EEG-Based Multi-Modal Emotion Recognition using Bag of Deep Features: An Optimal Feature Selection Approach

 , , , , ,
, , , , ,
Abstract
:1. Introduction
2. Materials
2.1. SEED Dataset
2.2. DEAP Dataset
2.3. Electrode to Channel Mapping
3. Methodology
3.1. Time Frequency Representation
Contineous Wavelet Transform
3.2. Feature Extraction
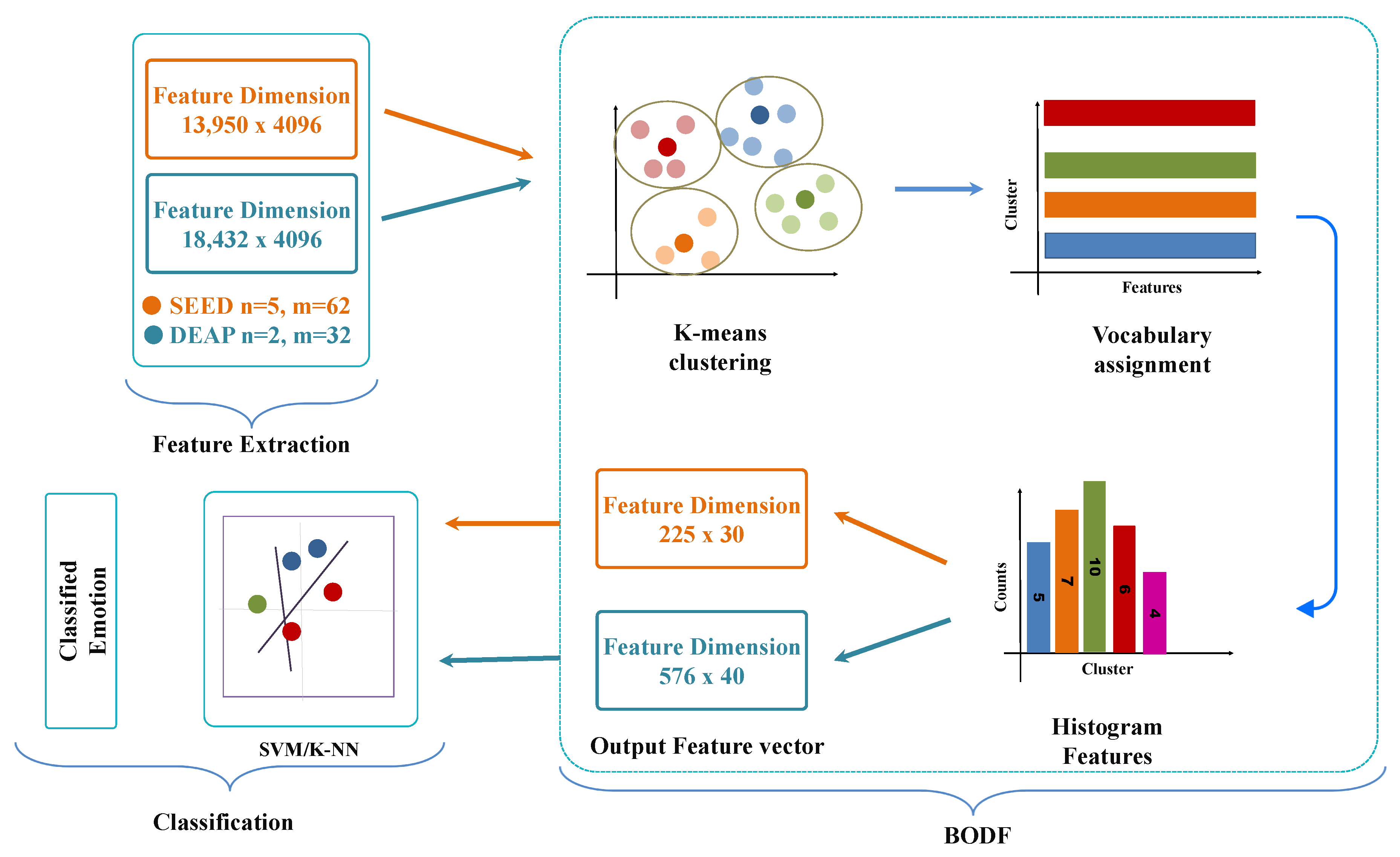
3.3. Bag of Deep Features (BoDF)
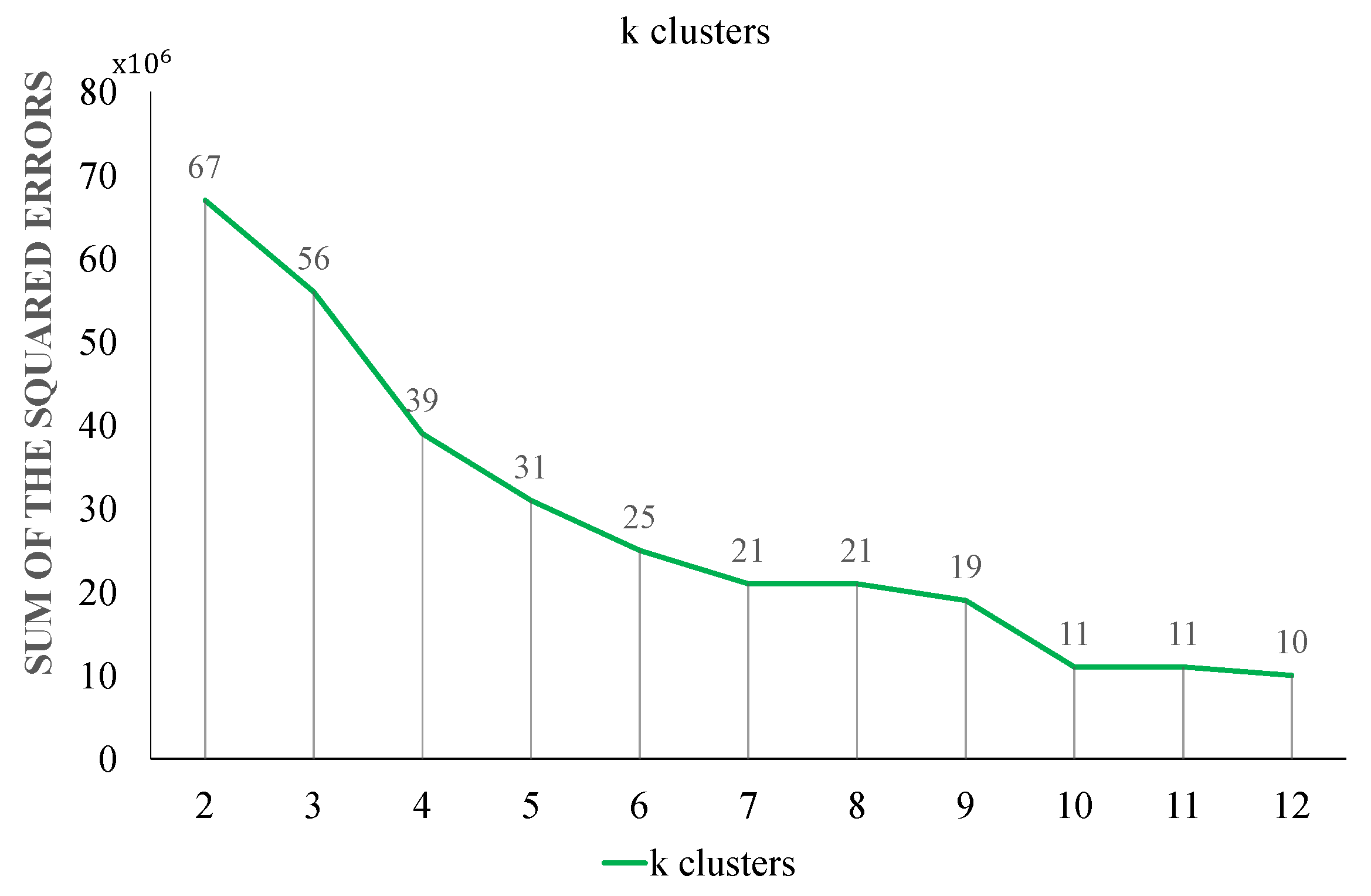
3.3.1. Stage 1: k-Mean Clustering
3.3.2. Stage 2: Histogram Features
3.4. Classification
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tarnowski, P.; Kołodziej, M.; Majkowski, A.; Rak, R.J. Combined analysis of GSR and EEG signals for emotion recognition. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujście, Poland, 9–12 May 2018; pp. 137–141. [Google Scholar]
- Faust, O.; Hagiwara, Y.; Hong, T.J.; Lih, O.S.; Acharya, U.R. Deep learning for healthcare applications based on physiological signals: A review. Comput. Methods Progr. Biomed. 2018, 161, 1–13. [Google Scholar] [CrossRef]
- Tripathi, S.; Beigi, H. Multi-Modal Emotion recognition on IEMOCAP Dataset using Deep Learning. arXiv 2018, arXiv:1804.05788. [Google Scholar]
- Hao, C.; Liang, D.; Yongli, L.; Baoyun, L. Emotion Recognition from Multiband EEG Signals Using CapsNet. Sensors 2019, 19, 2212. [Google Scholar] [CrossRef]
- Anagnostopoulos, C.-N.; Iliou, T.; Giannoukos, I. Features and classifiers for emotion recognition from speech: A survey from 2000 to 2011. Artif. Intell. Rev. 2015, 43, 155–177. [Google Scholar] [CrossRef]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-End Multimodal Emotion Recognition Using Deep Neural Networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef]
- Aloise, F.; Aricò, P.; Schettini, F.; Salinari, S.; Mattia, D.; Cincotti, F. Asynchronous gaze-independent event-related potential-based brain-computer interface. Artif. Intell. Med. 2013, 59, 61–69. [Google Scholar] [CrossRef] [PubMed]
- Aric, P.; Borghini, G.; di Flumeri, G.; Sciaraffa, N.; Babiloni, F. Passive BCI beyond the lab: Current trends and future directions. Physiol. Meas. 2018, 39, 08TR02. [Google Scholar] [CrossRef]
