Real-Time Vehicle-Detection Method in Bird-View Unmanned-Aerial-Vehicle Imagery



Abstract
:1. Introduction
2. Related Work
3. Proposed Method
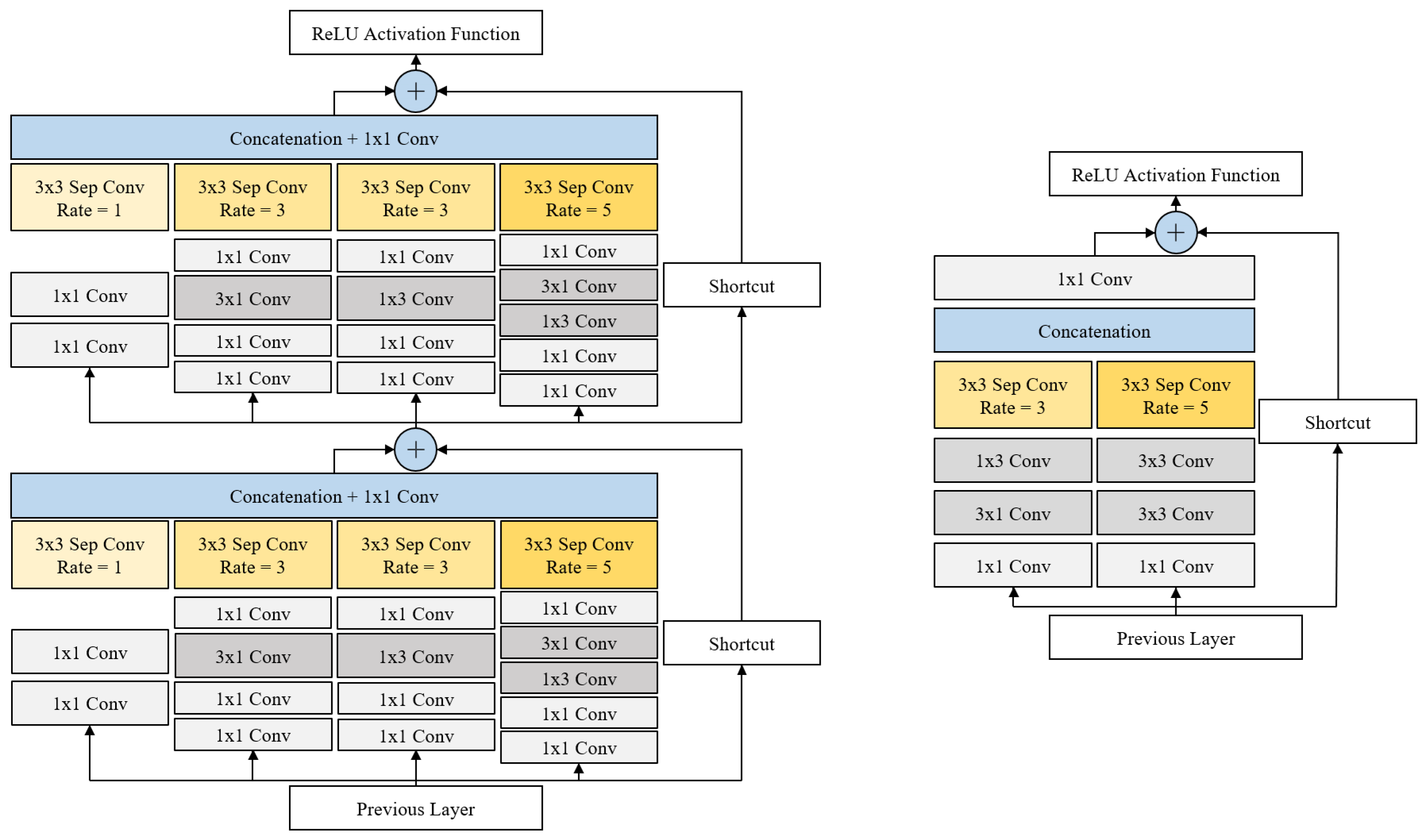
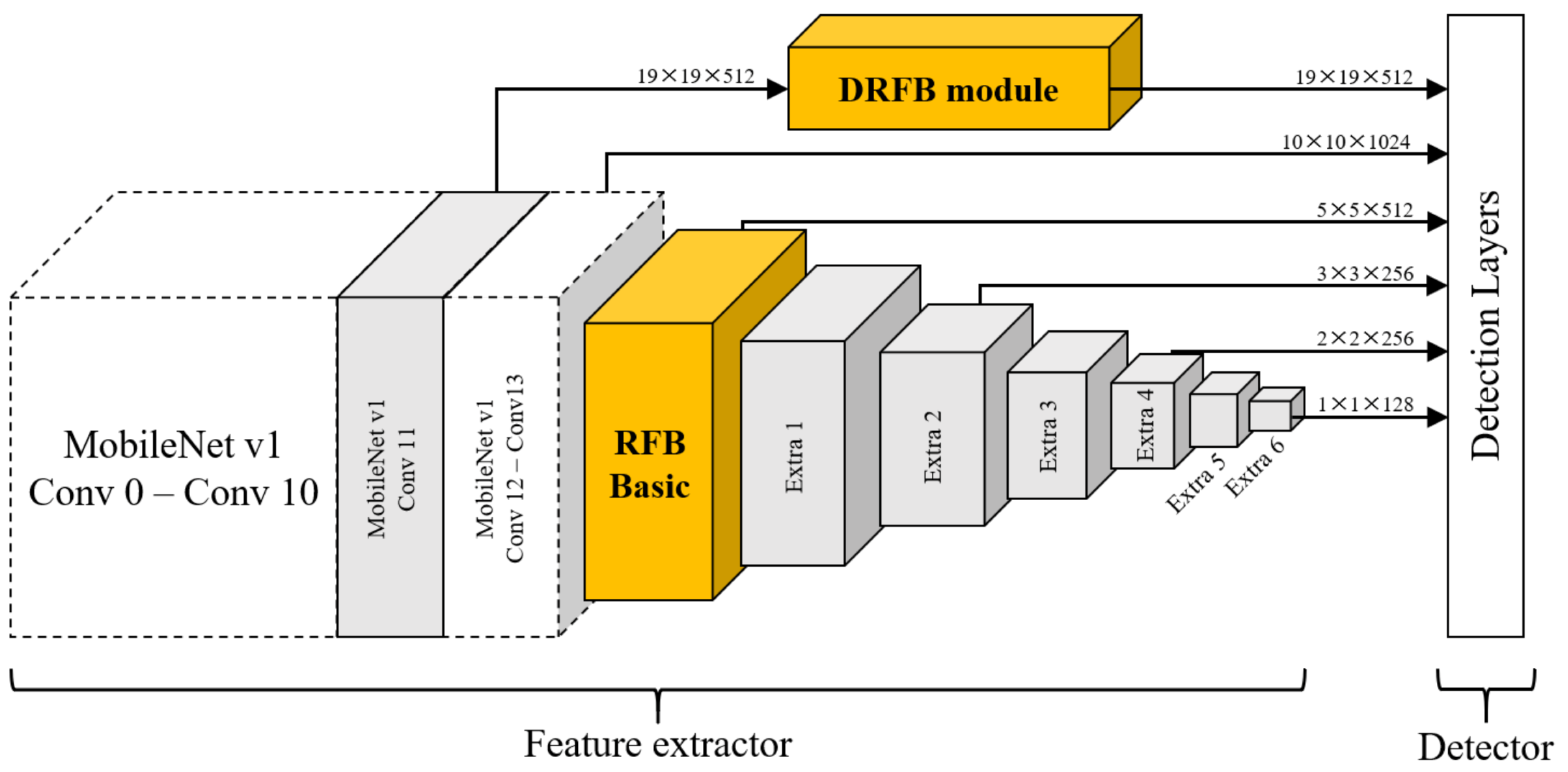
3.1. DRFBNet300
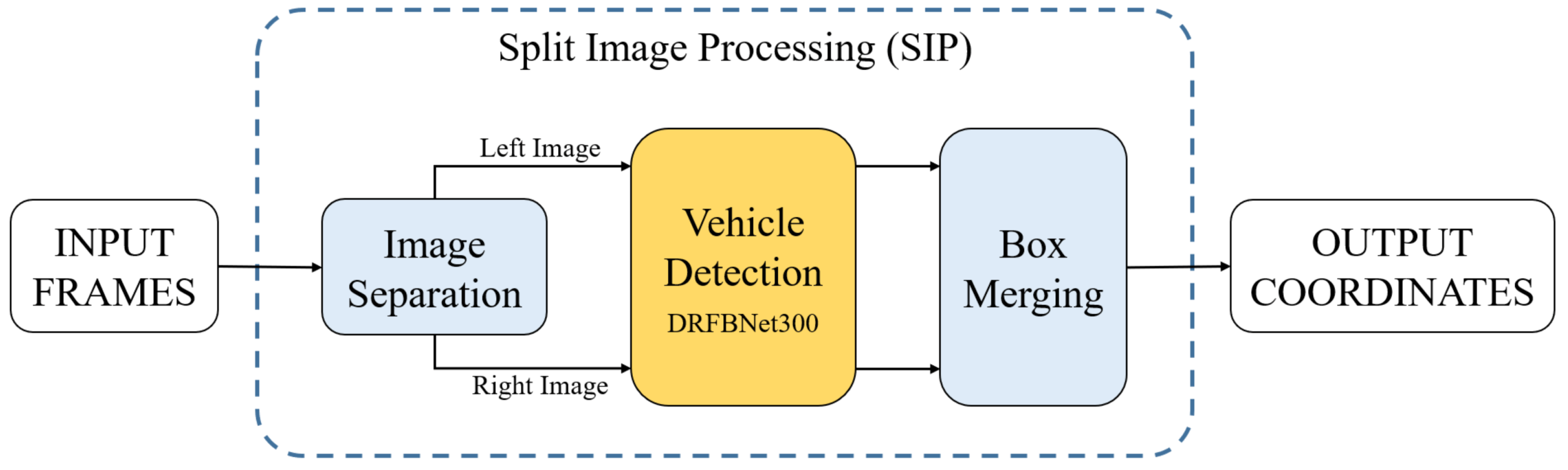
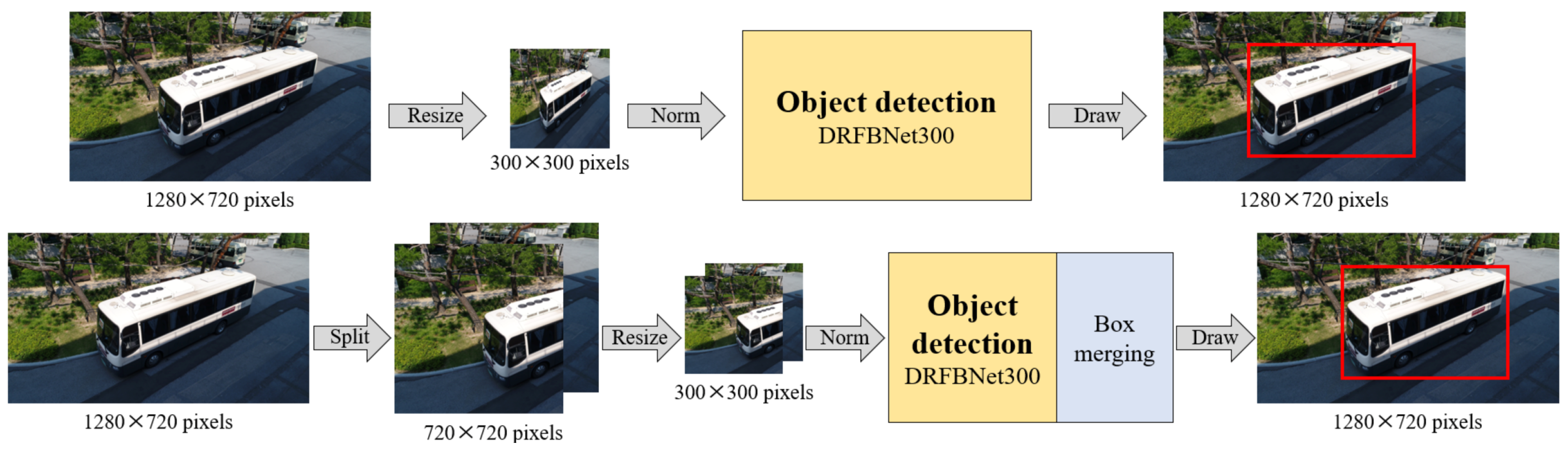
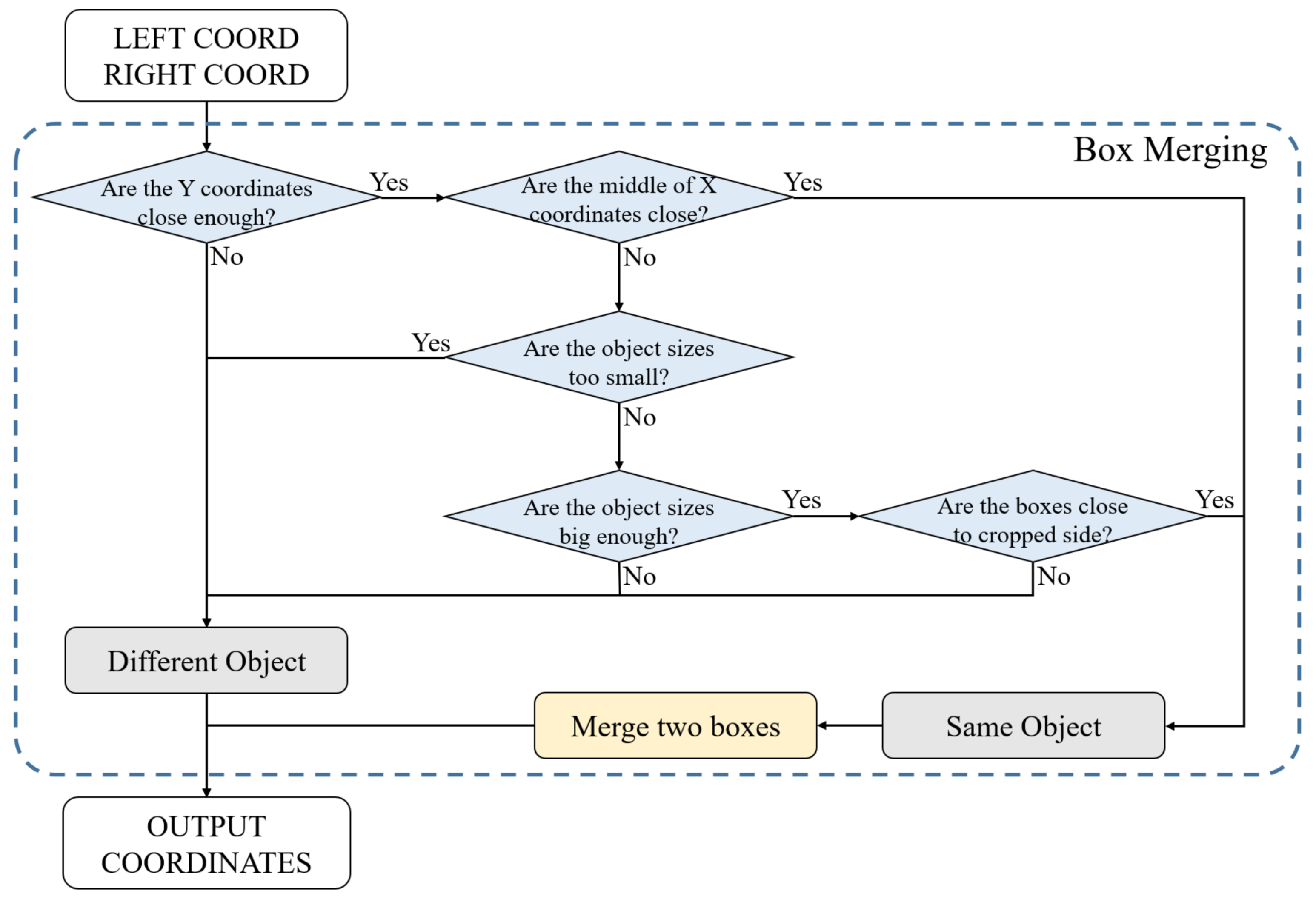
3.2. Split Image Processing
3.3. UAV-Cars Dataset
3.4. Vehicle Detection in UAV Imagery
4. Experimental Environment
4.1. UAV Specification
4.2. Experiment Environment
4.3. Training Strategies
5. Experimental Results
5.1. MS COCO
5.2. UAV-Cars Dataset
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zacharie, M.; Fuji, S.; Minori, S. Rapid Human Body Detection in Disaster Sites Using Image Processing from Unmanned Aerial Vehicle (UAV) Cameras. In Proceedings of the 2018 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Bangkok, Thailand, 21–24 October 2018; Volume 3, pp. 230–235. [Google Scholar]
