1. Introduction
Both recreational runners and running athletes can enhance their training outcomes by monitoring their fatigue level while training. The concept of muscular fatigue is usually described in two levels, or thresholds, where the first threshold represents neuromuscular fatigue and the second represents fatigue due to an imbalance between lactate production and lactate removal [
1]. Most markers that are used to indicate fatigue during running, i.e., lactate or ventilatory parameters, need to be measured via blood samples or ventilation. However, due to the inconvenience of this during outdoor and recreational activities, neither of these are feasible to use in everyday training. Therefore, both recreational and competitive runners could be assisted by a new monitoring system that can predict fatigue level while running using noninvasive, portable instruments. Examples of such measurement units are electromyography devices, which in recent years have become small enough to be portable and possible to use inside clothing materials [
2].
Previous studies have shown that features from an electromyography (EMG) signal can be used to detect fatigue thresholds both during cycling and running [
3,
4]. The features that have most frequently been used to calculate the fatigue thresholds are amplitude-based measures, such as the root mean square and integrated EMG, and frequency-based measures, such as mean power frequency or median frequency [
3]. However, there are also studies that report a lack of direct correlation between the mean power frequency and fatigue level [
5]. The validations of the above features are mainly based on comparing the time or workload of the thresholds in comparison to known critical fatigue thresholds, such as the ventilatory threshold, the neuromuscular threshold, or the lactate threshold (LT). However, few studies report methods to continuously monitor fatigue level in relation to lactate level or ventilatory oxygen uptake, to use as input into an intelligent system. One of the early attempts of an autonomous fatigue prediction system [
6] used linear discriminant analysis to predict fatigue in a static exercise. Another study was successful in finding fatigue predicting features in a dynamic biceps curl exercise [
7]. However, rarely are sporting activities static and localized to one muscle only, which is why vigorous activities, such as bicycling and running, are of interest to study further.
Razanskas et al. [
8] developed an algorithm using the cumulative sum of scores and correlation methods to train a machine-learning model to detect changes in lactate levels during bicycling. They found that a random forest (RF) model could predict the lactate level based on surface-electromyography (sEMG) signals with R
2 values > 0.9 when trained using the time domain features and >0.8 when trained using the frequency domain features. However, for a model to be valid to use in a product application, it needs to be useful also for other types of activities, such as running. Furthermore, the model needs to be able to predict an individual’s fatigue level without knowledge of the workload or the state of recovery. Furthermore, LT assessed by the absolute accumulation of lactate is a subjective variable [
9,
10], which may provide errors in determining the current fatigue state just by finding the lactate prediction level. Therefore, it may be of interest to further explore whether better prediction accuracy can be obtained using an a priori classification model that determines the fatigue level based on lactate slope parameters.
The purpose of this study was to investigate whether the machine learning method that was previously shown useful in detecting fatigue in bicycling using sEMG on lower limbs [
8] can also predict fatigue in a running task. Furthermore, the study aimed to develop this method further by adding a segmentation of fatigue levels to the analysis in order to improve accuracy.
2. Materials and Methods
The overall study design is described in a schematic diagram in
Figure 1. In the first step, data were acquired using a treadmill protocol, as described below, and sEMG sensors placed on the lower limb muscles of runners. Secondly, the sEMG signals were preprocessed. Three different types of feature sets were extracted from the signals, and a forward sequential feature elimination algorithm was used for feature selection. Two different RF models were trained, of which the first model was used to predict lactate accumulation using regression, as described previously by Razanskas et al. [
8], and the second model to classify fatigue based on change-point segmentation of lactate accumulation. The algorithm steps are described further below.
2.1. Data Collection
Twelve aerobically trained participants (five women and seven men) volunteered to participate in the study. Data were acquired during a single test session of an incremental treadmill-running test, as described below. Participants were either amateur long-distance runners (n = 4) or amateur triathlon athletes (n = 8) with a mean (±SD) running volume of 46.2 (±15.6) km/week, age 43 (±8) years, body mass 71.9 (±11.7) kg, and stature 1.75 (±0.99) m. All participants were informed about the study prior to the test occasion, both orally and in writing. Ethical approval was obtained from the regional ethical review board (Reg. No. 2014/162).
