A Novel Recurrent Neural Network-Based Ultra-Fast, Robust, and Scalable Solver for Inverting a “Time-Varying Matrix”



Abstract
:1. Introduction
2. Related Works of Dynamical Neural Networks
2.1. The Gradient Method
2.2. Zhang Dynamics
2.3. Chen Dynamics
2.4. Summary of the Main Previous/Traditional Methods
3. Our Concept: The Novel RNN Method
4. Model Implementation in SIMULINK
5. Illustrative Examples
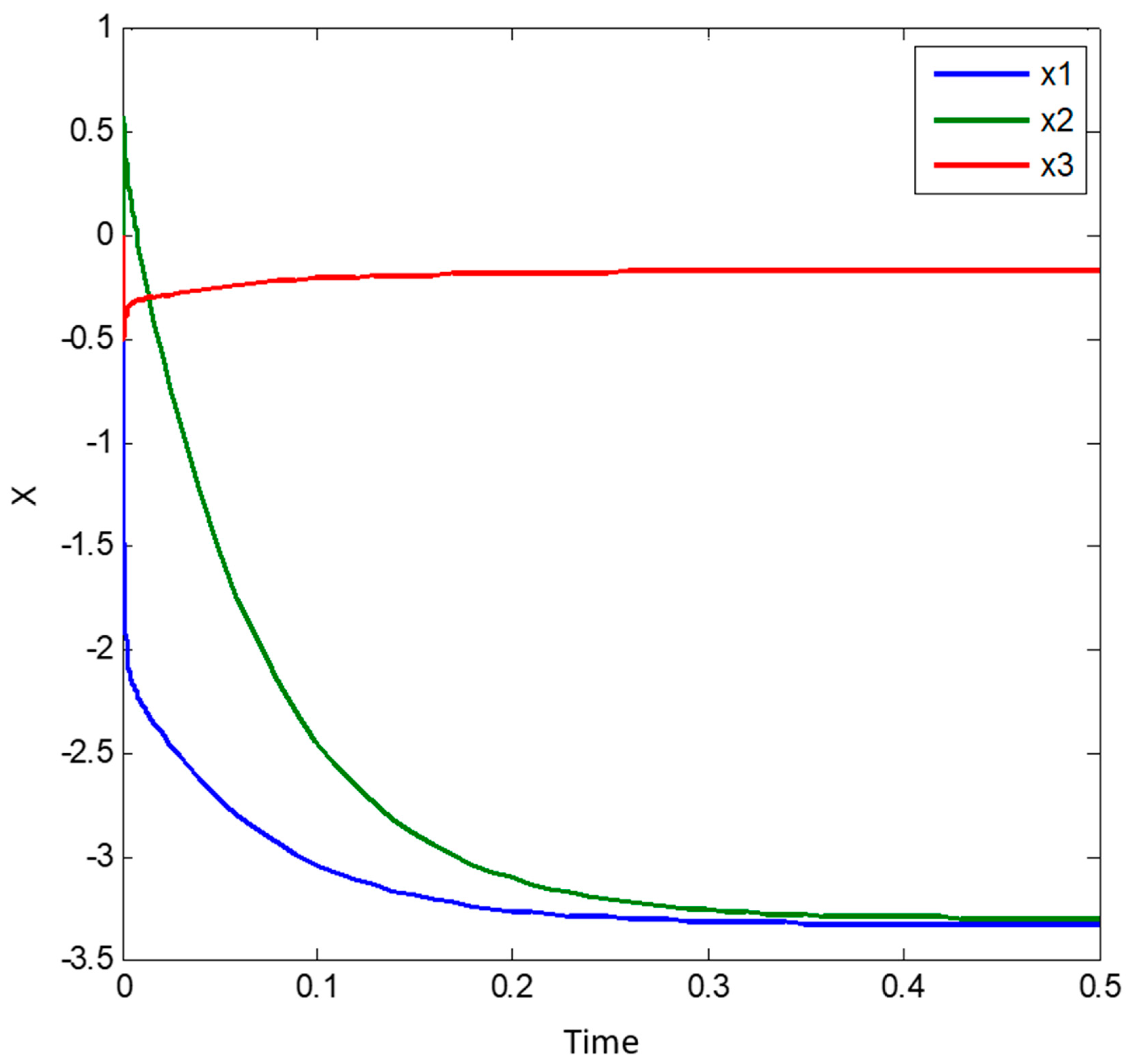
5.1. Illustrative Example 1
5.2. Illustrative Example 2
5.3. Illustrative Example 3
6. Comparison of Our Novel Method with Previous Studies
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lumpkin, B. Algebra Activities from Many Cultures; J. Weston Walch: Portland, ME, USA, 1997. [Google Scholar]
- Song, W.; Wang, Y. Locating Multiple Optimal Solutions of Nonlinear Equation Systems Based on Multiobjective Optimization. IEEE Trans. Evol. Comput. 2015, 19, 414–431. [Google Scholar] [CrossRef]
- Wang, Y.; Leib, H. Sphere Decoding for MIMO Systems with Newton Iterative Matrix Inversion. IEEE Commun. 2013, 17, 389–392. [Google Scholar] [CrossRef]
- Gu, B.; Sheng, V. Feasibility and Finite Convergence Analysis for Accurate On-Line ν-Support Vector Machine. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1304–1315. [Google Scholar]
- Eilert, J.; Wu, D.; Liu, D. Efficient Complex Matrix Inversion for MIMO Software Defined Radio. In Proceedings of the IEEE International Symposium on Circuits and Systems, New Orleans, LA, USA, 27–30 May 2007. [Google Scholar]
- Wu, M.; Yin, B.; Vosoughi, A.; Studer, C.; Cavallaro, J.R.; Dick, C. Approximate matrix inversion for high-throughput data detection in the large-scale MIMO uplink. In Proceedings of the ISCAS2013, Beijing, China, 19–23 May 2013; pp. 2155–2158. [Google Scholar]
- Ma, L.; Dickson, K.; McAllister, J.; McCanny, J. QR Decomposition-Based Matrix Inversion for High Performance Embedded MIMO Receivers. IEEE Trans. Signal Process. 2011, 59, 1858–1867. [Google Scholar] [CrossRef]
- Arias-García, J.; Jacobi, R.P.; Llanos, C.H.; Ayala-Rincón, M. A suitable FPGA implementation of floating-point matrix inversion based on Gauss-Jordan elimination. In Proceedings of the VII Southern Conference on Programmable Logic (SPL), Cordoba, Argentina, 13–15 April 2011; pp. 263–268. [Google Scholar]
- Irturk, A.; Benson, B.; Mirzaei, S.; Kastner, R. An FPGA Design Space Exploration Tool for Matrix Inversion Architectures. In Proceedings of the Symposium on Application Specific Processors, Anaheim, CA, USA, 8–9 June 2008; pp. 42–47. [Google Scholar]
- Benesty, J. Adaptive eigenvalue decomposition algorithm for passive acoustic source localization. J. Acoust. Soc. Am. 2001, 107, 384–391. [Google Scholar] [CrossRef]
- Warp, R.J.; Godfrey, D.; Dobbins, J.T. Applications of matrix inversion tomosynthesis. Med. Imaging 2000, 3977. [Google Scholar] [CrossRef]
- Godfrey, D.; McAdams, H.P.; Dobbins, J.T. The effect of averaging adjacent planes for artifact reduction in matrix inversion tomosynthesis. Med Phys. 2013, 40, 021907. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Ge, S. Design and analysis of a general recurrent neural network model for time-varying matrix inversion. IEEE Trans. Neural Netw. 2005, 16, 1477–1490. [Google Scholar] [CrossRef]