- Doherty, P.; Rudol, P. A uav search and rescue scenario with human body detection and geolocalization. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Gold Coast, Australia, 2–6 December 2007; pp. 1–13. [Google Scholar]
- Ma’sum, M.A.; Arrofi, M.K.; Jati, G.; Arifin, F.; Kurniawan, M.N.; Mursanto, P.; Jatmiko, W. Simulation of intelligent Unmanned Aerial Vehicle (UAV) For military surveillance. In Proceedings of the International Conference on Advanced Computer Science and Information Systems (ICACSIS), Bali, Indonesia, 28–29 September 2013; pp. 161–166. [Google Scholar]
- Xiaozhu, X.; Cheng, H. Object detection of armored vehicles based on deep learning in battlefield environment. In Proceedings of the 2017 4th International Conference on Information Science and Control Engineering (ICISCE), Changsha, China, 21–23 July 2017; pp. 1568–1570. [Google Scholar]
- Zhu, J.S.; Sun, K.; Jia, S.; Li, Q.Q.; Hou, X.X.; Lin, W.D.; Liu, B.Z.; Qiu, G.P. Urban Traffic Density Estimation Based on Ultrahigh-Resolution UAV Video and Deep Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 12, 4968–4981. [Google Scholar] [CrossRef]
- Ke, R.; Li, Z.; Tang, J.; Pan, Z.; Wang, Y. Real-time traffic flow parameter estimation from UAV video based on ensemble classifier and optical flow. IEEE Trans. Intell. Transp. Syst. 2018, 20, 54–64. [Google Scholar] [CrossRef]
- Yang, Z.; Pun-Cheng, L.S. Vehicle Detection in Intelligent Transportation Systems and its Applications under Varying Environments: A Review. Image Vis. Comput. 2017, 69, 143–154. [Google Scholar] [CrossRef]
- Zhao, T.; Nevatia, R. Car detection in low resolution aerial images. Image Vis. Comput. 2003, 21, 693–703. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, F.; Wang, P.; Luo, P.; Liu, X. Vehicle detection methods from an unmanned aerial vehicle platform. Proceedings of 2012 IEEE International Conference on Vehicular Electronics and Safety (ICVES 2012), Istanbul, Turkey, 24–27 July 2012; pp. 411–415. [Google Scholar]
- Xu, Y.; Yu, G.; Wu, X.; Wang, Y.; Ma, Y. An enhanced Viola-Jones vehicle detection method from unmanned aerial vehicles imagery. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1845–1856. