A Non-Invasive Method Based on Computer Vision for Grapevine Cluster Compactness Assessment Using a Mobile Sensing Platform under Field Conditions


Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Layout
- Vineyard site #1: Located in Logroño (lat. 42°27′42.3″N; long. 2°25′40.4″W; La Rioja, Spain) with 2.8 m row spacing and 1.2 m vine spacing, where a set of 95 Tempranillo clusters were imaged and sampled during season 2016, denoted as T16.
- Vineyard site #2: Located in Logroño (lat. 42°28′34.2″N; long. 2°29′10.0″W; La Rioja, Spain) with 2.5 m row spacing and 1 m vine spacing, where a set of 25 Grenache clusters were imaged and sampled during season 2017, denoted as G17.
- Vineyard site #3: Located in Vergalijo (lat. 42°27’46.0” N; long. 1°48’13.1” W; Navarra, Spain) with 2 m row spacing and 1 m vine spacing, where three sets of 75 clusters of Syrah, Cabernet Sauvignon, and Tempranillo (25 per grapevine variety) were imaged and sampled during season 2018, denoted as S18, CS18, and T18, respectively.
2.2. Image Acquisition
- RGB camera: a mirrorless Sony α7II RGB camera (Sony Corp., Tokyo, Japan) mounting a full-frame complementary metal oxide semiconductor (CMOS) sensor (35 mm and 24.3 MP resolution) and equipped with a Zeiss 24/70 mm lens was used for image acquisition in vineyard sites #1 and #2, while a Canon EOS 5D Mark IV RGB camera (Canon Inc. Tokyo, Japan) mounting a full-frame CMOS sensor (35 mm and 30.4 MP) equipped with a Canon EF 35 mm F/2 IS USM lens was used in vineyard site #3.
- Industrial computer: A Nuvo-3100VTC industrial computer was used for image storage and camera parameters setting for the Canon EOS 5D Mark IV using custom software developed, while the parameters of the Sony α7II camera were set in the camera itself and the storage in a Secure Digital (SD)-card.
2.3. Reference Measurements of Cluster Compactness
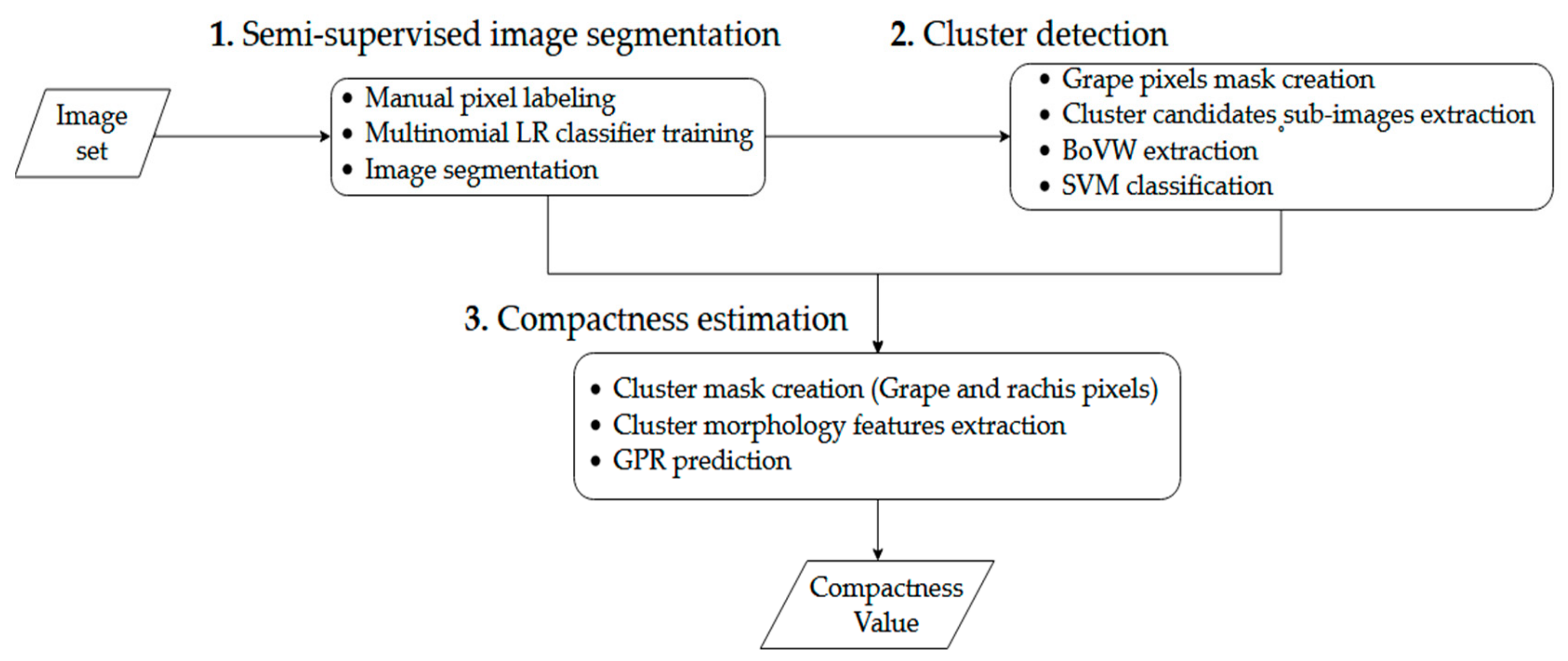
2.4. Image Processing
2.4.1. Semi-Supervised Image Segmentation
