Learning to Detect Cracks on Damaged Concrete Surfaces Using Two-Branched Convolutional Neural Network

Abstract
:1. Introduction
2. Related Works
2.1. Previous Studies in Crack Detection
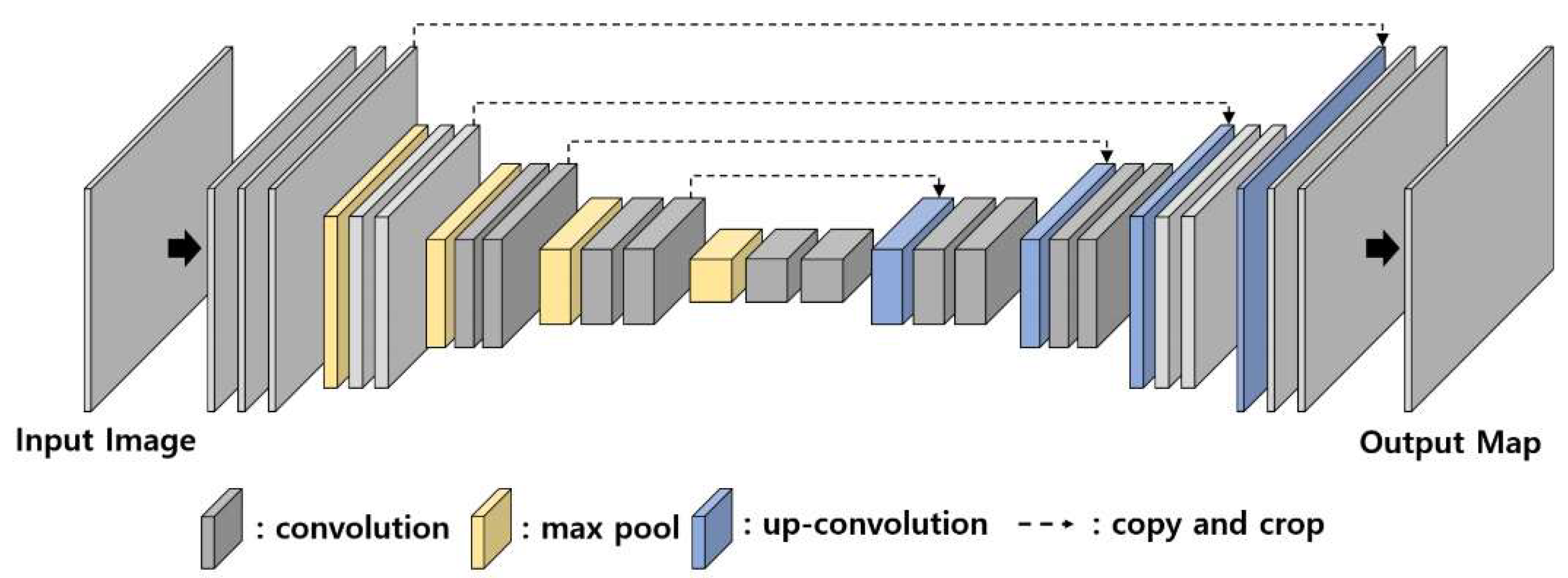
2.2. Convolution and Deconvolution Architecture in CNN
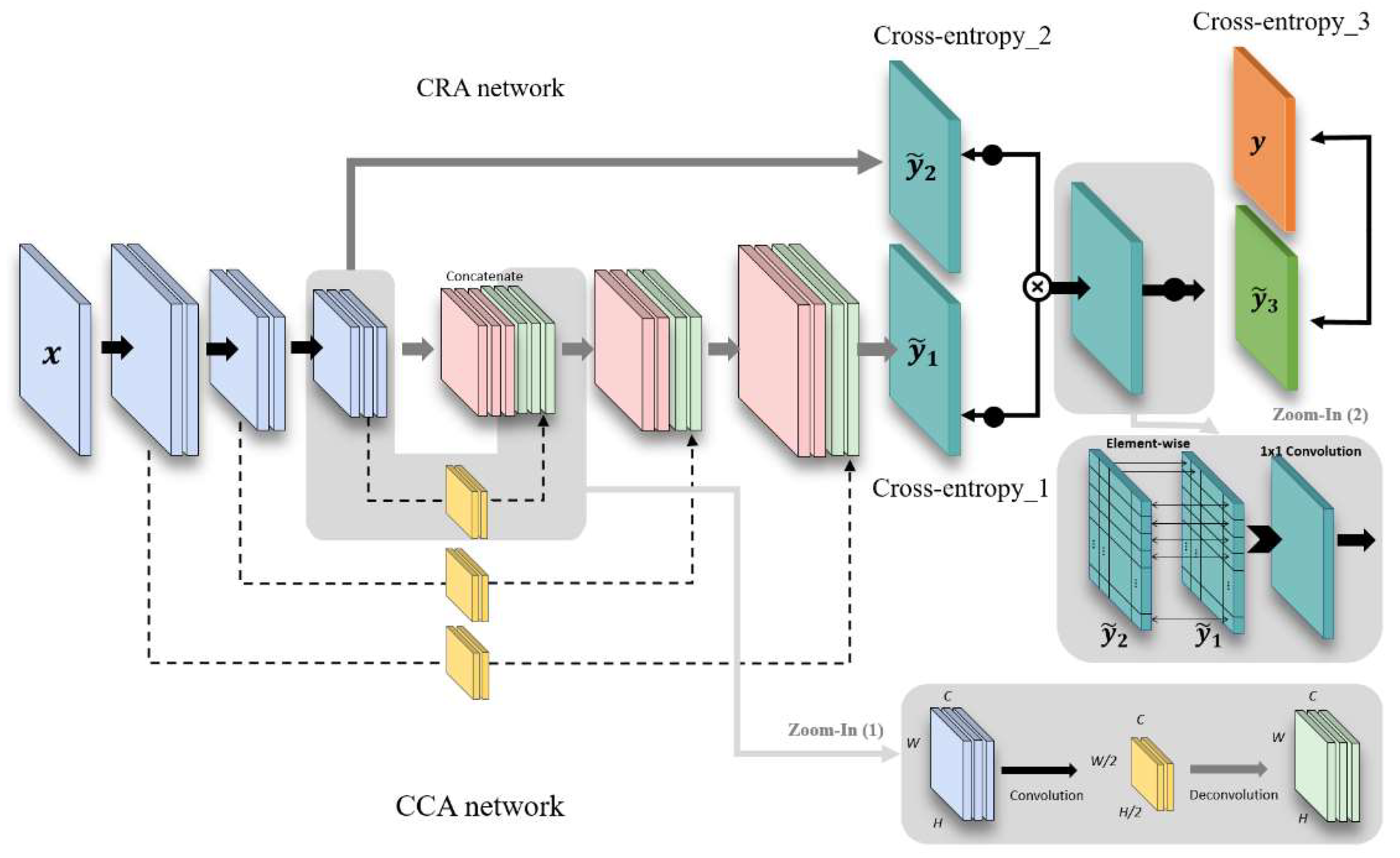
3. Proposed Crack Detection Network
3.1. Motivation
3.2. Architecture Description
3.2.1. Crack-Component-Aware Network
3.2.2. Crack-Region-Aware Network
3.2.3. Combination of CCA and CRA
4. Training
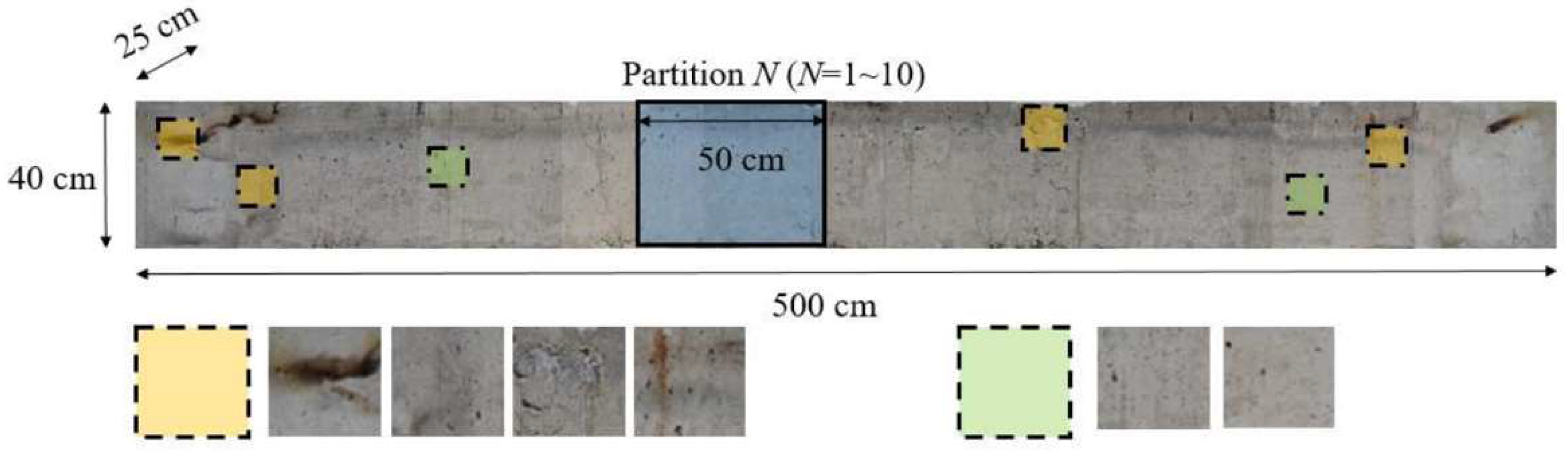
4.1. Crack Data Acquisition
4.1.1. Fire Crack Dataset (FCD)
4.1.2. Crack Forest Dataset (CFD) and AigleRN
4.2. Training Methods
4.3. Loss Function
5. Experimental Result
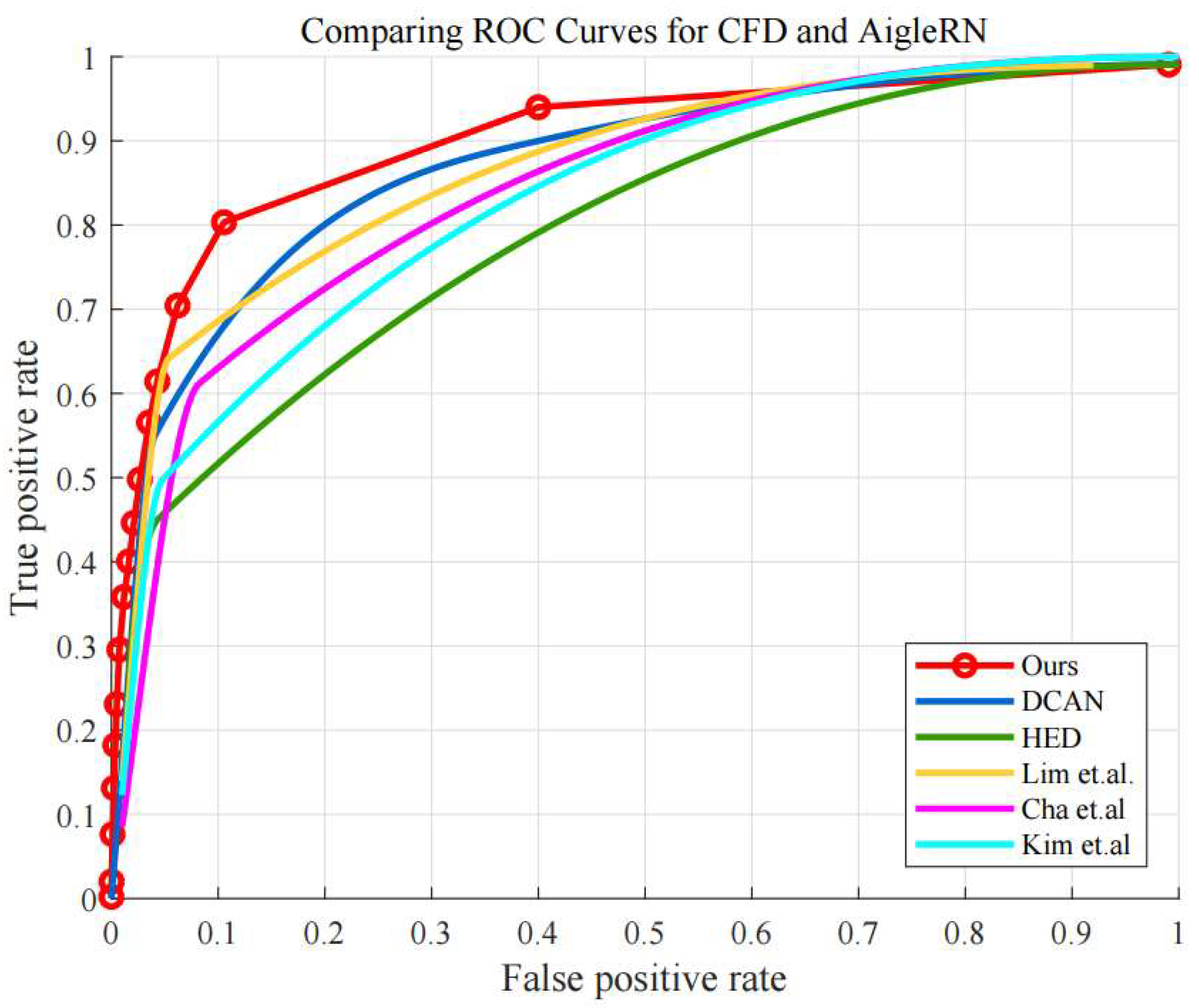
5.1. Performance Comparisons for Crack Detection
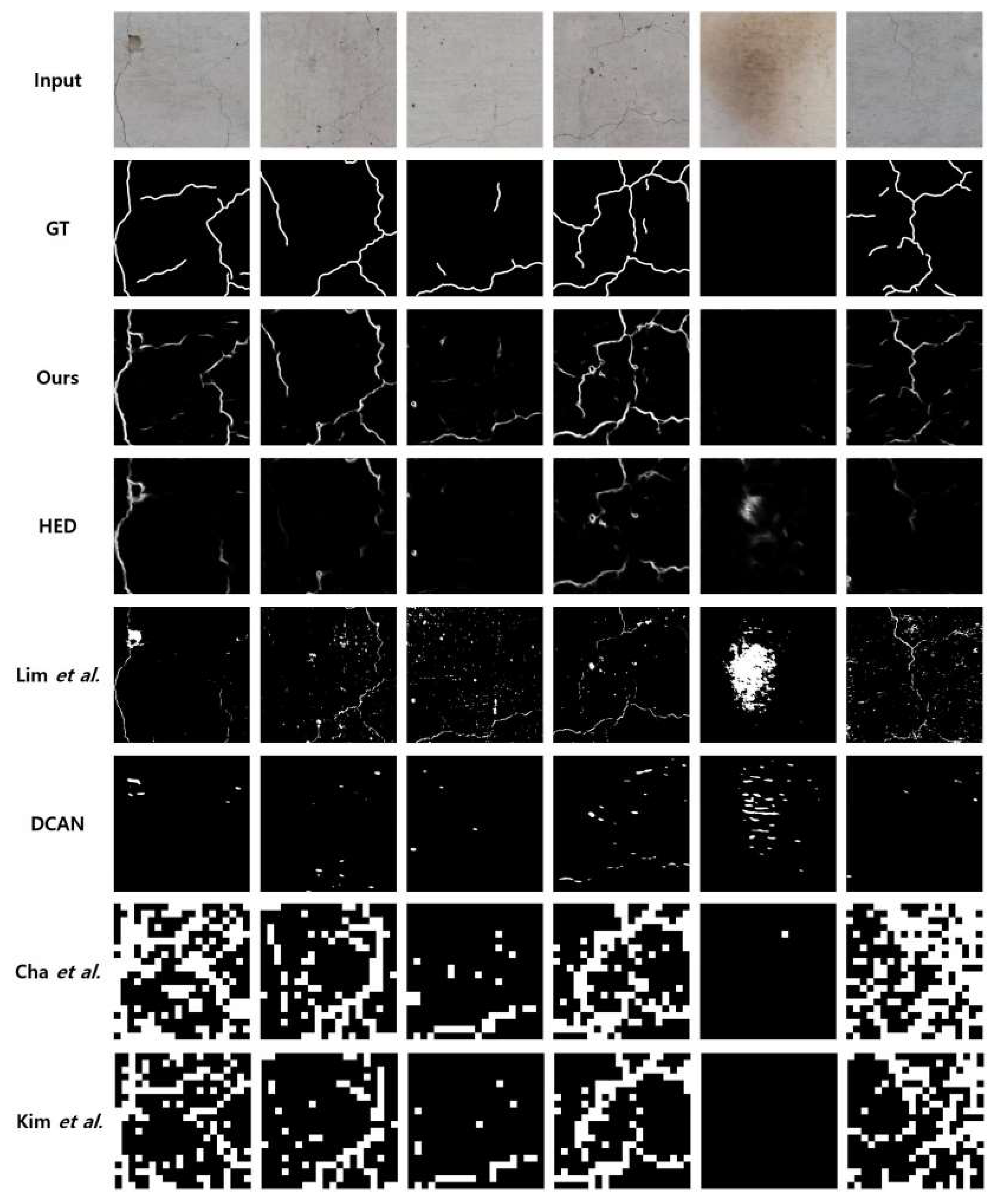
5.2. Visual Comparisons for Crack Detection
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; Hung, M.L.; Lim, R.S.; Parvardeh, H. Automated crack detection on concrete bridges. IEEE Trans. Autom. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Chen, F.-C.; Jahanshahi, M.R. Nb-cnn: Deep learning-based crack detection using convolutional neural network and naive bayes data fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Makantasis, K.; Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Loupos, C. Deep convolutional neural networks for efficient vision based tunnel inspection. In Proceedings of the 2015 IEEE International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2015. [Google Scholar]
