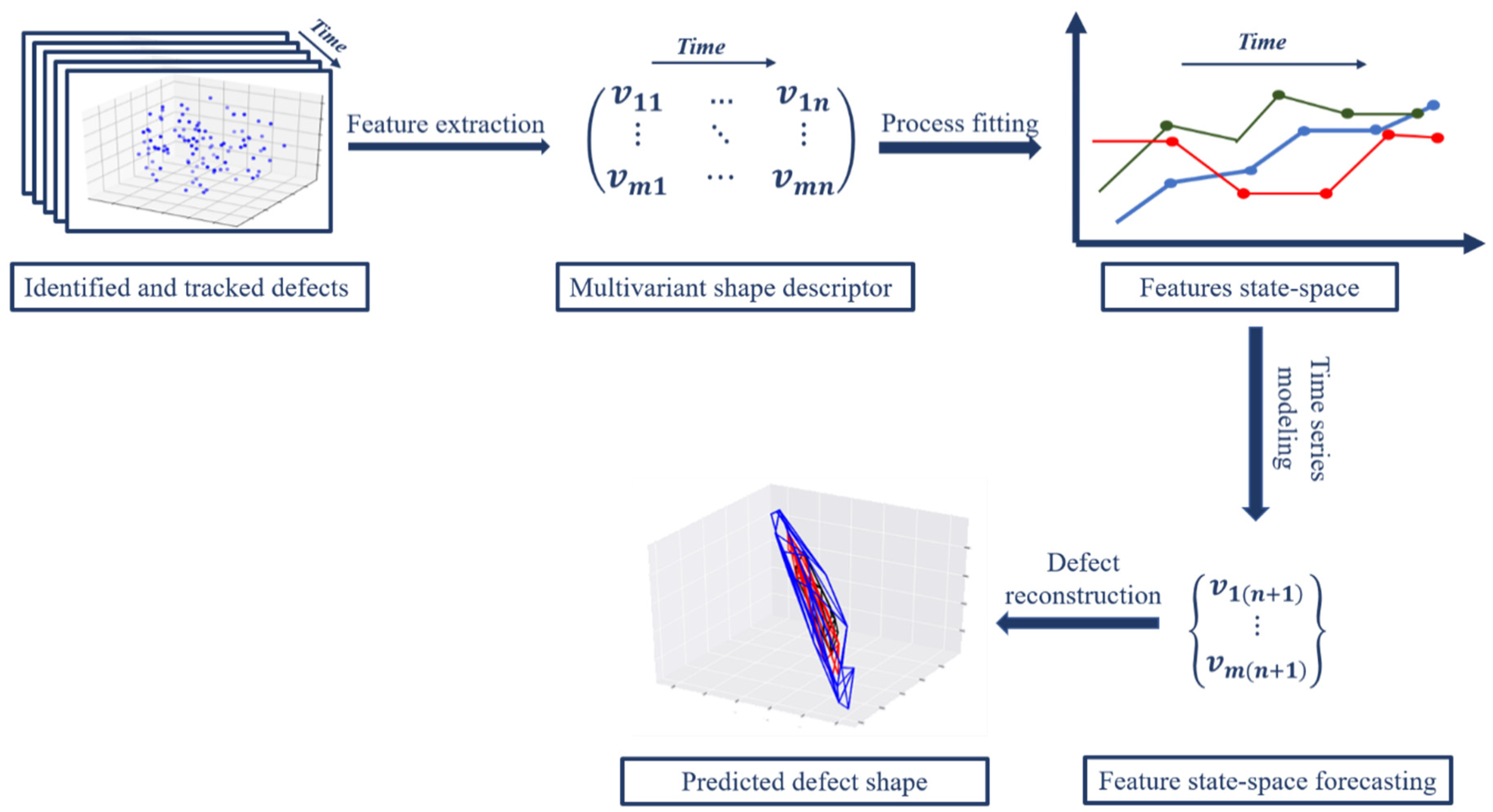
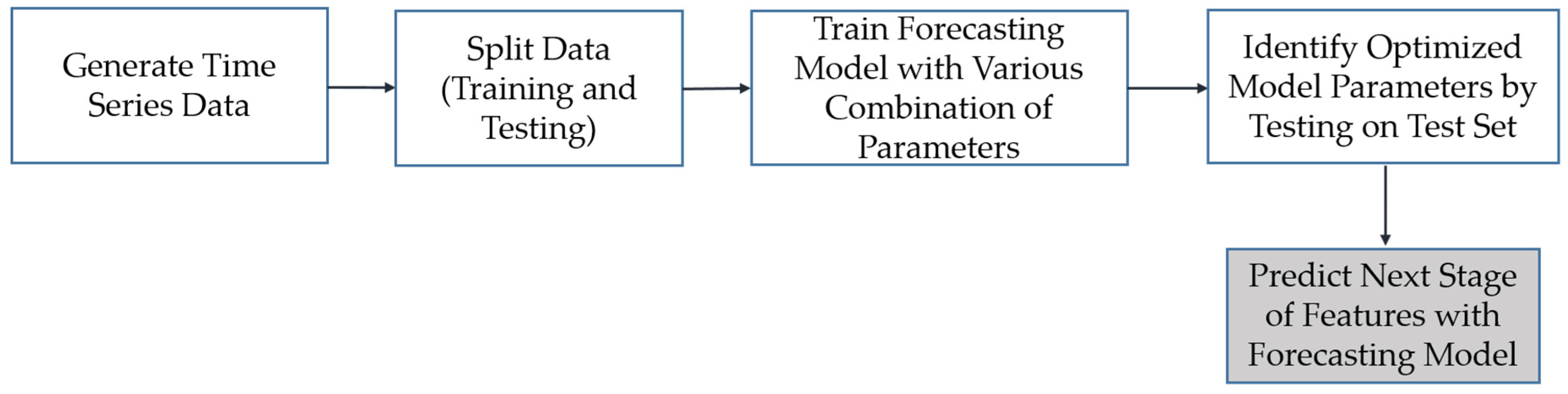
The methodology presented here consists of several steps (
Figure 1). Once a defect in the structure is detected, the defect must be parametrized in a way that can support a dynamic modeling of defect evolution over time. Parameterization is achieved with feature extraction from the point cloud through computational geometric modeling of the convex hull of the cloud, resulting in a combination of hull simplexes and vertices. These parameterizations are computed for multiple time steps over the life cycle of the structure. Once parameterized, a time-series model is fit to the sequence of parameterizations in order to capture the underlying process of evolution. This model fitting also enables the estimate the future state of the defect via out-sample forecasting. The defect shape is then reconstructed by reversing the parameterizations back to a geometric point set. While not considered in this work, the methodology presented here can then be used to update a finite element model of the structural component based on the predicted future defect topology, leading to predictive structural assessment.
2.1. Defect Parameterization
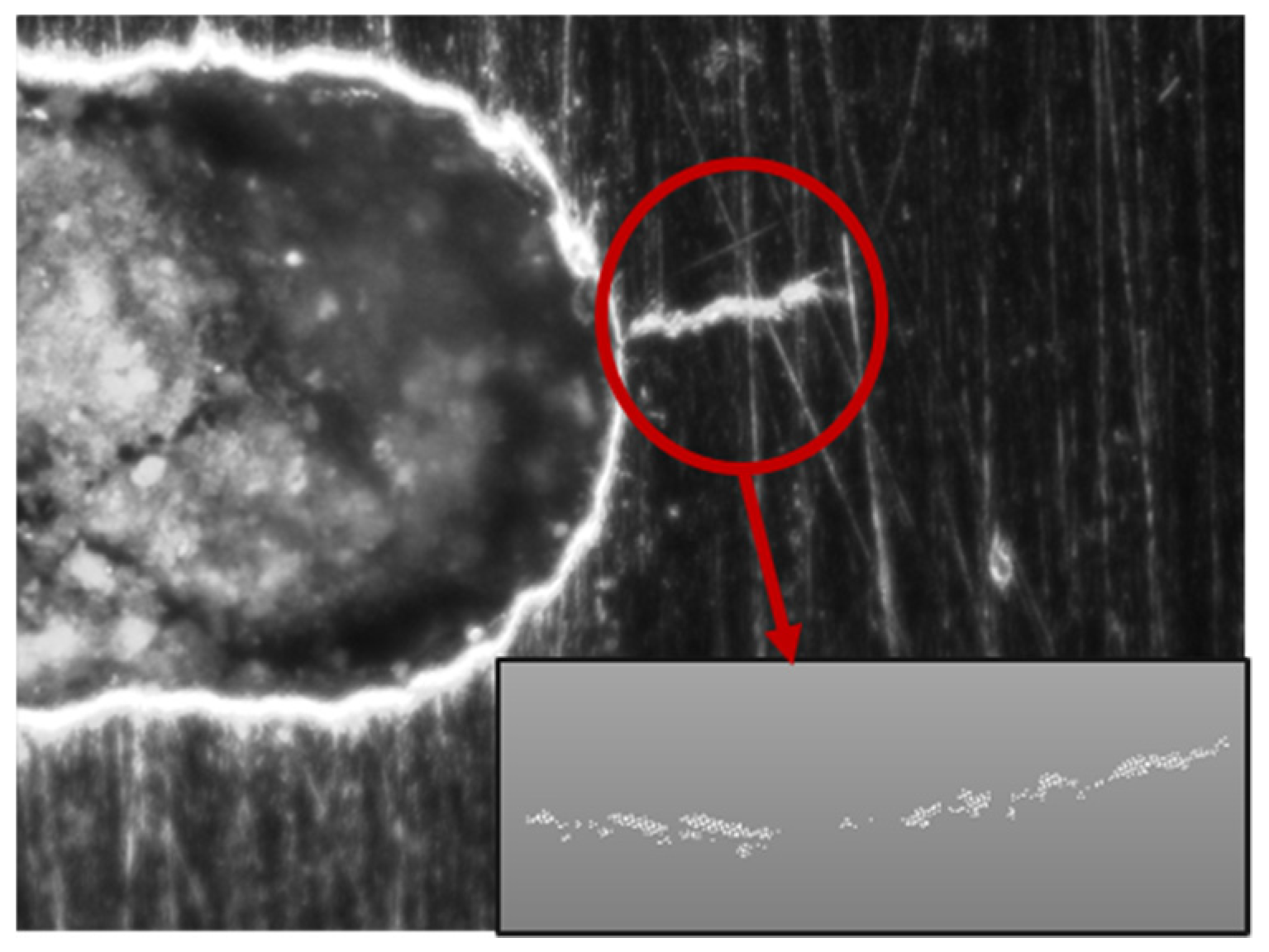
Once a remotely sensed defect in a structural component is detected through computer vision [