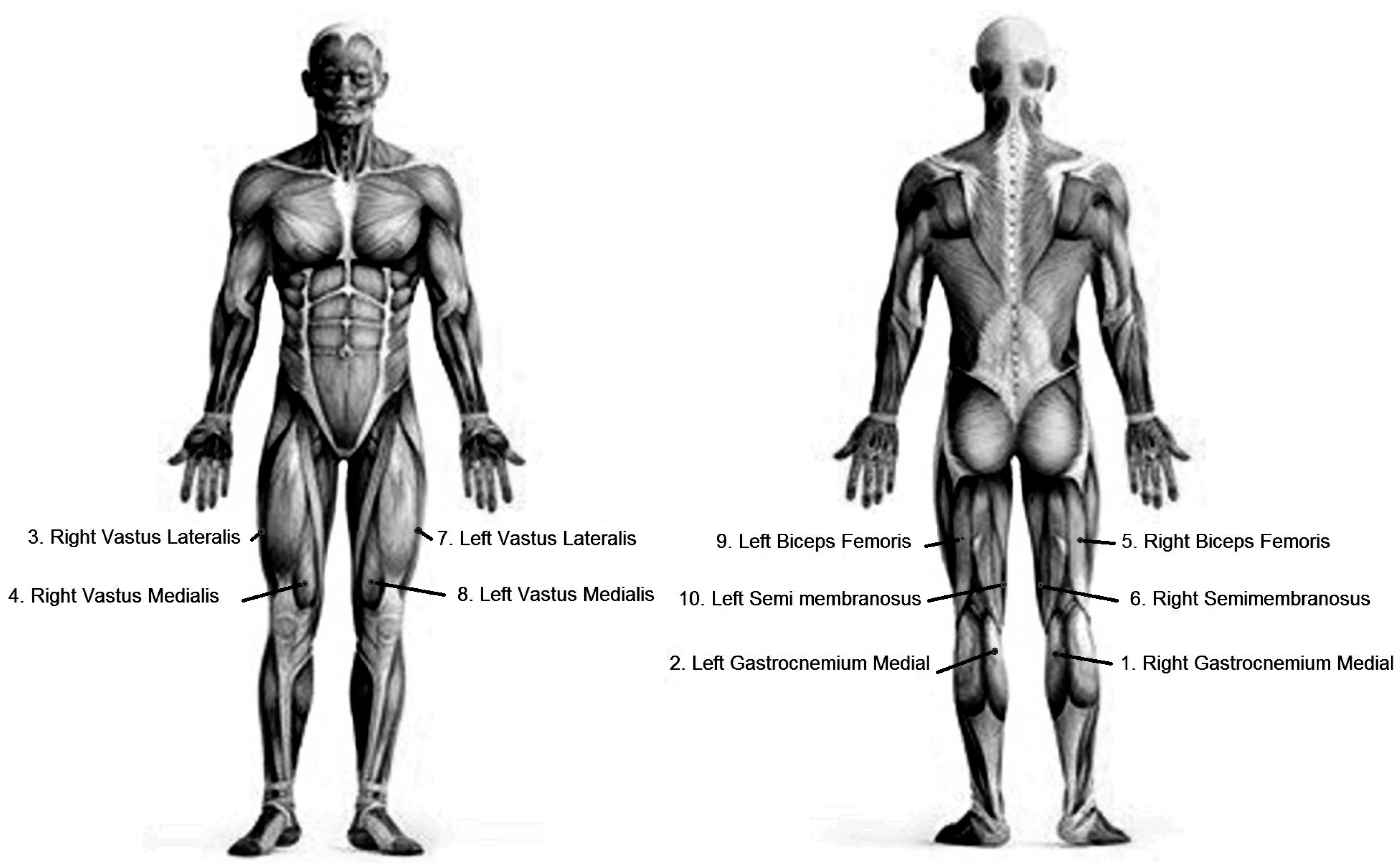
Participants were equipped with wireless sEMG-sensors (Delsys Trigno, Delsys, Boston, MA, USA) on m. Vastus Lateralis (VL), m. Vastus Medialis (VM), m. Biceps femoris (BF), m. Semitendinosus (SM), and the medial head of m. Gastrocnemius (GM), as shown in
Figure 2, abbreviated for the right leg as RVL, RVM, RBF, RSM, and RGM, respectively, and for the left leg as LVL, LVM, LBF, LSM, and LGM, respectively.
