1. Introduction
The Internet of Things (IoT) refers to the tens of billions of low-cost devices that communicate with each other and with remote servers on the Internet autonomously. It comprises everyday objects such as lights, cameras, motion sensors, door locks, thermostats, power switches and household appliances, facilitating our lives in almost every aspect of our day [
1,
2,
3,
4]. The most recent estimate is from GSMA Intelligence in June 2018, projecting “... over 25 billion IoT devices in 2025”, which is consistent with Gartner’s estimation in 2017 that by 2020 about 20 billion IoT devices will be connected to the Internet [
5].
The diversity of IoT application domains is wide: smart cities, building and home automation, logistics and transportation, environmental monitoring, smart enterprise environments, and other smart wearable devices [
6]. The recent rapid development of the IoT and its ability to offer a new platform for services and decision-making have made it one of the fastest growing technologies today. This new disruptive paradigm of a pervasive physically connected world will have a huge impact on social interactions, business, and industrial activities [
7]. IoT wearable devices are predicted to reach a total of 126.1 million units in 2019 according to IDC, which will result in a five-year compound annual growth rate of 45.1% [
8].
The proliferation of IoT, however, creates important security and privacy problem. IoT devices monitor, collect and store a huge amount of sensitive data and information about organizations, financial transactions, marketing insights, individuals, and product development [
7]. For example, the popularity of wearable tech is one trend that is currently supporting much more extensive data capturing processes. Inventions such as the Apple iWatch, Google Glass, the Apple Health Kit, the Apple Home Kit, and Google Fit are constantly collecting information about the lives and habits of their users. It includes everything from financial data to information on medical conditions, physical fitness, shopping routines, music preferences, browsing behaviors, and much more [
9]. However, when such sensitive personal data is released to third parties, the possibility of an unintentional or malicious privacy breach, such as detection of user activity, is very high [
10].
Despite the importance of the privacy risk, the majority of IoT users do not understand what kind of information is being collected about them or their environment. In fact, a significant proportion of users are not fully aware that they are sharing their information in the first place [
9]. The General Data Protection Regulation (GDPR) emphasizes that companies are required to protect the privacy of their EU customers by keeping Personally Identifiable Information (PII) secure. Personal data has been defined by the GDPR as follows: “Article 4(1): ‘personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person” [
11,
12].
There are two types of personal data: First, sensitive PII, which comprises information related to the user that is not for public use, or may violate the individual privacy and security by being made publicly available, e.g., log in details, telephone number, date of birth, full name, address. The other type of personal data is non-sensitive PII, which is information that can identify the user but will not affect his privacy or security, such as email address, first name, nickname, social media profile, website [
