Evaluating a Spoken Dialogue System for Recording Systems of Nursing Care


Abstract
:1. Introduction
2. Background
3. Methods
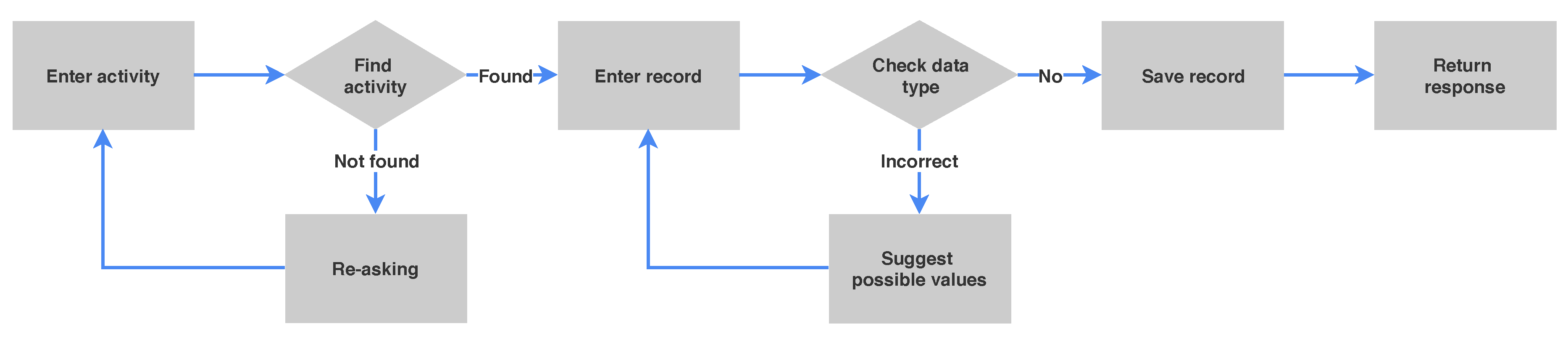
3.1. Dialogue System
3.2. Proposed Method
3.3. User Request Process
3.4. Data Collection
4. Implementation
4.1. Dialogue System Application
4.2. Dialogue System Web Server
5. Experimental Setup
6. Preliminary Evaluation
6.1. Measures of the Dialogue System Feasibility
6.2. Measures of the Dialogue System Usability
- –
- Q1: Was the system easy to understand?
- –
- Q2: Did the system understand what you said?
- –
- Q3: Was it easy to record the information you wanted?
- –
- Q4: Was the pace of interaction with the system appropriate?
- –
- Q5: Did you know what you could say at each point in the dialogue?
7. Limitations and Future Research
7.1. User Interface
7.2. Internet Connection
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| SDS | Spoken dialogue system |
| DSCR | Dialogue system care record |
| EHR | Electronic health record |
| E-forms | Electronic forms |
| NLP | Natural language processing |
| NLU | Natural language understanding |
| NLG | Natural language generation |
| DST | Dialogue state tracking |
| M2M | Machine-to-Machine |
References
- Kelley, T.F.; Brandon, D.H.; Docherty, S.L. Electronic nursing documentation as a strategy to improve quality of patient care. J. Nurs. Scholarsh. 2011, 43, 154–162. [Google Scholar] [CrossRef] [PubMed]
- Inoue, S.; Ueda, N.; Nohara, Y.; Nakashima, N. Mobile activity recognition for a whole day: Recognizing real nursing activities with big dataset. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 1269–1280. [Google Scholar]
- Hripcsak, G.; Vawdrey, D.K.; Fred, M.R.; Bostwick, S.B. Use of electronic clinical documentation: Time spent and team interactions. J. Am. Med Inform. Assoc. 2011, 18, 112–117. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.J.; Middleton, B.; Prosser, L.A.; Bardon, C.G.; Spurr, C.D.; Carchidi, P.J.; Kittler, A.F.; Goldszer, R.C.; Fairchild, D.G.; Sussman, A.J.; et al. A cost-benefit analysis of electronic medical records in primary care. Am. J. Med. 2003, 114, 397–403. [Google Scholar] [CrossRef]
- Lau, S.L.; König, I.; David, K.; Parandian, B.; Carius-Düssel, C.; Schultz, M. Supporting patient monitoring using activity recognition with a smartphone. In Proceedings of the 2010 7th International Symposium on Wireless Communication Systems, York, UK, 19–22 September 2010; pp. 810–814. [Google Scholar]
- Abdulnabi, M.; Al-Haiqi, A.; Kiah, M.L.M.; Zaidan, A.; Zaidan, B.; Hussain, M. A distributed framework for health information exchange using smartphone technologies. J. Biomed. Inform. 2017, 69, 230–250. [Google Scholar] [CrossRef] [PubMed]
- Dawson, L.; Johnson, M.; Suominen, H.; Basilakis, J.; Sanchez, P.; Estival, D.; Kelly, B.; Hanlen, L. A usability framework for speech recognition technologies in clinical handover: A pre-implementation study. J. Med Syst. 2014, 38, 56. [Google Scholar] [CrossRef] [PubMed]
- Suominen, H.; Zhou, L.; Hanlen, L.; Ferraro, G. Benchmarking clinical speech recognition and information extraction: New data, methods, and evaluations. JMIR Med. Inform. 2015, 3, e19. [Google Scholar] [CrossRef] [PubMed]
- Fratzke, J.; Tucker, S.; Shedenhelm, H.; Arnold, J.; Belda, T.; Petera, M. Enhancing nursing practice by utilizing voice recognition for direct documentation. J. Nurs. Adm. 2014, 44, 79–86. [Google Scholar] [CrossRef] [PubMed]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing; Pearson: London, UK, 2014; Volume 3. [Google Scholar]