The sensor positions were palpated according to the SENIAM (Surface Electromyography for the Non-Invasive Assessment of Muscles) guidelines, and sites were shaved, rubbed, and cleaned before attachment of the sensors. The sensors were attached using double-sided tape (Trigno Sensor Skin Interface, Delsys, Boston, MA, USA), and elastic sports tape around the limb to keep the sensors securely fixed. Maximum voluntary isometric contractions were performed for each muscle, according to the SENIAM guidelines, using manual resistance. Ventilatory measurements were performed using Oxycon Pro (Jaeger, Hoechberg, Germany), attached to a mask (7450 Series V2 Mask, Hans Rudolph Inc. Shawnee, Kansas, USA) worn by the participants to collect the ventilatory gases for analysis of ventilation, oxygen, and carbon dioxide. A heart rate monitor (Polar FT4, Kempele, Finland) was positioned on the thorax and connected to the Oxycon wirelessly. Subjective measures of leg fatigue and ventilatory fatigue were obtained using the Borg scale rating of perceived exertion, and blood lactate concentration samples (Lactate Pro 2, Arkray, Japan), were collected every two minutes throughout the test, by stepping to the side of the treadmill. This procedure took about 30 s. The blood samples were gathered from the right-hand fingertips of the participant. Prior to testing, each participant familiarized themselves with the perceived rating scale, the strategy to step aside from the treadmill to take a lactate sample, and the safety procedure when fatigue occurred. These procedures were practiced to enable safe and efficient data collection.
The incremental treadmill protocol started with a light warm-up at 8 (for women) or 9 (for men) km/h. The test started with six minutes of running at a speed corresponding to just below each athlete’s 10 km tempo, which was between 11 and 13 km/h. After the initial six minutes, an increase in workload (1–1.5 km/h) was performed every two minutes until the athlete reached a lactate level above 5 mmol/L (or was unable to increase the running workload). At this stage, the workload level was kept constant until the athlete was unable to continue (minimum six minutes). The final six minutes of the test were at the initial speed, i.e., their individual 10 km tempo.
2.2. Feature Extraction
The sEMG signals were recorded from the muscles at a sampling rate of 1926 Hz. In order to eliminate electronic noise and motion artifacts, the sampled signals were preprocessed using the suggested Butterworth filter [
11] with 10th order 400 Hz low pass filter at a stopband of 450 Hz with 60 dB attenuation and the 10th order 20 Hz high pass filter at a stopband of 10 Hz with 60 dB attenuation. The filtered signal S(t) was interpolated using Hermite cubic splines and used for feature extraction and analysis.
2.2.1. Frequency Domain Features
In order to extract frequency domain features, the preprocessed signal S(t) was segmented into muscle activity bursts S
i(t) using a method for detecting muscle activity previously described by Razanskas et al. [
8]. An i
th muscle activity burst corresponds to a single stride cycle in the running. The power spectrum P
i(f) of an i
th burst was computed by using discrete Fourier transform on S
i(t) using Equation (1):
P
i(f) was further used to compute the power distribution of frequencies D
i(f) of each i
th burst using Equation (2):
where f
Nyq is the Nyquist frequency. Frequency-based features were extracted using S
i(t) and D
i(f). The description of each feature is given in
Table 1. Details can be found elsewhere [
12].
2.2.2. Time-Domain Features
The muscle activation time is a critical time-domain feature that is defined as the time difference between the activation and deactivation of a muscle during a stride. The activation moment A(i) and the deactivation moment D(i) of a muscle were computed using the local maxima and the local minima of the derivative of the sEMG signal S(t), as described by Razanskas et al. [
12]. The time span of a single stride cycle was estimated using two consecutive muscle activation moments, A(i) and A(i+1). It was observed that muscles BF, VM, and VL fired sequentially during a stride cycle, i.e., the activation moment of BF preceded the activation moment of VM, and the activation moment of VM preceded the activation moment of VL. Hence, the length of time between A(i+1) and A(i) of muscle BF corresponds to the time span of one stride cycle, and the activation of other muscles can be computed as fractions of this baseline time length.