- Di Flumeri, G.; Aricò, P.; Borghini, G.; Sciaraffa, N.; Maglione, A.G.; Rossi, D.; Modica, E.; Trettel, A.; Babiloni, F.; Colosimo, A.; et al. EEG-based Approach-Withdrawal index for the pleasantness evaluation during taste experience in realistic settings. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Seogwipo, Korea, 11–15 July 2017; pp. 3228–3231. [Google Scholar]
- Aricò, P.; Borghini, G.; di Flumeri, G.; Bonelli, S.; Golfetti, A.; Graziani, I.; Pozzi, S.; Imbert, J.; Granger, G.; Benhacene, R.; et al. Human Factors and Neurophysiological Metrics in Air Traffic Control: A Critical Review. IEEE Rev. Biomed. Eng. 2017, 10, 250–263. [Google Scholar] [CrossRef]
- Lotte, F.; Guan, C. Regularizing common spatial patterns to improve BCI designs: Unified theory and new algorithms. IEEE Trans. Biomed. Eng. 2010, 58, 355–362. [Google Scholar] [CrossRef]
- Coogan, G.; He, B. Brain-computer interface control in a virtual reality environment and applications for the Internet of things. IEEE Access 2018, 6, 840–849. [Google Scholar] [CrossRef]
- Song, L.; Epps, J. Classifying EEG for brain-computer interface: Learning optimal filters for dynamical system features. Comput. Intell. Neurosci. 2007, 2007, 57180. [Google Scholar] [CrossRef] [PubMed]
- Sadiq, T.; Yu, X.; Yuan, Z.; Fan, Z.; Rehman, A.U.; Li, G.; Xiao, G. Motor imagery EEG signals classification based on mode amplitude and frequency components using empirical wavelet transform. IEEE Access 2019, 7, 678–692. [Google Scholar] [CrossRef]
- Mert, A.; Akan, A. Emotion recognition from EEG signals by using multivariate empirical mode decomposition. Pattern Anal. Appl. 2018, 21, 81–89. [Google Scholar] [CrossRef]
- Kevric, J.; Subasi, A. Comparison of signal decomposition methods in classification of EEG signals for motor-imagery BCI system. Biomed. Signal Process. Control 2017, 31, 398–406. [Google Scholar] [CrossRef]
- Gupta, V.; Chopda, M.D.; Pachori, R.B. Cross-Subject Emotion Recognition Using Flexible Analytic Wavelet Transform From EEG Signals. IEEE Sens. J. 2019, 19, 2266–2274. [Google Scholar] [CrossRef]