- Morbini, F.; Forbell, E.; DeVault, D.; Sagae, K.; Traum, D.; Rizzo, A. A mixed-initiative conversational dialogue system for healthcare. In Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Seoul, Korea, 14 March 2012; pp. 137–139. [Google Scholar]
- Laranjo, L.; Dunn, A.G.; Tong, H.L.; Kocaballi, A.B.; Chen, J.; Bashir, R.; Surian, D.; Gallego, B.; Magrabi, F.; Lau, A.Y.; et al. Conversational agents in healthcare: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1248–1258. [Google Scholar] [CrossRef] [PubMed]
- Spiliotopoulos, D.; Androutsopoulos, I.; Spyropoulos, C.D. Human-robot interaction based on spoken natural language dialogue. In Proceedings of the European Workshop on Service and Humanoid Robots, Santorini, Greece, 25–27 June 2001; pp. 25–27. [Google Scholar]
- Chu-Carroll, J. MIMIC: An adaptive mixed initiative spoken dialogue system for information queries. In Proceedings of the Sixth Conference on Applied Natural Language Processing, Seattle, WA, USA, 29 April–4 May 2000; pp. 97–104. [Google Scholar]
- Microsoft. Microsoft Cortana. Available online: https://www.microsoft.com/en-us/cortana (accessed on 2 April 2014).
- Amazon. Amazon Alexa. Available online: https://developer.amazon.com/alexa (accessed on 1 November 2014).
- Google. Google Assistant. Available online: https://assistant.google.com (accessed on 18 May 2016).
- Google. Google Home. Available online: https://store.google.com/category/google_nest (accessed on 4 November 2016).
- Raux, A.; Eskenazi, M. Using task-oriented spoken dialogue systems for language learning: Potential, practical applications and challenges. In Proceedings of the InSTIL/ICALL Symposium 2004, Venice, Italy, 17–19 June 2004. [Google Scholar]
- Van Oijen, J.; Van Doesburg, W.; Dignum, F. Goal-based communication using bdi agents as virtual humans in training: An ontology driven dialogue system. In Proceedings of the International Workshop on Agents for Games and Simulations, Toronto, ON, Canada, 10 May 2010; pp. 38–52. [Google Scholar]
- Yu, Z.; Papangelis, A.; Rudnicky, A. TickTock: A non-goal-oriented multimodal dialog system with engagement awareness. In Proceedings of the 2015 AAAI Spring Symposium Series, Palo Alto, CA, USA, 23–25 March 2015. [Google Scholar]
- Nio, L.; Sakti, S.; Neubig, G.; Toda, T.; Adriani, M.; Nakamura, S. Developing non-goal dialog system based on examples of drama television. In Natural Interaction with Robots, Knowbots and Smartphones; Springer: Berlin, Germany, 2014; pp. 355–361. [Google Scholar]
- Thompson, W.K.; Bliss, H.M. Frame Goals for Dialog System. U.S. Patent 7,657,434, 2 February 2010. [Google Scholar]
- Miller, A.H.; Feng, W.; Fisch, A.; Lu, J.; Batra, D.; Bordes, A.; Parikh, D.; Weston, J. Parlai: A dialog research software platform. arXiv 2017, arXiv:1705.06476. [Google Scholar]
- Shah, P.; Hakkani-Tür, D.; Tür, G.; Rastogi, A.; Bapna, A.; Nayak, N.; Heck, L. Building a Conversational Agent Overnight with Dialogue Self-Play. arXiv 2018, arXiv:1801.04871. [Google Scholar]
- Google. Dialogflow. Available online: https://dialogflow.com (accessed on 10 October 2017).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activity | Record | Type | Possible Values |
|---|---|---|---|
| Measuring vital signs | Maximum blood pressure | Input | greater than or equal to 0 |
| Minimum blood pressure | Input | greater than or equal to 0 | |
| Pulse beat (bpm) | Input | greater than or equal to 0 | |
