Reinforcement Learning-Based Data Forwarding in Underwater Wireless Sensor Networks with Passive Mobility

Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Preliminaries and Notations
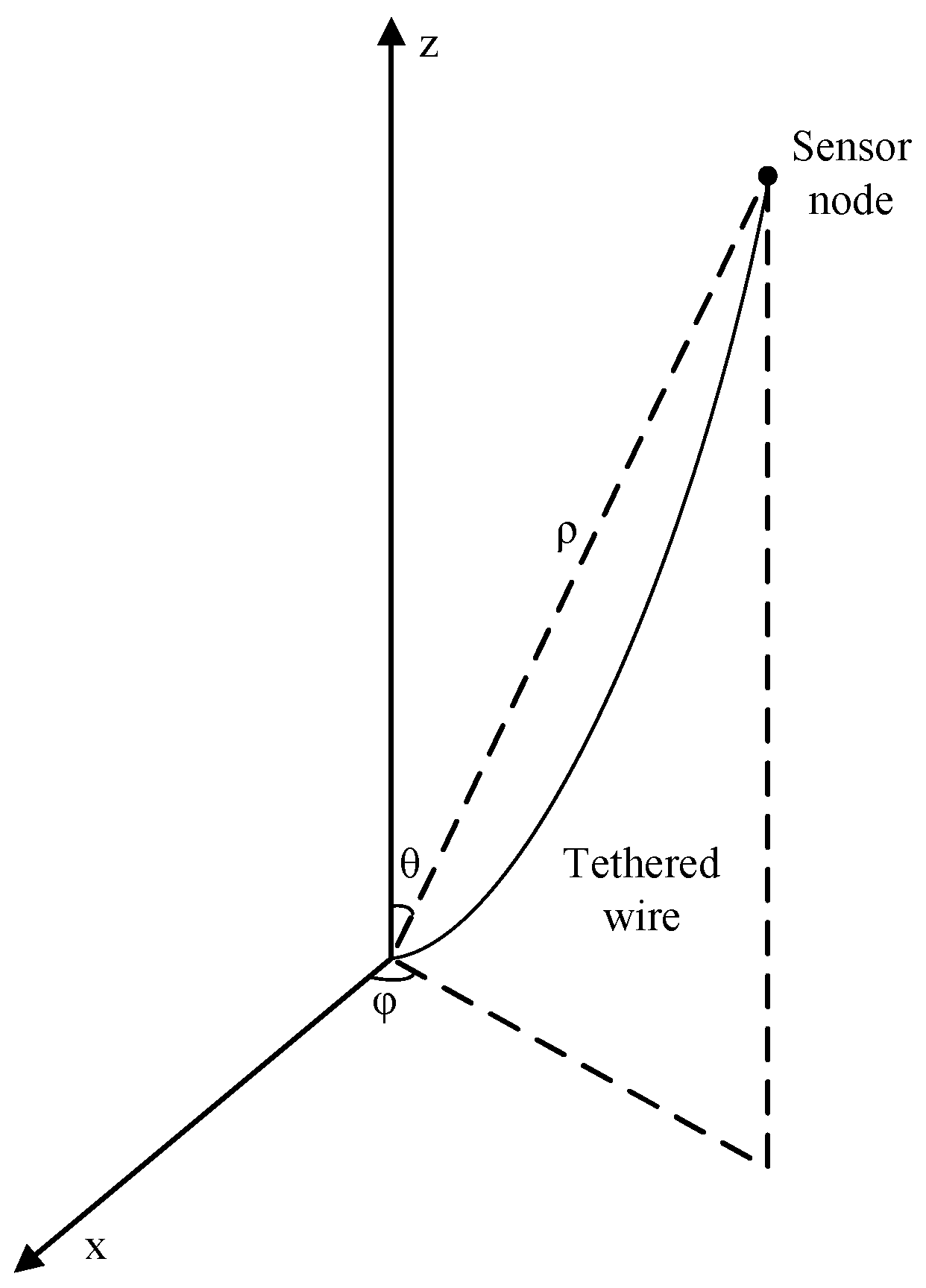
3.1.1. System Model
3.1.2. Underwater Movement Model
3.1.3. Value of Information
3.1.4. Energy Consumption
3.1.5. Forwarding Orientation
3.2. Problem Definition
3.3. Data Forwarding Method
3.3.1. Data Forwarding Procedure
- (1)
- In the beginning of each time slot, each sensor node and sink node broadcasts its beacon signal, e.g., the identifier, orientation and residual energy. Therefore, each sensor node knows its neighbors.
- (2)
- When hears the beacon signal from , it adds to the set of its available sink nodes . Similarly, if can hear the beacon signal of sensor node , will add to the set of its neighbors . Additionally, the distance and orientation of each neighbor or reachable sink node can be acquired locally via the Received Signal Strength (RSS) and Arrival of Angle (AoA) of the beacon signal, respectively. If cannot hear from any sink nodes or sensor nodes, will wait until the next time slot coming.