- Zangeneh Soroush, M.; Maghooli, K.; Setarehdan, S.K.; Motie Nasrabadi, A. Emotion classification through nonlinear EEG analysis using machine learning methods. Int. Clin. Neurosci. J. 2018, 5, 135–149. [Google Scholar] [CrossRef]
- Kroupi, E.; Yazdani, A.; Ebrahimi, T. EEG correlates of different emotional states elicited during watching music videos. In Affective Computing and Intelligent Interaction; Springer: Berlin/Heidelberg, Germany, 2011; pp. 457–466. [Google Scholar]
- Nie, D.; Wang, X.-W.; Shi, L.-C.; Lu, B.-L. EEG-based emotion recognition during watching movies. In Proceedings of the 2011 5th international IEEE/EMBS Conference on Neural Engineering (NER), Cancun, Mexico, 27 April–1 May 2011; pp. 667–670. [Google Scholar]
- Schaaff, K.; Schultz, T. Towards emotion recognition from electroencephalographic signals. In Proceedings of the 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–6. [Google Scholar]
- Zhang, S.; Zhao, Z. Feature selection filtering methods for emotion recognition in Chinese speech signal. In Proceedings of the 2008 9th International Conference on Signal Processing, Beijing, China, 26–29 October 2008; pp. 1699–1702. [Google Scholar]
- Nakisa, B.; Rastgoo, M.N.; Tjondronegoro, D.; Chandran, V. Evolutionary computation algorithms for feature selection of EEG-based emotion recognition using mobile sensors. Expert Syst. Appl. 2018, 93, 143–155. [Google Scholar] [CrossRef]
- Zhang, T.; Zheng, W.; Cui, Z.; Zong, Y.; Li, Y. Spatial-Temporal Recurrent Neural Network for Emotion Recognition. IEEE Trans. Cybern. 2019, 49, 839–847. [Google Scholar] [CrossRef]
- Duan, R.; Zhu, J.; Lu, B. Differential Entropy Feature for EEG-based Emotion Classification. In Proceedings of the 6th International IEEE EMBS Conference on Neural Engineering (NER), San Diego, CA, USA, 6–8 November 2013; pp. 81–84. [Google Scholar]
- Li, X.; Song, D.; Zhang, P.; Zhang, Y.; Hou, Y.; Hu, B. Exploring EEG features in cross-subject emotion recognition. Front. Neurosci. 2018, 12, 162. [Google Scholar] [CrossRef]
