Improved Bound Fit Algorithm for Fine Delay Scheduling in a Multi-Group Scan of Ultrasonic Phased Arrays



Abstract
:1. Introduction
2. Fine Delay Module for Multi-Group Scanning of UPAs
2.1. Fine Delay Scheduling Principle
- (1)
- High speed multi-channel ADC module (HADC): Ultrasonic echo signals are subjected to high-speed multi-channel ADC acquisition, conditioning conversion, and transformation into low-voltage differential signaling (LVDS) serial signals. They are then fed to the FPGA for further processing. ADCs are divided into groups according to the probe socket and multi-group scan.
- (2)
- Fine delay scheduling module (FDS): The LVDS serial signal is first converted into a parallel signal, then the parallel signal generated by the IP core is sent to the multi-channel first-in first-out memory (FIFO), which is used for buffering and scheduling. The scheduling module consists of several fine delay modules. The signal buffered in the FIFO is then fed to the scheduling module, where it is forwarded to different fine delay modules. Thus, time division multiplexing is achieved.
- (3)
- Coarse delay and sum module (CDS): Coarse delay is based on counter clock delay technology. All the relative delay parameters of focal laws, calculated by a PC, can be loaded from the “delay and scheduling parameters storage” block in Figure 1. The double data rate 3 (DDR3) synchronous dynamic random access memory input signal addresses the corresponding coarse delay parameter counted by the clock, and thus fixed integer coarse delay is achieved. The sum module merges signals processed by fine delay and coarse delay blocks in an ultrasonic digital beam, which represents the complete beamform of the focal laws. All signals of the ultrasonic digital beam are stored in memory, and all signal groups form a corresponding beamform. In other words, each focal law forms a digital beamform, and all the beamforms of the same group generate the initial image information of that group.
- (4)
- External DDR3: Since the internal RAM capacity of the FPGA is insufficient, a DDR3 controller with two DDR3 memories is used for coarse delay data storage. DDR3 memory has a coarse delay and reads the group focus module according to the group.
- (5)