34], the first step in the modeling process is to parameterize it so that a stochastic dynamic model can be reliably fit the extracted parameters, or a “feature vector” to track the defect evolution over time. The complex nature of point cloud data necessitates this low-dimensional parameterization, as tracking each individual point in a cloud would lead to an intractably high number of time-series model coefficients.
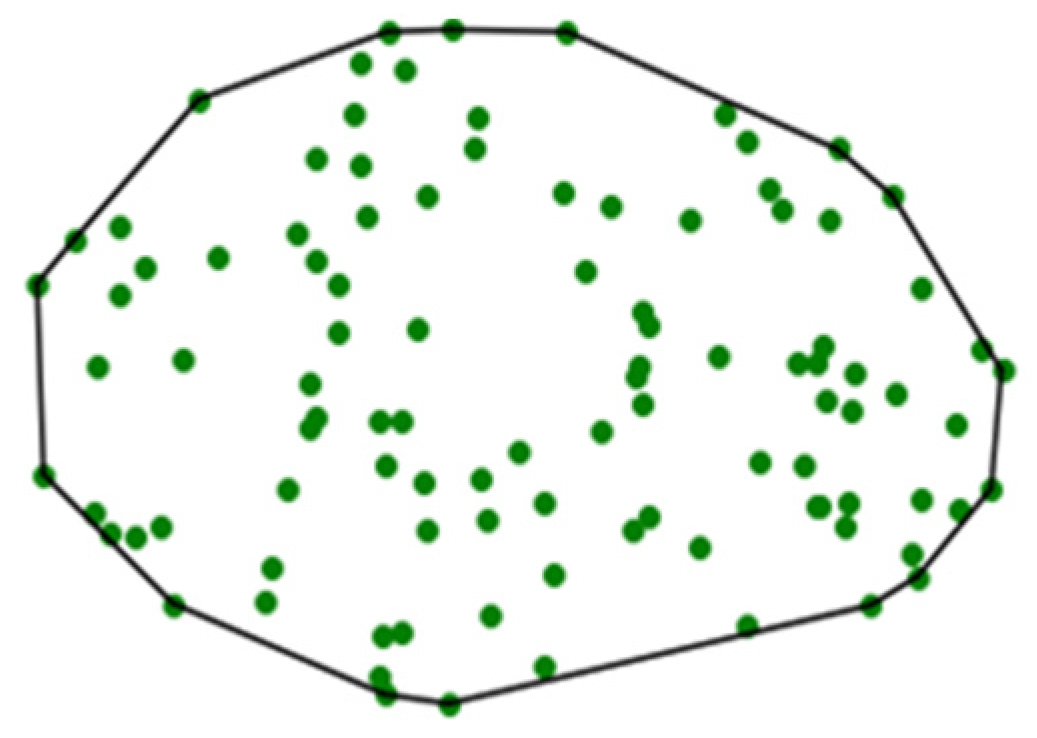
Here, we propose that the feature extraction can be done using the concept of a geometric convex hull. The convex hull of a point set is a unique representation of a point set in
Rn, defined as the smallest convex polygon that surrounds all points in the point set (
Figure 2) [
47]. In
R3 or higher-dimensional data spaces, the convex hull is similarly defined as the minimum convex polyhedron of the point set. It should be noted that, while this parameterization reduces the information complexity of the point cloud, the use of a convex hull serves to maintain the dimensionality of the underlying geometric object under observation. This is critical for reconstructing predicted defect states.
The determination of the convex hull is a geometric computation that is useful for many analyses and was successfully applied in domains such as image processing [
48] and pattern recognition [
49]. Although a number of alternative feature extraction approaches were considered in this study [