2.4.2. Cluster Detection
- A morphological opening (morphological erosion operation followed by a dilation) of the clusters’ candidates mask using a circular kernel with a radius of three pixels.
- An extraction of a sub-image per minimal bounding box that contains a connected component (groups of connected pixels) in the clusters’ candidates mask.
- An extraction of features for each sub-image that represents the information contained on it. For this, the bag-of-visual-words (BoVW) was employed.
- A classification of “cluster” vs. “non-cluster” sub-images.
- To extract SURF points for every sub-image.
- Cluster SURF points applying k-means. The set of cluster centroids would form the codebook of k codewords.
- Extraction of the bag-of-words per sub-image:
- To assign each SURF point of the image to the nearest centroid of the codebook.
- To calculate the histogram by counting the number of SURF points assigned to each centroid.
2.4.3. Cluster Compactness Estimation
- A new mask using only pixels of “grape” and “rachis” classes was created.
- A morphological opening on “grape” pixels using a circular kernel with a radius of two pixels was applied.
- A morphological opening on “rachis” pixels using a circular kernel with a radius of two pixels was also applied.
- A mask containing only the largest connected component formed by “grape” and “rachis” pixels, denoted as mask “A”, was created.
- A mask containing the convex hulls of each “grape” pixel’s connected component (that can represent several grouped berries on compact clusters or isolated grapes on loose clusters), denoted as mask “B”, was created.
- The final mask was created containing “grape” pixels and “rachis” pixels that were in mask “A” and inside the region of the convex hull of mask “B”. Those “rachis” pixels in mask “A” that were outside of the convex hull of mask “B” and connected at least two connected components of “grape” pixels were included as well.