We used the activation moment A(i) of RBF as the starting timestamp because it was the first activation signal to start each activation cycle. It is pertinent that Razanskas et al. [
8,
12] used three sEMG channels recorded from rectus femoris, vastus lateralis, and semitendinosus muscles of both legs for estimating bicycling fatigue. In order to develop a similar model for estimating running fatigue, we used three sEMG channels recorded from BF, VM, and VL, and discarded SM and GM when extracting features based on the time domain analysis.
The phase shift Ø
X, Y between the activation moments of two muscles, say X and Y, in one stride cycle, was computed using Equation (3):
Similarly, the active time percentage α
X of muscle X in one stride cycle was computed using Equation (4):
The root-mean-square ρ
X of the sEMG signal S(t) of muscle X for the i
th cycle was computed using Equation (5):
Furthermore, the arithmetic mean (AM) and standard deviation (SD) of features Ø
X, Y, α
X, and ρ
X were computed using Equations (6) and (7), respectively:
where
ai is the feature value for an
ith stride cycle, and
n is the total stride cycles. Moreover, the asymmetry of each feature was measured by computing the corresponding arithmetic means of that feature from the right and the left leg and finding the absolute difference between them, given as:
In order to reduce the model complexity, Razanskas et al. [
8] used a subset by excluding amplitude-based features from the time domain features. The subset was termed as the time event features. The time-domain and time event features (shaded grey) are listed in
Table 2.
2.3. Feature Selection
In order to reduce the complexity of feature space as well as computational time in estimating blood lactate using sEMG, and more importantly, to identify the most relevant features for the model construction, a forward sequential feature elimination algorithm based on the Spearman correlation coefficient was used. Importantly, Razanskas et al. [
8] used this feature selection method previously for predicting cycling fatigue.
As a preprocessing step, the blood lactate values were interpolated using Hermite cubic splines with Catmull–Rom tangents [
13] so as to equate the number of lactate samples to the number of sEMG segments. Then, the feature values and blood lactate values were normalized between 0 and 1. Spearman rank correlation coefficient
rs was computed for samples
i = 1…n using Equation (9), given as:
where
n is the total number of sEMG segments,
xi is a feature value of an
ith segment, and
yi is the blood lactate value for that segment, measured as mmol/L. The value of
rs is 1 if the relationship between
x and
y is monotonically increasing, and –1 if the relationship between
x and
y is monotonically decreasing. In the first round, feature sets were selected by setting the threshold of
rs as 0, i.e., all features were selected for the model construction. The threshold was increased by 0.05 in each iteration until the value was equal to 1, where the most significant and perfectly correlated features were selected for the model construction. The results are discussed in
Section 3.2.
2.4. Random Forest
A prediction model based on RF [
14] operates by constructing multiple decision trees that are trained using random subsets of the training dataset. This step of splitting the training set into random subsets and using these subsets for training the decision trees is termed bagging or bootstrap aggregation. Bagging splits the data in a way that two thirds of the random samples from the total dataset are used for training each decision tree and the remaining one third of the samples, termed out-of-bag (OOB) samples, are used for testing that tree. An error
is estimated for each OOB sample
i, where
Yi is the actual value of the sample and
is the predicted value of the sample produced by a decision tree in the forest.
In the case of a regression problem, the generalization performance of an RF model is estimated using an average of the coefficients of determination (R
2), computed using Equation (10):
where
E[
Y] is the mean OOB sample value, an R
2 value of 1 signifies complete regression, and 0 signifies naïve regression. In the case of a classification problem, voting is performed between the decision trees, each predicting an output class for a particular OOB sample
i. The class with the majority of votes in the forest, is selected as the predicted class. In both cases, regression and classification, the utilization of multiple decision trees in an RF eliminate the prediction bias that could possibly be introduced in an output of a single decision tree. Another advantage of using bagging is that the data variance is reduced, which prevents overfitting [
15].