50,
51], hull parameterization was used because of its inherent advantages. The description of a defect in terms of its parameterized hull allows for consistent temporal tracking for predictive purposes, while also reducing the dimension and complexity of the data implicitly. In addition, the convex hull concept can be extended to high-dimensional spaces to support the fusion of multiple sensors and data types, a longer-term goal of this work.
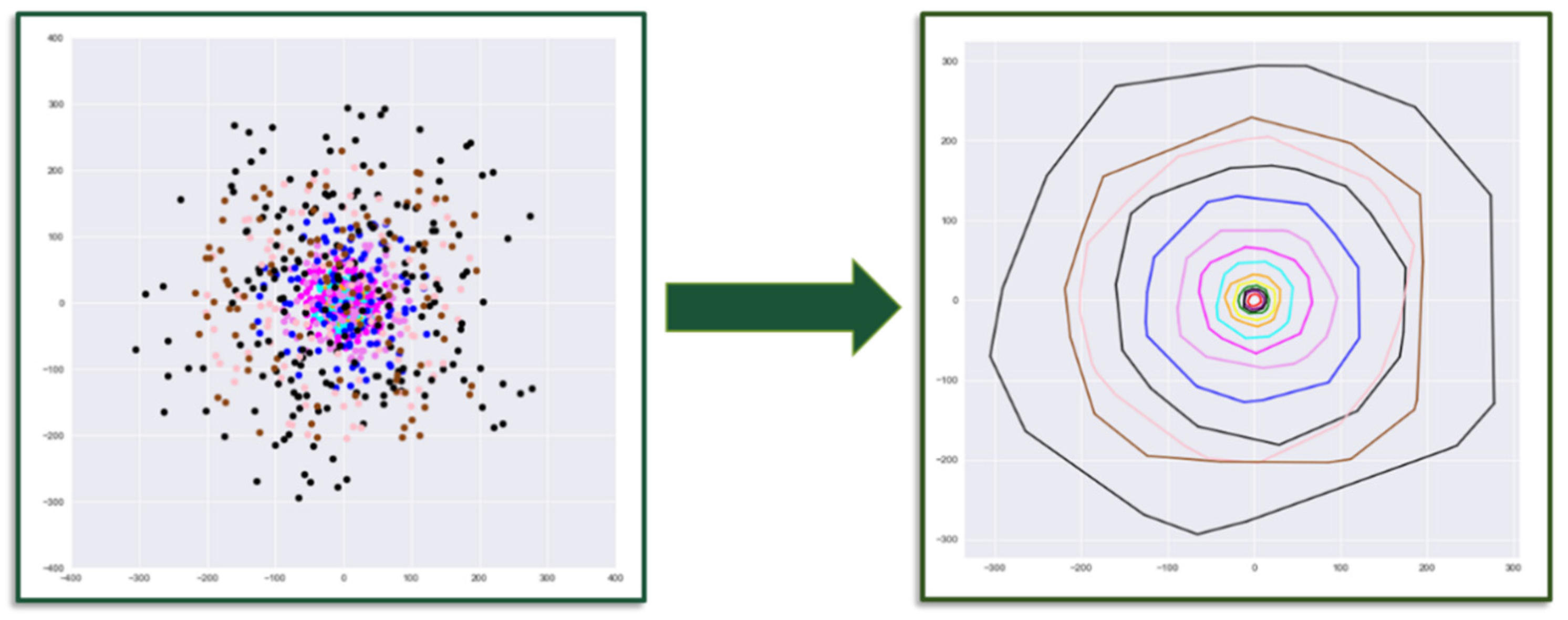
The convex hull of point cloud
P is a uniquely defined convex polygon. A natural way to represent a generalized polygon is by listing its vertices in clockwise order, starting with an arbitrary starting point. As such, the problem to be solved is as follows: given a point set
P = {
p1,
p2, …,
pm} in
Rn, compute a list that contains those points from
P that are the vertices of the convex hull, CH(
P). To find those vertices, the algorithm sorts all points through a “divide and conquer” approach [
52]. The convex hull algorithm finds two points with maximum and minimum spatial coordinates in a single dimension and computes a line joining these two points. This line divides the whole set into two halves. For a given half it finds the points with a maximum distance from the dividing line, forming a triangle defined by minimum and maximum