- Guo, D.; Zhang, Y. Zhang neural network, Getz–Marsden dynamic system, and discrete-time algorithms for time-varying matrix inversion with application to robots’ kinematic control. Neurocomputing 2012, 97, 22–32. [Google Scholar] [CrossRef]
- Guo, D.; Li, K.; Yan, L.; Nie, Z.; Jin, F. The application of Li-function activated RNN to acceleration-level robots’ kinematic control via time-varying matrix inversion. In Proceedings of the Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 3455–3460. [Google Scholar]
- Amato, F.; Moscato, V.; Picariello, A.; Sperlí, G. Recommendation in Social Media Networks. In Proceedings of the IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017; pp. 213–216. [Google Scholar]
- Amato, F.; Castiglione, A.; Moscato, V.; Picariello, A.; Sperli, G. Multimedia summarization using social media content. Multimed. Tools Appl. 2018, 77. [Google Scholar] [CrossRef]
- Hopf, B.; Dutz, F.; Bosselmann, T.; Willsch, M.; Koch, A.; Roths, J. Iterative matrix algorithm for high precision temperature and force decoupling in multi-parameter FBG sensing. Opt. Express 2018, 26, 12092–12105. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Tsai, P.; Huang, M. Matrix-Inversion-Free Compressed Sensing with Variable Orthogonal Multi-Matching Pursuit Based on Prior Information for ECG Signals. IEEE Trans. Biomed. Circuits Syst. 2016, 10, 864–873. [Google Scholar] [CrossRef] [PubMed]
- Ji, S.; Dunson, D.; Carin, L. Multitask Compressive Sensing. IEEE Trans. Signal Process. 2009, 57, 92–106. [Google Scholar] [CrossRef]
- Bicchi, A.; Canepa, G. Optimal design of multivariate sensors. Meas. Sci. Technol. 1994, 5, 319–332. [Google Scholar] [CrossRef]
- Mach, D.; Koshak, W.J. General matrix inversion technique for the calibration of electric field sensor arrays on aircraft platforms. J. Atmos. Ocean. Technol. 2007, 24, 1576–1587. [Google Scholar] [CrossRef]
- Liu, S.; Chepuri, S.P.; Fardad, M.; Maşazade, E.; Leus, G.; Varshney, P.K. Sensor Selection for Estimation with Correlated Measurement Noise. IEEE Trans. Signal Process. 2016, 64, 3509–3522. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Chen, K.; Tan, H. Performance Analysis of Gradient Neural Network Exploited for Online Time-Varying Matrix Inversion. IEEE Trans. Autom. Control 2009, 54, 1940–1945. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, W.; Cai, B. From Zhang Neural Network to Newton Iteration for Matrix Inversion. IEEE Trans. Circuits Syst. 2009, 56, 1405–1415. [Google Scholar] [CrossRef]
- Kandasamy, W.; Smarandache, F. Exploring the Extension of Natural Operations on Intervals, Matrices and Complex Numbers; ZIP Publishing: Columbus, OH, USA, 2012. [Google Scholar]
- Chen, Y.; Yi, C.; Qiao, D. Improved neural solution for the Lyapunov matrix equation based on gradient search. Inf. Process. Lett. 2013, 113, 876–881. [Google Scholar] [CrossRef]
- Yi, C.; Chen, Y.; Lu, Z. Improved gradient-based neural networks for online solution of Lyapunov matrix equation. Inf. Process. Lett. 2011, 111, 780–786. [Google Scholar] [CrossRef]