- Korea Concrete Institute. Korea Structural Concrete Design Code 2012; English & Korean; Korea Concrete Institute: Seoul, Korea, 2012. [Google Scholar]
- Noh, Y.; Koo, D.; Kang, Y.-M.; Park, D.; Lee, D. Automatic crack detection on concrete images using segmentation via fuzzy c-means clustering. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017. [Google Scholar]
- Youm, M.; Yun, H.; Jung, T.; Lee, G. High-speed crack detection of structure by computer vision. In Proceedings of the KSCE 2015 Convention 2015 Civil Expo and Conference, Gunsan, Korea, 28–30 October 2015. [Google Scholar]
- Song, Q.; Lin, G.; Ma, J.; Zhang, H. An edge-detection method based on adaptive canny algorithm and iterative segmentation threshold. In Proceedings of the 2016 2nd International Conference on Control Science and Systems Engineering (ICCSSE), Singapore, 27–29 July 2016. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.-H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Chen, H.; Qi, X.; Yu, L.; Heng, P.-A. Dcan: Deep contour-aware networks for accurate gland segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2487–2496. [Google Scholar]
- Kim, H.; Ryu, E.; Lee, Y.; Kang, J.-W.; Lee, J. Performance evaluation of fire damaged reinforced concrete beams using machine learning. In Proceedings of the 17th International Conference on Computing in Civil and Bulding Engineering, Tampere, Finland, 5–7 June 2018. [Google Scholar]
- Song, Q.; Wu, Y.; Xin, X.; Yang, L.; Yang, M.; Chen, H.; Liu, C.; Hu, M.; Chai, X.; Li, J. Real-time tunnel crack analysis system via deep learning. IEEE Access 2019, 7, 64186–64197. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Automated vision-based detection of cracks on concrete surfaces using a deep learning technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef] [PubMed]
- Yokoyama, S.; Matsumoto, T. Development of an automatic detector of cracks in concrete using machine learning. Procedia Eng. 2017, 171, 1250–1255. [Google Scholar] [CrossRef]
- Silva, W.; Diogo, S. Concrete cracks detection based on deep learning image classification. Multidiscip. Digit. Publ. Inst. Proc. 2018, 2, 489. [Google Scholar] [CrossRef]
- Basu, M. Gaussian-based edge-detection methods—A survey. IEEE Trans. Syst. Man Cybern. 2002, 32, 252–260. [Google Scholar] [CrossRef]
- Khan, A.; Sung, J.; Kang, J.-W. Multi-channel Fusion Convolutional Neural Network to Classify Syntactic Anomaly from Language-Related ERP Components. Inf. Fusion 2019, 52, 53–61. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the MICCAI 2015, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Lim, R.S.; La, H.M.; Sheng, W. A robotic crack inspection and mapping system for bridge deck maintenance. IEEE Trans. Autom. Sci. Eng. 2014, 11, 367–378. [Google Scholar] [CrossRef]