- Jirayucharoensak, S.; Panngum, S.; Israsena, P. EEG-based emotion recognition using deep learning network with principal component based covariate shift adaptation. Sci. World J. 2014, 2014, 627892. [Google Scholar] [CrossRef]
- Liu, W.; Zheng, W.L.; Lu, B.L. Emotion Recognition Using Multimodal Deep Learning. In Proceedings of the 23rd International Conference onNeural Information Processing, Kyoto, Japan, 16–21 October 2016; pp. 521–529. [Google Scholar]
- Yang, B.; Han, X.; Tang, J. Three class emotions recognition based on deep learning using staked autoencoder. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017. [Google Scholar]
- Thammasan, N.; Moriyama, K.; Fukui, K.; Numao, M. Continuous music-emotion recognition based on electroencephalogram. IEICE Trans. Inf. Syst. 2016, 99, 1234–1241. [Google Scholar] [CrossRef]
- Jie, X.; Cao, R.; Li, L. Emotion recognition based on the sample entropy of EEG. Bio-Med. Mater. Eng. 2014, 24, 1185. [Google Scholar]
- Liu, Y.J.; Yu, M.; Zhao, G.; Song, J.; Ge, Y.; Shi, Y. Real-time movie-induced discrete emotion recognition from EEG signals. IEEE Trans. Affect. Comput. 2017, 9, 550–562. [Google Scholar] [CrossRef]
- Zheng, W.-L.; Lu, B.-L. Investigating Critical Frequency Bands and Channels for EEG-based Emotion Recognition with Deep Neural Networks. IEEE Trans. Auton. Ment. Dev. (IEEE TAMD) 2015, 7, 162–175. [Google Scholar] [CrossRef]
- Koelstra, S.; Muehl, C.; Soleymani, M.; Lee, J.-S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- García-Martínez, B.; Martinez-Rodrigo, A.; Alcaraz, R.; Fernández-Caballero, A. A Review on Nonlinear Methods Using Electroencephalographic Recordings for Emotion Recognition. IEEE Trans. Affect. Comput. 2019. [Google Scholar] [CrossRef]
- Morris, J.D. SAM. The Self-Assessment Manikin an Efficient Cross-Cultural Measurement of Emotional Response. Advert. Res. 1995, 35, 63–68. [Google Scholar]
- Li, X.; Zhang, P.; Song, D.W.; Yu, G.L.; Hou, Y.X.; Hu, B. EEG Based Emotion Identification Using Unsupervised Deep Feature Learning. In Proceedings of the SIGIR2015Workshop on Neuro-Physiological Methods in IR Research, Santiago, Chile, 13 August 2015. [Google Scholar]