- Ratio of the area of the convex hull body of the cluster corresponding to holes (AH)
- Ratio of the clusters area corresponding to berries (AB)
- Ratio of the area corresponding to “rachis” (AR)
- Average width at % of the length of the cluster (W25)
- Average width at % of the length of the cluster (W50)
- Average width at % of the length of the cluster (W75)
- Ratio between “rachis” and “grape” pixels (RatioRG)
- Roundness of “grape” pixels (RDGrape):
- Compactness shape factor of “grape” pixels (CSFGrape):
- Ratio between the maximum width and the length of the cluster (AS)
- Ratio between W75 and W25 (RatioW75_W25)
- Proportion of the “rachis” pixels “inside” the cluster (RRin)
- Proportion of the “rachis” pixels “outside” the cluster (RRout)
- Ratio of the area of the cluster over the mean area of the clusters of its set (RAoM)
2.4.4. Performance Evaluation Metrics
2.4.5. Hyperparameter’s Optimization Procedure
3. Results and Discussion
3.1. Initial Segmentation Performance
3.2. Cluster Detection Performance
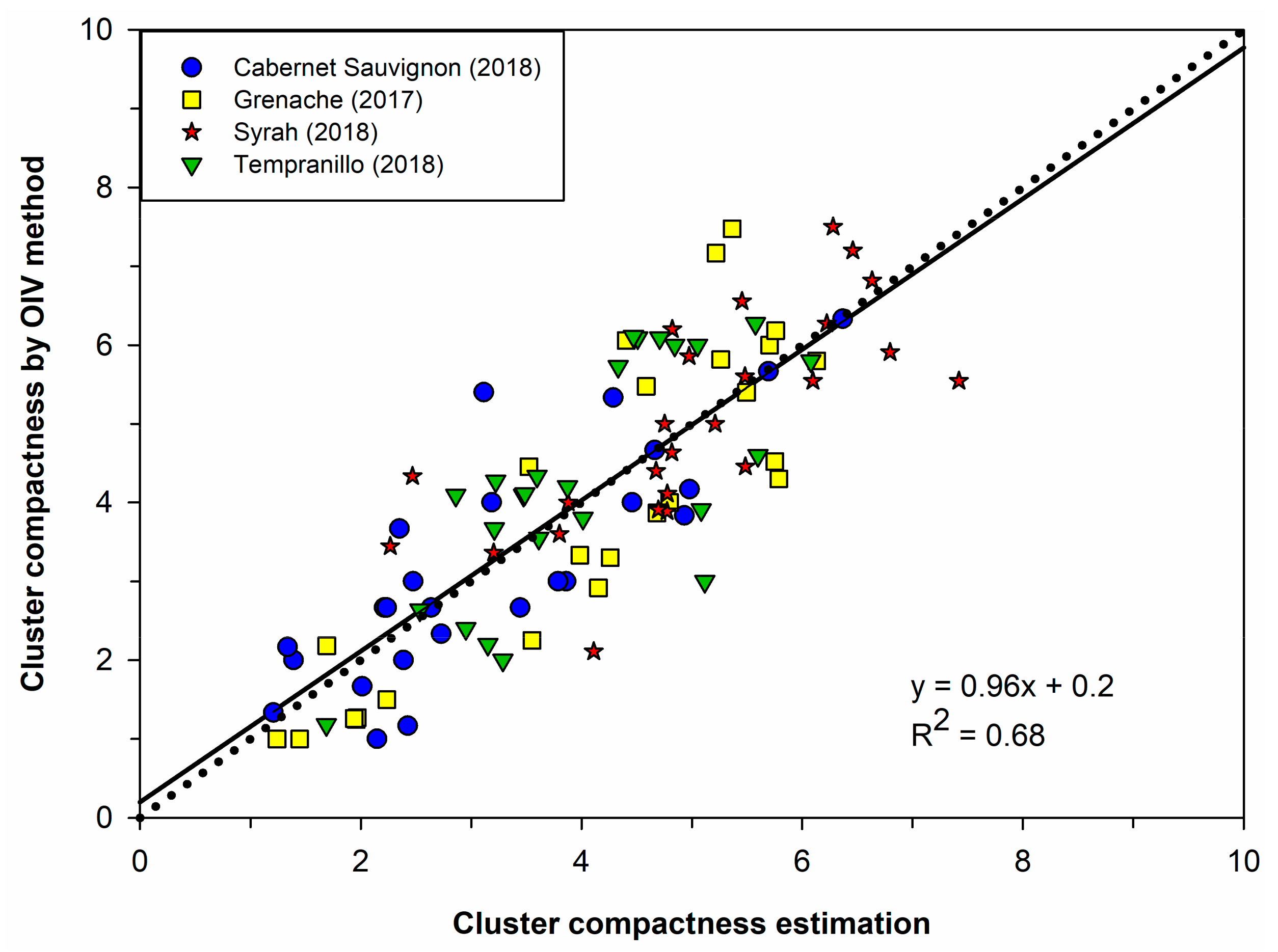
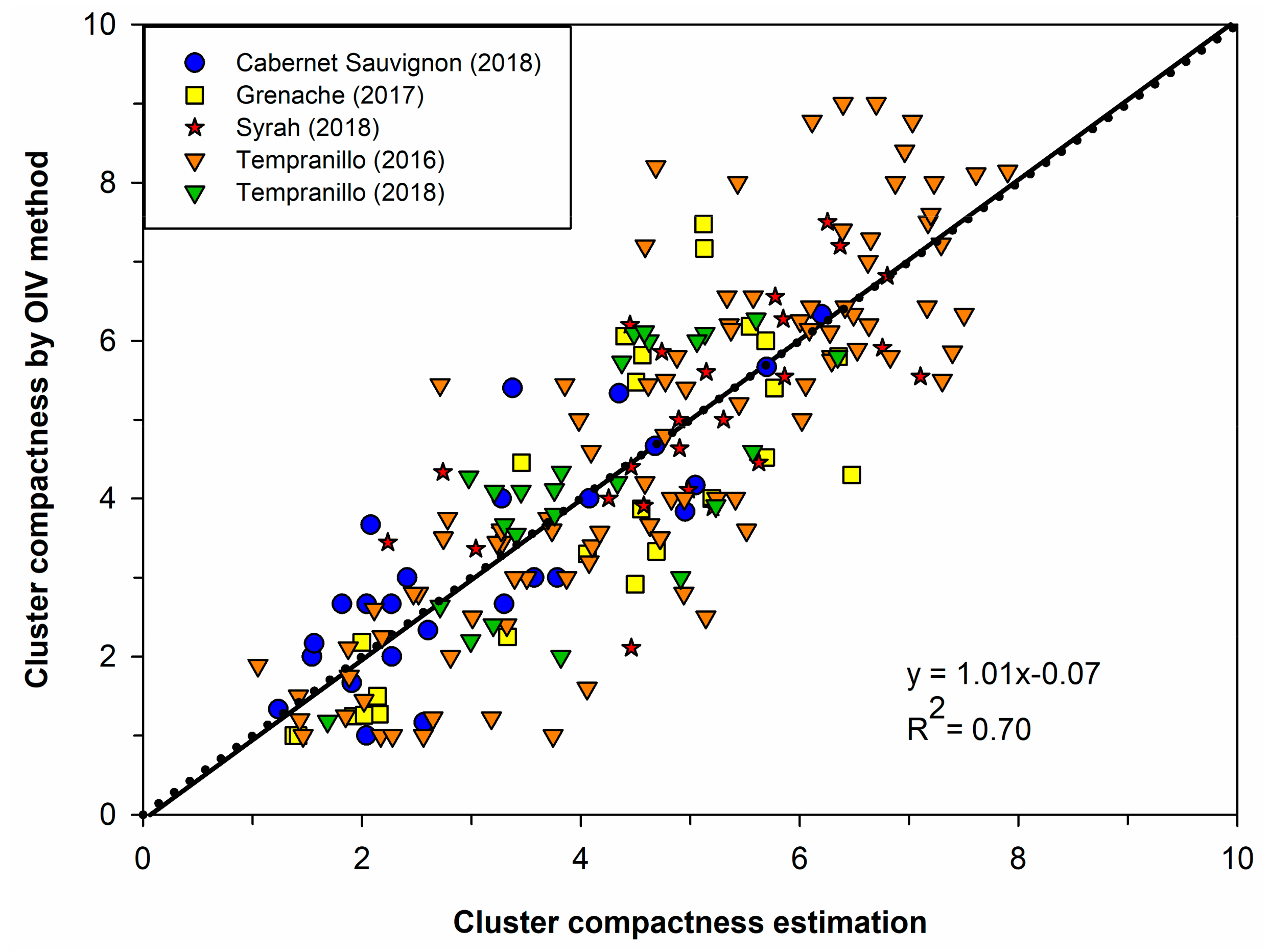
3.3. Cluster Compactness Estimation
- Occlusion of the cluster: the estimation was only performed on the visible region of the cluster. Therefore, a high level of occlusion of the cluster could increase the estimation error. An example of a cluster partially occluded by leaves is shown in Figure 9a and the final mask extracted for compactness estimation in Figure 9b, where the cluster mask presents an anomalous shape that would lead to incorrect compactness estimation.