- Cho, H.; Yoon, H.-J.; Jung, J.-Y. Image-based crack detection using crack width transform (cwt) algorithm. IEEE Access 2019, 6, 60100–60114. [Google Scholar] [CrossRef]
- Liang, S.; Jianchun, X.; Xun, Z. An algorithm for concrete crack extraction and identification based on machine vision. IEEE Access 2018, 6, 28993–29002. [Google Scholar] [CrossRef]
- Li, L.; Wang, Q.; Zhang, G.; Shi, L.; Dong, J.; Jia, P. A method of detecting the cracks of concrete undergo high-temperature. Constr. Build. Mater. 2018, 162, 345–358. [Google Scholar] [CrossRef]
- Zalama, E.; Gómez-García-Bermejo, J.; Medina, R.; Llamas, J. Road crack detection using visual features extracted by gabor filters. Comput. Aided Civ. Infrastruct. Eng. 2014, 29, 342–358. [Google Scholar] [CrossRef]
- Li, Y.; Li, H.; Wang, H. Pixel-Wise Crack Detection Using Deep Local Pattern Predictor for Robot Application. Sensors 2018, 18, 3042. [Google Scholar] [CrossRef]
- Chaudhury, S.; Nakano, G.; Takada, J.; Iketani, A. Spatial-temporal motion field analysis for pixelwise crack detection on concrete surfaces. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 336–344. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the ICML 2015, Lille, France, 6–11 July 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. Deepunet: A deep fully convolutional network for pixel-level sea-land segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef]