- Naser, D.S.; Saha, G. Classification of emotions induced by music videos and correlation with participants’ rating. Expert Syst. Appl. 2014, 41, 6057–6065. [Google Scholar]
- Naser, D.S.; Saha, G. Recognition of emotions induced by music videos using DT-CWPT. In Proceedings of the IEEE Indian Conference on Medical Informatics and Telemedicine (ICMIT), Kharagpur, India, 28–30 March 2013; pp. 53–57. [Google Scholar]
- Chung, S.Y.; Yoon, H.J. An effective classification using Bayesian classifier and supervised learning. In Proceedings of the 2012 12th International Conference on Control, Automation and Systems, Je Ju Island, Korea, 17–21 October 2012; pp. 1768–1771. [Google Scholar]
- Wang, D.; Shang, Y. Modeling Physiological Data with Deep Belief Networks. Int. J. Inf. Educ. Technol. 2013, 3, 505–511. [Google Scholar]
- Homan, R.; Herman, J.P.; Purdy, P. Cerebral location of international 10–20 system electrode placement. Electroencephalogr. Clin. Neurophysiol. 1987, 664, 376–382. [Google Scholar] [CrossRef]
- Vuong, A.K.; Zhang, J.; Gibson, R.L.; Sager, W.W. Application of the two-dimensional continuous wavelet transforms to imaging of the Shatsky Rise plateau using marine seismic data. Geol. Soc. Am. Spec. Pap. 2015, 511, 127–146. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Xie, C.; Shao, Y.; Li, X.; He, Y. Detection of early blight and late blight diseases on tomato leaves using hyperspectral imaging. Sci. Rep. 2015, 5, 16564. [Google Scholar] [CrossRef] [PubMed]
- O’Hara, S.; Draper, B.A. Introduction to the Bag of Features Paradigm for Image Classification and Retrieval. arXiv 2011, arXiv:1101.3354. [Google Scholar]
- Elazary, L.; Itti, L. Interesting objects are visually salient. J. Vis. 2008, 8, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; AAAI Press: Menlo Park, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Tsai, C.-F.; Hsu, Y.-F.; Lin, C.-Y.; Lin, W.-Y. Intrusion detection by machine learning: A review. Expert Syst. Appl. 2009, 36, 11994–12000. [Google Scholar] [CrossRef]