- Cluster overlapping: highly overlapped clusters would be identified as one, and therefore a unique estimation would be obtained, associated with the set of overlapped clusters. An example is illustrated in Figure 9c, where a set of clusters are overlapped, and in the extracted mask (Figure 9d), the clusters cannot be separated from each other for proper individual compactness estimation.
3.4. Commercial Applicability
3.5. Future Work
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hed, B.; Ngugi, H.K.; Travis, J.W. Relationship between cluster compactness and bunch rot in Vignoles grapes. Plant Dis. 2009, 93, 1195–1201. [Google Scholar] [CrossRef] [PubMed]
- Tello, J.; Marcos, J.I. Evaluation of indexes for the quantitative and objective estimation of grapevine bunch compactness. Vitis 2014, 53, 9–16. [Google Scholar]
- Austin, C.N.; Wilcox, W.F. Effects of sunlight exposure on grapevine powdery mildew development. Phytopathology 2012, 102, 857–866. [Google Scholar] [CrossRef] [PubMed]
- Vail, M.; Marois, J. Grape cluster architecture and the susceptibility of berries to Botrytis cinerea. Phytopathology 1991, 81, 188–191. [Google Scholar] [CrossRef]
- Molitor, D.; Behr, M.; Hoffmann, L.; Evers, D. Research note: Benefits and drawbacks of pre-bloom applications of gibberellic acid (GA3) for stem elongation in Sauvignon blanc. S. Afr. J. Enol. Vitic. 2012, 33, 198–202. [Google Scholar] [CrossRef]
- OIV. OIV Descriptor list for grape varieties and Vitis species. OIV 2009, 18, 178. Available online: http://www.oiv.int/public/medias/2274/code-2e-edition-finale.pdf (accessed on 2 September 2019).
- Palliotti, A.; Gatti, M.; Poni, S. Early leaf removal to improve vineyard efficiency: gas exchange, source-to-sink balance, and reserve storage responses. Am. J. Enol. Vitic. 2011, 62, 219–228. [Google Scholar] [CrossRef]
- Tardaguila, J.; Blanco, J.; Poni, S.; Diago, M. Mechanical yield regulation in winegrapes: Comparison of early defoliation and crop thinning. Aust. J. Grape Wine Res. 2012, 18, 344–352. [Google Scholar] [CrossRef]
- Zabadal, T.J.; Bukovac, M.J. Effect of CPPU on fruit development of selected seedless and seeded grape cultivars. HortScience 2006, 41, 154–157. [Google Scholar] [CrossRef]
- Evers, D.; Molitor, D.; Rothmeier, M.; Behr, M.; Fischer, S.; Hoffmann, L. Efficiency of different strategies for the control of grey mold on grapes including gibberellic acid (Gibb3), leaf removal and/or botrycide treatments. OENO One 2010, 44, 151–159. [Google Scholar] [CrossRef]
- Tello, J.; Aguirrezábal, R.; Hernáiz, S.; Larreina, B.; Montemayor, M.I.; Vaquero, E.; Ibáñez, J. Multicultivar and multivariate study of the natural variation for grapevine bunch compactness. Aust. J. Grape Wine Res. 2015, 21, 277–289. [Google Scholar] [CrossRef]
