Double Q-Learning for Radiation Source Detection


Abstract
:1. Introduction
2. Materials and Methods
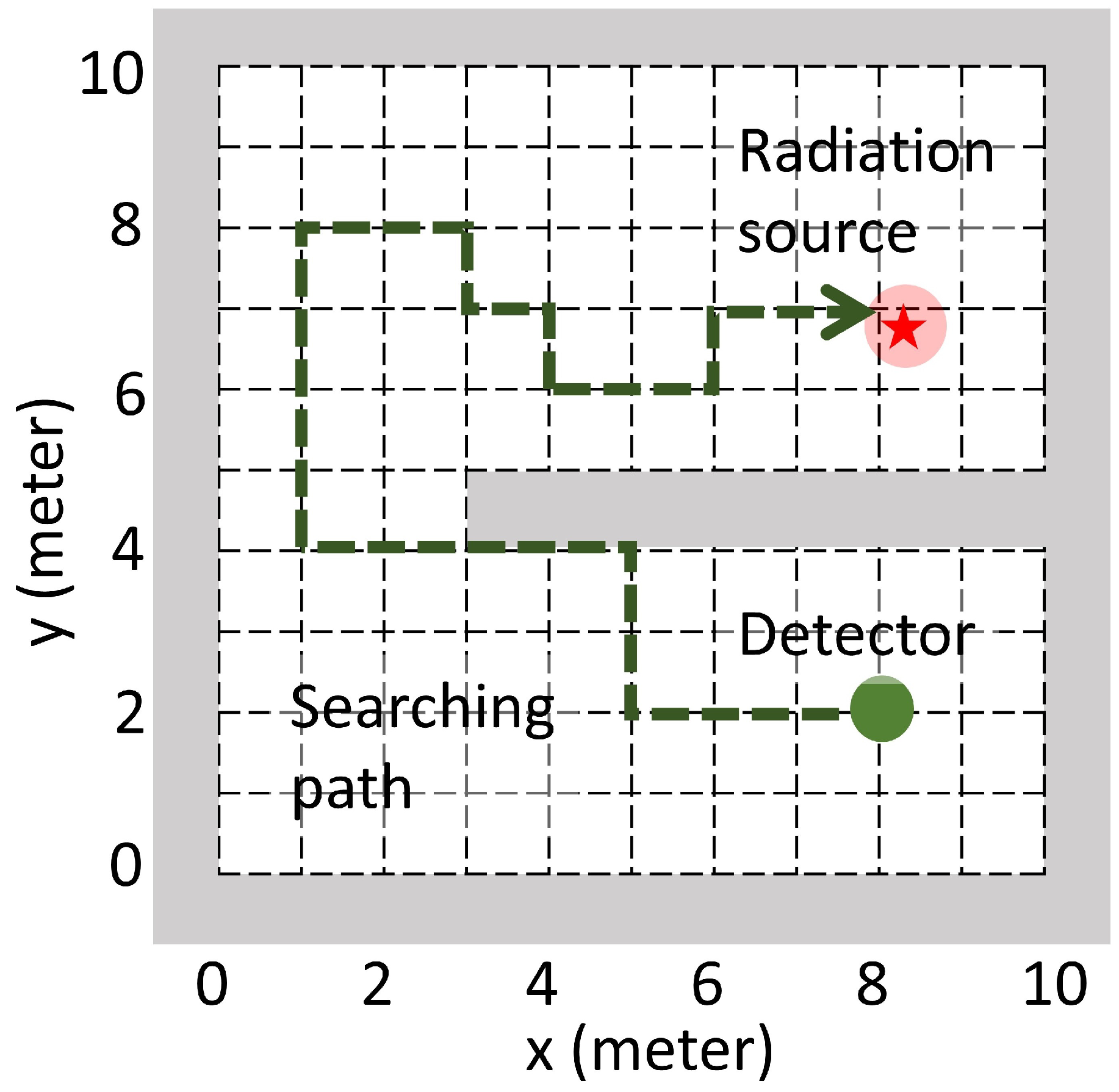
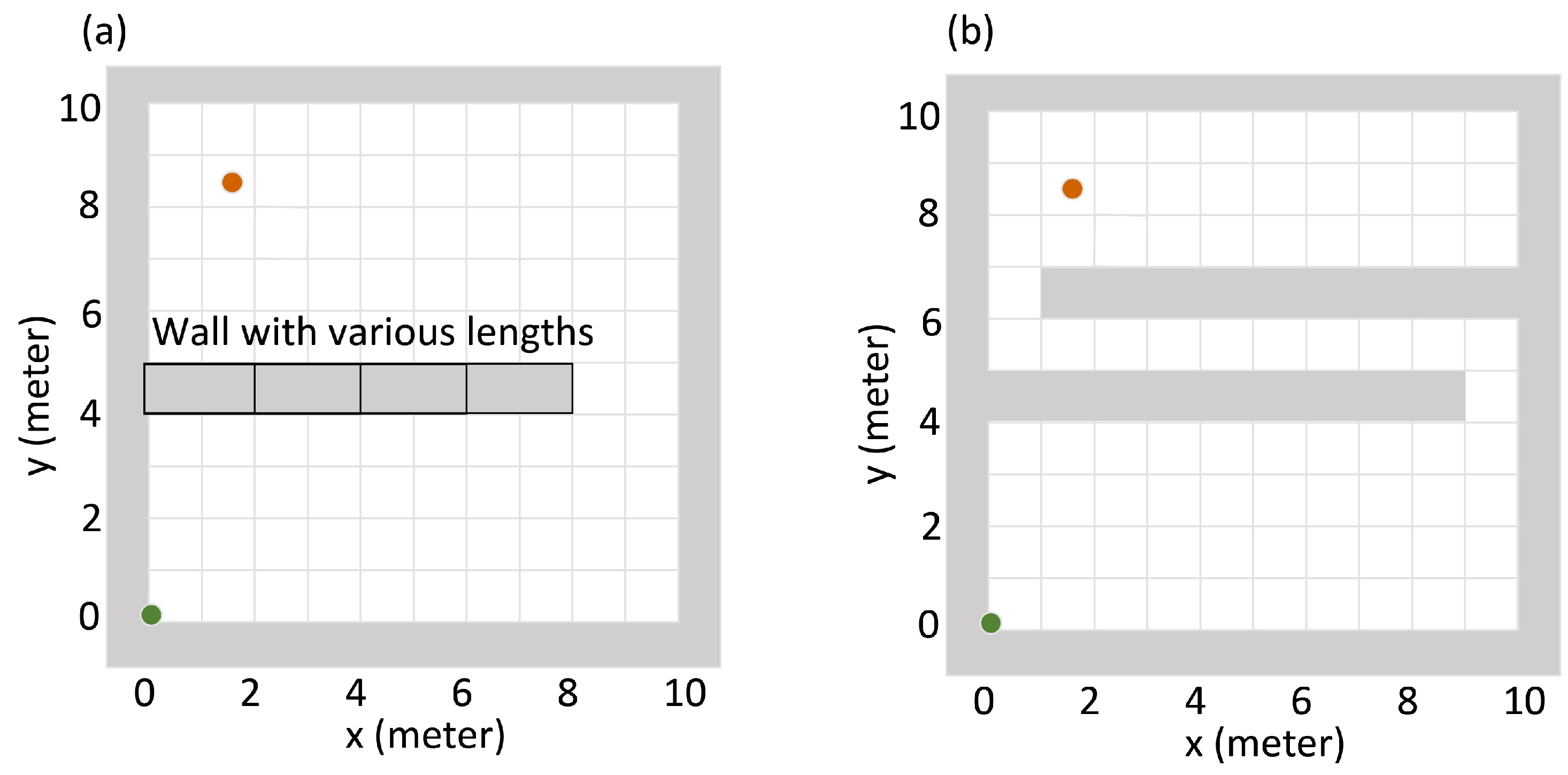
2.1. Radiation Source Detection Task
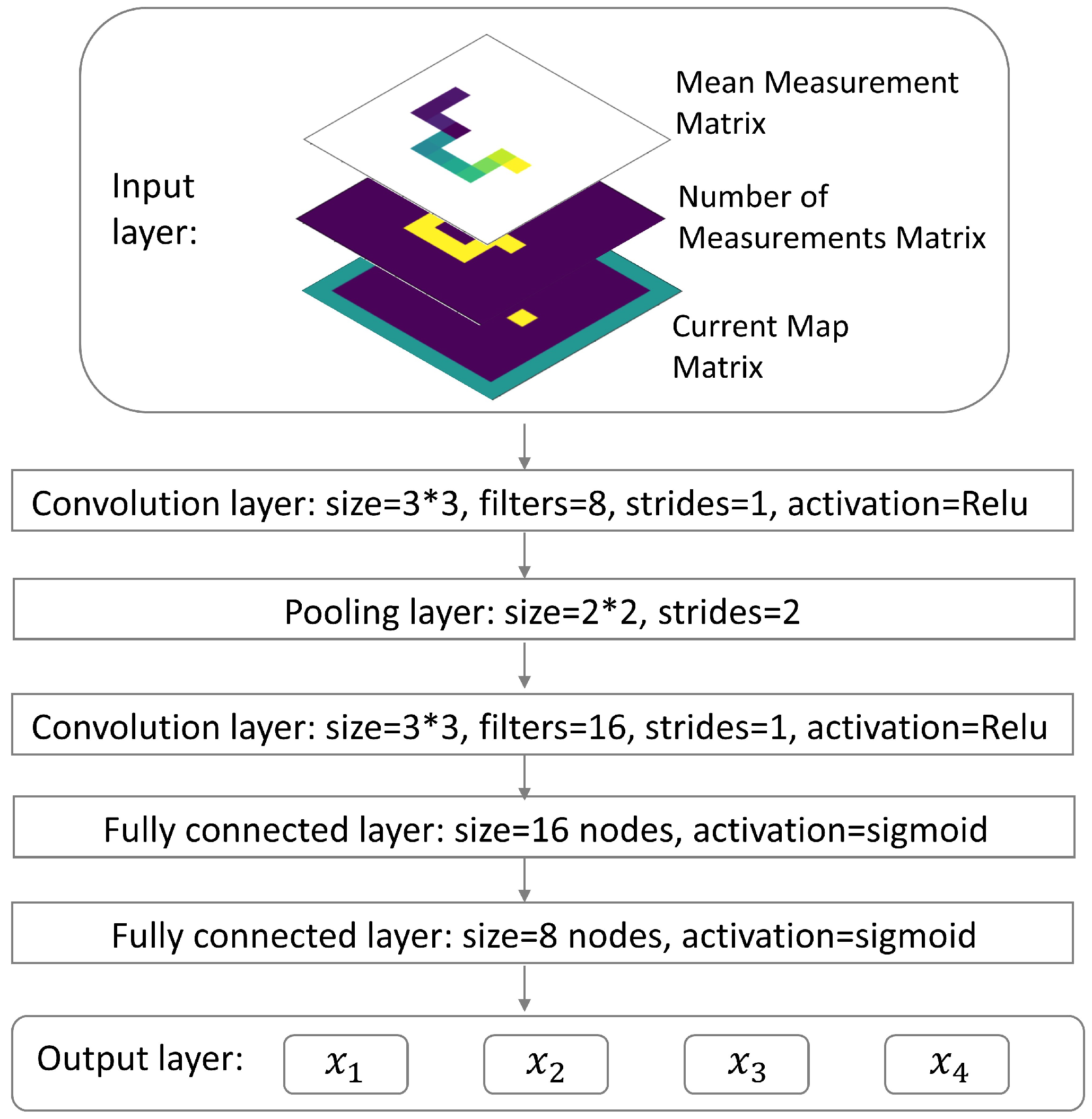
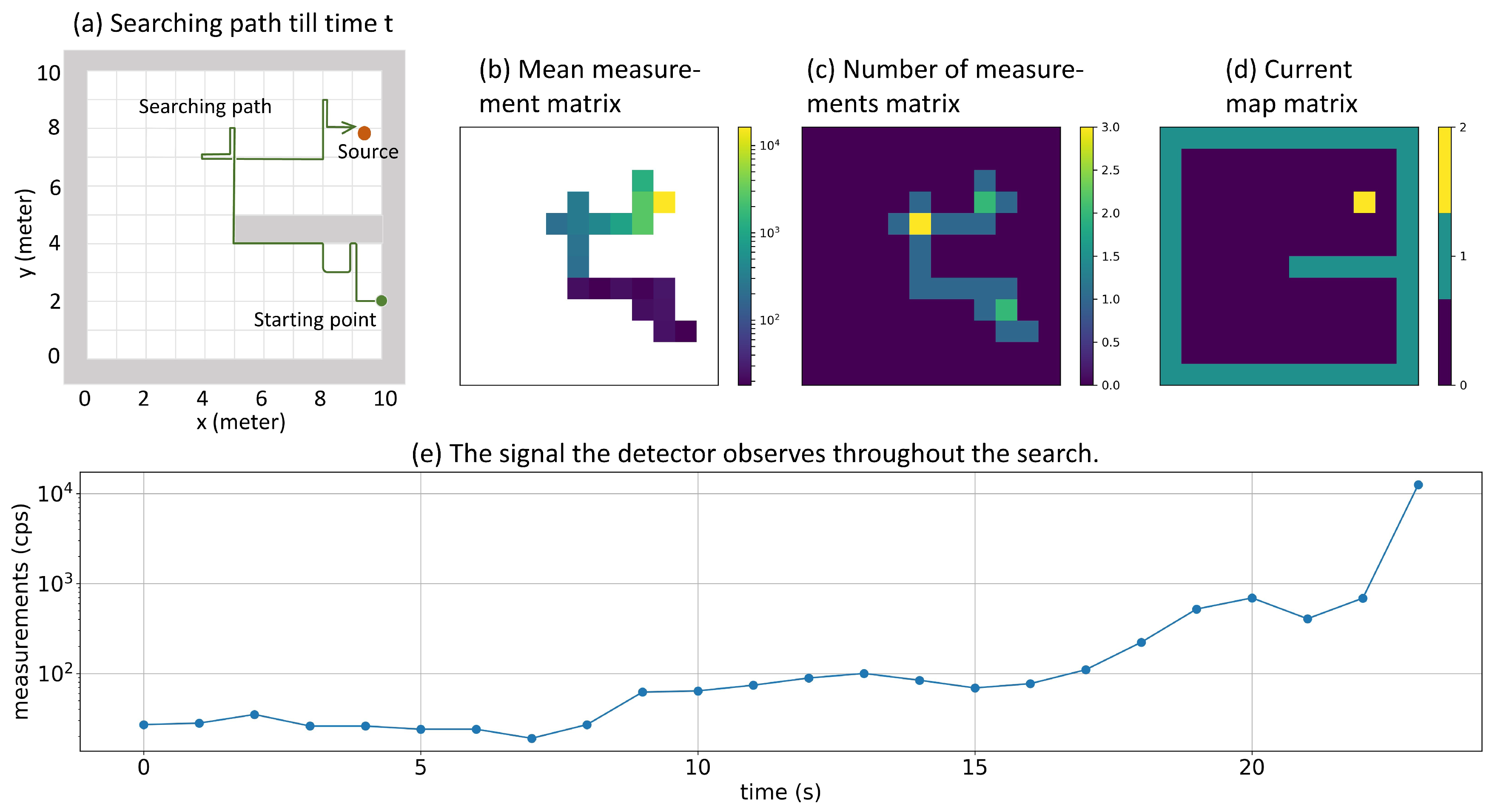
