1. Introduction
Accurate human detection and flow estimation attracts a lot of attention because of its vital application in the field of urban public transportation, intelligent building, etc. Such technology enables a new interaction between people. Specifically, flow estimation in public places such as airports, railway stations, and shopping malls can help staff analyze passenger density and channel dense crowds. In addition, the number of people getting on and off buses, metro systems and trains can contribute to the passenger flow analysis. Despite the significance of human detection and flow estimation, it remains a subject of active and challenging research.
Human detection derives from a combination of Histogram of Oriented Gradient (HOG) features and Support Vector Machine (SVM) classification, as shown in [
1]. Specific images are exhaustively searched for by a sliding window filter, which generates several candidate regions, resulting in high computational complexity. Thus, research efforts attempt to speed up the human detection process. Zhu et al. [
2] combine the rejection cascade approach to reduce computation. Beleznai C. et al. [
3] propose computationally efficient detection based on shape templates using contour integration by means of integral images, which are built by oriented string scans. Leo M et al. [
4] achieve foreground people tracking using a Hidden Markov Model based on blob geometrical information. Demirkus et al. [
5] consider geometric modelling in relation to pedestrian detection in fish-eye top-views for the first time. Selective search [
6] uses an underlying image structure to generate a set of region hypotheses. The hypothetic regions are merged in terms of similarity of features in color, texture, size, and shape compatibility. Despite the obvious decrease of candidate windows, selective search is still time consuming. With the rise of neural networks, recent research executed on the GPU platform have further reduced the computational complexity [
7,
8,
9]; it, however, continues to be a bottleneck for methods based on deep neural networks using RGB images.
In addition to computational efficiency, multi-scale, overlap, and occlusion are also challenges faced by RGB image-based methods. Moreover, the recognition results of RGB images are greatly affected by external environment changes, such as scene perspective distortions, illumination changes, and color variations. To address the aforementioned issues, a Time-of-Flight (TOF) camera becomes another choice.
TOF cameras produce depth images by measuring the phase difference between the radiated and reflected IR waves directed to the target object, each pixel of which encodes the distance to the corresponding point in the scene. Compared to RGB images, depth images measured by a TOF camera exhibit several advantages for human detection. In spite of low resolution, depth images provide more geometrical information. Features extracted from depth images are commonly not affected by scale, rotation, and illumination [
10]. An estimated 3D pose of an object from depth images is more accurate, compared to an estimated pose from RGB images [
11]. Moreover, TOF camera not only preserves privacy, but also achieves object segmentation in a more straightforward way than the traditional RGB cameras. Accordingly, depth images have the potential to overcome many difficulties faced by RGB images on human detection [
12]. In addition, TOF is highly adaptable to harsh lighting conditions and external environment changes. Conventional TOF cameras rely on a front-facing setup that suffers from occlusion if multiple people interact with each other simultaneously [
13]. The top-view TOF camera can solve the problem of multi-scale and occlusion under the front-view images.
Recent human detection approaches based on top-view TOF measurements can be divided into two broad categories, namely geometric model based and feature based. For the model-based approaches, Zhang et al. [
14] assume that the head is the closest body part to the vertical TOF camera and proposed head detection based on the local minimums of the depth image. This method is scale invariant, but cannot handle situations such as raising a hand over the head. Template matching is applied to locate head and shoulder patterns and split the fused blobs as individual people [
15]. However, in the case of crowding people, this method is limited and cannot accurately separate the detected hull into multiple persons. Similarly, the method [
16] projects the point cloud onto the ground plane to find people blobs. It also faces the problem that the projection may result in fused blobs for close people in extremely crowded scenes. A dynamic Gaussian Mixture Model (GMM) is used to extract the moving foreground objects as people in [
13]. In addition, graph-based segmentation [
17] separates the top-view human shape into a head region and other connected regions. As for complex scenes with high image noise, segmentation based on GMM and graph are not feasible. The other category is feature-based human detection. These methods, rather than relying on an explicit detection process to describe and identify persons in depth image, extract features to classify the candidate regions into people and other objects. A hemi-ellipsoid model is introduced to especially describe the 3D appearance of the upper head in [
17]. A 5-dimensional vector, composed of the fitted hemi-ellipsoid parameters, describes the configuration of head shapes. However, objects, such as floor lamps and basketballs, whose shapes are similar to the head surface model probably lead to false detection. Another approach proposes local maxima search and mean-shift clustering to generate sufficient head candidates. Moreover, a depth feature descriptor, based on SLTP feature [
18], computes relative depth differences as the input for SVM in [
19]. This method can respond to many challenging situations with humans tailgating and piggybacking. However, it generates excessive human candidates, resulting in high false positives and computational costs. Moreover, the proposed feature is insufficient to precisely represent the characteristics of the 3D head region shapes. Therefore, methods like [
17,
18,
19] need further processes to distinguish between human and other objects. A set of criteria on depth values and orientations in adjacent neighborhood areas is designed in [
20], in order to estimate the individual region of interest (ROI). Besides, a six-dimensional histogram feature, composed of the number of pixels in the head, neck and shoulder area, discriminates between people and other objects. Nevertheless, the components of the feature vector are sensitive to the appearance changes of people, such as hairstyle, hair length, and so on. Hence, the common problem of [
17,
18,
19,
20] is how to extract features that really describe the characteristics of the head region.