- Kicherer, A.; Klodt, M.; Sharifzadeh, S.; Cremers, D.; Töpfer, R.; Herzog, K. Automatic image-based determination of pruning mass as a determinant for yield potential in grapevine management and breeding. Aust. J. Grape Wine Res. 2017, 23, 120–124. [Google Scholar] [CrossRef]
- Millan, B.; Diago, M.P.; Aquino, A.; Palacios, F.; Tardaguila, J. Vineyard pruning weight assessment by machine vision: towards an on-the-go measurement system. OENO One 2019, 53. [Google Scholar] [CrossRef]
- Aquino, A.; Millan, B.; Gutiérrez, S.; Tardáguila, J. Grapevine flower estimation by applying artificial vision techniques on images with uncontrolled scene and multi-model analysis. Comput. Electron. Agric. 2015, 119, 92–104. [Google Scholar] [CrossRef]
- Liu, S.; Li, X.; Wu, H.; Xin, B.; Petrie, P.R.; Whitty, M. A robust automated flower estimation system for grape vines. Biosystems Eng. 2018, 172, 110–123. [Google Scholar] [CrossRef]
- Diago, M.P.; Krasnow, M.; Bubola, M.; Millan, B.; Tardaguila, J. Assessment of vineyard canopy porosity using machine vision. Am. J. Enol. Vitic. 2016, 67, 229–238. [Google Scholar] [CrossRef]
- Nuske, S.; Wilshusen, K.; Achar, S.; Yoder, L.; Narasimhan, S.; Singh, S. Automated visual yield estimation in vineyards. J. Field Rob. 2014, 31, 837–860. [Google Scholar] [CrossRef]
- Millan, B.; Velasco-Forero, S.; Aquino, A.; Tardaguila, J. On-the-Go Grapevine Yield Estimation Using Image Analysis and Boolean Model. J. Sens. 2018, 2018. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Zou, X.; Ye, M.; Feng, W.; Li, G. Vision-based extraction of spatial information in grape clusters for harvesting robots. Biosystems Eng. 2016, 151, 90–104. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Lu, Q.; Chen, X.; Zhang, P.; Zou, X. A vision methodology for harvesting robot to detect cutting points on peduncles of double overlapping grape clusters in a vineyard. Comput. Ind. 2018, 99, 130–139. [Google Scholar] [CrossRef]
- Cubero, S.; Diago, M.P.; Blasco, J.; Tardáguila, J.; Prats-Montalbán, J.M.; Ibáñez, J.; Tello, J.; Aleixos, N. A new method for assessment of bunch compactness using automated image analysis. Aust. J. Grape Wine Res. 2015, 21, 101–109. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Ding, H.; Yuan, L.-M.; Cai, J.-R.; Chen, X.; Lin, Y. New approach of simultaneous, multi-perspective imaging for quantitative assessment of the compactness of grape bunches. Aust. J. Grape Wine Res. 2018, 24, 413–420. [Google Scholar] [CrossRef]
- Diago, M.P.; Aquino, A.; Millan, B.; Palacios, F.; Tardaguila, J. On-the-go assessment of vineyard canopy porosity, bunch and leaf exposure by image analysis. Aust. J. Grape Wine Res. 2019, 25, 363–374. [Google Scholar] [CrossRef]
- Luo, M.R. CIELAB. In Encyclopedia of Color Science and Technology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–7. [Google Scholar]