13,
14]. Privacy is not only about access authorization and encryption; rather, it also emphasizes on the type of transmitted information [
15], and on how it will be used and shared by the legitimate recipient (e.g., IoT manufacturer) [
16].
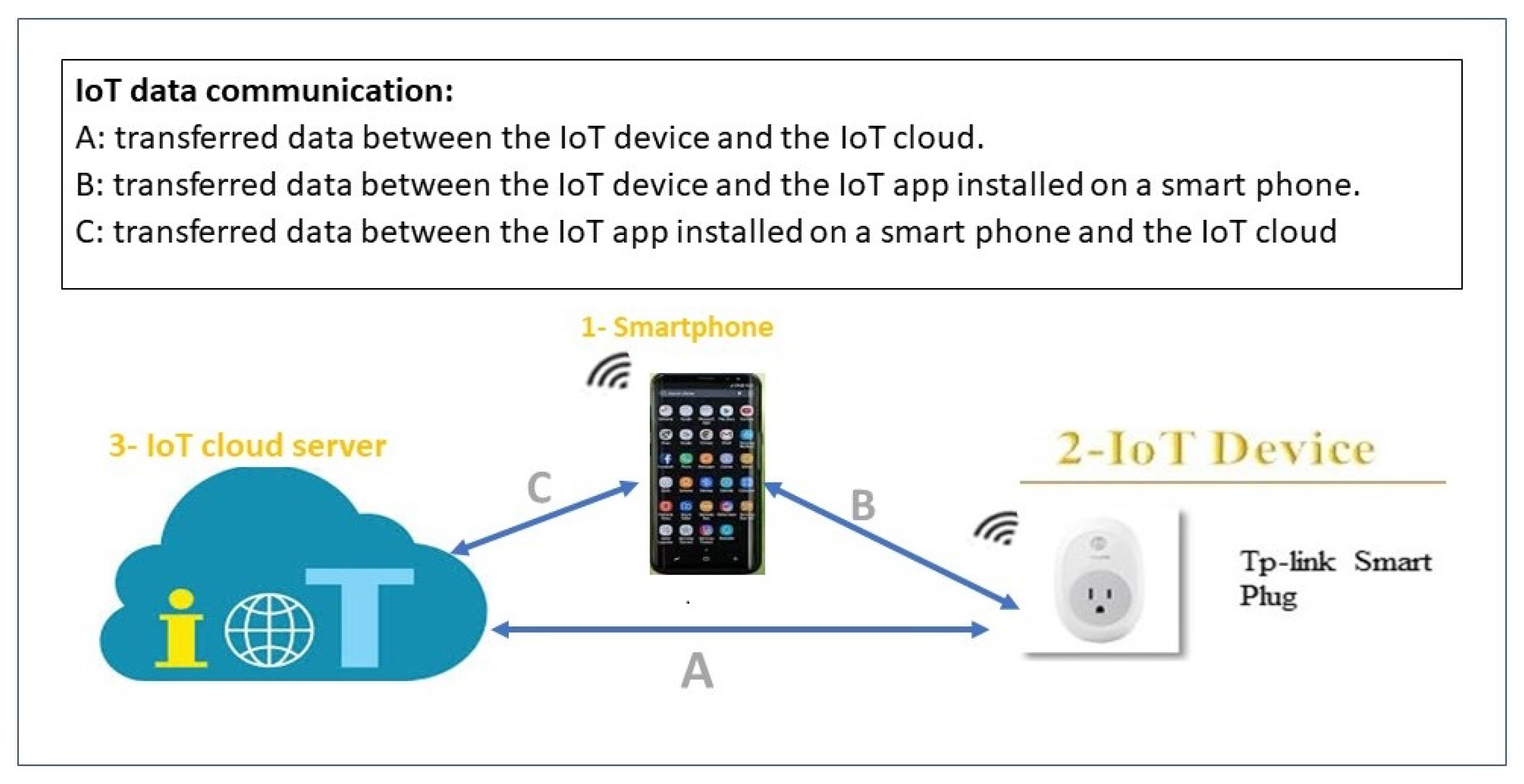
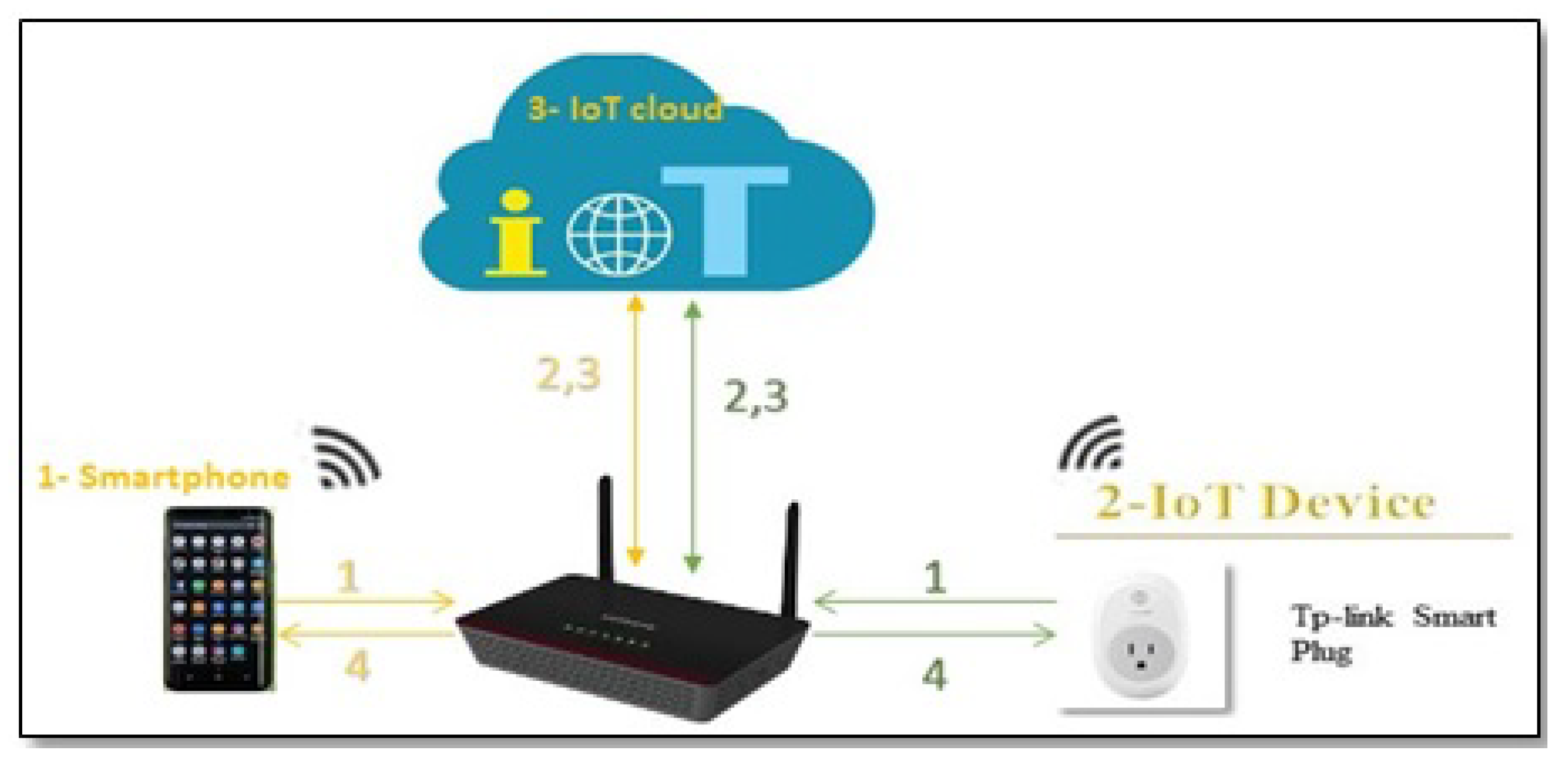
According to [
17], there are three different methods of communication between the IoT device and its cloud: IoT device to IoT cloud (D-C); IoT mobile application to IoT device (A-D); IoT mobile application to IoT cloud (A-C). In fact, there are ample research efforts to uncover IoT security vulnerabilities and exploits [
1,
4,
18,
19,
20,
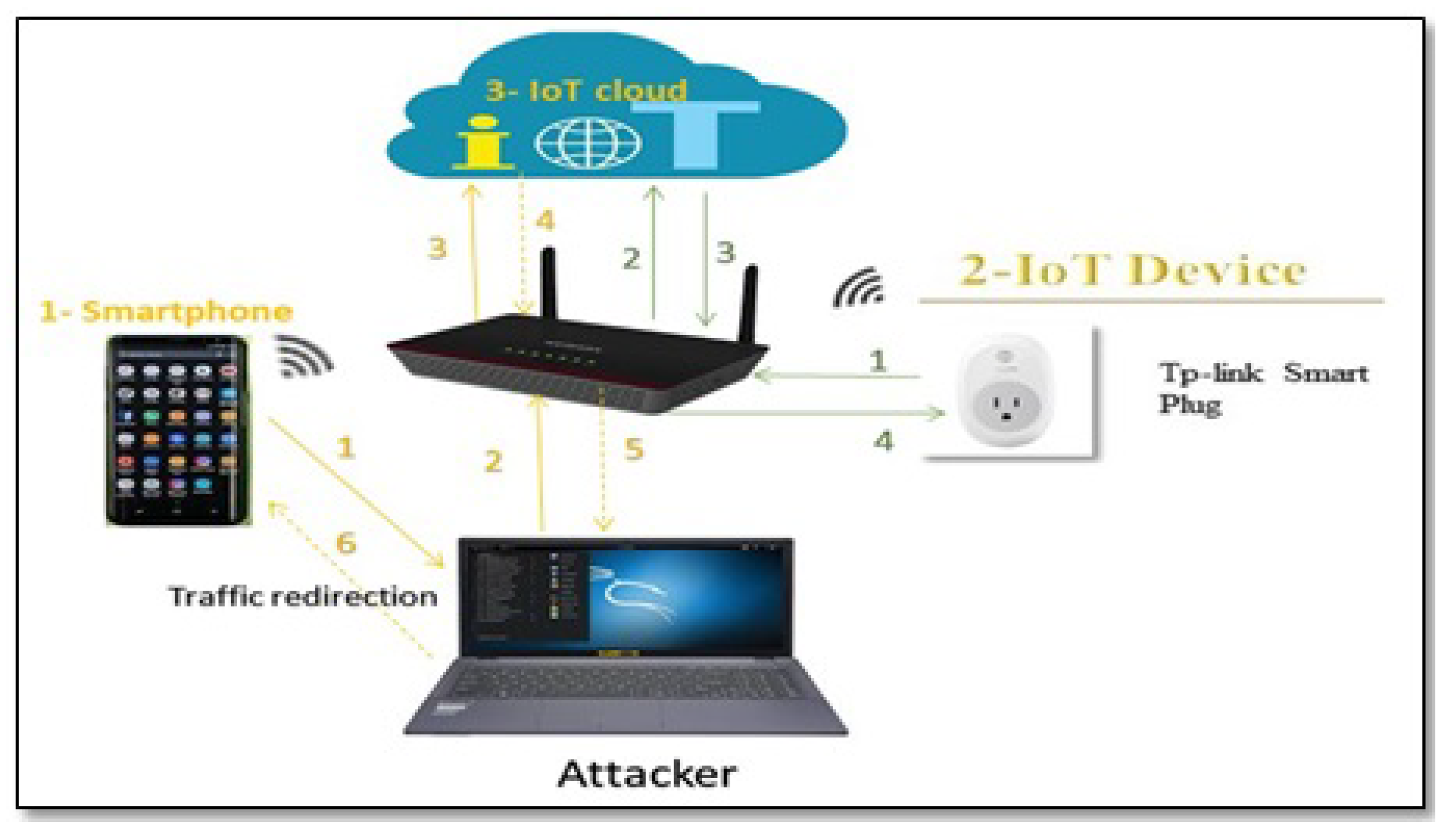
21]. However, researchers that address the privacy risks of IoT devices have focused on the traffic that goes directly from the IoT device to the IoT cloud (D-C) Path A in
Figure 1. Nevertheless, a significant number of home-based IoT devices come with a companion mobile application. Each IoT manufacturer creates its own mobile application to control, configure, and interface with the device. Therefore, data from the IoT device can also reach the IoT cloud via the IoT app installed on the smartphone (Paths B and C in
Figure 1).
To the best of our knowledge, no research studies this alternative path. Based on our analysis, the information that is being sent to the IoT cloud from the IoT app (path C) is much more sensitive than the information sent to the IoT cloud from the IoT device itself (path A) because this information not only reveals the type or the traffic rate of the IoT device, but also it could reveal users’ credentials, users’ location, or users’ current interaction with the IoT device via the app. The latter type of information is not evident from the traffic on path A.
In this work, we study the alternative data disclosure path C in depth. We invent an automated tool called IoT-app privacy inspector that analyzes collected encrypted traffic from IoT devices and classifies it using three supervised machine learning models. Each of them implements the Random Forest algorithm [
22] and is used for a separate classification:
The first classifier classifies traffic by the type of app-device interaction (e.g., the user logs into the IoT app).
The second classifies traffic according to whether it carries sensitive PII, non-sensitive PII, or non-PII.
The third classifies PII traffic by the type of information it contains (e.g., user credentials or user location).
Once an attacker identifies a user’s interaction type e.g., log in to the IoT app, he can infer sensitive PII packets caused by this particular interaction; after that, he can infer the content type of such sensitive PII packet, e.g., log in credentials or geographical location. According to Wang et al. [
23,
24] 77.38% of users reuse one of their existing passwords. Also, Das et al. [
25] estimate that 56% of users change their password at least once every 6 months because they tend to have the same passwords. This means that if an attacker manages to find the packet that contains the user’s password, he could mount an offline password attack to crack the password, which is impossible to detect and faster than an online attack. Therefore, he can gain access to every account the user has.