| Body temperature (c) | Input | greater than or equal to 0 | |
| Weight (kg) | Input | greater than or equal to 0 | |
| Height (cm) | Input | greater than or equal to 0 | |
| Note | Text | e.g., being sick, skin colors, have a fever, pain complaint | |
| Meal and medication | Meal assistance | Select | self-reliance, setting only, partial care, full care |
| Dietary volume | Select | 0 to 10 | |
| Meal size | Select | 0 to 10 | |
| Amount of water | Select | 0 to 500 | |
| Medication | Select | self-reliance, assistance, no medication | |
| Note | Text | e.g., dysphagia, appetite loss, using ThickenUp clear | |
| Oral care | Oral cleaning | Select | self-reliance, setting only, partial care, full care, no cleaning |
| Denture cleaning | Select | use of detergent, wash in water, no cleaning | |
| Note | Text | e.g., using sponge brush, using interdental brush, using dental floss, oral wound | |
| Excretion | Method of excretion | Select | toilet, portable toilet, urinal, on the bed |
| Excretion assistance | Select | self-reliance, setting only, partial care, full care | |
| Mode of Excretion | Select | defecation, urination, fecal incontinence, urinary incontinence, no excretion | |
| Urine volume | Select | small, medium, large, no choice | |
| Defecation volume | Select | small, medium, large, no choice | |
| Type of Waste | Select | watery mail, muddy stool, ordinary, hard stool, colo flight, no choice | |
| Diapering | Select | putt exchange, rehapan replacement, diaper change, wipe, vulva cleaning, change assistance | |
| Note | Text | e.g., hematuria, bloody stools, a tight stomach | |
| Bathing | Bathing method | Select | general bath, shower bath, machine bath, wipe, it was planned to bathe but there was no conduct |
| Bathing assistance | Select | self-reliance, setting only, partial care, full care | |
| Use of bath aids | Text | e.g., shower carry use |
| Experiment | Descriptive | Vital Signs | Meal | Med | Oral Care | Excretion | Bathing |
|---|---|---|---|---|---|---|---|
| Dialogue | Mean | 25.07 | 26.8 | 18.61 | 40.45 | 27.53 | 27.69 |
| Std | 2.84 | 3.32 | 1.57 | 3.23 | 1.42 | 2.47 | |
| Min | 20.97 | 22.47 | 16.3 | 36.12 | 25.2 | 24.21 | |
| Max | 29.54 | 31.7 | 21.32 | 44.76 | 29 | 31.26 | |
| E-forms | Mean | 31.31 | 35.82 | 22.03 | 44.77 | 29.88 | 32.76 |
| Std | 2.15 | 2.86 | 2.38 | 3.13 | 1.96 | 2.49 | |
| Min | 28.35 | 31.29 | 18.27 | 40.34 | 27.18 | 29.08 | |
| Max | 34.17 | 39.83 | 26.09 | 49.59 | 32.82 | 36.5 |
| Activity | Speech Error | Intent Error |
|---|---|---|
| Measuring vital signs | 6.4% | 0.8% |
| Meal & Medication | 3.2% | 0.8% |
| Oral care | 4.0% | 0.7% |
| Excretion | 7.3% | 1.0% |
| Bathing | 3.6% | 0.4% |
| Sum | 24.5% | 3.69% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mairittha, T.; Mairittha, N.; Inoue, S. Evaluating a Spoken Dialogue System for Recording Systems of Nursing Care. Sensors 2019, 19, 3736. https://doi.org/10.3390/s19173736
Mairittha T, Mairittha N, Inoue S. Evaluating a Spoken Dialogue System for Recording Systems of Nursing Care. Sensors. 2019; 19(17):3736. https://doi.org/10.3390/s19173736
Chicago/Turabian StyleMairittha, Tittaya, Nattaya Mairittha, and Sozo Inoue. 2019. "Evaluating a Spoken Dialogue System for Recording Systems of Nursing Care" Sensors 19, no. 17: 3736. https://doi.org/10.3390/s19173736
APA StyleMairittha, T., Mairittha, N., & Inoue, S. (2019). Evaluating a Spoken Dialogue System for Recording Systems of Nursing Care. Sensors, 19(17), 3736. https://doi.org/10.3390/s19173736