2.2. Q-Learning with Convolutional Neural Network
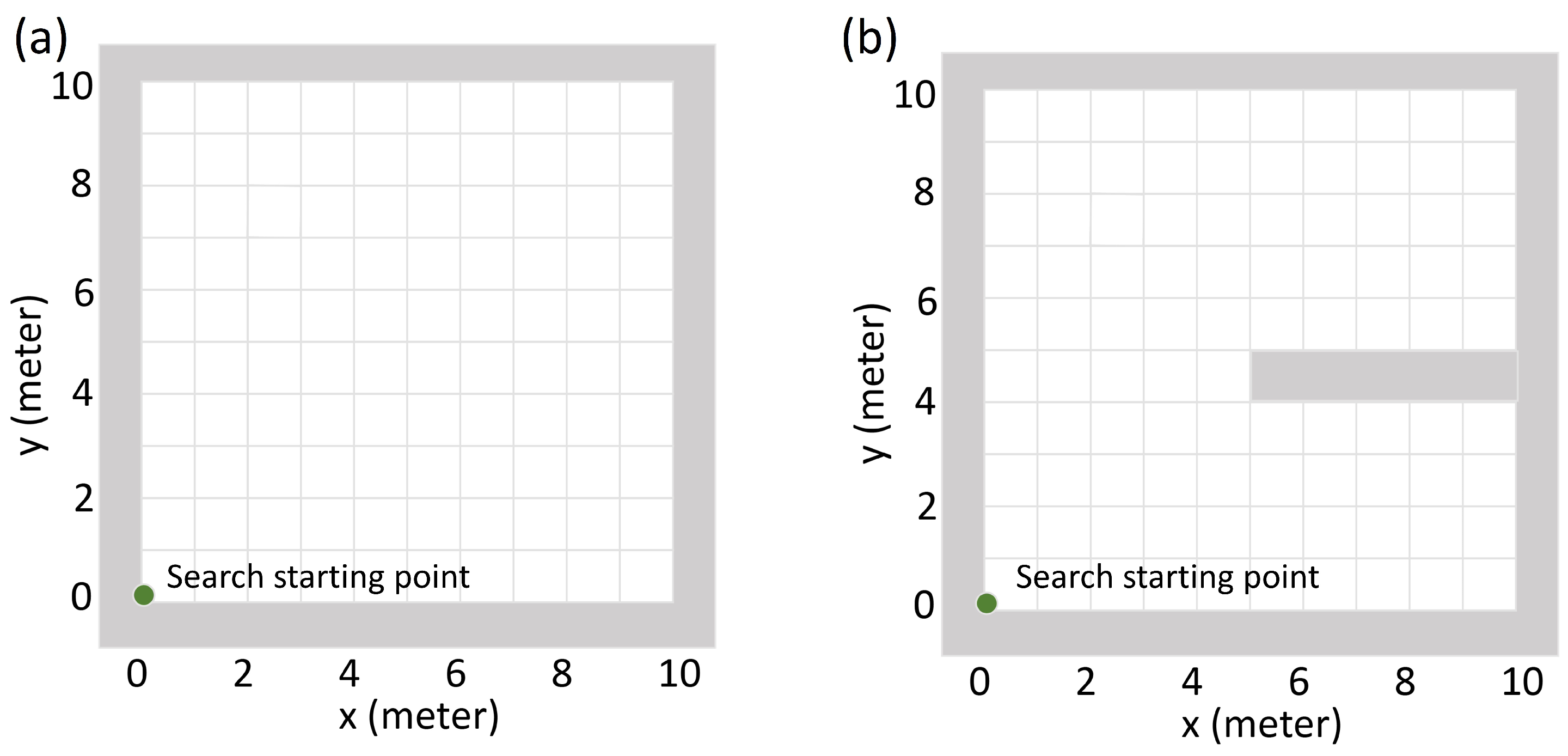
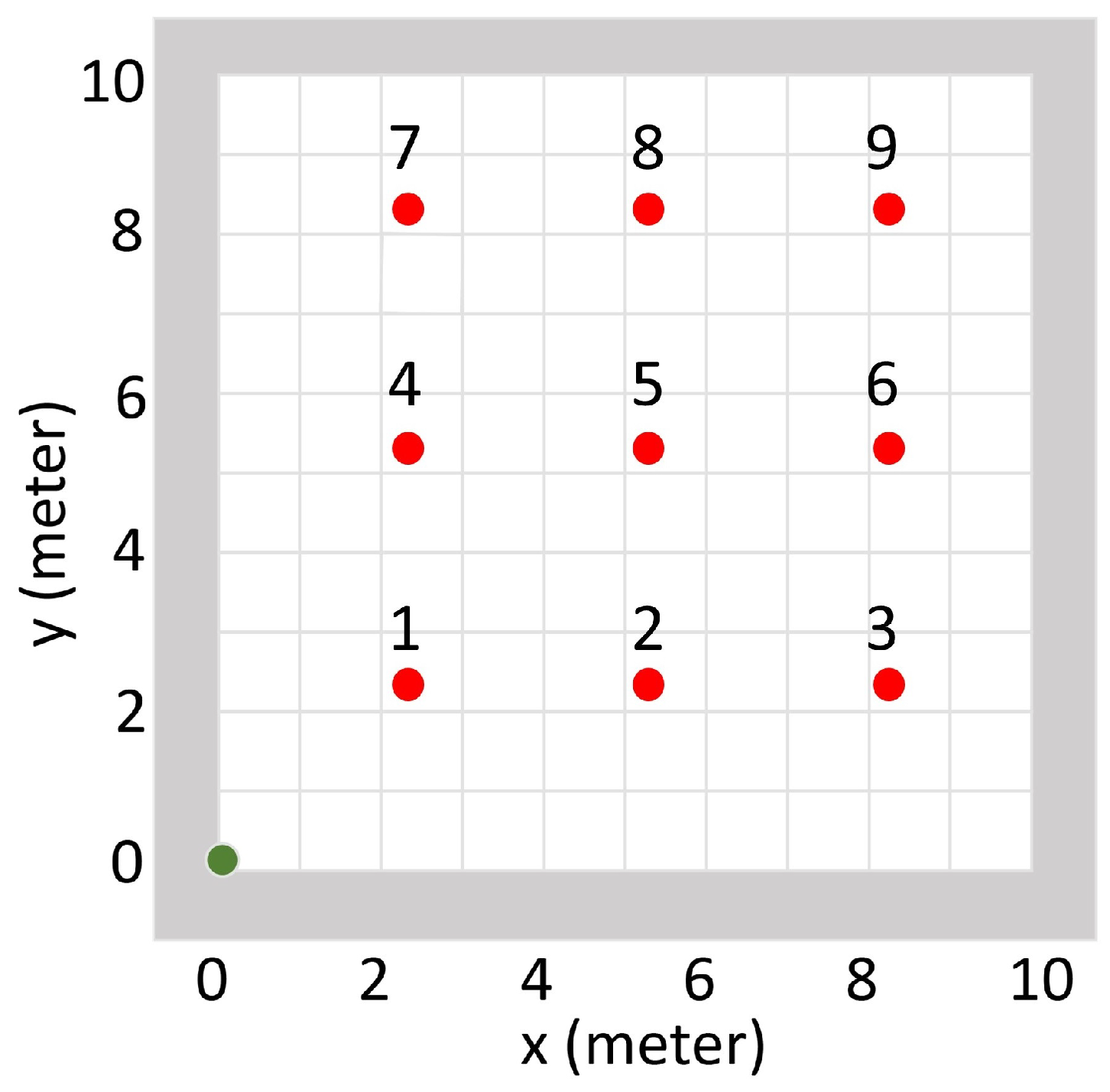
2.3. Evaluation
3. Results and Discussion
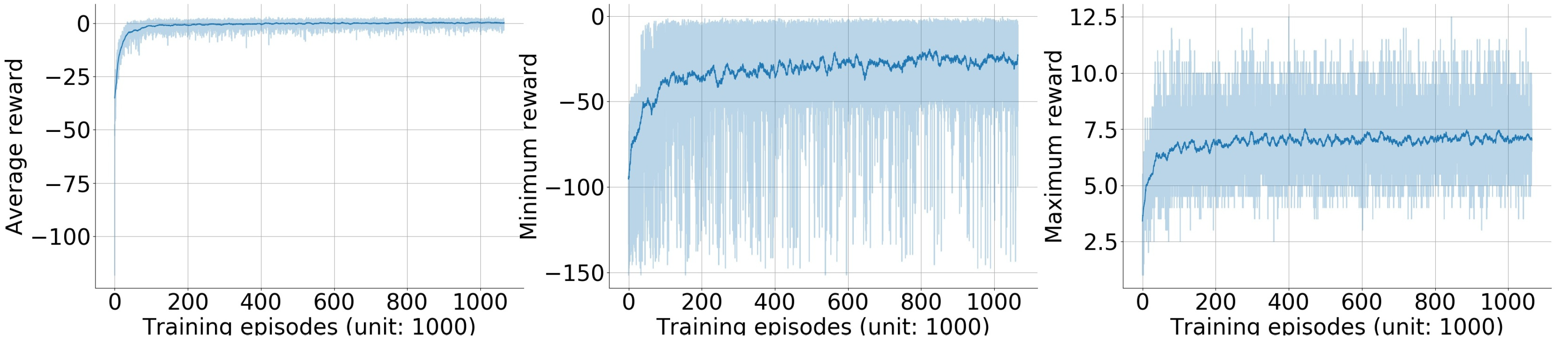
3.1. Training Result of the Double Q-Learning Algorithm
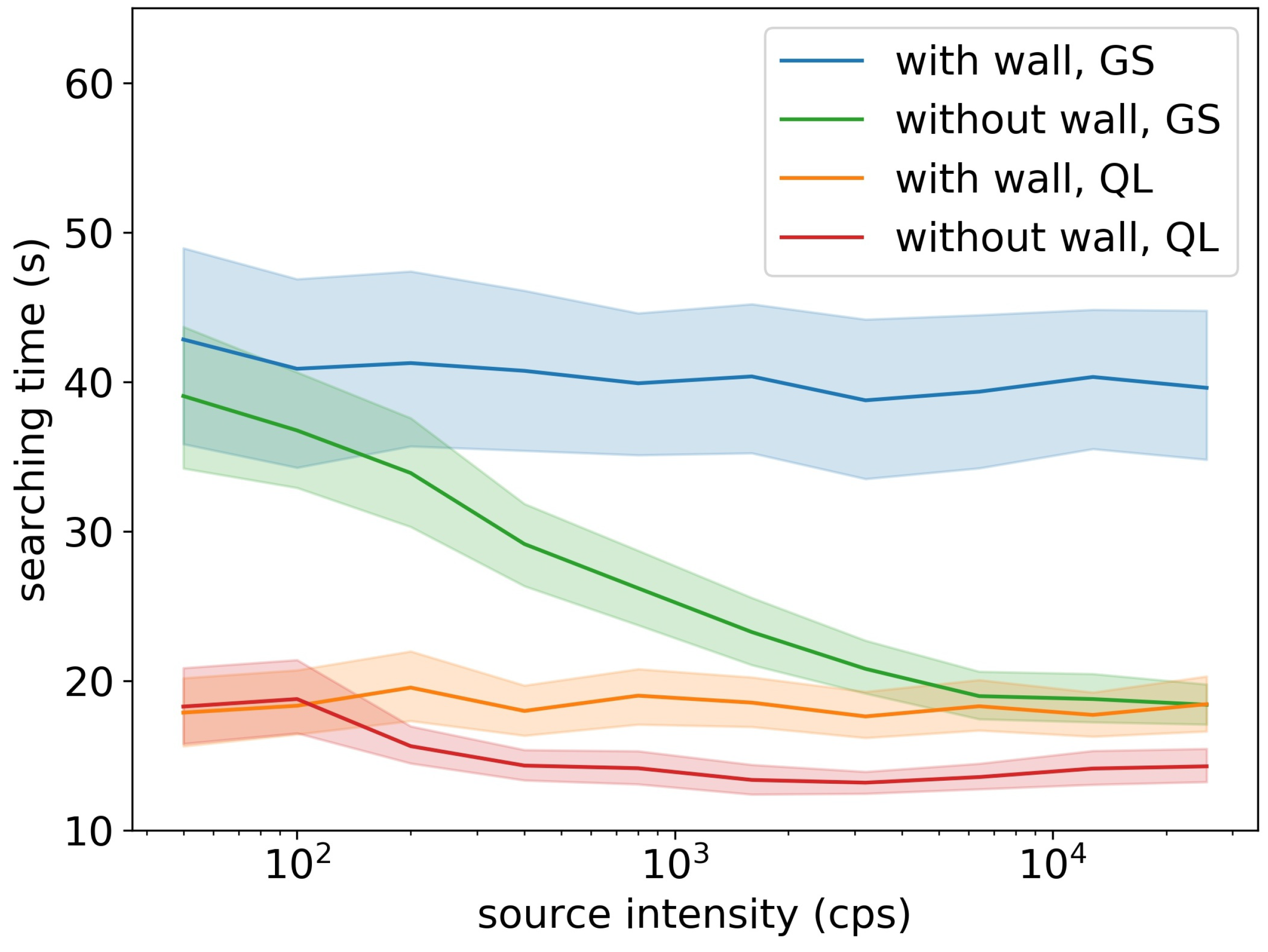
