Distinguishing Emotional Responses to Photographs and Artwork Using a Deep Learning-Based Approach


Abstract
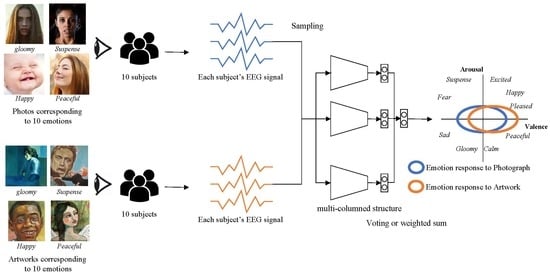
:
1. Introduction
2. Related Work
2.1. Deep Learning-Based Emotion Recognition Studies
2.1.1. Early Models
2.1.2. CNN-Based Models
2.1.3. RNN-Based Models
2.1.4. Hybrid Models
2.2. Emotional Response from Visual Contents
3. Emotion Model
3.1. Russell’s Model
3.2. Emotion Dataset Construction
3.2.1. Dataset Collection
3.2.2. Verification by Expert Group
3.2.3. Movie Clip Construction
4. Emotion Recognition Model
4.1. Multi-Column Model
4.2. Model Training
5. Experiment and Result
5.1. Experiment Setup
5.2. Experiment
- The data was downsampled to 128 Hz.
- A bandpass frequency filter from 4.0–45.0 Hz was applied.
- The EEG channels were reordered so that they all follow that of DEAP.
- The data was segmented into eighteen 60-second trials and one baseline recording.
- Detrending was performed.
5.3. Result
6. Analysis
6.1. Quantitative Analysis Through t-Test
6.2. Further Analysis
6.3. Limitation
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Excited | Happy | Pleased | Peaceful | Calm | Gloomy | Sad | Fear | Suspense | ||
|---|---|---|---|---|---|---|---|---|---|---|
| sub1 | Val. | 0.2 | 0.4 | 0.6 | 0.5 | 0.1 | −0.2 | −0.7 | −0.6 | −0.2 |
| Arou. | 0.6 | 0.5 | 0.3 | −0.2 | −0.6 | −0.6 | −0.3 | 0.2 | 0.7 | |
| sub2 | Val. | 0.15 | 0.33 | 0.58 | 0.52 | 0.12 | −0.17 | −0.75 | −0.5 | −0.15 |
| Arou. | 0.5 | 0.47 | 0.32 | −0.52 | −0.67 | −0.62 | −0.25 | 0.21 | 0.8 | |
| sub3 | Val. | 0.21 | 0.46 | 0.53 | 0.52 | 0.02 | −0.25 | −0.65 | −0.58 | −0.17 |
| Arou. | 0.71 | 0.51 | 0.28 | −0.15 | −0.7 | −0.65 | −0.27 | 0.15 | 0.65 | |
| sub4 | Val. | 0.18 | 0.42 | 0.59 | 0.51 | 0.07 | −0.21 | −0.68 | −0.62 | −0.21 |
| Arou. | 0.65 | 0.51 | 0.31 | −0.17 | −0.58 | −0.61 | −0.29 | 0.17 | 0.61 | |
| sub5 | Val. | 0.19 | 0.41 | 0.57 | 0.53 | 0.09 | −0.22 | −0.71 | −0.57 | −0.19 |
| Arou. | 0.52 | 0.49 | 0.33 | −0.17 | −0.51 | −0.62 | −0.22 | 0.16 | 0.65 | |
| sub6 | Val. | 0.22 | 0.45 | 0.59 | 0.48 | 0.05 | −0.23 | −0.75 | −0.59 | −0.18 |
| Arou. | 0.59 | 0.51 | 0.35 | −0.21 | −0.55 | −0.59 | −0.31 | 0.19 | 0.75 | |
| sub7 | Val. | 0.23 | 0.42 | 0.61 | 0.52 | 0.05 | −0.16 | −0.62 | −0.65 | −0.13 |
| Arou. | 0.63 | 0.52 | 0.32 | −0.19 | −0.53 | −0.57 | −0.25 | 0.23 | 0.67 | |
| sub8 | Val. | 0.17 | 0.3 | 0.69 | 0.52 | 0.03 | −0.12 | −0.67 | −0.59 | −0.21 |
| Arou. | 0.54 | 0.58 | 0.29 | −0.15 | −0.49 | −0.48 | −0.31 | 0.19 | 0.7 | |
| sub9 | Val. | 0.21 | 0.48 | 0.59 | 0.45 | 0.05 | −0.12 | −0.59 | −0.61 | −0.29 |
| Arou. | 0.7 | 0.55 | 0.32 | −0.25 | −0.61 | −0.55 | −0.32 | 0.21 | 0.85 | |
| sub10 | Val. | 0.2 | 0.31 | 0.51 | 0.52 | 0.05 | −0.14 | −0.59 | −0.54 | −0.21 |