For the tracking algorithm, a height-based matching algorithm is proposed in [
21]. Bondi et al. [
17] use a greedy approach that iteratively associates track/detection pairs with the smallest distance. A constant speed model is used to perform the probabilistic filtering and tracking based on extended particle filter with a clustering process in [
20]. The kalman-based multi-object tracking of coordinates and velocity of each detected object is proposed to match and update the tracks [
22]. Besides, a weighted K Nearest Neighbor based multi-target tracking method is adopted to track each confirmed head and count people through the surveillance region [
23]. The corresponding weights are calculated by the Gaussian function of distance between head position point and K nearest trajectories. These matching algorithms based on single features cannot cope with complex scenes such as occlusion.
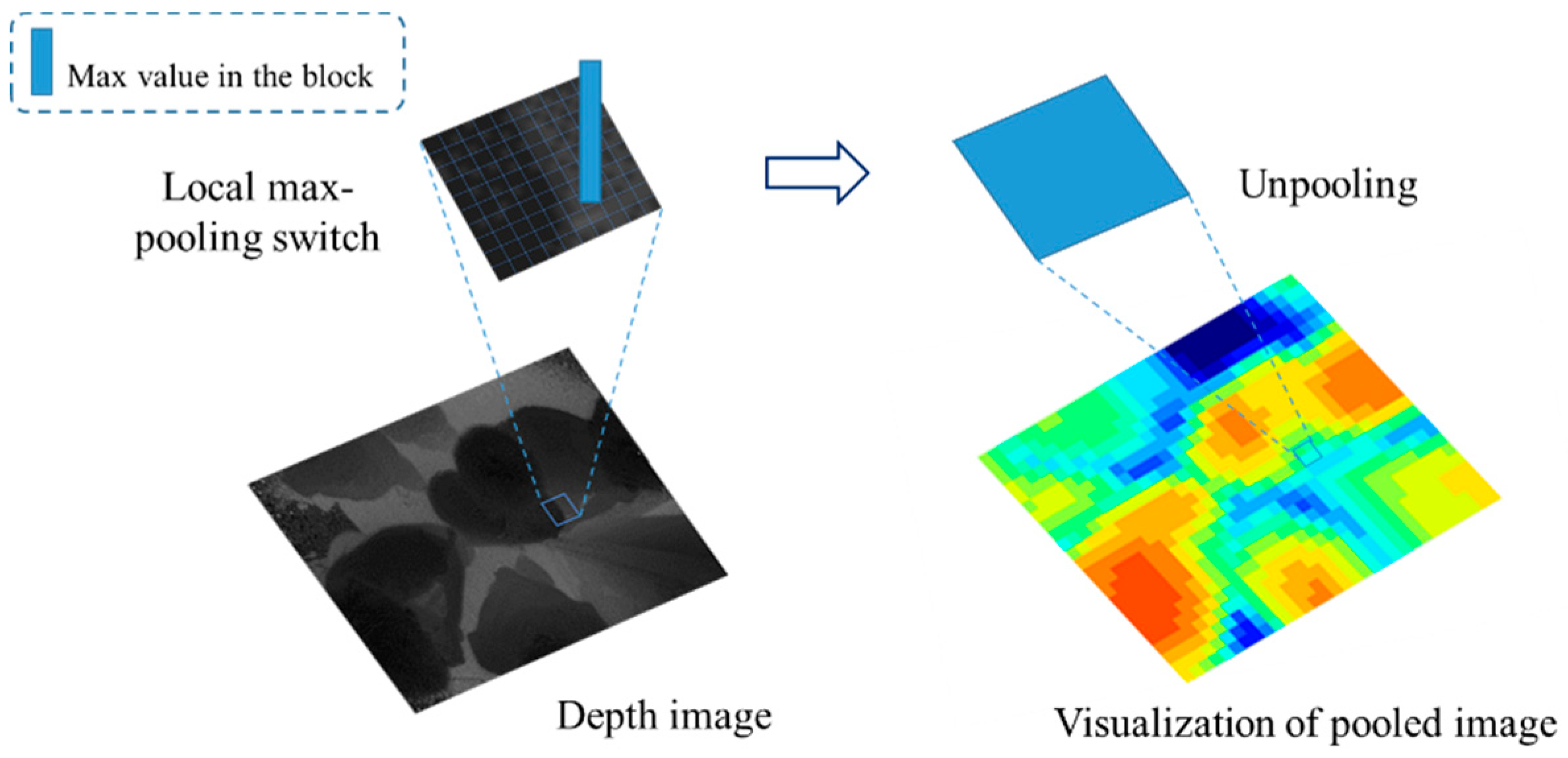