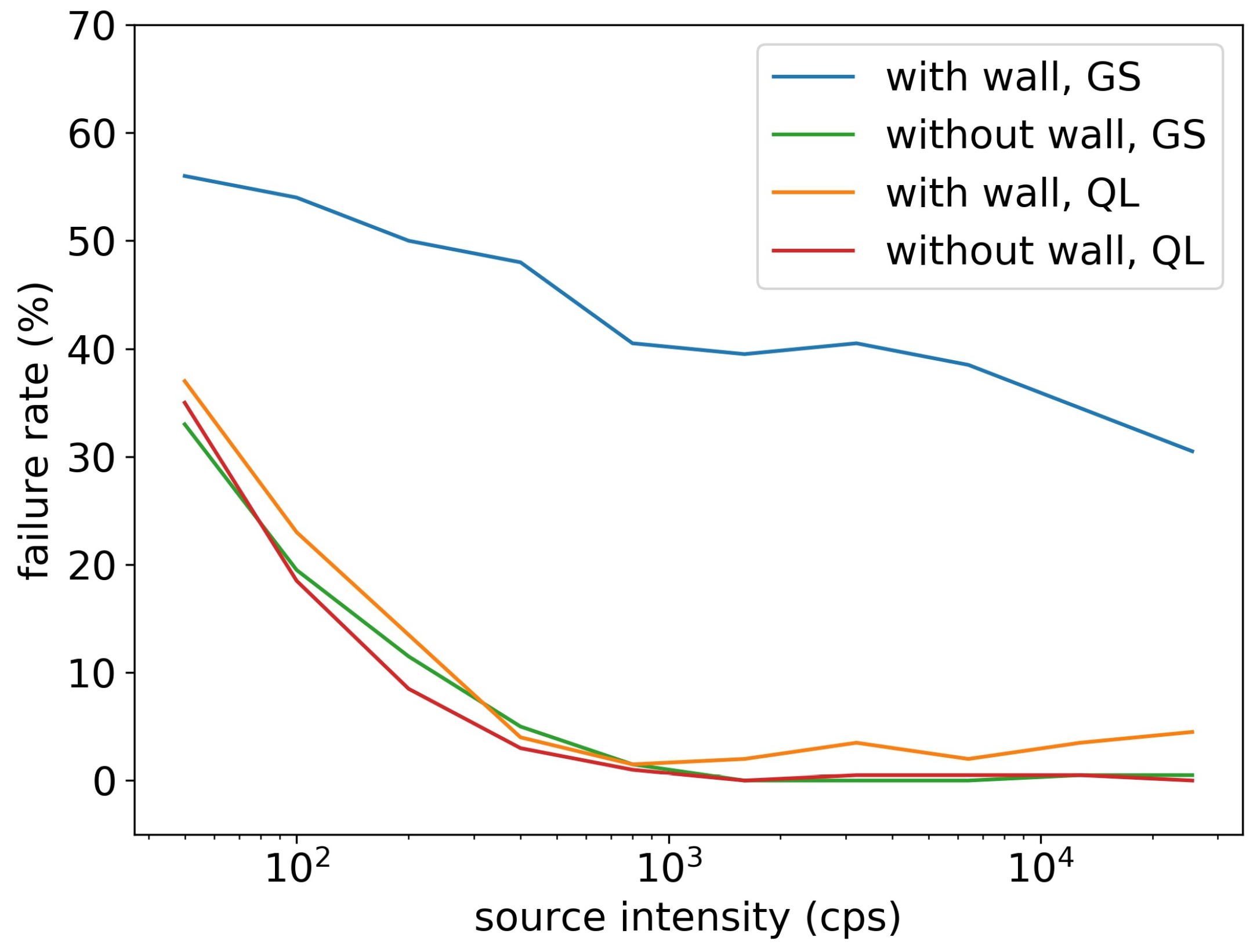
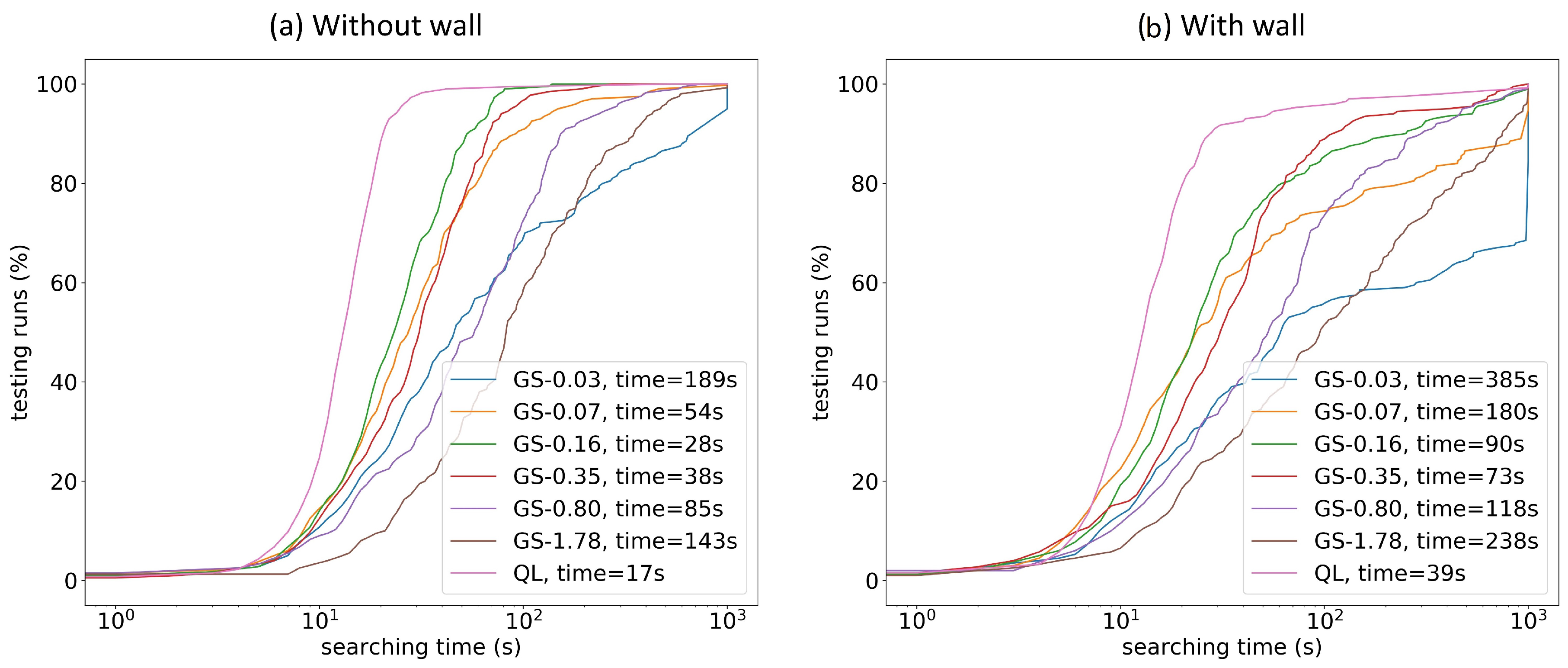
3.2. Radiation Source Searching Test
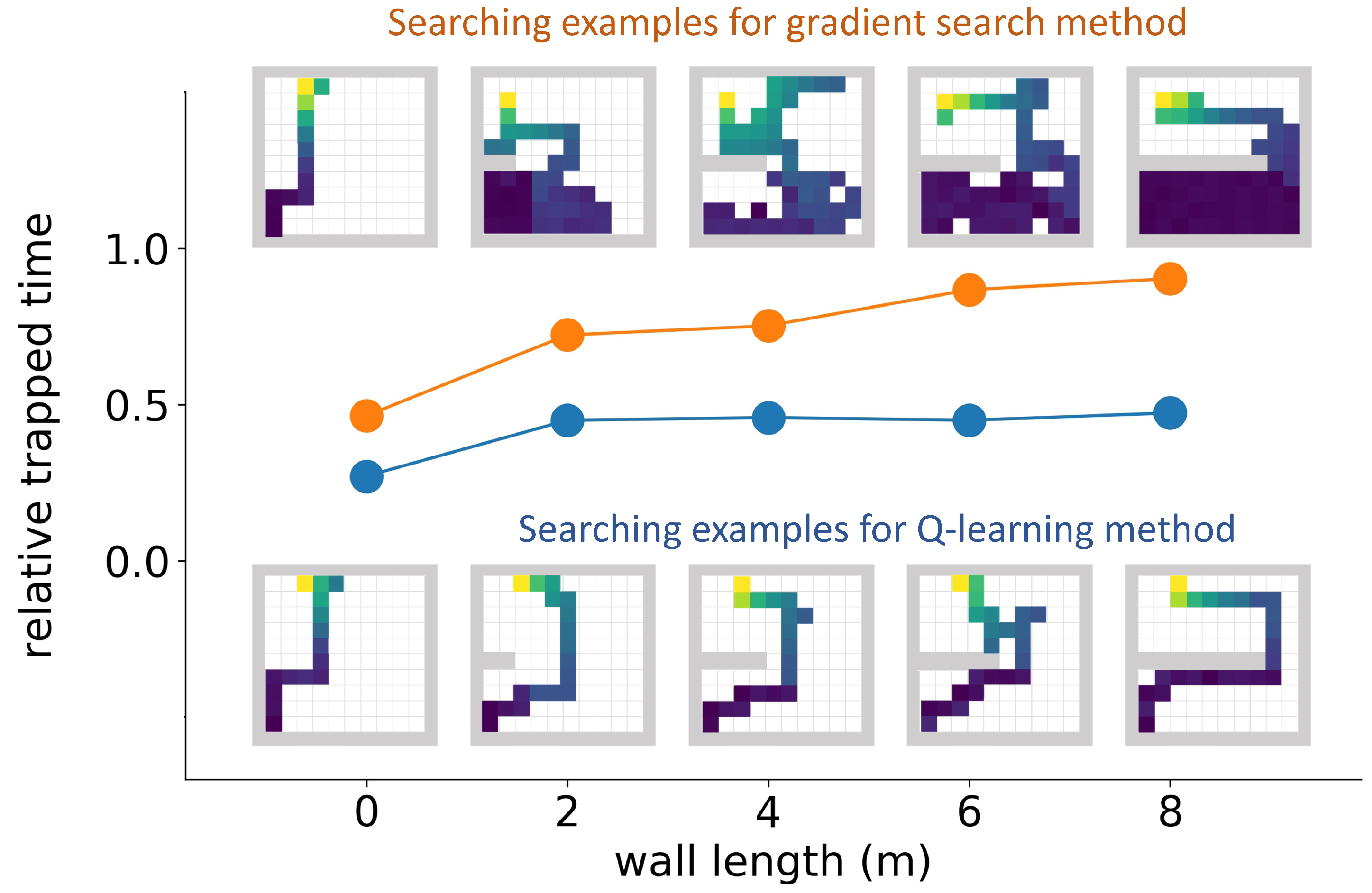
3.3. Detector Trapping Test
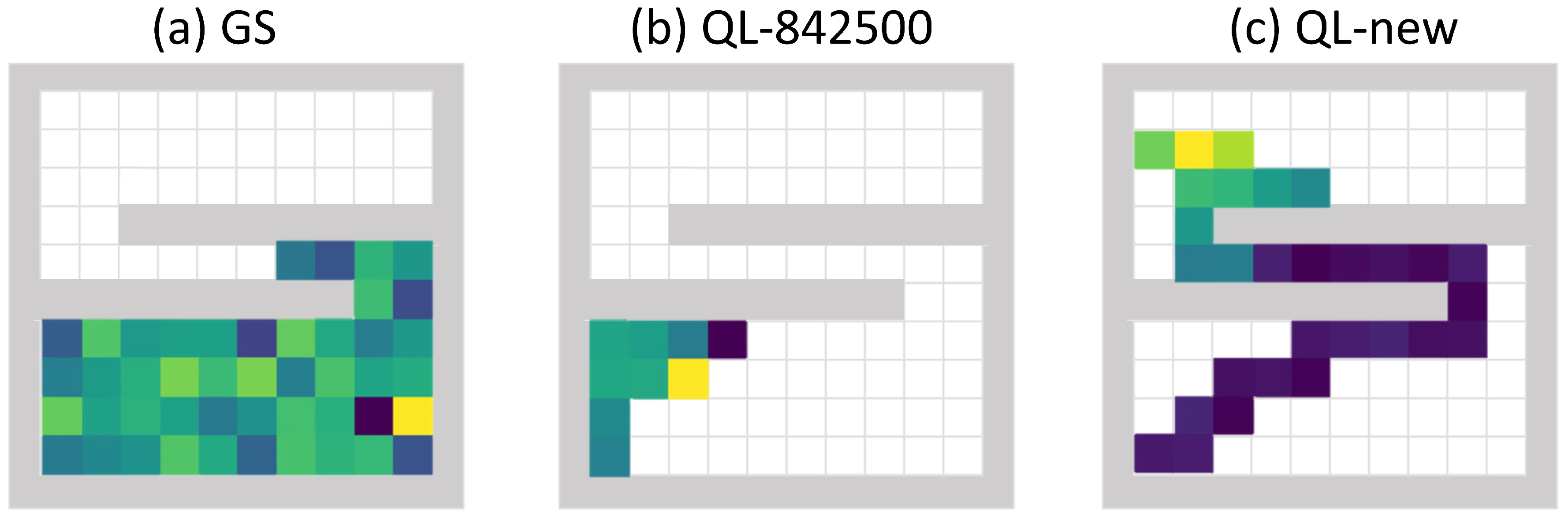
3.4. Radiation Source Estimation Test
4. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