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [Green Version]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Radovic, M.; Adarkwa, O.; Wang, Q. Object recognition in aerial images using convolutional neural networks. J. Imaging 2017, 3, 21. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Fan, Q.; Brown, L.; Smith, J. A closer look at Faster R-CNN for vehicle detection. In Proceedings of the 2016 Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 124–129. [Google Scholar]
- Xu, Z.; Shi, H.; Li, N.; Xiang, C.; Zhou, H. Vehicle Detection Under UAV Based on Optimal Dense YOLO Method. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 407–411. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL visual object classes (VOC) challenge. Int. J. Comput. Vis. IJCV 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR 2016), San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Breckon, T.P.; Barnes, S.E.; Eichner, M.L.; Wahren, K. Autonomous real-time vehicle detection from a medium-level UAV. In Proceedings of the 24th International Conference on Unmanned Air Vehicle Systems, Bristol, UK, 30 March–1 April 2009. [Google Scholar]
- Gaszczak, A.; Breckon, T.P.; Han, J. Real-time people and vehicle detection from UAV imagery. In Proceedings of the Intelligent Robots and Computer Vision XXVIII: Algorithms and Techniques, San Francisco, CA, USA, 24 January 2011; pp. 536–547. [Google Scholar]
- Shao, W.; Yang, W.; Liu, G.; Liu, J. Car detection from high-resolution aerial imagery using multiple features. IEEE Int. Geosci. Remote Sens. Symp. 2012, 53, 4379–4382. [Google Scholar]
- Moranduzzo, T.; Melgani, F. Detecting Cars in UAV Images With a Catalog-Based Approach. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6356–6367. [Google Scholar] [CrossRef]
- Tang, T.; Deng, Z.; Zhou, S.; Lei, L.; Zou, H. Fast vehicle detection in UAV images. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–5. [Google Scholar]
- Xie, X.; Yang, W.; Cao, G.; Yang, J.; Zhao, Z.; Chen, S.; Liao, Q.; Shi, G. Real-time Vehicle Detection from UAV Imagery. In Proceedings of the Fourth IEEE International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Dala, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- He, D.-C.; Wang, L. Texture Unit, Texture Spectrum, In addition, Texture Analysis. IEEE Trans. Geosci. Remote Sens. 1990, 28, 509–512. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greek, 20–27 September 1999. [Google Scholar]
- Suhr, J.K. Kanade-lucas-tomasi (klt) feature tracker. In Computer Vision (EEE6503); Yonsei University: Seoul, Korea, 2009; pp. 9–18. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4203–4212. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Murphy, K.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the IEEE 2017 Conference on Computer Vision and Pattern Recognition (CVPR) 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wandell, B.A.; Winawer, J. Computational neuroimaging and population receptive fields. Trends Cognit. Sci. 2015, 19, 349–357. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First, AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Mehta, R.; Ozturk, C. Object detection at 200 frames per second. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September.