Previous studies have shown that lactate accumulation during running is highly individual [
9,
10], which may lead to the high variability of lactate prediction during this activity. Therefore, another method was tested alongside that proposed by Razanskas et al. [
12] to incorporate subjective trends. We incorporated subjective trends of lactate concentration based on some a priori information of physiological behavior to train an RF model for predicting running fatigue. This was done by using a change-point segmentation (CPS) method, which identified timestamps at which the lactate values reached aerobic, anaerobic, and the maximum lactate accumulation level at exhaustion during the exercise. As a result, the previous regression problem to predict blood lactate accumulation in bicycling was transformed into a new classification problem that enabled the generalization of the model for predicting blood lactate accumulation in the running.
2.5. Change-Point Segmentation
The change-point method segmented the duration of the total exercise time between three classes (
Figure 3), based on the individual slope changes between lactate points. Class ‘1’ represented the aerobic phase, i.e., the time between the start of the test and the LT. Class ‘2’ represented the anaerobic or lactate accumulation phase, i.e., the time between the LT and the point where the lactate accumulation was maximum at exhaustion. Class ‘3’ represented the post-exhaustion lactate recovery phase, i.e., the time between the maximum lactate accumulation and during the recovery.
In order to find the best fitting segmentation of classes 1, 2, and 3, a linear piecewise connected function was defined and selected by means of the least square method. That is, given the lactate samples
x (
t) observed at the time points
t1,
t2,
t3 …
tn where 0 ≤
t1 <
t2 <
t3 < … <
tn ≤ max, the segmentation was the pair of breaks was defined as:
where
l(
t1),
l(
t2),
l(
t3), …,
l(
tn) are values of the piecewise connected lines, given as:
for:
and:
which guarantees the connection of the lines. Here,
t’ refers to the timestamp at LT and
t’’ represents the timestamp at maximum lactate accumulation at exhaustion. From this minimization procedure, class 1 is the time duration between timestamps 0 and
t’, class 2 is between timestamps
t’ and
t’’, and class 3 is between
t’’ and max. The recorded sEMG signals were segmented using the timestamps
t’ and
t’’ between the three classes, aerobic, anaerobic, and recovery phases, as shown in
Figure 3, and used as training targets. Each lactate classification model was checked visually to ensure that the classification model performed according to other methods of determining LT [
9].
2.6. Model Validation
Two different experiments were performed, first to validate the previous bicycling models on the running data. The second experiment was to validate the novel CPS method for the classification of running fatigue. In order to optimize the generalization performance, the forward sequential feature elimination algorithm was used in both experiments. In the first experiment, RF regression models were trained separately using the frequency-based features (
Table 1), the time-domain features (
Table 2), and the time event features (
Table 2: shaded) extracted from the sEMG signals recorded during the running exercise. As previously suggested [
8,
12], RF with 100 trees was used with an initial 10 random seeds. Models were trained separately for predicting lactate as well as oxygen uptake. A comparative analysis of the RF regression models for bicycling and running is presented in
Section 3.1.
In the second experiment, the new CPS-based RF classification model was trained to discriminate between running fatigue classes using the feature sets. The model was stratified using 100 trees and 10 initial random seeds. Two different approaches were used. In the first approach, full feature sets were used for training. In the second approach, the forward sequential feature elimination algorithm was used to identify the combination of features producing the highest classification accuracies. The classification performance was analyzed using the area under the receiver operating characteristic (ROC) curves (AUC). Results and comparisons between frequency, time event, and the time-domain models for the classification of running fatigue are presented in
Section 3.2. Significant features that contributed to model training were examined using a non-parametric Kruskal Wallis (KW) test by grouping samples from all participants into classes 1, 2, and 3. This was done to ensure that the classification accuracy obtained by the model was not due to noise or overfitting. Importantly, a significant
p-value (
p < 0.05) rejected the null hypothesis that samples belong to the same group.