Appendix A. Q-Learning and Radiation Source Detection
Appendix A.1. Radiation Source Detection Model
Appendix A.2. Bellman Equation in Q-Learning
Appendix A.3. Neural Network for Q-Learning
Appendix B. Training Details
| Algorithm A1 Double Q-learning with CNN. |
|
Appendix C. Other Source Searching Algorithms
Appendix C.1. Gradient Search Algorithm

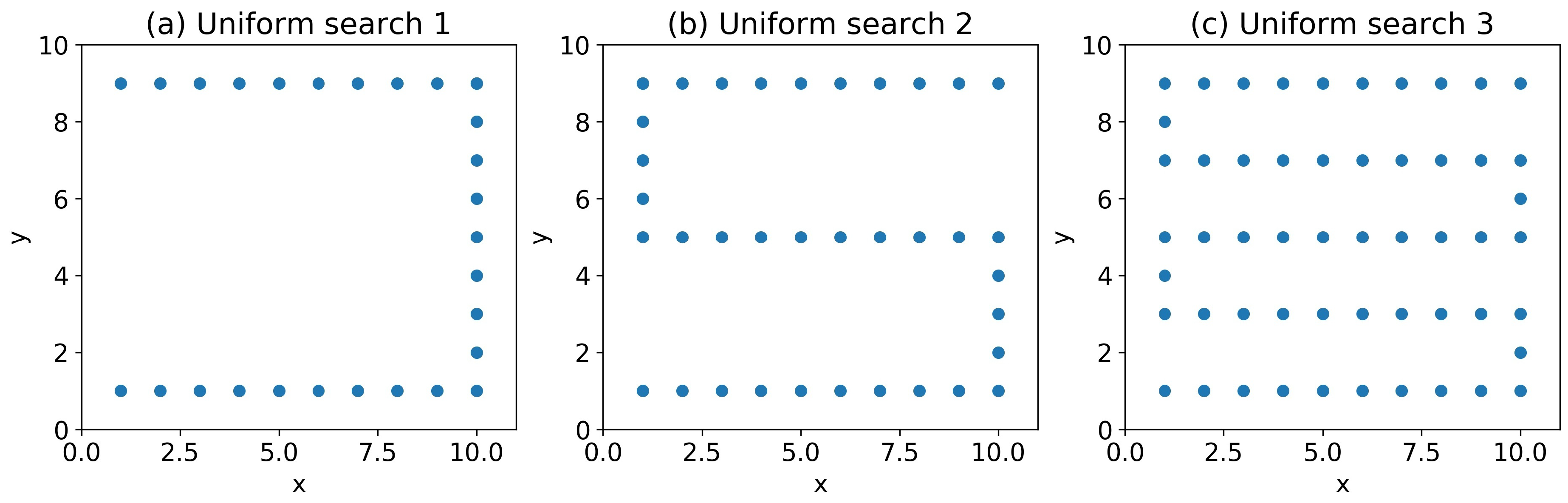
Appendix C.2. Uniform Search Algorithm

References
- Zavala, M. Autonomous Detection and Characterization of Nuclear Materials Using Co-Robots. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2016. [Google Scholar]
- Liu, A.H. Simulation and Implementation of Distributed Sensor Network for Radiation Detection. Ph.D. Thesis, California Institute of Technology, Pasadena, CA, USA, 2010. [Google Scholar]
- Philips, G.W.; Nagel, D.J.; Coffey, T. A Primer on the Detection of Nuclear and Radiological Weapons; Technical Report; National Defence University, Center For Technology and National Security Policy: Washington, DC, USA, 2005. [Google Scholar]
- International Atomic Energy Agency. Naturally Occurring Radioactive Material. Available online: https://www.iaea.org/topics/radiation-safety-norm (accessed on 19 February 2019).