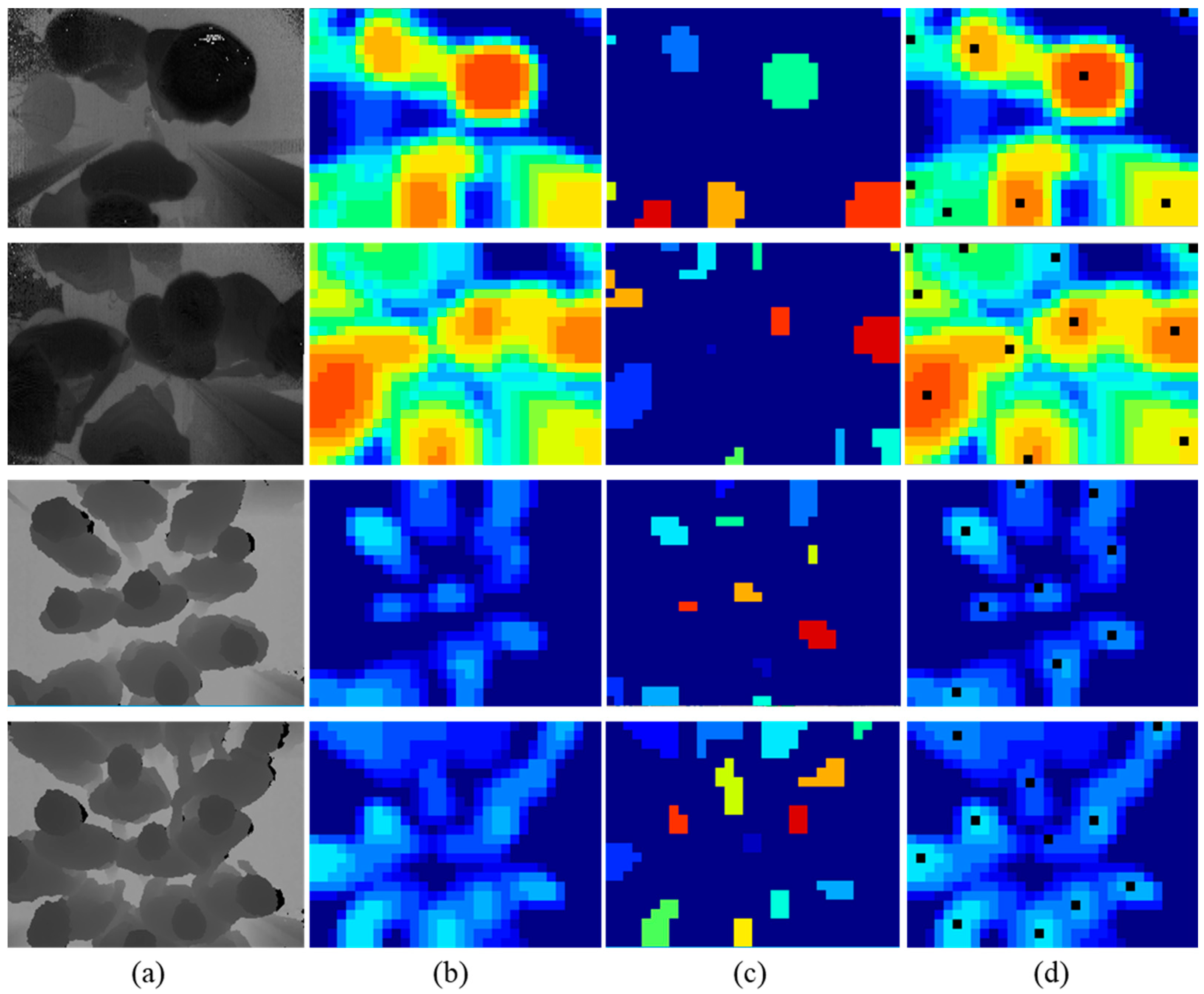
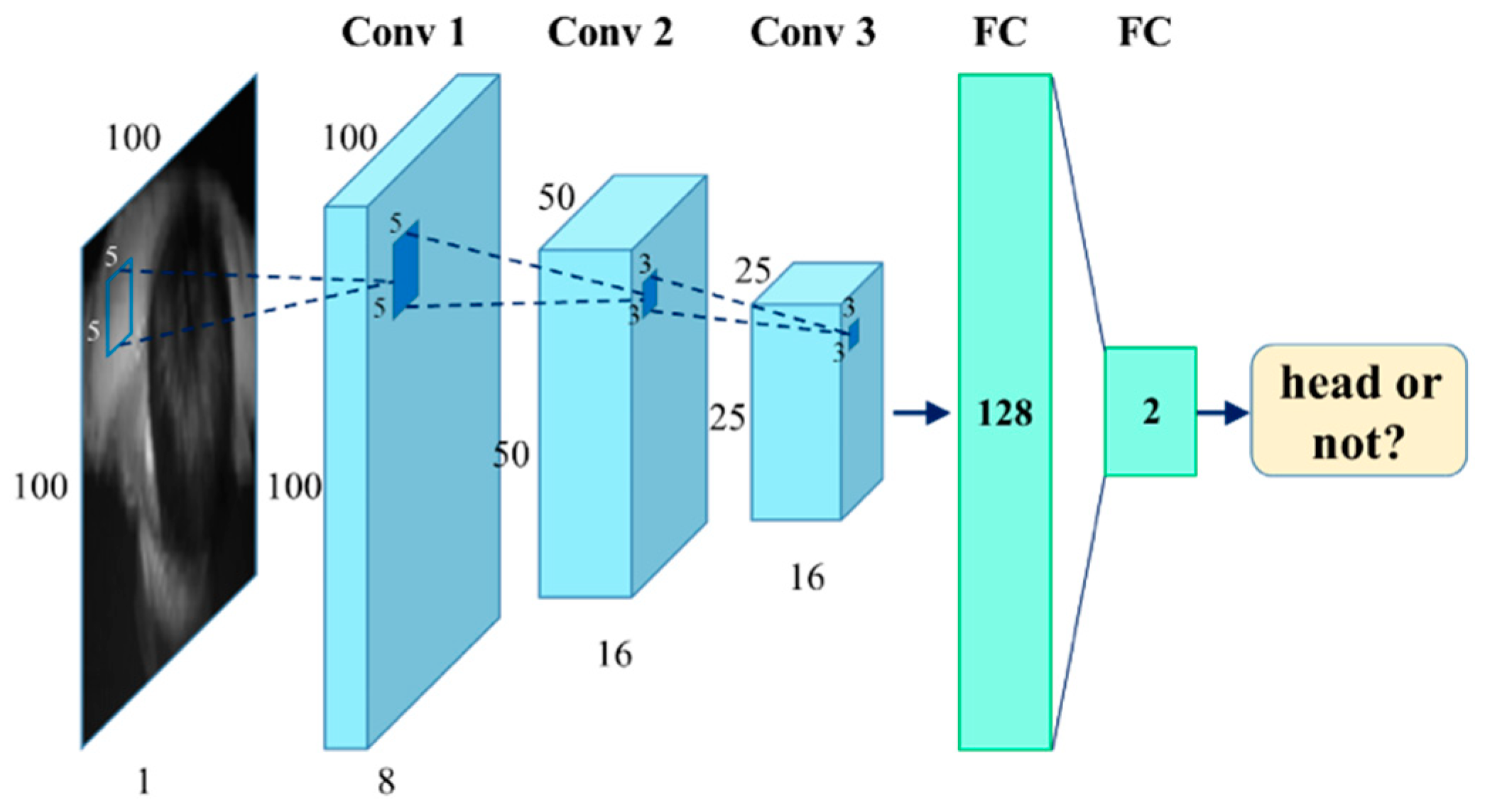
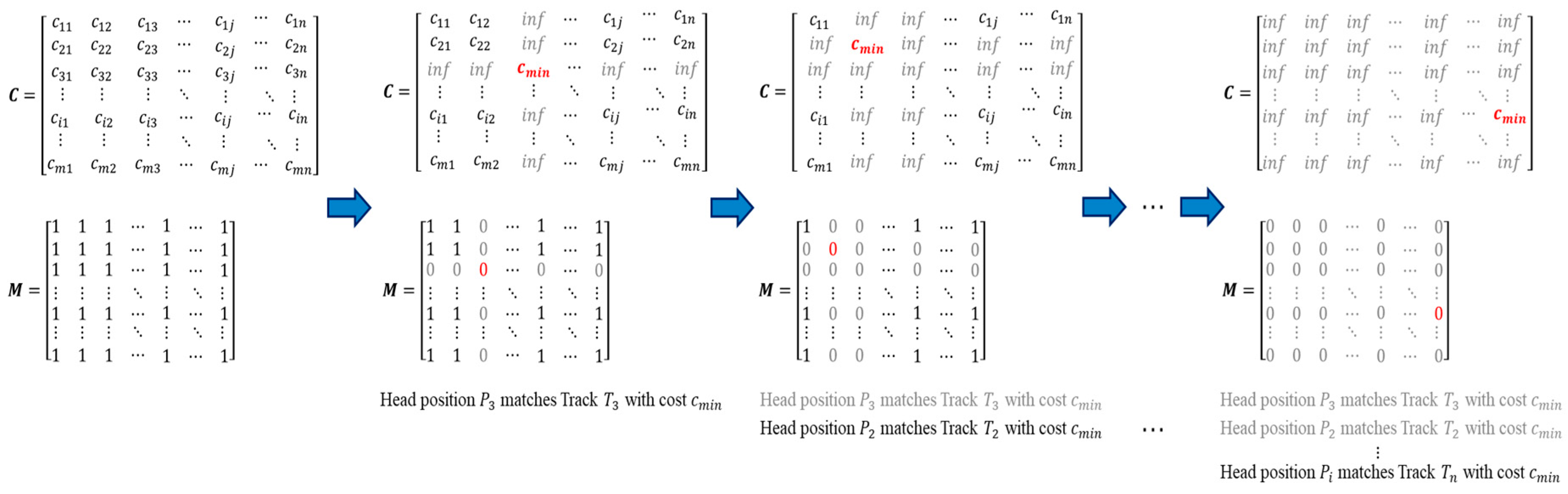
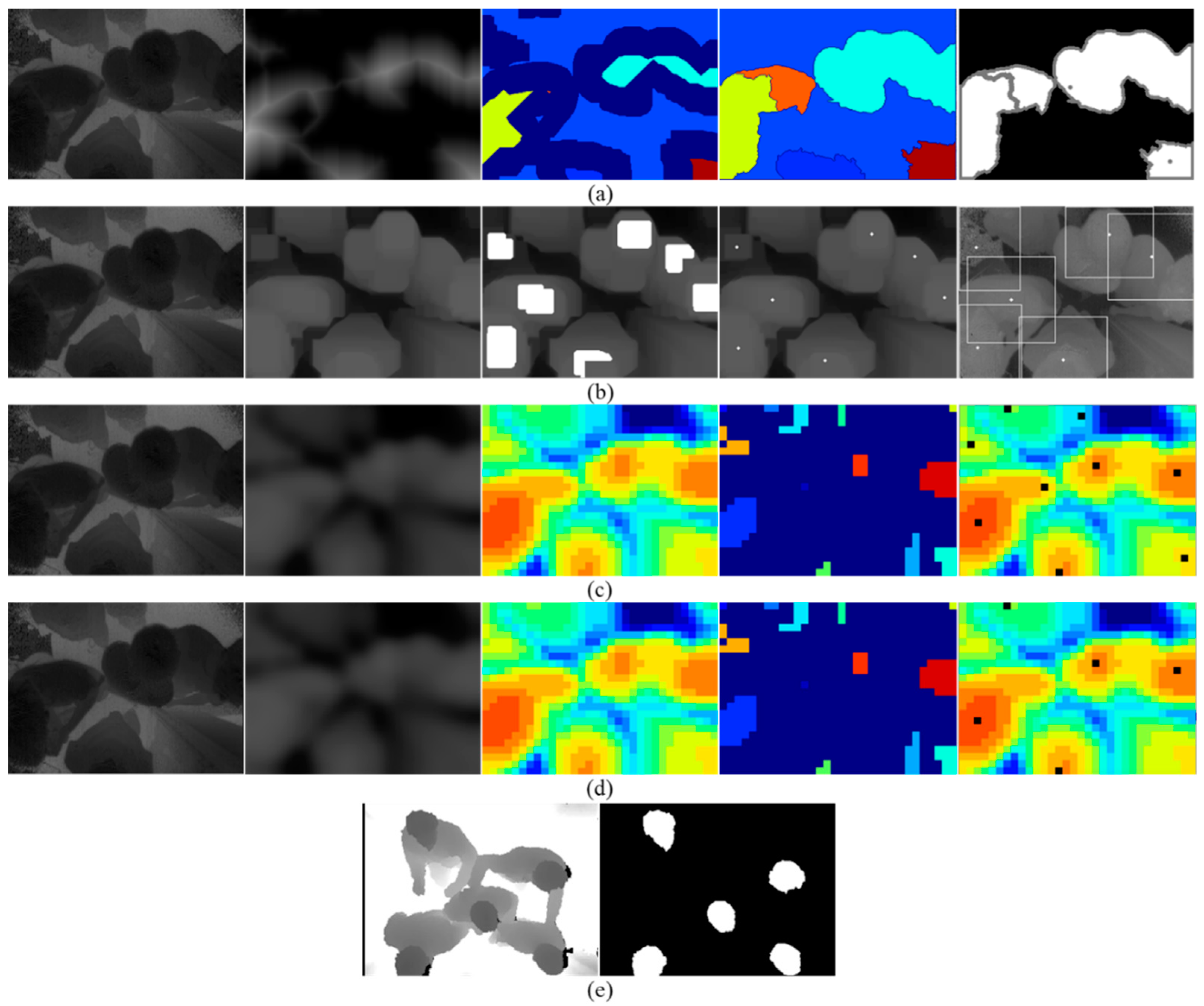
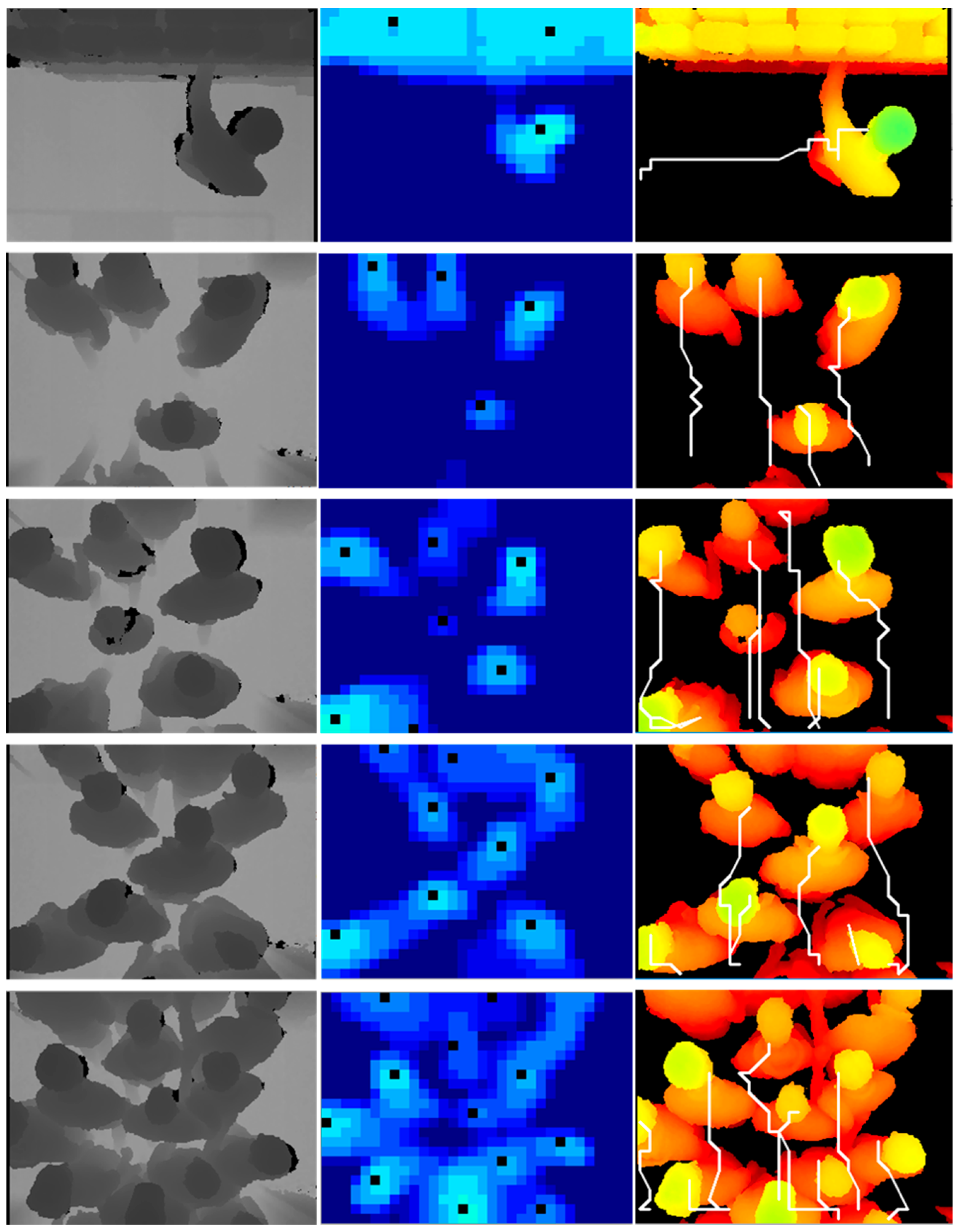
In this paper, we present a real-time framework for human detection and flow estimation using top-view TOF camera measurements. The proposed algorithm mainly consists of three modules: head detection based on local pooling and searching, classification refinement based on human morphological features, and tracking assignment filter based on dynamic multi-dimensional features. Local pooling dramatically reduces the amount of computation, while preserving local key information for the depth image. In addition, the multi-dimensional feature combines the spatial relationship and height of human candidate points by a penalty function. The common constraint of multiple features make the trajectory assignment and update more accurate. As the previous datasets are all captured by front- or side-view camera, we contribute a new dataset from top-view camera for human detection and flow estimation. The new dataset includes more than 10k entries and departure events with detailed human location annotations. The experiments demonstrate that our method achieves high accuracy (97.73%) and reduces the running time significantly with 23.10 ms per frame on a CPU platform. In addition, the proposed robust approach is still effective in complex situations such as fast walking, occlusion, crowded scenes, etc.
This paper is organized as follows.
Section 1 provides a general introduction and review of the related literature.
Section 2 includes the detailed human detection and flow estimation approach. The experimental setup and results are introduced in
Section 3. Finally,
Section 4 states the conclusions and future work.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}