The contributions of our work are the following:
We show how passive packet-level analysis can be done to infer the behavior of the IoT device through the encrypted network traffic of its apps.
We show how an attacker can infer the type of user interaction between the IoT app that controls the IoT device and the IoT manufacturer’s cloud (e.g., log into or log out from the IoT application).
We show how an attacker can infer whether the IoT app sends sensitive PII to the IoT manufacturer cloud, as well as the kind of this sensitive PII, caused by user interactions.
The rest of the paper is organized as follows:
Section 2 highlights recent research in IoT traffic classification as well as in IoT privacy. In
Section 3, we discuss how an attacker could attack and collect smart-home traffic in our attacker model, followed by a detailed description of the method we use to establish the ground truth in
Section 4. In
Section 5, we present our attack design and implementation, while in
Section 6 we develop our inspector tool with three multi-class classification methods, each one used to infer a different goal; we also evaluate our tool. We present the limitations of our research and discuss future work in
Section 7, followed by a summary and conclusion in
Section 8.
3. Attacker Model
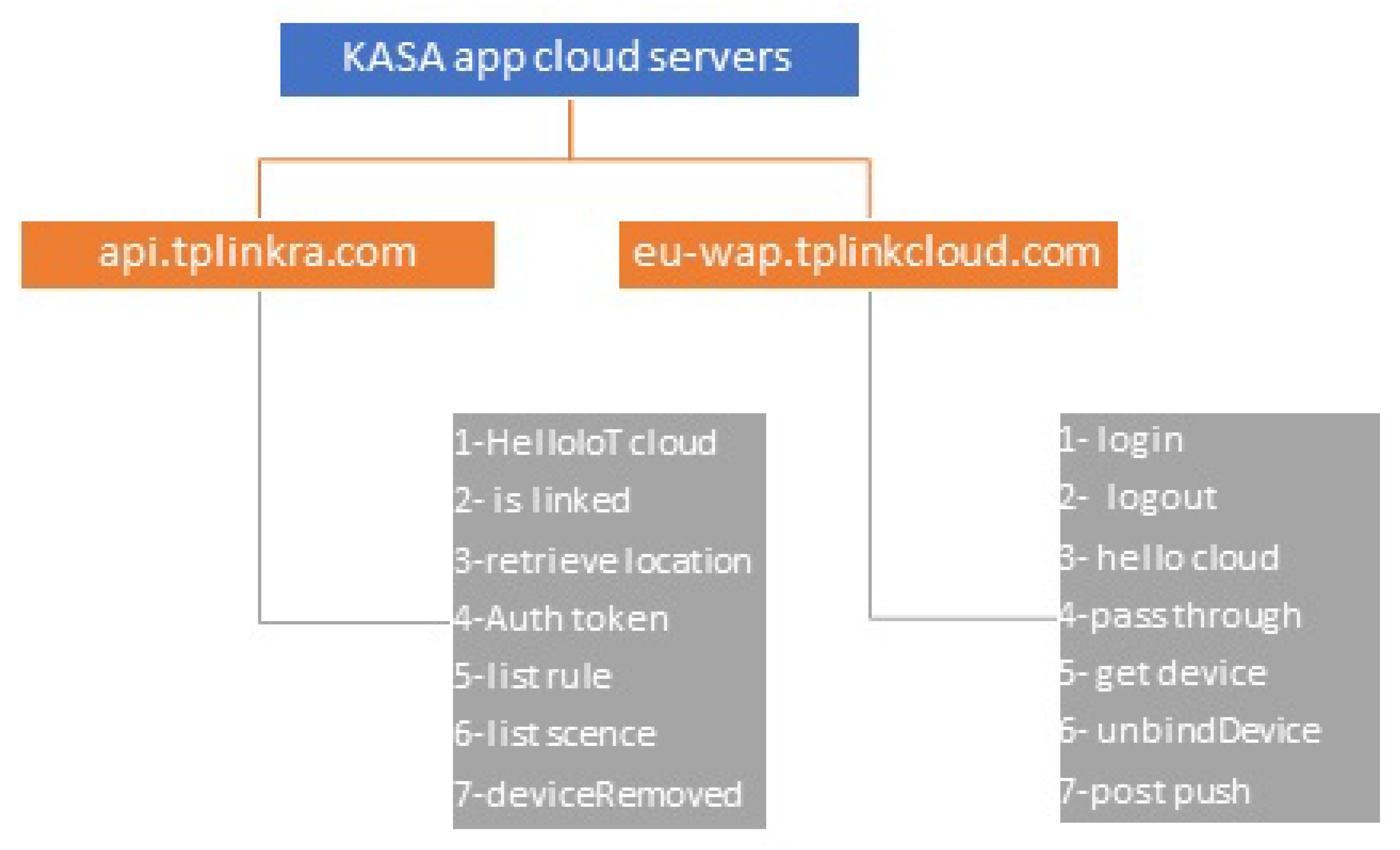
We consider a passive network observer who accesses smart-home traffic. We assume that our adversary can collect the transport-layer traffic of a smart home. Also, we assume that packet contents are encrypted using TLS. This adversary can be the ISP, which can collect and store traffic regularly, or, in general, it can be any adversary who knows the SSID and the WPA2 password of the smart-home router. Finally, the adversary can get a database of labeled traffic from smart-home devices for training machine learning algorithms.
The adversary’s goals are the following:
- (A)
Infer the user’s interactions with IoT devices in a smart home (e.g., logging into the smart-plug app),
- (B)
Determine whether the transmitted data carries sensitive personal identifiable information (PII), non-sensitive PII, or non-PII about the user,
- (C)
Determine the type of sensitive PII (e.g., password for the IoT device app) or non-sensitive PII (e.g., user email) that is being transmitted.