point distances. Those points inside the triangle are determined to not be part of convex hull. Then, these steps are iteratively repeated to search for points with maximum distance from the separating line, until there is no point left outside of the computed triangles. The points selected at this step constitutes the convex hull. The convex hull results in a vector containing the Cartesian coordinates of the hull vertices. This extracted vector of vertices is the numerical descriptor that is later fit to a stochastic process model (
Figure 3).
2.2. Hull Registration and Structuring for Time-Series Modeling
Once the hull vertices are extracted, the data must be structured and compiled for time history modeling. Firstly, point clouds from each time step are aligned and registered in a common reference frame. In this work, manual registration was sufficient; however, automatic registration approaches such as the iterative closest point (ICP) algorithm, or by determining the 2D or 3D homography between point sets via feature-based computer vision methods, may be necessary (
Figure 4) [
53,
54]. The registered defect point clouds are then parameterized using the convex hull computation, resulting in individual 2 ×
n arrays of vertex coordinates. Each vertex at
t =
t1 is then spatially tracked across the temporal sequence of vertex arrays. The vertices of a hull in stage 1 (hull
1) are matched to their nearest neighbor (NN) vertices in
hull2 and, likewise, those are matched to their NN vertices in hull
3, and so on [
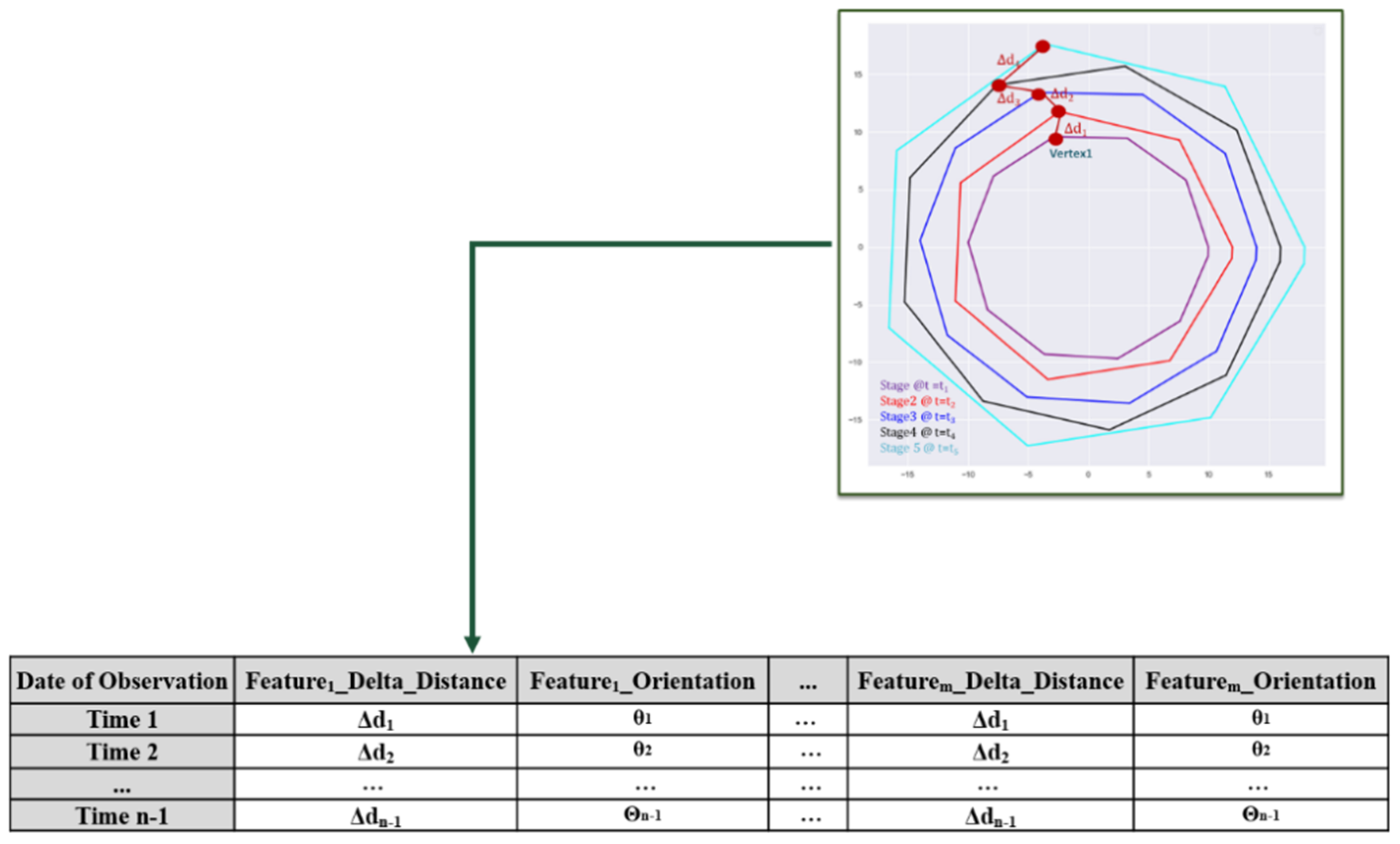
55]. The assumed movement of one of the vertices is shown in
Figure 5. The nearest neighbor is found based on the smallest Euclidean distance between vertex sets. Equation (1) shows the nearest neighbor search in
from
p1 ∊
in 2D space (
and
are two consecutive descriptor vectors).
At each time step, the NN of vertices in two time steps are determined, and the change in magnitude and orientation between matched vertices is computed and compiled for the complete temporal sequence (
Figure 5). This resulting dataset consists of the distances and orientations of vertex changes between subsequent hull stages throughout a time series. This dataset is illustrated for the identified and aligned multiple stage of a defect with a polygon shape in
Figure 4 and
Figure 5.
2.3. Time-Series Modeling
The overall approach to time-series modeling is illustrated in
Figure 6 and presented here. Once the dataset representing the evolution of defects is constructed (
Section 2.2), a stochastic model can be fit to the dataset to model the dynamics of defect evolution. Each column of this dataset is a time series that represents the evolution of each feature over time. Time-series forecasting is performed in order to capture the underlying long-term life-cycle trends in inspection data. The model can then be used to extrapolate the time series into the future. This modeling approach is particularly useful when the temporal behavior is stochastic, as opposed to understood deterministic evolution, and where the relationship between parameterization variables is not well understood [
56]. For example, in the problem presented later in this paper, there is no knowledge available on the boundary conditions (i.e., applied load and support reactions) of the tested structural component, and there is no established deterministic model for the propagation of fatigue cracks.
There are several common approaches to time-series modeling, including autoregression, moving average, exponential smoothing, autoregressive integrated moving average (ARIMA), and multivariate time-series vectorized autoregression (VAR). All of these models are linear, meaning that their predictions of the future values are constrained to be linear functions of past observations. Because of their effectiveness and ease of implementation, linear models are the main research focus for time-series modelers, as is the case in this study. Nonlinear modeling approaches such as recurrent neural networks were not considered here due to the limited training data available for observing defect evolution.