- United States Nuclear Regulatory Commission. Special Nuclear Material. Available online: https://www.nrc.gov/materials/sp-nucmaterials.html (accessed on 19 February 2019).
- U.S. Department of Health and Human Services. Radiological Dispersal Devices (RDDs). Available online: https://www.remm.nlm.gov/rdd.htm (accessed on 19 February 2019).
- Gunatilaka, A.; Ristic, B.; Gailis, R. On localisation of a radiological point source. In Information, Decision and Control; IEEE: Piscataway, NJ, USA, 2007; pp. 236–241. [Google Scholar]
- Chandy, M.; Pilotto, C.; McLean, R. Networked sensing systems for detecting people carrying radioactive material. In Proceedings of the INSS 5th International Conference on Networked Sensing Systems, Kanazawa, Japan, 17–19 June 2008; pp. 148–155. [Google Scholar] [CrossRef]
- Deb, B. Iterative estimation of location and trajectory of radioactive sources with a networked system of detectors. IEEE Tran. Nucl. Sci. 2013, 60, 1315–1326. [Google Scholar] [CrossRef]
- Bai, E.W.; Heifetz, A.; Raptis, P.; Dasgupta, S.; Mudumbai, R. Maximum likelihood localization of radioactive sources against a highly fluctuating background. IEEE Trans. Nucl. Sci. 2015, 62, 3274–3282. [Google Scholar] [CrossRef]
- Liu, A.H.; Bunn, J.J.; Chandy, K.M. Sensor networks for the detection and tracking of radiation and other threats in cities. In Proceedings of the 10th International Conference onInformation Processing in Sensor Networks (IPSN), Chicago, IL, USA, 12–14 April 2011; pp. 1–12. [Google Scholar]
- Morelande, M.; Ristic, B.; Gunatilaka, A. Detection and parameter estimation of multiple radioactive sources. In Proceedings of the IEEE 10th International Conference on Information Fusion, Québec, QC, Canada, 9–12 July 2007; pp. 1–7. [Google Scholar]
- Morelande, M.R.; Ristic, B. Radiological source detection and localisation using Bayesian techniques. IEEE Trans. Signal Process. 2009, 57, 4220–4231. [Google Scholar] [CrossRef]
- Pfund, D.M.; Runkle, R.C.; Anderson, K.K.; Jarman, K.D. Examination of count-starved gamma spectra using the method of spectral comparison ratios. IEEE Trans. Nucl. Sci. 2007, 54, 1232–1238. [Google Scholar] [CrossRef]
- Alamaniotis, M.; Mattingly, J.; Tsoukalas, L.H. Kernel-based machine learning for background estimation of NaI low-count gamma-ray spectra. IEEE Trans. Nucl. Sci. 2013, 60, 2209–2221. [Google Scholar] [CrossRef]
- Klimenko, A.V.; Priedhorsky, W.C.; Hengartner, N.W.; Borozdin, K.N. Efficient strategies for low-statistics nuclear searches. IEEE Trans. Nucl. Sci. 2006, 53, 1435–1442. [Google Scholar] [CrossRef]
- Cortez, R.A.; Papageorgiou, X.; Tanner, H.G.; Klimenko, A.V.; Borozdin, K.N.; Lumia, R.; Priedhorsky, W.C. Smart radiation sensor management. IEEE Robot. Automat. Mag. 2008, 15, 85–93. [Google Scholar] [CrossRef]
- Hutchinson, M.; Oh, H.; Chen, W.H. Adaptive Bayesian sensor motion planning for hazardous source term reconstruction. IFAC Pap. Online 2017, 50, 2812–2817. [Google Scholar] [CrossRef]
- Lazna, T.; Gabrlik, P.; Jilek, T.; Zalud, L. Cooperation between an unmanned aerial vehicle and an unmanned ground vehicle in highly accurate localization of gamma radiation hotspots. Int. J. Adv. Robot. Syst. 2018, 15, 1729881417750787. [Google Scholar] [CrossRef]
- Ristic, B.; Morelande, M.; Gunatilaka, A. Information driven search for point sources of gamma radiation. Signal Process. 2010, 90, 1225–1239. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; Volume 1. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. A brief survey of deep reinforcement learning. arXiv, 2017; arXiv:1708.05866. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning; AAAI: Menlo Park, CA, USA, 2016; Volume 16, pp. 2094–2100. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 19 February 2019).
- Ziock, K.; Goldstein, W. The lost source, varying backgrounds and why bigger may not be better. In Unattended Radiation Sensor Systems for Remote Applications; AIP Publishing: College Park, MD, USA, 2002; Volume 632, pp. 60–70. [Google Scholar]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach * | Mean Estimation Error | Mean Searching Time (s) ** | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| QL | 0.057 | 0.064 | 6.3 | 7.85 | 16.70 | 22.35 | 6.90 | 15.70 | 17.75 | 15.65 | 16.75 | 22.70 |
| GS | 0.090 | 0.101 | 6.5 | 11.2 | 17.2 | 31.3 | 17.85 | 21.15 | 52.1 | 38.8 | 37.0 | 76.05 |
| U1 | 0.082 | 0.134 | 5.0 | 28 | ||||||||
| U2 | 0.024 | 0.026 | 3.1 | 37 | ||||||||
| U3 | 0.013 | 0.011 | 1.7 | 54 | ||||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Abbaszadeh, S. Double Q-Learning for Radiation Source Detection. Sensors 2019, 19, 960. https://doi.org/10.3390/s19040960
Liu Z, Abbaszadeh S. Double Q-Learning for Radiation Source Detection. Sensors. 2019; 19(4):960. https://doi.org/10.3390/s19040960
Chicago/Turabian StyleLiu, Zheng, and Shiva Abbaszadeh. 2019. "Double Q-Learning for Radiation Source Detection" Sensors 19, no. 4: 960. https://doi.org/10.3390/s19040960
APA StyleLiu, Z., & Abbaszadeh, S. (2019). Double Q-Learning for Radiation Source Detection. Sensors, 19(4), 960. https://doi.org/10.3390/s19040960