4. Discussion
The results suggest that the method shown useful to predict fatigue in bicycling [
8,
12] needs development to be valid for use in running. Razanskas et al. [
8,
12] used RF regression models with 100 trees for predicting bicycling fatigue. Strong R
2 values (>0.8) were produced when frequency-based features (
Figure 4) were used to train the model, and the performance was improved (R
2 > 0.9) when the time domain features were used. However, these results relied on the assumption of the cyclic stationarity of the extracted sEMG segments [
16]. When we used this model to predict lactate concentration in running fatigue, a higher standard deviation in the R
2 for different runners was observed compared to the standard deviation in the R
2 for bikers (
Figure 4), supporting that LT during running is a subjective trait [
9,
10]. It was observed that runners produced subjective physiological trends relative to the exercise intensity, i.e., the duration and the values of the observed lactate concentrations at aerobic and anaerobic thresholds, and the maximum lactate concentration at exhaustion was varying for different runners, making it complicated for an RF regression model to generalize the lactate accumulation trends. In addition, some runners do not attain their maximum lactate concentration. The CPS-method, however, which was developed in this study, improved model accuracy (
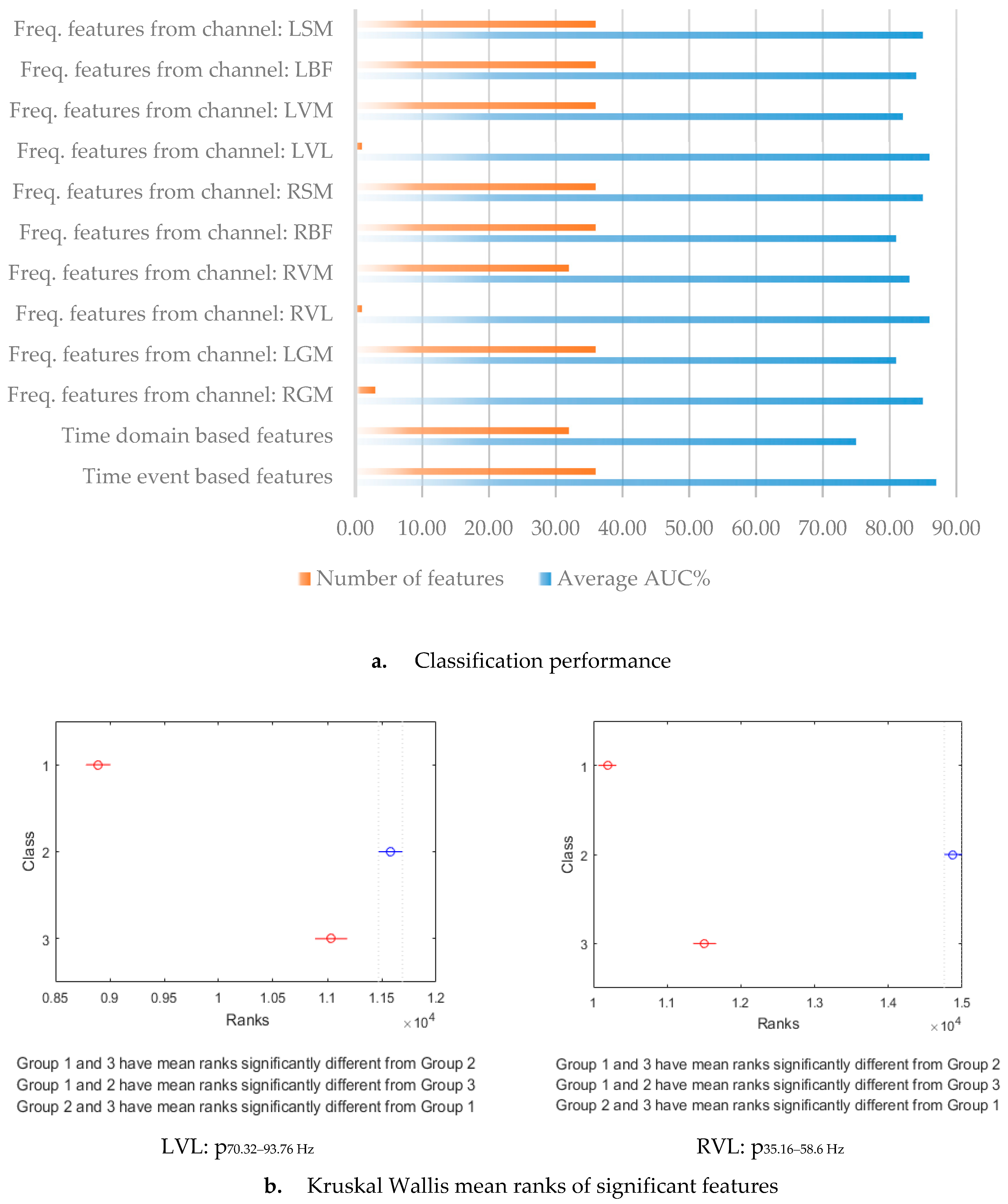
Figure 7). The best feature found was frequency percentage features for the VL muscles. We obtained an area under the ROC above 0.8, which can be considered promising for the intended use (
Table 3b). However, there may be further improvements available to increase the validity of fatigue prediction.