From the available time-series models, ARIMA and VAR models were selected for this study, and their performances were compared against each other. The autoregressive integrated moving average model (ARIMA) methodology developed by Box and Jenkins [
57] is able to handle non-stationary time series, in other words, scenarios where the statistical properties of the time series measurements do not remain constant over time. As such, it relaxes the requirement that time-series data be covariance-stationary prior to modeling, and it is well suited to the challenging variations in field conditions that impact remote sensing-based inspection practices [
58]. With ARIMA, the future value of a variable is assumed to be a linear function of several past observations and random errors. An ARIMA model contains two sub-processes (autoregressive, moving average process) and explicitly includes differencing in the formulation to account for the non-stationarity of the data. ARIMA gained enormous popularity in many areas, and research practice confirmed its power and flexibility [
59,
60,
61]. A generalized form of the ARIMA time-series model is shown in Equation (2).
where
and
are the actual value and random error at time
t, respectively.
(
i = 1, 2, …,
p) and
(
j = 0, 1, 2, …,
q) are the vectorized model coefficients.
p and
q are integers, often referred to as orders of the model.
As an alternative, vector autoregressive (VAR) models are effective for multivariant time-series data where there is a potential dependency between model variables. Therefore, unlike an ARIMA model that estimates the present value of a variable based only on its past values, VAR models consider past values of other variables as well. This model was used here to study the dependency and effect of the movement of convex hull vertices on other vertices. The VAR model [
62] was used for damage detection studies previously [
63,
64], but there was no effort to model the life cycle of a defect to date. The general form of the autoregressive model is shown in Equation (3). Similar to ARIMA, the VAR model relates the current value of a variable to its past values.
where
is random error (random shock) and
represents a constant. Similarly, the VAR model relates the current value of a vector to its past values, and each variable depends not only on its own past values but also on those of other variables, in which
K × 1 is a random vector,
represents a fixed (
K ×
K) coefficient matrix, and
is a
K-dimensional random error [
62]. To summarize, the power of ARIMA modeling stems from its ability to handle non-stationary time series with non-constant statistical properties over time. On the other hand, VAR is suitable for analyzing stationary multivariant time series with constant statistical properties and dependancy among variables.
2.3.1. Model Parameter Identification
Prior to fitting the coefficients of the time-series model, the model order must be optimized. The ARIMA model contains three components for which an order must be determined: autoregressive (AR), integrated (I), and moving average (MA) (Equation (2)). The AR component uses the dependent relationship between an observation and some number of lagged observations. The order of the AR component (
p) is the number of lag observation included in the model. The integrated component (I) employs differencing of raw observation data in order to make the time series stationary, and its order (
d) is the number of times that the raw observation is differenced. The MA component uses the dependency between an observation and a residual error, and its order (
q) is the size of the moving average window. In this study, ARIMA model orders (
p,
d, and
q) were evaluated based on a mean squared error. A prototyping dataset was divided into train and test sets, and the optimized combination of model orders was chosen such that they produced the least mean squared error in the test set. For the VAR model, the model order,
p, was selected based on Hannan–Quinn information criterion (HQIC) [
65]. This criterion was applied because this is used to consistently estimate the order under fairly general conditions [
66]. The criterion is shown in Equation (4).
where
n is the number of observations,
k is the number of parameters to be estimated (e.g., the normal distribution has mu and sigma), and
Lmax is the maximized value of the log-likelihood for the estimated model. The coefficients for
k indicate the level to which the number of model parameters is being penalized. The objective is to find the model order of the selected information criterion with the lowest value HQIC value.