- Lee, J.; Kang, M.; Kang, J.-W. Ensemble of Binary Tree Structured Deep Convolutional Network for Image Classification. In Proceedings of the Asia-Pacific Signal and Information Processing Association (APSIPA), Kuala Lumpur, Malaysia, 12–15 December 2017. [Google Scholar]
- Mun, Y.J.; Kang, J.-W. Ensemble of Random Binary Output Encoding for Adversarial Robustness. IEEE Access 2019, 7, 124632–124640. [Google Scholar] [CrossRef]
- Islam, M.; Sohaib, M.; Kim, J.; Kim, J. Crack Classification of a Pressure Vessel Using Feature Selection and Deep Learning Methods. Sensors 2018, 18, 4379. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. Automatic crack detection on two-dimensional pavement images: An algorithm based on minimal path selection. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2718–2729. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Fatigue crack detection using unmanned aerial systems in fracture critical inspection of steel bridges. J. Bridge Eng. 2018, 23, 04018078. [Google Scholar] [CrossRef]
- Martin, D.; Fowlke, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, H.; Hintton, G.E. (Eds.) ImageNet Classification with Deep Convolutional Neural Networks; NIPS: Lake Tahoe, CA, USA, 2012. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Dorafshan, S.; Thomas, R.; Maguire, M. SDNET2018: An annotated image dataset for non-contact concrete crack detection using deep convolutional neural networks. Data Brief 2018, 1664–1668. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Kernel Size | Stride | Feature Map |
|---|---|---|---|
| Conv1_1 | 3 | 1 | 512 × 512 × 64 |
| Conv1_2 | |||
| Pool1 | 2 | 2 | 256 × 256 × 64 |
| Conv2_1 | 3 | 1 | 256 × 256 × 128 |
| Conv2_2 | |||
| Pool2 | 2 | 2 | 128 × 128 × 128 |
| Conv3_1 | 3 | 1 | 128 × 128 × 256 |
| Conv3_2 | |||
| Conv3_3 | |||
| Pool3 | 2 | 2 | 64 × 64 × 256 |
| Deconv1 | 4 | 2 | 128 × 128 × 128 |
| Deconv2 | 4 | 2 | 256 × 256 × 64 |
| Deconv3 | 4 | 2 | 512 × 512 × 32 |
| 1×1 Conv | 1 | 1 | 512 × 512 × 1 |
| Cross-entropy | 1 | 1 | 512 × 512 × 1 |
| Layer | Kernel Size | Stride | Feature Map |
|---|---|---|---|
| Conv1_1 | 3 | 1 | 512 × 512 × 64 |
| Conv1_2 | |||
| Pool1 | 2 | 2 | 256 × 256 × 64 |
| Conv2_1 | 3 | 1 | 256 × 256 × 128 |
| Conv2_2 | |||
| Pool2 | 2 | 2 | 128 × 128 × 128 |
| Conv3_1 | 3 | 1 | 128 × 128 × 256 |
| Conv3_2 | |||
| Conv3_3 | |||
| Pool3 | 2 | 2 | 64 × 64 × 256 |
| Deconv1 | 16 | 8 | 512 × 512 × 128 |
| 1×1 Conv | 1 | 1 | 512 × 512 × 1 |
| Cross-entropy | 1 | 1 | 512 × 512 × 1 |
| Precision | Recall | F-measure | AUC | |
|---|---|---|---|---|
| Ours | 0.749 | 0.753 | 0.751 | 0.904 |
| HED | 0.774 | 0.655 | 0.709 | 0.779 |
| DCAN | 0.746 | 0.137 | 0.231 | 0.602 |