- Dobson, A.J.; Barnett, A. An introduction to generalized linear models; Chapman and Hall/CRC: New York, NY, USA, 2008. [Google Scholar]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on statistical learning in computer vision, ECCV, Prague, Czech Republic, 15 May 2004; pp. 1–2. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. Springer 2006, 3951, 404–417. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Mockus, J.; Tiesis, V.; Zilinskas, A. The application of Bayesian methods for seeking the extremum. In Towards Global Optimization; Elsevier: Amsterdam, The Netherlands, 2014; pp. 117–129. [Google Scholar]
- Jones, D.R. A Taxonomy of Global Optimization Methods Based on Response Surfaces. J. Glob. Optim. 2001, 21, 345–383. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kernel Function (fixed) | Optimized Hyperparameters Range | Final Values | |||
|---|---|---|---|---|---|
| SVM | Radial basis function (RBF) | Box Constraint | Kernel scale | Box Constraint | Kernel scale |
| [10−3, 103] | [10−3, 103] | 1.4654 | 24.628 | ||
| GPR | Exponential | Sigma | Kernel scale | Sigma | Kernel scale |
| [10−4, 22.5184] | [0.1216, 121.6122] | 0.83194 | 91.5821 | ||
| Vineyard Canopy Class | T16 | G17 | Dataset | CS18 | T18 | Average | 5-Fold CV | 10-Fold CV |
|---|---|---|---|---|---|---|---|---|
| S18 | ||||||||
| Sensitivity | ||||||||
| Trellis | 0.9420 | 0.8760 | 0.9500 | 0.9200 | 0.9760 | 0.9328 | 0.5284 | 0.6700 |
| Gap | 0.9740 | 0.9900 | 0.9920 | 0.9960 | 0.9940 | 0.9892 | 0.9868 | 0.9880 |
| Leaf | 0.9760 | 0.9340 | 0.9060 | 0.9680 | 0.9700 | 0.9508 | 0.7476 | 0.8980 |
| Shoot | 0.9440 | 0.9520 | 0.9880 | 1.0000 | 0.9900 | 0.9748 | 0.8992 | 0.9208 |
| Rachis | 0.8640 | 0.9020 | 0.9220 | 0.9660 | 0.9580 | 0.9224 | 0.6912 | 0.7964 |
| Trunk | 0.9020 | 0.9560 | 0.9540 | 0.9660 | 0.9980 | 0.9552 | 0.3620 | 0.6992 |
| Grape | 0.9320 | 0.9720 | 0.9700 | 0.9540 | 0.9800 | 0.9616 | 0.7652 | 0.8732 |
| Specificity | ||||||||
| Trellis | 0.9897 | 0.9883 | 0.9930 | 0.9883 | 0.9970 | 0.9913 | 0.9554 | 0.9648 |
| Gap | 0.9950 | 0.9987 | 0.9967 | 0.9990 | 0.9977 | 0.9974 | 0.9955 | 0.9963 |
| Leaf | 0.9960 | 0.9893 | 0.9897 | 0.9960 | 0.9947 | 0.9931 | 0.9796 | 0.9829 |
| Shoot | 0.9900 | 0.9963 | 0.9983 | 0.9997 | 0.9987 | 0.9966 | 0.9335 | 0.9789 |
| Rachis | 0.9813 | 0.9850 | 0.9810 | 0.9927 | 0.9947 | 0.9869 | 0.9181 | 0.9673 |
| Trunk | 0.9803 | 0.9820 | 0.9923 | 0.9933 | 0.9987 | 0.9893 | 0.9151 | 0.9423 |
| Grape | 0.9900 | 0.9907 | 0.9960 | 0.9927 | 0.9963 | 0.9931 | 0.9661 | 0.9751 |
| F1 Score | ||||||||
| Trellis | 0.9401 | 0.9003 | 0.9538 | 0.9246 | 0.9789 | 0.9396 | 0.5884 | 0.7123 |
| Gap | 0.9721 | 0.9910 | 0.9861 | 0.9950 | 0.9900 | 0.9868 | 0.9801 | 0.9831 |
| Leaf | 0.9760 | 0.9349 | 0.9207 | 0.9719 | 0.9690 | 0.9545 | 0.7996 | 0.8978 |
| Shoot | 0.9421 | 0.9645 | 0.9890 | 0.9990 | 0.9910 | 0.9771 | 0.7826 | 0.8996 |
| Rachis | 0.8745 | 0.9056 | 0.9057 | 0.9612 | 0.9628 | 0.9220 | 0.6334 | 0.7993 |
| Trunk | 0.8931 | 0.9264 | 0.9540 | 0.9631 | 0.9950 | 0.9463 | 0.3869 | 0.6836 |