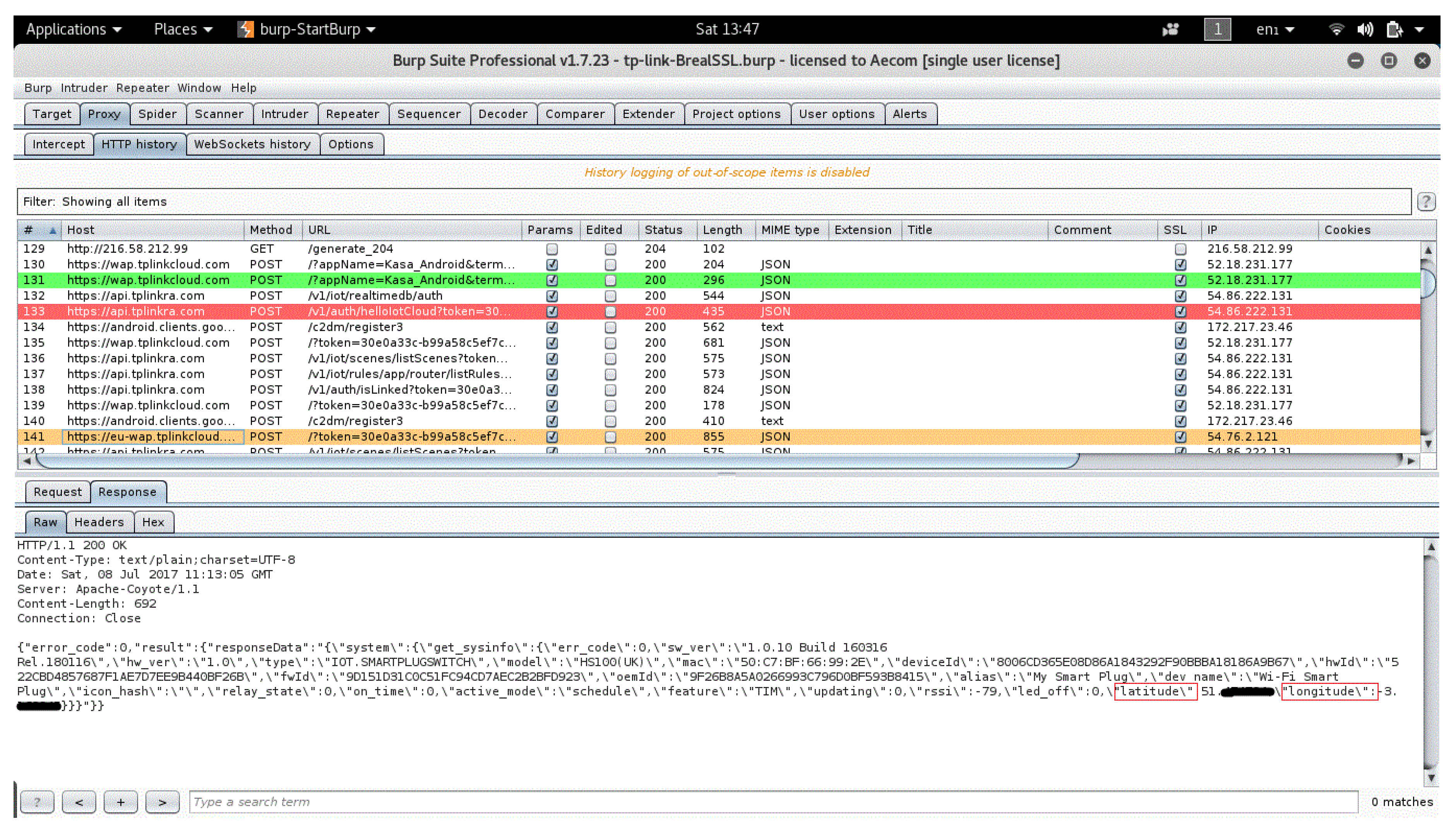
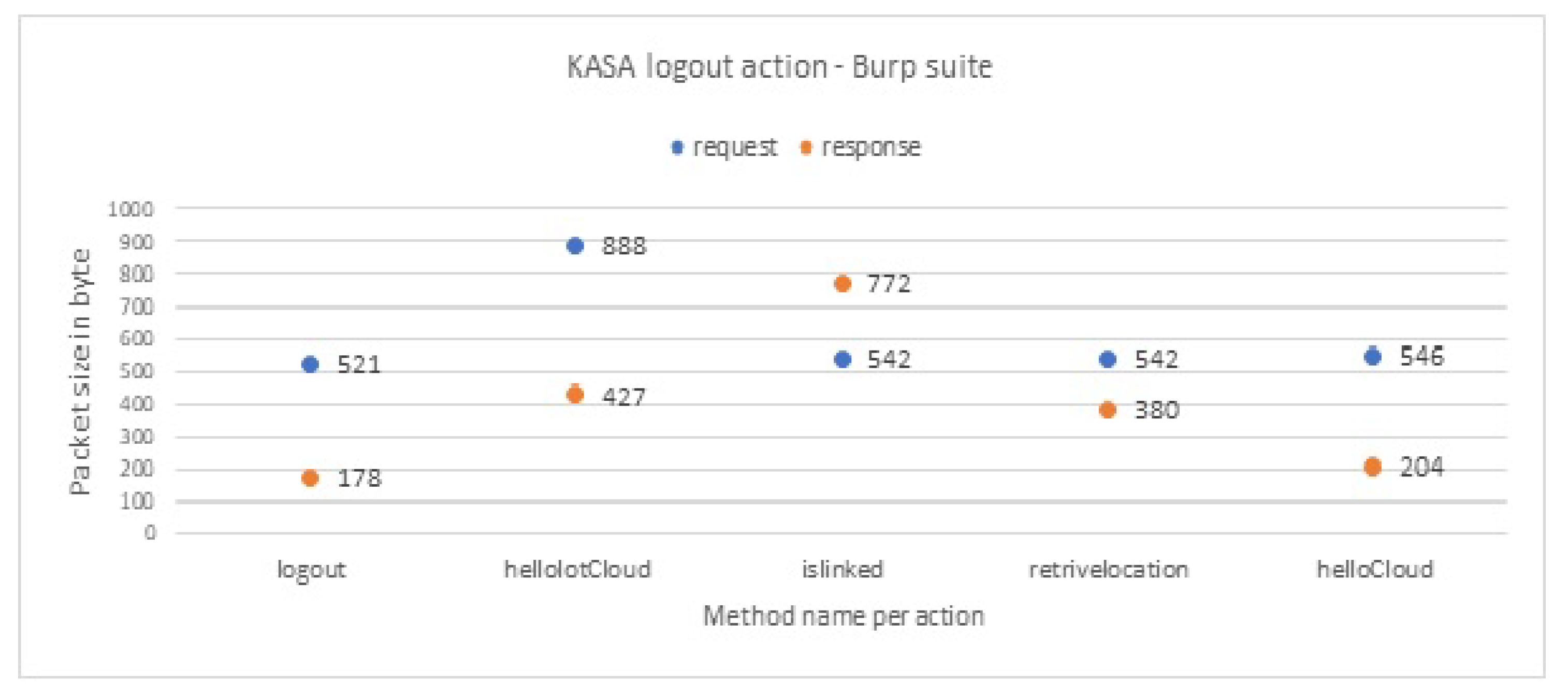
As the traffic is TLS-encrypted, the adversary must rely on traffic rate, packet size, and packet sequence information to make any inference; he cannot read the packet contents. This inference is especially worrisome as it is completely passive, and so it would require no change to existing data collection procedures.
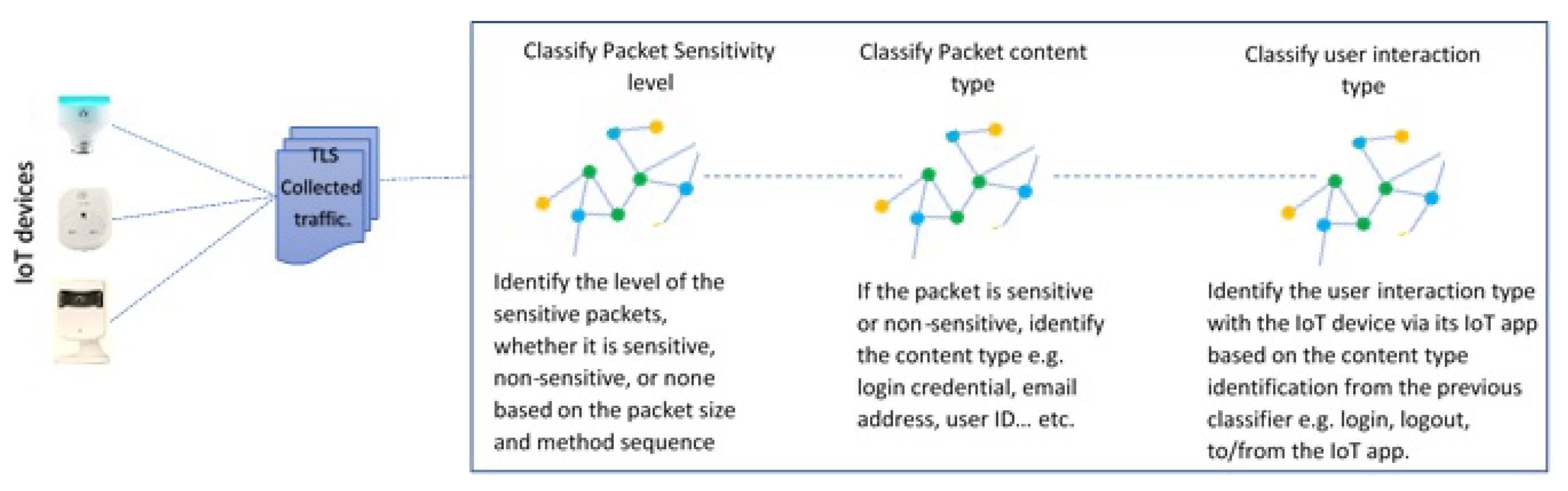
6. Machine Learning-Based Classification
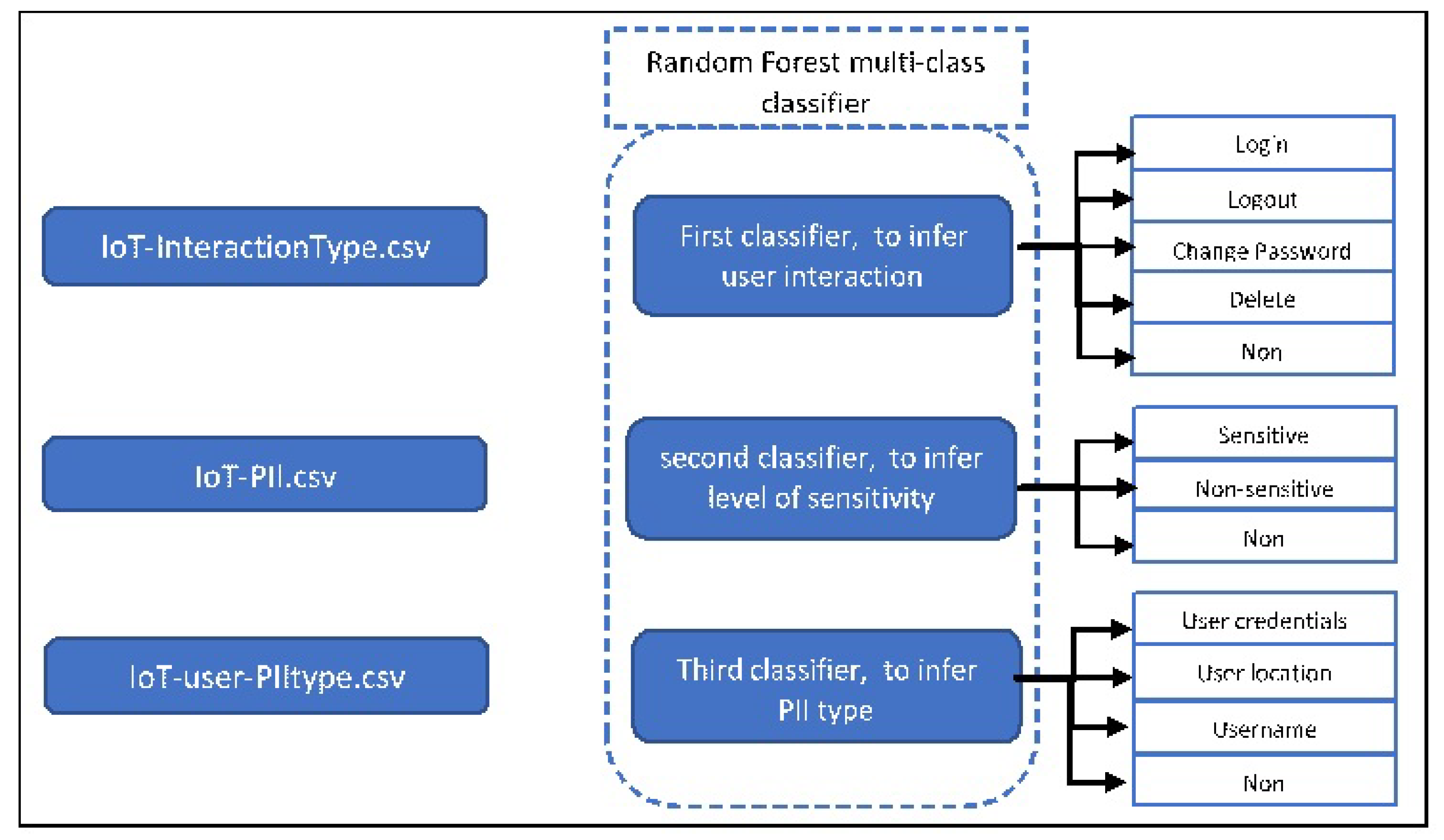
We treat the tasks of identifying user interaction type, packet sensitivity level, and sensitive data type as a multi-class classification problem. Accordingly, six classifiers were selected based on their ability to support multi-class classification.
To evaluate the performance of the selected algorithms and hence choose the best classifier for our problem, we apply several measures. The most common measures are precision, recall, F-mean, and accuracy. As an example, the first multi-class classification problem is evaluated relative to the training dataset, producing the following four outputs:
True positive (TP)—packets are predicted as a sensitive PII, when they are truly sensitive PII.
True negative (TN)—packets are predicted as a None when they are truly None.
False positive (FP)—packets are predicted as sensitive PII, when they are truly None.
False negative (FP)—packets are predicted as None when they are truly sensitive PII.
Precision (P) measures the ratio of the packets that were correctly labeled as sensitive PII to the total packets that are truly sensitive PII [Precision = TP/(TP + FP)]. Recall (R) measures the ratio of the packets that were correctly labeled as sensitive PII to the total of all packets [Recall = TP/(TP + FN)]. F-measure (F) takes both false positives and false negatives into account by calculates precision and recall. Then, it provides a single weighted metric to evaluate the overall classification performance [F1 Score = 2 × (Recall × Precision)/(Recall + Precision)]. Accuracy measures the ratio of the packets that were correctly predicted to the total packets number of the packets [Accuracy = (TP + TN)/(TP + FP + FN + TN)]. However, using accuracy to measure the performance of a classifier is a problem. This is because if the classifier always infers a particular class, it will achieve high accuracy, which makes it useless when it comes to building such a classifier.