| Arou. | 0.59 | 0.52 | 0.31 | −0.19 | −0.55 | −0.54 | −0.27 | 0.23 | 0.71 | |
| sub11 | Val. | 0.13 | 0.34 | 0.63 | 0.47 | 0.06 | −0.24 | −0.73 | −0.54 | −0.17 |
| Arou. | 0.59 | 0.46 | 0.33 | −0.18 | −0.59 | −0.63 | −0.30 | 0.16 | 0.76 | |
| sub12 | Val. | 0.13 | 0.29 | 0.55 | 0.49 | 0.13 | −0.21 | −0.79 | −0.48 | −0.16 |
| Arou. | 0.51 | 0.47 | 0.34 | −0.21 | −0.69 | −0.60 | −0.25 | 0.28 | 0.79 | |
| sub13 | Val. | 0.21 | 0.39 | 0.54 | 0.48 | 0.03 | −0.24 | −0.72 | −0.55 | −0.21 |
| Arou. | 0.76 | 0.48 | 0.28 | −0.15 | −0.68 | −0.59 | −0.24 | 0.14 | 0.69 | |
| sub14 | Val. | 0.21 | 0.49 | 0.55 | 0.56 | 0.02 | −0.24 | −0.74 | −0.68 | −0.26 |
| Arou. | 0.72 | 0.50 | 0.26 | −0.14 | −0.54 | −0.66 | −0.24 | 0.12 | 0.65 | |
| sub15 | Val. | 0.17 | 0.37 | 0.62 | 0.46 | 0.08 | −0.20 | −0.75 | −0.56 | −0.21 |
| Arou. | 0.46 | 0.49 | 0.39 | −0.22 | −0.46 | −0.69 | −0.26 | 0.14 | 0.64 | |
| sub16 | Val. | 0.17 | 0.39 | 0.64 | 0.50 | −0.01 | −0.18 | −0.79 | −0.59 | −0.25 |
| Arou. | 0.62 | 0.46 | 0.33 | −0.25 | −0.50 | −0.61 | −0.33 | 0.15 | 0.72 | |
| sub17 | Val. | 0.24 | 0.43 | 0.67 | 0.46 | 0.03 | −0.12 | −0.58 | −0.68 | −0.06 |
| Arou. | 0.66 | 0.51 | 0.28 | −0.20 | −0.48 | −0.54 | −0.26 | 0.23 | 0.69 | |
| sub18 | Val. | 0.16 | 0.27 | 0.63 | 0.56 | −0.01 | −0.05 | −0.72 | −0.65 | −0.17 |
| Arou. | 0.51 | 0.60 | 0.34 | −0.22 | −0.55 | −0.49 | −0.26 | 0.22 | 0.74 | |
| sub19 | Val. | 0.25 | 0.45 | 0.61 | 0.48 | 0.10 | −0.16 | −0.56 | −0.66 | −0.28 |
| Arou. | 0.75 | 0.52 | 0.27 | −0.26 | −0.62 | −0.59 | −0.37 | 0.22 | 0.73 | |
| sub20 | Val. | 0.25 | 0.29 | 0.52 | 0.54 | 0.04 | −0.14 | −0.54 | −0.53 | −0.28 |
| Arou. | 0.56 | 0.57 | 0.27 | −0.16 | −0.57 | −0.54 | −0.27 | 0.27 | 0.65 | |
| average | Val. | 0.194 | 0.385 | 0.590 | 0.504 | 0.055 | −0.180 | −0.682 | −0.589 | −0.200 |
| Arou. | 0.608 | 0.510 | 0.312 | −0.195 | −0.574 | −0.588 | −0.278 | 0.193 | 0.708 | |
| Excited | Happy | Pleased | Peaceful | Calm | Gloomy | Sad | Fear | Suspense | ||
|---|---|---|---|---|---|---|---|---|---|---|
| sub21 | Val. | 0.32 | 0.53 | 0.67 | 0.61 | 0.18 | −0.13 | −0.55 | −0.47 | −0.14 |
| Arou. | 0.67 | 0.52 | 0.31 | −0.21 | −0.61 | −0.15 | −0.28 | 0.21 | 0.59 | |
| sub22 | Val. | 0.26 | 0.42 | 0.71 | 0.69 | 0.25 | −0.1 | −0.45 | −0.45 | −0.09 |
| Arou. | 0.61 | 0.49 | 0.33 | −0.25 | −0.69 | −0.59 | −0.21 | 0.15 | 0.49 | |
| sub23 | Val. | 0.33 | 0.53 | 0.63 | 0.72 | 0.14 | −0.08 | −0.45 | −0.39 | −0.07 |
| Arou. | 0.72 | 0.49 | 0.29 | −0.13 | −0.73 | −0.49 | −0.19 | 0.2 | 0.6 | |
| sub24 | Val. | 0.21 | 0.52 | 0.69 | 0.62 | 0.19 | −0.08 | −0.47 | −0.42 | −0.1 |
| Arou. | 0.61 | 0.52 | 0.35 | −0.18 | −0.52 | −0.48 | −0.21 | 0.15 | 0.52 | |
| sub25 | Val. | 0.29 | 0.51 | 0.69 | 0.62 | 0.21 | −0.17 | −0.68 | −0.52 | −0.1 |