- Wilkinson, J. Error Analysis of Direct Methods of Matrix Inversion. JACM 1961, 8, 281–330. [Google Scholar] [CrossRef]
- Chua, L.; Yang, L. Cellular Neural Networks: Theory. IEEE Trans. Circuits Syst. 1988, 35, 1257–1272. [Google Scholar] [CrossRef]
- Roska, T.; Chua, L. The CNN universal machine: An analogic array computer. IEEE Trans. Circuits Syst. 1993, 40, 163–173. [Google Scholar] [CrossRef]
- Endisch, C.; Stolze, P.; Hackl, C.M.; Schröder, D. Comments on Backpropagation Algorithms for a Broad Class of Dynamic Networks. IEEE Trans. Neural Netw. 2009, 20, 540–541. [Google Scholar] [CrossRef]
- Potluri, S.; Fasih, A.; Kishore, L.; Machot, F.A.; Kyamakya, K. CNN Based High Performance Computing for Real Time Image Processing on GPU. In Proceedings of the Nonlinear Dynamics and Synchronization (INDS) & 16th Int’l Symposium on Theoretical Electrical Engineering (ISTET), Klagenfurt, Austria, 25–27 July 2011; pp. 1–7. [Google Scholar]
- Mainzer, K. CNN and the Evoulution of Complex Information Systems in Nature and Technology. In Proceedings of the 7th IEEE Cellular Neural Networks and Their Applications, Frankfurt, Germany, 24 July 2002; pp. 480–485. [Google Scholar]
- Chedjou, J.; Kyamakya, K.; Khan, U.; Latif, M. Potential Contribution of CNN-based Solving of Stiff ODEs & PDEs to Enabling Real-Time Computational Engineering. In Proceedings of the 2010 12th International Workshop on Cellular Nanoscale Networks and their Applications (CNNA 2010), Berkeley, CA, USA, 3–5 February 2010; pp. 1–6. [Google Scholar]
- Chedjou, J.; Kyamakya, K. A Universal Concept Based on Cellular Neural Networks for Ultrafast and Flexible Solving of Differential Equations. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 749–762. [Google Scholar] [CrossRef]
- Stanimirovic, P. Recurrent Neural Network for Computing the Drazin Inverse. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2830–2843. [Google Scholar] [CrossRef]
- Wang, J. Recurrent Neural Networks for Computing Pseudoinverses of Rank-Deficient Matrices. Siam J. Sci. Comput. 1997, 5, 1479–1493. [Google Scholar] [CrossRef]
- Chen, K. Recurrent Implicit Dynamics for Online Matrix Inversion. Appl. Math. Comput. 2013, 219, 10218–10224. [Google Scholar] [CrossRef]
- Feng, F.; Zhang, Q.; Liu, H. A Recurrent Neural Network for Extreme Eigenvalue Problem. In Proceedings of the ICIC 2005, Fuzhou, China, 20–23 August 2015; pp. 787–796. [Google Scholar]
- Tang, Y.; Li, J. Another neural network based approach for commuting eigenvalues and eigenvectors of real skew-symmetric matrices. Comput. Math. Appl. 2010, 60, 1385–1392. [Google Scholar] [CrossRef]
- Xu, L.; King, I. A PCA approach for fast retrieval of structural patterns in attributed graphs. IEEE Trans. Syst. Man Cybern. 2001, 31, 812–817. [Google Scholar]
- Liu, Y.; You, Z.; Cao, L. A recurrent neural network computing the largest imaginary or real part of eigenvalues of real matrices. Comput. Math. Appl. 2007, 53, 41–53. [Google Scholar] [CrossRef] [Green Version]
- Bouzerdorm, A.; Pattison, T. Neural Network for Quadratic Optimization with Bound Constraints. IEEE Trans. Neural Netw. 1993, 4, 293–304. [Google Scholar] [CrossRef]