- Li, M.; Xu, H.P.; Liu, X.W.; Lu, S.F. Emotion recognition from multichannel EEG signals using K-nearest neighbor classification. Technol. Health Care 2018, 29, 509–519. [Google Scholar] [CrossRef]
- Wichakam, I.; Vateekul, P. An evaluation of feature extraction in EEG-based emotion prediction with support vector machines. In Proceedings of the 11th international Joint Conference on Computer Science and Software Engineering, Chon Buri, Thailand, 14–16 May 2014. [Google Scholar]
- Palaniappan, R.; Sundaraj, K.; Sundaraj, S. A comparative study of the SVM and K-nn machine learning algorithms for the diagnosis of respiratory pathologies using pulmonary acoustic signals. BMC Bioinform. 2014, 27, 223. [Google Scholar] [CrossRef] [Green Version]
- Hmeidi, I.; Hawashin, B.; El-Qawasmeh, E. Performance of KNN and SVM classifiers on full word Arabic articles. Adv. Eng. Inf. 2008, 22, 106–111. [Google Scholar] [CrossRef]
- Pan, F.; Wang, B.; Hu, X.; Perrizo, W. Comprehensive vertical sample-based KNN/LSVM classification for gene expression analysis. J. Biomed. Inform. 2004, 37, 240–248. [Google Scholar] [CrossRef] [Green Version]
- Khandoker, A.H.; Lai DT, H.; Begg, R.K.; Palaniswami, M. Wavelet-based feature extraction for support vector machines for screening balance impairments in the elderly. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 587–597. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
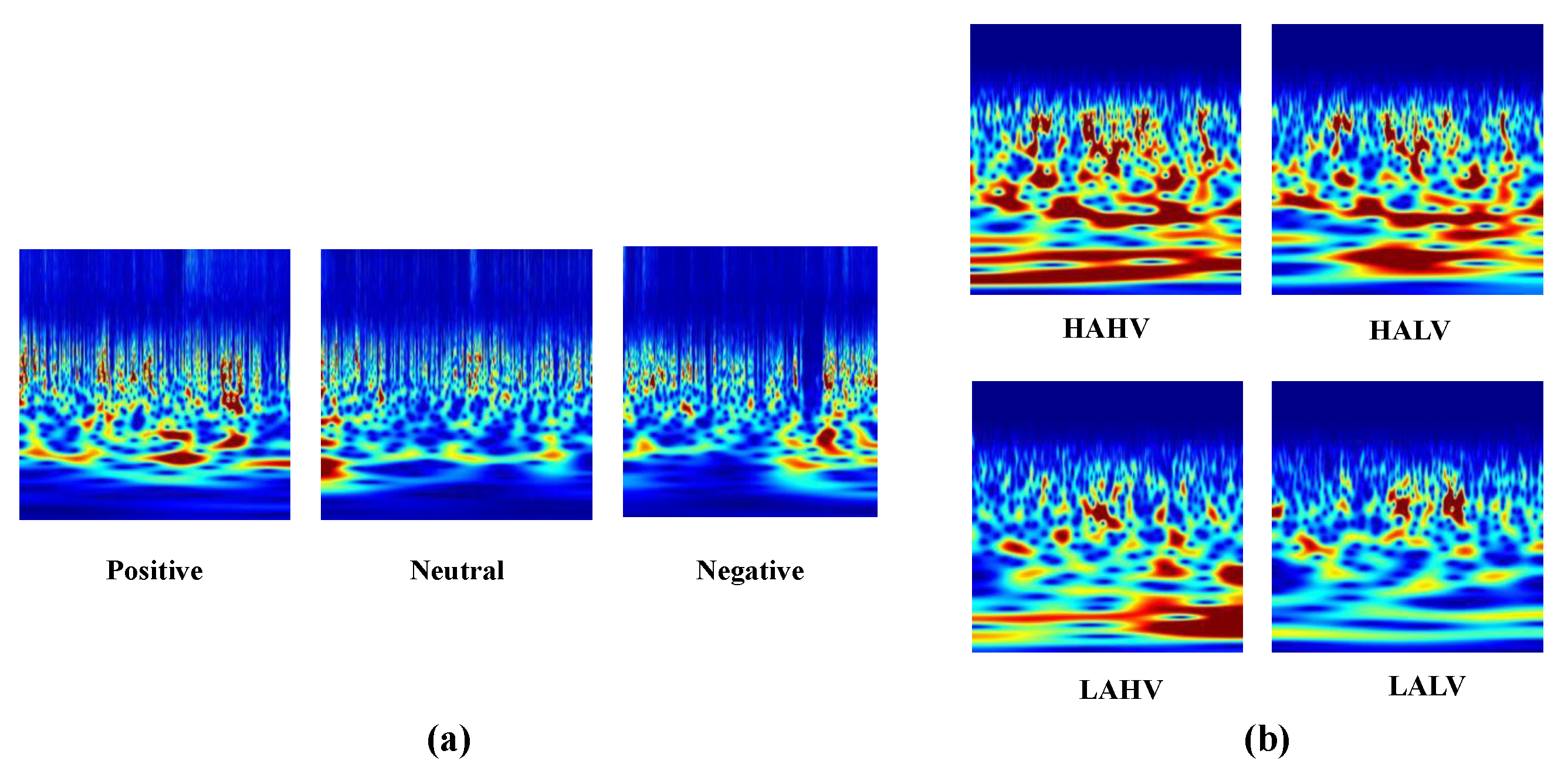
| No. | Emotion Label | Film Clip Source |
|---|---|---|
| 1 | Negative | Tangshan Earthquake |
| 2 | Negative | 1942 |
| 3 | Positive | Lost in Thailand |
| 4 | Positive | Flirting scholar |
| 5 | Positive | Just another Pandora’s Box |
| 6 | Neutral | World Heritage in Chine |
| No. | Emotion Label | States |
|---|---|---|
| 1 | LAHV (Low Arousal High Valence) | Alert |
| 2 | HALV (High Arousal Low Valence) | Calm |
| 3 | HAHV (High Arousal High Valence) | Happy |
| 4 | LALV (Low Arousal Low Valence) | Sad |
| Classifier | SEED | DEAP | ||
|---|---|---|---|---|
| k Value | Accuracy | k Value | Accuracy | |
