocon 1 | piD-TECH 0–20 ppm | Volatile Organic Compounds (VOCs) | Photoionization (PID) |
| ELT 2 | S300 | Carbon Dioxide (CO2) | Nondispersive Infrared (NDIR) |
| Alphasense 3 | H2S-BH | Hydrogen Sulfide (H2S) | Electrochemical |
| O3-B4 | Ozone (O3) | Electrochemical | |
| NO2-B1 | Nitrogen Dioxide (NO2) | Electrochemical | |
| CO-B4 | Carbon Monoxide (CO) | Electrochemical | |
| NO-B4 | Nitric Oxide (NO) | Electrochemical | |
| Figaro 4 | TGS 2602 | “VOCs and odorous gases” | Metal Oxide |
| TGS 2600 | “Air Contaminants” | Metal Oxide | |
| TGS 2611 | Methane (CH4) | Metal Oxide | |
| TGS 4161 | Carbon Dioxide (CO2) | Metal Oxide | |
| e2v 5 | MiCS-5525 | Carbon Monoxide (CO) | Metal Oxide |
| MiCS-2611 | Ozone (O3) | Metal Oxide | |
| MiCS-2710 | Nitrogen Dioxide (NO2) | Metal Oxide | |
| MiCS-5121WP | CO/VOCs | Metal Oxide |
| Source | Component Gases |
|---|---|
| Biomass Burning | CO, CO2 |
| Mobile Sources | CO, CO2, NO2 |
| Gasoline/Oil and Gas Condensates | Gasoline Vapor |
| Natural Gas Leaks | CH4, C2H6, C3H8 |
| Classification Model | ||||||
|---|---|---|---|---|---|---|
| Logistic_class | NeurNet_class | RandFor_class | SVMgaus_class | SVMlin_class | ||
| Regression Model | FullLM | 0.677 | 0.417 | 0.718 | 0.610 | 0.711 |
| GaussProc | 0.416 | 0.401 | 0.394 | 0.288 | 0.535 | |
| NeurNet | 0.596 | 0.496 | 0.690 | 0.569 | 0.596 | |
| RandFor | 0.332 | 0.442 | 0.479 | 0.578 | 0.556 | |
| RidgeLM | 0.521 | 0.376 | 0.570 | 0.493 | 0.596 | |
| SelectLM | 0.600 | 0.531 | 0.545 | 0.493 | 0.596 | |
| StepLM | 0.695 | 0.502 | 0.619 | 0.614 | 0.616 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thorson, J.; Collier-Oxandale, A.; Hannigan, M. Using A Low-Cost Sensor Array and Machine Learning Techniques to Detect Complex Pollutant Mixtures and Identify Likely Sources. Sensors 2019, 19, 3723. https://doi.org/10.3390/s19173723
Thorson J, Collier-Oxandale A, Hannigan M. Using A Low-Cost Sensor Array and Machine Learning Techniques to Detect Complex Pollutant Mixtures and Identify Likely Sources. Sensors. 2019; 19(17):3723. https://doi.org/10.3390/s19173723
Chicago/Turabian StyleThorson, Jacob, Ashley Collier-Oxandale, and Michael Hannigan. 2019. "Using A Low-Cost Sensor Array and Machine Learning Techniques to Detect Complex Pollutant Mixtures and Identify Likely Sources" Sensors 19, no. 17: 3723. https://doi.org/10.3390/s19173723
APA StyleThorson, J., Collier-Oxandale, A., & Hannigan, M. (2019). Using A Low-Cost Sensor Array and Machine Learning Techniques to Detect Complex Pollutant Mixtures and Identify Likely Sources. Sensors, 19(17), 3723. https://doi.org/10.3390/s19173723