The goal is to maximize all measures, which range from 0 to 1, to achieve better classification performance.
Table 4 illustrates the overall results based on previous measurements. As we can see, the Random forest exhibits the best performance across all six classifiers. Therefore, we develop our classification tool based on the Random Forest classifiers. To support our choice, a recent survey on ML methods for security [
49] discusses the advantages of using Random Forest. Their study is related to our research as it combines decision-tree induction with ensemble learning; these advantages are:
Very fast when classifying input data
Resilient to over-fitting.
It takes a few input parameters.
The variance decreases as per the increment of tree numbers, excluding any biased results.
6.1. Multi-Class Classifier Training
To perform our classification experiments, we randomly split each dataset described in
Section 5.1.1 into 80% for training, and the remaining 20% for testing. Notice that each classifier applies to one dataset; see
Figure 11. Each classifier is responsible for inferring the possible label of one category. As we can see in
Table 4, the Random Forest classifier achieves the best performance resulting in 99.8%, 99.8%, and 99.8% in the first and the second classifier, while it achieves 99.4%, 99.4%, and 99.4% in the third classifier for the measurements of precision, recall, and F-mean score, respectively. Additionally, the classification time is 0.35 s, for each classifier.
To validate that the classifier does not overfit, we perform several experiments:
10-fold cross validation experiments
To determine the optimal hyperparameters of the Random Forest algorithm [
22,
50], we try many different combinations using GridSearch algorithm optimization. Based on the results, we set our hyperparameters as follows: the number of n-estimator is 10, min-samples-leaf is 3, bootstrap is “False”, min-samples-split is 8, criterion is “entropy”, max-features is “auto”, and the max depth is 90.