Although this study showed that the model suggested previously by Razanskas et al. [
8,
12] did not seem valid for running, the technique using CPS showed promising results for use in general fatigue prediction. However, it needs to be validated for several types of endurance activities, such as running and bicycling outdoors. A successful outcome of validation studies may result in sensor implementation into clothing that can be used to keep track of lactate accumulation without collecting blood samples during training.
Previous studies that have determined thresholds (aerobic and anaerobic threshold) based on lactate measures from incremental exercise tests used a number of different methods to perform this, for example, fixed levels, increments of 0.5–1.5 mmol/L, and various slope gradients [
9]. The method used to segment the LT in this study was based on a combination of previous methods and CPS methods [
9]. The piecewise linear function estimates the slopes of the first two segments and put a threshold (segment breakpoint) where the two lines intersect, similar to the approach of Bunc et al. [
17]. There are some issues regarding the validity of the LT based on incremental exercise tests, and which method works best seems to depend on the individual [
18]. However, the segmentation approach in this study was mainly aimed to map and estimate feature prediction from the EMG-data, which seemed to work well as a first step.
Something to take into consideration when developing this method further is that the LT may occur at a lower exertion level in cycling compared to running [
19]. Therefore, a future study may be recommended to test the method on both running and cycling using the same athletes and setup, and involve more ecologically valid contexts, such as varied terrain.
Although this study aimed to compare the results with the previously performed study by Razanskas et al. [
12], there were some methodological differences, due to the type of exercise performed. Firstly, the exercise protocol differed in building up to the highest workload. The running protocol made incremental increases up to the maximum level, whereas the cycling study went from 60% of maximum to 90% of maximum directly. The reason for incremental increases during running was for the central circulatory system to be able to adapt to the new workload before the increase in workload. Furthermore, by increasing from 60% to 90% without incremental steps, there will be an instantaneous effect of workload above the LT, which makes it more challenging to determine the transition between a completely aerobic phase and an anaerobic phase.
The practical application of this study implies that machine learning techniques of EMG-signals can be used to predict whether the running athlete is currently in a phase where there is a balance between lactate production and lactate removal (aerobic state), or whether lactate is accumulating in the blood (anaerobic state). Although the results of this study seem promising, in use, the algorithm will require calibration at an individual level to be valid. This is due to the individual differences in LT and maximal fatigue capacity. A calibration procedure could be performed as a treadmill run with incremental steps whilst giving feedback on a rate of perceived effort scale. Although most users of a fatigue-monitoring product would likely be experienced runners and cyclists, it may be considered a risk to promote running to exhaustion, which is why a submaximal procedure would be preferable.
It is essential in a practical application that as few features as possible are used to optimize the estimates of the outcome, due to signal processing time [
20]. In this study, the two features that showed the best estimate of the segmentation model for running was the relative power of the signal (p
35.16–58.6 Hz of the RVL and p
70.32–93.76 Hz of the LVL muscle). Therefore, the recommendation would be to involve these features in a minimized setting of fatigue analysis during running.
In conclusion, the proposed CPS-based classification algorithm was able to generalize the discrimination between lactate accumulation phases for different participants that were previously not possible using the bicycling model. The method is an alternative to the previous lactate estimation from blood samples that were not feasible for use in everyday training. Our experiments have shown that only one feature based on the power spectrum of the sEMG signal could estimate fatigue levels and the state of recovery, suggesting that sEMG signals could be processed accurately in real-time as a result of the lower time and computational complexity of the model. The algorithm was able to generalize the given population. However, we plan to validate the new model further to test ecological validity.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}