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Tzutalin. LabelImg. Available online: https://github.com/tzutalin/labelImg (accessed on 30 July 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Branch 0 | Branch 1 | Branch 2 | Branch 3 |
|---|---|---|---|
| Input () | |||
| 512/128, BN, ReLU | 512/128, BN, ReLU | 512/128, BN, ReLU | 512/64, BN, ReLU |
| 128/128, BN, ReLU | 128/128, BN, ReLU | 128/128, BN, ReLU | 64/64, BN, ReLU |
| 128/128, -, ReLU | 128/128, BN, ReLU | 128/128, BN, ReLU | 64/96, BN, ReLU |
| - | 128/128, BN, ReLU | 128/128, BN, ReLU | 96/128, BN, ReLU |
| - | 128/128, -, ReLU | 128/128, -, ReLU | 128/128, BN, ReLU |
| - | - | - | 128/128, -, ReLU |
| Concatnation + Conv (BN, ) | |||
| CPU | Inter Core I7-7700K |
|---|---|
| RAM | DDR4 16GB |
| GPU | Nvidia GeForce GTX Titan X (Maxwell) |
| O/S | Ubuntu 16.04 LTS |
| GPU Library | CUDA 9.0 with cuDNN v7.5 |
| Toolkit | Pytorch-GPU 1.0.1 |
| Method | Backbone | # of Params | Time (ms) | Avg. Precision, IoU | Avg. Precision, Area | ||||
|---|---|---|---|---|---|---|---|---|---|
| 0.5:0.95 | 0.5 | 0.75 | Small | Medium | Large | ||||
| SSD300 | 7.8 M | 19.8 | 0.181 | 0.318 | 0.181 | 0.014 | 0.173 | 0.369 | |
| FSSD300 | 19.1 M | 60.9 | 0.229 | 0.402 | 0.236 | 0.055 | 0.258 | 0.386 | |
| YOLOv3 320 | MobileNet v1 | 24.4 M | 40.1 | 0.236 | 0.407 | 0.241 | 0.082 | 0.240 | 0.386 |
| RFBNet300 | 6.8 M | 21.3 | 0.206 | 0.358 | 0.209 | 0.018 | 0.210 | 0.381 | |
| DRFBNet300 | 7.6 M | 22.3 | 0.210 | 0.368 | 0.212 | 0.018 | 0.212 | 0.387 | |
| Method | Meta Architecture | Backbone | Time (ms) | AP by Altitude (%) | ||||
|---|---|---|---|---|---|---|---|---|
| 10 m | 20 m | 30 m | 40 m | 50 m | ||||
| W/O SIP method | SSD300 | MobileNet v1 | 13.3 | 98.59 | 72.19 | 36.07 | 26.73 | 5.01 |
| RFBNet300 | 14.9 | 99.98 | 82.81 | 64.35 | 54.75 | 24.35 | ||
| DRFBNet300 | 17.5 | 99.54 | 90.19 | 71.38 | 55.22 | 27.21 | ||
| W/ SIP method | SSD300 | 21.6 | 95.58 | 81.99 | 58.65 | 45.54 | 18.23 | |
| RFBNet300 | 26.2 | 94.28 | 84.73 | 71.11 | 64.65 | 47.09 | ||
| DRFBNet300 | 30.2 | 94.82 | 91.13 | 76.85 | 68.44 | 57.28 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, S.; Yoo, J.; Kwon, S. Real-Time Vehicle-Detection Method in Bird-View Unmanned-Aerial-Vehicle Imagery. Sensors 2019, 19, 3958. https://doi.org/10.3390/s19183958
Han S, Yoo J, Kwon S. Real-Time Vehicle-Detection Method in Bird-View Unmanned-Aerial-Vehicle Imagery. Sensors. 2019; 19(18):3958. https://doi.org/10.3390/s19183958
Chicago/Turabian StyleHan, Seongkyun, Jisang Yoo, and Soonchul Kwon. 2019. "Real-Time Vehicle-Detection Method in Bird-View Unmanned-Aerial-Vehicle Imagery" Sensors 19, no. 18: 3958. https://doi.org/10.3390/s19183958
APA StyleHan, S., Yoo, J., & Kwon, S. (2019). Real-Time Vehicle-Detection Method in Bird-View Unmanned-Aerial-Vehicle Imagery. Sensors, 19(18), 3958. https://doi.org/10.3390/s19183958