| Grape | 0.9357 | 0.9586 | 0.9729 | 0.9550 | 0.9790 | 0.9602 | 0.7773 | 0.8634 |
| AUC | ||||||||
| Trellis | 0.9658 | 0.9322 | 0.9715 | 0.9542 | 0.9865 | 0.9620 | 0.7419 | 0.8174 |
| Gap | 0.9845 | 0.9943 | 0.9943 | 0.9975 | 0.9958 | 0.9933 | 0.9912 | 0.9922 |
| Leaf | 0.9860 | 0.9617 | 0.9478 | 0.9820 | 0.9823 | 0.9720 | 0.8636 | 0.9405 |
| Shoot | 0.9670 | 0.9742 | 0.9932 | 0.9998 | 0.9943 | 0.9857 | 0.9164 | 0.9499 |
| Rachis | 0.9227 | 0.9435 | 0.9515 | 0.9793 | 0.9763 | 0.9547 | 0.8047 | 0.8818 |
| Trunk | 0.9412 | 0.9690 | 0.9732 | 0.9797 | 0.9983 | 0.9723 | 0.6386 | 0.8207 |
| Grape | 0.9610 | 0.9813 | 0.9830 | 0.9733 | 0.9882 | 0.9774 | 0.8656 | 0.9241 |
| IoU | ||||||||
| Trellis | 0.8870 | 0.8187 | 0.9117 | 0.8598 | 0.9587 | 0.8872 | 0.4169 | 0.5532 |
| Gap | 0.9456 | 0.9821 | 0.9725 | 0.9901 | 0.9803 | 0.9741 | 0.9610 | 0.9667 |
| Leaf | 0.9531 | 0.8778 | 0.8531 | 0.9453 | 0.9399 | 0.9139 | 0.6661 | 0.8146 |
| Shoot | 0.8906 | 0.9315 | 0.9782 | 0.9980 | 0.9821 | 0.9561 | 0.6428 | 0.8175 |
| Rachis | 0.7770 | 0.8275 | 0.8276 | 0.9253 | 0.9283 | 0.8571 | 0.4635 | 0.6657 |
| Trunk | 0.8068 | 0.8628 | 0.9120 | 0.9288 | 0.9901 | 0.9001 | 0.2399 | 0.5193 |
| Grape | 0.8792 | 0.9205 | 0.9473 | 0.9138 | 0.9589 | 0.9239 | 0.6358 | 0.7596 |
| Sensitivity | Specificity | F1 Score | AUC | ||
|---|---|---|---|---|---|
| Test Set | k = 10 | 0.760 | 0.660 | 0.724 | 0.751 |
| k = 50 | 0.738 | 0.770 | 0.750 | 0.828 | |
| k = 100 | 0.765 | 0.795 | 0.777 | 0.865 | |
| k = 150 | 0.750 | 0.770 | 0.758 | 0.841 | |
| k = 200 | 0.720 | 0.765 | 0.737 | 0.848 | |
| 5-Fold CV | k = 10 | 0.811 | 0.678 | 0.761 | 0.821 |
| k = 50 | 0.804 | 0.788 | 0.798 | 0.884 | |
| k = 100 | 0.821 | 0.781 | 0.805 | 0.903 | |
| k = 150 | 0.790 | 0.805 | 0.796 | 0.888 | |
| k = 200 | 0.799 | 0.813 | 0.804 | 0.902 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palacios, F.; Diago, M.P.; Tardaguila, J. A Non-Invasive Method Based on Computer Vision for Grapevine Cluster Compactness Assessment Using a Mobile Sensing Platform under Field Conditions. Sensors 2019, 19, 3799. https://doi.org/10.3390/s19173799
Palacios F, Diago MP, Tardaguila J. A Non-Invasive Method Based on Computer Vision for Grapevine Cluster Compactness Assessment Using a Mobile Sensing Platform under Field Conditions. Sensors. 2019; 19(17):3799. https://doi.org/10.3390/s19173799
Chicago/Turabian StylePalacios, Fernando, Maria P. Diago, and Javier Tardaguila. 2019. "A Non-Invasive Method Based on Computer Vision for Grapevine Cluster Compactness Assessment Using a Mobile Sensing Platform under Field Conditions" Sensors 19, no. 17: 3799. https://doi.org/10.3390/s19173799
APA StylePalacios, F., Diago, M. P., & Tardaguila, J. (2019). A Non-Invasive Method Based on Computer Vision for Grapevine Cluster Compactness Assessment Using a Mobile Sensing Platform under Field Conditions. Sensors, 19(17), 3799. https://doi.org/10.3390/s19173799