- (3)
- Sensor node selects the reachable sink node or next relay node by the algorithm RelaySelect which performs a learned choice of a relay node. The RelaySelect algorithm will be introduced in detail in the third subsection.
| Algorithm 1 DataForwarding(). |
|
3.3.2. Q-Learning Model
3.3.3. Learning to Forward
| Algorithm 2 RelaySelect(). |
|
4. Results
4.1. Experimental Setup
4.2. Simulation Metrics
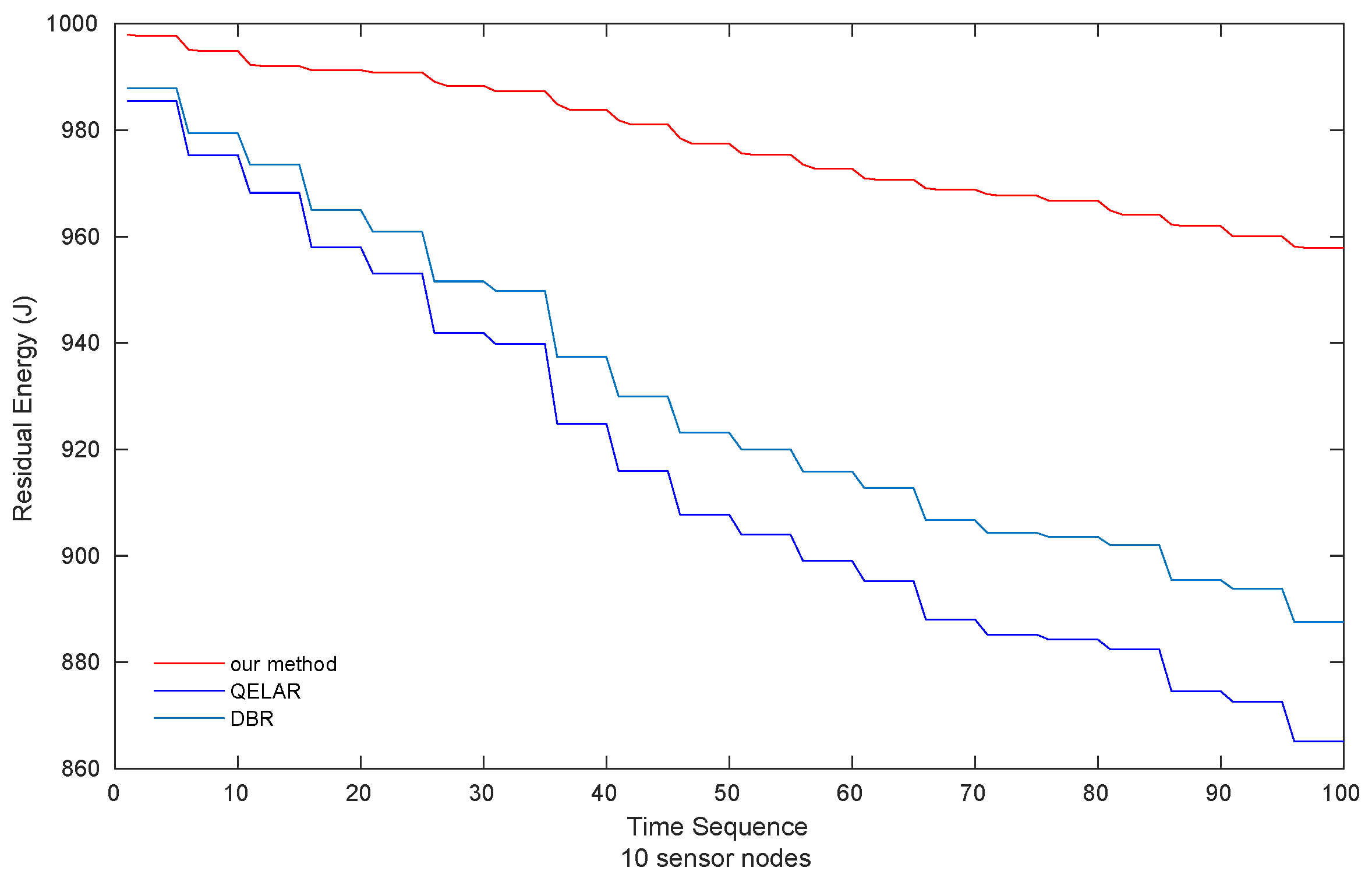
4.3. Simulation Results
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lloret, J. Underwater sensor nodes and networks. Sensors 2013, 13, 11782–11796. [Google Scholar] [CrossRef] [PubMed]
- Garcia, M.; Sendra, S.; Atenas, M.; Lloret, J. Underwater wireless ad-hoc networks: A survey. In Mobile Ad Hoc Networks: Current Status and Future Trends; CRC Press: Boca Raton, FL, USA, 2011; Chapter 14; pp. 379–411. [Google Scholar]
- Gjanci, P.; Petrioli, C.; Basagni, S.; Phillips, C.; Boloni, L.; Turgut, D. Path Finding for Maximum Value of Information in Multi-Modal Underwater Wireless Sensor Networks. IEEE Trans. Mobile Comput. 2018, 17, 404–418. [Google Scholar] [CrossRef]
- Liang, W.; Xu, W.; Ren, X.; Jia, X.; Lin, X. Maintaining Sensor Networks Perpetually Via Wireless Recharging Mobile Vehicles. In Proceedings of the 39th Annual IEEE Conference on Local Computer Networks, Edmonton, AB, Canada, 8–11 September 2014; pp. 270–278. [Google Scholar]
- Ma, Y.; Liang, W.; Xu, W. Charging Utility Maximization in Wireless Rechargeable Sensor Networks by Charging Multiple Sensors Simultaneously. IEEE/ACM Trans. Netw. 2018, 26, 1591–1604. [Google Scholar] [CrossRef]
- Basagni, S.; Valerio, D.; Gjanci, P.; Petrioli, C. Finding MARLIN: Exploiting Multi-Modal Communications for Reliable and Low-latency Underwater Networking. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Atlanta, GA, USA, 1–4 May 2017; pp. 1701–1709. [Google Scholar]
- Hu, T.; Fei, Y. QELAR: Q-Learning-based Energy-Efficient and Lifetime-Aware Routing Protocol for Underwater Sensor Networks. IEEE Trans. Mob. Comput. 2010, 9, 796–809. [Google Scholar]
- Coutinho, R.; Boukerche, A.; Vieira, L.; Loureiro, A. EnRO: Energy Balancing Routing Protocol for Underwater Sensor Networks. In Proceedings of the IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Jin, Z.; Ma, Y.; Su, Y.; Li, S.; Fu, X. A Q-Learning-Based Delay-Aware Routing Algorithm to Extend the Lifetime of Underwater Sensor Networks. Sensors 2017, 17, 1660. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Liu, Y. On Exploring Data Forwarding Problem in Opportunistic Underwater Sensor Network Using Mobility-Irregular Vehicles. IEEE Trans. Veh. Technol. 2015, 64, 4712–4727. [Google Scholar] [CrossRef]