Confusion matrix experiments
To get a better understanding of the performance of the classifier across the experiments, the confusion matrices of the three classifiers in
Table 5,
Table 6 and
Table 7 consecutively show the predicted classes for individual packets compare against the actual ones. Every confusion matrix is a synopsis of inferring the outcome of one multi-classification problem, which demonstrates the process in which our classification model is confused upon making an inference. Then correct and incorrect inference numbers are summarized through count values and decoded to each class. The individual confusion matrix gives us an in-depth look into errors being made by a classifier and mainly focuses on the sort of errors being made. For example in
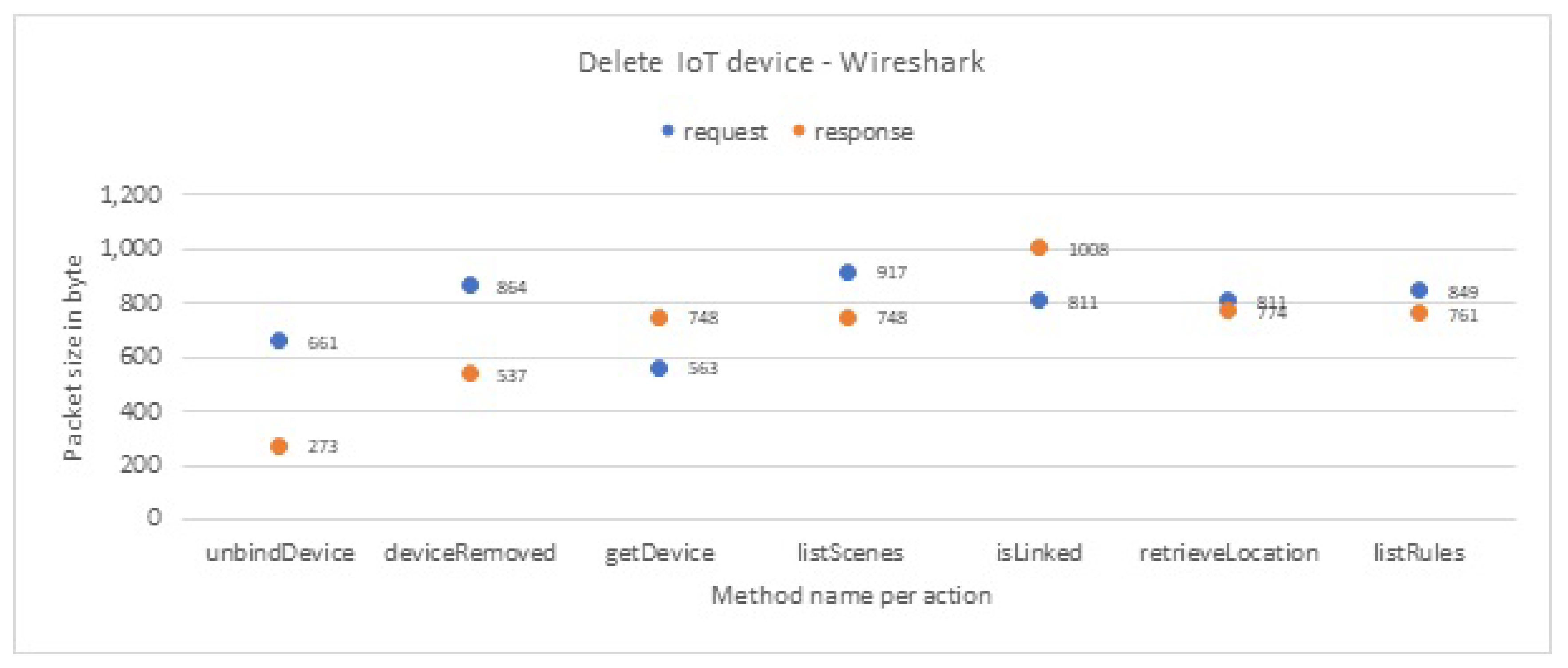
Table 5, the confusion matrix which is related to inferring the user interaction, shows that the actual number of the Delete interaction sessions is 284. However, the classifier correctly infers 281 sessions as a Delete interaction, while it infers incorrectly two packets as Logout interaction and one packet as No-action. These results confirm the high accuracy and reliability of our classifiers.
Compare the accuracy of the training dataset with the accuracy of the testing dataset
The training accuracy is the accuracy of the classifier on the training dataset, while the testing accuracy is the accuracy of the classifier on the testing dataset. If the accuracy of the training data is almost similar to the accuracy of the testing dataset, then there is no over-fitting issue; otherwise, we have an over-fitting issue.
Table 8 shows that the accuracy of the training dataset and the accuracy of the testing dataset are very similar in all the three classifiers.
As a result of the previous experiments, we conclude that the IoT-app privacy inspector tool does not fall into the over-fitting problem.
6.2. Results and Discussion
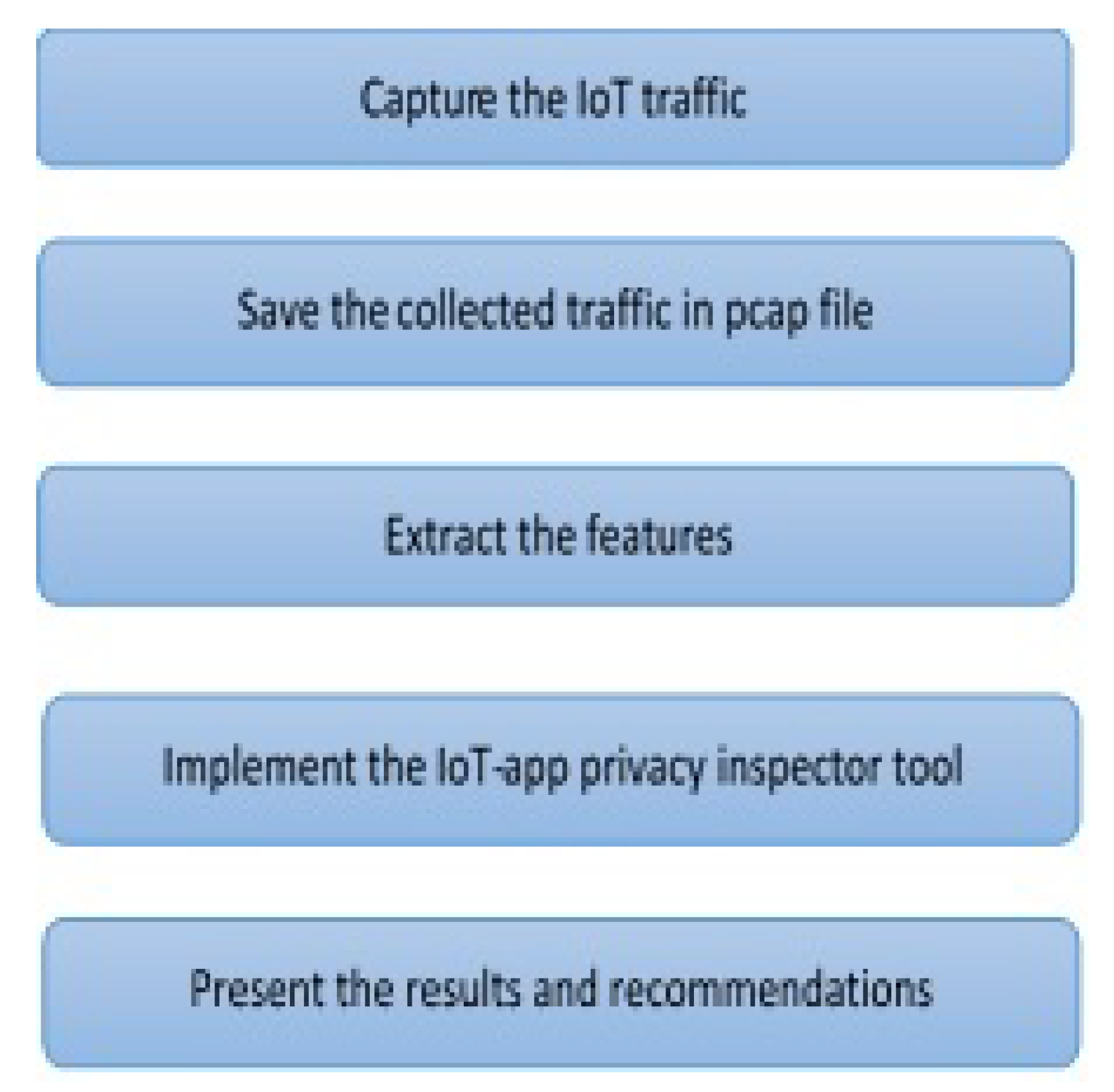
An overview of the steps of the IoT-app privacy inspector tool is outlined in
Figure 12. At first, the tool receives collected unseen IoT traffic in a pcap file format. Next, it extracts the relevant features from the pcap file as mentioned earlier (
Section 5.1.1). Three different classifiers will be applied to this dataset. Each one is used for different inferences (
Figure 11).
Unseen Validation Datasets
To evaluate the performance of our tool, we apply the trained classifiers to unseen datasets. We collect such datasets in
Section 5.1.1 to validate the classifiers. Notice that we did not include the validation dataset in the original dataset used to train our classifiers. Accordingly, we conduct two types of evaluations to evaluate the accuracy and reliability of the IoT-app privacy inspector tool.