| Arou. | 0.59 | 0.54 | 0.34 | −0.19 | −0.55 | −0.49 | −0.15 | 0.14 | 0.55 | |
| sub26 | Val. | 0.42 | 0.61 | 0.71 | 0.55 | 0.19 | −0.1 | −0.68 | −0.17 | 0.42 |
| Arou. | 0.68 | 0.53 | 0.35 | −0.2 | −0.53 | −0.45 | −0.14 | 0.68 | 0.67 | |
| sub27 | Val. | 0.33 | 0.56 | 0.72 | 0.65 | 0.23 | −0.11 | −0.51 | −0.1 | 0.33 |
| Arou. | 0.71 | 0.54 | 0.35 | −0.21 | −0.52 | −0.49 | −0.15 | 0.59 | 0.71 | |
| sub28 | Val. | 0.29 | 0.49 | 0.75 | 0.61 | 0.1 | −0.07 | −0.5 | −0.17 | 0.29 |
| Arou. | 0.65 | 0.59 | 0.3 | −0.16 | −0.51 | −0.39 | −0.25 | 0.59 | 0.65 | |
| sub29 | Val. | 0.31 | 0.54 | 0.69 | 0.55 | 0.12 | −0.09 | −0.49 | −0.19 | 0.31 |
| Arou. | 0.78 | 0.56 | 0.34 | −0.27 | −0.62 | −0.48 | −0.21 | 0.69 | 0.78 | |
| sub30 | Val. | 0.39 | 0.48 | 0.65 | 0.72 | 0.59 | −0.29 | −0.58 | −0.27 | 0.39 |
| Arou. | 0.62 | 0.53 | 0.32 | −0.21 | −0.56 | −0.5 | −0.21 | 0.65 | 0.62 | |
| sub31 | Val. | 0.29 | 0.59 | 0.65 | 0.65 | 0.17 | −0.11 | −0.49 | −0.41 | −0.11 |
| Arou. | 0.74 | 0.56 | 0.24 | −0.20 | −0.59 | −0.43 | −0.22 | 0.23 | 0.65 | |
| sub32 | Val. | 0.26 | 0.43 | 0.71 | 0.71 | 0.23 | −0.07 | −0.38 | −0.38 | −0.13 |
| Arou. | 0.57 | 0.50 | 0.35 | −0.19 | −0.66 | −0.53 | −0.23 | 0.11 | 0.45 | |
| sub33 | Val. | 0.38 | 0.51 | 0.63 | 0.79 | 0.17 | −0.08 | −0.39 | −0.38 | −0.08 |
| Arou. | 0.70 | 0.48 | 0.36 | −0.14 | −0.71 | −0.55 | −0.15 | 0.17 | 0.59 | |
| sub34 | Val. | 0.22 | 0.50 | 0.69 | 0.64 | 0.24 | −0.07 | −0.42 | −0.46 | −0.14 |
| Arou. | 0.59 | 0.49 | 0.32 | −0.22 | −0.58 | −0.44 | −0.18 | 0.22 | 0.48 | |
| sub35 | Val. | 0.26 | 0.57 | 0.68 | 0.61 | 0.19 | −0.18 | −0.73 | −0.47 | −0.07 |
| Arou. | 0.52 | 0.49 | 0.40 | −0.20 | −0.52 | −0.48 | −0.13 | 0.09 | 0.50 | |
| sub36 | Val. | 0.37 | 0.63 | 0.77 | 0.59 | 0.24 | −0.15 | −0.64 | −0.60 | −0.20 |
| Arou. | 0.62 | 0.53 | 0.32 | −0.27 | −0.55 | −0.40 | −0.10 | 0.19 | 0.74 | |
| sub37 | Val. | 0.33 | 0.60 | 0.78 | 0.60 | 0.27 | −0.07 | −0.50 | −0.54 | −0.12 |
| Arou. | 0.71 | 0.47 | 0.28 | −0.23 | −0.55 | −0.45 | −0.11 | 0.08 | 0.55 | |
| sub38 | Val. | 0.22 | 0.50 | 0.78 | 0.65 | 0.12 | −0.11 | −0.45 | −0.37 | −0.12 |
| Arou. | 0.60 | 0.63 | 0.35 | −0.19 | −0.54 | −0.38 | −0.23 | 0.20 | 0.57 | |
| sub39 | Val. | 0.26 | 0.57 | 0.74 | 0.62 | 0.18 | −0.10 | −0.44 | −0.47 | −0.23 |
| Arou. | 0.75 | 0.63 | 0.32 | −0.32 | −0.57 | −0.53 | −0.19 | 0.24 | 0.75 | |
| sub40 | Val. | 0.33 | 0.51 | 0.69 | 0.72 | 0.63 | −0.29 | −0.62 | −0.50 | −0.29 |
| Arou. | 0.57 | 0.52 | 0.28 | −0.24 | −0.58 | −0.46 | −0.15 | 0.13 | 0.70 | |
| average | Val. | 0.304 | 0.529 | 0.701 | 0.646 | 0.232 | −0.122 | −0.521 | −0.470 | −0.145 |
| Arou. | 0.650 | 0.531 | 0.324 | −0.210 | −0.585 | −0.476 | −0.185 | 0.167 | 0.596 | |




References