- Zhang, Y. Towards piecewise-linear primal neural networks for optimization and redundant robotics. In Proceedings of the IEEE International Conference on Networking, Sensing and Control, Ft. Lauderdale, FL, USA, 23–25 April 2006. [Google Scholar]
- Hopfield, J.J.; Tank, D. Neural Computation of Decisions in Optimization Problems. Cybernetics 1984, 52, 141–152. [Google Scholar]
- Kenndey, M.P. Neural Networks for Nonlinear Programming. IEEE Trans Circuits Syst. 1988, 35, 554–562. [Google Scholar] [CrossRef]
- He, Z.; Gao, S.; Xiao, L.; Liu, D.; He, H.; Barber, D. Wider and deeper, cheaper and faster: Tensorized LSTMs for sequence learning. In Proceedings of the Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar]
- Jang, J.-S.; Lee, S.-Y.; Shin, S.-Y. An Optimization Network for Matrix Inversion. In Proceedings of the 1987 IEEE Conference on Neural Information Processing Systems, Denver, CO, USA, 8–12 November 1987. [Google Scholar]
- Zhang, Y.; Li, Z.; Li, K. Complex-valued Zhang neural network for online complex-valued time-varying matrix inversion. Appl. Math. Comput. 2011, 217, 10066–10073. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria/Method | Gradient NN | Zhang NN | Chen |
|---|---|---|---|
| Convergence rate | |||
| Time-varying matrix inversion | not available | Available | not available |
| Implementation | Easy | Hard | very hard/difficult |
| Noise sensitivity | High | Low | very low |
| Component | Description |
|---|---|
 | |
 | |
 | I-M |
 | Time-derivative of M; if M is constant, just put zero values in the matrix M’:
|
 | C is a weight value matrix equal to For the setting n= 2, we do have the following value for C: |
| Criteria/n | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Convergence Time to MSE 0.01 | 8.4 | 3.8 | 2.8 | 1.9 |
| MSE in t = 2.0 | 3.4 | 0.4 | 0.06 | 0.008 |
| Approximated estimation of memory usage in Bytes | 96 | 128 | 128 | 128 |
| Criteria/ Function used in Equation (31) with n = 3 | Linear | Sigmoid | Arctan | Tanh | |
|---|---|---|---|---|---|
| MSE at t = 0.05 | 0.075 | 7.90 | 4.58 | 7.83 | 0.062 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tavakkoli, V.; Chedjou, J.C.; Kyamakya, K. A Novel Recurrent Neural Network-Based Ultra-Fast, Robust, and Scalable Solver for Inverting a “Time-Varying Matrix”. Sensors 2019, 19, 4002. https://doi.org/10.3390/s19184002
Tavakkoli V, Chedjou JC, Kyamakya K. A Novel Recurrent Neural Network-Based Ultra-Fast, Robust, and Scalable Solver for Inverting a “Time-Varying Matrix”. Sensors. 2019; 19(18):4002. https://doi.org/10.3390/s19184002
Chicago/Turabian StyleTavakkoli, Vahid, Jean Chamberlain Chedjou, and Kyandoghere Kyamakya. 2019. "A Novel Recurrent Neural Network-Based Ultra-Fast, Robust, and Scalable Solver for Inverting a “Time-Varying Matrix”" Sensors 19, no. 18: 4002. https://doi.org/10.3390/s19184002
APA StyleTavakkoli, V., Chedjou, J. C., & Kyamakya, K. (2019). A Novel Recurrent Neural Network-Based Ultra-Fast, Robust, and Scalable Solver for Inverting a “Time-Varying Matrix”. Sensors, 19(18), 4002. https://doi.org/10.3390/s19184002