- Delay and scheduling parameters storage (DSPS): Delay and scheduling parameters storage is a large-scale storage block in the FPGA. The delay and scheduling parameters are calculated using a focal law calculator in the PC, corresponding to the input data entered by the user. DSPS contains a scheduling table, the pulse repetition frequency of each group, and the time delay parameter for both fine and coarse delays according to focal laws. It also includes algorithmic control for scheduling Mux and Demux based on the above parameters. A fine delay scheduling model diagram in the multi-scan group is presented in Figure 4.
2.2. Fine Delay Scheduling Problem in Multi-Group Scanning
- (1)
- Each focal law must be separately processed in fine delay modules. In other words, one fine delay module must process only one focal law datum.
- (2)
- The process cannot be interrupted or preemptive, i.e., a no-interrupt non-preemptive (NINP) model is adopted.
- (3)
- There is no time gap between the start time of focal law and the start time of the pulse repetition period.
- (4)
- The sample depth is less than the pulse repetition period.
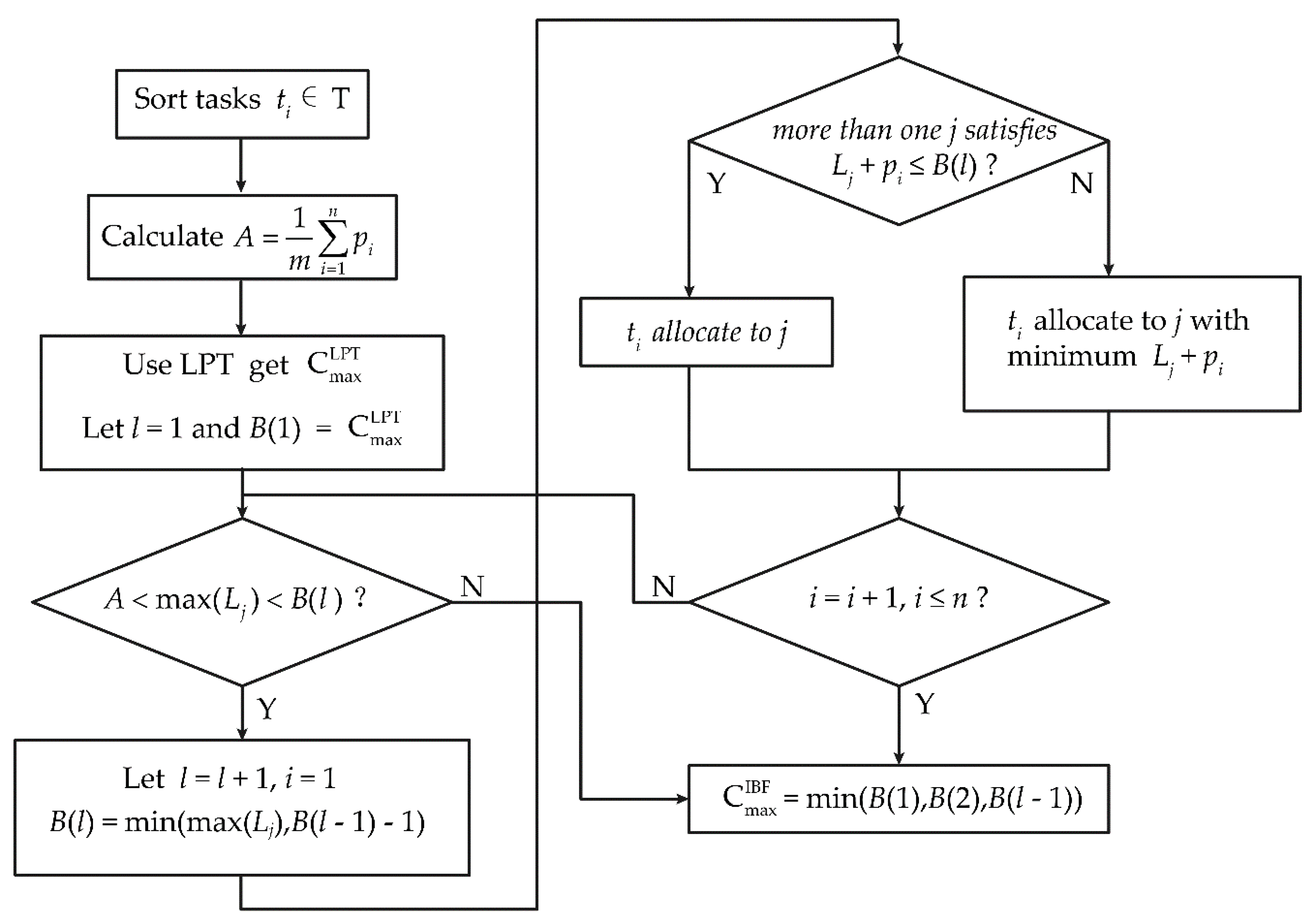
3. IBF Algorithm
4. Experimental Results
4.1. Time Performance
4.2. Resource Consumption
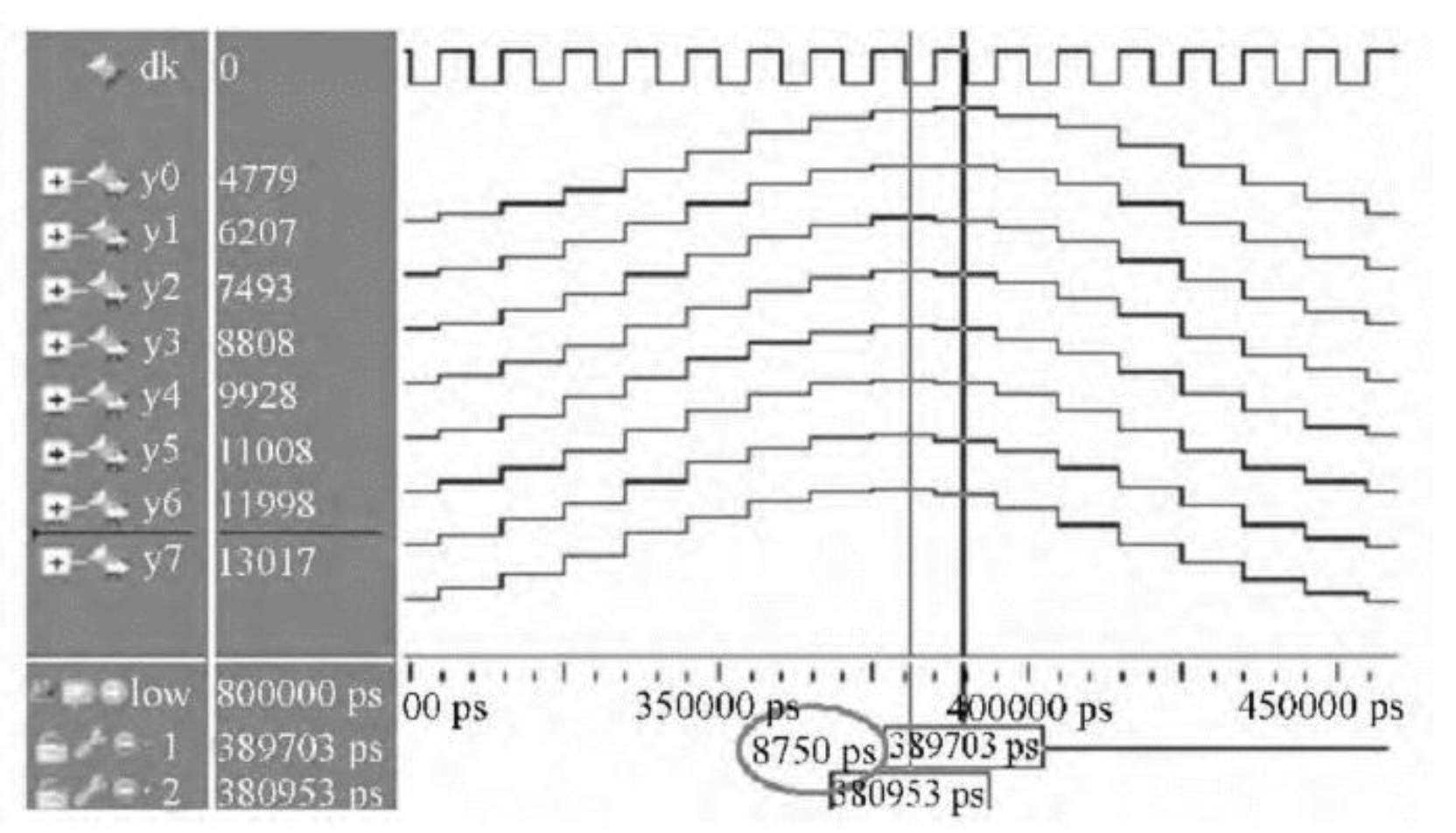
4.3. Real-Time Verification
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Holmes, C.; Drinkwater, B.W.; Wilcox, P.D. Post-processing of the full matrix of ultrasonic transmit–receive array data for non-destructive evaluation. Ndt E Int. 2005, 38, 701–711. [Google Scholar] [CrossRef]
- Njiki, M.; Bouaziz, S.; Elouardi, A.; Casula, O.; Roy, O. A multi-FPGA implementation of real-time reconstruction using Total Focusing Method. In Proceedings of the 2013 IEEE International Conference on Cyber Technology in Automation, Control and Intelligent Systems, Nanjing, China, 26–29 May 2013; pp. 468–473. [Google Scholar]
- Shao, Z. Research on a GPU-based Real-Time Ultrasound Imaging System. Ph.D. Thesis, Nanjing University, Nanjing, China, 2014. [Google Scholar]
- Guo, J.Q.; Li, X.; Gao, X.; Wang, Z.; Zhao, Q. Implementation of total focusing method for phased array ultrasonic imaging on FPGA. In Proceedings of the International Symposium on Precision Engineering Measurement & Instrumentation, Changsha, China, 8–11 August 2014. [Google Scholar]