| Lim et al. | 0.471 | 0.173 | 0.253 | 0.617 |
| Cha et al. | 0.212 | 0.983 | 0.349 | 0.626 |
| Kim et al. | 0.169 | 0.833 | 0.281 | 0.620 |
| Precision | Recall | F-measure | AUC | |
|---|---|---|---|---|
| Ours | 0.834 | 0.830 | 0.832 | 0.910 |
| HED | 0.344 | 0.502 | 0.408 | 0.795 |
| DCAN | 0.702 | 0.837 | 0.764 | 0.872 |
| Lim et al. | 0.723 | 0.791 | 0.756 | 0.867 |
| Cha et al. | 0.266 | 0.935 | 0.414 | 0.843 |
| Kim et al. | 0.244 | 0.774 | 0.371 | 0.830 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Kim, H.-S.; Kim, N.; Ryu, E.-M.; Kang, J.-W. Learning to Detect Cracks on Damaged Concrete Surfaces Using Two-Branched Convolutional Neural Network. Sensors 2019, 19, 4796. https://doi.org/10.3390/s19214796
Lee J, Kim H-S, Kim N, Ryu E-M, Kang J-W. Learning to Detect Cracks on Damaged Concrete Surfaces Using Two-Branched Convolutional Neural Network. Sensors. 2019; 19(21):4796. https://doi.org/10.3390/s19214796
Chicago/Turabian StyleLee, Jieun, Hee-Sun Kim, Nayoung Kim, Eun-Mi Ryu, and Je-Won Kang. 2019. "Learning to Detect Cracks on Damaged Concrete Surfaces Using Two-Branched Convolutional Neural Network" Sensors 19, no. 21: 4796. https://doi.org/10.3390/s19214796
APA StyleLee, J., Kim, H. -S., Kim, N., Ryu, E. -M., & Kang, J. -W. (2019). Learning to Detect Cracks on Damaged Concrete Surfaces Using Two-Branched Convolutional Neural Network. Sensors, 19(21), 4796. https://doi.org/10.3390/s19214796