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis; Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Brunner, C.; Naeem, M.; Leeb, R.; Graimann, B.; Pfurtscheller, G. Spatial filtering and selection of optimized components in four class motor imagery EEG data using independent components analysis. Pattern Recognit. Lett. 2007, 28, 957–964. [Google Scholar] [CrossRef]
- Petrantonakis, P.; Hadjileontiadis, L. Emotion recognition from EEG using higher order crossings. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 186–197. [Google Scholar] [CrossRef]
- Korats, G.; Le Cam, S.; Ranta, R.; Hamid, M. Applying ICA in EEG: Choice of the window length and of the decorrelation method. In Proceedings of the International Joint Conference on Biomedical Engineering Systems and Technologies, Vilamoura, Portugal, 1–4 February 2012; pp. 269–286. [Google Scholar]
- Duan, R.N.; Zhu, J.Y.; Lu, B.L. Differential entropy feature for EEG-based emotion classification. In Proceedings of the IEEE/EMBS Conference on Neural Engineering, San Diego, CA, USA, 6–8 November 2013; pp. 81–84. [Google Scholar]
- Jenke, R.; Peer, A.; Buss, M. Feature extraction and selection for emotion recognition from EEG. IEEE Trans. Affect. Comput. 2014, 5, 327–339. [Google Scholar] [CrossRef]
- Zheng, W. Multichannel EEG-based emotion recognition via group sparse canonical correlation analysis. IEEE Trans. Cogn. Dev. Syst. 2016, 9, 281–290. [Google Scholar] [CrossRef]
- Mert, A.; Akan, A. Emotion recognition from EEG signals by using multivariate empirical mode decomposition. Pattern Anal. Appl. 2018, 21, 81–89. [Google Scholar] [CrossRef]
- Jirayucharoensak, S.; Pan-Ngum, S.; Israsena, P. EEG-based emotion recognition using deep learning network with principal component based covariate shift adaptation. Sci. World J. 2014, 2014, 627892. [Google Scholar] [CrossRef] [Green Version]
- Khosrowabadi, R.; Chai, Q.; Kai, K.A.; Wahab, A. ERNN: A biologically inspired feedforward neural network to discriminate emotion from EEG signal. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 609–620. [Google Scholar] [CrossRef]
- Tang, Z.; Li, C.; Sun, S. Single-trial EEG classification of motor imagery using deep convolutional neural networks. Optik 2017, 130, 11–18. [Google Scholar] [CrossRef]
- Croce, P.; Zappasodi, F.; Marzetti, L.; Merla, A.; Pizzella, V.; Chiarelli, A.M. Deep Convolutional Neural Networks for Feature-Less Automatic Classification of Independent Components in Multi-Channel Electrophysiological Brain Recordings. IEEE Trans. Biom. Eng. 2019, 66, 2372–2380. [Google Scholar] [CrossRef]
- Tripathi, S.; Acharya, S.; Sharma, R.D.; Mittal, S.; Bhattacharya, S. Using deep and convolutional neural networks for accurate emotion classification on DEAP dataset. In Proceedings of the AAAI Conference on Innovative Applications, San Francisco, CA, USA, 6–9 February 2017; pp. 4746–4752. [Google Scholar]