- Zhang, X.; Guo, J.; Luo, X.; Gao, X.; Wang, Z.; Zhao, Q.; Zheng, B. Defect detection study on total focus method of sound field imaging based on parallel processing. In Proceedings of the 2014 IEEE Far East Forum on Nondestructive Evaluation/Testing (FENDT), Chengdu, China, 20–23 June 2014; pp. 112–116. [Google Scholar]
- Tang, W.; Liu, G.; Li, Y.; Tan, D. An improved scheduling algorithm for data transmission in ultrasonic phased arrays with multi-group ultrasonic sensors. Sensors 2017, 17, 2355. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.; Li, X.; Li, H.; Su, Z.; Zhang, H. Implementation of high time delay accuracy of ultrasonic phased array based on interpolation CIC filter. Sensors 2017, 17, 2322. [Google Scholar] [CrossRef] [PubMed]
- Su, T.; Yao, D.J.; Li, D.Y.; Zhang, S. Ultrasound parallel delay multiply and sum beamforming algorithm based on GPU. In Proceedings of the 2nd IET International Conference on Biomedical Image and Signal Processing (ICBISP 2017), Wuhan, China, 13–14 May 2017. [Google Scholar]
- Asano, S.; Maruyama, T.; Yamaguchi, Y. Performance comparison of FPGA, GPU and CPU in image processing. In Proceedings of the International Conference on Field Programmable Logic & Applications, Prague, Czech Republic, 31 August–2 September 2009. [Google Scholar]
- Ullman, S.D. Complexity of Sequencing Problems. Computers and Job-Shop Scheduling; John Wiley: New York, NY, USA, 1976. [Google Scholar]
- Graham, R.L. Bounds on multiprocessing timing anomalies. SIAM J. Appl. Math. 1969, 17, 416–429. [Google Scholar] [CrossRef]
- Coffman, F.G., Jr.; Garey, M.R.; Johnson, D.S. An application of bin-packing to multiprocessor scheduling. SIAM J. Compt. 1978, 7, 1–17. [Google Scholar] [CrossRef]
- Friesen, D.K. Tighter bounds for the multifit processor scheduling algorithm. SIAM J. Comput. 1984, 13, 170–181. [Google Scholar] [CrossRef]
- Lee, C.Y.; Massey, J.D. Multiprocessor scheduling: Combining LPT and MULTIFIT. Discret. Appl. Math. 1988, 20, 233–242. [Google Scholar] [CrossRef]
- Kang, Y.; Zheng, Y. Independent tasks scheduling on identical parallel processors. Acta Autom. Sin. 1997, 23, 81–84. [Google Scholar]
- Li, X.P.; Xu, X.F.; Zhan, D.C. A Quick Algorithm for Independent Tasks Scheduling on Identical Parallel Processors. J. Softw. 2002, 13, 812–814. [Google Scholar]