- Forster, A.; Murphy, A. CLIQUE: Role-Free Clustering with Q-Learning for Wireless Sensor Networks. In Proceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), Montreal, QC, Canada, 22–26 June 2009; pp. 441–449. [Google Scholar]
- Webster, R.; Munasinghe, K.; Jamalipour, A. Murmuration Inspired Clustering Protocol for Underwater Wireless Sensor Networks. In Proceedings of the IEEE International Conference on Communications (ICC), Kansas, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Caruso, A.; Paparella, F.; Viera, L.; Erol, M.; Gerla, M. The Meandering Current Mobility Model and its Impact on Underwater Mobile Sensor Networks. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Phoenix, AZ, USA, 13–18 April 2008; pp. 221–225. [Google Scholar]
- Pearce, D.; Miller, A.; Rowlands, G.; Turner, M. Role of projection in the control of bird flocks. Proc. Natl. Acad. Sci. USA 2014, 111, 10422–10426. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, H.; Shi, Z.; Cui, J. DBR: Depth-Based Routing for Underwater Sensor Networks. In NETWORKING 2008 Ad Hoc and Sensor Networks, Wireless Networks, Next Generation Internet; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4982, pp. 72–86. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Value |
|---|---|
| 300 m | |
| 1000 bit | |
| 100 J | |
| J/bit | |
| 100 m per time slot | |
| 10 time slots | |
| 0.5 | |
| k | 1 |
| 1 |
| PDR() | DBR | QELAR | Our Method |
|---|---|---|---|
| PDR(10) | |||
| PDR(50) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, H.; Feng, J.; Duan, C. Reinforcement Learning-Based Data Forwarding in Underwater Wireless Sensor Networks with Passive Mobility. Sensors 2019, 19, 256. https://doi.org/10.3390/s19020256
Chang H, Feng J, Duan C. Reinforcement Learning-Based Data Forwarding in Underwater Wireless Sensor Networks with Passive Mobility. Sensors. 2019; 19(2):256. https://doi.org/10.3390/s19020256
Chicago/Turabian StyleChang, Haotian, Jing Feng, and Chaofan Duan. 2019. "Reinforcement Learning-Based Data Forwarding in Underwater Wireless Sensor Networks with Passive Mobility" Sensors 19, no. 2: 256. https://doi.org/10.3390/s19020256
APA StyleChang, H., Feng, J., & Duan, C. (2019). Reinforcement Learning-Based Data Forwarding in Underwater Wireless Sensor Networks with Passive Mobility. Sensors, 19(2), 256. https://doi.org/10.3390/s19020256