- Salama, E.S.; El-Khoribi, R.A.; Shoman, M.E.; Shalaby, M.A.E. EEG-based emotion recognition using 3D convolutional neural networks. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 329–337. [Google Scholar] [CrossRef]
- Moon, S.-E.; Jang, S.; Lee, J.-S. Convolutional neural network approach for EEG-based emotion recognition using brain connectivity and its spatial information. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, Canada, 15–20 April 2018; pp. 2556–2560. [Google Scholar]
- Yang, H.; Han, J.; Min, K. A Multi-Column CNN Model for Emotion Recognition from EEG Signals. Sensors 2019, 19, 4736. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, J.; Wu, Y.; Feng, W.; Wang, J. Spatially Attentive Visual Tracking Using Multi-Model Adaptive Response Fusion. IEEE Access 2019, 7, 83873–83887. [Google Scholar] [CrossRef]
- Alhagry, S.; Fahmy, A.A.; El-Khoribi, R.A. Emotion recognition based on EEG using LSTM recurrent neural network. Int. J. Adv. Comput. Sci. App. 2017, 8, 355–358. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Tian, X.; Shu, L.; Xu, X.; Hu, B. Emotion Recognition from EEG Using RASM and LSTM. Commun. Comput. Inf. Sci. 2018, 819, 310–318. [Google Scholar]
- Xing, X.; Li, Z.; Xu, T.; Shu, L.; Hu, B.; Xu, X. SAE+LSTM: A New framework for emotion recognition from multi-channel EEG. Front. Nuerorobot. 2019, 13, 37. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, Q.; Qiu, M.; Wang, Y.; Chen, X. Emotion recognition from multi-channel EEG through parallel convolutional recurrent neural network. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Yoo, G.; Seo, S.; Hong, S.; Kim, H. Emotion extraction based on multi-bio-signal using back-propagation neural network. Multimed. Tools Appl. 2018, 77, 4925–4937. [Google Scholar] [CrossRef]
- Kim, J.; Kim, M. Change of Sensitivity Perception Subsequent to the Difference in Color Temperature of Light in the Image. J. Korea Des. Knowl. 2009, 10, 1–167. [Google Scholar]
- Lechner, A.; Simonoff, J.; Harrington, L. Color-emotion associations in the pharmaceutical industry: Understanding universal and local themes. Color Res. Appl. 2012, 37, 59–71. [Google Scholar] [CrossRef]
- Yang, H. Enhancing emotion using an emotion model. Int. J. Adv. Media Commun. 2014, 5, 128–134. [Google Scholar] [CrossRef]
- Russell, J. Evidence for a three-factor theory of emotions. J. Res. Pers. 1977, 11, 273–294. [Google Scholar] [CrossRef]
- BCI+: LiveAmp. Compact Wireless Amplifier for Mobile EEG Applications. BCI+ Solutions by Brain Products. Available online: bci.plus/liveamp/ (accessed on 12 December 2019).