- Liu, G.; Tang, W.; Tan, D. Focusing time delay of ultrasonic phased array based on multistage half-band filter. Opt. Precis. Eng. 2014, 22, 1571–1576. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Parameter |
|---|---|
| Number of groups (n) 1 | |
| Number of focal laws in the ith group | |
| Sample depth of the ith group | |
| Number of fine delay modules (m) 1 | |
| Read parameter time of focal law | |
| Tclock-cycle | Clock period in FPGA |
| Processing time in the ith group (pi) 1 |
| m | LIST | LPT | BF | IBF | |||
|---|---|---|---|---|---|---|---|
| 2 | 1092.39 | 996.67 | 995.96 | 3.02 | 991.17 | 2.64 | 8.76% |
| 4 | 1174.41 | 1005.26 | 999.65 | 4.01 | 996.65 | 5.49 | 14.40% |
| 6 | 1264.74 | 1007.05 | 997.98 | 5.28 | 996.91 | 8.11 | 20.37% |
| 8 | 1258.18 | 1008.45 | 997.63 | 6.86 | 997.16 | 10.1 | 19.85% |
| 10 | 1282.96 | 1007.41 | 996.22 | 8.01 | 996.06 | 11.61 | 21.48% |
| Number of Groups | Number of Modules | Total LUT | Total Reg. | Total 9-bit Mult. | Fmax (MHz) | |
|---|---|---|---|---|---|---|
| All-par. 32 ch. | 4 | 4 | 5086 (4.44%) | 3977 | 320 (60%) | 137.74 |
| 1/2 Sch. 32 ch. | 4 | 2 | 2902 (2.53%) | 2445 | 160 (30%) | 146.99 |
| All-par. 64 ch. | 8 | 8 | 14,340 (12.53%) | 8569 | 532 (100%) 1 | 113.77 |
| 1/2 Sch. 64 ch. | 8 | 4 | 5902 (5.16%) | 4857 | 320 (60%) | 126.53 |
| Group | Number of Focal Laws | Sample Depth | Processing Time 1 (pi) |
|---|---|---|---|
| 0 | 64 | 2048 | 196,608 |
| 1 | 64 | 2048 | 196,608 |
| 2 | 128 | 4096 | 655,360 |
| 3 | 128 | 8192 | 1,179,648 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Tang, W.; Liu, G. Improved Bound Fit Algorithm for Fine Delay Scheduling in a Multi-Group Scan of Ultrasonic Phased Arrays. Sensors 2019, 19, 906. https://doi.org/10.3390/s19040906
Li Y, Tang W, Liu G. Improved Bound Fit Algorithm for Fine Delay Scheduling in a Multi-Group Scan of Ultrasonic Phased Arrays. Sensors. 2019; 19(4):906. https://doi.org/10.3390/s19040906
Chicago/Turabian StyleLi, Yuzhong, Wenming Tang, and Guixiong Liu. 2019. "Improved Bound Fit Algorithm for Fine Delay Scheduling in a Multi-Group Scan of Ultrasonic Phased Arrays" Sensors 19, no. 4: 906. https://doi.org/10.3390/s19040906
APA StyleLi, Y., Tang, W., & Liu, G. (2019). Improved Bound Fit Algorithm for Fine Delay Scheduling in a Multi-Group Scan of Ultrasonic Phased Arrays. Sensors, 19(4), 906. https://doi.org/10.3390/s19040906