Classification Accuracy for Each IoT-App Interaction Separately
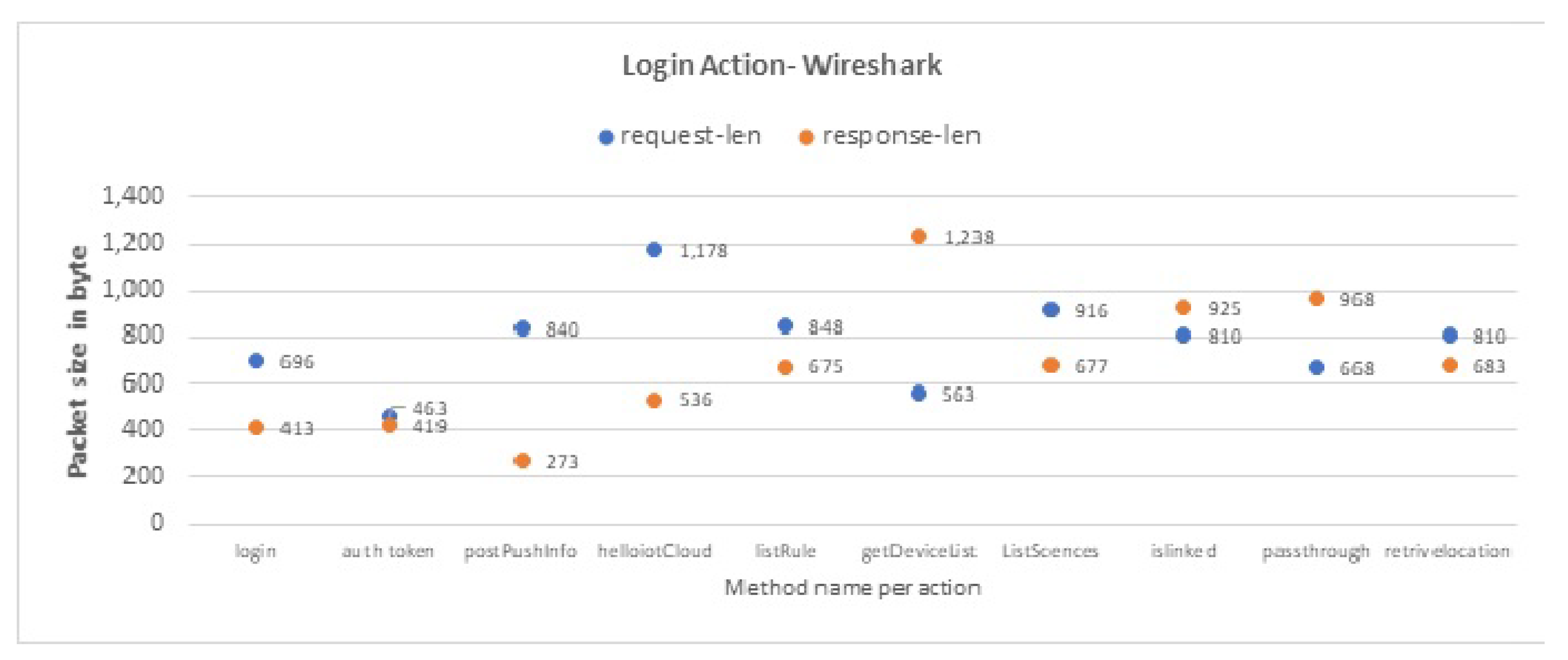
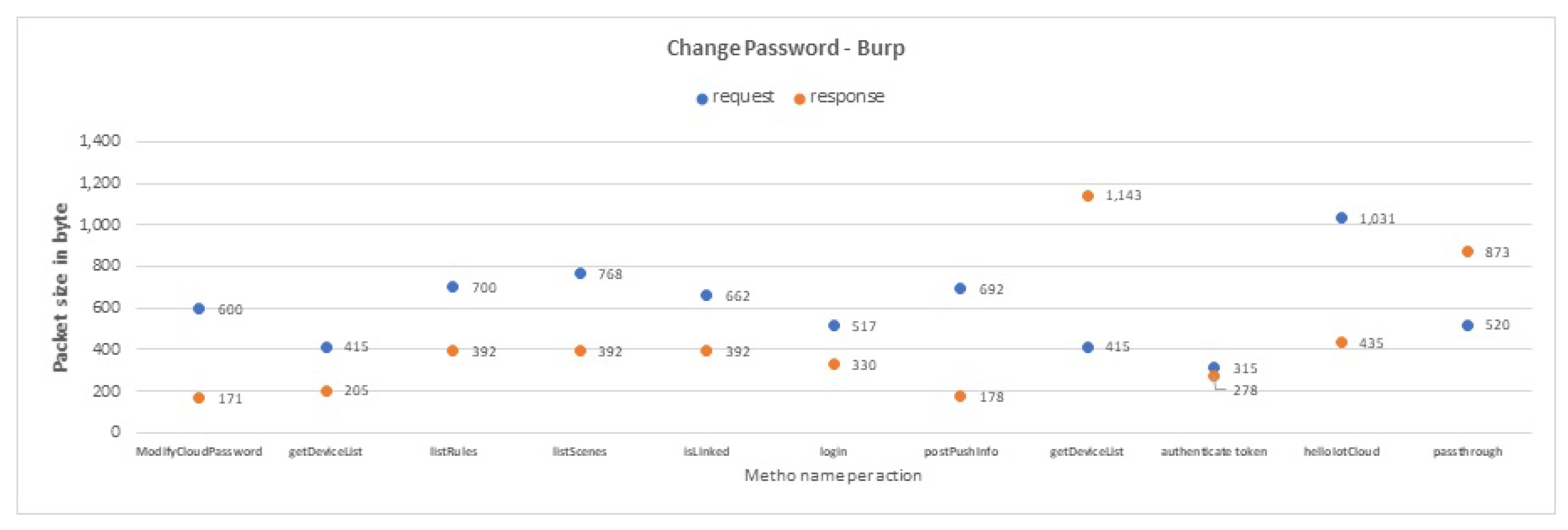
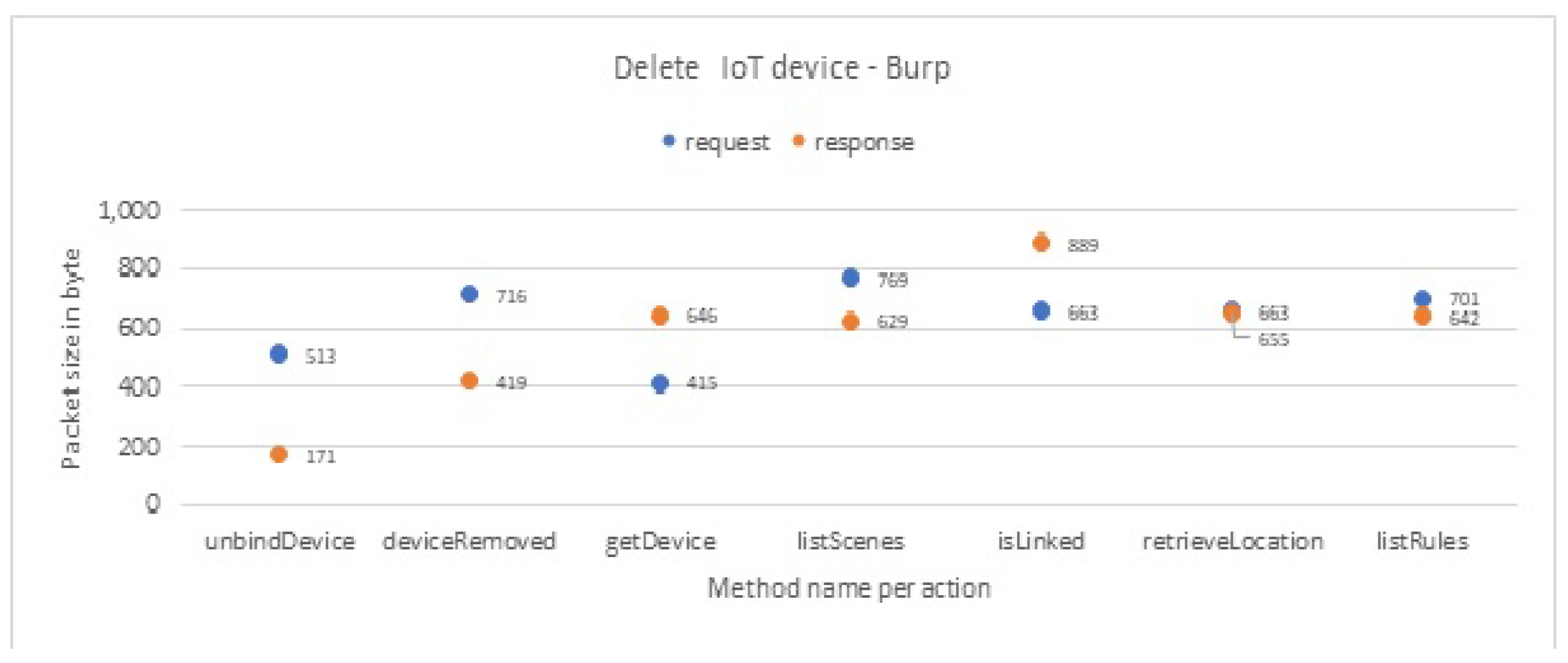
In the first evaluation experiment, we test the tool on each IoT device individually (one IoT device each time). For each IoT device, we apply the tool four times, on a collected dataset for each interaction Login, Logout, Delete, and Change Password. Thus, we apply the tool 16 times in total.