- Klem, G.H.; Lüders, H.O.; Jasper, H.H.; Elger, C. The ten-twenty electrode system of the International Federation. The International Federation of Clinical Neurophysiology. Electroencephalogr. Clin. Neurophysiol. Suppl. 1999, 52, 3–6. [Google Scholar]








| Marker Code | Event Description | Estimated Event Length |
|---|---|---|
| 1 | start of baseline recording | (3000 ms) |
| 2 | start of video playback 1 | 60,000 ms |
| 3 | end of video playback 1 | 5000 ms |
| 4 | start of video playback 2 | 60,000 ms |
| ... | ... | ... |
| 35 | end of video playback 17 | 5000 ms |
| 36 | start of video playback 18 | 60,000 ms |
| 37 | end of video playback 18 | 5000 ms |
| 38 | end of recording | - |
| Photograph Group | Artwork Group | ||
|---|---|---|---|
| in 20 s | 10 | 12 | |
| age | in 30 s | 6 | 5 |
| in 40 s or older | 4 | 3 | |
| sum | 20 | 20 | |
| female | 9 | 10 | |
| sex | male | 11 | 10 |
| sum | 20 | 20 | |
| engineering and science | 8 | 6 | |
| social science | 7 | 8 | |
| background | art | 3 | 4 |
| other | 2 | 2 | |
| sum | 20 | 20 | |
| Excited | Happy | Pleased | Peaceful | Calm | Gloomy | Sad | Fear | Suspense | |
|---|---|---|---|---|---|---|---|---|---|
| valence | 4.59 × 10−8 | 7.89 × 10−9 | 4.66 × 10−9 | 7.79 × 10−10 | 1.45 × 10−5 | 3.70 × 10−3 | 2.24 × 10−6 | 1.58 × 10−6 | 6.33 × 10−4 |
| arousal | 1.02 × 10−1 | 1.34 × 10−1 | 2.48 × 10−1 | 2.51 × 10−1 | 6.13 × 10−1 | 6.88 × 10−8 | 4.25 × 10−8 | 7.32 × 10−2 | 3.38× 10−5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Han, J.; Min, K. Distinguishing Emotional Responses to Photographs and Artwork Using a Deep Learning-Based Approach. Sensors 2019, 19, 5533. https://doi.org/10.3390/s19245533
Yang H, Han J, Min K. Distinguishing Emotional Responses to Photographs and Artwork Using a Deep Learning-Based Approach. Sensors. 2019; 19(24):5533. https://doi.org/10.3390/s19245533
Chicago/Turabian StyleYang, Heekyung, Jongdae Han, and Kyungha Min. 2019. "Distinguishing Emotional Responses to Photographs and Artwork Using a Deep Learning-Based Approach" Sensors 19, no. 24: 5533. https://doi.org/10.3390/s19245533
APA StyleYang, H., Han, J., & Min, K. (2019). Distinguishing Emotional Responses to Photographs and Artwork Using a Deep Learning-Based Approach. Sensors, 19(24), 5533. https://doi.org/10.3390/s19245533