| SVM | 10 | 93.8 | 10 | 77.4 |
| 8 | 92.6 | 8 | 76.3 | |
| 6 | 92.4 | 6 | 76.1 | |
| 4 | 91.8 | 4 | 75.3 | |
| 2 | 90.9 | 2 | 75.1 | |
| k-NN | 10 | 91.4 | 10 | 73.6 |
| 8 | 90.2 | 8 | 71.1 | |
| 6 | 87.4 | 6 | 69.8 | |
| 4 | 87.1 | 4 | 68.5 | |
| 2 | 86.6 | 2 | 67.3 | |
| Ref. | Features | Dataset | Number of Channels | Classifier | Accuracy (%) |
|---|---|---|---|---|---|
| [3] | MOCAP | IMOCAP | 62 | CNN | 71.04 |
| [4] | MFM | DEAP | 18 | CapsNet | 68.2 |
| [17] | MFCC | SEED | 12 | SVM | 83.5 |
| Random Forest | 72.07 | ||||
| DEAP | 6 | Random Forest | 72.07 | ||
| [15] | MEMD | DEAP | 12 | ANN | 75 |
| k-NN | 67 | ||||
| [24] | STRNN | SEED | 62 | CNN | 89.5 |
| [26] | RFE | SEED | 18 | SVM | 90.4 |
| DEAP | 12 | SVM | 60.5 | ||
| [23] | DE | MAHNOB | 18 | PNN | 77.8 |
| DEAP | 32 | PNN | 79.3 | ||
| Our work | DWT-BODF | SEED | 62 | SVM | 93.8 |
| k-NN | 91.4 | ||||
| DEAP | 32 | SVM | 77.4 | ||
| k-NN | 73.6 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asghar, M.A.; Khan, M.J.; Fawad; Amin, Y.; Rizwan, M.; Rahman, M.; Badnava, S.; Mirjavadi, S.S. EEG-Based Multi-Modal Emotion Recognition using Bag of Deep Features: An Optimal Feature Selection Approach. Sensors 2019, 19, 5218. https://doi.org/10.3390/s19235218
Asghar MA, Khan MJ, Fawad, Amin Y, Rizwan M, Rahman M, Badnava S, Mirjavadi SS. EEG-Based Multi-Modal Emotion Recognition using Bag of Deep Features: An Optimal Feature Selection Approach. Sensors. 2019; 19(23):5218. https://doi.org/10.3390/s19235218
Chicago/Turabian StyleAsghar, Muhammad Adeel, Muhammad Jamil Khan, Fawad, Yasar Amin, Muhammad Rizwan, MuhibUr Rahman, Salman Badnava, and Seyed Sajad Mirjavadi. 2019. "EEG-Based Multi-Modal Emotion Recognition using Bag of Deep Features: An Optimal Feature Selection Approach" Sensors 19, no. 23: 5218. https://doi.org/10.3390/s19235218
APA StyleAsghar, M. A., Khan, M. J., Fawad, Amin, Y., Rizwan, M., Rahman, M., Badnava, S., & Mirjavadi, S. S. (2019). EEG-Based Multi-Modal Emotion Recognition using Bag of Deep Features: An Optimal Feature Selection Approach. Sensors, 19(23), 5218. https://doi.org/10.3390/s19235218