The results show that in every experiment the tool infers the correct class. We summarize and group the results from the 16 experiments according to each IoT app in
Table 9. Each row represents one user interaction and the output of the IoT-app inspector tool (the three classifiers). For example, in the first row, the IoT-app inspector tool accurately infers that when the user logs into to KASA app, only sensitive PII packets are sent to the IoT cloud. The type of these sensitive packets is user credentials and user location.
In
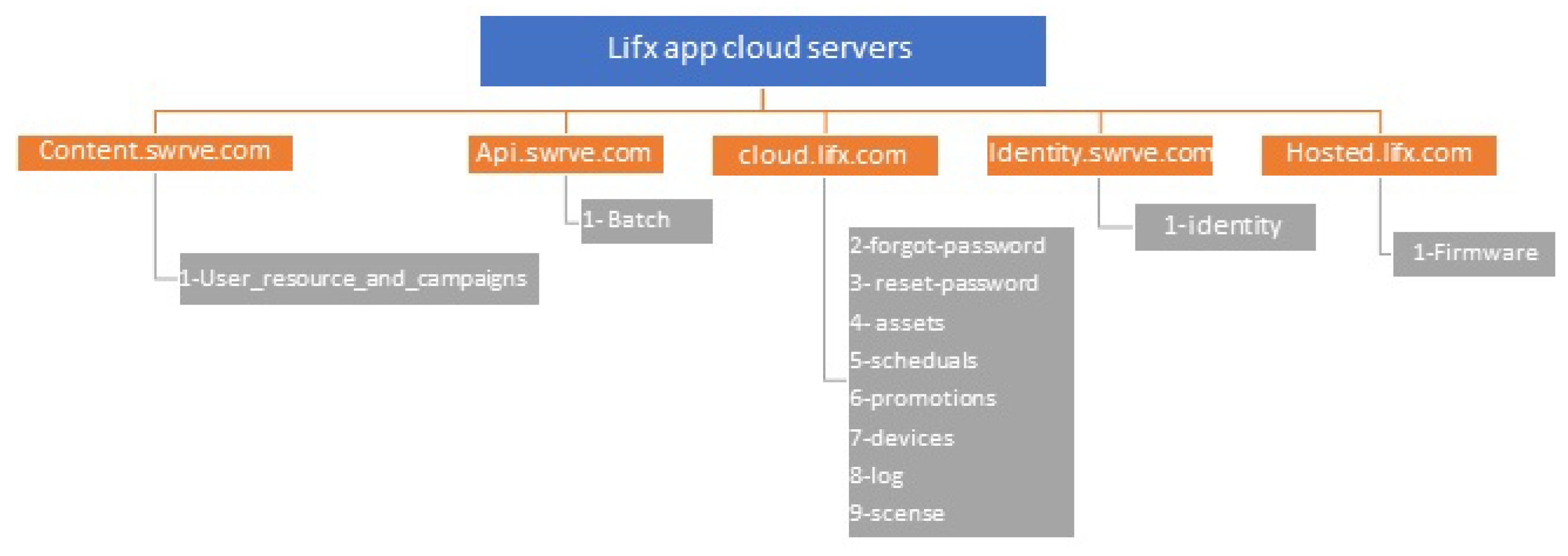
Table 10, we compare the results of all user interactions with all IoT devices. Our findings show that most interactions are similar in terms of sending sensitive PII or non-sensitive PII packets to their IoT cloud. However, we highlight three important things. First, the change-password interaction and the login interaction send both sensitive PII and non-sensitive PII packets to the IoT cloud from Lifx app. This means that Lifx app excessively sends sensitive PII packets about their user to the Lifx cloud through these two interactions. Second, logout interaction from netcam app does not send any type of sensitive packets to its IoT cloud, which makes it the safest interaction among the others. Finally, the delete interaction and the logout interaction of KASA, TpCam, and Lifx send only non-sensitive PII packets to its IoT cloud. Hence, these two interactions are seen to be the interactions that least send sensitive PII packets about the user to the IoT cloud.
Classification Accuracy with Mixed IoT Interactions in the Same File
In the second evaluation experiment, we test the tool four times on each IoT device individually (one IoT device each time). For each IoT device, we apply the tool on mixed user interactions between the IoT app and its IoT device to validate the classification accuracy by inferring the previously mentioned aims. The results presented in
Table 11 demonstrate very high classification accuracy of our three classifiers:
the average accuracy (number of correctly inferred user interactions divided by the total number of interactions) is 99.4% with F1 score 0.994;
the average accuracy (number of packets for which the level of sensitivity is correctly inferred divided by the total number of packets) is 99.8% with F1 score 0.998;
the average accuracy (number of packets for which the content of the sessions correctly inferred divided by the total number of packets) is 99.8% with F1 score 0.998.
As a result of the previous experiments, we prove the validity and reliability of such a tool. We achieve high accuracy for inferring the correct type of sensitive information, as well as for inferring the user interaction type that occurs between the IoT device and the user.
8. Conclusions
In this research, we start with the observation that there are two different ways of sending information about the IoT user to the IoT cloud: Device-to-cloud and App-to-cloud. To the best of our knowledge, no research has been done on the second way i.e., App-to-cloud. We show that any adversary who can observe and collect smart-home traffic can reveal sensitive information about the IoT user through the packet sizes and the packet sequences. For example, the adversary can infer, in real time, that a specific interaction (e.g., login to the IoT app) is occurring between the user and a smart plug via its related IoT app. In addition, the adversary can infer which packets carry sensitive information about their user, as well as the type of this information (e.g., user location or user credential).
We build a multi-class classification tool called IoT-app privacy inspector using supervised machine learning to raise the awareness of the IoT users about specific interactions that cause a violation of their privacy. For training data, we label the encrypted TLS transport-layer traffic that is being sent to the IoT cloud from the IoT app. We want the tool to be able to
classify the interaction of the user with every IoT-app (e.g., log in to/log out of the IoT-app);
classify the packets generated by the user interaction according to their sensitivity level (e.g., sensitive PII, non-sensitive PII, non-PII)
classify the content of the sensitive PII (into e.g., user credentials, user location) and the content of the non-sensitive PII (into e.g., user email, username).
We leverage the observation that the traffic generated by IoT apps follows a limited set of patterns, which allows us to perform the three classifications above. After training, this tool can be continuously applied to classify newly collected (unlabeled) IoT device traffic data.
Our tool aims to help IoT users by notifying them of any interactions that send excessive personal data to the IoT cloud e.g., when they login to the IoT app. The tool can accurately detect the TLS traffic that originates from any IoT app that controls the IoT device. Then it infers the user interaction type with the IoT app, infers whether there is any sensitive PII packet being sent to the IoT cloud and infers the type of the sensitive PII packet (e.g., user credentials). The results show that 99.4% of the user interactions with the IoT app are correctly detected, while 99.8% of the packets the carry sensitive PII caused by this interaction are correctly detected. Finally, 99.8% of the content type of this sensitive PII packets are correctly detected. The high accuracy results achieved by our tool prove the reliability of such a tool. Finally, we point out a security problem: It is possible for an attacker to identify the packet that contains the user’s password, and thus to launch an offline password cracking attack.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