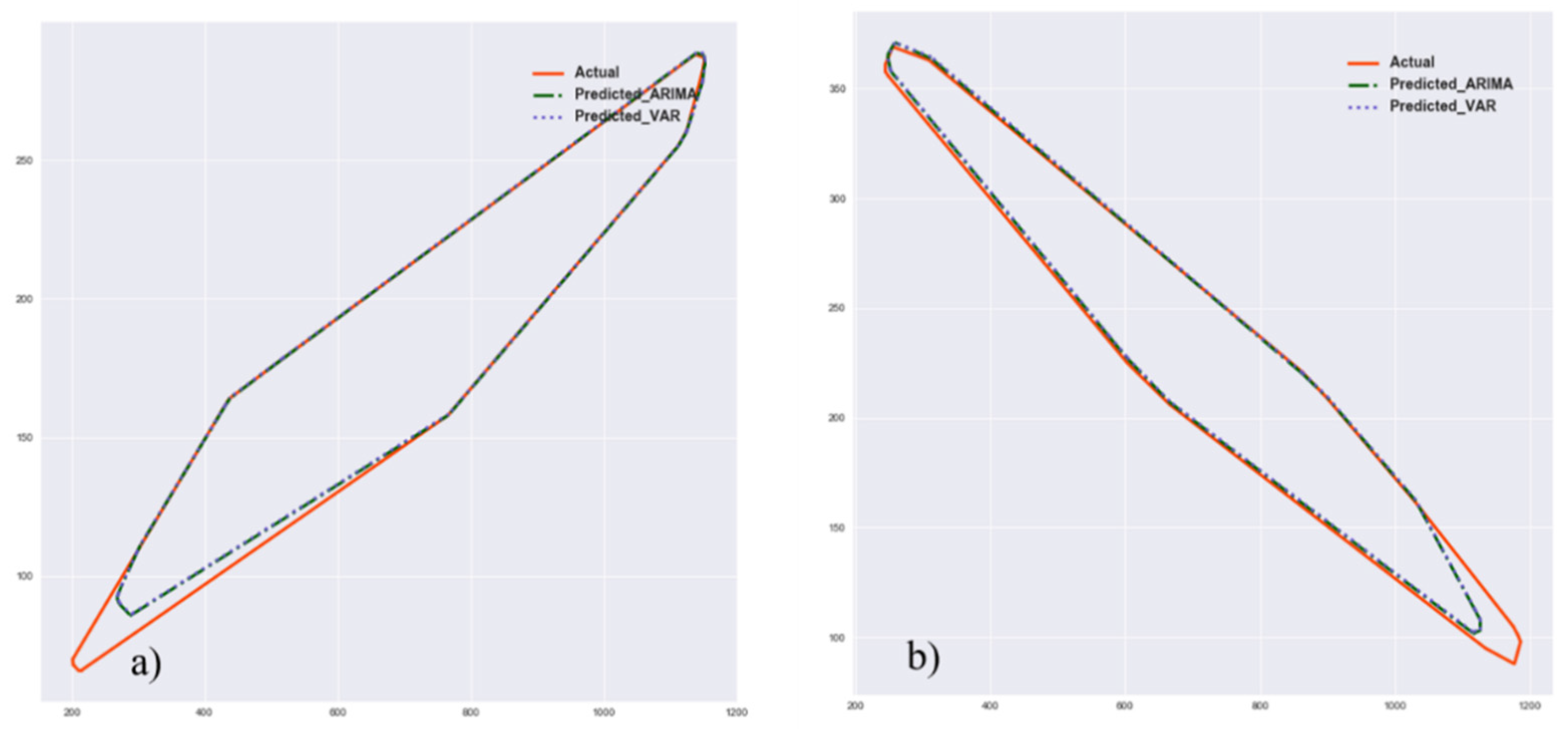
2.3.2. Forecasting and Defect Reconstruction
Once a model is fitted to a sequence of defect observations, the future state of the convex hull parameterizations can be predicted by the forecasting model. Once predicted, the future defect shape can then be reconstructed by converting the feature vector into a hull shape. A complication is that the number of extracted features may be inconsistent at different time steps, and this discrepancy in the length of the vectors in some cases leads to an inaccurate defect prediction. This case will happen when the number of features extracted by convex hull computation at early time steps is significantly smaller than that in the later time steps. To handle this issue, a statistical assumption is employed. For features that were not fit to a model and, therefore, their values were not predicted by dynamic modeling, the arithmetic mean of other features can be used as their expected value.
The pseudocode for the complete algorithmic methodology is shown in
Figure 7. Upon reconstruction of the predicted geometric configuration of a defect, it is then possible to update a numerical simulation to account for the predicted change in the structure’s geometry due to the defect. This updating process is not tested here, but such capabilities were developed in prior related work, including efforts by the authors [
34,
35,
36].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}